【多模态】46、DeepSeek-OCR | 一张图片是否真能抵千词

论文:DeepSeek-OCR: Contexts Optical Compression
代码:https://github.com/deepseek-ai/DeepSeek-OCR
出处:DeepSeek-AI
时间:2025.10
一、背景
当前大型语言模型(LLM)在处理长文本时面临计算复杂度高的问题(序列长度的平方级增长),所以该方法探索视觉模态在文本压缩中的潜力,验证“一张图片是否真能抵千词”(高压缩比下保持文本解码精度)。
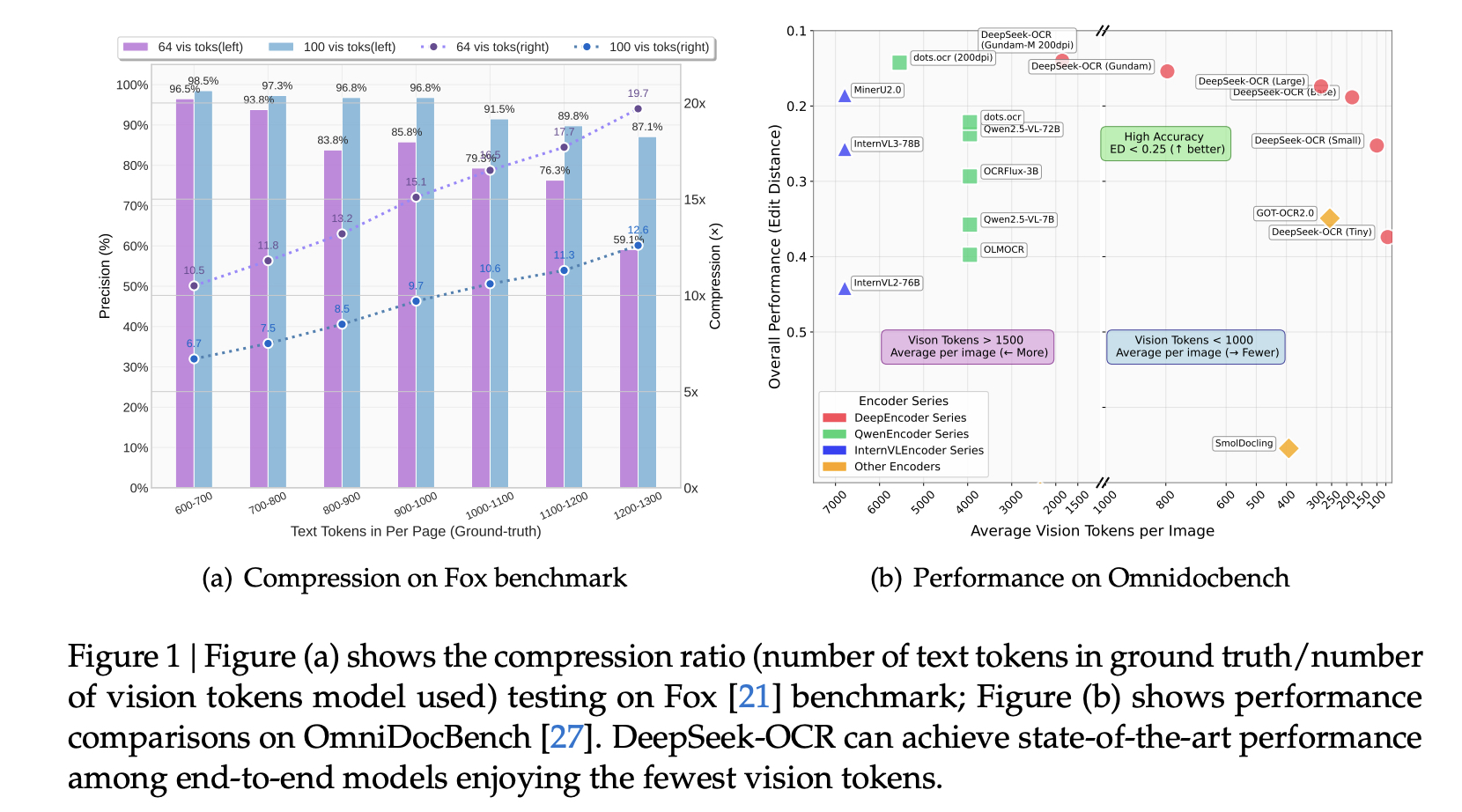
二、方法
DeepSeek-OCR提出了DeepEncoder,专门解决现有视觉编码器的痛点:高分辨率输入时token过多、激活内存大、不支持多分辨率等。

具体处理流程:
- 输入图片1024x1024
- 切分为16x16的patch,共4096patch token
- 送入SAM(80M,不参与训练)进行local attention,输出还是4096token
- 送入压缩卷积将4096token降维到256token(重点!)
- 压缩后的token送入 CLIP-large(300M,训练,去掉第一层patch嵌入层,直接输入压缩后的token),通过全局注意力提取全局信息
- 将CLIP的输出送入 DeepSeek-3bA570M,训练
特点:
- 支持高分辨率输入(如 1024×1024)且保持低激活内存。
- 动态多分辨率支持(Tiny/Small/Base/Large/Gundam 模式),适应不同压缩比需求。
- 通过位置编码插值实现灵活输入尺寸调整。
三、数据集
数据配比:OCR : general vision : text-only = 70% :20%:10%
1、OCR1.0数据:包括图片OCR和文档OCR
-
图片OCR:
- 收集 LAION/Wukong等,使用PaddleOCR打标,中英各1000万
-
文档OCR:
- 包括3000万PDF页面(包括100种语言,2500万是中英文、500万是其他语言)
- 处理方式:
- ①粗糙处理:使用 fitz 提取全文信息
- ②精细处理:借助版面检测模型(PP-DocLayout)进行版面切割,然后用OCR模型(MinuerU和GOT-OCR2.0)进行识别
- 粗糙处理和精细处理的数据会使用不同的prompt用于训练
2、OCR2.0数据:图表、化学公式、平面几何
- 图表数据:借鉴OneChart,使用pyecharts和matplotlib渲染 1000 万图片,主要包括 line、bar、pie、composite charts。
- 化学式数据:使用来自PubChem的SMILES格式作为数据来源,并通过RDKit将其渲染为图像,构建500万条图像-文本对
- 平面几何数据:参考 Slow Perception 进行生成,共构建100万平面几何数据。
3、通用视觉数据:caption、detection、grounding
- 因为 DeepSeek-OCR不是锚定通用模型的,所以只加了20%的该类数据参与训练,只是为了保留一些通用视觉理解能力。
4、纯文本数据:为了保留模型语言能力,加入了 10% 的 in-house text-only 数据
四、训练方式
两阶段训练方式:
- stage1:只训练训练 DeepEncoder,冻结语言模型
- stage2:全流程训练DeepSeek-OCR
1.4.1 stage1
数据:使用所有 OCR1.0 和 OCR2.0 数据,从LAION 中随机选出 1亿 通用数据
训练超参数:2epoch,batch 1280,AdamW,lr=5e-5,长度=4096
1.4.2 stage2
训练模式:训练由4部分流水线训练(pipeline parallelism,PP)组成,前两部分训练 DeepseekEncoder(SAM+压缩器冻结,CLIP训练),后两部分训练语言模型
五、效果展示
对指令跟随能力一般,下面展示几个支持的典型场景和prompt
1、全文分块定位+识别
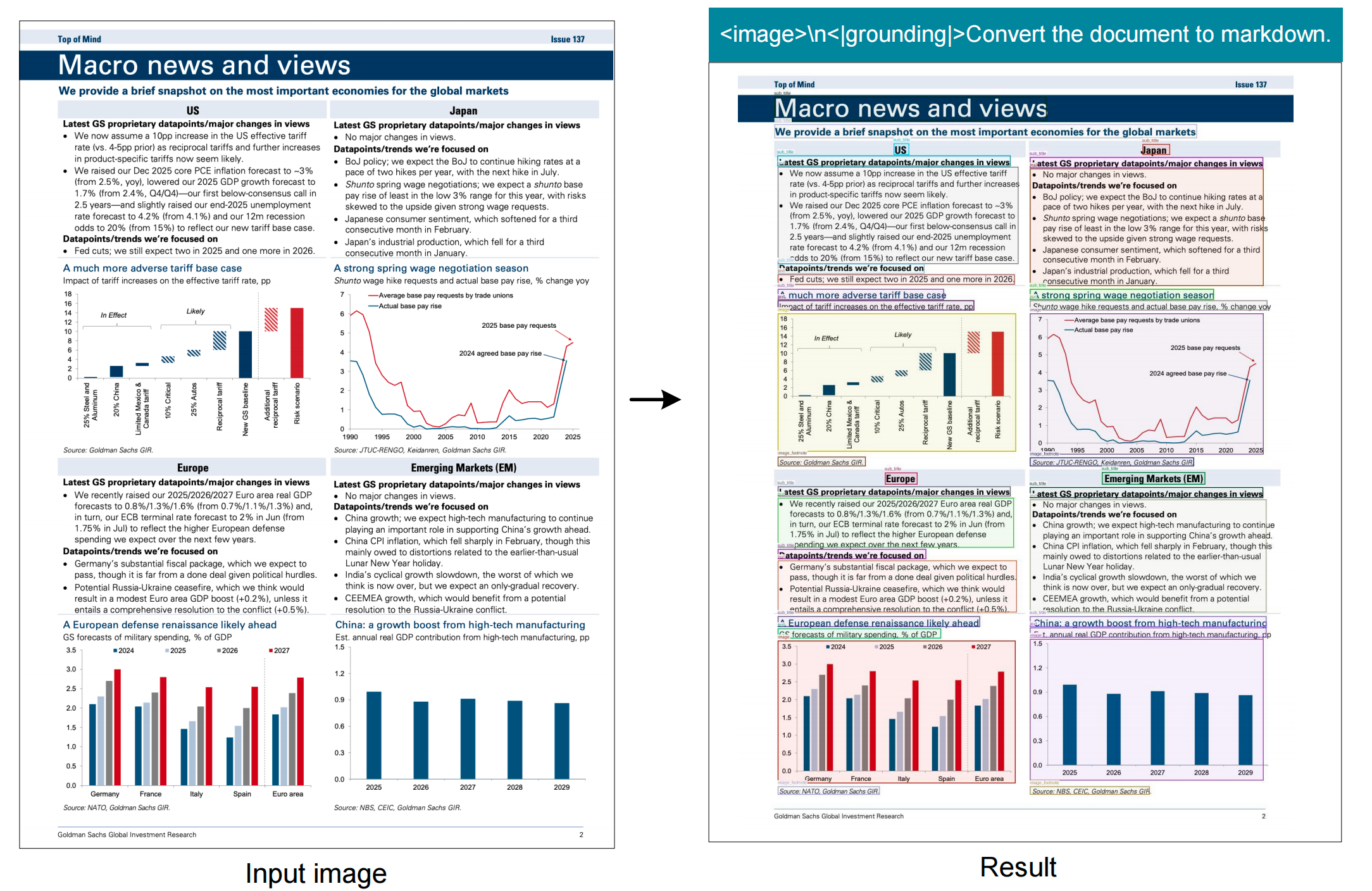
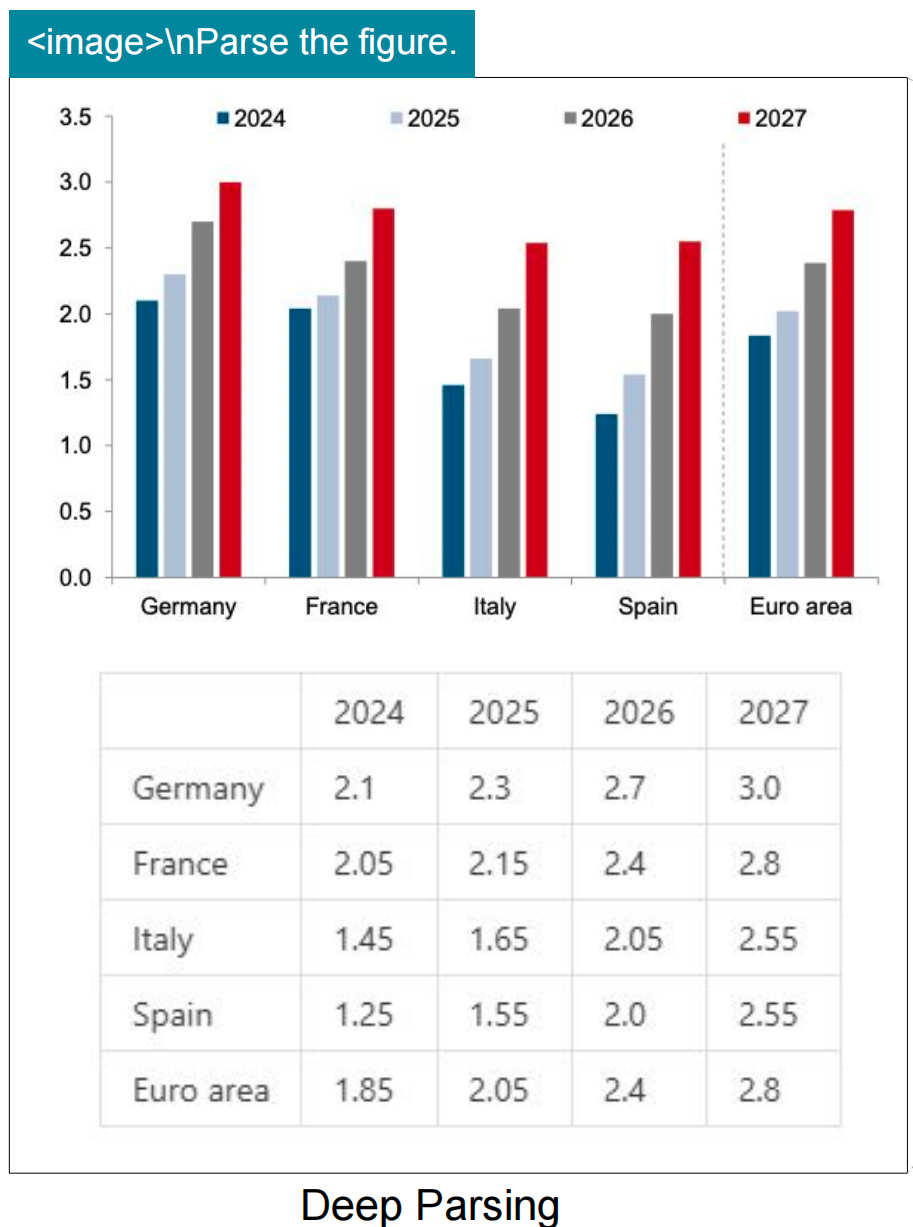
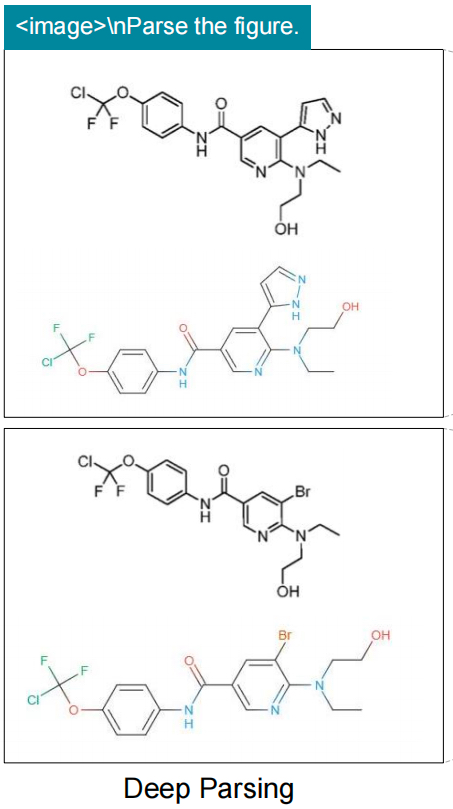
2、表格解析、配图理解

3、文本定位、目标定位任务
