【Redis典型应用——缓存详解】
系列文章目录
文章目录
- 系列文章目录
- 一、缓存基础知识
- 1.什么是缓存
- 2.为什么用Redis作为缓存
- 二、缓存更新策略
- 1.定期生成
- 1.实现逻辑:
- 2.优点和不足
- 2.实时生成
- 1.实现逻辑:
- 2.缓存淘汰策略:
- 三、缓存注意事项缓存预热,缓存穿透,缓存雪崩和缓存击穿
- 1.缓存预热
- 2.缓存穿透
- 一、什么是缓存穿透?
- 二、缓存穿透的 3 个核心成因
- 三、解决缓存穿透的 3 个实用方案
- 3.缓存雪崩
- 二、产生的原因:
- 三、解决方案
- 4.缓存击穿
- 二、缓存击穿的核心成因
- 三、解决方法
一、缓存基础知识
1.什么是缓存
缓存不是某一种工具,而是一种 “数据存储策略”,核心逻辑是 “把高频使用的数据,放到更快的存储介质里,方便后续快速取用”。
可以用生活例子理解:
比如超市会把 “常买的零食、饮料” 放在入口的货架(快取区),而不常买的大米、面粉放在仓库(慢取区)。这里的 “入口货架” 就是 “缓存”,目的是让顾客不用跑仓库,更快拿到商品。
对应到计算机里:“仓库” 是数据库(如 MySQL,存在磁盘,读写慢),“入口货架” 就是缓存(存在内存,读写快),高频访问的数据(如首页商品、用户 Session)会先存到缓存里,后续请求直接查缓存,不用查数据库。
注意:缓存的访问速度是更快,但是相对的空间往往不足,所以大部分只存放热点数据。
2.为什么用Redis作为缓存
一般在网站中,我们经常会使用关系型数据库(比如MySQL)来存储数据,虽然能存储的数据多,但性能不高。
- 数据库数据存储在硬盘上,硬盘的IO速度并不快,尤其还是随机访问。
- 如果查询不能命中索引,就需要进行表的遍历,会大大增加IO次数。
- 关系型数据库对于SQL的执行会做一系列的解析,校验,优化工作。
- 如果是复杂的查询,例如联合查询,还需要笛卡尔积操作,效率会降低很多。
如何让数据库承担更大的并发量?核心思路主要是两个:
1.开源:引入更多机器,部署更多数据库实例,构成数据库集群(主从复制、分库分表等)。
2.节流:引入缓存,用其他方式保存经常访问的热点数据,从而降低直接访问数据库的请求数量。
Redis就是一个用作数据缓存的常见方案
Redis优点:
- 速度快:数据存于内存,读写速度达 10 万 +/ 秒,远超数据库(磁盘 IO)。
- 支持多数据结构:不止存字符串,还能存 Hash、List、Set 等,适配不同缓存场景(比如用 Hash 存用户信息,List 存消息队列)。
- 高可用:支持主从复制、哨兵、集群,避免缓存单点故障。
- 可持久化:能把内存数据存到磁盘,重启后数据不丢失(避免缓存全量重建)。
如下图所示:
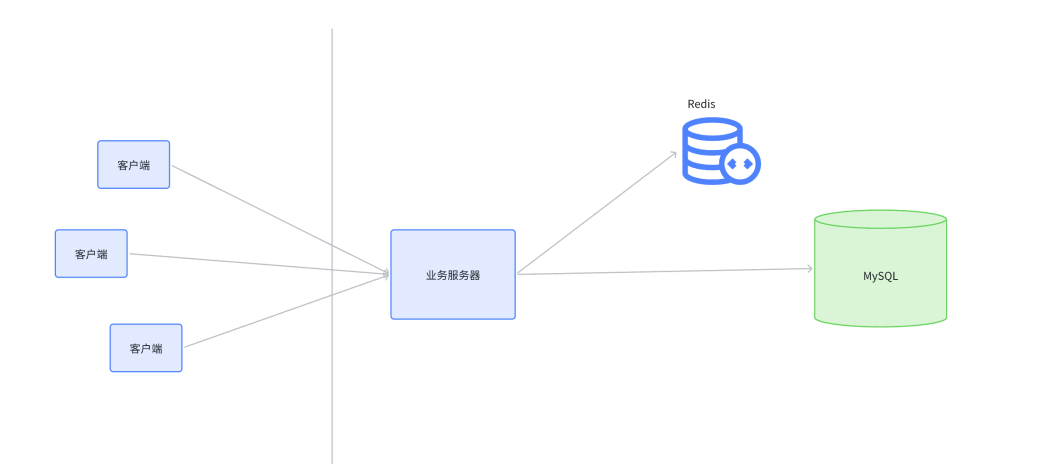
- 客户端访问业务服务器,发起查询请求。
- 业务服务器先查询 Redis,看想要的数据是否在 Redis 中存在。
- 如果已经在 Redis 中存在,就直接返回,此时不必访问 MySQL。
- 如果在 Redis 中不存在,再查询 MySQL。按照 “二八定律”,只需要在 Redis 中放 20% 的热点数据,就可以使 80% 的请求不再真正查询数据库。
二、缓存更新策略
1.定期生成
缓存数据按 “固定时间间隔” 更新,不管数据是否变化。典型应用如搜索引擎热词、常规商品推荐等场景。
1.实现逻辑:
以 “搜索引擎热词缓存” 为例,完整流程如下:
1.日志记录访问数据:
先将用户的访问行为(如搜索框输入的查询词)以日志形式持久化(若数据量大,可存储在分布式系统 HDFS 中)。
离线统计热点数据
2.用大数据工具(如 Hadoop MapReduce、Python 脚本)对日志进行分析:
统计 “每个词的访问频率”,按频率降序排序;
提取前 20% 的 “热点词”(符合二八定律,少量数据承接大部分访问)。
3.定时任务同步到 Redis 缓存
编写离线脚本(如 Shell、Python),通过定时任务(Crontab、Quartz 等) 按周期(如每天凌晨)执行:
-
从数据库 / 数据仓库中拉取 “热点词对应的搜索结果”;
-
用SET key value EX 86400(设 1 天过期)将数据写入 Redis,完成缓存更新。
比如每天凌晨 2 点同步一次商品库存到 Redis,每 30 分钟刷新一次首页推荐列表 —— 核心是 “到点就更”,不依赖实时数据变化。
2.优点和不足
优点:
1.实现逻辑清晰:从 “日志记录→统计分析→缓存同步” 全流程可拆解,方便开发和排查问题(比如 Redis 中缓存了哪些热词,可通过脚本和日志回溯)。
2.资源消耗可预测:定时任务按固定时间执行,不会因突发流量导致缓存或数据库压力陡增。
3.适配 Redis 特性:可结合EXPIRE命令设置过期时间,避免缓存长期占用内存;若任务执行失败,还可通过 “重试机制” 或 “兜底查询”(缓存过期后读数据库回写)保障数据可用。
不足:
1.无法响应突发热点:若出现突发性事件(如春节晚会的临时热词),定期更新的缓存无法及时承接流量,可能导致数据库压力骤增。
2.时效性滞后:数据更新周期越长(如按月更新),缓存与实际数据的偏差可能越大。
2.实时生成
1.实现逻辑:
先给缓存设定容量上限(可通过 Redis 配置文件的 maxmemory 参数设定)。
接下来用户每次查询:
- 若在 Redis 查到,直接返回。
- 若 Redis 中不存在,从数据库查询,并将结果写入 Redis。
- 若缓存已满(达到上限),触发缓存淘汰策略,淘汰一些 “相对不那么热门” 的数据。
2.缓存淘汰策略:
FIFO(先进先出):
淘汰缓存中存在时间最久的数据。举例:超市货架补货时,先把最早摆放的商品下架,上新最近到货的商品。
LRU(最久未使用):
记录每个 key 的最近访问时间,淘汰最近访问时间最老的 key。举例:手机后台 APP 清理,很久没打开的 APP 会被优先清理掉。
LFU(最少访问次数):
记录每个 key 最近一段时间的访问次数,淘汰访问次数最少的 key。举例:公司食堂窗口,学生光顾次数最少的窗口,会优先被调整或替换。
Random(随机淘汰):
从所有 key 中随机选一个淘汰。
理解淘汰策略:假设你手机里装了上百个 APP(相当于数据库全量数据),但常用的就那么几个(比如微信、抖音、外卖 APP,相当于缓存里的热点数据)。新出了一款超火的手游,你想下载,就得卸载一个旧 APP。该淘汰谁呢?
FIFO(先进先出):最早下载的 APP(比如刚买手机时装的 “万年历”),因为存在时间最久,被你卸载。
LRU(最久未使用):统计最近使用时间 —— 相册(一周前用过)、地图(昨天用过)、读书 APP(两周前用过)、股票软件(一个月前用过)。股票软件最久没被使用,被卸载。
LFU(最少访问次数):统计最近一个月的使用次数 —— 相册(3 次)、地图(15 次)、读书 APP(1 次)、股票软件(10 次)。读书 APP 使用次数最少,被卸载。
Random(随机淘汰):随机挑一个 APP,比如随机到相册,就把相册卸载了。
–
三、缓存注意事项缓存预热,缓存穿透,缓存雪崩和缓存击穿
1.缓存预热
概念:缓存预热的核心是在 Redis 缓存 “空” 或失效时,提前加载热点数据到 Redis,避免 MySQL 直接承压,本质是为 Redis 快速建立 “防护屏障”,适配 Redis 作为 MySQL 缓存的典型场景。
当 Redis 处于以下两种关键状态时,缓存能力基本失效:
Redis 刚启动:内存中无任何缓存数据,所有请求会直接穿透到 MySQL。
Redis 大批 key 失效:如缓存雪崩导致大量 key 同时过期,短时间内缓存 “空窗”。
此时,提前将 “热点数据” 主动写入 Redis,让 Redis 快速具备承接请求的能力,减少 MySQL 的直接访问量,这一操作就是缓存预热。它不需要等待用户请求触发 “查数据库→回写缓存” 的流程,而是主动为 Redis “填充弹药”。
注意:热点数据基于之前介绍的统计方式生成即可。这份热点数据不一定要那么 “准确”,只要能帮助 MySQL 抵挡大部分请求就行。随着程序运行,缓存的热点数据会逐渐自动调整,以更适应当前情况。
2.缓存穿透
概念:缓存穿透的核心是访问的 key 在 Redis 和数据库中均不存在,导致请求绕过缓存直接冲击数据库,长期会造成数据库压力过载,是 Redis 缓存架构中的典型风险点。
一、什么是缓存穿透?
当用户发起查询请求时,若满足以下两个条件,即构成缓存穿透:
目标 key 在 Redis 中不存在(缓存未命中);
该 key 在数据库(如 MySQL)中也不存在;
由于 key 在数据库中无数据,无法回写到 Redis,后续相同请求会持续绕过缓存,重复访问数据库,导致数据库承担不必要的高频请求压力。
二、缓存穿透的 3 个核心成因
缓存穿透并非偶然,主要源于业务设计、操作失误或恶意攻击,具体可分为三类:
- 业务设计不合理:缺少参数合法性校验环节,导致非法 key 被允许查询。
例:查询用户信息时,未校验用户 ID 格式(如允许 “ID=-1”“ID=abc” 这类无效值),这类 key 在 Redis 和数据库中均不存在,会持续触发穿透。 - 开发 / 运维误操作:不慎删除数据库中的部分数据,导致原本存在的 key 变为 “双不存在”。
- 黑客恶意攻击:通过批量发送不存在的 key 请求,蓄意消耗数据库资源。
三、解决缓存穿透的 3 个实用方案
针对上述成因,需从 “拦截非法请求”“避免重复穿透”“提前判定存在性” 三个维度设计解决方案,落地性强且覆盖大部分场景:
-
严格校验查询参数合法性:在业务层前置拦截无效 key,从源头减少穿透请求。
-
缓存 “不存在的 key”(空值缓存):对数据库中不存在的 key,在 Redis 中存储空值,避免后续重复访问数据库。
操作逻辑:
当数据库查询结果为空时,用SET key “” EX 3600(设 1 小时过期)将空值写入 Redis;后续相同请求会命中 Redis 的空值,直接返回,无需访问数据库; -
用布隆过滤器前置判定 key 存在性:在缓存前加一层布隆过滤器,提前过滤 “绝对不存在的 key”。
操作逻辑:
初始化时,将数据库中所有有效 key(如所有用户 ID、商品 ID)存入布隆过滤器(本质是一个二进制数组,通过哈希算法标记 key 存在);
用户请求时,先通过布隆过滤器判定 key 是否存在:
若过滤器判定 “不存在”,直接返回,不进入 Redis 或数据库;
若判定 “可能存在”(布隆过滤器有极小误判率),再继续查询 Redis 和数据库;
优势:布隆过滤器占用内存极小(百万级 key 仅需几 MB),判定速度快(微秒级),能有效拦截绝大多数不存在的 key。
3.缓存雪崩
缓存雪崩的核心是Redis 缓存的 “防护层” 短时间内大面积失效,导致原本由缓存承接的请求瞬间全部涌向 MySQL,造成数据库压力骤增甚至直接宕机,是高并发场景下缓存架构的致命风险。
二、产生的原因:
- Redis 服务本身不可用(缓存层整体宕机)
Redis 作为缓存核心,若自身出现故障,会导致所有依赖 Redis 的请求直接穿透到 MySQL - 大量 Redis key 同时过期(缓存数据集体失效)
这是更常见的雪崩场景,核心原因是 “短时间内缓存的大量 key 设置了相同过期时间”,到期后集体失效。
三、解决方案
- 部署高可用 Redis 集群,搭配完善监控报警。
- 优化 Redis key 的过期时间,避免集体失效。
核心思路是 “打散 key 的过期时间”,不让大量 key 在同一时间到期,从源头减少雪崩风险。
例如给过期时间添加随机因子(最常用):
操作逻辑:在设置过期时间时,不使用固定值,而是在基础过期时间上叠加一个随机数,让 key 的过期时间分散开;
4.缓存击穿
概念:它是单一热点 key 突然过期,导致大量请求集中冲击数据库的特殊场景,属于缓存雪崩的 “定向缩小版”,需重点与穿透、雪崩做区分。
二、缓存击穿的核心成因
所有缓存击穿的根源都指向 “热点 key 的缓存突然不可用”,唯一触发条件是:
key 是高频访问的热点数据:该 key 的访问量远高于其他 key(如占总请求量的 30% 以上),是流量核心;
key 突然过期 / 被删除。
三、解决方法
- 热点 key “永不过期”(主动更新避免失效)
核心是 “不给热点 key 设固定过期时间,用定时任务主动同步数据”,从源头杜绝 “过期” 问题。
操作逻辑:
优势:彻底避免热点 key 过期,无需担心击穿风险;
注意点:需确保定时任务的稳定性(如加重试机制),若任务失败,可临时触发 “手动同步”,避免 Redis 存旧数据。 - 分布式锁限流(限制数据库并发请求)
核心是 “当热点 key 过期时,用分布式锁控制仅 1 个请求去查数据库,其他请求等待重试”,避免数据库被瞬间压垮,将服务降级。
优势:无需提前识别热点 key,适合热点 key 动态变化的场景;
注意点:锁的过期时间需大于 “查 MySQL + 写 Redis” 的耗时(如 5 秒足够),避免锁提前释放导致多个请求查数据库。
3. 热点 key 提前预热(主动填充缓存)
核心是 “在热点 key 可能过期前,提前用脚本或任务更新缓存”,属于 “防患于未然” 的前置方案,与缓存预热逻辑一致。
优势:无锁竞争开销,用户请求无感知,体验更好;
适用场景:热点 key 的过期时间固定、可预测(如每日固定时间过期的活动商品)。