DeepSeek-GRPO (PPO)
PPO
知识准备
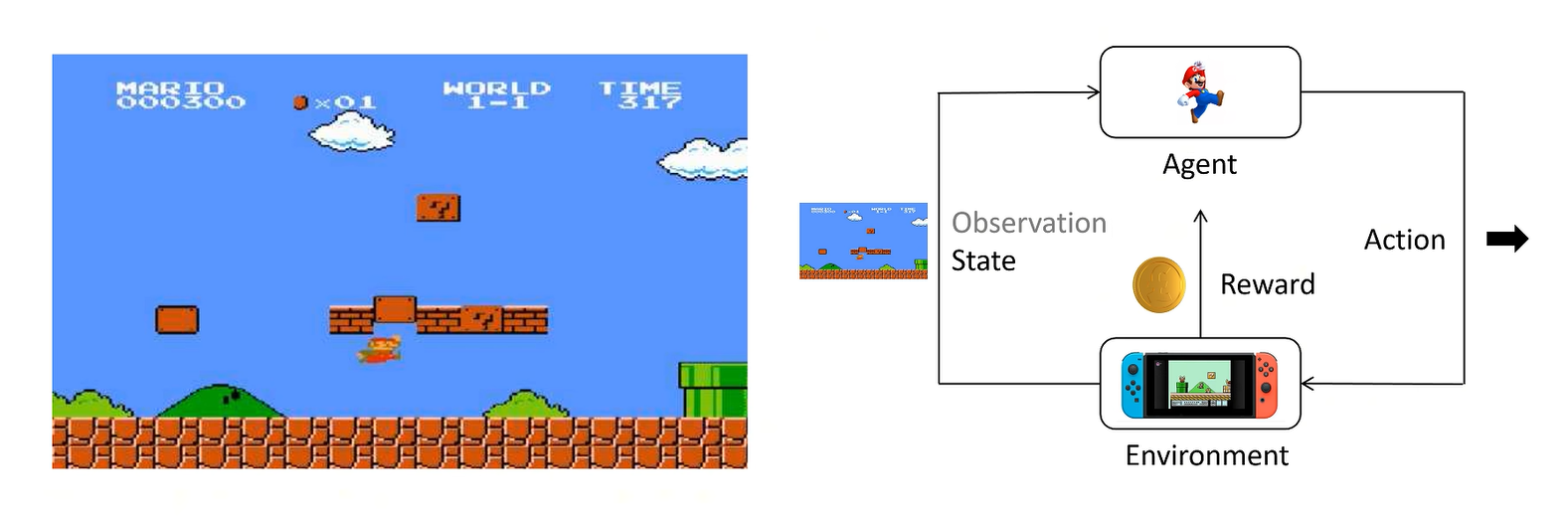

有两种状态转移方式
确定的和不确定的

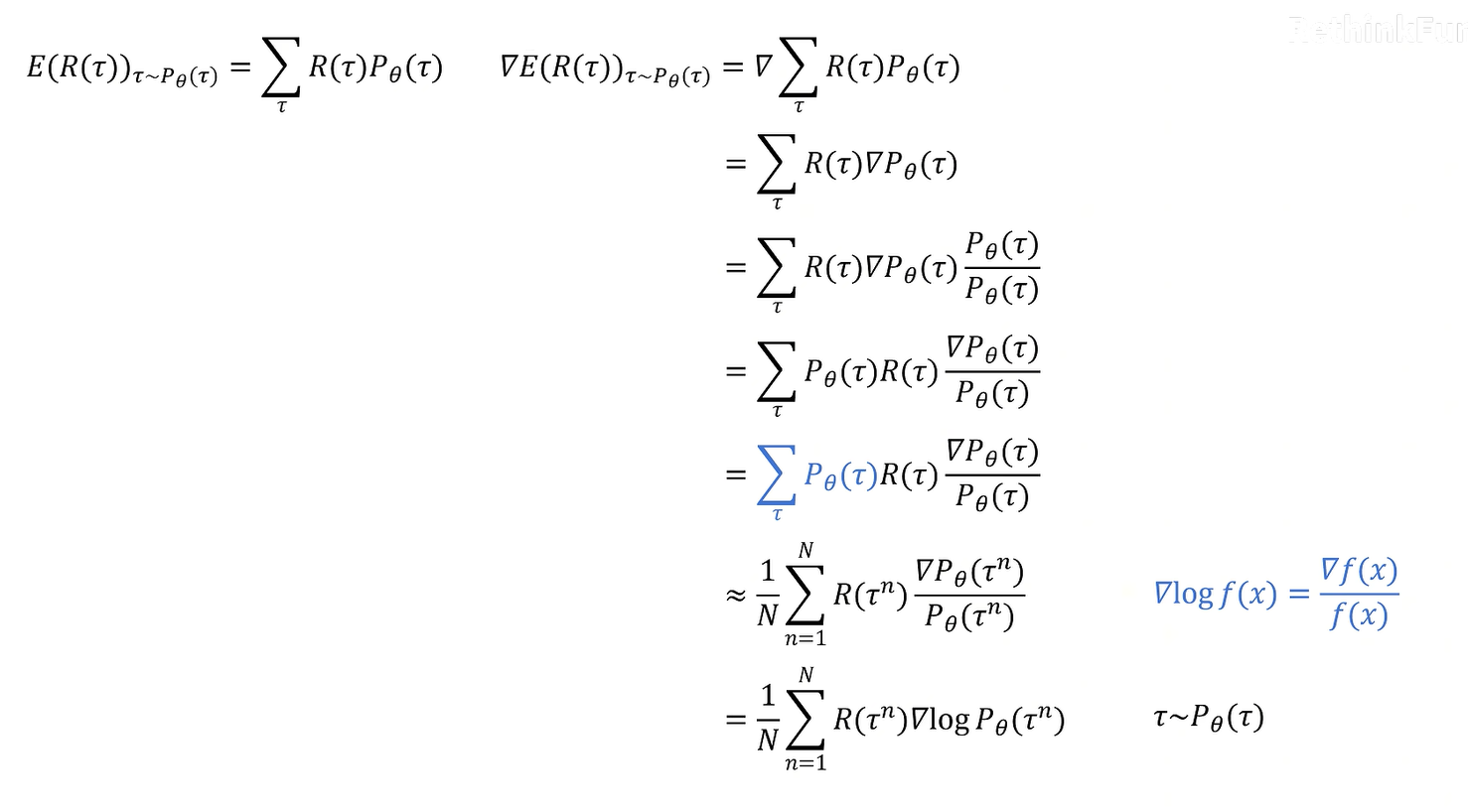
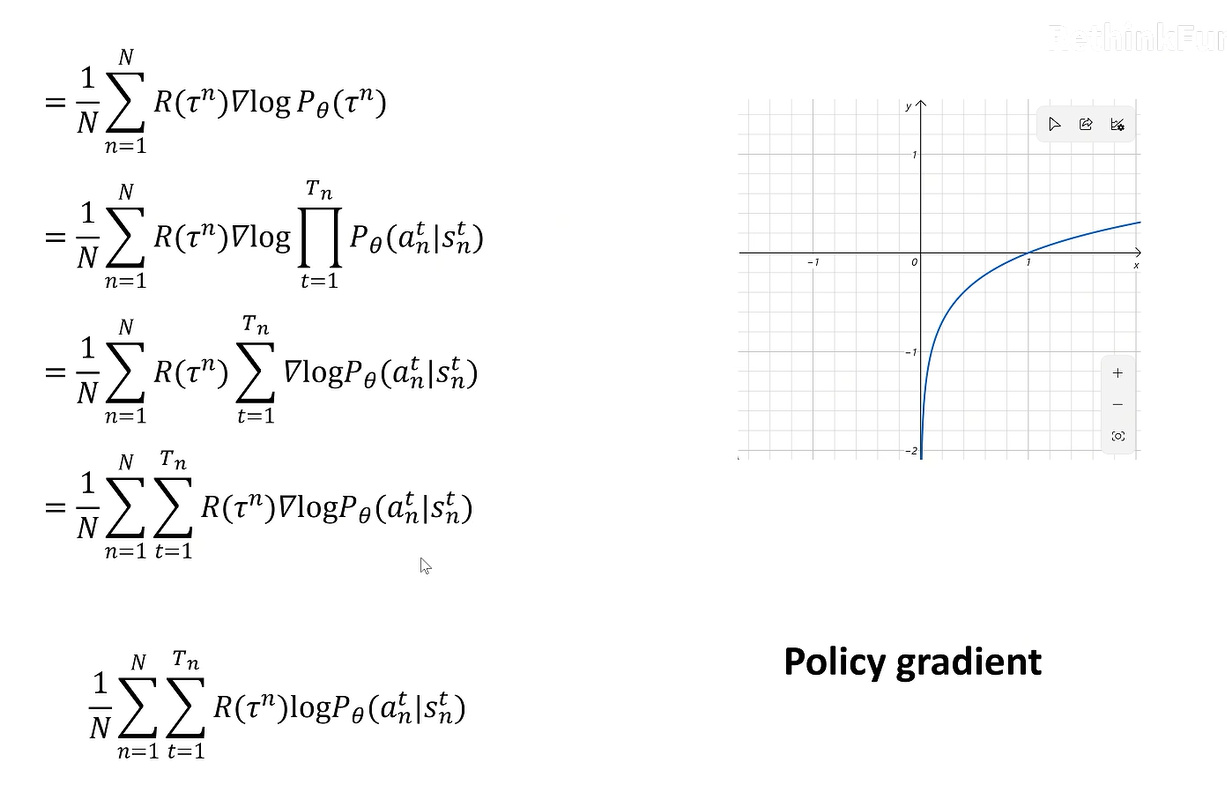
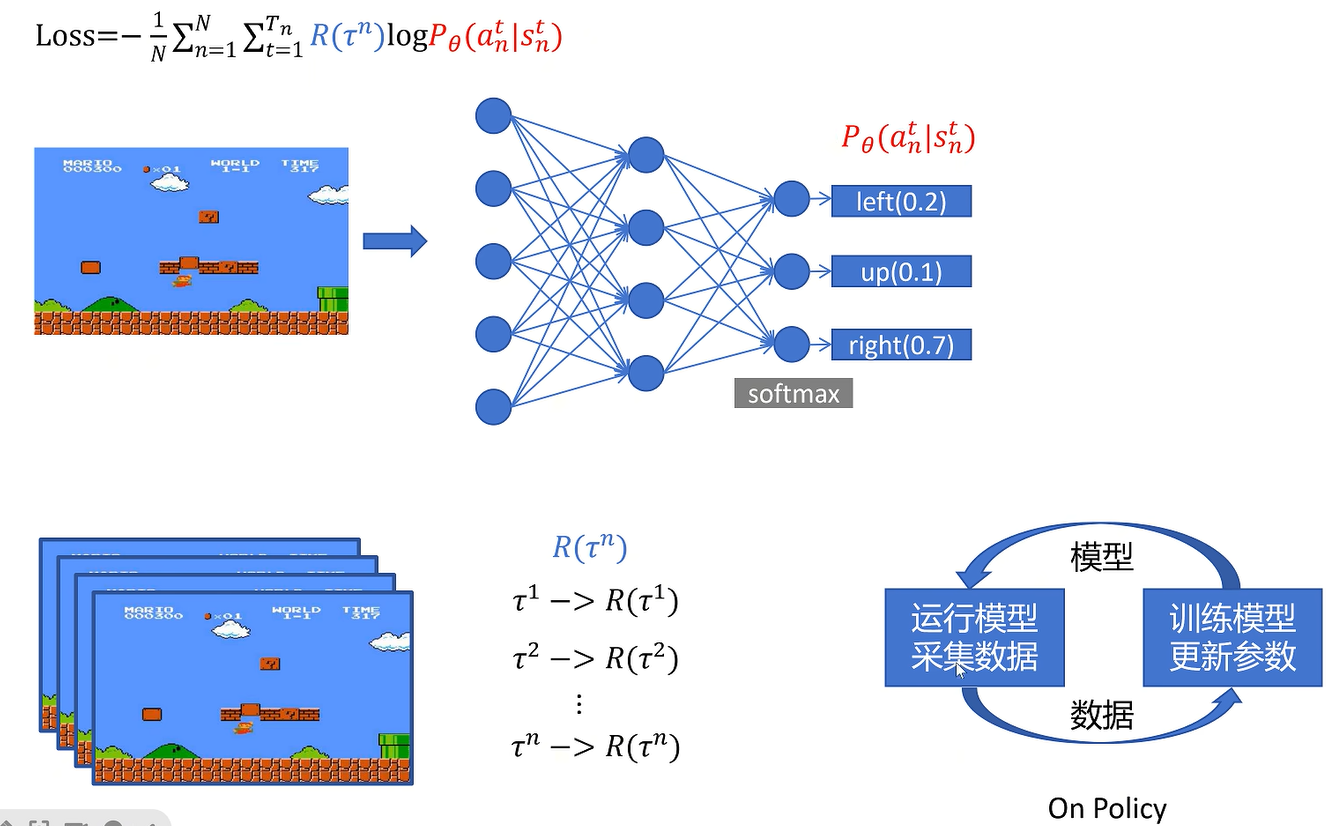
R来自于采样
on policy:采集数据和训练数据用的策略是一样的
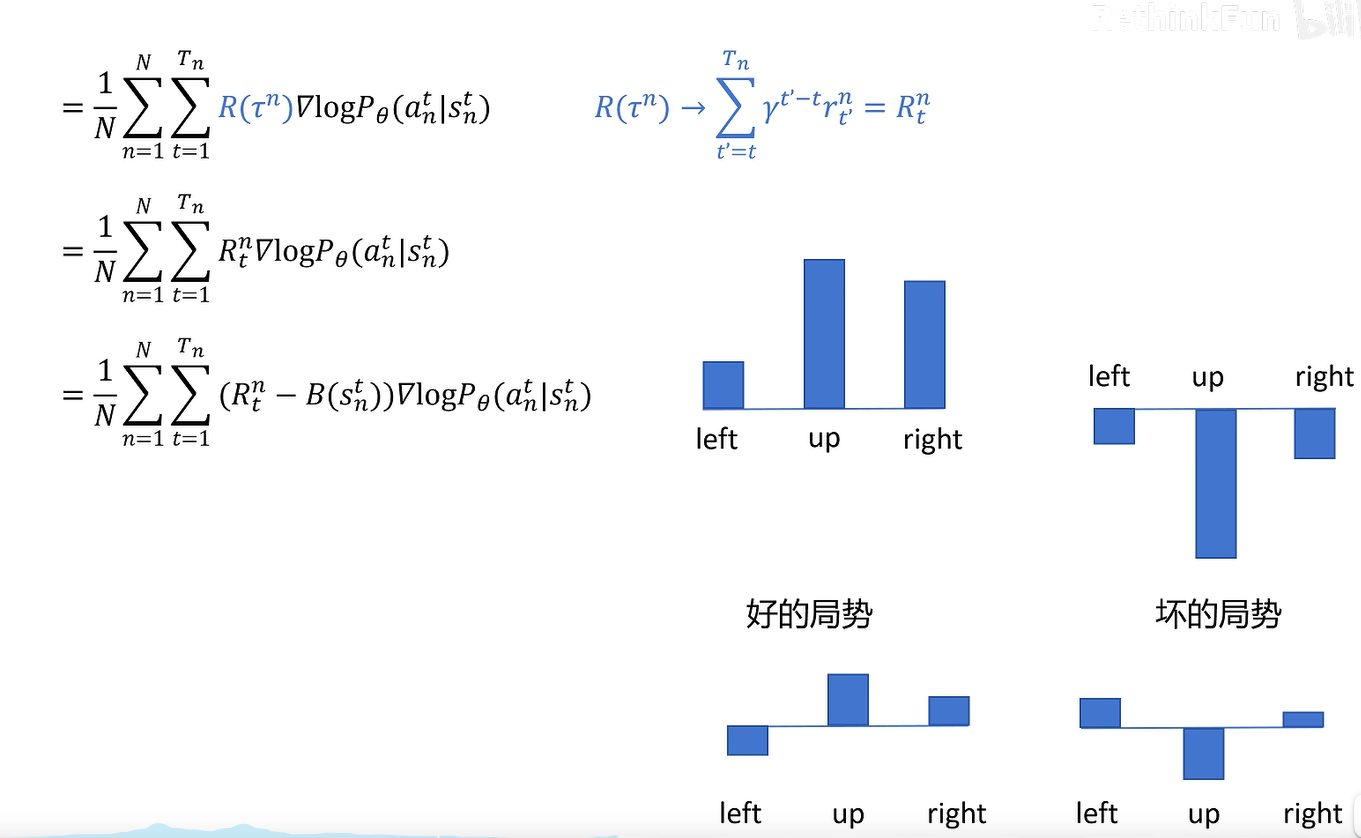
为了避免在好的局势下,所有动作概率都变大,坏的局势下,所有动作概率都减少,这会使得训练过程变幻,无法体现动作间的相对差异。因此减一个base,这个base也将训练得到,使得所有局势下都能体现相对回报


使用采样

采样多少呢。GAE全都要
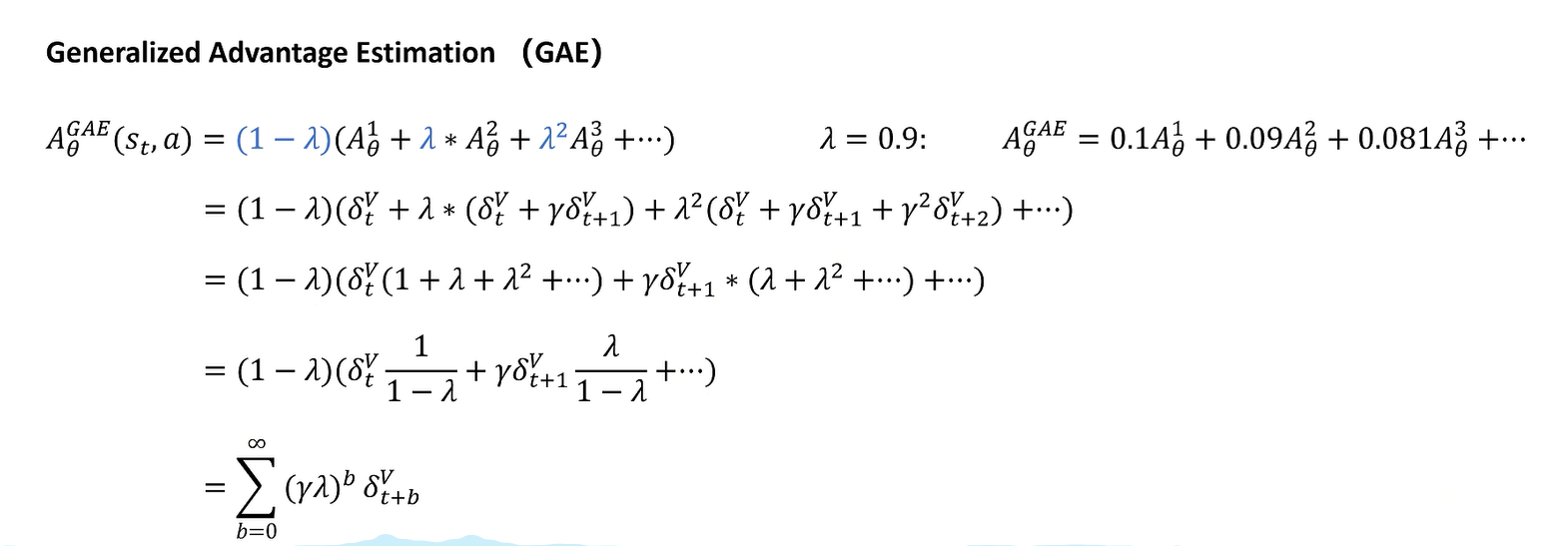
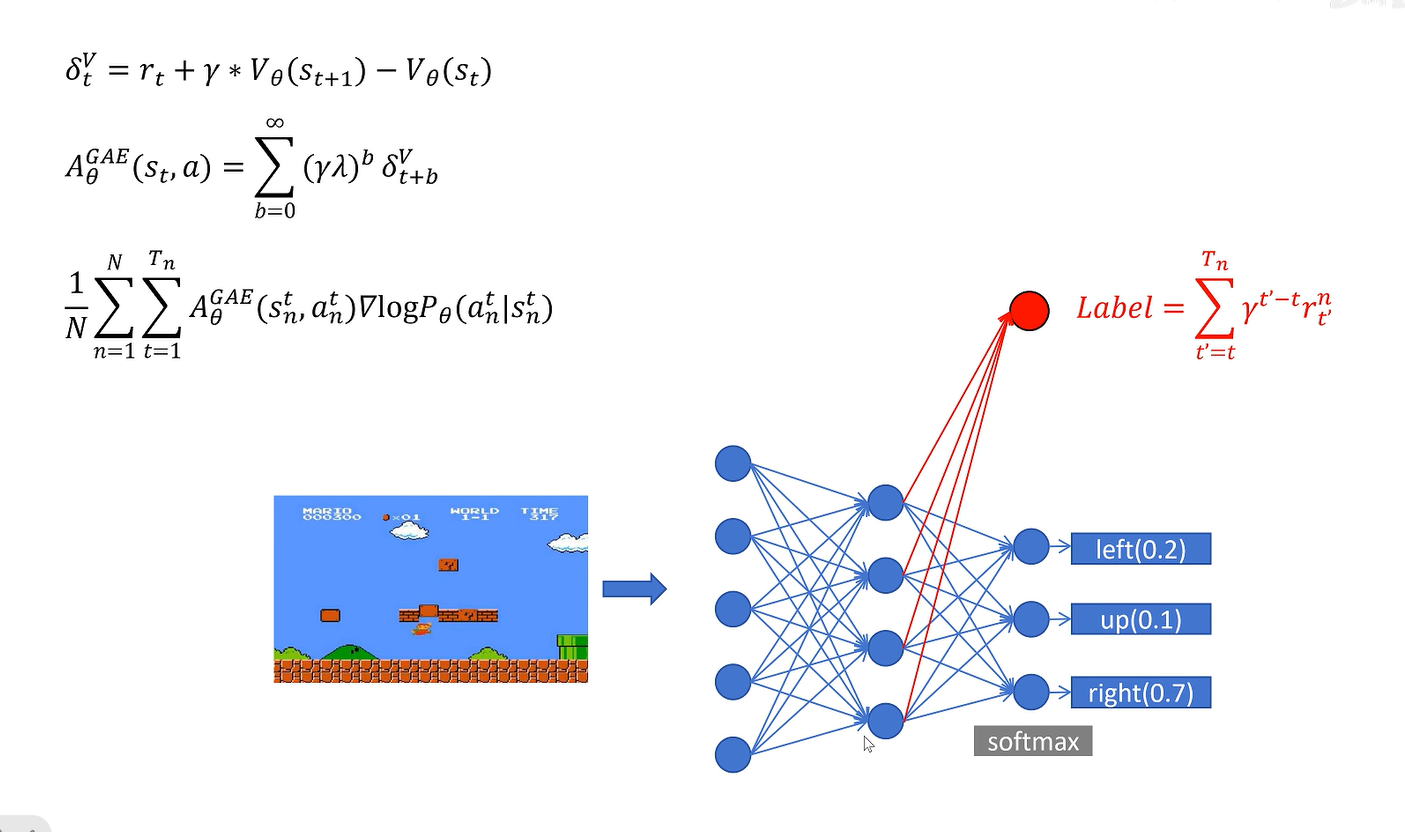
PPO

On policy:采集数据的策略和训练数据的策略一样。采集的数据用一次就丢弃。训练慢
Off policy:如果训练的模型和采集数据的模型不是同一个,采集的数据可以用来多次训练,就可以加快速度。
例子:
小明上课,老师批评或表扬小明,小明据此调整自己的言行,这是ON policy;
而其他同学根据老师对小明的批评或表扬而调整自己的言行,就是off policy

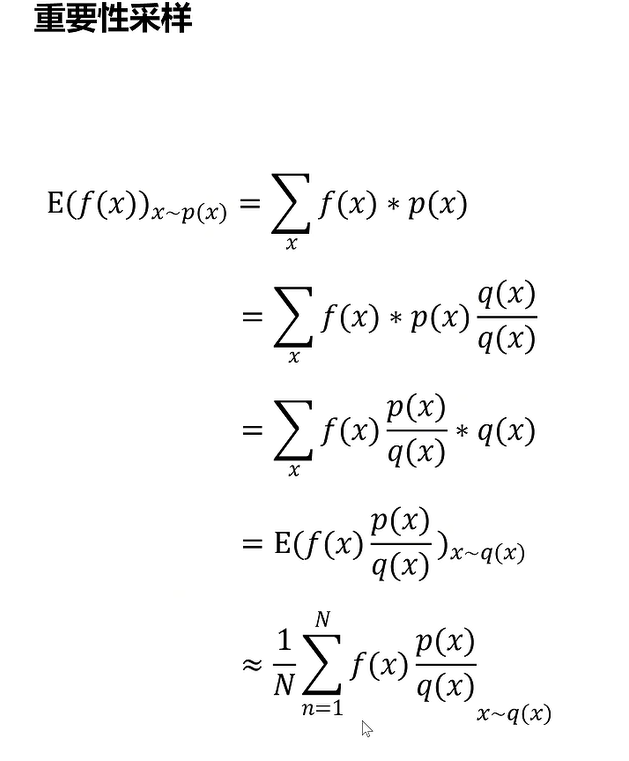
进而我们引入一个参考策略

从而我们可以用参考策略进行采样,并且采样的数据可以多次用于训练
限制:参考的策略不能与训练的策略差别太多,不然没有参考意义,学习不到东西
进一步提高:加上KL散度,防止训练的的策略和参考的策略偏差过大
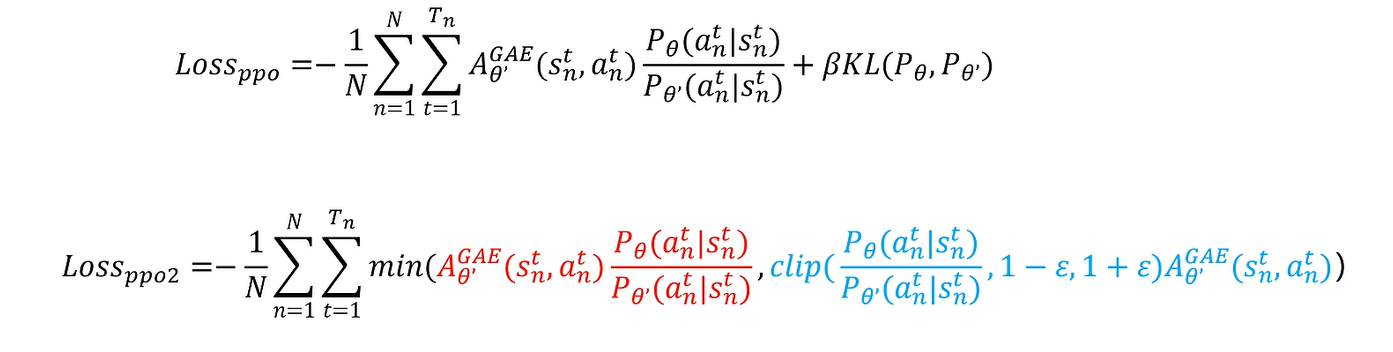
在大模型中使用强化学习
大模型的能力上限是由预训练决定的,强化学习使得大模型逼近极限。
关键是定义奖励
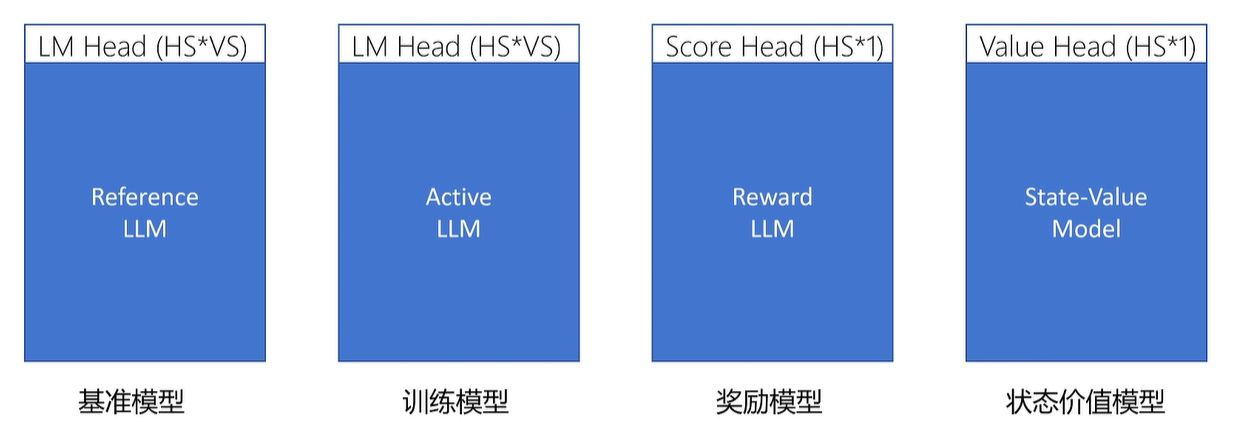
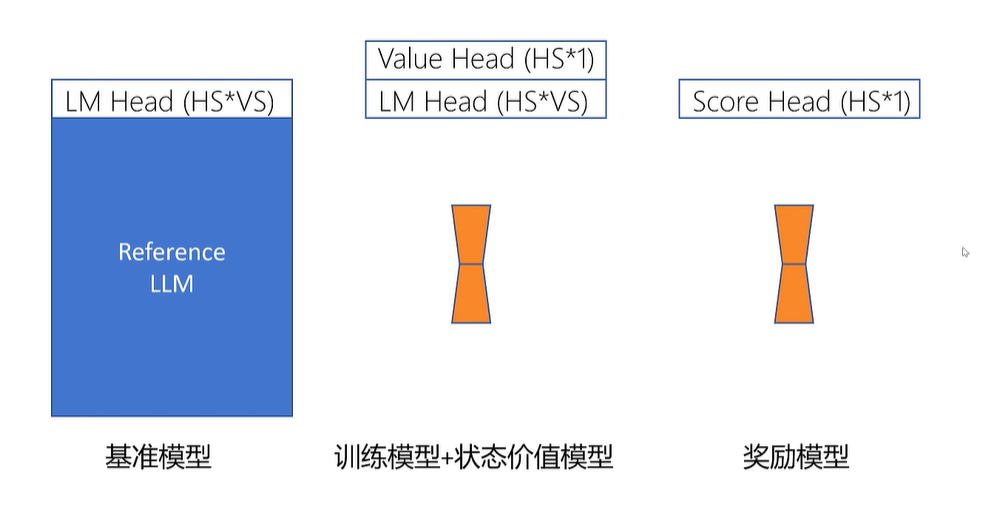


在ppo loss中训练模型和基准模型输出的概率分布不能相差太大
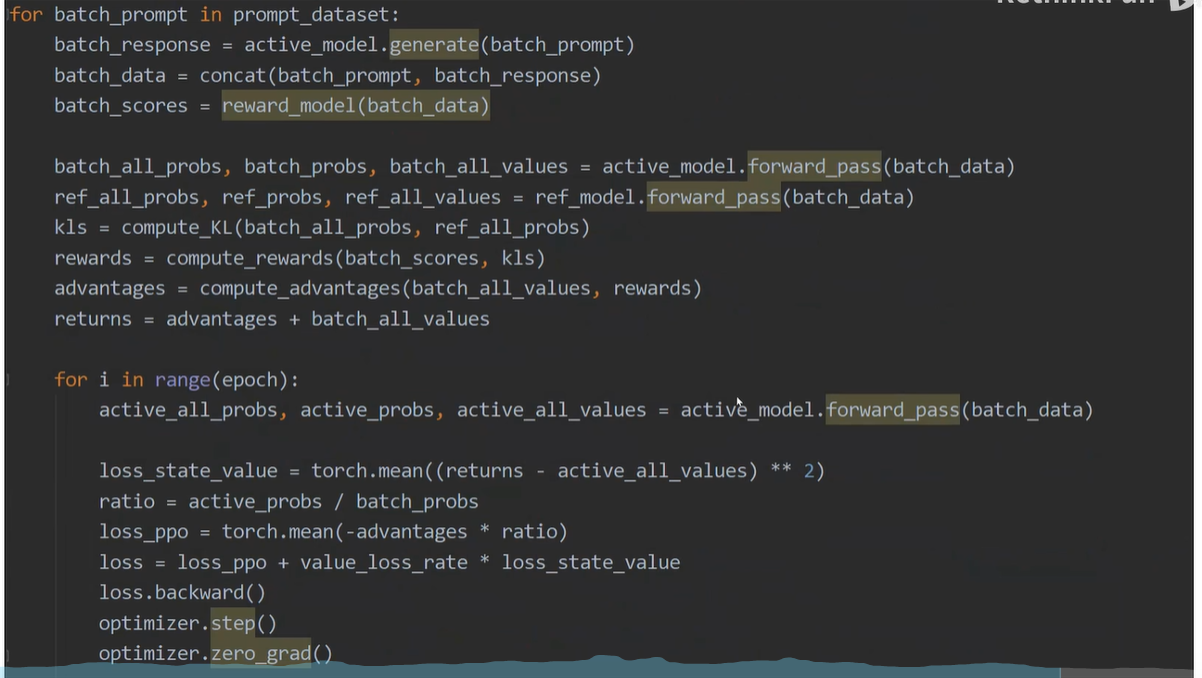
每次以当前训练的模型当作重要性采样的模型,训练下一次模型
相关库:PPOTrainer
GRPO
因为当前动作只会对后面的动作的回报产生影响,且大概率只影响相邻几个动作,而对太往后的动作影响有限。

在某些局势下,任何动作都将好或都不好,这时候为了加快训练,不再使用绝对回报,而是回报和基准的差值




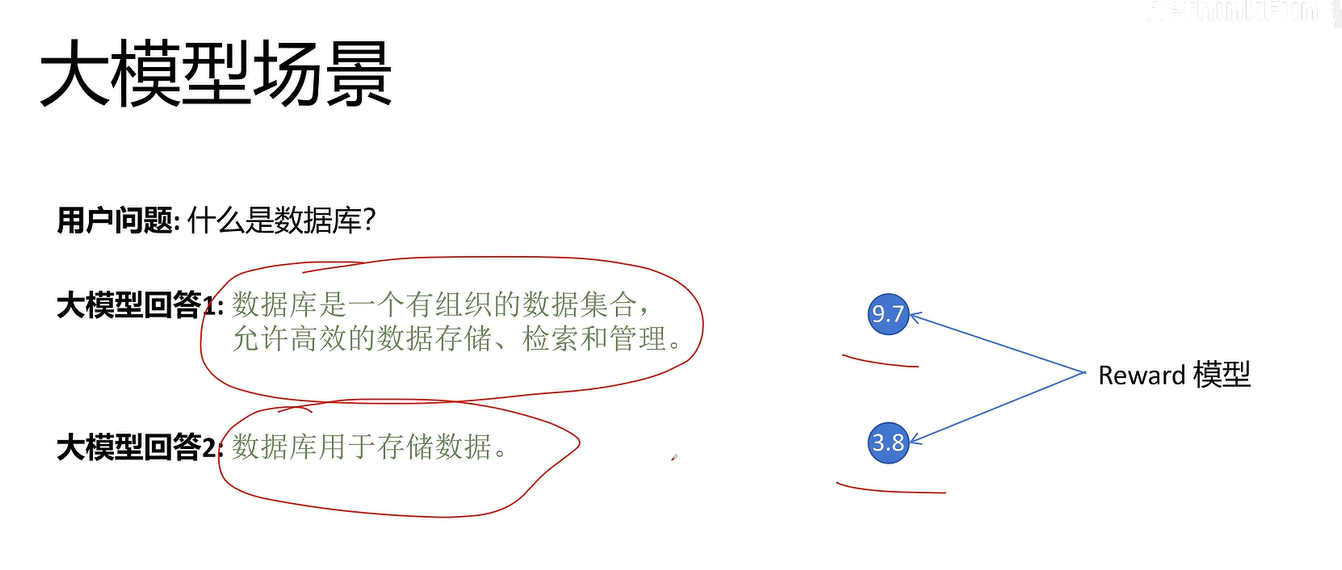
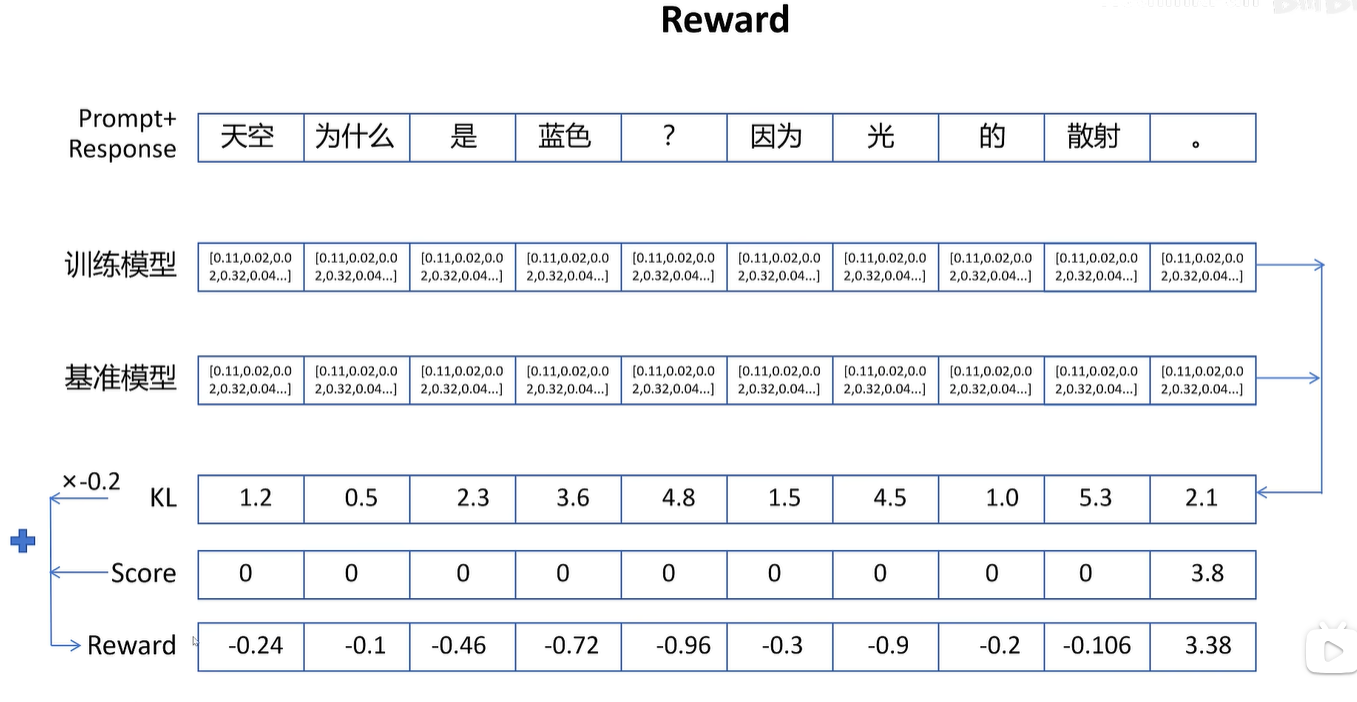
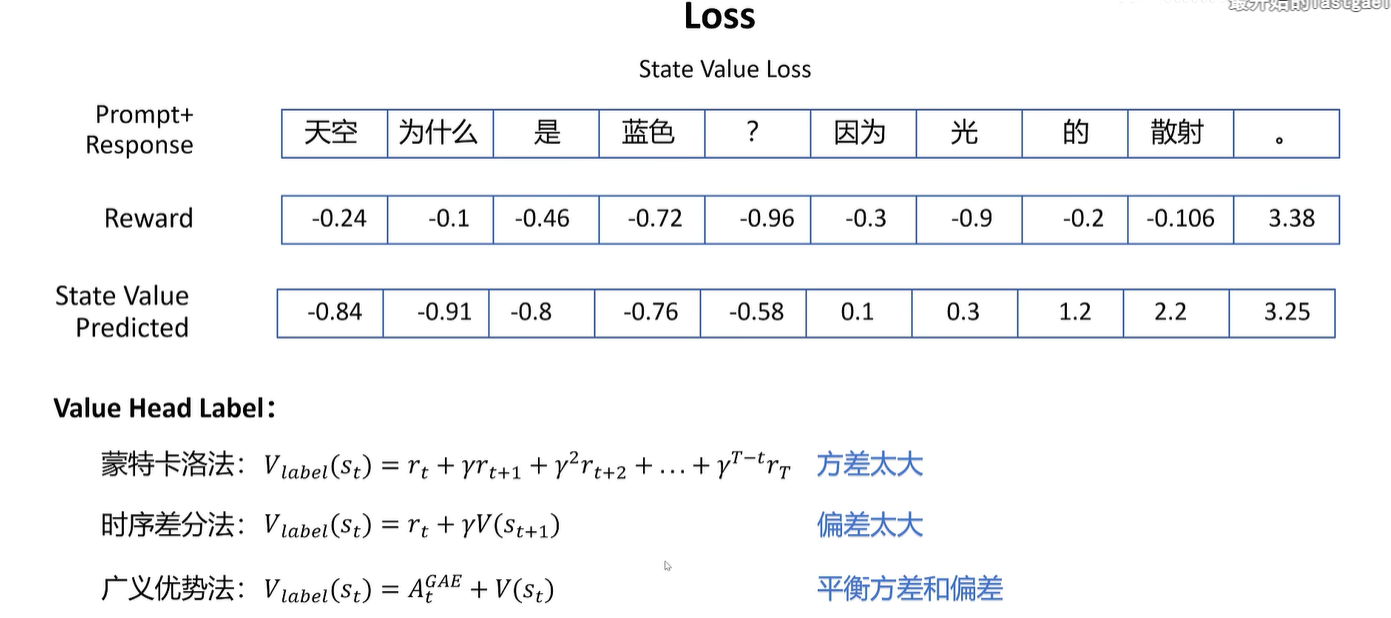
大模型不能对每个token进行打分,只能对最终的整体回答进行打分
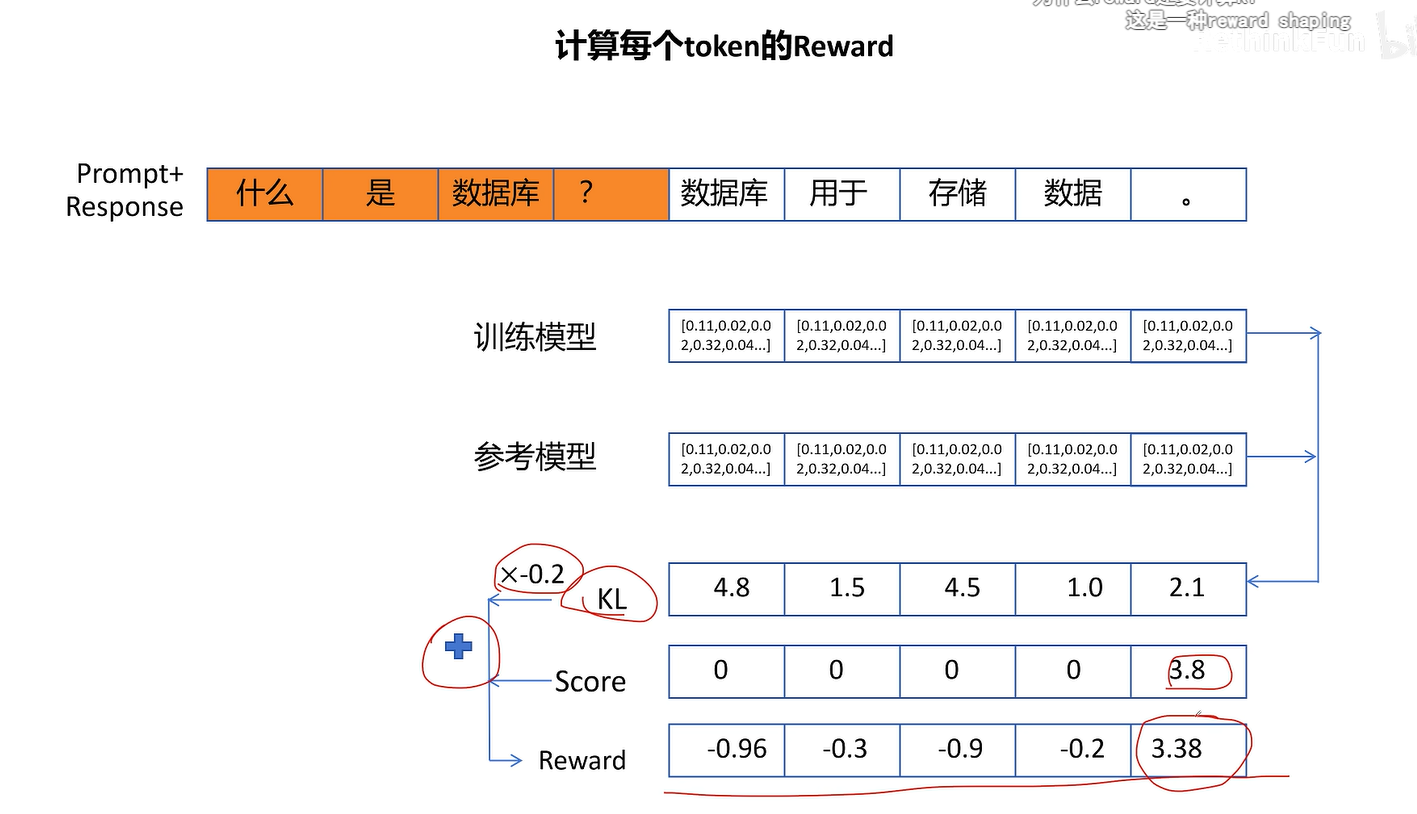
上面方法中,只有最后一个token的值有意义(3.38),因为只能对最终回答打分,其中值都是防止参考模型和训练模型差异过大,作用不大,因为该值不直接体现该动作的实际影响
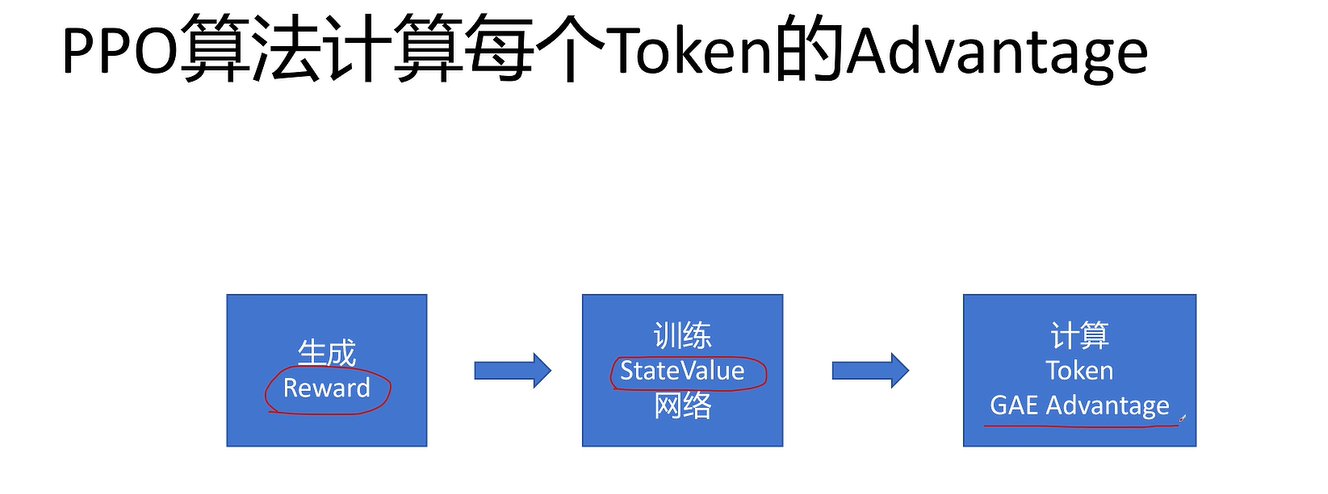
由于开始的reward并不准确,所以上述过程不太好。
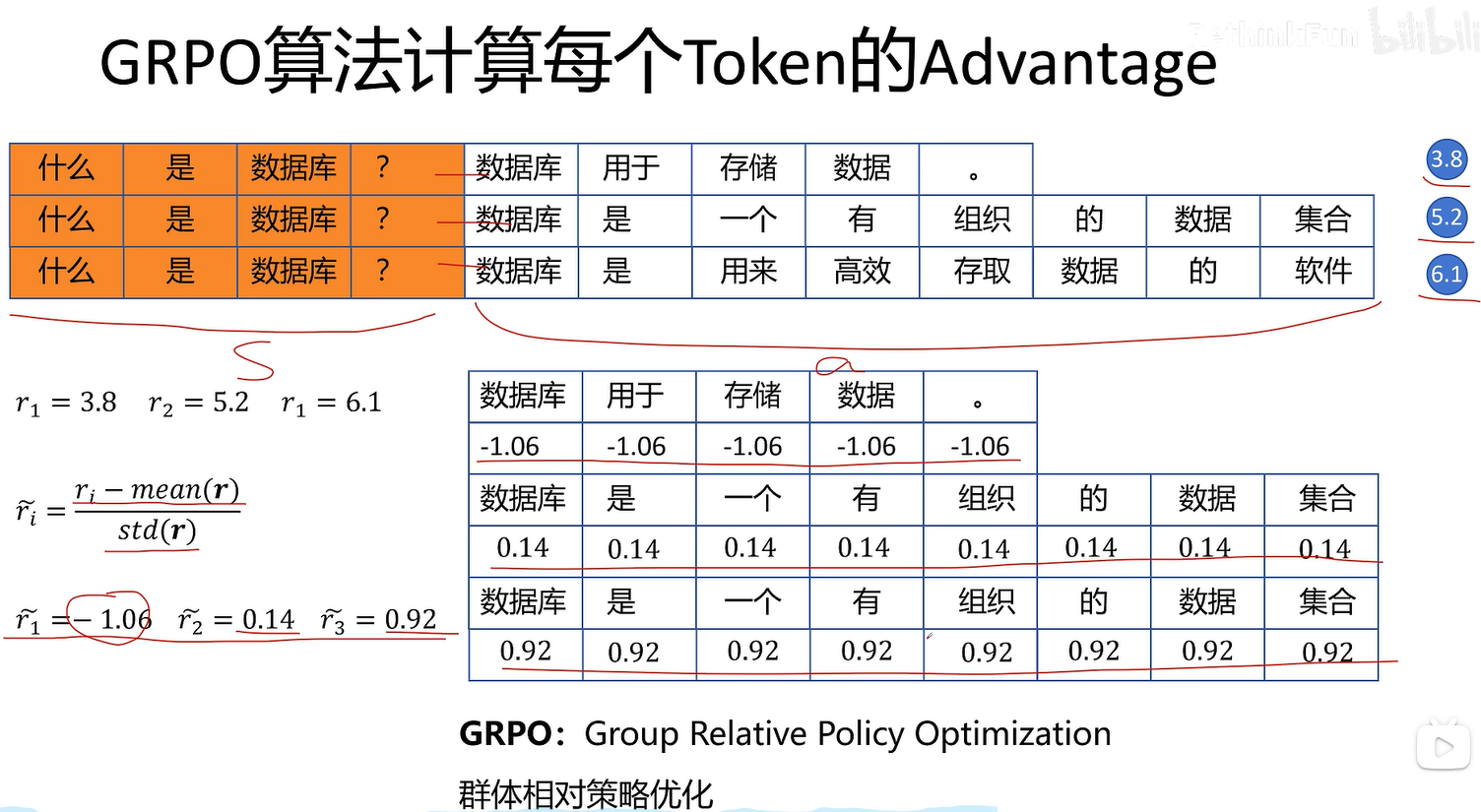
同一个prompt看成一个状态 S
不同回答看成不同动作 a
对不同回答进行评分就是该动作的回报
不需要训练状态价值网络就可以估算token优势值
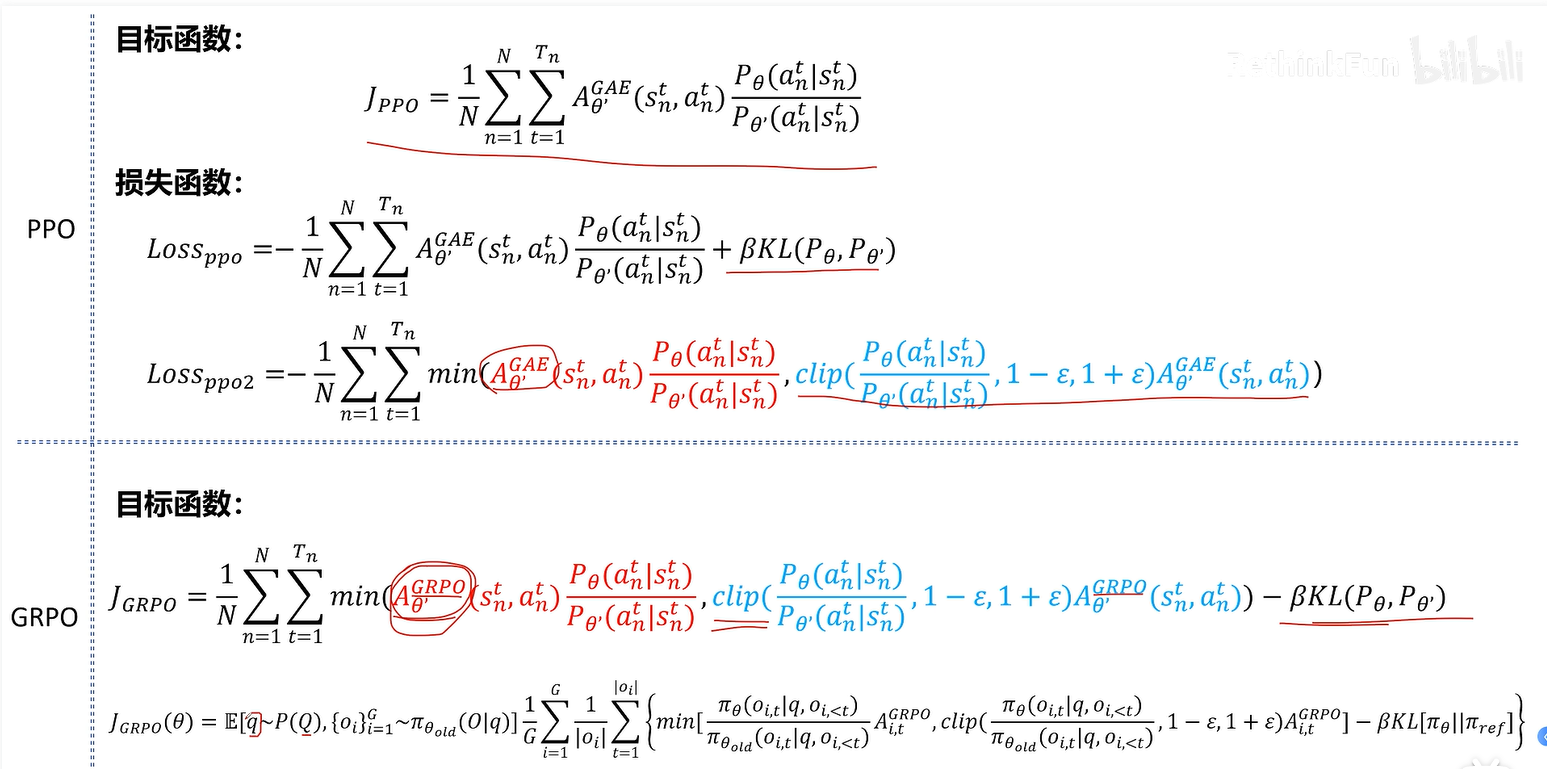

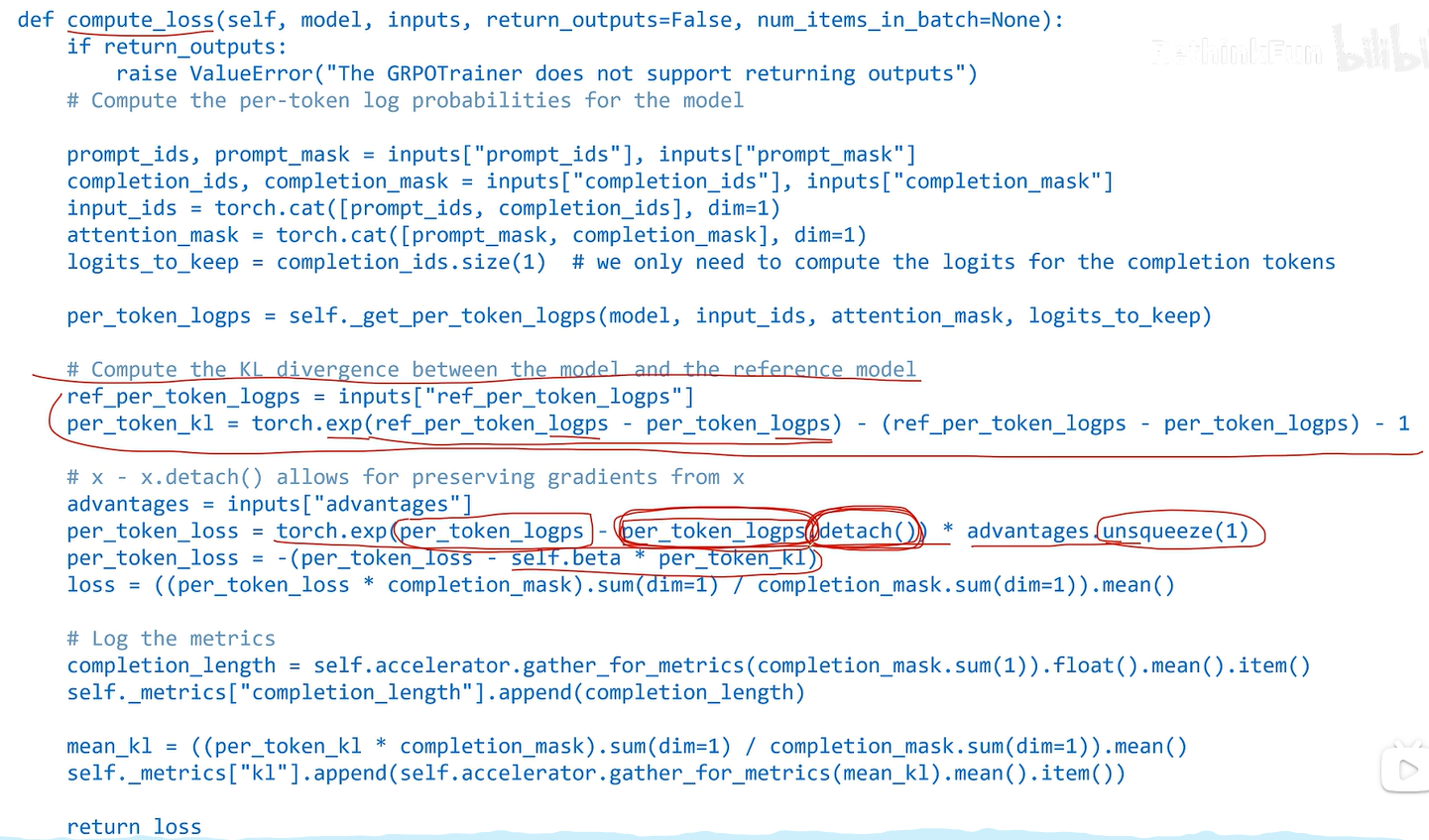
loss实现中没有截断函数,因为本质上截断函数跟KL散度功能差不多。
参考资料
【代码实现大模型强化学习(PPO),看这个视频就够了。】 https://www.bilibili.com/video/BV1rixye7ET6/?share_source=copy_web&vd_source=fec93c465877186fa07de6e0442d1339
【DeepSeek-GRPO】 https://www.bilibili.com/video/BV1enQLYKEA5/?share_source=copy_web&vd_source=fec93c465877186fa07de6e0442d1339