【Transformer入门到实战】神经网络基础知识和常见激活函数详解
🚀 作者 :“大数据小禅@yopai”
🚀 文章简介 :本专栏后续将持续更新大模型相关文章,从开发到微调到RAG、多Agent等,个V: 【yopa66】,持续分享前沿AI实战。
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬
Transformer入门篇
- 一、Transformer到底是个啥?
- 1.1 Transformer解决了什么问题?
- 1.2 Transformer的核心思想
- 二、Transformer和大模型是什么关系?
- 2.1 简单类比
- 2.2 著名的大模型都用Transformer
- 2.3 训练大模型的过程
- 三、神经网络是什么?
- 3.1 人脑神经元的启发
- 3.2 人工神经元
- 3.3 神经网络 = 很多神经元连在一起
- 四、激活函数:神经网络的灵魂
- 4.1 为什么需要激活函数?
- 4.2 常见的激活函数
- **1. Sigmoid函数**
- **2. ReLU (Rectified Linear Unit) - 最常用!**
- **3. Leaky ReLU - ReLU的改进版**
- **4. GELU (Gaussian Error Linear Unit) - Transformer最爱!**
- **5. Tanh (双曲正切函数)**
- **6. Softmax - 多分类专用**
- 五、总结:把所有知识串起来
- 📚 知识框架
一、Transformer到底是个啥?
简单来说,Transformer就是一种神经网络架构,就像盖房子的图纸一样。2017年Google的研究人员在论文《Attention is All You Need》中提出了它,从此改变了整个AI界。
1.1 Transformer解决了什么问题?
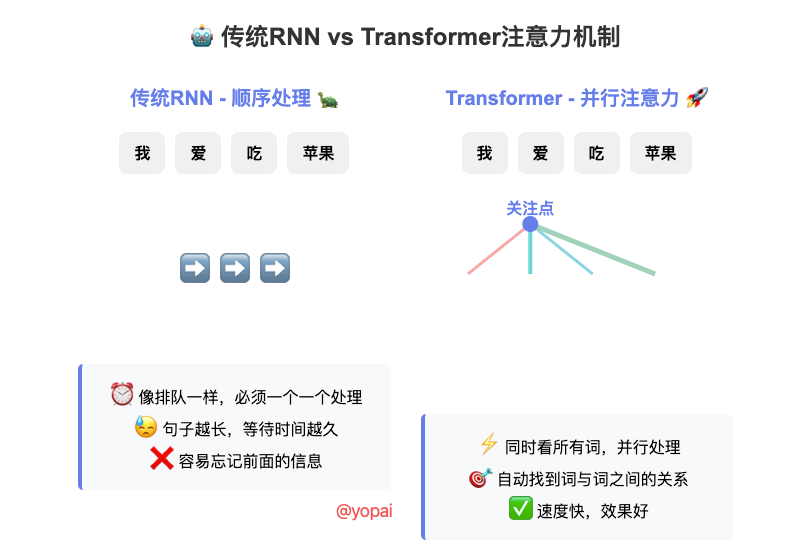
在Transformer出现之前,处理文本主要用RNN(循环神经网络)和LSTM。但这些模型有个大问题:处理长文本时太慢了!
举个例子:
- 你要翻译一句话:“我今天早上吃了一个苹果”
- 传统RNN要这样处理:先看"我",再看"今天",再看"早上"…一个字一个字按顺序来
- 这就像你排队买奶茶,前面的人不走,你就得一直等
而Transformer用了自注意力机制(Self-Attention),可以同时看所有的字,就像开了很多个窗口,大家一起办业务,效率高多了!
1.2 Transformer的核心思想
Transformer的核心是"注意力机制"。什么意思呢?
想象你在读一篇文章:
- 当你看到"它"这个字时,你的大脑会自动往前找,"它"指的是什么
- 可能是前面提到的"猫",也可能是"汽车"
- 你的大脑会自动"注意"到相关的词
Transformer就是模仿这个过程,让模型学会关注句子中最重要的部分。
二、Transformer和大模型是什么关系?
2.1 简单类比
- Transformer = 建筑设计图纸
- 大模型 = 用这个图纸建出来的摩天大楼
更具体地说:
- Transformer是架构,告诉你神经网络应该怎么搭建
- 大模型是用这个架构训练出来的具体模型
2.2 著名的大模型都用Transformer
看看这些你肯定听过的名字:
- GPT系列 (GPT-3, GPT-4, ChatGPT)
- 只用了Transformer的**解码器(Decoder)**部分
- 擅长生成文本、对话、写代码
- BERT
- 只用了Transformer的**编码器(Encoder)**部分
- 擅长理解文本、分类、问答
- T5、BART
- 用了完整的Transformer(Encoder + Decoder)
- 擅长翻译、摘要等任务
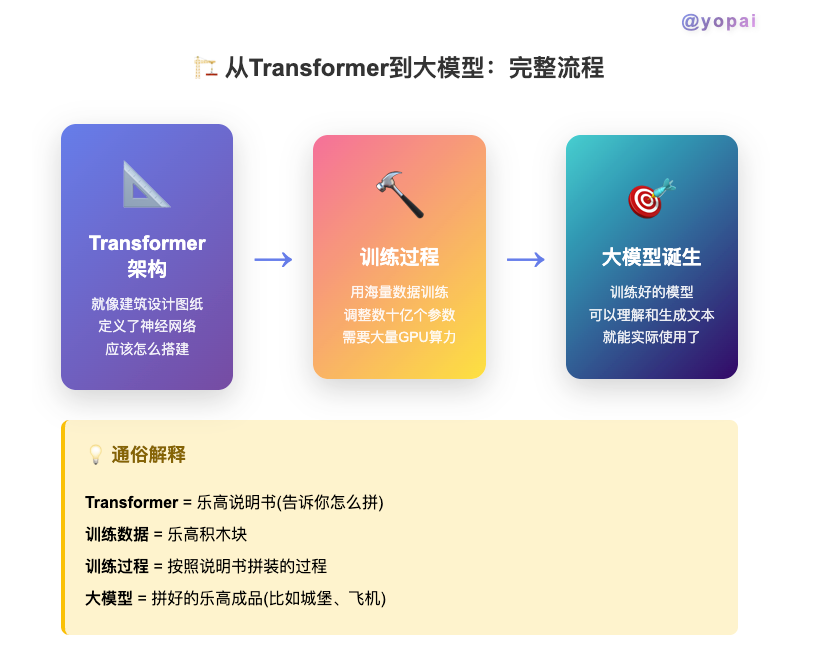
2.3 训练大模型的过程
大模型使用了Transformer架构训练过程是这样的:
- 准备数据:收集海量文本(比如整个互联网的文章)
- 搭建架构:按照Transformer设计搭建神经网络
- 开始训练:让模型不断学习,调整参数
- 得到大模型:训练好后就能用了
就像:
- Transformer = 健身房的器材和训练计划
- 训练过程 = 你每天去健身
- 大模型 = 练出来的好身材
三、神经网络是什么?
在讲激活函数之前,我们得先理解什么是神经网络。
3.1 人脑神经元的启发
人的大脑有大约860亿个神经元,它们互相连接,传递信息。神经网络就是模仿这个原理!
一个神经元的工作原理:
- 接收信号:从其他神经元接收电信号
- 处理信号:把这些信号加起来
- 决定是否激活:如果信号够强,就"点亮",传给下一个神经元
3.2 人工神经元
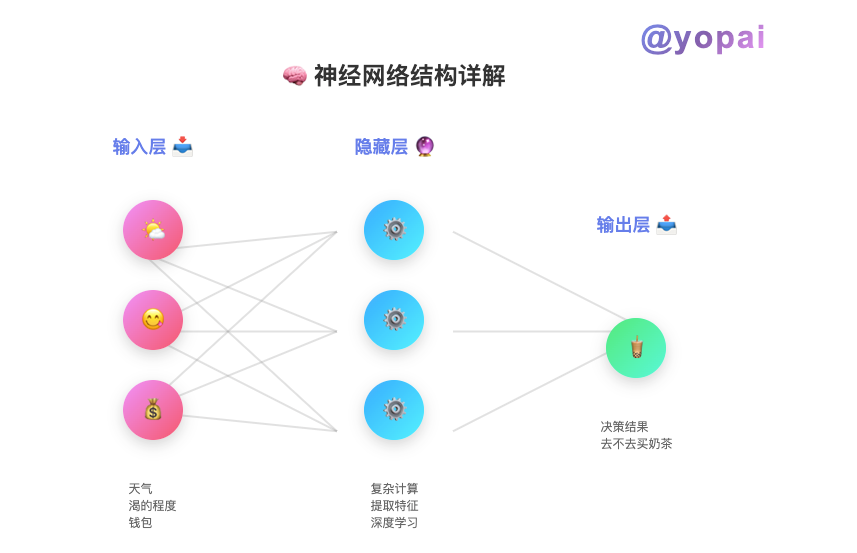
计算机里的神经元是这样工作的:
输入1 × 权重1 + 输入2 × 权重2 + 输入3 × 权重3 + 偏置 = 输出
举个实际例子,判断要不要出门买奶茶:
- 输入1:天气好不好 (0-10分)
- 输入2:有多渴 (0-10分)
- 输入3:钱包里有多少钱 (0-10分)
每个输入都有一个权重(重要性):
- 天气权重 = 0.3 (不太重要)
- 渴的程度权重 = 0.5 (比较重要)
- 钱的数量权重 = 0.2 (不太重要)
计算:
决策分数 = 天气×0.3 + 渴×0.5 + 钱×0.2 + 偏置
如果分数 > 5,就去买奶茶!
3.3 神经网络 = 很多神经元连在一起
一个神经元只能做简单判断,但把成千上万个神经元连起来,分成好几层,就能处理超级复杂的任务!
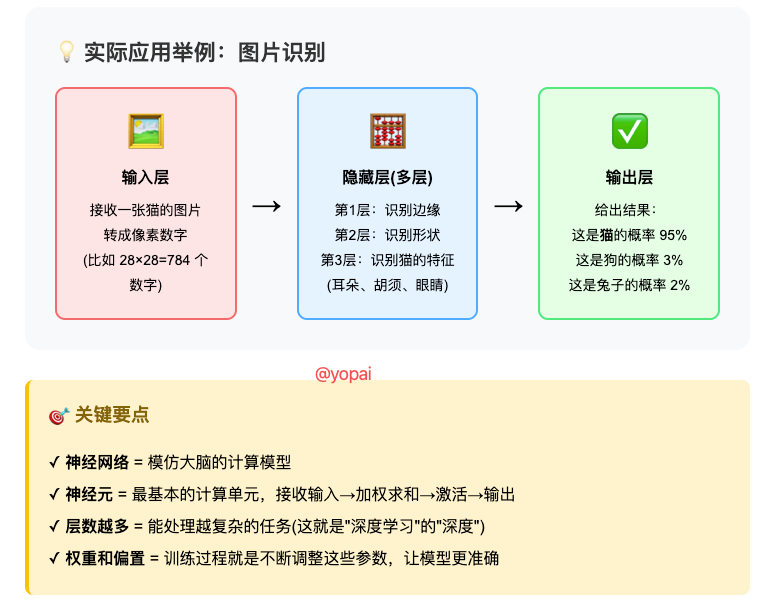
典型的三层结构:
- 输入层:接收原始数据
- 隐藏层:进行复杂计算(可以有很多层)
- 输出层:给出最终结果
四、激活函数:神经网络的灵魂
激活函数是神经网络中非常重要的部分。
4.1 为什么需要激活函数?
不用激活函数会怎样?
如果没有激活函数,神经网络就只能做线性计算:
y = w1×x1 + w2×x2 + w3×x3 + b
这样不管你堆多少层,本质上都等于一个简单的线性函数!就像:
- 1层线性 = y = 2x + 1
- 100层线性堆叠 = 还是 y = 某个数×x + 某个数
这太简单了,根本处理不了复杂问题!
有了激活函数之后:
激活函数引入了非线性,让神经网络可以学习复杂的模式。就像:
- 线性 = 只能画直线
- 非线性 = 可以画曲线、圆、各种复杂图形
4.2 常见的激活函数
1. Sigmoid函数
公式: σ(x) = 1 / (1 + e^(-x))
特点:
- 输出范围:0到1之间
- 形状:S形曲线
- 可以理解为"概率"
形象理解: 就像一个温柔的开关:
- 当输入很小时(负数),输出接近0 = “关”
- 当输入很大时(正数),输出接近1 = “开”
- 中间过渡是平滑的
什么时候用?
- 二分类问题的输出层(判断是或否)
- 需要输出概率的时候
缺点:
- 容易梯度消失(训练变慢)
- 计算相对慢
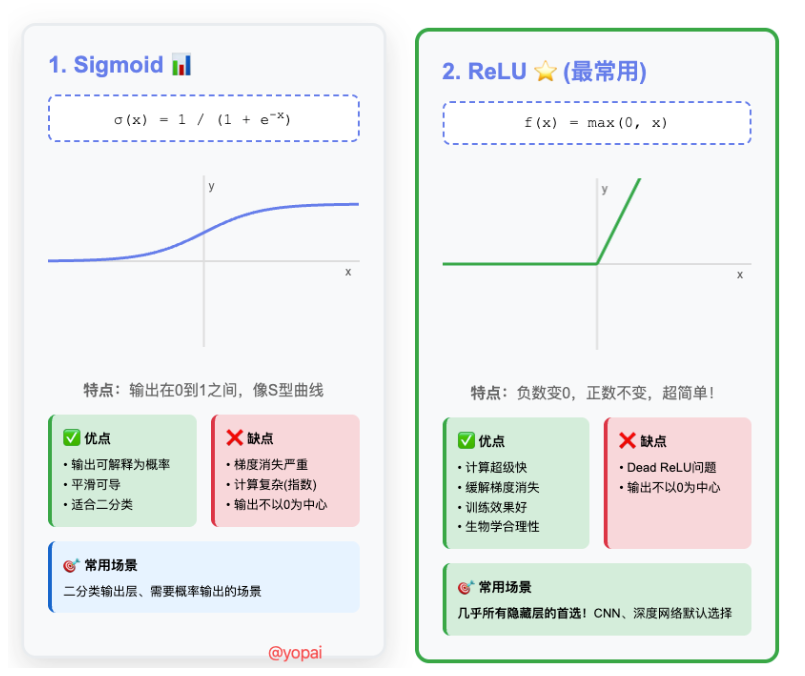
2. ReLU (Rectified Linear Unit) - 最常用!
公式: f(x) = max(0, x)
特点:
- 输入为负数时,输出0
- 输入为正数时,输出就是输入本身
形象理解: 就像一个严格的门卫:
- 负面情绪(负数)一律拦住 = 输出0
- 正面能量(正数)直接放行 = 输出原值
为什么这么受欢迎?
- 计算超快(只需要比较大小)
- 缓解梯度消失问题
- 训练效果好
什么时候用?
- 隐藏层的默认选择
- 几乎所有的深度学习模型
缺点:
- "Dead ReLU"问题:有些神经元可能永远输出0
3. Leaky ReLU - ReLU的改进版
公式: f(x) = max(0.01x, x)
特点:
- 负数时不是完全为0,而是一个很小的负数(0.01x)
形象理解: 比ReLU温柔一点的门卫:
- 负面情绪不是完全拦住,而是让它稍微进来一点点
优点:
- 解决了Dead ReLU问题
- 保留了ReLU的优点
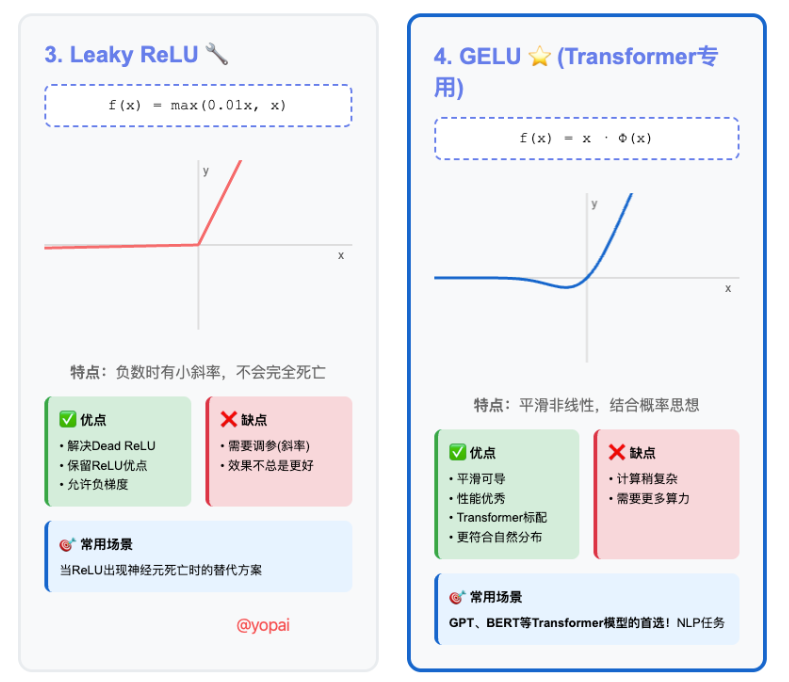
4. GELU (Gaussian Error Linear Unit) - Transformer最爱!
公式: f(x) = x × Φ(x) (其中Φ(x)是高斯分布的累积分布函数)
特点:
- 更平滑的曲线
- 结合了概率的思想
形象理解: 就像一个会思考的智能门卫:
- 不只看正负,还看"有多正"或"有多负"
- 决策更细腻、更智能
为什么Transformer用它?
- 训练效果更好
- 更符合自然语言的分布特征
- GPT、BERT都在用!
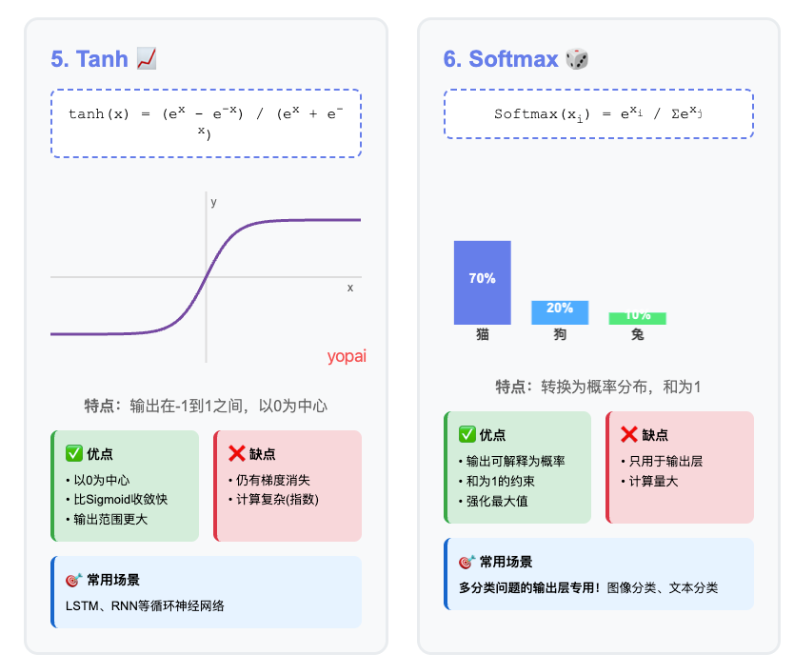
5. Tanh (双曲正切函数)
公式: tanh(x) = (e^x - e^(-x)) / (e^x + e^(-x))
特点:
- 输出范围:-1到1之间
- 形状:S形曲线,但中心在0
形象理解: 类似Sigmoid,但更对称:
- 负输入给负输出
- 正输入给正输出
- 比Sigmoid收敛更快
什么时候用?
- 需要输出正负值的场景
- LSTM等循环神经网络
6. Softmax - 多分类专用
公式: Softmax(xi) = e^xi / Σe^xj
特点:
- 把一堆数字转成概率分布
- 所有输出加起来=1
形象理解: 就像评委打分:
- 输入:[猫:5分, 狗:2分, 兔子:1分]
- 输出:[猫:70%, 狗:24%, 兔子:6%]
- 把分数变成百分比,加起来刚好100%
什么时候用?
- 多分类问题的输出层
- 需要概率分布的时候
五、总结:把所有知识串起来
📚 知识框架
- Transformer是什么?
- 一种神经网络架构(设计图纸)
- 基于自注意力机制
- 可以并行处理,速度快
- Transformer和大模型的关系
- Transformer = 架构设计
- 大模型 = 用这个架构训练出来的成品
- GPT、BERT都是基于Transformer
- 神经网络基础
- 模仿人脑神经元
- 由输入层、隐藏层、输出层组成
- 通过权重和偏置进行计算
- 激活函数的作用
- 引入非线性
- 让网络能学习复杂模式
- 不同场景选择不同的激活函数
如果你要做NLP任务(比如训练一个小型语言模型):
架构:Transformer
隐藏层激活函数:GELU
输出层:Softmax(分类)或Linear(生成)
如果你要做图像识别:
架构:CNN
隐藏层激活函数:ReLU
输出层:Softmax
如果你遇到训练问题:
- ReLU导致神经元死亡 → 试试Leaky ReLU
- 训练太慢 → 检查是不是用了Sigmoid/Tanh在隐藏层
- Transformer效果不好 → 确认是否用了GELU