什么是索引下推?
索引下推是MySQL5.6出现的优化手段,一般在联合索引中出现,对于失效的联合索引字段,在存储引擎层仍会进行条件筛选。如果没有索引下推,失效的联合索引字段并不会在存储引擎层筛选,而是返回到server层进行二次筛选。
要理解索引下推,首先知道MySQL架构分层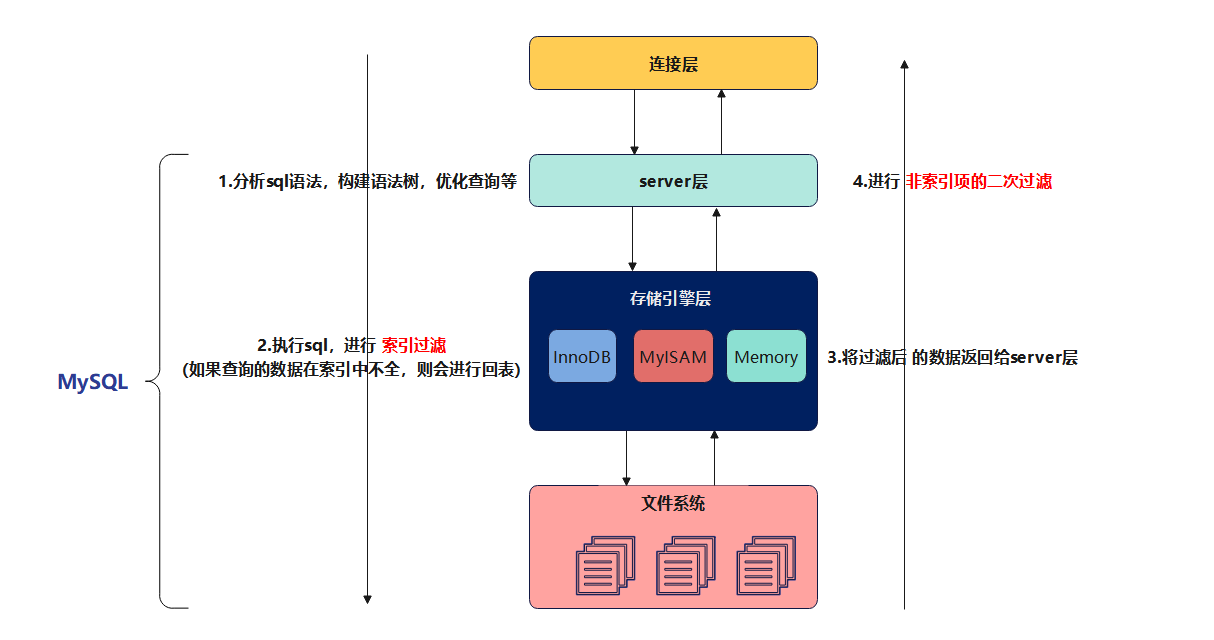
可以看到在索引层按照索引的匹配规则过滤了一次,在server层又按照非索引字段过滤了一次
现有user表
create table `user`(
id bigint primary key auto_increment,
name varchar(16) not null ,
age int not null ,
address varchar(128),
index(name, age)
);
insert into
user(name, age, address)
values
( 'zs', 18, '苏州'),
('zz', 19, '杭州'),
('jack', 20,'深圳');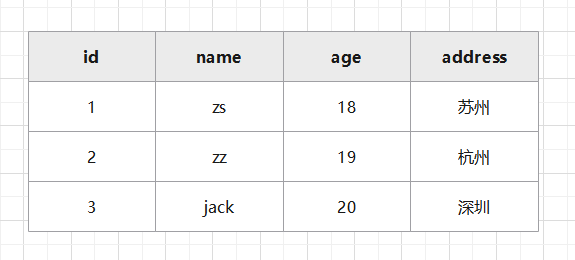
要查询name以z开头,age=18岁的人,查询语句如下:
select * from user where name like 'z%' and age=18在MySQL5.6之前 不走索引下推的情况
这里由于第一个字段name并不是等值匹配(不满足左匹配原则),因此age字段索引失效,无法走索引,在引擎层只能按照name进行过滤,然后通过回表查询出其他字段,age会在server层二次过滤,如图:
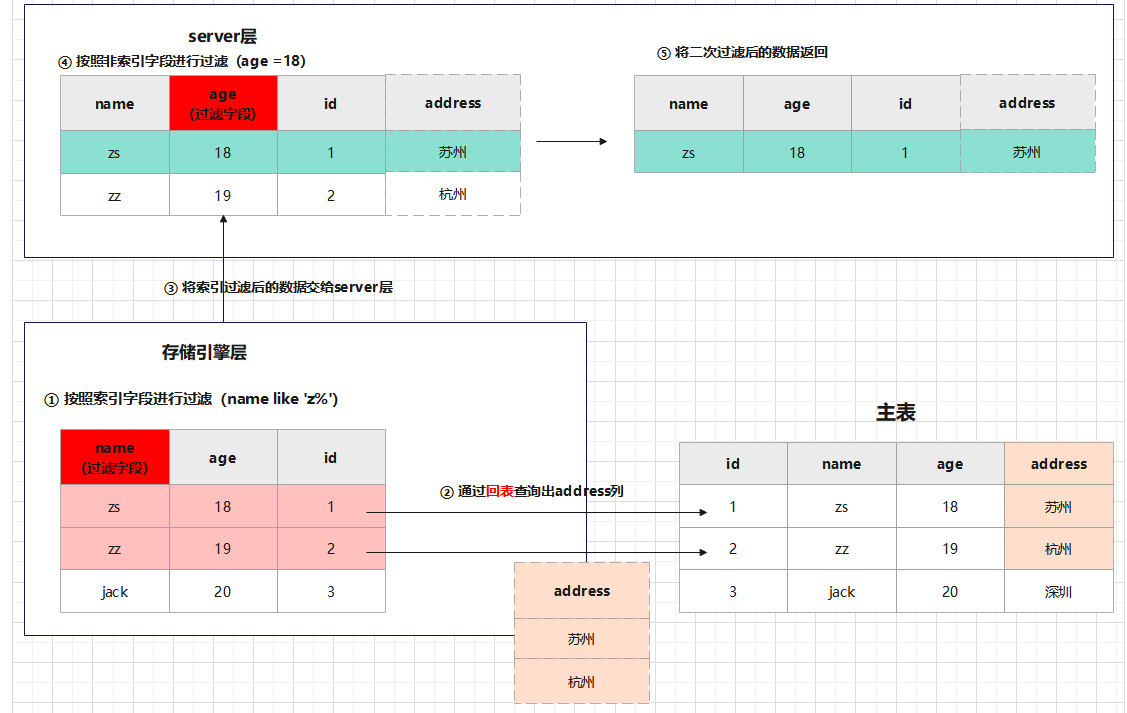
可以看到age字段是在server层过滤的,并且存储引擎层进行了两次回表
MySQL5.6之后 走索引下推的情况

可以看到在引擎层将失效的索引age也进行了过滤(将本应是上层server层过滤的条件下推到了引擎层,因此叫索引条件下推),并且只进行了一次回表,返回的数据量也变少了
结论:
① 索引下推情况下将失效的索引也会在引擎层进行筛选
② 索引下推能减少回表次数,提高查询效率
③ 索引下推能减少传输的数据量,减少IO