windows10安装WSL2 ubuntu24.04中安装vLLM vLLM中部署Qwen2.5-VL
文章目录
- 一、安装WSL2
- 下载 wsl.x64.msi 并安装
- 登录WSL
- Ubuntu 24.04 迁移到 D 盘
- 二、安装uv
- 三、创建虚拟环境并安装vLLM
- 四、测试Qwen2.5-VL模型的效果
- 1. 下载Qwen2.5-VL模型
- 2. 注
本文记录下,如何使用vLLM部署模型。安装教程参考视频教程:https://www.bilibili.com/video/BV1BijSzfEmQ/。由于vLLM只支持Linux操作系统,所以首先安装WSL2。
一、安装WSL2
在管理员模式下打开CMD,输入 wsl --install ,然后重新启动计算机。点击此处可查看微软官方文档。
下载 wsl.x64.msi 并安装
实际上,用上述指令下载是很慢的,我们可以手动下载 WSL 安装包。访问网址 https://github.com/microsoft/WSL/releases 即可下载。按下图安装即可。
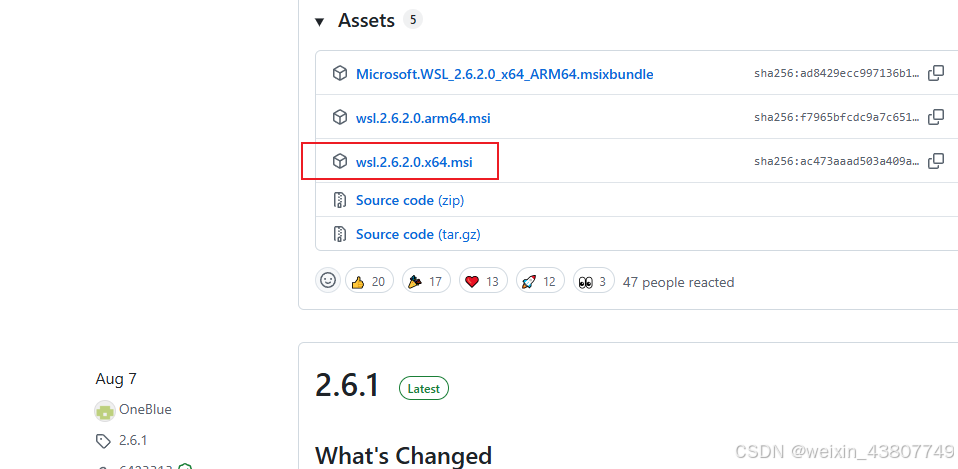
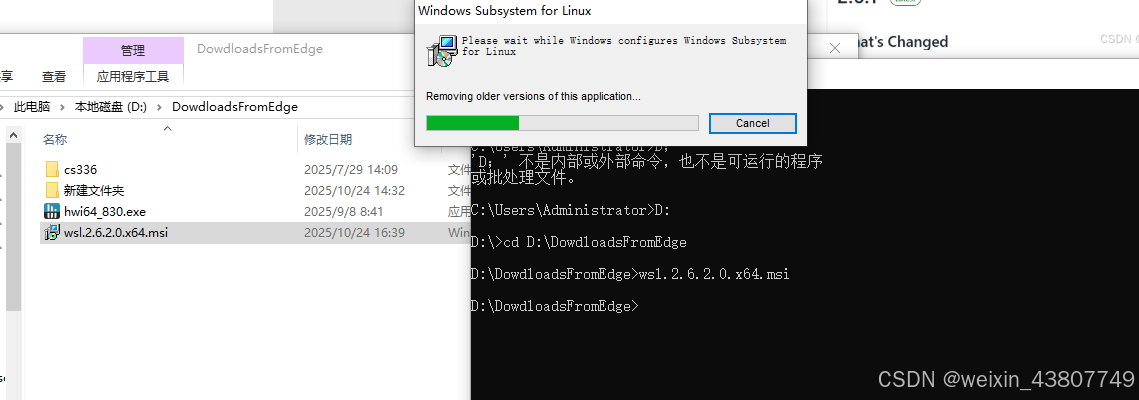
WSL2安装好了,可以使用wsl.exe --list --online查看支持的操作系统。接下来安装ubuntu24.04:wsl.exe --install Ubuntu-24.04。这个下载速度就快多了。
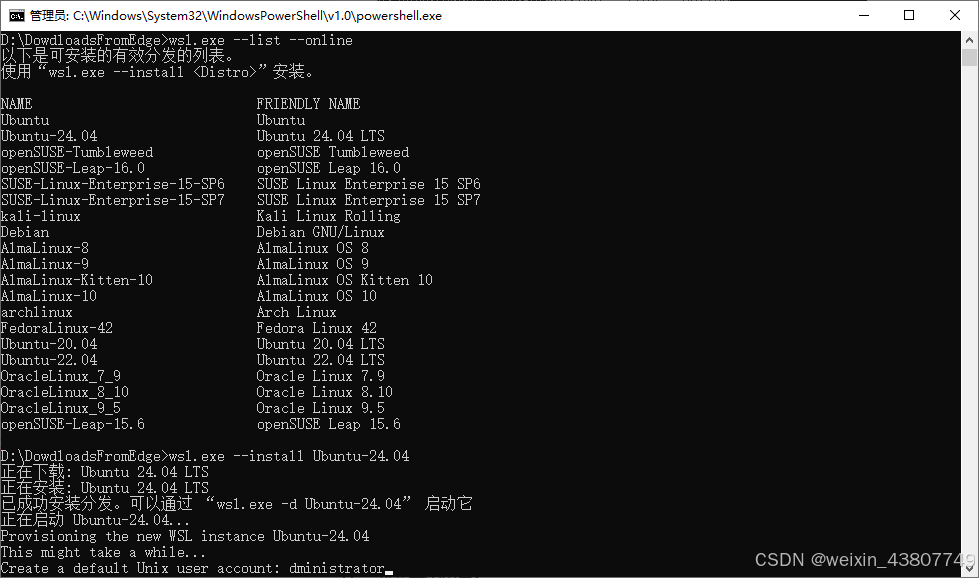
查看所用的WSL版本: wsl -l -v
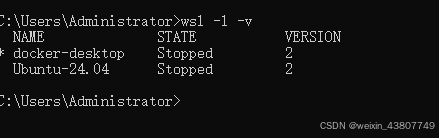
登录WSL
创建一个默认用户xx,设置密码:
可以查看所用的Linux版本: lsb_release -a

更新软件包:sudo apt update && sudo apt upgrade
Ubuntu 24.04 迁移到 D 盘
首先我们查看一下虚拟机状态,输入下列命令:
wsl -l -v执行 wsl --shutdown 命令使其停止运行,再次执行 wsl -l -v 确认停用。先手动创建迁移的目标文件夹,然后通过命令导出原虚拟机的备份:
wsl --export Ubuntu-24.04 D:\WSL2\Ubuntu\Ubuntu.tar注销原 wsl 虚拟机:
wsl --unregister Ubuntu-24.04将备份导入到新的目标文件夹中:
wsl --import Ubuntu-24.04 D:\WSL2 D:WSL2\Ubuntu\Ubuntu.tar开启WSL2
二、安装uv
官方教程:https://uv.doczh.com/getting-started/installation/ 按照教程中的curl -LsSf https://astral.sh/uv/install.sh | sh下载很慢。我们可以直接访问https://astral.sh/uv/install.sh 把文件下载下来,然后切换到sh文件目录,执行:chmod +x uv-installer.sh并安装./uv-installer.sh。
一般这一步也会卡。。。
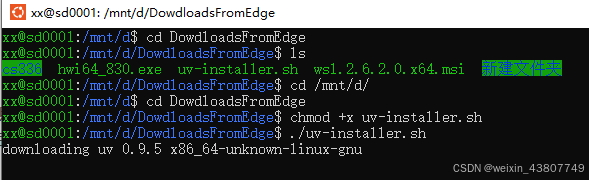
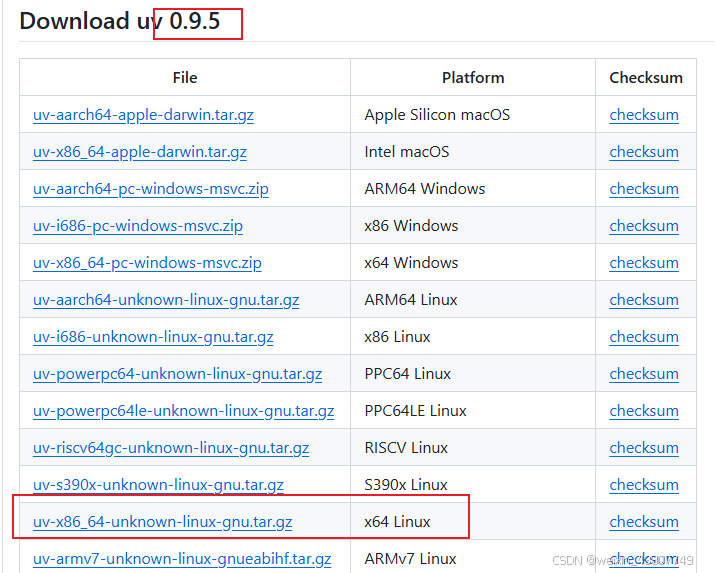
直接访问uv官网https://github.com/astral-sh/uv/releases下载文件,然后手动安装:
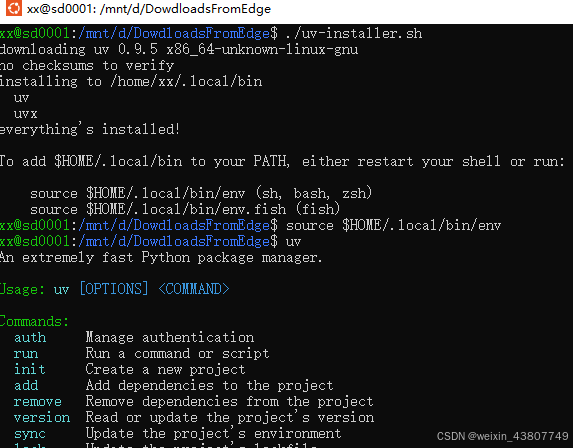
如果你安装成功了,执行source $HOME/.local/bin/env 即可:
三、创建虚拟环境并安装vLLM
vLLM的安装可参考官网文档:https://docs.vllm.com.cn/en/latest/getting_started/installation/gpu.html
这里我们使用uv安装。
uv venv --python 3.12
source .venv/bin/activate
uv pip install "vllm>=0.8.5" modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
# 有可能需要: uv pip install flashinfer-python==0.2.10 -i https://pypi.tuna.tsinghua.edu.cn/simple
四、测试Qwen2.5-VL模型的效果
1. 下载Qwen2.5-VL模型
激活vllm虚拟环境,下载模型:
modelscope download --model Qwen/Qwen2.5-VL-32B-Instruct-AWQ --local_dir /mnt/d/scripts/myvllm2/model/Qwen2.5-VL-32B-Instruct-AWQ
Qwen2.5-VL-7B-Instruct支持最长32768个token的上下文长度。使用双卡运行模型:
export TORCH_CUDA_ARCH_LIST="8.9"
export CUDA_VISIBLE_DEVICES=3,4
vllm serve model/Qwen2.5-VL-7B-Instruct \--tensor-parallel-size 2 \--max-model-len 32768 \--dtype auto \--gpu-memory-utilization 0.90 \--port 8089 \--host 0.0.0.0 \--enable-auto-tool-choice \--tool-call-parser hermes \--enable-chunked-prefill \--enable-prefix-caching
实测效果如下:
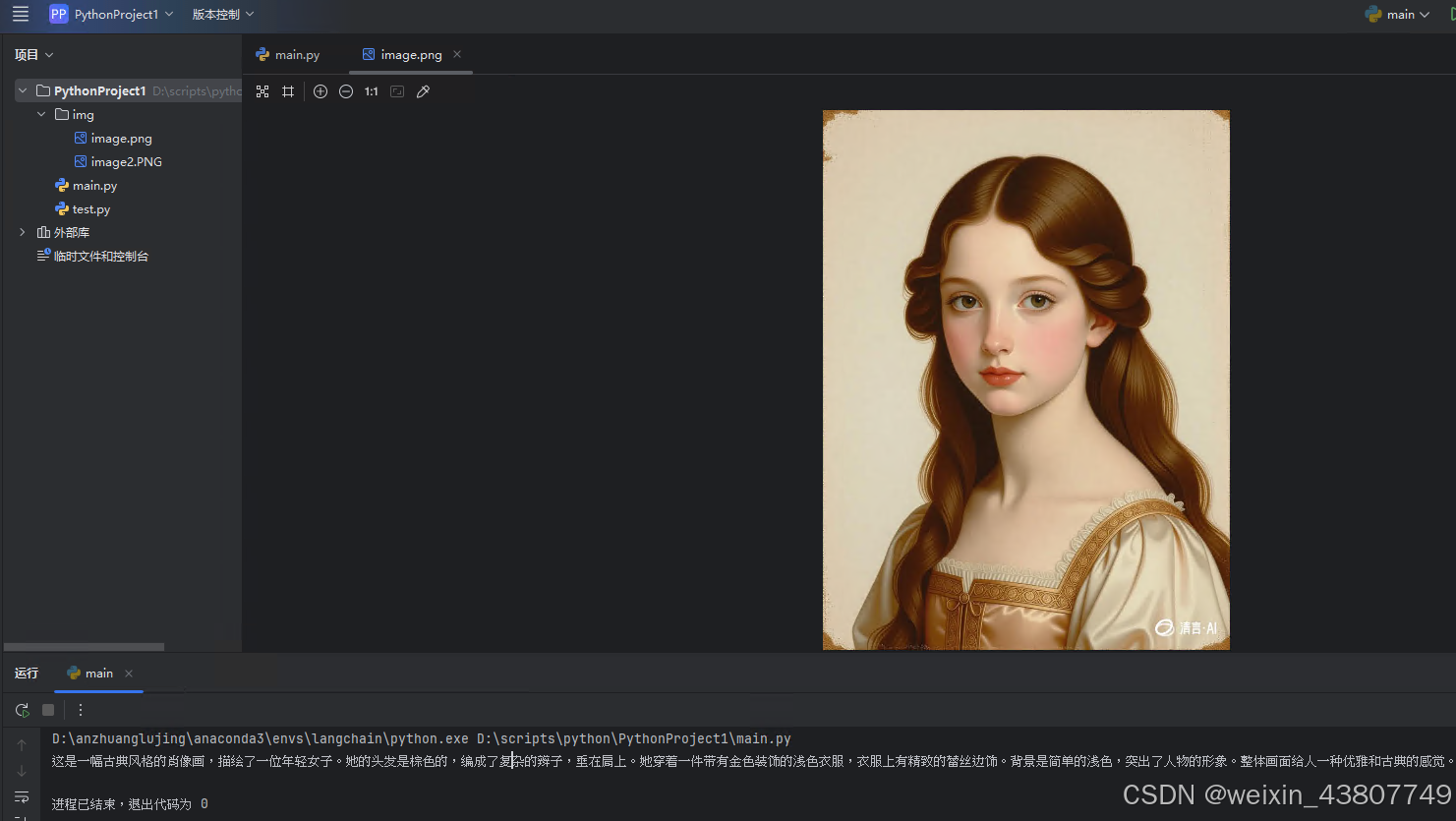
测试代码如下:
from openai import OpenAI
import base64# 初始化客户端,指向你的vLLM服务器
client = OpenAI(api_key="EMPTY", # vLLM默认不需要API keybase_url="http://localhost:8089/v1" # 替换为你的服务器IP和端口
)# 函数:读取图片并转换为base64编码
def image_to_base64(image_path):with open(image_path, "rb") as image_file:return base64.b64encode(image_file.read()).decode('utf-8')# 指定本地图片路径
image_path = "img/image.png" # 请替换为你实际的图片路径# 构建请求消息
messages = [{"role": "user","content": [{"type": "text", "text": "请描述这张图片的内容。"}, # 你的文本指令{"type": "image_url","image_url": {# 指向本地图片文件"url": f"data:image/png;base64,{image_to_base64(image_path)}"}}]}
]# 发送请求
response = client.chat.completions.create(model="model/Qwen2.5-VL-7B-Instruct", # 模型名称,需与启动时一致messages=messages,max_tokens=1024 # 控制模型生成的最大token数
)# 打印模型回复
print(response.choices[0].message.content)
2. 注
笔者最开始下载的是 Qwen/Qwen2.5-VL-32B-Instruct-AWQ,2025年9月12日在vllm=0.10.1版本上,输入图片会返回乱码。
