网站集群建设申请建设银行暑期招聘网站
向量数据库基础夯实:相关概念的详细介绍
向量数据库的核心功能
对于传统数据库,基本操作包括创建、读取、更新和删除记录。向量数据库的许多操作与此类似,但针对向量的复杂性进行了优化。
索引:HNSW索引与数据传输
在向量数据库中,索引向量类似于在传统数据库中创建条目。然而,这一步对于向量数据库尤为重要。向量需要被以便于搜索的方式进行组织。
HNSW(分层可导航小世界)是一种高效的索引算法,大多数向量数据库都依赖它来组织向量以实现快速搜索。
HNSW 构建了一个多层图,每个向量是一个节点,连接表示相似性。较高层次连接大体相似的向量,而较低层次则连接紧密相关的向量,使得搜索随着深入逐渐精确。
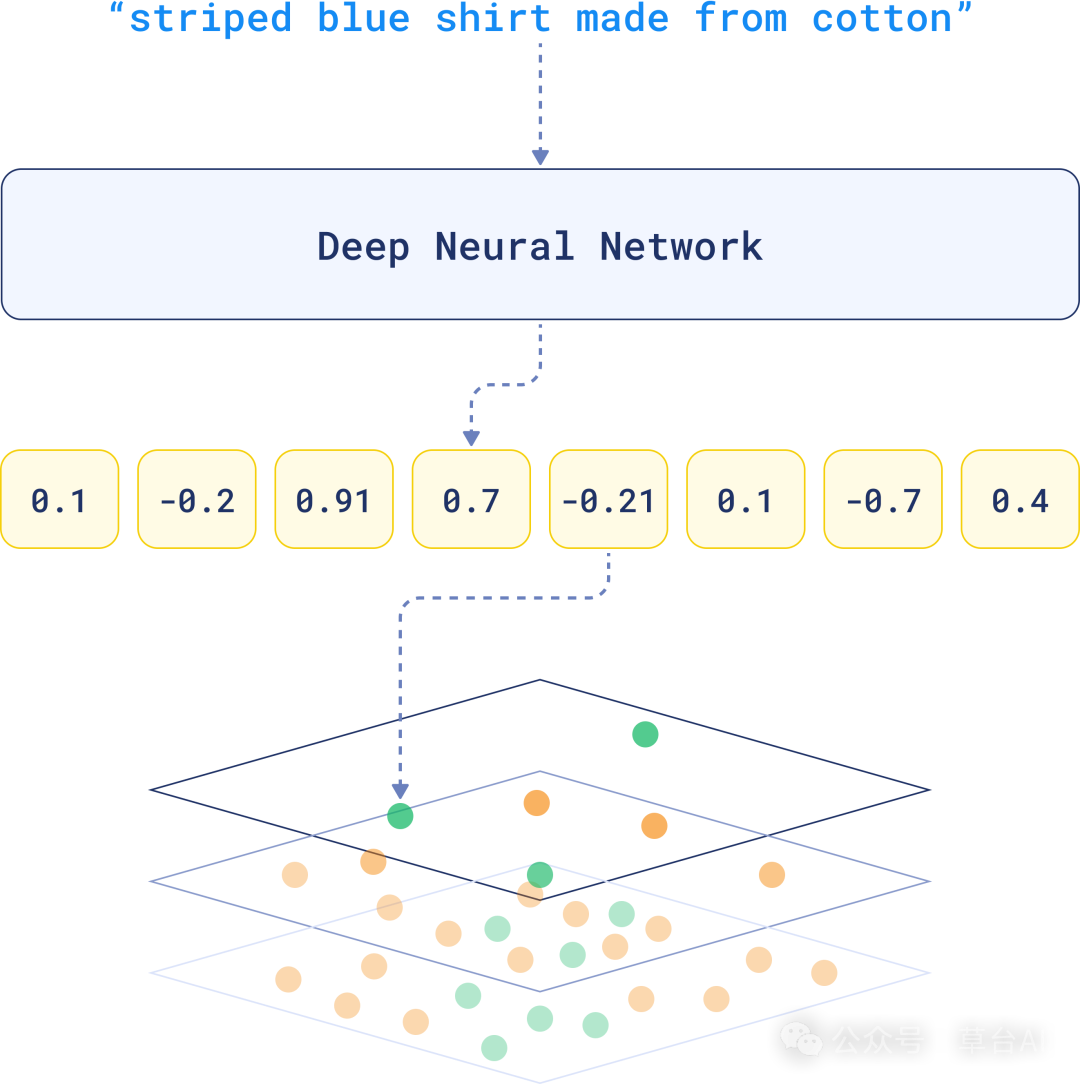
使用HNSW算法索引数据
当运行搜索时,HNSW 从顶部开始,通过跳转层快速缩小搜索范围。随着深入搜索,仅专注于相关向量。
1.1 有效负载索引
🧠 什么是 Qdrant 的「有效负载索引(Payload Index)」?
✅ 先理解几个关键词
| 术语 | 通俗解释 |
|---|---|
| 向量 | 是 chunk 向量化后产生的一组数字(语义表示) |
| 有效负载(Payload) | 是和这个向量绑定的“非语义信息”或“标签数据” |
| HNSW | 是 Qdrant 用来做向量近似检索的算法(Hierarchical Navigable Small World) |
| 索引(Index) | 是让数据库“查得快”的技术 |
📦 举个例子说明
假设你把以下三个文档 chunk 向量化后存入 Qdrant:
| 向量ID | 向量 | Payload(元数据) |
|---|---|---|
| 1 | [0.13, -0.21, ...] | {category: "法律", source: "合同.pdf"} |
| 2 | [0.91, 0.04, ...] | {category: "医疗", source: "病例.docx"} |
| 3 | [0.72, -0.61, ...] | {category: "法律", source: "政策.md"} |
如果你现在的用户问题是:
“查找和‘知识产权纠纷’相关的法律文档”
你希望做到两件事:
✅ 用“知识产权纠纷”这个问题 → 转成向量 → 找语义上相似的文段(这是 HNSW 处理的)
✅ 只返回 category = “法律” 的内容(这是 Payload 过滤处理的)
🟩 那什么是「有效负载索引」?
Qdrant 默认是可以用 Payload 做“过滤”的,比如你可以写:
"filter": {"must": [{ "key": "category", "match": { "value": "法律" } }]
}
但是!为了加速这种过滤条件的执行速度,你需要“为这个字段建一个索引”。
✅ 有效负载索引的作用就是:
⚡ 加速 Payload 的过滤效率,让你在千万级数据中也能快速过滤出想要的那几类。
🔧 怎么用?
你可以在 Python 中给某个字段加上索引:
client.create_payload_index(collection_name="my_docs",field_name="category",field_schema="keyword" # 告诉 Qdrant 这个是用来匹配的字段
)
这相当于告诉 Qdrant:
“以后在用 category 这个字段过滤数据的时候,请提前建立索引,加快匹配速度。
2. 搜索:近似最近邻(ANN)搜索
相似性搜索允许你按意义进行搜索。例如,查找唤起相同情感的类似歌曲、匹配艺术构想的图像,甚至探索文本中的情感模式。

相似单词的分组
工作原理是,当用户向数据库查询时,查询也会被转换成一个向量。算法快速识别图中最可能包含与查询向量最近的区域
搜索逐步向下进行,逐渐缩小范围到更相关的向量。当在底层找到最接近的向量时,这些点会被翻译回实际数据,表示你的最高分文档。
3. 更新向量:实时与批量调整
数据是动态的,向量也不例外。保持向量的最新状态对于搜索的相关性至关重要。
实时更新: 当需要立即调整向量时,Qdrant 提供了高效的实时修改功能:
批量更新: 对于大规模更改(如在模型更新后重新索引向量),批量更新可以在一个操作中更新多个向量,而不会影响搜索性能:
4. 删除向量:管理过时和重复数据
高效的向量管理是保持搜索准确性和数据库精简性的关键。删除表示过时或不相关数据的向量(如过期产品、旧新闻文章或归档用户档案),可以帮助保持性能和相关性。
在 Qdrant 中,删除向量非常简单,只需指定向量的 ID:
密集向量与稀疏向量
密集向量与稀疏向量
理解向量的基本概念后,接下来要了解两种主要的向量类型:密集向量(Dense Vectors)和稀疏向量(Sparse Vectors)。
1. 密集向量
密集向量几乎每个元素都包含信息。向量中的每个数值都贡献了数据的语义意义、关系和细微差别。
例如,这句“我爱向量相似性”的密集向量表示可能如下所示:
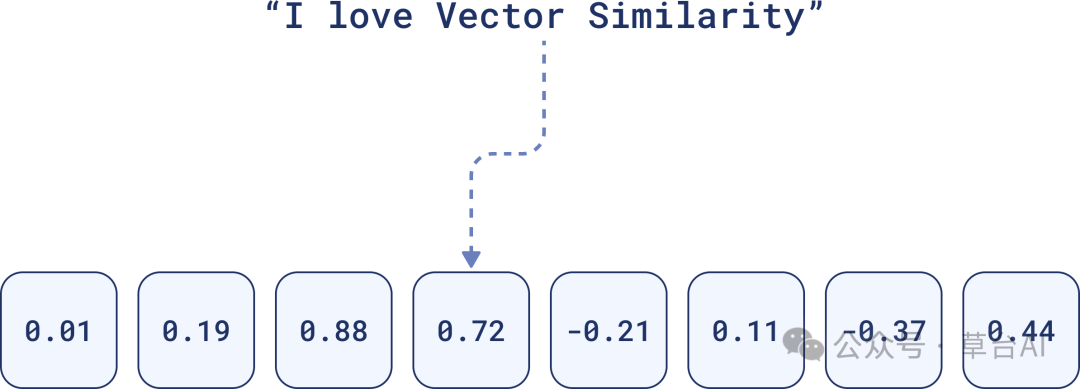
密集向量的表示
每个数字都有权重,所有数字共同传递了句子的整体意义。因此,它们更适合识别上下文相似的内容,即使字词完全不匹配。
2. 稀疏向量
稀疏向量则更注重要点。在稀疏向量中,大量元素是零。只有在某些特征或标记存在时,才会赋值非零值。
例如,“我爱向量相似性”被分解为标记(tokens)后,通过标记化(tokenization)每个标记分配一个唯一的ID,生成如下稀疏向量:
{ 193: 0.04, 9182: 0.12, 15012: 0.73, 6731: 0.69, 454: 0.21
}
稀疏向量特别适用于关键词搜索或元数据过滤,例如检查特定标记是否存在,而无需捕捉完整的意义或上下文。
| 项目 | 稀疏向量(Sparse) | 密集向量(Dense) |
|---|---|---|
| ✅ 核心思想 | 词有没有出现?出现几次? | 整体语义相似程度 |
| 📐 向量维度 | 非常高(10,000+) | 较低(256~1536) |
| 🔢 值的分布 | 大多数是 0 | 大多数是非零实数 |
| 📖 可解释性 | 强(某个词在哪个维度) | 弱(每个维度不代表具体词) |
| 🔍 匹配方式 | 精确关键词匹配 | 模糊语义匹配 |
| 🧠 适合任务 | 关键词搜索、精准查找 | 语义理解、模糊检索 |
| 🔄 模型例子 | TF-IDF、BM25 | BERT、bge、E5、OpenAI Ada |
| 🧰 检索方式 | 倒排索引、布尔查询 | 向量近似搜索(ANN) |
| 🔗 向量库支持 | Elasticsearch、VESPA | FAISS、Qdrant、Pinecone |
混合搜索的优势
有时仅靠上下文还不够,需要同时具有精确匹配能力。密集向量非常适合基于数据的上下文或意义检索结果,而稀疏向量则在需要关键词或特定属性匹配时表现优异。
混合搜索允许同时利用两者的优势,实现更相关且经过过滤的搜索。
例如,Qdrant 使用归一化和融合技术来将多种搜索方法的结果结合起来。常见的融合方法是互惠排名融合(RRF),它结合了不同方法的结果,并将同时被两种方法高度评价的项优先列出。