深度学习打卡第TR5周:Transformer实战:文本分类
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
目录
一、准备工作
二、数据预处理
2.1 构建词典
2.2 生成数据批次和迭代器
2.3 构建数据集
三、模型构建
3.1 定义位置编码函数
3.2 定义transformer模型
3.3 定义模型训练和评估函数
四、模型训练
一、准备工作
import torch
from torch import nn
import torchvision
from torchvision import transforms,datasets
import os,PIL,pathlib,warningswarnings.filterwarnings("ignore") # 忽略警告信息device = torch.device("cuda" if torch.cuda.is_available else "cpu")
deviceimport pandas as pdtrain_data = pd.read_csv('./data/TR5/train.csv',sep='\t',header=None)
train_data.head()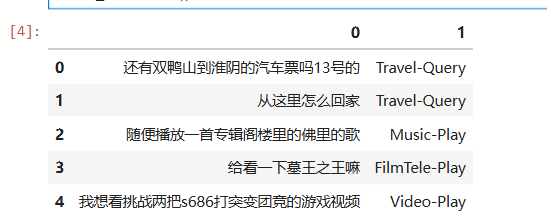
# 构造数据集迭代器
def custom_data_iter(texts,labels):for x,y in zip(texts,labels):yield x,ytrain_iter = custom_data_iter(train_data[0].values[:],train_data[1].values[:])二、数据预处理
2.1 构建词典
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba# 中文分词方法
tokenizer = jieba.lcutdef yield_tokens(data_iter):for text,_ in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter),specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])label_name = list(set(train_data[1].values))
text_pipeline = lambda x:vocab(tokenizer(x))
label_pipeline = lambda x:label_name.index(x)2.2 生成数据批次和迭代器
from torch.utils.data import DataLoader
def collate_batch(batch) :label_list, text_list,offsets = [],[],[0]for (_text,_label) in batch:#标签列表label_list.append( label_pipeline(_label))#文本列表processed_text = torch.tensor(text_pipeline(_text),dtype=torch.int64)text_list.append(processed_text)#偏移量,即语句的总词汇量offsets.append( processed_text.size(0))label_list = torch.tensor(label_list,dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[ :-1]).cumsum(dim=0)#返回维度dim中输入元素的累计和return text_list.to(device),label_list.to(device),offsets.to(device)2.3 构建数据集
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_datasetBATCH_SIZE = 4
train_iter = custom_data_iter(train_data[0].values,train_data[1].values)
train_dataset = to_map_style_dataset(train_iter)split_train,split_valid = random_split(train_dataset,[int(len(train_dataset)*0.8),int(len(train_dataset)*0.2)])train_dataloader = DataLoader(split_train,batch_size=BATCH_SIZE,shuffle=True,collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid,batch_size=BATCH_SIZE,shuffle=True,collate_fn=collate_batch)三、模型构建
3.1 定义位置编码函数
import math, os, torch
import torch.nn as nnclass PositionalEncoding(nn.Module):def __init__(self, embed_dim, max_len=500):super(PositionalEncoding, self).__init__()# 创建一个大小为 [max_len, embed_dim] 的零张量pe = torch.zeros(max_len, embed_dim)# 创建一个形状为 [max_len, 1] 的位置索引张量position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, embed_dim, 2).float() * (-math.log(100.0) / embed_dim))pe[:, 0::2] = torch.sin(position * div_term) # 计算 PE(pos, 2i)pe[:, 1::2] = torch.cos(position * div_term) # 计算 PE(pos, 2i+1)pe = pe.unsqueeze(0).transpose(0, 1)# 将位置编码张量注册为模型的缓冲区,参数不参与梯度下降,保存model的时候会将其保存下来self.register_buffer('pe', pe)def forward(self, x):# 将位置编码添加到输入张量中,注意位置编码的形状x = x + self.pe[:x.size(0)]return x3.2 定义transformer模型
from tempfile import TemporaryDirectory
from typing import Tuple
from torch import nn, Tensor
from torch.nn import TransformerEncoder, TransformerEncoderLayer
from torch.utils.data import Datasetclass TransformerModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class, nhead=8, d_hid=256, nlayers=12, dropout=0.1):super().__init__()self.embedding = nn.EmbeddingBag(vocab_size, # 词典大小embed_dim, # 嵌入的维度sparse=False) # self.pos_encoder = PositionalEncoding(embed_dim)# 定义编码器层encoder_layers = TransformerEncoderLayer(embed_dim, nhead, d_hid, dropout)self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)self.embed_dim = embed_dimself.linear = nn.Linear(embed_dim*4, num_class)def forward(self, src, offsets, src_mask=None):src = self.embedding(src, offsets)src = self.pos_encoder(src)output = self.transformer_encoder(src, src_mask)output = output.view(4, self.embed_dim*4)output = self.linear(output)return outputvocab_size = len(vocab) # 词汇表的大小
embed_dim = 64 # 嵌入维度
num_class = len(label_name)# 创建 Transformer 模型,并将其移动到设备上
model = TransformerModel(vocab_size,embed_dim,num_class).to(device)3.3 定义模型训练和评估函数
import timedef train(dataloader):model.train() # 切换为训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 300start_time = time.time()for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad() # grad属性归零loss = criterion(predicted_label, label) # 计算网络输出和真实值之间的差距,label为真实值loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:1d} | {:4d}/{:4d} batches ''| train_acc {:.3f} train_loss {:.5f}'.format(epoch, idx, len(dataloader),total_acc/total_count, train_loss/total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换为测试模式total_acc, train_loss, total_count = 0, 0, 0with torch.no_grad():for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 计算loss值# 记录测试数据total_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)return total_acc/total_count, train_loss/total_count四、模型训练
import time
import torch# 超参数
EPOCHS = 10criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']print('-' * 69)print('| epoch {:1d} | time: {:4.2f}s | ''valid_acc {:4.3f} valid_loss {:4.3f} | lr {:4.6f}'.format(epoch,time.time() - epoch_start_time,val_acc, val_loss, lr))print('-' * 69)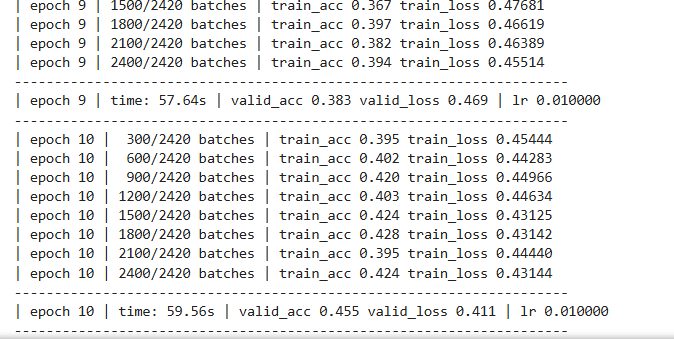
test_acc, test_loss = evaluate(valid_dataloader)
print('模型准确率为:{:5.4f}'.format(test_acc))![]()