【图像超分】论文复现:轻量化超分 | SPAN的Pytorch源码复现,跑通源码进行训练、测试
【图像超分】论文复现:轻量化超分 | SPAN的Pytorch源码复现,跑通源码进行训练、测试
前言
论文题目:Swift Parameter-free Attention Network for Efficient Super-Resolution
论文地址:https://arxiv.org/abs/2311.12770
论文源码:https://github.com/hongyuanyu/SPAN?tab=readme-ov-file
NTIRE 2024高效超分辨率挑战赛运行赛道第一名
摘要:Single Image Super-Resolution (SISR) is a crucial task in low-level computer vision, aiming to reconstruct high-resolution images from low-resolution counterparts. Conventional attention mechanisms have significantly improved SISR performance but often result in complex network structures and large number of parameters, leading to slow inference speed and large model size. To address this issue, we propose the Swift Parameter-free Attention Network (SPAN), a highly efficient SISR model that balances parameter count, inference speed, and image quality. SPAN employs a novel parameter-free attention mechanism, which leverages symmetric activation functions and residual connections to enhance high-contribution information and suppress redundant information. Our theoretical analysis demonstrates the effectiveness of this design in achieving the attention mechanism’s purpose. We evaluate SPAN on multiple benchmarks, showing that it outperforms existing efficient super-resolution models in terms of both image quality and inference speed, achieving a significant quality-speed trade-off. This makes SPAN highly suitable for real-world applications, particularly in resource-constrained scenarios. Notably, we won the first place both in the overall performance track and runtime track of the NTIRE 2024 efficient super-resolution challenge. Our code and models are made publicly available at this https URL.
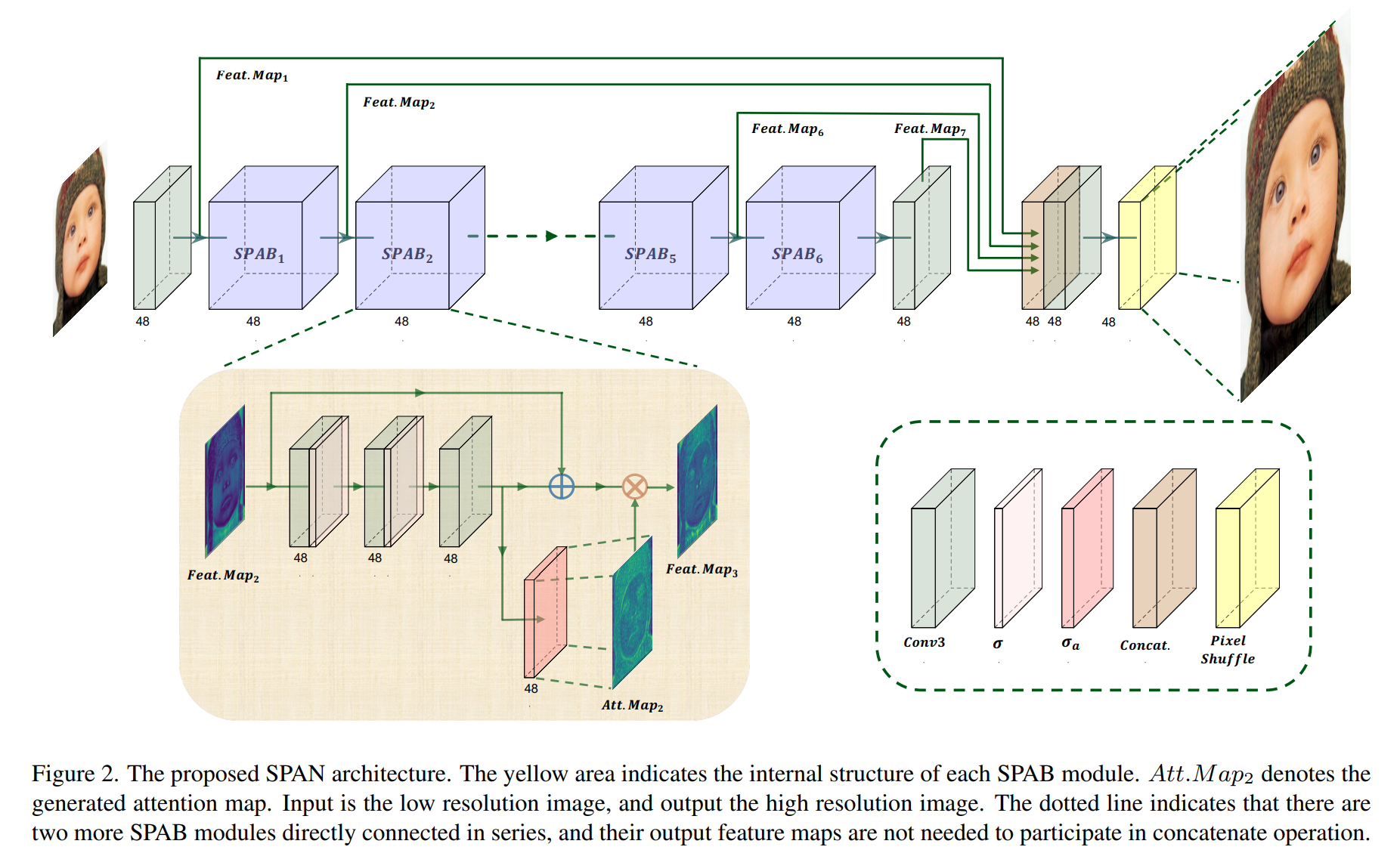
网络结构
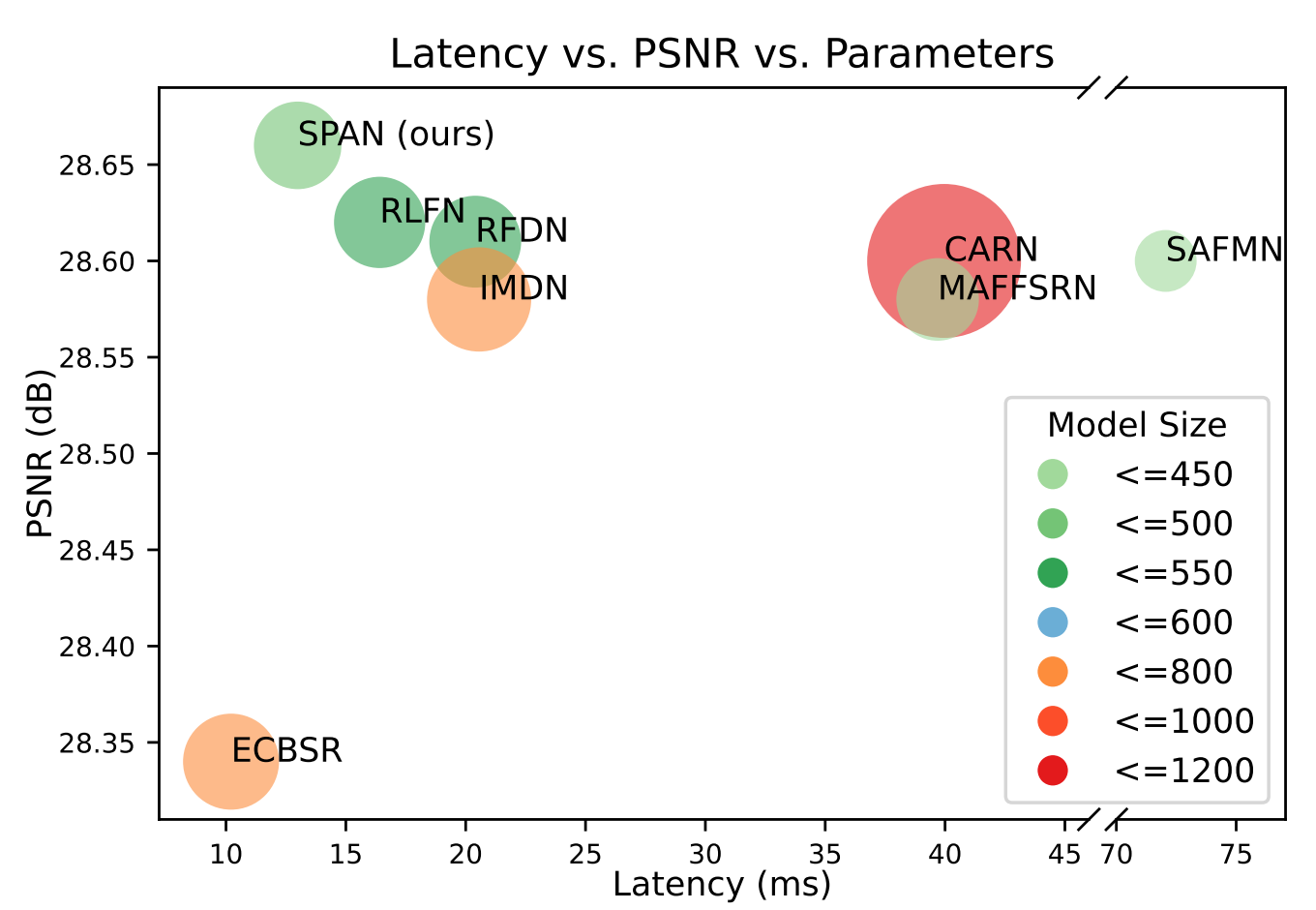
📈 结果

模型代码
from collections import OrderedDict
import torch
from torch import nn as nn
import torch.nn.functional as F
from basicsr.utils.registry import ARCH_REGISTRYdef _make_pair(value):if isinstance(value, int):value = (value,) * 2return valuedef conv_layer(in_channels,out_channels,kernel_size,bias=True):"""Re-write convolution layer for adaptive `padding`."""kernel_size = _make_pair(kernel_size)padding = (int((kernel_size[0] - 1) / 2),int((kernel_size[1] - 1) / 2))return nn.Conv2d(in_channels,out_channels,kernel_size,padding=padding,bias=bias)def activation(act_type, inplace=True, neg_slope=0.05, n_prelu=1):"""Activation functions for ['relu', 'lrelu', 'prelu'].Parameters----------act_type: strone of ['relu', 'lrelu', 'prelu'].inplace: boolwhether to use inplace operator.neg_slope: floatslope of negative region for `lrelu` or `prelu`.n_prelu: int`num_parameters` for `prelu`.----------"""act_type = act_type.lower()if act_type == 'relu':layer = nn.ReLU(inplace)elif act_type == 'lrelu':layer = nn.LeakyReLU(neg_slope, inplace)elif act_type == 'prelu':layer = nn.PReLU(num_parameters=n_prelu, init=neg_slope)else:raise NotImplementedError('activation layer [{:s}] is not found'.format(act_type))return layerdef sequential(*args):"""Modules will be added to the a Sequential Container in the order theyare passed.Parameters----------args: Definition of Modules in order.-------"""if len(args) == 1:if isinstance(args[0], OrderedDict):raise NotImplementedError('sequential does not support OrderedDict input.')return args[0]modules = []for module in args:if isinstance(module, nn.Sequential):for submodule in module.children():modules.append(submodule)elif isinstance(module, nn.Module):modules.append(module)return nn.Sequential(*modules)def pixelshuffle_block(in_channels,out_channels,upscale_factor=2,kernel_size=3):"""Upsample features according to `upscale_factor`."""conv = conv_layer(in_channels,out_channels * (upscale_factor ** 2),kernel_size)pixel_shuffle = nn.PixelShuffle(upscale_factor)return sequential(conv, pixel_shuffle)class Conv3XC(nn.Module):def __init__(self, c_in, c_out, gain1=1, gain2=0, s=1, bias=True, relu=False):super(Conv3XC, self).__init__()self.weight_concat = Noneself.bias_concat = Noneself.update_params_flag = Falseself.stride = sself.has_relu = relugain = gain1self.sk = nn.Conv2d(in_channels=c_in, out_channels=c_out, kernel_size=1, padding=0, stride=s, bias=bias)self.conv = nn.Sequential(nn.Conv2d(in_channels=c_in, out_channels=c_in * gain, kernel_size=1, padding=0, bias=bias),nn.Conv2d(in_channels=c_in * gain, out_channels=c_out * gain, kernel_size=3, stride=s, padding=0, bias=bias),nn.Conv2d(in_channels=c_out * gain, out_channels=c_out, kernel_size=1, padding=0, bias=bias),)self.eval_conv = nn.Conv2d(in_channels=c_in, out_channels=c_out, kernel_size=3, padding=1, stride=s, bias=bias)self.eval_conv.weight.requires_grad = Falseself.eval_conv.bias.requires_grad = Falseself.update_params()def update_params(self):w1 = self.conv[0].weight.data.clone().detach()b1 = self.conv[0].bias.data.clone().detach()w2 = self.conv[1].weight.data.clone().detach()b2 = self.conv[1].bias.data.clone().detach()w3 = self.conv[2].weight.data.clone().detach()b3 = self.conv[2].bias.data.clone().detach()w = F.conv2d(w1.flip(2, 3).permute(1, 0, 2, 3), w2, padding=2, stride=1).flip(2, 3).permute(1, 0, 2, 3)b = (w2 * b1.reshape(1, -1, 1, 1)).sum((1, 2, 3)) + b2self.weight_concat = F.conv2d(w.flip(2, 3).permute(1, 0, 2, 3), w3, padding=0, stride=1).flip(2, 3).permute(1, 0, 2, 3)self.bias_concat = (w3 * b.reshape(1, -1, 1, 1)).sum((1, 2, 3)) + b3sk_w = self.sk.weight.data.clone().detach()sk_b = self.sk.bias.data.clone().detach()target_kernel_size = 3H_pixels_to_pad = (target_kernel_size - 1) // 2W_pixels_to_pad = (target_kernel_size - 1) // 2sk_w = F.pad(sk_w, [H_pixels_to_pad, H_pixels_to_pad, W_pixels_to_pad, W_pixels_to_pad])self.weight_concat = self.weight_concat + sk_wself.bias_concat = self.bias_concat + sk_bself.eval_conv.weight.data = self.weight_concatself.eval_conv.bias.data = self.bias_concatdef forward(self, x):if self.training:pad = 1x_pad = F.pad(x, (pad, pad, pad, pad), "constant", 0)out = self.conv(x_pad) + self.sk(x)else:self.update_params()out = self.eval_conv(x)if self.has_relu:out = F.leaky_relu(out, negative_slope=0.05)return outclass SPAB(nn.Module):def __init__(self,in_channels,mid_channels=None,out_channels=None,bias=False):super(SPAB, self).__init__()if mid_channels is None:mid_channels = in_channelsif out_channels is None:out_channels = in_channelsself.in_channels = in_channelsself.c1_r = Conv3XC(in_channels, mid_channels, gain1=2, s=1)self.c2_r = Conv3XC(mid_channels, mid_channels, gain1=2, s=1)self.c3_r = Conv3XC(mid_channels, out_channels, gain1=2, s=1)self.act1 = torch.nn.SiLU(inplace=True)self.act2 = activation('lrelu', neg_slope=0.1, inplace=True)def forward(self, x):out1 = (self.c1_r(x))out1_act = self.act1(out1)out2 = (self.c2_r(out1_act))out2_act = self.act1(out2)out3 = (self.c3_r(out2_act))sim_att = torch.sigmoid(out3) - 0.5out = (out3 + x) * sim_attreturn out, out1, sim_att@ARCH_REGISTRY.register()
class SPAN(nn.Module):"""Swift Parameter-free Attention Network for Efficient Super-Resolution"""def __init__(self,num_in_ch,num_out_ch,feature_channels=48,upscale=4,bias=True,img_range=255.,rgb_mean=(0.4488, 0.4371, 0.4040)):super(SPAN, self).__init__()in_channels = num_in_chout_channels = num_out_chself.img_range = img_rangeself.mean = torch.Tensor(rgb_mean).view(1, 3, 1, 1)self.conv_1 = Conv3XC(in_channels, feature_channels, gain1=2, s=1)self.block_1 = SPAB(feature_channels, bias=bias)self.block_2 = SPAB(feature_channels, bias=bias)self.block_3 = SPAB(feature_channels, bias=bias)self.block_4 = SPAB(feature_channels, bias=bias)self.block_5 = SPAB(feature_channels, bias=bias)self.block_6 = SPAB(feature_channels, bias=bias)self.conv_cat = conv_layer(feature_channels * 4, feature_channels, kernel_size=1, bias=True)self.conv_2 = Conv3XC(feature_channels, feature_channels, gain1=2, s=1)self.upsampler = pixelshuffle_block(feature_channels, out_channels, upscale_factor=upscale)def forward(self, x):self.mean = self.mean.type_as(x)x = (x - self.mean) * self.img_rangeout_feature = self.conv_1(x)out_b1, _, att1 = self.block_1(out_feature)out_b2, _, att2 = self.block_2(out_b1)out_b3, _, att3 = self.block_3(out_b2)out_b4, _, att4 = self.block_4(out_b3)out_b5, _, att5 = self.block_5(out_b4)out_b6, out_b5_2, att6 = self.block_6(out_b5)out_b6 = self.conv_2(out_b6)out = self.conv_cat(torch.cat([out_feature, out_b6, out_b1, out_b5_2], 1))output = self.upsampler(out)return outputif __name__ == "__main__":from fvcore.nn import FlopCountAnalysis, flop_count_tableimport timemodel = SPAN(3, 3, upscale=4, feature_channels=48).cuda()model.eval()inputs = (torch.rand(1, 3, 256, 256).cuda(),)print(flop_count_table(FlopCountAnalysis(model, inputs)))
复现过程
下载数据集DIV2K(https://data.vision.ee.ethz.ch/cvl/DIV2K/)以及Flickr2K(http://cv.snu.ac.kr/research/EDSR/Flickr2K.tar)
更改train配置文件
# general settings
name: 206_EDSR_Lx4_f256b32_DIV2K_300k_B16G1_204pretrain_wandb
model_type: SRModel
scale: 4
num_gpu: 1 # set num_gpu: 0 for cpu mode
manual_seed: 10# dataset and data loader settings
datasets:train:name: DIV2Ktype: PairedImageDatasetdataroot_gt: C:\Users\27879\jiangguolong\EDSR-PyTorch-master\EDSR-PyTorch-master\datasets\DIV2K\DIV2K\DIV2K_train_HRdataroot_lq: C:\Users\27879\jiangguolong\EDSR-PyTorch-master\EDSR-PyTorch-master\datasets\DIV2K\DIV2K\DIV2K_train_LR_bicubic\X4# (for lmdb)# dataroot_gt: datasets/DIV2K/DIV2K_train_HR_sub.lmdb# dataroot_lq: datasets/DIV2K/DIV2K_train_LR_bicubic_X4_sub.lmdbfilename_tmpl: '{}'io_backend:type: disk# (for lmdb)# type: lmdbgt_size: 192use_hflip: trueuse_rot: true# data loadernum_worker_per_gpu: 12batch_size_per_gpu: 32dataset_enlarge_ratio: 1prefetch_mode: ~val:name: Set5type: PairedImageDatasetdataroot_gt: datasets/Set5/image_SRF_4/HRdataroot_lq: datasets/Set5/image_SRF_4/LRio_backend:type: disk# network structures
network_g:type: SPANnum_in_ch: 3num_out_ch: 3upscale: 4img_range: 255.rgb_mean: [0.4488, 0.4371, 0.4040]# path
path:pretrain_network_g: ~strict_load_g: falseresume_state: ~# training settings
train:ema_decay: 0.999optim_g:type: Adamlr: !!float 1e-4weight_decay: 0betas: [0.9, 0.99]scheduler:type: MultiStepLRmilestones: [200000]gamma: 0.5total_iter: 300000warmup_iter: -1 # no warm up# lossespixel_opt:type: L1Lossloss_weight: 1.0reduction: mean# validation settings
val:val_freq: !!float 5e3save_img: falsemetrics:psnr: # metric name, can be arbitrarytype: calculate_psnrcrop_border: 4test_y_channel: false# logging settings
logger:print_freq: 100save_checkpoint_freq: !!float 5e3use_tb_logger: truewandb:project: ~resume_id: ~# dist training settings
dist_params:backend: ncclport: 29500训练命令
python .\basicsr\train.py -opt .\options\train\EDSR\train_EDSR_Lx4.yml