修改langgraph-checkpoint-mysql插件兼容Tidb
文章目录
- 背景
- 哪些地方不兼容
- 适配
- 建表
- 一处错误
- 启动测试
- 其他
背景
使用langgraph-checkpoint-mysql(第三方插件)来实现TiDB的检查点存储。
第三方MySQL扩展:https://github.com/tjni/langgraph-checkpoint-mysql
一个A2A调用LangGraphj的demo:https://github.com/a2aproject/a2a-samples/tree/main/samples/python/agents/langgraph
demo用的是内存
这里使用的是mysql插件2.0.17,最新版
PS D:\code\a2a-samples\a2a-samples\samples\python\agents\langgraph> uv pip show langgraph-checkpoint-mysql
Name: langgraph-checkpoint-mysql
Version: 2.0.17
Location: D:\code\a2a-samples\a2a-samples\samples\python\agents\langgraph\.venv\Lib\site-packages
Requires: langgraph-checkpoint, orjson, typing-extensions
Required-by:
但是由于MySQL和TiDB的部分内容不兼容,导致无法达到预期效果
详情见TiDB和MySQL的不兼容点-CSDN博客
哪些地方不兼容
位置Lib\site-packages\langgraph\checkpoint\mysql\base.py
这个base文件里面主要就是检查点增删改查的SQL,以及检查点的建表语句
不兼容点
问题 1:JSON_TABLE 接收 JSON_KEYS 作为输入(动态解析 JSON 键)
问题 2:CONCAT 动态生成 JSON 路径(导致 JSON_EXTRACT 返回 NULL)
如下
with channel_versions as (select thread_id, checkpoint_ns_hash, checkpoint_id, channel, json_unquote(json_extract(checkpoint, concat('$.channel_versions.', '"', channel, '"'))) as versionfrom checkpoints, json_table(json_keys(checkpoint, '$.channel_versions'),'$[*]' columns (channel VARCHAR(150) CHARACTER SET utf8mb4 PATH '$')) as channels{{WHERE}}
)
问题 3:mysql_mariadb_branch 条件注释(TiDB 忽略导致错误)
select json_arrayagg(json_array(bl.channel,bl.type,{mysql_mariadb_branch("bl.blob", "to_base64(bl.blob)")}
))
上面这段类似的代码在SELECT_SQL中共有两处,整个增改查所有的sql一共有七处使用了mysql_mariadb_branch
适配
修改上述不兼容点,也就是base.py里的sql语句,使其适配TIDB
关键修改点
- 拆分 CTE:新增
channel_names专门提取通道名,再通过channel_versions提取对应版本,避免JSON_EXTRACT嵌套在JSON_QUOTE中导致的语法解析问题。 - 简化 JSON 路径:版本提取路径从嵌套拼接改为直接使用
channel_names中的channel字段,语法更简洁,TiDB 更易解析。 - 保持兼容性:继续使用枚举索引规避递归 CTE,同时适配 TiDB 对 JSON 函数的解析规则。
修改后的base文件在仓库中。(仓库链接在最后)
建表
除了增删改查的sql外还有建表,建表语句没有修改,而是直接自动创建了。
既然自己建表了,如何避免走插件的建表逻辑呢?
在获取检查点时不掉用setup()方法即可,就是官方案例中的setup()方法
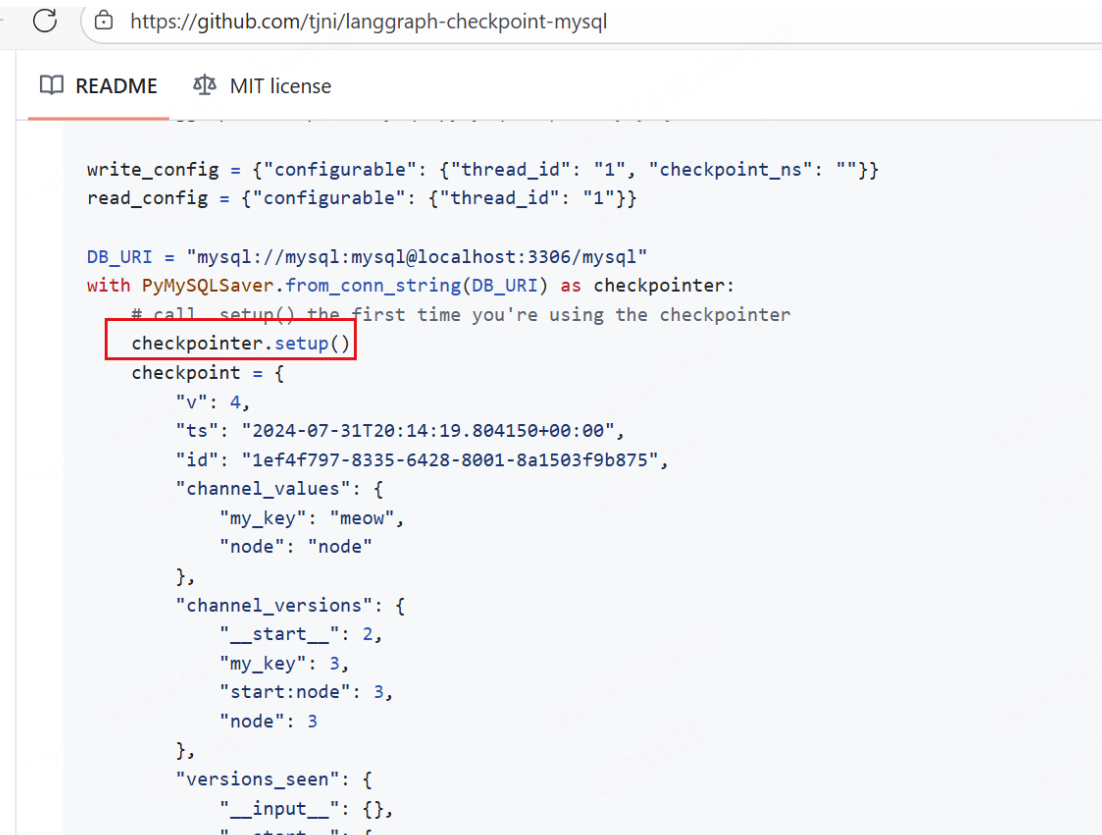
建表语句在仓库中。
一处错误
位置Lib\site-packages\langgraph\checkpoint\mysql\aio_base.py
因为我使用的是官方的第二个案例(也就是异步的那个),在使用过程中发现错误。
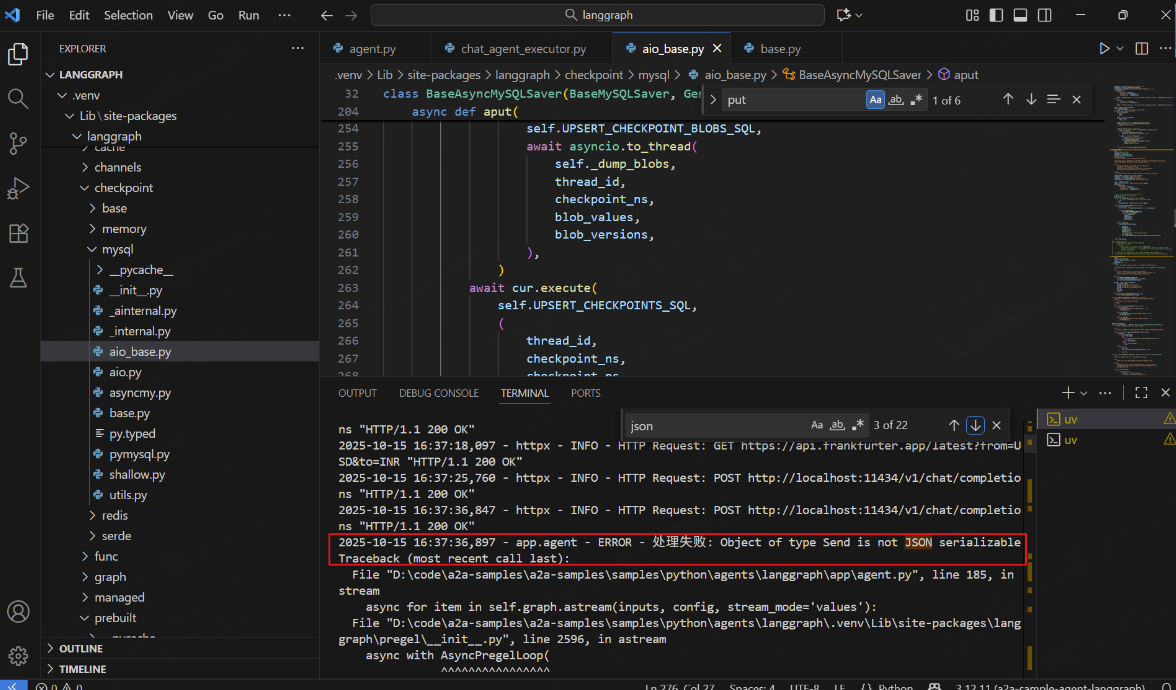
源码:
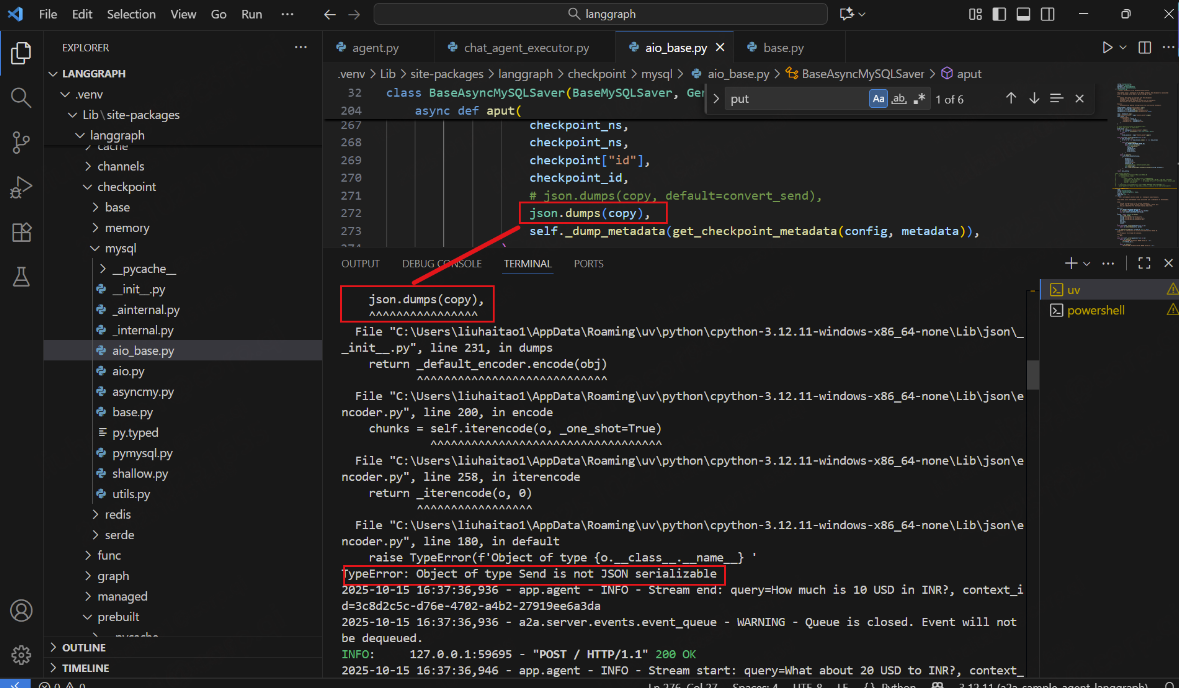
数据库使用json存储,在存储前转换json时,其中自定义的类型Send无法被序列化进而报错。
原因:这里使用的dumps()方法只能序列化python的一些基本数据类型
解决办法:自定义一个临时的json转换,来适配json。
修改后代码在仓库中。
启动测试
langgraph官方给的案例中,我修改了agent.py文件,包括连接等(还有一些其他内容)一样放到仓库中。
下面这个是统一的测试格式,不是tidb的。我是使用了ollama服务,注意ollama下载的LLM的名字是否和你配置的一样!!!
一个A2A调用LangGraphj的demo:https://github.com/a2aproject/a2a-samples/tree/main/samples/python/agents/langgraph
# Basic run on default port 10000
uv run app# On custom host/port
uv run app --host 0.0.0.0 --port 8080uv run app/test_client.py
运行案例需要解决LLM访问,可以使用本地LLM
步骤1:安装并启动Ollama
# 安装Ollama(如果还没安装)
# macOS: brew install ollama
# 或者从 https://ollama.ai 下载
# 启动Ollama服务ollama serve# 在另一个终端安装模型
ollama pull llama3.2
在.env文件中,配置环境变量后,就可以正常启动了
# 模型配置 - 设置为 openai 以使用 OpenAI 兼容的 API
model_source=openai# 使用 OpenAI API(如果你有API Key)
# API_KEY=your_openai_api_key_here
# TOOL_LLM_URL=https://api.openai.com/v1
# TOOL_LLM_NAME=gpt-3.5-turbo# 或者使用本地 LLM(如 Ollama)
# 请确保 Ollama 正在运行,并且已安装 llama3.2 模型
TOOL_LLM_URL=http://localhost:11434/v1
TOOL_LLM_NAME=llama3.2:1b
其他
1,一些命令
#查看版本
uv pip show langgraph-checkpoint-mysql
2,async with AIOMySQLSaver.from_conn_string(DB_URI) as saver: 会在退出上下文时关闭连接。
我们需要在整个应用生命周期内保持数据库连接。
3,仓库地址langgraph-checkpoint-mysql-tidbCompatible: 在langgraph-checkpoint-mysql插件的基础上兼容tidb