PaddleOCR-VL:紧凑型0.9B参数模型在多语言文档解析领域表现卓越
作者:算力魔方创始人/飞桨开发者专家 刘力
近日,百度飞桨团队正式推出 PaddleOCR-VL🚀
https://huggingface.co/PaddlePaddle/PaddleOCR-VL一款创新的视觉语言模型,专为文档解析场景设计,在保持高效性能的同时显著降低资源消耗。
文档解析的技术挑战在于现实文档的复杂性。典型文档通常包含布局、表格📊、图表📈、公式、手写内容✍️和多语言文本等多种元素的混合呈现,这对传统解析模型构成了巨大挑战。PaddleOCR-VL
https://huggingface.co/PaddlePaddle/PaddleOCR-VL(0.9B) 以其精巧的0.9B参数规模,创新性地结合了动态高分辨率视觉编码器和轻量级ERNIE-4.5–0.3B语言模型,在保证高精度的同时大幅减少计算需求。
✅ 支持 109 种语言
✅ 处理复杂的文档元素
✅ 在有限的硬件上高效运行
✅ 在实际场景中超越更大的模型
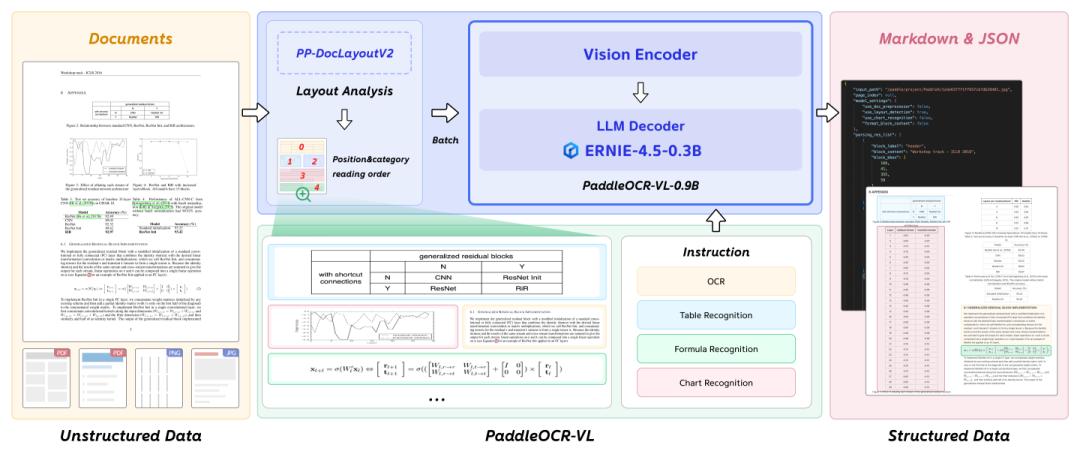
一,🐜 小模型,🐘 大性能
传统文档AI模型往往需要在速度与精度间进行权衡,而PaddleOCR-VL实现了二者的平衡。
-
动态视觉编码器:采用NaViT风格架构,高效处理高分辨率图像
-
轻量语言模型:基于ERNIE-4.5–0.3B,提供优质语义理解能力
这种架构组合确保了高精度🎯与低延迟⚡的兼得,使得复杂文档解析具备实际应用价值。
PaddleOCR-VL架构示意图:
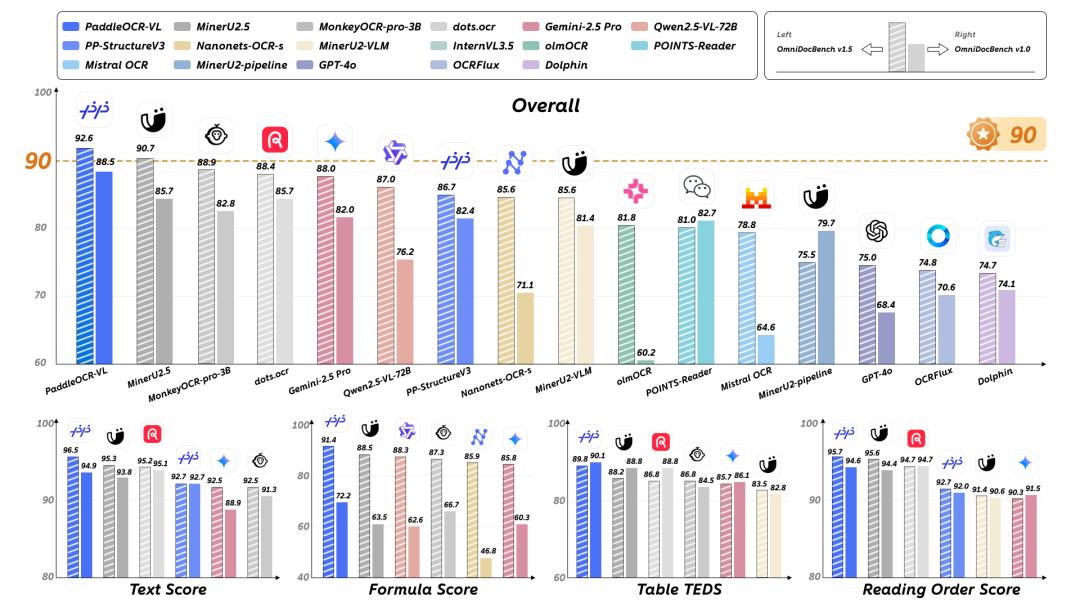
二,🏆 领先的准确率表现
PaddleOCR-VL 在公共基准测试的两个方面均处于领先地位:
页面级理解
✅ 布局识别
✅ 阅读顺序检测
元素级提取
✅ 表格 📊
✅ 公式 ➗
✅ 图表 📈
✅ 手写文字 ✍️
✅ 历史文档 📜
它功能多样、鲁棒性强且经过实战检验。

三,🌐 多语言支持 单一模型
PaddleOCR-VL专为全球化应用设计,支持语言远超英语范畴。
涵盖中文、英语、日语、韩语、拉丁语等主要语言,同时支持西里尔字母(俄语)、阿拉伯语、天城文(印地语)等多种文字体系。
面对多语言混合文档,该模型能够直接处理。🌍

四,🚀 快速入门指南
1️⃣ 环境安装依赖:PaddlePaddle 和 PaddleOCR:
https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/linux-pip.html
https://github.com/PaddlePaddle/PaddleOCRpip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
pip install -U "paddleocr[doc-parser]"
pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl2️⃣ 命令行使用:
paddleocr doc_parser -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_ocr_vl_demo.png
https://./cli.webphttps://./cli.webp3️⃣ Python API 调用:
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL()
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_ocr_vl_demo.png")
for res in output:res.print()res.save_to_json(save_path="output")res.save_to_markdown(save_path="output")4️⃣ 基于vLLM的推理加速
步骤 1. 启动 VLM 推理服务器(默认端口为 8080):
docker run \--rm \--gpusall \--network host \ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server
# 你也可以使用 ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server 作为 SGLang 服务器步骤 2. 调用 PaddleOCR Python API:
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL(vl_rec_backend="vllm-server", vl_rec_server_url="http://127.0.0.1:8080")
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_ocr_vl_demo.png")
for res in output:res.print()res.save_to_json(save_path="output")res.save_to_markdown(save_path="output")五,✅ 技术亮点总结
PaddleOCR-VL作为专为文档解析优化的0.9B参数视觉语言模型,通过动态视觉编码器与轻量语言模型的创新结合,在有限硬件资源下实现了业界领先的解析精度。
它的突出之处在于:
🌍 涵盖109种语言支持
📊 全面覆盖表格、图表、公式等复杂元素
🧠 全面覆盖表格、图表、公式等复杂元素
⚡ 以更低的计算成本超越更大的模型
✅ 输出结构化的 JSON 和 Markdown
简而言之:
PaddleOCR-VL 将前沿文档智能技术封装为紧凑、高效、多语言且可直接部署的解决方案。
🔗 探索更多
📦 GitHub:
https://github.com/PaddlePaddle/PaddleOCR
🤗 Hugging Face 模型:
https://huggingface.co/PaddlePaddle/PaddleOCR-VL
🚀 在线体验:
https://aistudio.baidu.com/application/detail/98365
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!