二、模型训练与参数高效微调范式
模型训练是将预训练模型从“通用能力”转向“场景适配”的核心环节。随着模型参数规模从亿级增长到万亿级,传统全量微调的成本急剧上升,因此催生出“分阶段训练”和“参数高效微调”两大技术体系。前者通过“预训练→后训练→微调”的阶梯式流程实现知识的逐步聚焦,后者通过仅调整少量参数即可适配下游任务,大幅降低训练成本。
2.1 训练阶段划分
模型的能力迁移遵循“通用知识→领域知识→任务技能”的递进逻辑,对应三个核心训练阶段:预训练(Pretrain)、后训练(Post-training)、微调(Finetune)。三者的关系如同“基础教育→专业基础教育→职业技能培训”,共同构成模型从“通用”到“专用”的完整成长路径。
2.1.1 预训练(Pretrain):通用知识的“奠基阶段”
- 定义:在大规模无标注/弱标注的通用数据上,通过自监督任务训练模型基础能力的过程,是模型“从零到一”构建通用语义表示的核心环节。
- 核心目标:让模型学习“世界的基本规律”,包括语言结构(语法、语义)、视觉特征(物体形状、光影)、跨模态关联(“猫”的文字与图像的对应)等通用知识,形成可迁移的基础表示。
- 数据特点:
- 规模大:通常为千亿级token(文本)或数十亿图文对(多模态),例如GPT-3训练数据包含45TB文本,CLIP包含4亿图文对。
- 多样性:覆盖书籍、网页、论文、图片等多来源数据,确保知识的通用性(如既有新闻文本,也有小说、代码)。
- 无标注/弱标注:无需人工标注标签,依赖数据自身结构设计自监督任务(如文本的“下一词预测”,图像的“旋转预测”)。
- 典型任务:
- 文本领域:掩码语言模型(MLM,BERT)、下一词预测(GPT)、文本片段重建(T5)。
- 多模态领域:图像-文本对比学习(CLIP)、跨模态掩码预测(ALBEF的MLM结合图像信息)。
- 输出产物:预训练基础模型(如BERT-base、GPT-3、CLIP),具备通用语义理解/生成能力,但未针对具体领域或任务优化。
- 关键特点:
- 计算成本极高:训练一次千亿参数模型需数万GPU小时(如GPT-3训练成本约1200万美元),通常由大型机构完成(OpenAI、Google、Meta等)。
- 通用性优先:不聚焦任何特定领域或任务,追求“一模型适配万场景”的基础能力。
2.1.2 后训练(Post-training):领域知识的“强化阶段”
- 定义:介于预训练与微调之间,在特定领域的通用数据(非任务特定数据)上对预训练模型进行二次训练,目的是向模型注入领域知识(如医学、法律、金融),属于“领域适配”的中间环节。
- 核心目标:让模型从“懂通用知识”升级为“懂领域知识”,例如从“认识‘细胞’这个词”到“理解细胞的结构与功能”,为后续任务微调降低难度。
- 数据特点:
- 领域聚焦:仅使用目标领域的通用数据(如医学领域用PubMed论文、病例报告;法律领域用法规条文、判例)。
- 规模中等:通常为百万到亿级token(远小于预训练,大于微调),例如医学BERT的后训练数据包含200万篇医学论文。
- 弱标注为主:仍以自监督任务为主(避免领域标注数据稀缺问题),部分场景会加入领域内的结构化知识(如医学术语表)。
- 典型任务:
- 领域内自监督任务:如医学领域的“掩码医学实体预测”(将“[MASK]是一种肺部感染疾病”中的掩码预测为“肺炎”)。
- 领域知识对齐:将领域术语表与模型表示关联(如法律中的“善意取得”与模型语义空间绑定)。
- 与预训练/微调的区别:
维度 预训练(Pretrain) 后训练(Post-training) 微调(Finetune) 数据范围 通用数据(跨领域) 特定领域的通用数据 特定领域的任务数据(带标签) 目标 学习通用知识 注入领域知识 适配具体任务技能 任务类型 自监督 以自监督为主 监督学习(任务特定) 参数更新 全量参数训练 部分/全量参数更新(轻量训练) 少量/全量参数更新 - 典型案例:
- BioBERT:在PubMed论文上对BERT进行后训练,使其理解医学术语(如“心肌梗死”“安慰剂”),后续在医学问答、病例分类任务上的微调效果远超原生BERT。
- LegalBERT:在欧盟法律文本上后训练,优化对“判例”“法条”等法律领域文本的理解。
- 关键价值:解决“预训练模型领域知识不足”的问题——原生预训练模型在专业领域(如医学)的性能往往较差(因通用数据中领域知识占比低),后训练通过聚焦领域数据,大幅提升模型的领域适配基础。
2.1.3 微调(Finetune):任务技能的“适配阶段”
- 定义:在具体任务的标注数据上对预训练/后训练模型进行训练,调整模型参数以适配特定任务需求(如情感分析、视觉问答),是模型落地的最后一步。
- 核心目标:让模型从“懂领域知识”升级为“会做具体任务”,例如从“理解医学术语”到“能回答‘糖尿病的症状有哪些’”。
- 数据特点:
- 任务特定:仅包含目标任务的标注数据(如情感分析的“句子+正负标签”,VQA的“图片+问题+答案”)。
- 规模小:通常为几千到几万样本(标注成本高),例如IMDb情感分析数据集仅5万条样本。
- 强标注:每条数据均带任务标签(如分类标签、答案文本)。
- 典型流程:
- 加载预训练/后训练模型的权重作为初始参数。
- 在任务数据上,通过监督学习优化模型(计算预测结果与标签的损失,反向传播更新参数)。
- 针对任务设计输出层(如分类任务加全连接层输出标签概率,生成任务加解码层输出文本)。
- 传统微调的局限性:
- 全量参数更新成本高:千亿参数模型微调需大量GPU内存(如GPT-3全量微调需数万GPU小时),中小企业难以承担。
- 样本效率低:当任务数据少时,易过拟合(模型“死记硬背”训练样本,泛化差)。
- 灾难性遗忘:微调可能覆盖预训练习得的通用知识(如微调法律任务后,模型对日常对话的理解能力下降)。
- 典型案例:
- 用SQuAD数据集微调BERT做问答任务:输入“问题+上下文”,模型输出答案在上下文中的起始/结束位置。
- 用COCO数据集微调BLIP做图像 captioning:输入图片,模型输出描述文本(如“a cat sitting on a chair”)。
2.1.4 三阶段训练的流程关系(附流程图)
三个阶段形成“通用→领域→任务”的阶梯式知识传递链,流程如下:
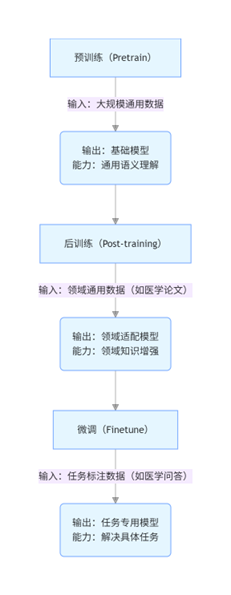
- 核心逻辑:预训练构建“通用认知”,后训练补充“领域常识”,微调打磨“任务技能”,三者缺一不可——跳过预训练则模型无基础能力,跳过领域后训练则模型在专业场景表现差,跳过微调则模型无法直接解决具体任务。
2.2 参数高效微调技术
随着模型参数规模突破千亿(如GPT-3、LLaMA-2 70B),传统全量微调的成本已难以承受(单轮微调成本超百万美元)。参数高效微调技术通过仅调整模型的少量参数(通常<1%),即可达到与全量微调接近的效果,同时解决样本效率低、灾难性遗忘等问题,成为大模型落地的核心技术。
2.2.1 增量微调(Delta Tuning):参数高效微调的统称
定义
一类轻量级微调方法的统称,核心思想是"冻结预训练模型的大部分参数,仅学习一个’增量参数(Delta)'",模型最终输出为"预训练参数+增量参数"的组合(即f(x;θ+Δθ)f(x; \theta + \Delta\theta)f(x;θ+Δθ),其中θ\thetaθ是预训练参数,Δθ\Delta\thetaΔθ是增量参数)。
核心目标
用极少的参数更新实现任务适配,同时保留预训练模型的通用能力(避免灾难性遗忘)。
技术分类
根据增量参数的形式,可分为三类:
- 附加型增量:在预训练模型中插入新的可学习参数(如额外的注意力层、全连接层),仅训练这些新参数(如Adapter Tuning)
- 修改型增量:对预训练模型的部分参数(如注意力权重、嵌入层)进行微调,其他参数冻结(如LoRA对权重矩阵的低秩修改)
- 提示型增量:通过学习"提示向量"引导模型输出,不修改模型本身参数(如Prompt Tuning)
优势
- 参数量少:通常仅需训练原模型0.1%-1%的参数(如70B模型仅需训练700万-7000万参数),训练成本降低100-1000倍
- 样本效率高:在小样本场景下(如仅100条标注数据),性能远超全量微调(全量微调易过拟合)
- 多任务兼容:不同任务的增量参数可独立存储,一个基础模型可同时适配多个任务(如用不同Prompt向量分别处理情感分析和翻译)
局限性
- 在数据量极大的场景下,性能略逊于全量微调(增量参数难以捕捉复杂任务模式)
- 部分方法(如Adapter)会增加推理延迟(需加载额外层)
2.2.2 低秩适配(LoRA:Low-Rank Adaptation)
定义
一种通过"低秩矩阵分解"来参数化增量的高效微调方法,核心是将高维权重更新分解为两个低维矩阵的乘积,大幅减少可训练参数。
核心原理
-
传统全量微调中,模型权重更新是直接修改高维矩阵W∈Rd×kW \in \mathbb{R}^{d \times k}W∈Rd×k(如Transformer中的注意力权重矩阵,维度可能达1024×1024)
-
LoRA将权重更新ΔW\Delta WΔW分解为两个低秩矩阵的乘积:ΔW=B×A\Delta W = B \times AΔW=B×A,其中A∈Rd×rA \in \mathbb{R}^{d \times r}A∈Rd×r,B∈Rr×kB \in \mathbb{R}^{r \times k}B∈Rr×k,rrr是低秩维度(通常取8-32,远小于ddd和kkk)
-
训练时仅更新AAA和BBB,推理时将ΔW\Delta WΔW与原权重W0W_0W0合并(W=W0+B×AW = W_0 + B \times AW=W0+B×A),不增加推理延迟
-
数学示意图:
原权重矩阵 W0 (d×k)↓ 增量矩阵 ΔW = B (r×k) × A (d×r) (r << d, k)↓ 最终权重 W = W0 + ΔW (推理时合并,无额外成本)
技术特点
- 聚焦关键层:通常仅在Transformer的查询(Query)和值(Value)矩阵上应用LoRA(这些层对任务适配最敏感)
- 低秩假设:基于"任务适配的权重更新具有低秩特性"的观察——复杂任务的权重变化可通过低维空间近似,无需全量更新
优势
- 参数量极少:以70B模型为例,若r=16r=16r=16,单个LoRA适配器仅需约70B×2×16/(1024×1024)≈2100万参数(仅为原模型的0.003%)
- 推理无延迟:合并后权重与原模型结构一致,无需修改推理代码,优于Adapter(需额外计算层)
- 多任务切换灵活:不同任务的AAA和BBB可独立存储,切换任务时仅需加载对应矩阵
典型应用
- 大模型个性化微调:如用用户对话历史通过LoRA微调LLaMA,使其适配用户说话风格(成本仅需单GPU几小时)
- Stable Diffusion风格迁移:通过LoRA训练特定画家风格(如梵高、宫崎骏),参数文件仅几MB,可快速加载切换
局限性
- 低秩维度rrr需调参:rrr太小可能无法捕捉任务复杂度,rrr太大则失去参数高效优势
- 对非低秩特性的任务适配效果较差(如复杂逻辑推理任务)
2.2.3 提示学习(Prompt-learning)
- 定义:通过设计“提示(Prompt)”引导模型输出,将下游任务转化为预训练任务形式(如下一词预测),从而复用预训练知识,实现少样本/零样本适配的技术。
- 核心原理:
- 预训练模型在“下一词预测”等任务上已积累大量知识,提示学习通过构造“输入文本+提示模板”,让下游任务的目标与预训练任务对齐。
- 例如:将情感分析任务(输入“这部电影很棒”,输出“正面”)转化为提示形式——输入“这部电影很棒。情感:[MASK]”,让模型预测[MASK]为“正面”(复用MLM预训练任务)。
- 技术分类:
-
离散提示(Discrete Prompt):
- 定义:由人工设计的自然语言文本组成(如“这句话的情感是:积极/消极?”)。
- 特点:无需训练参数,依赖人工设计(“提示工程”),适合零样本场景。
- 示例:用“总结以下内容:[文本]”作为提示,引导GPT生成文本摘要。
-
连续提示(Continuous Prompt / Prompt Tuning):
- 定义:将提示表示为可学习的连续向量(而非自然语言),插入模型输入层或隐藏层,通过训练优化这些向量。
- 特点:需训练少量参数(通常几千到几万),不依赖人工设计,适合少样本场景。
- 示例:在BERT的输入嵌入层前插入5个可学习向量(Prompt向量),通过情感分析数据训练这些向量,使其能引导模型输出正确情感标签。
-
- 关键创新:“Prefix Tuning”(前缀提示)
- 在Transformer的每一层输入前添加可学习的“前缀向量”,而非仅在输入层。
- 优势:更贴近模型的深层语义空间,生成任务(如文本续写)效果优于传统Prompt Tuning。
- 优势:
- 样本效率极高:在小样本场景(如10条标注数据)下,性能远超全量微调(因复用预训练任务的知识)。
- 无灾难性遗忘:不修改模型参数,仅通过提示引导,保留原模型的通用能力。
- 局限性:
- 离散提示依赖人工经验:设计优质提示需大量试错(如“这部电影太烂了”的情感提示用“差评?”比“情感?”效果好)。
- 连续提示在大模型上效果更优:小模型(如BERT-base)的连续提示性能可能不如全量微调,需配合大模型才能发挥优势。
- 典型应用:
- 少样本分类:用3条示例构造提示(“例1:今天天气好→积极;例2:作业太多→消极;例3:[待分类文本]→?”),让模型直接输出分类结果。
- 跨语言迁移:用英语提示引导模型处理小语种任务(如用“Translate to French: [英语句子]”让模型翻译法语,无需法语训练数据)。
2.2.4 指令微调方法(Self-Instruct methods)
- 定义:通过模型自生成“指令-样本对”来扩充训练数据,再用这些数据进行指令微调,提升模型零样本/少样本能力的技术。核心是解决“人工指令数据稀缺”的问题。
- 核心逻辑:
- 大模型本身具备一定的零样本能力,可通过“自我提问”生成新的指令和对应样本(如让模型生成“写一首关于春天的诗”的指令,并自己创作一首诗作为样本)。
- 用这些自生成数据微调模型,强化其“理解指令→执行任务”的能力,形成“生成数据→训练模型→提升生成能力”的正循环。
- 典型流程(以Self-Instruct论文为例):
- 种子数据初始化:人工构造少量高质量指令-样本对(如50条,涵盖分类、生成、问答等任务类型)。
- 自生成指令:让预训练模型(如GPT-3)基于种子数据生成新指令(如“请将以下句子改为被动语态”)。
- 自生成样本:对每个新指令,让模型生成对应的输入-输出样本(如输入“猫追老鼠”,输出“老鼠被猫追”)。
- 数据过滤:去除低质量样本(如重复、错误答案),保留约50k-100k条有效数据。
- 指令微调:用过滤后的“指令-样本对”微调模型,优化其遵循指令的能力。
- 关键创新:
- 任务多样性增强:通过引导模型生成不同类型的指令(如“解释”“总结”“转换格式”),提升模型对多样化任务的适配性。
- 质量控制:通过“自一致性检查”(让模型对同一指令生成多个样本,保留一致的结果)过滤错误数据。
- 优势:
- 低成本扩充数据:无需人工标注,仅需少量种子数据即可生成海量指令样本(成本降低100倍以上)。
- 显著提升零样本能力:经Self-Instruct微调的模型,在未见过的任务上的零样本准确率可提升20%-50%(如GPT-3经微调后,在情感分析、翻译等任务上的零样本效果接近少样本微调)。
- 典型应用:
- Alpaca:用Self-Instruct方法基于LLaMA生成52k指令样本,微调后在零样本任务上性能接近GPT-3。
- Vicuna:通过用户共享的ChatGPT对话数据(类指令数据)微调LLaMA,实现接近ChatGPT的对话能力。
- 局限性:
- 数据质量依赖基础模型:若基础模型能力弱,生成的指令和样本可能存在逻辑错误(如数学计算指令的答案错误)。
- 存在“模式坍塌”风险:模型可能反复生成相似类型的指令(如过度集中在“翻译”任务),需通过多样性引导缓解。
2.2.5 参数高效微调技术对比
| 技术 | 可训练参数占比 | 推理延迟 | 样本效率 | 适用场景 | 典型代表工具 |
|---|---|---|---|---|---|
| LoRA | 0.01%-0.1% | 无 | 高 | 大模型微调、多任务切换 | PEFT(Hugging Face) |
| Prompt Tuning | 0.001%-0.01% | 无 | 极高 | 少样本分类、零样本迁移 | PromptBench |
| Adapter Tuning | 1%-5% | 增加5%-10% | 中 | 中等规模模型、领域适配 | AdapterHub |
| Self-Instruct | 全量/部分参数 | 无 | 中 | 提升零样本指令遵循能力 | Alpaca-LoRA |
- 选择建议:
- 若追求极致参数效率和低延迟:优先选LoRA(尤其大模型生成任务)。
- 若样本极少(<100条):优先选Prompt Tuning(连续提示)。
- 若需提升模型的通用指令能力:结合Self-Instruct生成数据+LoRA微调。
通过上述训练阶段划分和参数高效微调技术,模型可在控制成本的前提下,从通用基础能力逐步升级为领域适配、任务专用的高性能模型,为多模态等复杂场景的落地提供核心支撑。