网站seo搜索引擎优化案例千牛怎么做免费推广引流
二、pandas数据分析库
5、DataFrame的分析统计
在DataFrame中,我们有很多的函数可以对二维表格进行数据的分析:
比如我们可以对二维表格进行转置操作:
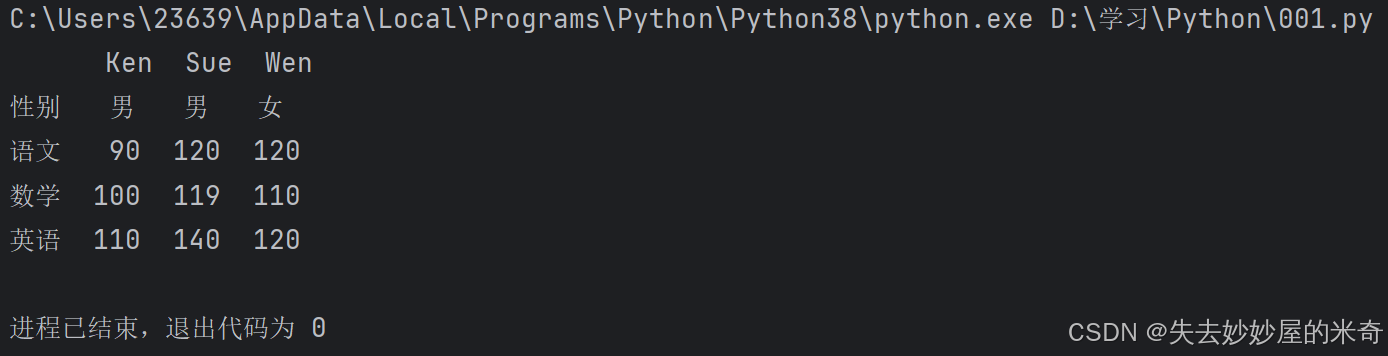
import pandas as pdpd.set_option("display.unicode.east_asian_width" , True) #这一行的作用是防止中文字符的宽度导致表格显示错误scores = [['男',90,100,110] , ['男',120,119,140] , ['女',120,110,120]]
names = ["Ken" , "Sue" , "Wen"]
courses = ["性别" , "语文" , "数学" , "英语"]df = pd.DataFrame(data = scores , index = names , columns = courses) #先用DataFrame创建一个函数,里面分别是二维表格的数据,行标签,列标签#————————————————————————以上是创建了一个二维表格————————————————————————print(df.T)输出:
我们也可以对数据进行分析排序运算:
import pandas as pdpd.set_option("display.unicode.east_asian_width" , True) #这一行的作用是防止中文字符的宽度导致表格显示错误scores = [['男',90,100,110] , ['男',120,119,140] , ['女',120,110,120]]
names = ["Ken" , "Sue" , "Wen"]
courses = ["性别" , "语文" , "数学" , "英语"]df = pd.DataFrame(data = scores , index = names , columns = courses) #先用DataFrame创建一个函数,里面分别是二维表格的数据,行标签,列标签#————————————————————————以上是创建了一个二维表格————————————————————————df.drop('性别' , axis = 1 , inplace = True) #删除性别那一列,因为字符串无法进行下面的计算print(df.sort_values("数学" , ascending=False)) #按照数学的降序排序print(df.sum()["语文"] , df.mean()["数学"] , df.median()["英语"]) print(df.max()["数学"]) #求数学标签下的数据的最大值print(df.max(axis=1)["Sue"]) #求Sue的最高分print(df["英语"].idxmax()) #求英语科目的最高分输出:

6、DataFrame的增删查看操作
import pandas as pdpd.set_option("display.unicode.east_asian_width" , True) #这一行的作用是防止中文字符的宽度导致表格显示错误scores = [['男',90,100,110] , ['男',120,119,140] , ['女',120,110,120]]
names = ["Ken" , "Sue" , "Wen"]
courses = ["性别" , "语文" , "数学" , "英语"]df = pd.DataFrame(data = scores , index = names , columns = courses) #先用DataFrame创建一个函数,里面分别是二维表格的数据,行标签,列标签#————————————————————————以上是创建了一个二维表格————————————————————————df.drop('性别' , axis = 1 , inplace = True) #删除性别那一列df.loc["Sue" , "英语"] = df.iloc[1,1] = 150 #修改Sue的英语成绩和Ken的语文成绩,让这两个都是150分pd.set_option("display.unicode.east_asian_width" , True)
df["性别"] = ['男' , '男' , '女' ]df.loc[: , '语文'] += 5 #所有人语文加5分print(df)输出:

三、pandas与Excel文档
1、pandas读取Excel文档
pandas功能强大,我们可以用它来读取一个Excel文档,在读取的时候,对于pandas,每一张工作表就是一个DataFrame。
我们来看一个简单的例子:
我们先在执行代码的当前目录下,创建一个Excel表格,里面包含以下内容:

然后我们在代码中写入:
import pandas as pdpd.set_option('display.unicode.east_asian_width' , True) #防止表格格式出现错乱
dt = pd.read_excel("001.xlsx" , sheet_name = ['Sheet1' , 1] , index_col = 0) #pd.read_excel()函数用于读取一个Excel文档,里面的三个参数分别是:想要打开的文件名,要打开文件的哪个工作表,以及把第0列当作DataFrame的索引
#注:pd.read_excel()函数返回的是一个字典,里面包含若干键值对,键就是工作表的名称或索引,值就是DataFrame
#在sheet_name这个参数中,我们可以选择多个工作表来打开,上面的例子就是打开名字是Sheet1和索引是1(也就是第二个表)
df = dt['Sheet1'] #从代码中取出键是Sheet1的键值对的值,把值赋给dfprint(df)输出:

(若表格为空,输出就显示NaN)
2、pandas查询修改Excel文档
在pandas中,我们可以用下标来查询某一个数据,也可以用行列的索引:
import pandas as pdpd.set_option('display.unicode.east_asian_width' , True) #防止表格格式出现错乱
dt = pd.read_excel("001.xlsx" , sheet_name = ['Sheet1' , 1] , index_col = 0) df = dt['Sheet1'] print(df.iloc[0,0] , df.loc['张三' , '身高'])
#用下标查询的话,注意这个是只包含数据的,不包含那些行列索引的数据,比如df.iloc[0,0]输出的是2025001,而不是姓名!!!输出:

我们还可以用isnull函数来判断某一个表示是不是空的:
#接上面程序
print(pd.isnull(df.loc["赵六" , "成绩"]))
print(pd.isnull(df.loc["张三" , "成绩"]))输出:

我们也可以用fillna函数,来替换某些数值:
#接上面程序
df.fillna(0 , inplace = True)
print(df)输出:

3、用pandas写Excel文档
import pandas as pdpd.set_option('display.unicode.east_asian_width' , True) #防止表格格式出现错乱
dt = pd.read_excel("001.xlsx" , sheet_name = ['Sheet1' , 1] , index_col = 0)df = dt['Sheet1']with pd.ExcelWriter("new.xlsx", engine="openpyxl") as writer: #创建一个writer对象,用pd.ExcelWriter函数来同时创建多张表的,里面的两个参数分别是指出文件的名字以及用openpyxl来处理Excel我呢见df.to_excel(writer , sheet_name = "S1")#把df的DataFrame拿出来,放到新文件里面的一个名字是S1的表格中df.T.to_excel(writer , sheet_name = "S2")#多了一个T,就是转置的意思,即行列互换df.sort_values("成绩" , ascending=False).to_excel(writer , sheet_name = "S3")#根据成绩的降序来排列再输出新的列表df['身高'].to_excel(writer , sheet_name = "S4")#只拿df中的身高这一列的数据来做一个新的表格结果:
我们可以在代码的当前目录下得到一个新的Excel文档,里面包含了四个表格:




从上到下分别是S1、S2、S3、S4
注:有的地方可能会把with部分的代码这么写:
writer = pd.ExcelWriter("new.xlsx")
df.to_excel(writer , sheet_name = "S1")
df.T.to_excel(writer , sheet_name = "S2")
df.sort_values("成绩" , ascending=False).to_excel(writer , sheet_name = "S3")
df['身高'].to_excel(writer , sheet_name = "S4")
writer.save()这种方法在旧版本的pandas库上是可行的,如果在新的库中输入这个,会报错
新的with...as语句可以自动保存,更加便利!
四、pandas与csv文件
1、啥是csv文件
csv文件是一种常见的文本格式,用于存储表格数据,是一个以.csv为后缀的文件,它广泛应用于数据交换、存储和处理场景,尤其是在需要轻量级和通用性的情况下。
2、用pandas创建一个csv文件
import pandas as pdpd.set_option('display.unicode.east_asian_width' , True) #防止表格格式出现错乱
dt = pd.read_excel("001.xlsx" , sheet_name = ['Sheet1' , 1] , index_col = 0)df = dt['Sheet1']df.to_csv("result.csv" , sep = "," , na_rep = 'NA' , float_format = "%.2f" , encoding = "gbk")
#df.to_csv就是把df的DataFrame存到一个csv文件中,里面的各个参数是指:①文件名②sep指定字段之间的分隔符③把表格中空的格子变成NA④把浮点数保留小数点后两位⑤指定文件的编码格式输出:
我们会在当前目录下得到一个result.csv的文件打开后如下:

3、用pandas读取一个csv文件
import pandas as pddf = pd.read_csv("result.csv", encoding="gbk")
print(df)输出:

注意