LwIP协议栈MPA多进程架构
LwIP协议栈MPA多进程架构
1 引言:LwIP协议栈与多进程架构的价值 💡
LwIP(Light Weight IP)是一款专为嵌入式系统设计的开源TCP/IP协议栈,它以资源占用少、模块化设计良好而闻名。LWIP的含义是轻量级IP协议,其重点是在保持TCP协议主要功能的基础上减少对RAM的占用。传统的LwIP应用通常以单进程模式运行,但随着嵌入式设备处理网络负载的增加,单进程架构在性能瓶颈和资源管理方面显现出局限性。
MPA(Multi-Process Architecture)多进程架构通过将LwIP协议栈的功能分布到多个协同工作的进程中,可以显著提高系统的并行处理能力和整体稳定性。这种架构特别适合需要高并发TCP连接处理的场景,如工业物联网网关、智能路由器和嵌入式服务器等。
在现代嵌入式网络应用中,设备需要处理越来越多的并发连接和更高的数据吞吐量。本文提出的MPA架构旨在解决单进程LwIP无法充分挖掘多核处理器潜力的问题,通过进程间通信和智能连接分配,实现网络处理性能的线性提升。
2 LwIP协议栈概述与进程模型分析 🔍
2.1 LwIP协议栈架构特点
LwIP是TCP/IP协议栈的一个实现,其优势在于内存使用率和代码量较小,适用在资源受限的情况下实现和处理Internet协议。LwIP支持多网络接口下的IP转发、ICMP协议、TCP(包括阻塞控制,RTT估算和快速恢复和快速转发)、UDP、DNS、DHCP等多种网络协议。
与传统的TCP/IP实现不同,LwIP设计的一个重要特点是协议栈的各层之间可以直接访问共享内存,避免了数据在层之间传递时频繁的内存拷贝操作。LwIP的模块化架构使其能够灵活适应不同的应用场景,无论是无操作系统的裸机环境,还是基于RTOS的嵌入式系统。
2.2 LwIP的进程模型
LwIP支持三种主要的进程模型,每种模型各有优缺点:
-
独立进程模型:TCP/IP协议族的每一个协议作为一个独立的进程存在。这种模型框架简单清晰,但数据跨层传递时会引起上下文切换(context switch)。对于接收一个TCP段要引起3次上下文切换,从网卡驱动程序到链路层进程,从链路层进程到IP层进程,从IP层进程到TCP进程。
-
内核驻留模型:协议栈驻留在操作系统内核中,应用程序通过系统调用与协议栈通讯。各层协议不必被严格的区分,但可以使用交叉协议分层技术。
-
单进程模型:所有TCP/IP协议栈都在一个进程中,这样TCP/IP协议栈就和操作系统内核分开了。而应用层程序既可以是单独的进程也可以驻留在TCP/IP进程中。LwIP主要采用这种模型,通过回调函数机制提高效率。
在传统的单进程模型中,所有网络数据包的处理都在同一个任务上下文中完成,这可能导致处理瓶颈、优先级反转以及故障扩散等问题。MPA多进程架构正是为了解决这些问题而提出的。
表:LwIP进程模型对比
| 进程模型 | 性能表现 | 系统资源占用 | 移植难度 | 适用场景 |
|---|---|---|---|---|
| 独立进程模型 | 较低(上下文切换开销大) | 较高 | 中等 | 对实时性要求不高的简单应用 |
| 内核驻留模型 | 高 | 低 | 高 | 对性能要求极高的专用系统 |
| 单进程模型 | 中等 | 低 | 低 | 多数嵌入式网络应用 |
| MPA多进程模型 | 高(可充分利用多核) | 中等 | 高 | 高并发、高性能网络应用 |
3 MPA多进程架构设计方案 🏗️
3.1 整体架构概述
MPA多进程架构的核心思想是将传统的单进程LwIP协议栈拆分为多个协同工作的进程,通过连接分发和负载均衡机制提高系统整体处理能力。该架构包含三个关键组件:
- LwIP主进程:负责网络接口管理、连接分配、协议栈初始化以及子进程管理。
- LwIP子进程(X个):每个子进程运行一个独立的LwIP协议栈实例,处理分配给它的TCP连接。
- IPC通信机制:使用高效的无锁队列实现主进程与子进程间的数据交换。
在这种架构中,数据包的流动路径为:物理网卡→驱动中断处理→LwIP主进程(链路层/网络层处理)→连接分派→对应的LwIP子进程(传输层/应用层处理)→应用程序。这种设计实现了网络处理任务的水平扩展,能够有效利用多核处理器的计算资源。
3.2 架构流程图
以下是MPA多进程架构的整体流程图:
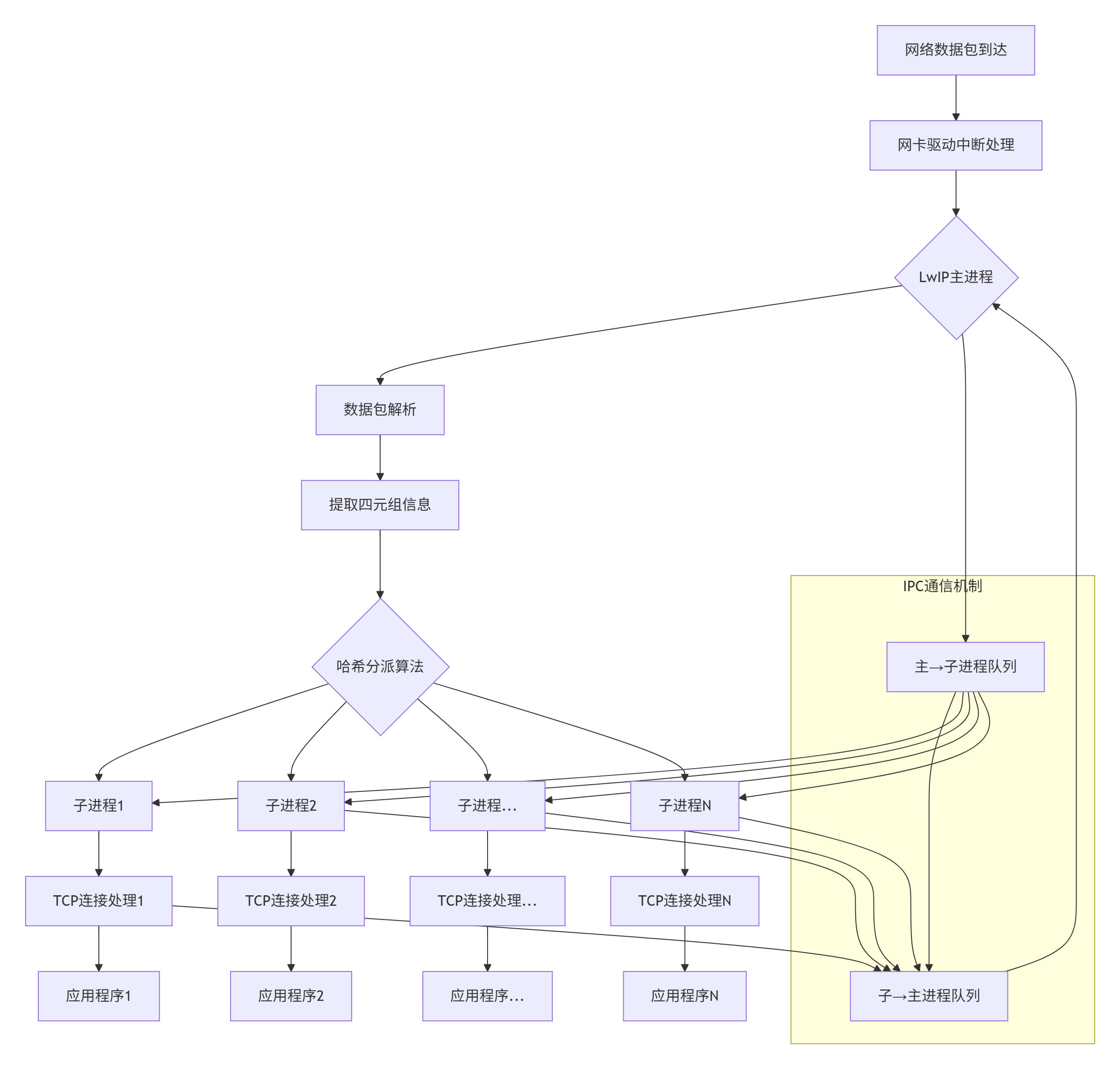
3.3 LwIP主进程设计与功能
LwIP主进程作为系统的核心管理器,承担以下关键职责:
- 系统初始化:负责全局数据结构的初始化,包括协议栈初始化、网络接口配置、子进程创建等。
- 子进程管理:动态创建、监控和调度LwIP子进程,保证系统的容错能力。
- 连接分派:根据TCP/IP四元组哈希算法,将传入的网络连接分派到合适的子进程。
- 网络接口管理:统一管理物理网络接口,处理数据包的接收和发送。
主进程的关键伪代码实现如下:
// 主进程数据结构
struct lwip_main_process {struct netif netif_interface; // 网络接口struct subprocess_manager *subprocs; // 子进程管理器struct ipc_queues *ipc_arrays; // IPC队列数组struct connection_table *conn_table; // 连接跟踪表uint32_t subproc_count; // 子进程数量
};// 主进程主循环
int main_process_loop(void) {// 初始化协议栈lwip_init();// 创建子进程create_subprocesses(SUBPROCESS_COUNT);// 初始化IPC通信机制setup_ipc_queues();while(1) {// 接收网络数据包struct pbuf *packet = low_level_input(&netif_interface);if(packet != NULL) {// 解析数据包并提取连接标识struct connection_id conn_id = extract_connection_id(packet);// 根据四元组哈希选择子进程int subproc_index = hash_quad(conn_id) % SUBPROCESS_COUNT;// 通过IPC队列将数据包发送给选定的子进程ipc_send_packet(subproc_index, packet);}// 处理子进程状态监控monitor_subprocesses();}
}
3.4 LwIP子进程设计与功能
每个LwIP子进程包含一个完整的LwIP协议栈实例,负责处理分配给它的TCP连接。子进程的设计需要考虑以下方面:
- 协议栈实例化:每个子进程运行独立的LwIP协议栈,需要确保不同子进程间的协议栈实例不会相互干扰。
- 连接处理:子进程负责处理TCP连接的完整生命周期,保证同一TCP连接的所有数据包由同一子进程处理。
- IPC通信处理:子进程需要高效处理与主进程之间的IPC通信。
子进程的关键伪代码实现如下:
// 子进程数据结构
struct lwip_subprocess {struct tcp_pcb *tcp_protocol_control_block;struct udp_pcb *udp_protocol_control_block;struct ipc_queue *rx_queue; // 主进程到子进程的接收队列struct ipc_queue *tx_queue; // 子进程到主进程的发送队列int process_id;
};// 子进程主循环
int subprocess_loop(int subproc_id) {// 初始化子进程的LwIP协议栈实例lwip_init_subprocess();// 获取分配给本进程的IPC队列struct ipc_queues *queues = get_ipc_queues(subproc_id);while(1) {// 检查接收队列是否有数据包待处理struct pbuf *packet = ipc_receive_packet(queues->rx_queue);if(packet != NULL) {// 处理数据包(TCP/IP协议栈处理)process_packet(packet);}// 处理协议栈定时事件tcp_timer_handler();// 检查是否需要发送数据process_output_packets(queues->tx_queue);}
}
4 IPC进程间通信机制设计 📡
4.1 共享内存与无锁队列实现
IPC通信机制是MPA架构的性能关键,我们采用共享内存与SPSC(单生产者单消费者)无锁队列相结合的方式,实现高效的主进程-子进程间通信。这种设计具有以下优势:
- 零拷贝数据传输:通过共享内存区域,数据在进程间传递时无需复制,只需传递指针或描述符。
- 低延迟:无锁队列避免了互斥锁带来的上下文切换开销。
- 确定性性能:SPSC队列保证了在任何负载条件下都能提供可预测的性能表现。
队列的数据结构设计如下:
// SPSC无锁队列数据结构
struct spsc_queue {volatile uint32_t head; // 队列头指针volatile uint32_t tail; // 队列尾指针uint32_t mask; // 队列大小掩码(队列大小为2的幂)uint8_t *buffer; // 数据缓冲区uint32_t element_size; // 每个元素的大小uint32_t capacity; // 队列容量
};// 队列元素结构(固定MTU 1500字节)
struct queue_element {uint8_t data[1500]; // 数据负载uint16_t length; // 实际数据长度uint32_t flags; // 标志位struct connection_id conn_id; // 连接标识
};
队列的容量设计为100-1000个元素,这个范围经过精心计算,能够在绝大多数场景下避免队列满的情况。即使出现瞬时流量高峰,队列也有足够的缓冲能力,只有在极端情况下才会触发阻塞机制。
4.2 双通道通信机制
MPA架构为每个主进程-子进程对建立两个方向的通信通道,形成完整的双向数据传输路径:
- 主进程到子进程通道:用于传递接收到的网络数据包和控制消息。
- 子进程到主进程通道:用于传递待发送的数据包和处理结果。
这种双通道设计实现了全双工通信,主进程和子进程可以同时进行数据的发送和接收,最大限度地提高了系统的并发处理能力。
4.3 队列拥塞控制与流量管理
虽然SPSC队列提供了高性能的IPC机制,但仍需考虑流量控制问题,防止队列溢出导致数据丢失。MPA架构实现了多层次的流量控制机制:
- 阻塞式入队:当队列使用率达到高水位线(如90%)时,入队操作将采用阻塞模式。
- 动态流量调整:监控各子进程的队列深度,动态调整数据分派策略。
- 紧急数据处理:为控制消息和高优先级数据提供紧急通道。
流量控制算法的实现如下:
// 智能入队函数
int smart_enqueue(struct spsc_queue *queue, struct queue_element *elem, int timeout_ms) {uint32_t head = queue->head;uint32_t tail = queue->tail;uint32_t count = (head - tail) & queue->mask;// 检查队列是否接近满载if (count > queue->capacity * 0.9) {// 高负载情况下的处理策略if (timeout_ms == 0) {return -1; // 非阻塞模式,立即返回}// 计算最大等待时间uint32_t start_time = get_current_time_ms();while (count > queue->capacity * 0.8) {if (get_current_time_ms() - start_time > timeout_ms) {return -1; // 超时}// 短暂等待后重试usleep(1000);}}// 执行入队操作return spsc_enqueue(queue, elem);
}
4.4 IPC通信序列图(SPSC)
以下IPC通信的序列图展示了主进程与子进程之间的交互过程:
5 TCP连接分发与负载均衡策略 ⚖️
5.1 基于四元组哈希的分发算法
连接分发是MPA架构的核心功能,其目标是将TCP连接均匀分布到各个子进程,同时保证同一连接的所有数据包由同一子进程处理。我们采用基于TCP/IP四元组的哈希算法实现这一目标。
哈希算法的设计考虑了以下因素:
- 均匀性:哈希函数应产生均匀的分布,确保各子进程负载均衡。
- 高效性:哈希计算应简单高效,避免成为性能瓶颈。
- 一致性:同一连接的四元组无论出现多少次,都应哈希到相同的子进程。
我们采用Bob Jenkins的哈希算法变体,它在分布均匀性和计算效率之间取得了良好平衡:
// 四元组哈希函数
uint32_t hash_quad_tuple(struct connection_id *conn) {uint32_t a = conn->src_ip;uint32_t b = conn->dst_ip;uint32_t c = (conn->src_port << 16) | conn->dst_port;// Bob Jenkins哈希算法变体a = a - b; a = a - c; a = a^(c >> 13);b = b - c; b = b - a; b = b^(a << 8);c = c - a; c = c - b; c = c^(b >> 13);a = a - b; a = a - c; a = a^(c >> 12);b = b - c; b = b - a; b = b^(a << 16);c = c - a; c = c - b; c = c^(b >> 5);a = a - b; a = a - c; a = a^(c >> 3);b = b - c; b = b - a; b = b^(a << 10);c = c - a; c = c - b; c = c^(b >> 15);return c;
}// 子进程选择函数
int select_subprocess(struct connection_id *conn, int subprocess_count) {uint32_t hash = hash_quad_tuple(conn);return hash % subprocess_count;
}
5.2 负载均衡与动态调整
简单的哈希分发在大多数情况下能实现负载均衡,但为了应对不均衡的流量模式(如某些连接流量特别大),MPA架构还实现了动态负载调整机制:
- 负载监控:主进程实时监控各子进程的负载指标,包括队列深度、CPU使用率、连接数量等。
- 动态重分配:当检测到负载不均衡时,主进程可以迁移部分连接从过载子进程到负载较轻的子进程。
- 连接迁移:对于长连接且流量大的连接,可以实现连接迁移机制。
负载均衡算法的实现如下:
// 负载均衡决策函数
struct load_balance_info {int subprocess_id;uint32_t connection_count;uint32_t queue_depth;float cpu_usage;uint32_t score; // 负载评分
};int load_balance_decision(struct load_balance_info *info, int count) {// 计算平均负载uint32_t total_score = 0;for (int i = 0; i < count; i++) {total_score += info[i].score;}uint32_t avg_score = total_score / count;// 寻找负载最轻和最重的子进程int lightest = -1, heaviest = -1;uint32_t min_score = UINT32_MAX, max_score = 0;for (int i = 0; i < count; i++) {if (info[i].score < min_score) {min_score = info[i].score;lightest = i;}if (info[i].score > max_score) {max_score = info[i].score;heaviest = i;}}// 如果最重子进程负载超过最轻子进程的1.5倍,触发负载均衡if (max_score > min_score * 1.5) {return heaviest; // 返回需要迁移连接的子进程ID}return -1; // 无需负载均衡
}
5.3 连接跟踪与状态管理
为了确保TCP连接的正确处理,MPA架构需要维护连接跟踪表,记录每个连接的当前状态和所在子进程。连接跟踪表由主进程统一管理,子进程在需要时可以查询连接信息。
连接跟踪表的设计考虑以下因素:
- 高效查找:使用哈希表实现快速的连接查找。
- 并发访问:支持主进程和子进程的并发读取,保证系统性能。
- 容错恢复:在子进程异常退出时,能够恢复连接状态并重新分配连接。
连接跟踪表的关键数据结构如下:
// 连接跟踪表条目
struct conn_track_entry {struct connection_id conn_id;int subprocess_id;uint32_t last_activity; // 最后活动时间戳volatile uint32_t refcount; // 引用计数uint32_t flags; // 状态标志
};// 连接跟踪表
struct connection_table {struct conn_track_entry *entries;uint32_t size; // 表大小pthread_rwlock_t lock; // 读写锁
};// 连接查找函数
int find_connection_subprocess(struct connection_table *table, struct connection_id *conn_id) {// 加读锁pthread_rwlock_rdlock(&table->lock);// 计算哈希值定位条目uint32_t hash = hash_quad_tuple(conn_id);uint32_t index = hash % table->size;// 处理哈希冲突while (table->entries[index].conn_id.src_ip != 0) {if (memcmp(&table->entries[index].conn_id, conn_id, sizeof(struct connection_id)) == 0) {int subproc_id = table->entries[index].subprocess_id;pthread_rwlock_unlock(&table->lock);return subproc_id;}index = (index + 1) % table->size;}pthread_rwlock_unlock(&table->lock);return -1; // 未找到
}
6 性能优化与系统稳定性 🚀
6.1 内存管理优化
内存管理是高性能网络系统的关键因素。LwIP协议栈采用了一种混合内存管理策略:一种是内存堆分配,一种是内存池分配。MPA架构针对LwIP的内存管理进行了多项优化:
- 零拷贝数据传递:通过共享内存和指针传递,避免数据在进程间复制。
- 内存池预分配:启动时预分配所有需要的内存块,减少运行时动态分配的开销。
- 缓存友好布局:优化数据结构布局,提高CPU缓存命中率。
内存管理的优化实现如下:
// 高效内存池实现
struct memory_pool {void *base_addr; // 内存池基地址uint32_t block_size; // 每个块的大小uint32_t total_blocks; // 总块数volatile uint32_t free_head; // 空闲链表头volatile uint32_t *free_list; // 空闲链表
};// 内存分配函数
void *mp_alloc(struct memory_pool *mp) {uint32_t old_head, new_head;do {old_head = mp->free_head;if (old_head == MP_NULL_INDEX) {return NULL; // 内存池耗尽}new_head = mp->free_list[old_head];} while (!__sync_bool_compare_and_swap(&mp->free_head, old_head, new_head));return (void *)((uint8_t *)mp->base_addr + old_head * mp->block_size);
}
LwIP使用pbuf结构体描述数据包,每个pbuf管理的数据不能覆盖整个数据包,所以需要链表结构。在MPA架构中,我们对pbuf的管理也进行了优化,确保数据包在进程间高效传递。
6.2 系统容错与故障恢复
MPA架构通过多种机制确保系统的高可用性:
- 子进程监控:主进程定期检查子进程的健康状态,发现异常子进程及时重启。
- 连接恢复:当子进程异常退出时,主进程负责恢复其处理的连接,尽量减少对应用的影响。
- 优雅降级:在系统资源紧张时,自动减少子进程数量或限制新连接,保证系统基本功能可用。
容错机制的关键实现:
// 子进程监控函数
void monitor_subprocesses(struct main_process *mp) {for (int i = 0; i < mp->subproc_count; i++) {if (mp->subprocesses[i].pid == 0) {continue; // 空槽位}// 检查子进程状态int status;pid_t result = waitpid(mp->subprocesses[i].pid, &status, WNOHANG);if (result == 0) {// 子进程正常运行continue;} else if (result == mp->subprocesses[i].pid) {// 子进程异常退出printf("Subprocess %d exited unexpectedly, restarting...\n", i);// 恢复子进程处理的连接recover_connections(mp, i);// 重启子进程restart_subprocess(mp, i);}}
}// 连接恢复函数
void recover_connections(struct main_process *mp, int failed_subproc) {// 锁定连接表pthread_rwlock_wrlock(&mp->conn_table->lock);// 遍历连接表,找到故障子进程处理的连接for (int i = 0; i < mp->conn_table->size; i++) {if (mp->conn_table->entries[i].subprocess_id == failed_subproc) {// 重新分配连接到其他子进程int new_subproc = select_subprocess(&mp->conn_table->entries[i].conn_id, mp->subproc_count);mp->conn_table->entries[i].subprocess_id = new_subproc;}}pthread_rwlock_unlock(&mp->conn_table->lock);
}
7 总结🔮
本文详细探讨了LwIP协议栈的MPA多进程架构设计方案,重点介绍了TCP连接分发、IPC进程间通信、负载均衡等关键技术。MPA架构通过将传统的单进程LwIP协议栈拆分为多个协同工作的进程,成功解决了高并发场景下的性能瓶颈问题。