Data Warehouse简介
目录
引入数据仓库
数据仓库定义
数据仓库的特征
数据仓库与数据库的区别
数据仓库分层架构
为什么要分层?
分层架构
ETL和ELT
引入数据仓库
以前数据库既要支撑业务也要勉强承担分析工作;企业各部门“各自为战”,每个部门的业务系统都有独立的数据库,服务于单一业务场景。这给整体数据的使用带来一些问题:
1、数据孤岛。各部门数据不互通,想做跨业务分析需要手动整合,耗时还容易出错;
2、口径混乱。没有统一的数据定义标准,每个部门会按自己的理解统计数据,最终导致数据打架,无法基于数据做决策;
3、分析与业务抢资源。分析的要求是全,而业务的目标是快,数据库会优先保障分析操作,导致用户卡顿甚至报错;
4、业务系统为了保证运行速度,只存短期业务数据(近3个月,超出会删除或归档到冷存储,取数时间慢),无法满足对历史数据存储和分析的需求。
为了解决这些问题,需要一个能整合全量数据、与业务系统隔离、统一数据标准、长期存储历史数据的专用平台,而数据仓库就做到了这些点。
数据仓库定义
数据仓库(简称“数仓”)是为企业统一存储、整合数据并支持决策分析而设计的专用数据平台。为了解决传统分散业务系统无法高效支持数据分析的问题。它不生产数据也不消费数据。
数据仓库的特征
面向主题:“主题”指的是企业最关心的核心业务领域,数仓会围绕这些主题,把分散在多个系统里的相关数据“打包整合”;
集成性:“集成性”是数仓打破数据孤岛的核心能力,靠ETL流程(抽取Extract—>转换Transform—>加载Load)完成,本质是把“杂乱”的数据变成“标准”的数据;
相对稳定:“相对稳定”指数据进入数仓后,很少做修改或删除操作,主要以“新增”为主。核心是为了数据逻辑清晰,不会因为后续操作而导致结果混乱;
反映历史:“反映历史”指数仓会长期存储几年甚至更长时间的全量数据,核心是为了满足企业长期趋势分析的需求
数据仓库与数据库的区别
①用途:数仓用于复杂决策分析,数据库用于实时业务操作;
②组织:数仓按业务主题整合数据,数据库按业务系统划分数据;
③存储:数仓长期存储全量数据,数据库存储短期数据;
④更新:数仓主要是新增数据很少修改,数据库增删改查频繁;
⑤设计目标:数仓要求快速处理海量数据的复杂计算,数据库确保用户操作秒级响应。
常用软件:数仓常用Hive、ClickHouse,数据库常用MySOL、Oracle
数据仓库分层架构
数仓分层架构不是 “建好就一成不变” 的静态结构,而是会随着业务发展、技术迭代、数据量增长持续变化和维护,是为了让数仓始终适配企业的实际需求,避免成为 “僵化的架子”。
为什么要分层?
主要是为了解耦、复用和问题可追溯
1、如果不分层,直接把业务系统的原始数据和清洗后的数据存一起会导致:
①数据异常时无法分清是原始数据有误还是后续加工错误,无法回查;
②如果直接在原始数据上修改,后续没有干净的原始数据可用,只能再次从业务系统同步,而且重复开发严重,浪费资源;
2、如果不分层,直接把原始数据一步到位会导致:
①SQL代码冗长,容易出错还不好排查;
②业务需求频繁变化时,修改会频繁牵一发而动全身;
分层架构
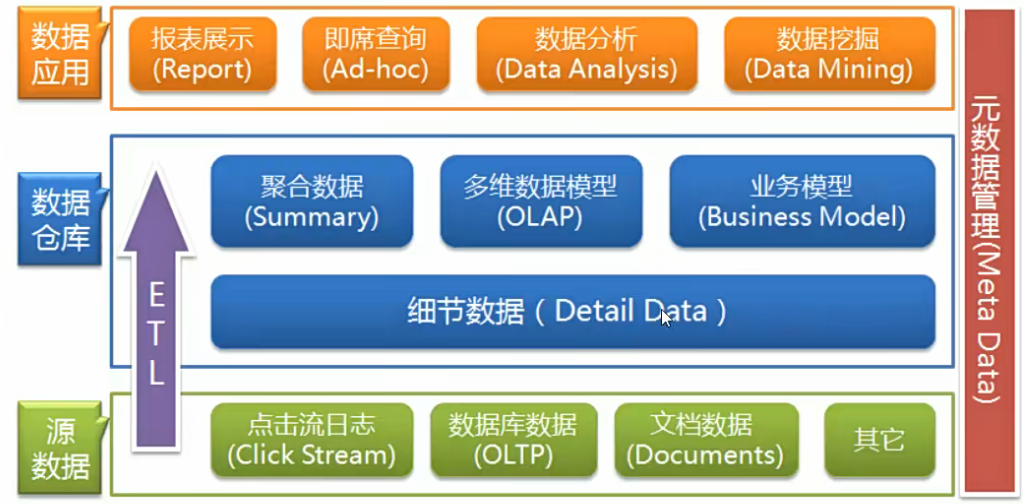
三层架构
最基础的架构。按数据流向分为三层:源数据层(Operational Data Store:ODS)、数据仓库层(Data Warehouse:DW)、数据集市层(Data Mart:DM)
ODS层:直接对接业务系统,存储原始数据,是数仓的数据入口;
DW层:核心层,对ODS层数据进行清洗、整合、建模,把杂乱的原始数据变成规范的可用数据;
DM层:面向具体业务部门的“专用数据子集”,直接对接前端分析工具(如PowerBI)或业务系统,让业务人员/分析人员能快速拿到直观的数据。
四层架构
最常见的架构,适合业务复杂、数据量大的场景。四层架构的ODS层和DM层和三层架构的一致只是把DW层分为了数据明细层(Data Warehouse Detail:DWD)和数据汇总层(Data Warehouse Service:DWS)
DWD层:清洗数据,并标准化。处理ODS层的脏数据,同时按业务含义拆分数据,保留最细粒度的明细数据;
DWS层:在DWD层明细数据基础上,按“业务主题”整合数据,并做轻度汇总(不做最终整合,保留一定粒度),为后续分析提供统一的汇总数据,减少重复计算。
ETL和ELT
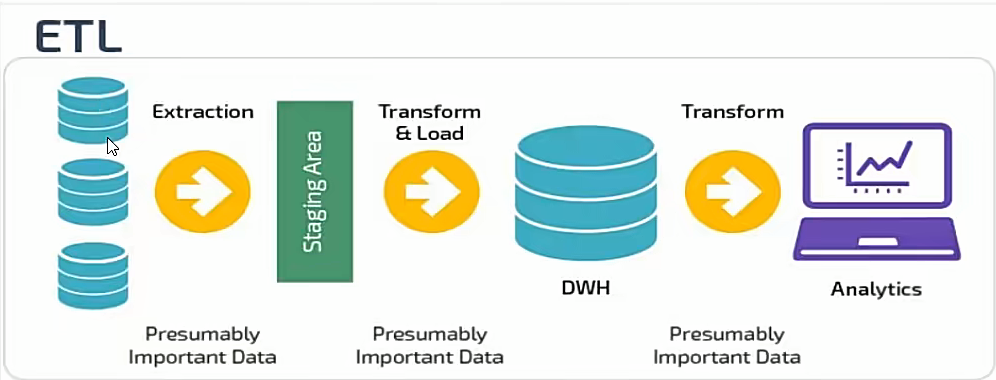
传统数仓的ETL适合数据量小、需求稳定、以结构化数据为主的业务场景(如银行)
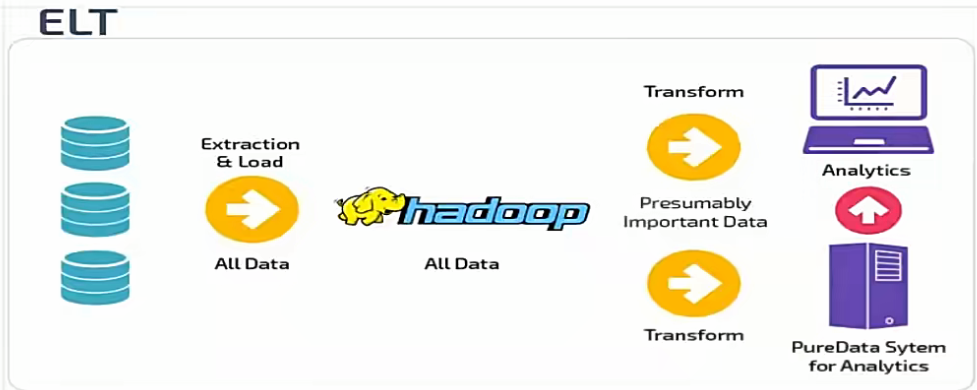
大数据ELT适合数据量大、需求多变、多源异构数据的场景(如电商、互联网)
ETL流程是:抽取原始数据后,在数仓外部的专用ETL工具中完成转换,再将数据加载到数仓中。其中转换过程依赖工具的计算能力,数仓主要承担存储和查询角色;
而ELT流程是:抽取原始数据后,直接将其加载到数仓的底层(如HDFS、数据湖),利用数仓自身的分布式计算能力(如Spark SQL),在数仓内部完成转换。
实际工作中,很多企业会采用 “混合模式”:结构化的核心业务数据用 ETL 保证准确性,非结构化的海量数据用 ELT 保证灵活性。