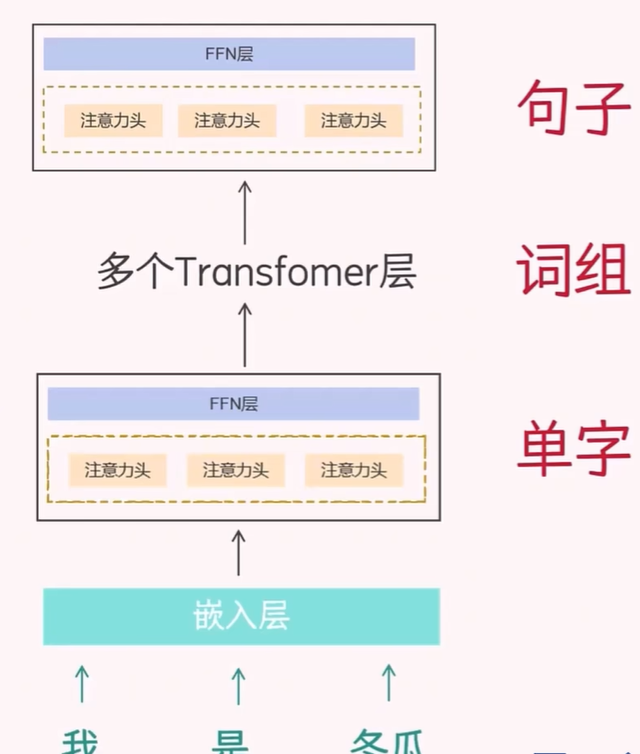
【大模型的原理 - 从输入到输出】Transformer 的 Decoder-only 架构
文章目录
- 前言
- 1. 如何准备训练数据
- 2. 嵌入层
- 3 Transformer 层
- 3.1 不涉及 QKV 之前的探讨
- 3.2 涉及 QKV 之后的探讨
- 3.3 多头注意力机制
- 3.4 FFN 层
- 4 输出层
- 参考
前言
本文将介绍大模型是如何预测下一个词(next token)的。与我们常听到的 2017 年《Attention Is All You Need》论文中提出的原始 Transformer 架构不同,那种架构是 Encoder-Decoder 结构,主要用于像机器翻译这样的序列到序列任务。
然而,在“预测下一个词”这个任务中,也就是所谓的自回归语言建模(autoregressive language modeling),我们更常使用的是Decoder-only架构。这种架构被广泛应用于像 GPT 系列这样的大语言模型中。
简单来说,Decoder-only 模型会通过前面已经生成的词,逐步预测下一个最可能的词,直到生成完整的句子或段落。这种方式更适合文本生成任务,也因此成为了当前大模型的主流架构。
当然,Encoder-Decoder 架构(如 T5)也可以用于生成任务,但在语言建模效率和效果上,Decoder-only 架构表现更佳。
1. 如何准备训练数据
大模型的本质是在不停的预测下一个词。
- 推理阶段
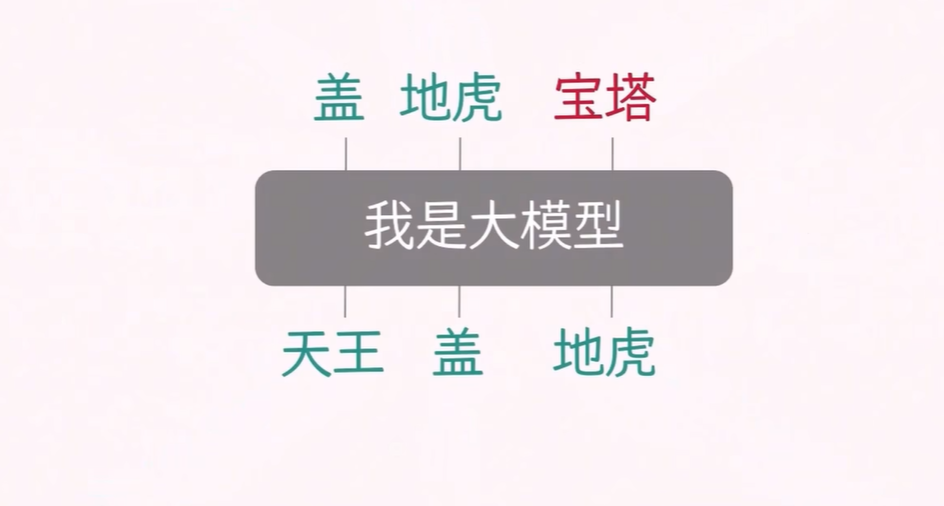
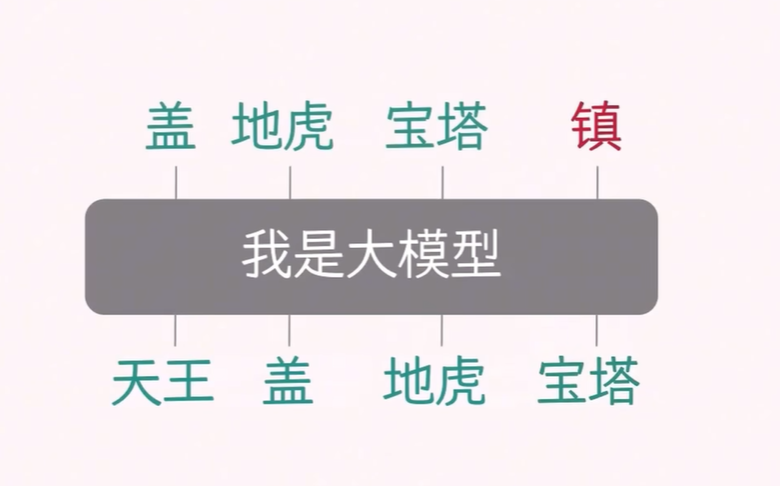
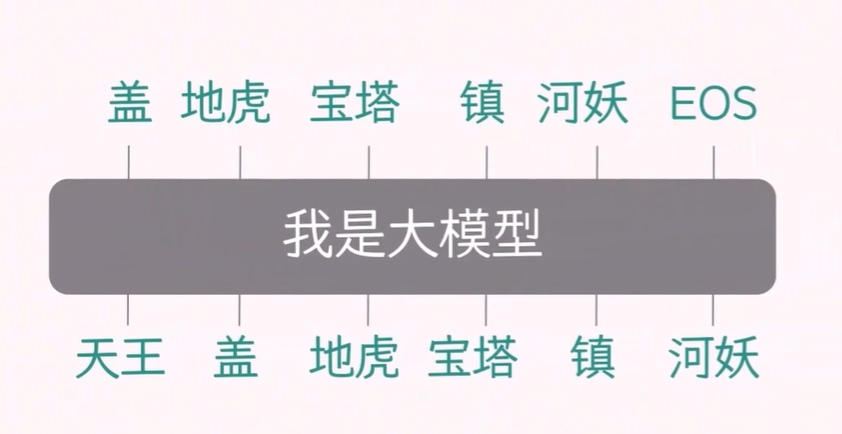
如下面四张图所示,在推理阶段,当你给大模型输入一句话,它并不会一次性吐出整句,而是生成同样长度的句子:
把已有文本送进 Decoder-only 网络;
模型在下一个位置只产出 1 个新 token(即概率最高的词);
把这个新 token 拼到原文本末尾,再整体喂回模型;
循环往复,直到输出特殊结束符 。
由于每一步都把自己上一步的输出作为下一步的输入,这种“自己回归自己”的生成方式就叫 自回归(Autoregressive)。

- 训练阶段
在训练阶段,因为有真实的标签数据,所以不必一步步生成来执行自回归操作,而是一次算完所有位置,实现并行。具体做法叫 Teacher Forcing,通过用因果掩码挡住未来信息,让第 i 个位置只能看见 0~i-1 的信息;来并行算出每个位置的预测概率,与标签求交叉熵损失,再平均后反向传播。
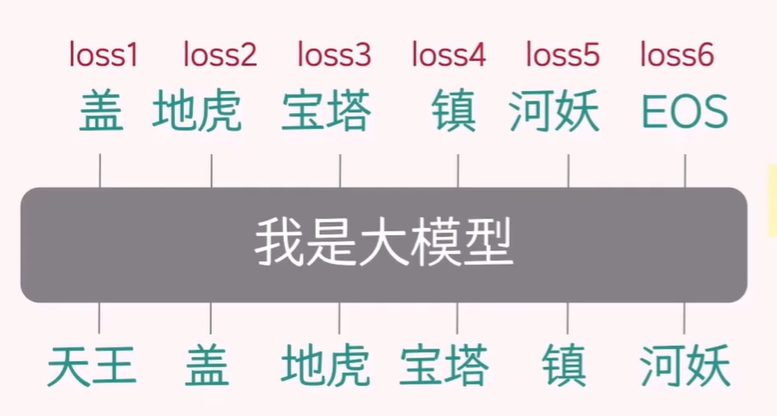

因此,从以上的训练阶段和推理阶段,可以得知我们应该如何准备数据,需要准备成对的输入和目标数据。

输入和目标数据的配对如上图所示,即:
每条样本就是这么一对等长、错位 1 的向量。
为什么要这么配对?等长、错位 1
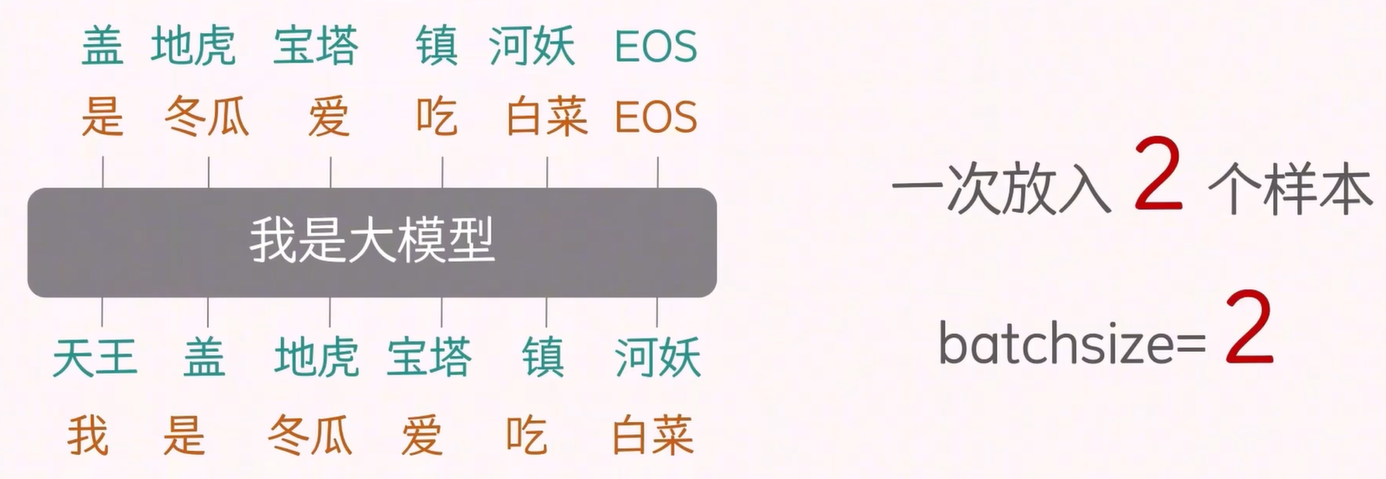
首先,这种配对方式是为了适应训练阶段的 Teacher Forcing 过程,它允许模型并行计算多个预测任务。以一个包含 6 个 token 的序列为例,输入数据是“天王 盖 地虎 宝塔 镇 河妖”,而目标数据是“盖 地虎 宝塔 镇 河妖 EOS”。这里,输入序列比目标序列提前一个 token,实现了所谓的 shift-right 配对。
在训练过程中,模型需要完成 6 个子任务,每个子任务负责预测序列中的下一个 token。这些子任务虽然可以并行计算,但模型内部的预测过程仍然是自回归的,即每个 token 的预测依赖于其前面的 token。这种错位配对方式使得模型能够在模拟自回归预测的同时,利用 Teacher Forcing 实现高效的并行计算。
| 模型能看到的 | 要猜的字 |
|---|---|
| 天王 | 盖 |
| 天王 盖 | 地虎 |
| 天王 盖 地虎 | 宝塔 |
| 天王 盖 地虎 宝塔 | 镇 |
| 天王 盖 地虎 宝塔 镇 | 河妖 |
| 天王 盖 地虎 宝塔 镇 河妖 | EOS |
训练时,模型通过一次前向传播计算出这 6 个位置的预测概率,并与真实标签进行比较,计算损失(loss),然后通过反向传播更新模型参数。这种错位 1 的设计,使得模型能够将序列中的每个 token 预测任务拆分成多个不同的子任务,同时使用前缀或掩码技术从输入和目标中提取数据,可以通过查看该表格的两列内容,左面这一列的完整内容就是输入,右面这一列的完整内容就是目标。
总结来说,错位 1 的配对方式是为了在保持自回归预测特性的同时,实现高效的并行计算,这是 Transformer 模型训练的关键技术之一。
在获得语料库后,我们首先对其进行分词处理,得到每个 token。然后,我们对这些 token 进行去重,形成一个庞大的词典。接下来,我们对这些 token 进行编号,创建 token 到 ID 的匹配表和 ID 到 token 的匹配表。

在分词结果的每句话之后,我们添加一个特殊标志,如 EOS,表示句子的结束。这个结束标志也是模型需要学习和预测的目标之一,即模型需要学习如何生成句子。

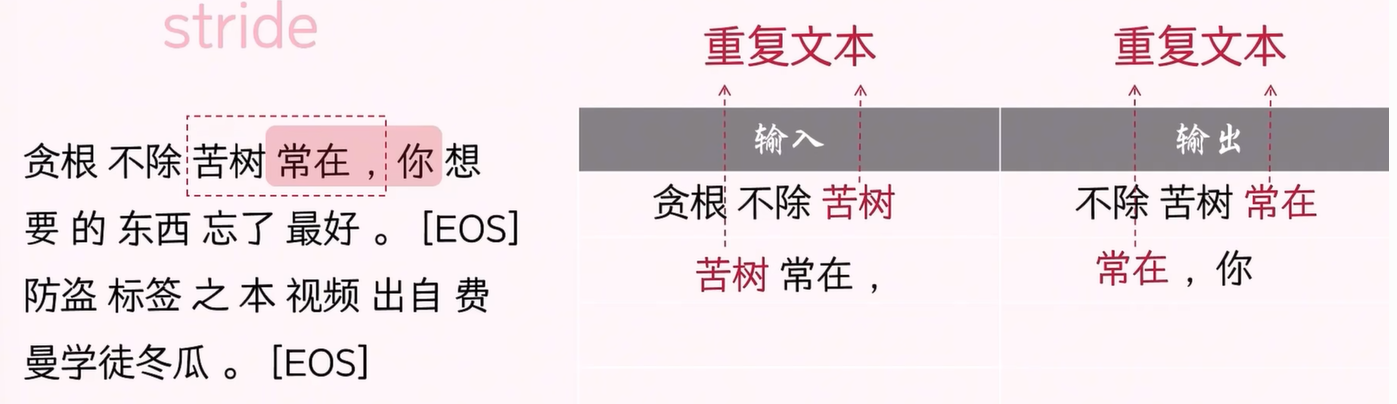
接下来,我们开始采样训练数据。假设模型每次最多可以处理 3 个 token,那么这 3 个 token 贪根 不除 苦树 就可以作为输入数据。然后,我们将其向右移位 1 个 token,得到目标数据 不除 苦树 常在。

在这个例子中,输入数据和目标数据的 token 个数被称为上下文长度(context_length),它决定了模型可以处理的上下文长度。目前,主流的大模型支持的上下文长度为 128K 或更大。
在本例中,我们通过将输入和目标窗口整体向右移动 2 个 token,得到新的输入-目标数据对,并持续采样,以获取完整的训练数据。

采样过程中,我们使用一个参数 stride 来控制移动步幅。stride 设置得小,会导致更多的文本重复;设置得大,重复的文本就少。当 stride 大于上下文长度时,文本将不会重复。如果 stride 设置过小,模型可能会学习到大量重复数据,从而容易过拟合。
另一个重要的参数是 batch_size,它指的是每次训练中使用的样本数量。这里提到的一个样本包含输入数据和目标数据。
通过这些步骤,我们就完成了训练数据的采集。

2. 嵌入层
在本节中,我们将详细解释嵌入层、Transformer 层和输出层的原理。

由于文本不能直接用于数学计算,我们需要将文本转换成向量形式,以便模型能够处理。这一过程的目的是使向量能够携带足够的信息量,这就是 token 嵌入层的作用。
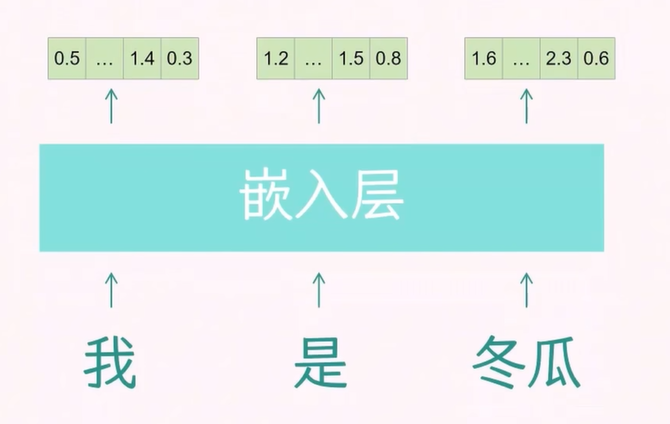
我们使用之前得到的 token-ID 词汇表,随机初始化一个 token 的向量矩阵。矩阵的行数对应 token 的个数,列数对应 d_model(例如 512 或 1024,图中称为 emb_dim)。d_model 的维度越大,包含的 token 信息就越多。
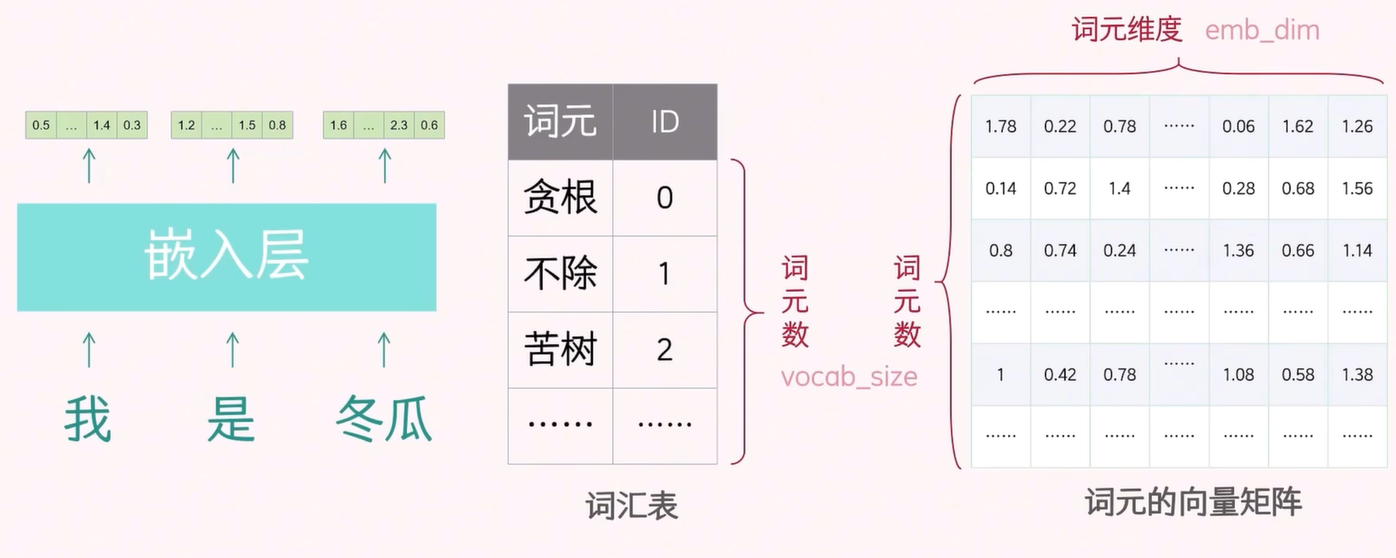
进行 token embedding 操作时,我们取出准备好的训练数据,将输入数据的 token 在 token-ID 表中进行检索,匹配得到 ID。
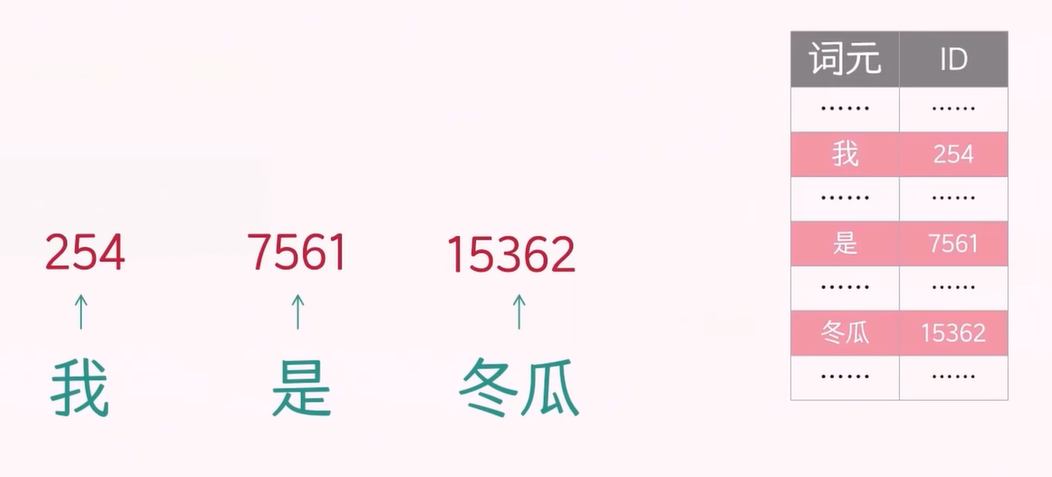
然后,根据这个 ID 到向量矩阵中检索,就可以得到该 token 的向量。(下图中其实应该是 第 7562 行)

接着,我们需要将 token 的位置信息加入到 token 向量中。关于 positional embedding 的表示方法有两种:一种是作为可学习的嵌入通过训练得到(如 GPT-2),另一种是通过公式进行计算。
对于训练得到的,行数是上下文长度 context_length,来表示每个位置的信息,列是 d_model,同样和 token 向量初始一样,都是随机初始化的向量,以确保位置向量可以和 token 向量进行同维度相加。
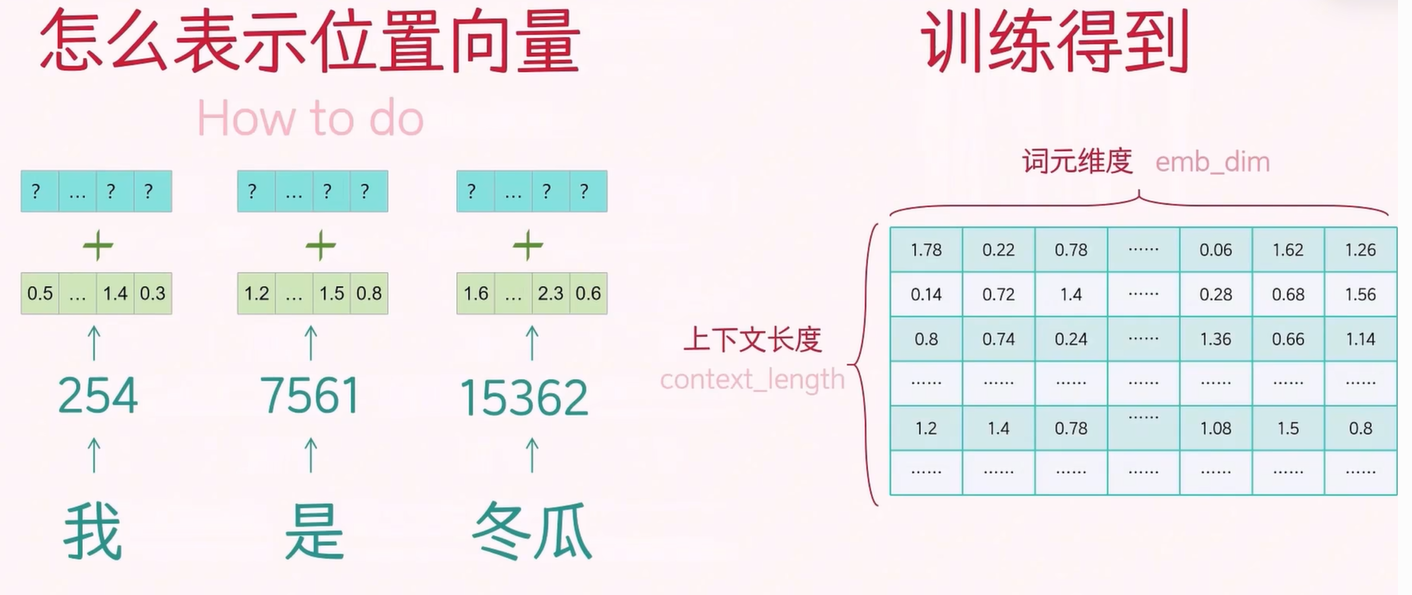
对于公式计算得到的,是 《Attentin Is All You Need》论文中关于位置向量的计算方法,偶数索引使用第一个公式,奇数索引使用第二个公式,下图以“是”为例,可以直接计算得到。

此外,位置向量还可以分为绝对位置嵌入和相对位置嵌入,后者根据 token 之间的相对位置来计算,目前常用。
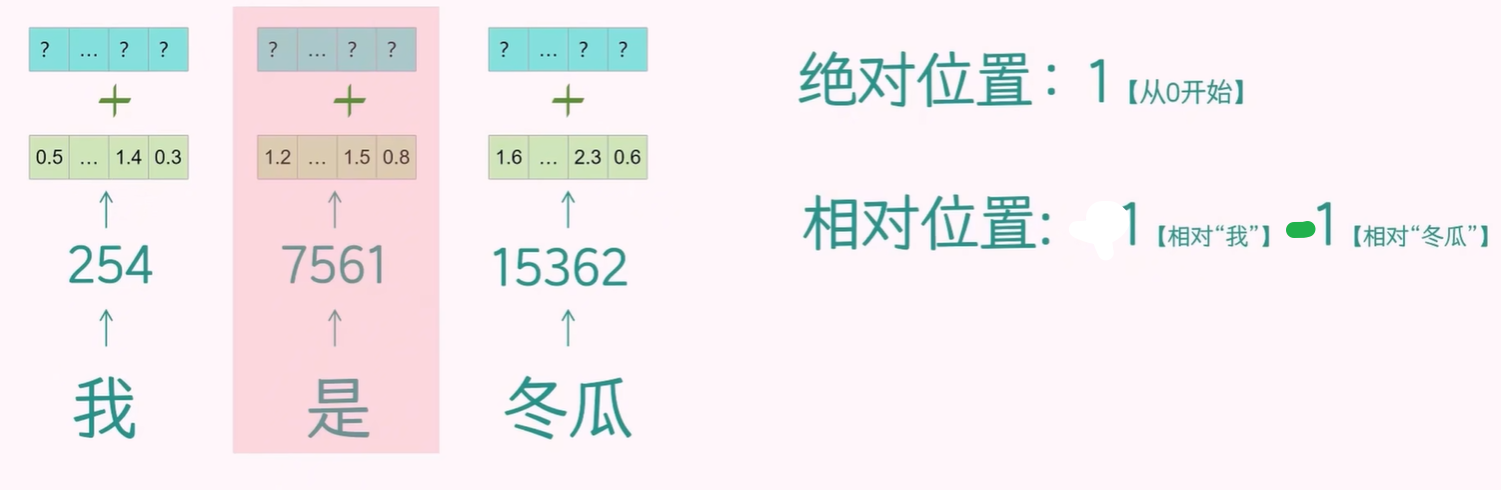
因此,嵌入层包含 token 的 token 向量和 positional 向量。token 向量表示 token 本身的含义,而 positional 向量携带 token 的位置信息。两者结合可以增强嵌入向量的语义表示能力。

补充:
在通过 token ID 从对应的 token 向量矩阵中检索 token 向量时,虽然本质上是一次查找操作,但由于“键值对”式的检索本身不可导,因此无法通过反向传播来更新 token 向量矩阵。
为了解决这一问题,通常会将该检索过程转化为可导的线性操作,即使用矩阵乘法来实现。具体做法是:将 token ID 表示为一个 one-hot 向量,其长度等于词表大小,在该向量中,目标 token 对应的位置为 1,其余位置为 0。将该 one-hot 向量与 token 向量矩阵相乘,即可得到对应的 token 向量。
简而言之,这种方式将原本不可导的“查找”操作转化为可导的“矩阵乘法”操作,从而使得整个过程可以参与模型的反向传播与参数更新。

接下来,我们将 token 向量输入到 Transformer 层,最后得到的 token 向量将学习到更加丰富的信息。
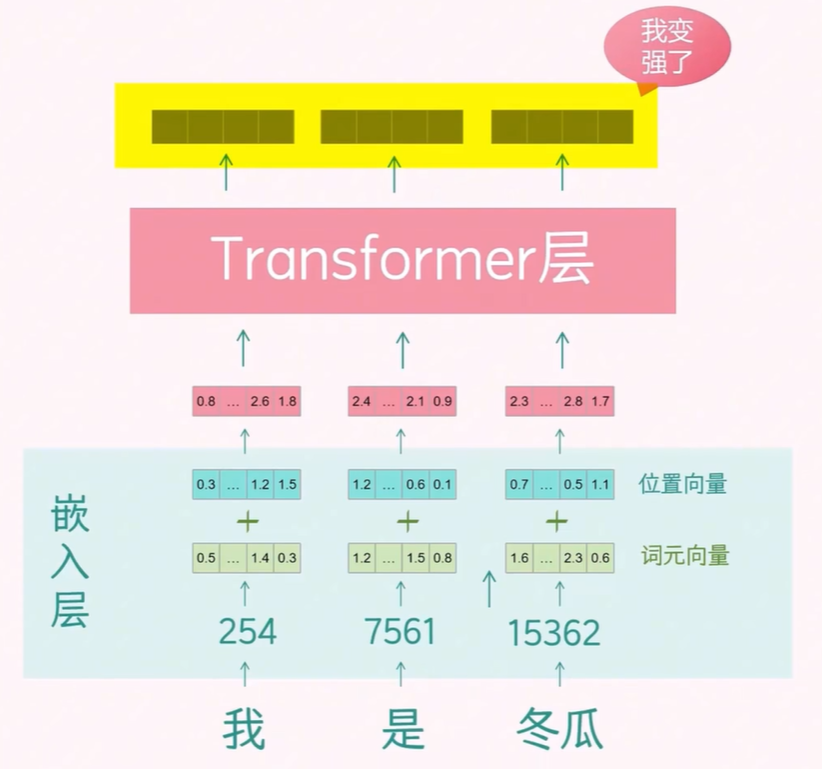
3 Transformer 层
3.1 不涉及 QKV 之前的探讨
在本小节中,我们将暂时不涉及 QKV(Query, Key, Value)的概念,以便更容易理解注意力权重矩阵。
当我们将 3 个 token 向量输入到 Transformer 层时,得到的 3 个向量已经捕捉到了其他 token 的注意力信息。这些新向量是通过将旧向量与注意力权重相乘并求和得到的,其中 α1、α2、α3 是通过 softmax 归一化的注意力权重得分。
注意力机制是 Transformer 的一个伟大发明,它能够捕捉同一个词语在不同语境中的含义。
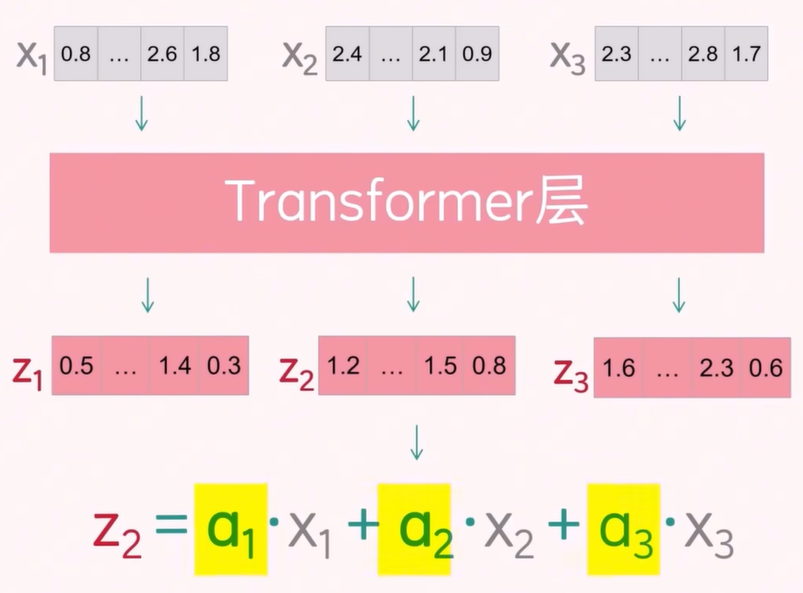
注意力得分的计算方法如下:
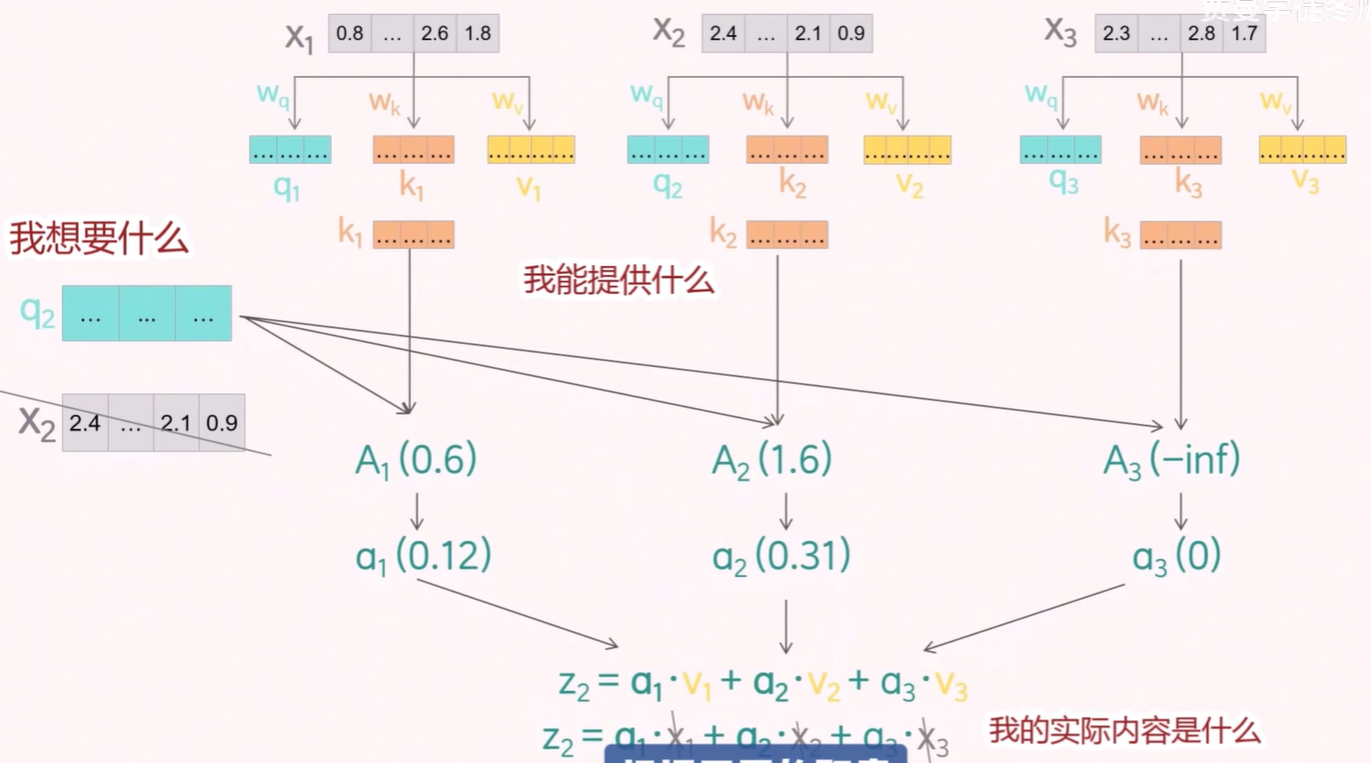
以第二个 token 为例,将它的 token 向量和所有 token 向量进行点积计算。点积结果越大,说明两个向量的相似度越高,也代表这个 token 的注意力权重越高。
在下图中,发现"冬瓜"和"是"的注意力权重是最高的,说明,"冬瓜"更有可能是"是"的下一个 token。

对于 token X2, 将注意力权重得分进行 softmax 归一化,得到最终的注意力权重分数。

然后按照同样的方法,得到所有 token 完整的注意力矩阵分数。
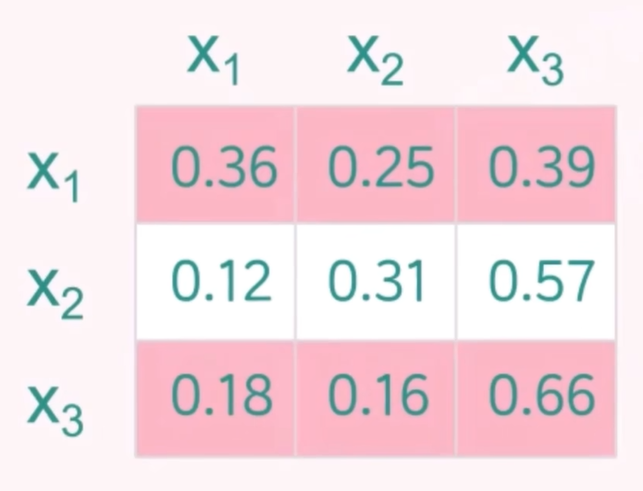
当前的注意力得分矩阵仍存在较大问题。在训练阶段,对于 token X2 来说,token X3 是其后续的 token,如果模型在计算注意力时对 token X3 分配了权重,就等于在训练时提前“泄露”了答案。
这种信息泄露会导致训练损失异常偏低,因为模型在学习过程中获得了未来的信息。然而,在推理阶段,模型无法访问未来的 token,因而无法复现训练时的表现,最终可能导致推理效果严重下降,出现“翻车”现象。
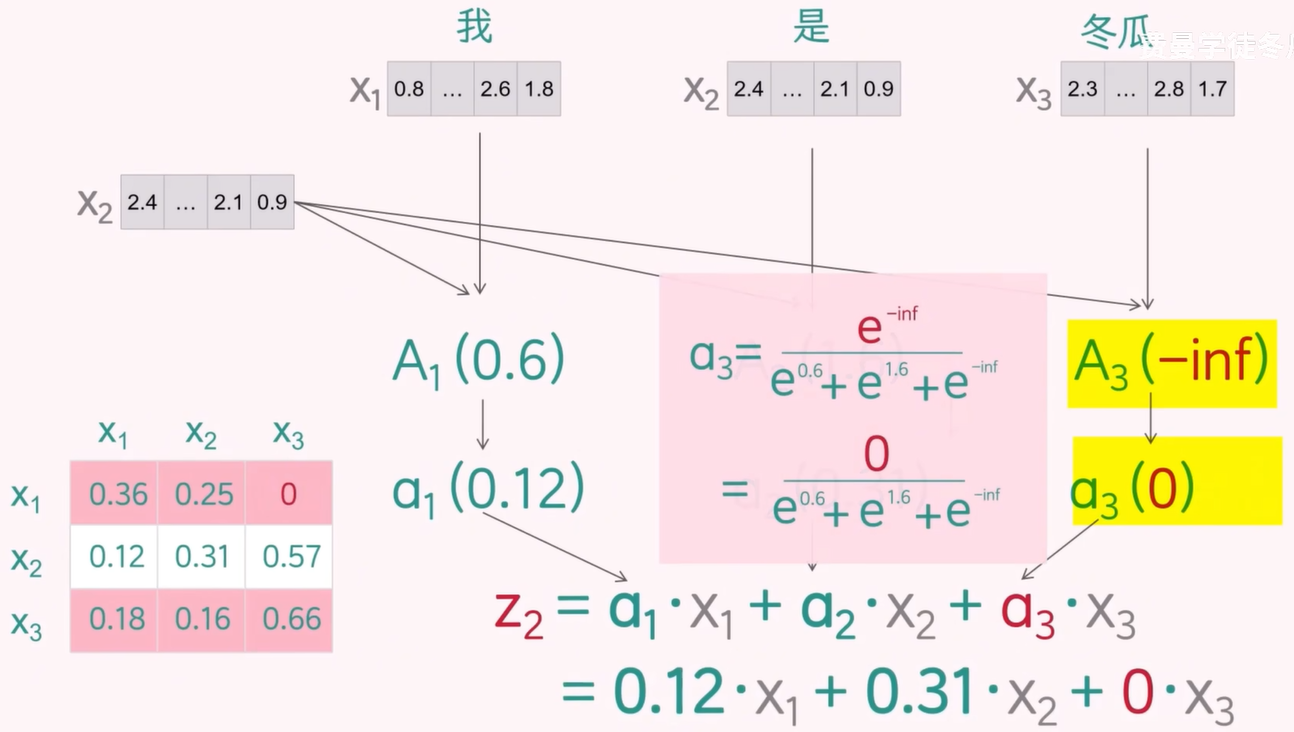
掩码机制:
在引入 QKV 机制后,注意力计算的核心是将查询向量 Q 与键向量的转置 KT 进行点积,得到注意力得分矩阵。在进行 softmax 归一化之前,为了防止模型在训练阶段“偷看”未来信息,需要对当前 token 之后的注意力得分进行屏蔽处理。
具体做法是:将当前 token 之后的所有点积结果替换为负无穷(-inf),这样在 softmax 计算中,由于 e 的 -inf 是 0 ,这些位置的注意力权重将变为 0,从而确保模型只能关注当前位置及其之前的 token。这种掩码机制有效防止信息泄露,使模型在训练阶段遵循自回归的因果结构。
在推理阶段,虽然模型逐步生成 token 并不存在完整的“答案”,但仍需使用相同的掩码机制以保持组件行为一致,确保每一步的注意力仅依赖于已生成的内容。
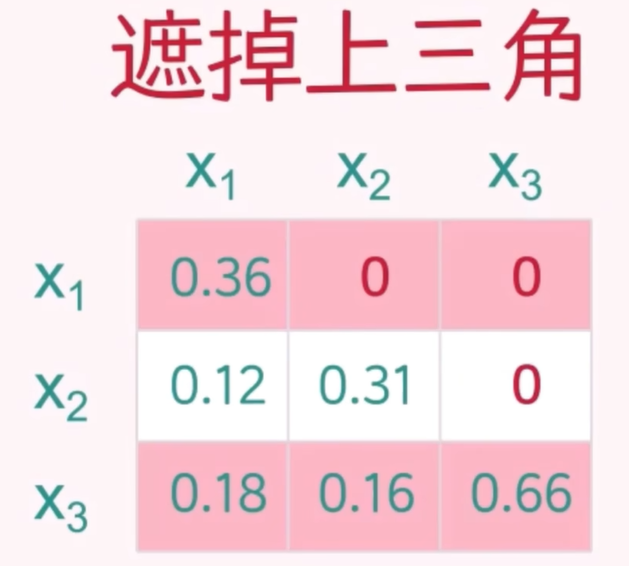
通过这种方式,Transformer 模型能够在训练和推理阶段都有效地学习并利用上下文信息。
3.2 涉及 QKV 之后的探讨
在引入 QKV 之后,其实 QKV 没有改变注意力计算的本质,只是强化了注意力捕捉的能力。QKV 的引入使得模型能够更灵活地捕捉不同类型的语义信息,从而提升注意力机制的效果。
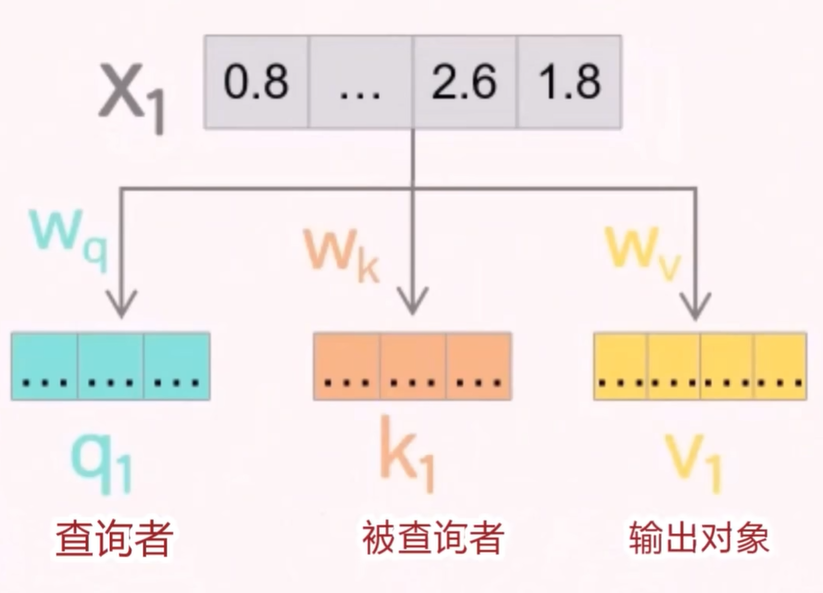
原本没有引入 QKV 之前,在早期的直觉类比中,我们可以把每个 token 的向量看作同时承担三个角色:查询者(Query)、被查询者(Key)和信息提供者(Value)。这种做法虽然简单,但容易导致语义混淆,限制了模型的表达能力。

于是将这三种身份直接拆开,引入 Wq、Wk、Wv 三个可学习的参数矩阵,原始的 token 向量乘上这三个参数矩阵,得到三个新的向量 q(查询者)、k(被查询者)、v(输出对象)。
- 查询向量 q:表示当前 token 想要关注什么;
- 键向量 k:表示其他 token 提供的信息的“标签”;
- 值向量 v:表示其他 token 实际提供的信息内容。
后续的计算过程和之前一样,只是现在变成:
将 token X2 的 token 向量换成 q2 向量,q 向量表示查询的内容,k 向量表示键的内容,v 向量表示值的内容。这三个向量根据不同的职责表达不同的语义,模型自然会有更强的表达能力。于是使用 q2 向量和其余的 token 对应的 k 的转置(T)向量相乘,得到注意力分数矩阵,然后除以根号 dk 进行缩放,接着应用掩码(Mask)机制,最后通过 softmax 归一化得到注意力权重矩阵,再与 v 相乘得到最终的上下文向量。
单头注意力机制矩阵的计算见公式:

按照上面的公式进行计算,其实本质上还是矩阵计算,这里以 GPT-2 为例,d_model = 768,Wq 的维度要和 Wk 的维度一致,因为要实现 Q · KT,一般 Wk 的 emb_dim 一般也是 token 向量的维度(此处是 768).
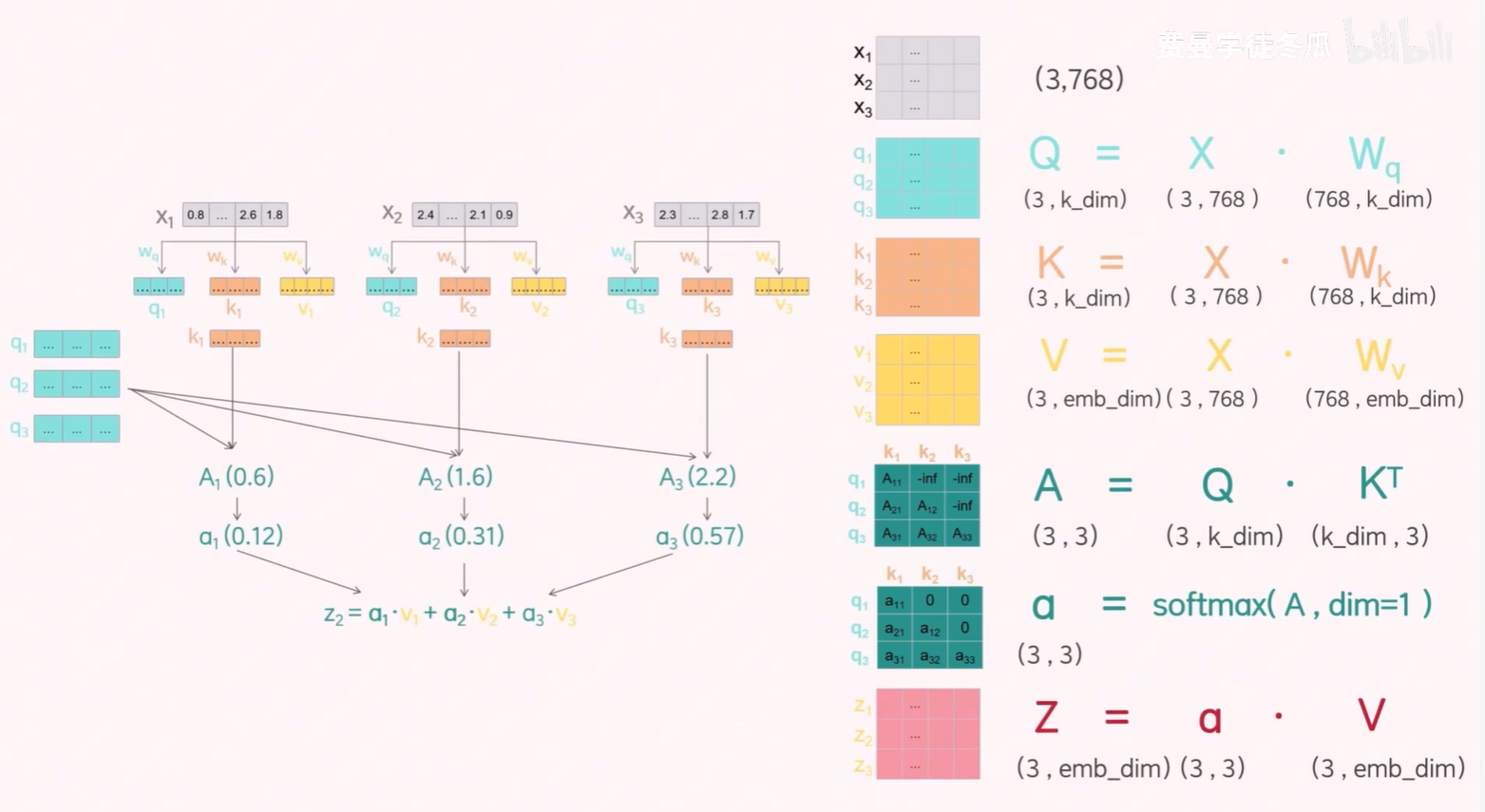

之所以在注意力计算中要除以 √dk,是因为在进行 Q · Kᵀ 点积后,结果的方差会显著增大。这意味着某些注意力得分可能非常大,而另一些则非常小,导致 softmax 归一化后的注意力分布极度不均衡,甚至可能出现大部分权重接近于 0 的情况。
假设 Q 和 K 的元素都服从均值为 0、标准差为 1 的正态分布,那么 Q · Kᵀ 的结果将是一个均值为 0、标准差为 √dk 的矩阵。为了让注意力得分在归一化前保持稳定,我们将其除以 √dk,使得标准差恢复为 1,从而避免数值过大带来的梯度问题。这样可以获得更平滑、更稳定的注意力权重,有助于模型的有效训练。
3.3 多头注意力机制
假设我们有一句话:“小猫在沙发上玩耍”,我们可以用这句话来类比 Transformer 模型是如何理解语言的。
在处理“玩耍”这个词时,Transformer 会使用多个注意力头(multi-head attention)来从不同角度理解上下文。例如:
第一个注意力头,它可能重点捕捉“小猫”,给“小猫”这个词更高的注意力权重,从而锁定执行玩耍这个动作的主体。
第二个注意力头,可能聚焦“沙发”,从而明确玩耍发生的具体位置。
第三个注意力头,可能扫描整个句子,给所有词平均的注意力权重,从而感受这个动作发生的整体氛围。
最终将这三个不同角度的信息,拼接融合起来,从而捕捉更丰富的上下文信息。
需要注意的是,这些关注模式并不是人为设定的,而是通过训练自动学习得到的。每个注意力头都可以学习到不同的依赖关系,从而丰富模型的表达能力。

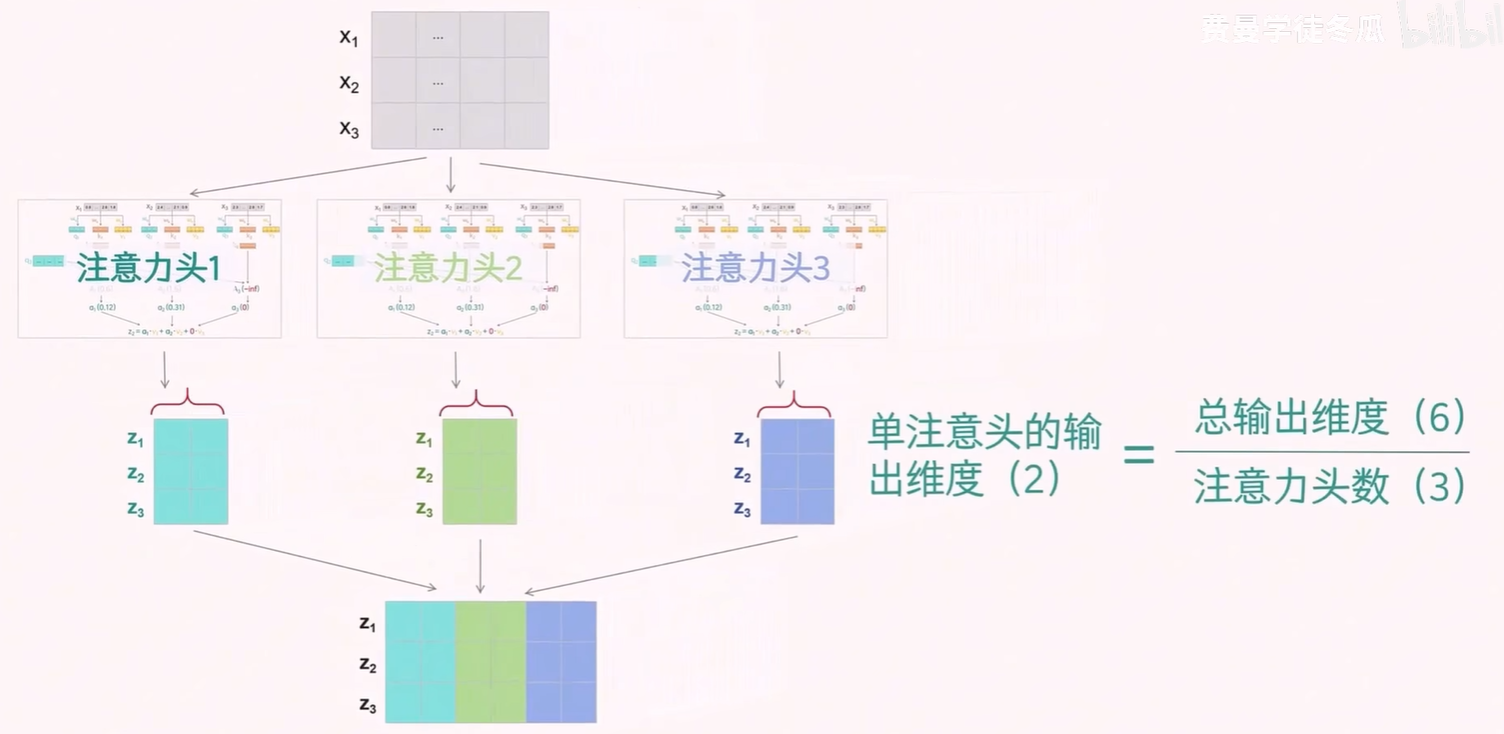
为了能同时捕捉一段文本中可能存在的多种依赖关系(例如动作的执行者、发生地点、修饰方式等),Transformer 为每个注意力头分别定义了自己的查询(Q)、键(K)和值(V)参数。通过对输入向量进行线性变换,生成对应的 Q、K、V 向量,然后计算注意力权重并得到每个头的输出。最后,将所有注意力头的输出拼接在一起,形成多头注意力的最终结果。
以 3 个注意力头为例,每一路都有自己的 QKV 参数(有些变种会共享 QKV),生成自己的 QKV 向量,计算自己的注意力,最后得到自己的输出。将所有的输出向量拼在一起,就得到了多头注意力的输出。
3.4 FFN 层
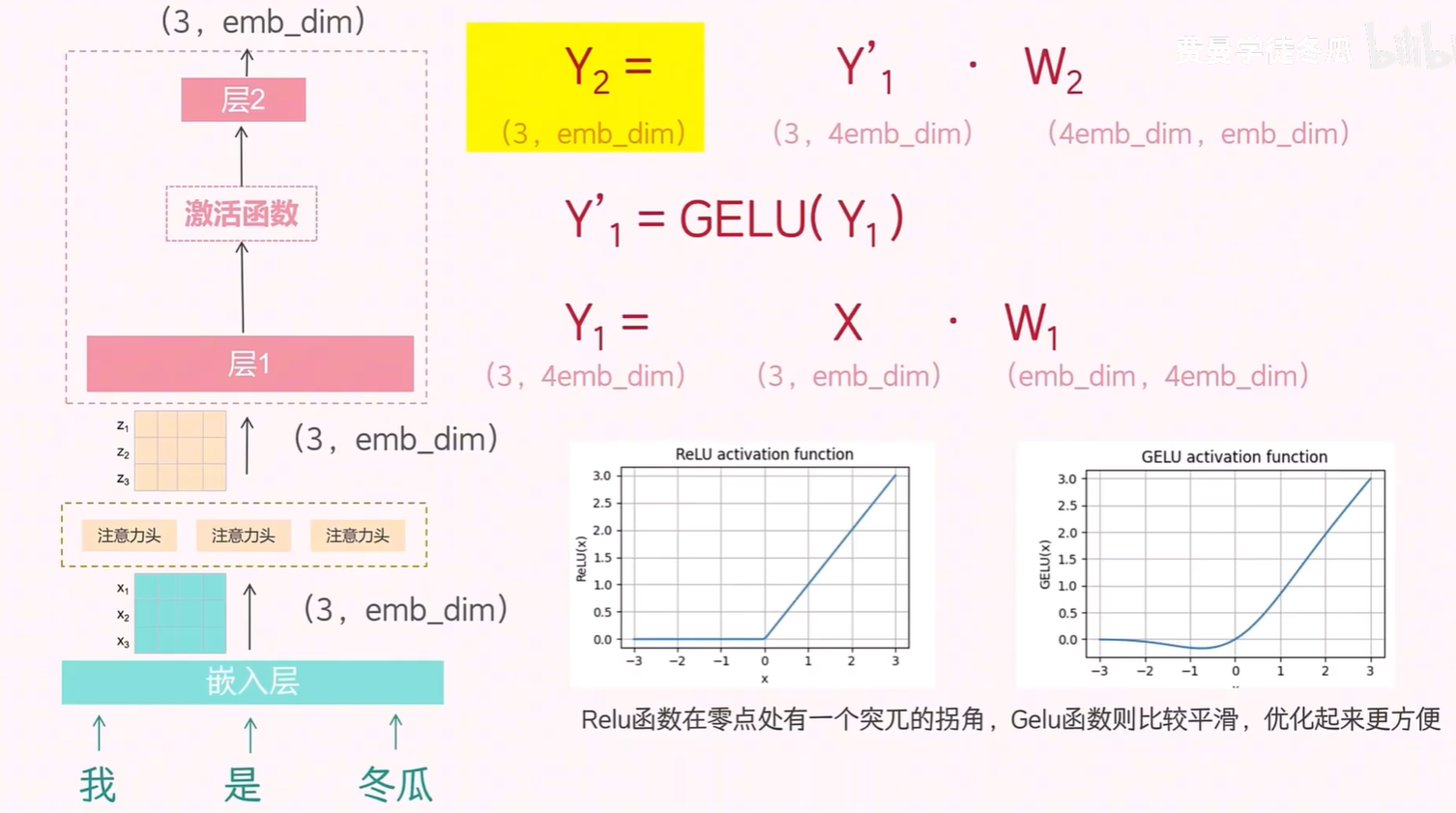
在注意力机制之后,Transformer 还包含一个前馈神经网络(Feed Forward Network, FFN)层。FFN 由两个全连接层组成:第一层将输入向量升维,第二层再将其降维回原始维度。
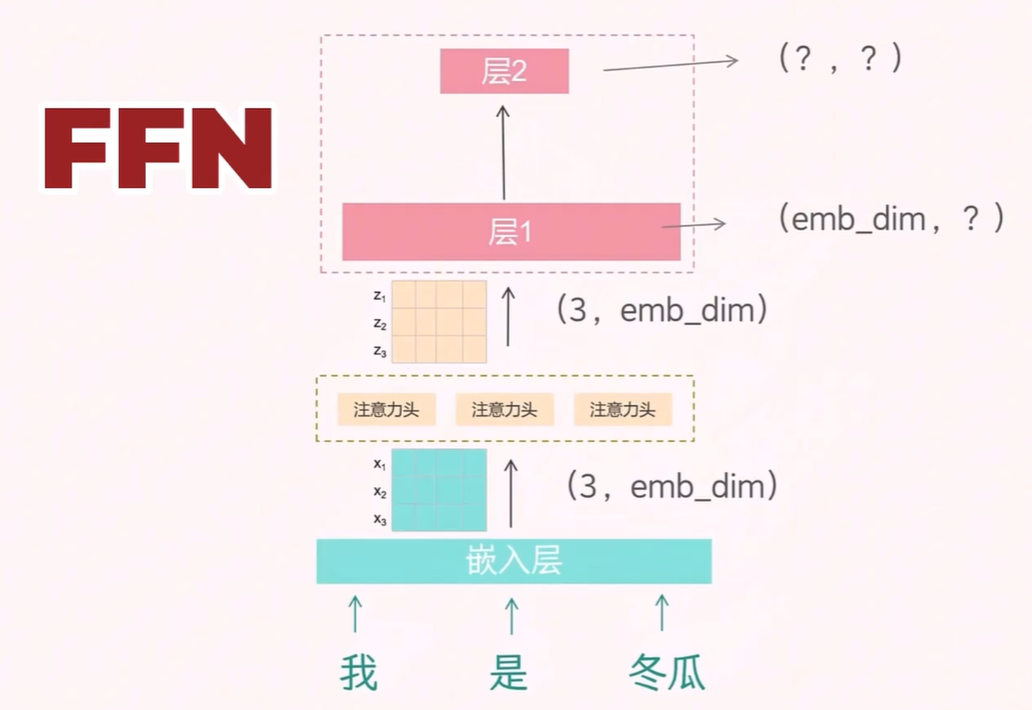
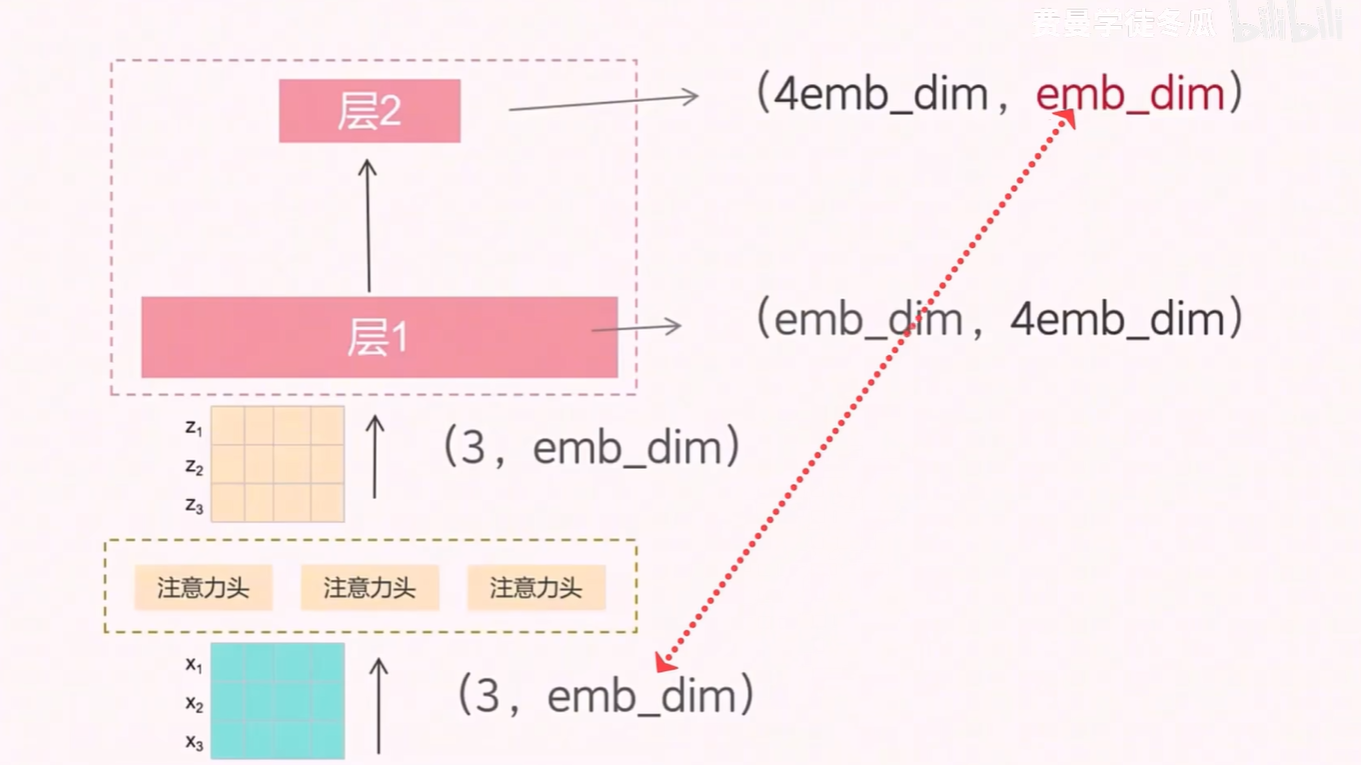
具体来说,使用图上标明的操作实现先升维再降维复原,虽然输入输出维度保持一致,但中间的高维表示可以帮助模型学习更复杂的特征。
由于 Transformer 层的输入输出维度保持一致,因此可以堆叠多个 Transformer 层。每一层都在前一层的基础上进一步提取语义信息,从而逐步构建出对整段文本的深层理解。
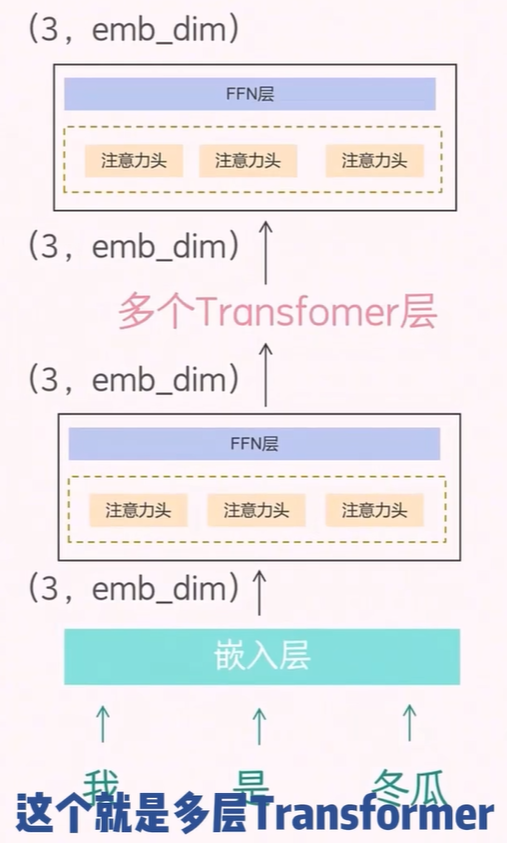
通过多个 Transformer 层,可以逐层学习到更复杂的语义信息。
4 输出层
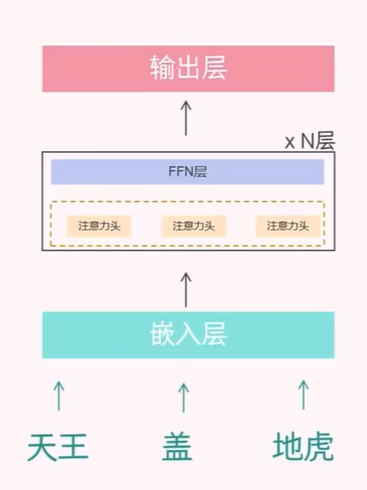
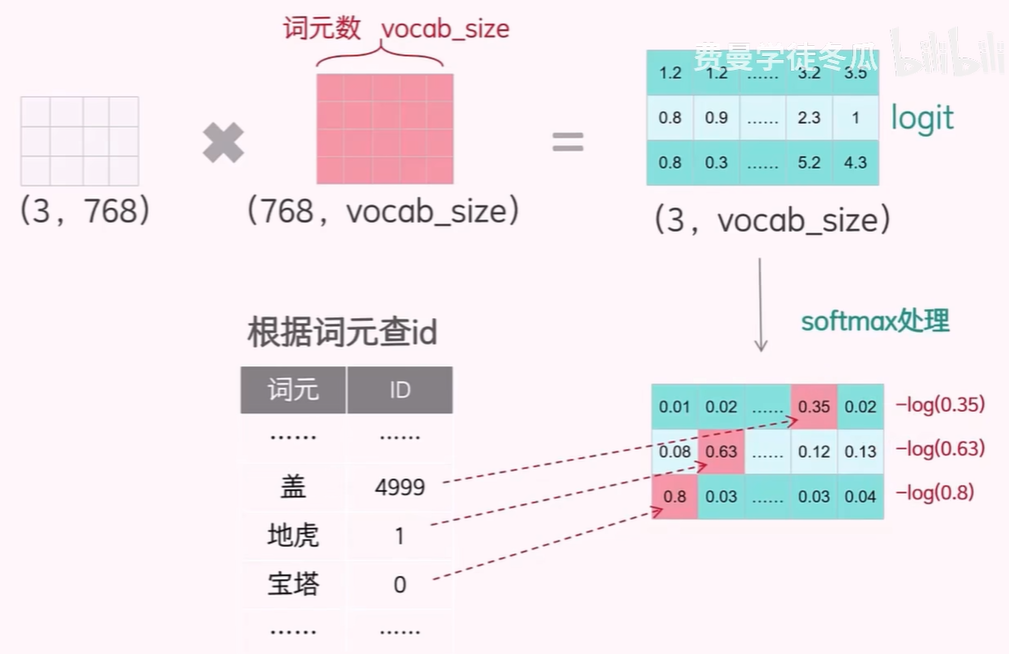
关于输出层的任务,主要考虑两个问题
- 训练阶段,如何计算损失
关于候选词概率表,计算流程如下:将多个 Transformer 层的输出矩阵(3,768)和输出层的参数矩阵相乘得到输出层的结果,然后对每个 token 的 logit 进行 softmax 处理来得到概率。
然后要找到哪个概率值是目标词(目标词是在训练过程中,我们希望模型能够正确预测的词,也就是实际上正确的 next token)的预测概率,找到概率之后,就可以计算这个 token 的交叉熵损失。
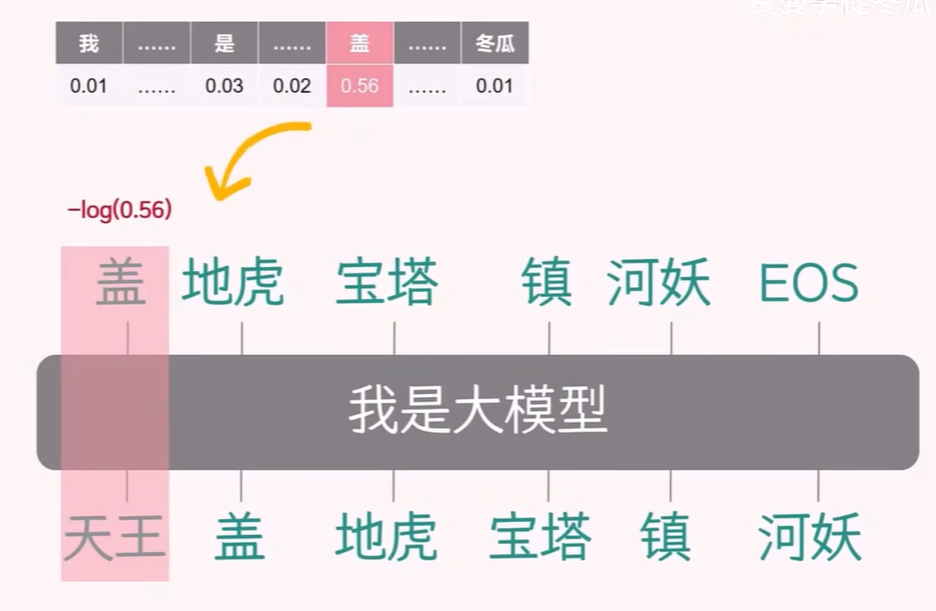
在训练阶段,对于 token “天王” 对应的真实 next token “盖”,在经过 softmax 计算得到的候选词概率,使用
-log 计算交叉熵损失值,相加计算平均值,得到最终的损失函数值。


- 推理阶段,如何从候选结果中选出下一个词
在推理阶段,模型会根据当前上下文预测下一个词。最简单的方式是选择概率最高的词(贪心策略),但这种方法存在两个问题:
- 相同输入总是产生相同输出,缺乏多样性;
- 局部最优不一定带来全局最优,可能导致生成内容缺乏创造性。
为了解决这些问题,可以引入采样策略:
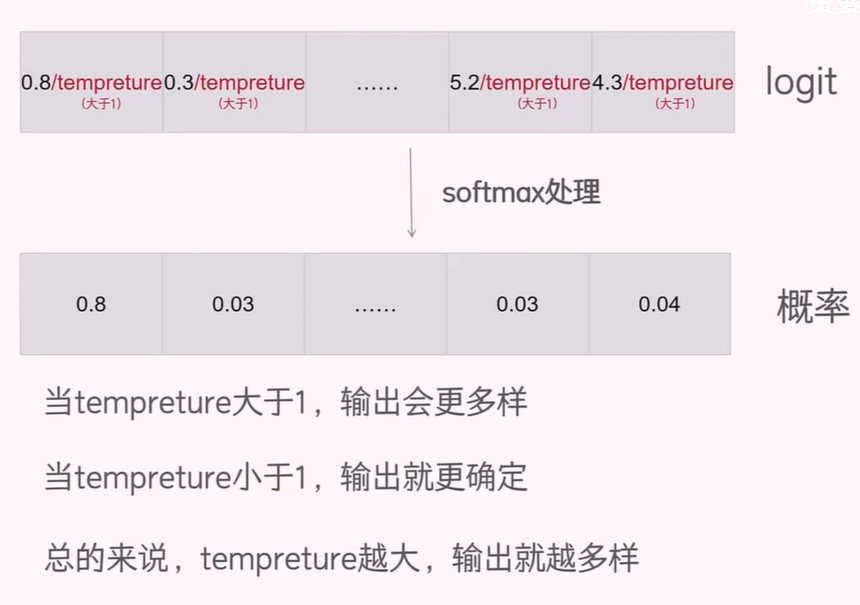
Temperature 调节:
将 logits 除以一个大于 1 的数(temperature),使 softmax 后的分布更平滑、均匀。较高的 temperature 会增加多样性,较低的 temperature 会增强确定性。
TopK 采样:
从预测概率最高的前 K 个词中进行随机抽样,限制候选范围,提升质量。

TopP(Nucleus)采样:
从累计概率((累计概率和指的是多个 token 的概率相加达到 90 %)达到阈值 P(如 0.9)的一组词中进行抽样,动态控制候选集大小,兼顾质量与多样性。

概率阈值过滤:
可以设置一个最小概率阈值,过滤掉预测概率过低的词,但这种方法在实际应用中较少单独使用,更多是作为 TopP 的补充。

参考
【完整版】硬核讲解:一个视频彻底了解大模型的原理,从输入层到输出层
Attention Is All You Need