性能测试-jmeter16-性能环境搭建、脚本编写、测试数据构造
课程:B站大学
记录软件测试-性能测试学习历程、掌握前端性能测试、后端性能测试、服务端性能测试的你才是一个专业的软件测试工程师
性能测试
- 性能脚本编写
- 性能测试环境搭建
- 1. 建立测试环境
- 1.1 性能测试环境的特点
- 1.2 如何保证测试环境与生产环境的一致性
- 2. 如何构造百万级别的测试数据呢?
- 使用 CSV + LOAD DATA INFILE 方式构造并导入百万级商品数据到 MySQL
- 1、整体流程
- 创建数据表结构(插入sql语句):
- ✅ 步骤 1:用 Python 生成 CSV 文件(10 万条商品数据:generate_goods_csv.py)
- ✅ 步骤 2:将 CSV 文件放到 MySQL 服务端可访
- 重启 MySQL 服务
- sql批量导入csv数据到mysql数据表中
- ✅ 步骤 4:验证导入结果
- 实践是检验整理的唯一标准
性能脚本编写
JMeter 业务流程脚本编写简要流程
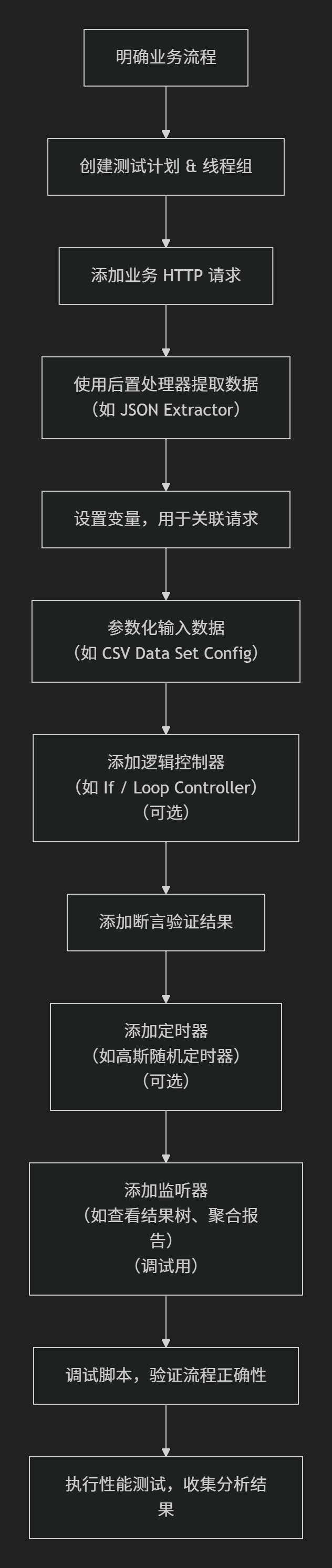
- 明确业务流程
确定要模拟的用户操作流程(如:登录 → 浏览 → 加购 → 下单 → 支付)。 - 创建测试计划 & 线程组
在 JMeter 中创建 Test Plan,在其下添加 Thread Group,设置并发用户数、循环次数等。
- 添加业务流程请求(HTTP Request)
按业务顺序添加多个 HTTP 请求,每个请求对应一个业务步骤(如登录接口、商品查询接口等)。 - 处理关联(数据传递)
使用 后置处理器(如 JSON Extractor) 从响应中提取关键数据(如 token、orderId),存为变量,供后续请求使用。 - 参数化输入
使用 CSV Data Set Config 或函数,为不同用户/场景提供动态数据(如用户名、商品ID)。 - 添加逻辑控制(可选)
使用 逻辑控制器(如 If Controller、Loop Controller) 控制流程分支或循环逻辑。 - 添加断言
验证每个关键请求的响应是否符合预期(如状态码 200、返回字段正确)。
- 添加定时器(可选)
模拟用户操作间隔,如 高斯随机定时器。
- 添加监听器(调试用)
如 查看结果树、聚合报告,用于调试与性能分析(正式压测时可关闭部分监听器)。 - 调试与执行测试
先小规模调试脚本,验证流程正确性;再执行正式性能测试,收集性能数据。
性能测试环境搭建
1. 建立测试环境
• 在进行性能测试之前,需要先完成性能测试环境的搭建工作,测试环境一般包括硬件环境、软件环境及网络环境。
• 一般情况下可以要求运维和开发工程师协助完成。
1.1 性能测试环境的特点
- 性能测试对测试环境的独立性要求更高,更为严格。如果某环境下运行多个系统,就很难判断其中的某个环境对资源的占用情况。
- 尽量保持性能测试环境与真实生产环境的一致性。
1.2 如何保证测试环境与生产环境的一致性
如何达成性能测试环境与生产环境一致:
• 硬件环境——找运维人员申请
• 软件环境——所有的软件版本和配置可以找开发人员要,然后自己安装
• 使用场景一致性
• 测试数据:需要测试自己构造(通过python脚本构造相同数量级的数据)
• 业务场景:通过需求分析和运营数据获取主要的业务操作和对应的并发指标
2. 如何构造百万级别的测试数据呢?
使用 CSV + LOAD DATA INFILE 方式构造并导入百万级商品数据到 MySQL
1、整体流程
- 先创建对应的mysql表结构
- 用 Python 生成 CSV 文件(包含 10 万~100 万条商品数据)
- 将 CSV 文件放到 MySQL 服务端可访问的目录
- 使用 MySQL 的 LOAD DATA INFILE命令高速导入
- 验证数据是否导入成功
前提条件:
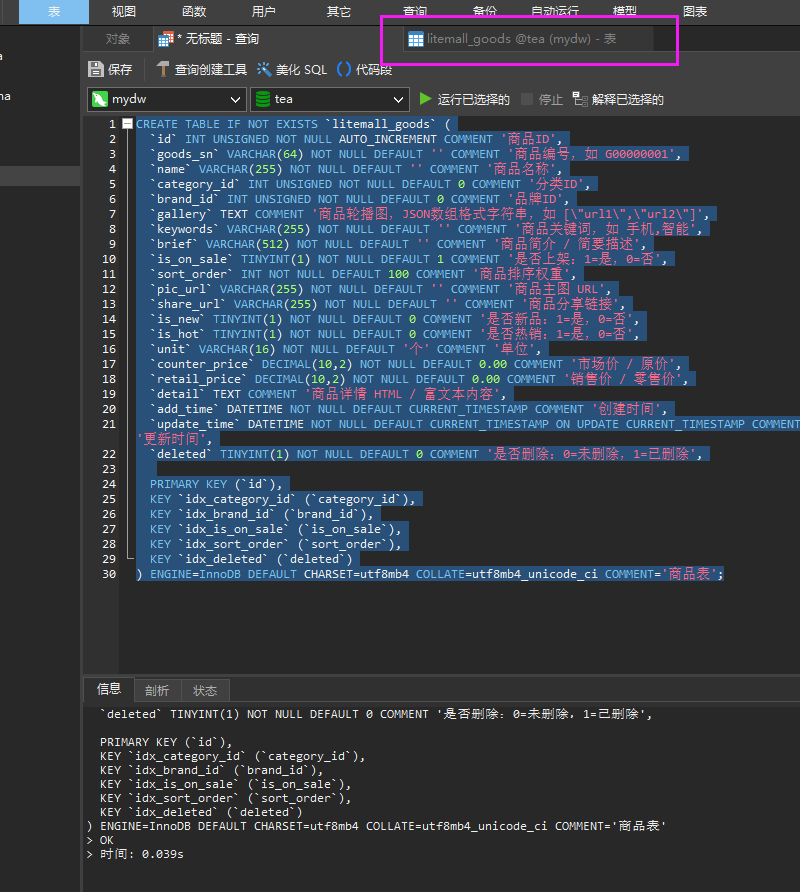
创建数据表结构(插入sql语句):
CREATE TABLE IF NOT EXISTS `litemall_goods` (`id` INT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '商品ID',`goods_sn` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '商品编号,如 G00000001',`name` VARCHAR(255) NOT NULL DEFAULT '' COMMENT '商品名称',`category_id` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '分类ID',`brand_id` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '品牌ID',`gallery` TEXT COMMENT '商品轮播图,JSON数组格式字符串,如 [\"url1\",\"url2\"]',`keywords` VARCHAR(255) NOT NULL DEFAULT '' COMMENT '商品关键词,如 手机,智能',`brief` VARCHAR(512) NOT NULL DEFAULT '' COMMENT '商品简介 / 简要描述',`is_on_sale` TINYINT(1) NOT NULL DEFAULT 1 COMMENT '是否上架:1=是,0=否',`sort_order` INT NOT NULL DEFAULT 100 COMMENT '商品排序权重',`pic_url` VARCHAR(255) NOT NULL DEFAULT '' COMMENT '商品主图 URL',`share_url` VARCHAR(255) NOT NULL DEFAULT '' COMMENT '商品分享链接',`is_new` TINYINT(1) NOT NULL DEFAULT 0 COMMENT '是否新品:1=是,0=否',`is_hot` TINYINT(1) NOT NULL DEFAULT 0 COMMENT '是否热销:1=是,0=否',`unit` VARCHAR(16) NOT NULL DEFAULT '个' COMMENT '单位',`counter_price` DECIMAL(10,2) NOT NULL DEFAULT 0.00 COMMENT '市场价 / 原价',`retail_price` DECIMAL(10,2) NOT NULL DEFAULT 0.00 COMMENT '销售价 / 零售价',`detail` TEXT COMMENT '商品详情 HTML / 富文本内容',`add_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`update_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',`deleted` TINYINT(1) NOT NULL DEFAULT 0 COMMENT '是否删除:0=未删除,1=已删除',PRIMARY KEY (`id`),KEY `idx_category_id` (`category_id`),KEY `idx_brand_id` (`brand_id`),KEY `idx_is_on_sale` (`is_on_sale`),KEY `idx_sort_order` (`sort_order`),KEY `idx_deleted` (`deleted`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='商品表';
✅ 步骤 1:用 Python 生成 CSV 文件(10 万条商品数据:generate_goods_csv.py)
在pythob环境中安装对应的包,此处我使用的anaconda虚拟环境(方便管理python的库和包)

import csv
from faker import Faker
import random
from datetime import datetime# 初始化 Faker(中文数据)
fake = Faker('zh_CN')# 商品数据生成函数
def generate_goods_csv(filename='goods_data.csv', num=100000):headers = ['id', 'goods_sn', 'name', 'category_id', 'brand_id', 'gallery','keywords', 'brief', 'is_on_sale', 'sort_order', 'pic_url','share_url', 'is_new', 'is_hot', 'unit', 'counter_price','retail_price', 'detail', 'add_time', 'update_time', 'deleted']with open(filename, mode='w', newline='', encoding='utf-8') as f:writer = csv.writer(f)writer.writerow(headers) # 写入表头for i in range(1, num + 1):goods_sn = f'G{i:08d}'name = f'商品{i}号 - {fake.word()}系列'category_id = random.randint(1, 100)brand_id = random.randint(1, 50)gallery = '[]' # 可为 JSON 字符串,如 '["url1","url2"]'keywords = f'{fake.word()},{fake.word()}'brief = fake.sentence(nb_words=8)is_on_sale = 1sort_order = random.randint(1, 1000)pic_url = f'http://example.com/pic_{i}.jpg'share_url = f'http://example.com/share_{i}'is_new = random.randint(0, 1)is_hot = random.randint(0, 1)unit = '个'counter_price = round(random.uniform(100, 1000), 2)retail_price = round(random.uniform(50, counter_price), 2)detail = f'<p>{fake.text(max_nb_chars=200)}</p>'add_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')update_time = add_timedeleted = 0writer.writerow([i, goods_sn, name, category_id, brand_id, gallery,keywords, brief, is_on_sale, sort_order, pic_url,share_url, is_new, is_hot, unit, counter_price,retail_price, detail, add_time, update_time, deleted])print(f"✅ 已生成 {num} 条商品数据到文件:{filename}")if __name__ == '__main__':generate_goods_csv('goods_data.csv', 100000) # 生成 10 万条
成功生成10万级别数据
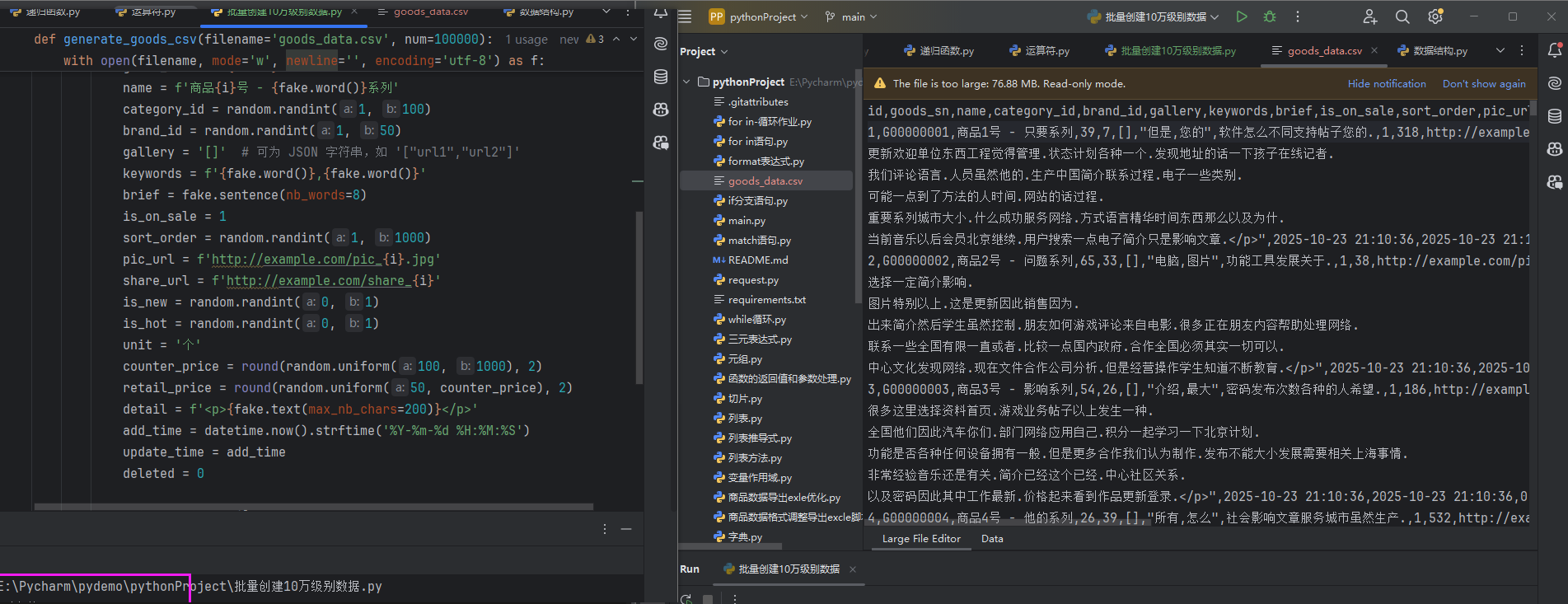
📌 运行此脚本后,会在当前目录生成一个 goods_data.csv文件,内容为 10 万条结构化的商品数据,字段与 MySQL 商品表 litemall_goods对应。
✅ 步骤 2:将 CSV 文件放到 MySQL 服务端可访
- 如果你是本地开发,且 MySQL 也在本地,直接放在如 /tmp/或
C:\temp(Windows)下即可。问目录 - 如果你是远程 MySQL 服务,需要将 CSV 文件 上传到 MySQL 服务器上,比如:
- /tmp/goods_data.csv
- 或某个 MySQL 有权限读取的目录,如 /var/lib/mysql-files/(取决于 MySQL 配置)
⚠️ 注意:LOAD DATA INFILE要求文件必须在 MySQL 服务端可读,不是你的客户端!
步骤 3:使用 MySQL 命令行导入(LOAD DATA INFILE)
- CSV 文件路径:/tmp/goods_data.csv
- 目标表:litemall_goods(请确保该表已存在,字段顺序与 CSV 一致!)
- MySQL 用户有 FILE 权限
这里本地的mysql server默认拒绝访问本地本地,故需要配置my.ini文件
- 找到 MySQL 配置文件 my.ini
MySQL 8.0 默认安装在C:\Program Files\MySQL\MySQL Server 8.0
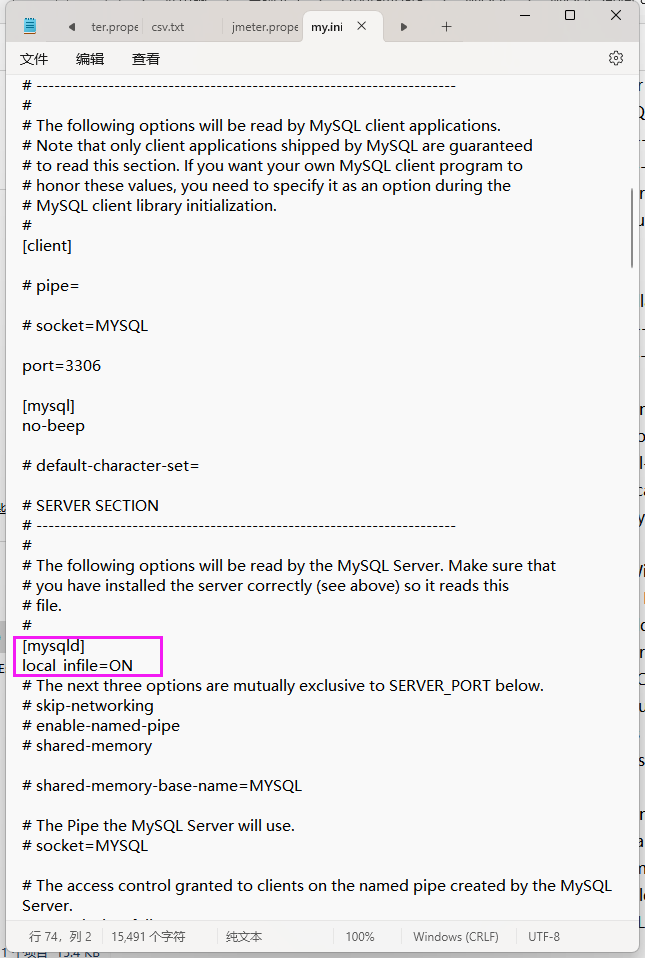
重启 MySQL 服务
- 按下 Win + R,输入:services.msc,回车
- 找到服务:MySQL80(或者你安装的版本,比如 MySQL、MySQL57 等)
- 右键 → 重新启动
sql批量导入csv数据到mysql数据表中
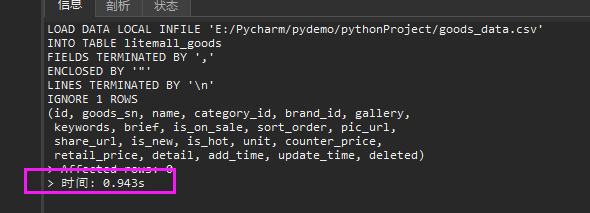
LOAD DATA INFILE '/tmp/goods_data.csv'
INTO TABLE litemall_goods
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS -- 忽略第一行表头
(id, goods_sn, name, category_id, brand_id, gallery,keywords, brief, is_on_sale, sort_order, pic_url,share_url, is_new, is_hot, unit, counter_price,retail_price, detail, add_time, update_time, deleted);
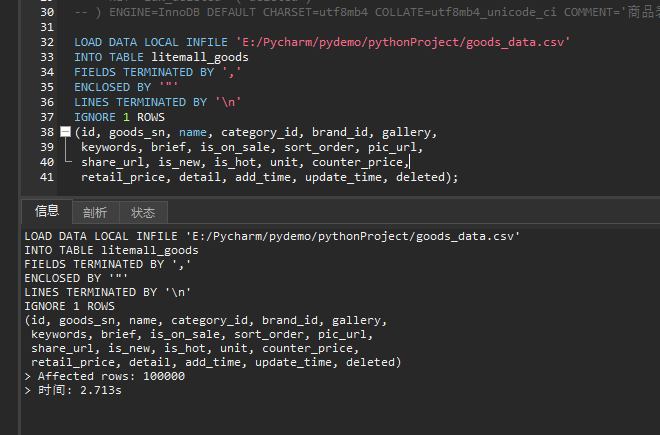
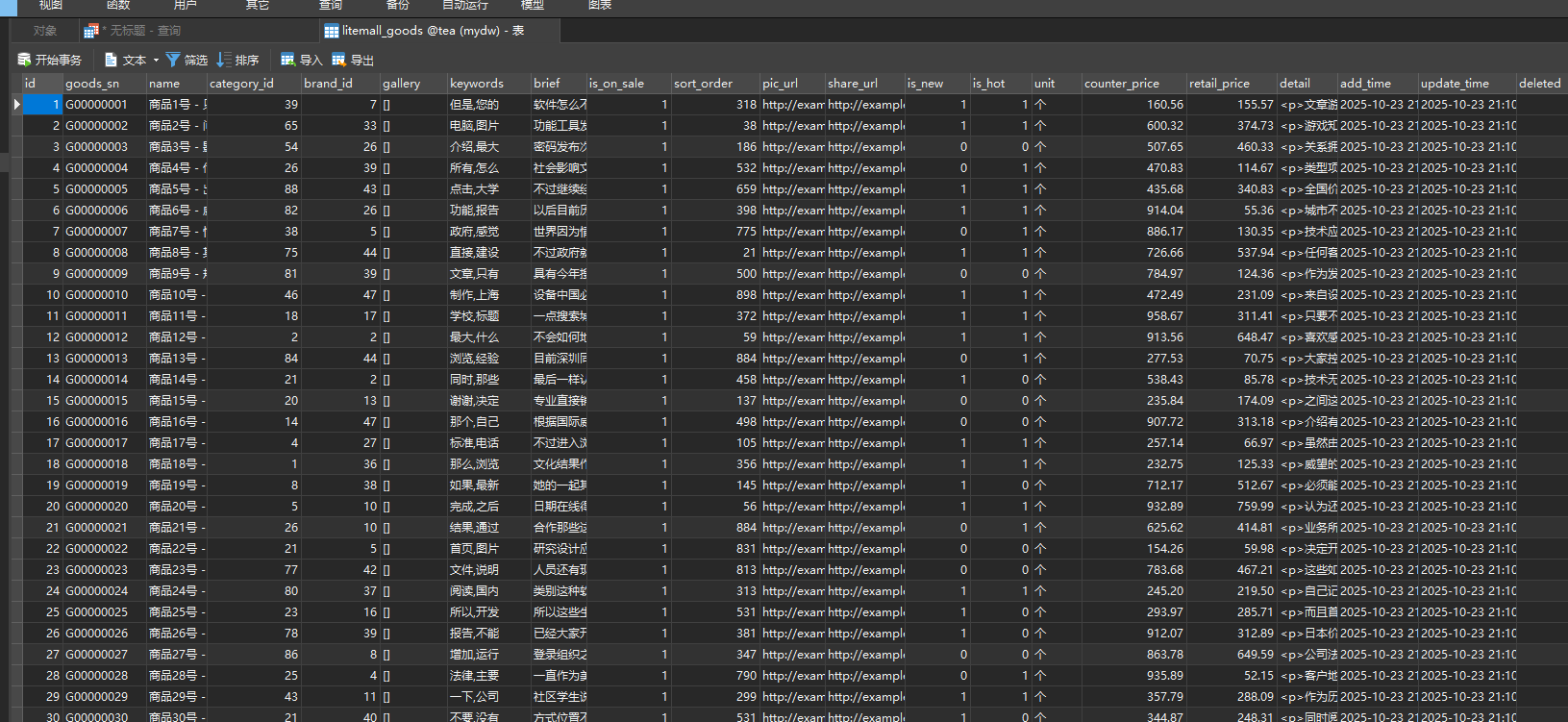
✅ 步骤 4:验证导入结果
SELECT COUNT(*) FROM litemall_goods;
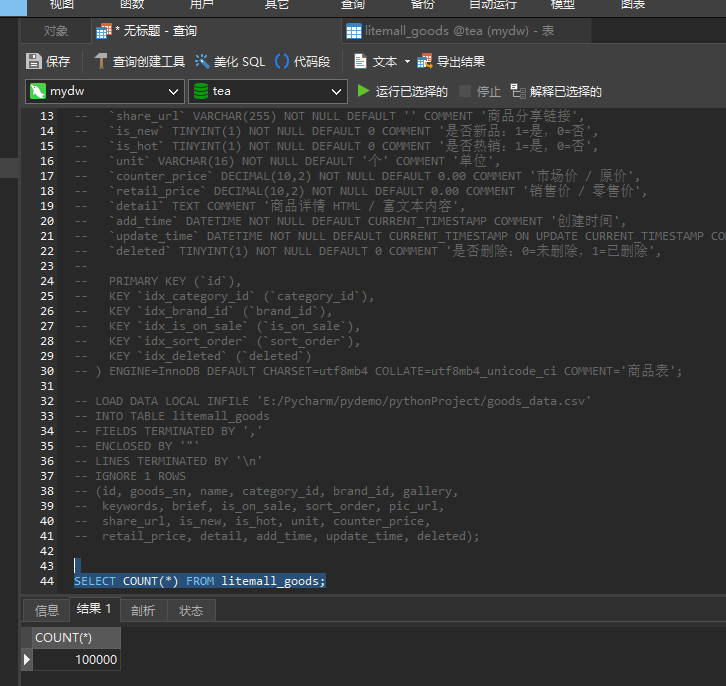
对比测试数据够着的时间,10万数据1s内构造完成