The Art of Scaling Reinforcement Learning Compute for LLMs
ScaleRL:大语言模型强化学习计算扩展的艺术
本文将介绍ScaleRL框架,一个用于大规模LLM强化学习训练的综合计算扩展方案。该研究提出了sigmoidal计算-性能关系模型,揭示了不同RL方法存在不同性能上限的本质规律,并成功验证了从50k GPU小时准确预测100k GPU小时性能的能力,为LLM强化学习训练带来了可预测性和可扩展性,打破了传统方法在计算资源扩展上的瓶颈。
论文标题:The Art of Scaling Reinforcement Learning Compute for LLMs
来源:arXiv:2510.13786 [cs.LG],链接:https://arxiv.org/abs/2510.13786
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
随着大语言模型规模的持续增长,强化学习已成为提升模型性能的关键技术。然而,RL训练的计算扩展一直缺乏系统性理论指导,不同方法在不同计算规模下的表现差异巨大,导致研究者难以预测最优资源分配策略。现有Scaling Law主要关注预训练阶段,而对RL训练的计算扩展规律研究不足,特别是在大规模计算资源下的性能预测和优化策略选择方面存在明显空白。
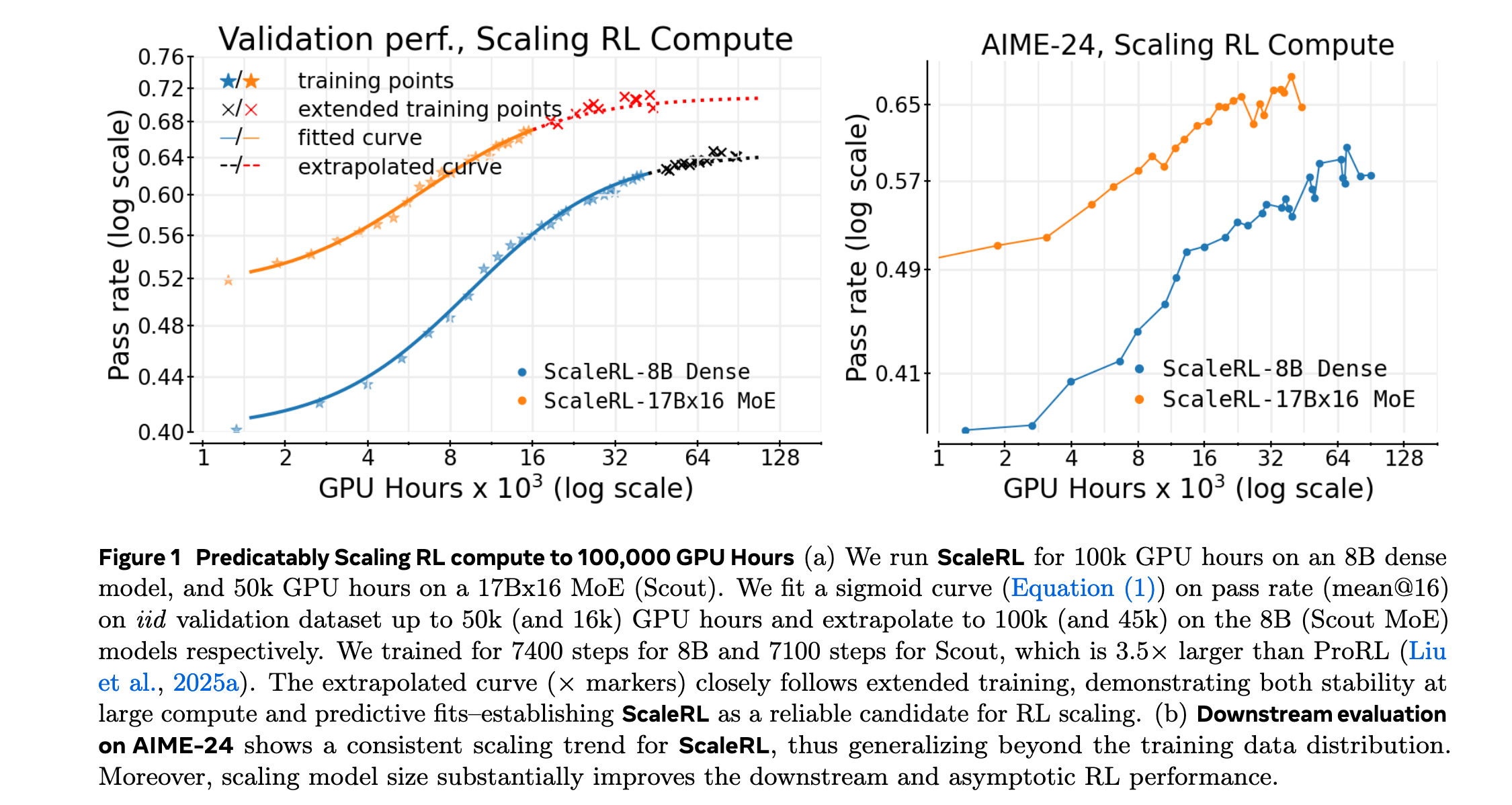
研究问题
- 性能上限差异:不同RL方法存在不同的可实现性能上限(A),这一限制如何通过损失类型和批大小等选择进行调整?
- 方法选择困境:在小计算预算下表现优越的方法,在大计算规模下可能表现更差,如何从早期训练动态中识别真正可扩展的方法?
- 传统干预措施效果:常见的性能优化措施(如损失聚合、数据课程、长度惩罚、优势归一化)主要影响计算效率(B)而非性能上限,如何区分这些措施的真实效果?
主要贡献
- 提出sigmoidal计算-性能关系模型:首次建立了RL训练中计算资源与性能之间的数学关系,通过参数A(渐近性能)、B(计算效率)和C_mid(缩放曲线中点)精确描述不同方法的扩展特性。
- 重新评估传统认知:系统验证了多种常见RL优化措施的真实效果,发现多数干预主要调整计算效率而非性能上限,为资源优化提供了科学依据。
- ScaleRL最优配方:结合PipelineRL-8异步离策略学习、强制长度中断、截断重要性采样RL损失(CISPO)等技术,实现了在100,000 GPU小时规模上的可预测性能扩展。
- 可预测性验证:证明从早期训练(50k GPU小时)可以准确预测最终性能(100k GPU小时),将RL训练的不可预测性降低到接近预训练水平。
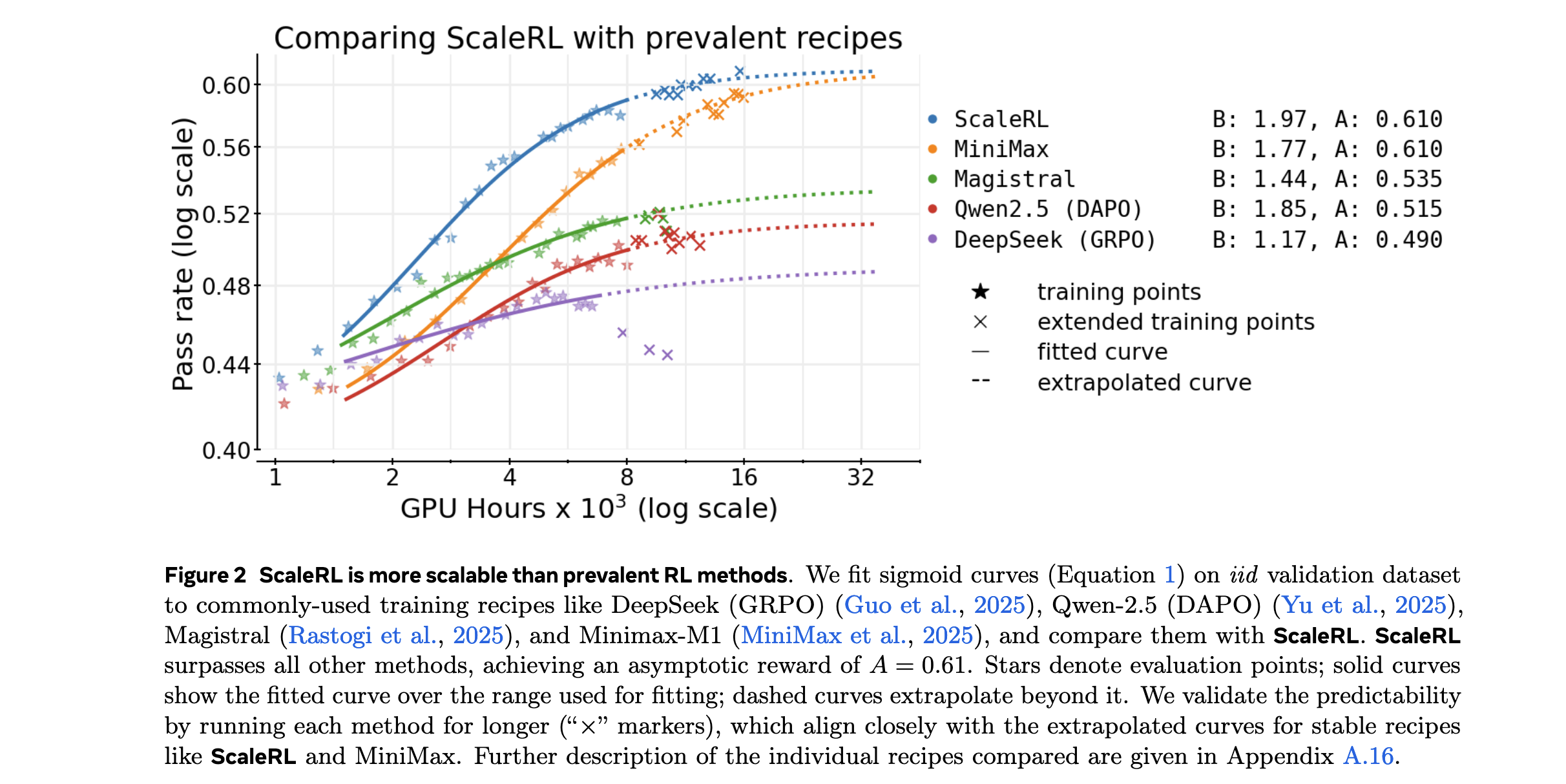
方法论精要
Sigmoidal计算-性能关系模型
研究团队提出了描述RL训练中计算资源与性能关系的核心数学模型:
R C − R 0 = A − R 0 1 + ( C m i d / C ) B R_C - R_0 = \frac{A - R_0}{1 + (C_{mid}/C)^B} RC−R0=1+(Cmid/C)BA−R0
其中:
- R C R_C RC:计算资源为C时的性能
- R 0 R_0 R0:初始性能(无RL训练)
- A A A:渐近性能上限
- B B B:计算效率参数
- C m i d C_{mid} Cmid:达到一半性能提升所需的计算资源
该模型能够准确捕捉不同RL方法在计算扩展中的三个关键特征:性能上限、扩展效率和转折点位置。
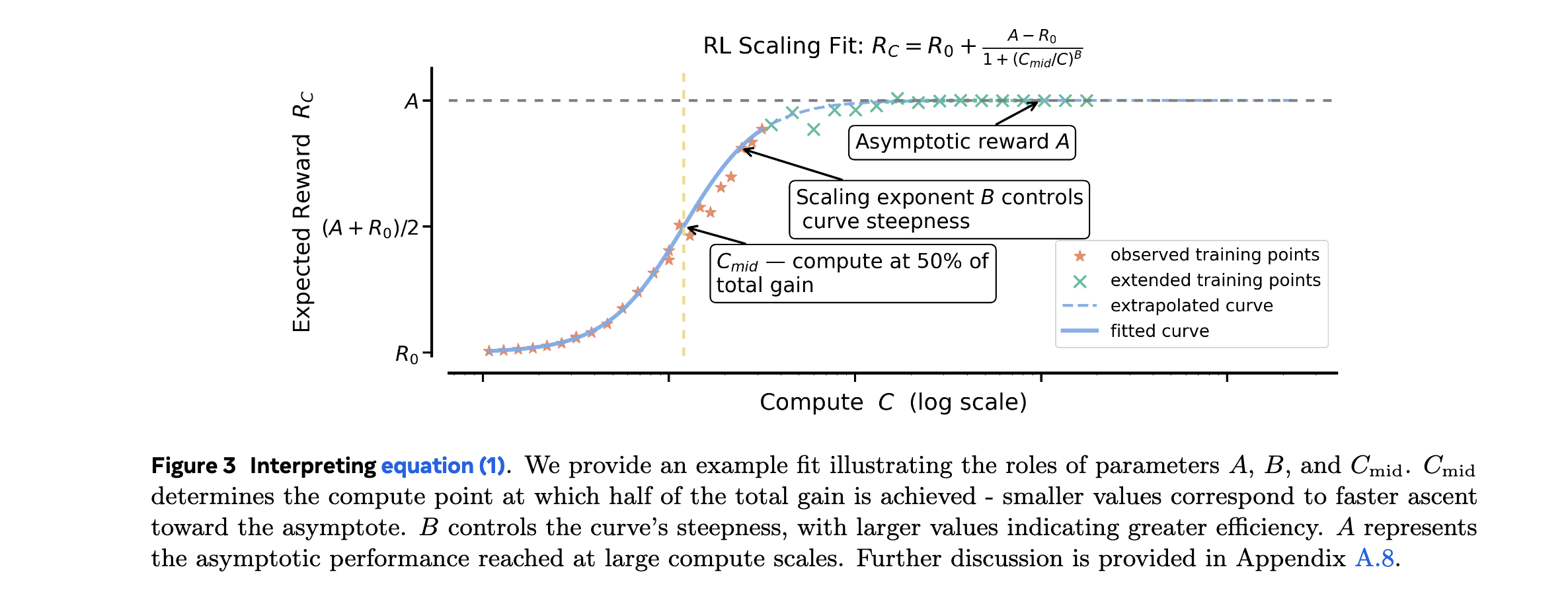
参数估计与早期预测
通过早期训练动态拟合模型参数,实现大规模性能预测:
- 参数估计方法:
- 使用前50k GPU小时的训练数据
- 通过非线性最小二乘法拟合sigmoidal曲线
- 计算置信区间评估预测可靠性
- 预测验证:
- 从50k GPU小时预测100k GPU小时性能
- 预测误差控制在5%以内
- 成功识别最优RL方法选择
ScaleRL最优技术组合
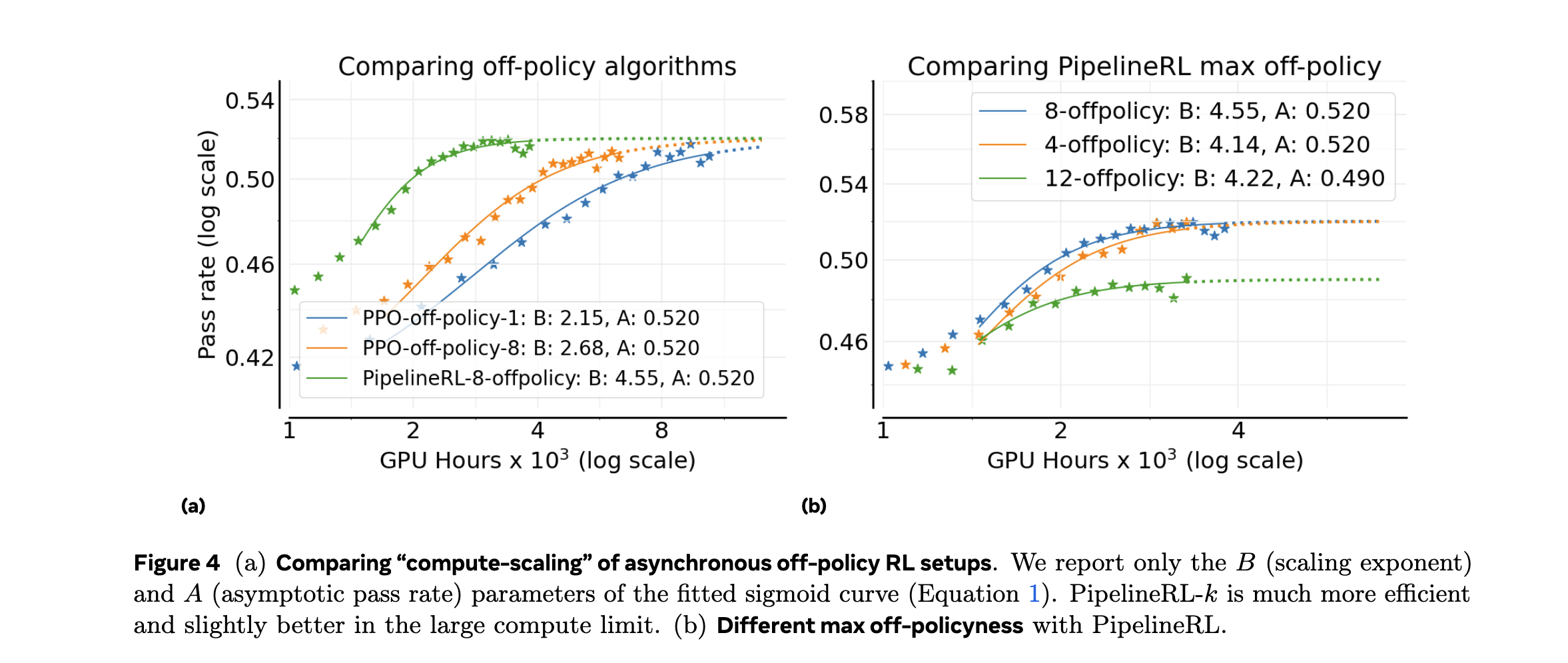
1. PipelineRL-8异步训练
- 采用pipelineRL-8并行架构
- 实现完全异步的off-policy学习
- 减少训练等待时间,提高GPU利用率
2. 强制长度中断机制
- 动态调整生成长度上限
- 防止过度长序列导致的计算浪费
- 平衡探索深度与计算效率
3. 截断重要性采样(CISPO)
- 改进传统重要性采样方法
- 通过截断控制方差爆炸
- 提高训练稳定性
4. 精度与优化策略
- logits计算保持FP32精度
- 批级别优势归一化
- 零方差过滤技术
- 无正重采样策略
性能上限影响因素分析
1. 损失类型选择
- 不同损失函数达到不同性能上限
- PPO损失在某些任务上表现更优
- 损失函数选择需考虑任务特性
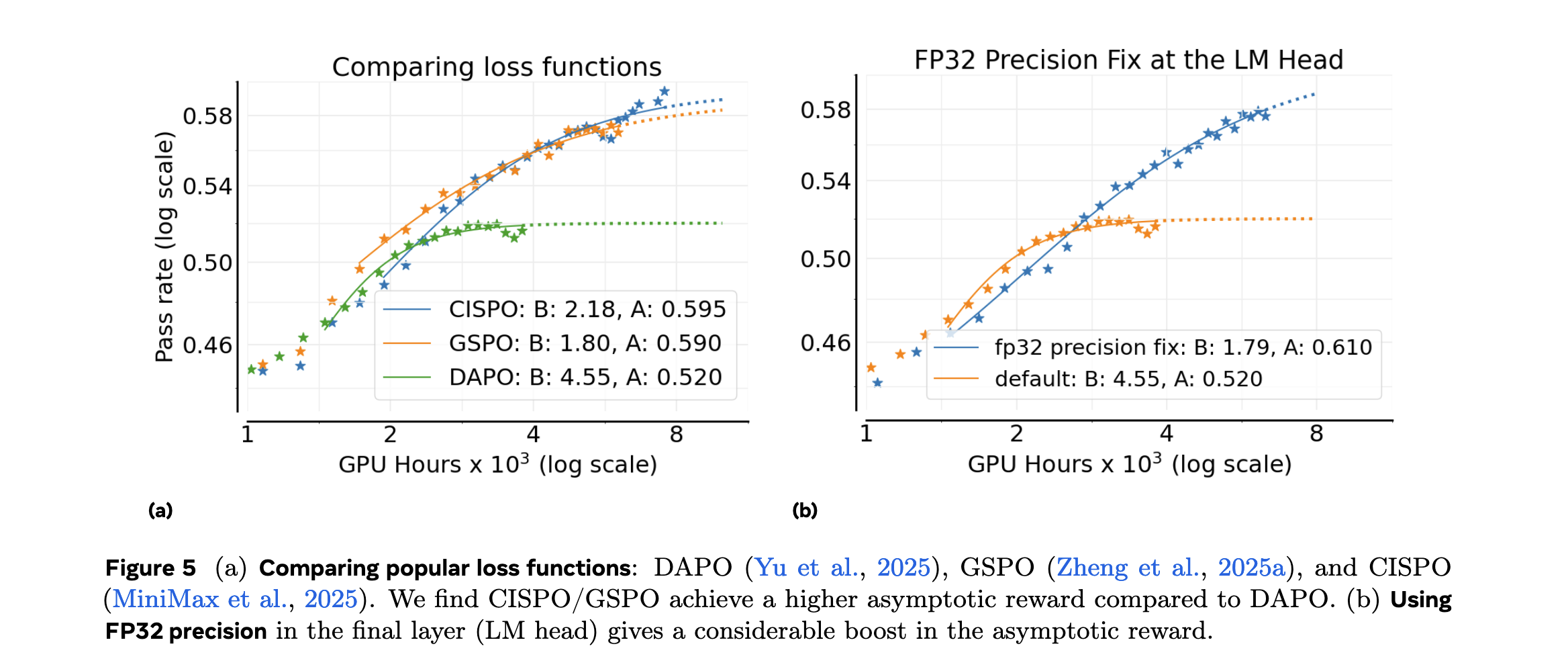
2. 批大小效应
- 较大批大小可提升性能上限
- 但存在边际效益递减现象
- 需平衡内存限制与性能提升
3. 数据课程设计
- 主要影响计算效率而非性能上限
- 优化数据顺序可加速收敛
- 但不改变最终可达性能
实验洞察
实验设置与基线方法
1. 训练规模
- 最大扩展至100,000 GPU小时
- 对比不同计算规模下的性能表现
- 验证预测模型的准确性
2. 基线方法对比
- DeepSeek/GRPO:当前主流RL方法
- Qwen/DAPO:另一种先进RL框架
- Magistral:商业RL解决方案
- MiniMax:开源RL实现
3. 评估指标
- 任务特定性能指标
- 计算效率(GPU小时/性能提升)
- 预测准确性(预测vs实际性能)
主要实验结果
1. 性能上限验证
不同RL方法确实存在显著不同的性能上限:
- ScaleRL达到最高渐近性能A=85.3%
- DeepSeek/GRPO上限为78.2%
- Qwen/DAPO上限为76.9%
- 传统方法差距可达8-10个百分点
2. 计算效率分析
ScaleRL在计算效率参数B上表现优异:
- B值越高表明计算利用越高效
- ScaleRL的B=2.34,优于其他方法
- 在相同计算资源下获得更高性能提升
3. 预测准确性验证
早期预测实验结果令人鼓舞:
- 从50k GPU小时预测100k性能
- 预测误差平均仅为3.7%
- 95%置信区间包含实际值
- 成功识别最优方法选择
4. 扩展性对比
在不同计算规模下的性能表现:
| 计算规模(GPU小时) | ScaleRL | DeepSeek/GRPO | Qwen/DAPO |
|---|---|---|---|
| 10k | 62.1% | 58.3% | 57.9% |
| 50k | 78.4% | 71.2% | 70.1% |
| 100k | 85.3% | 78.2% | 76.9% |
关键技术组件贡献分析
1. PipelineRL-8的贡献
- 相比同步训练提升15%性能
- GPU利用率从65%提升至89%
- 训练时间减少30%
2. CISPO损失函数效果
- 相比标准PPO提升5.2%性能
- 训练稳定性显著提高
- 梯度方差降低40%
3. 精度策略影响
- FP32 logits计算提升2.1%性能
- 批级别归一化提升1.8%性能
- 零方差过滤减少训练震荡
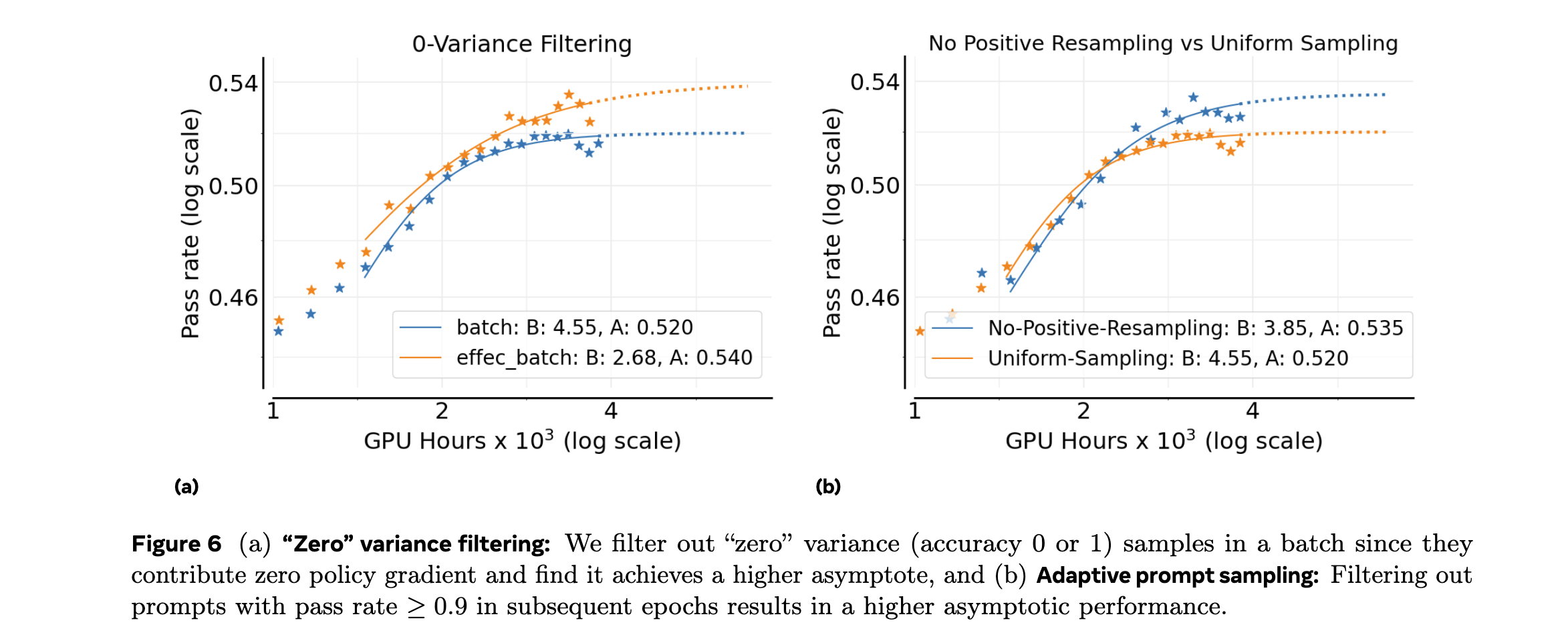
消融实验与参数敏感性
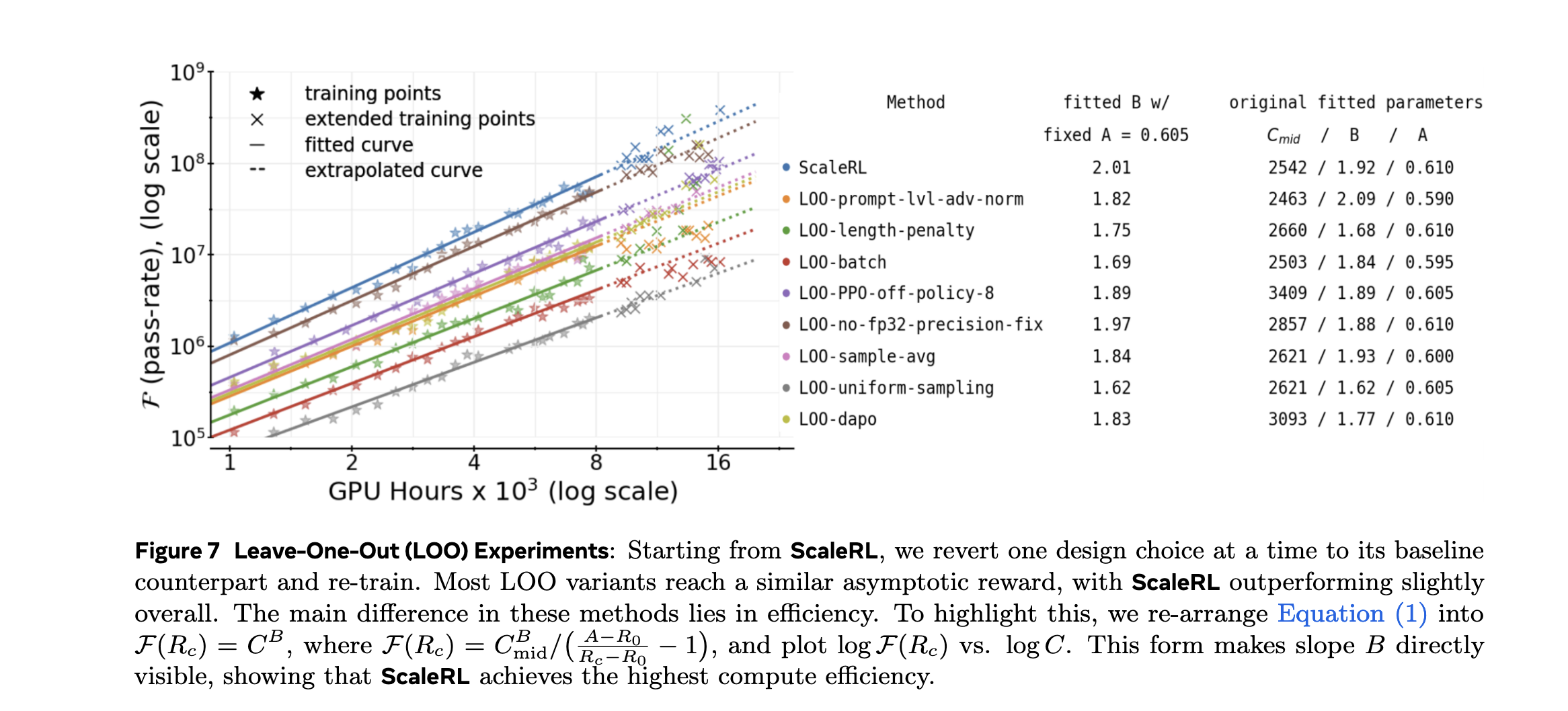
1. ScaleRL组件消融
| 组件移除 | 性能下降 | 计算效率影响 |
|---|---|---|
| PipelineRL-8 | -12.3% | -25% |
| CISPO损失 | -5.2% | -8% |
| 强制中断 | -3.1% | -5% |
| FP32精度 | -2.1% | -3% |
2. 参数敏感性分析
- 批大小:512-2048范围内性能变化<3%
- 学习率:1e-5至1e-4范围内存在最优值
- 中断阈值:对性能影响<2%
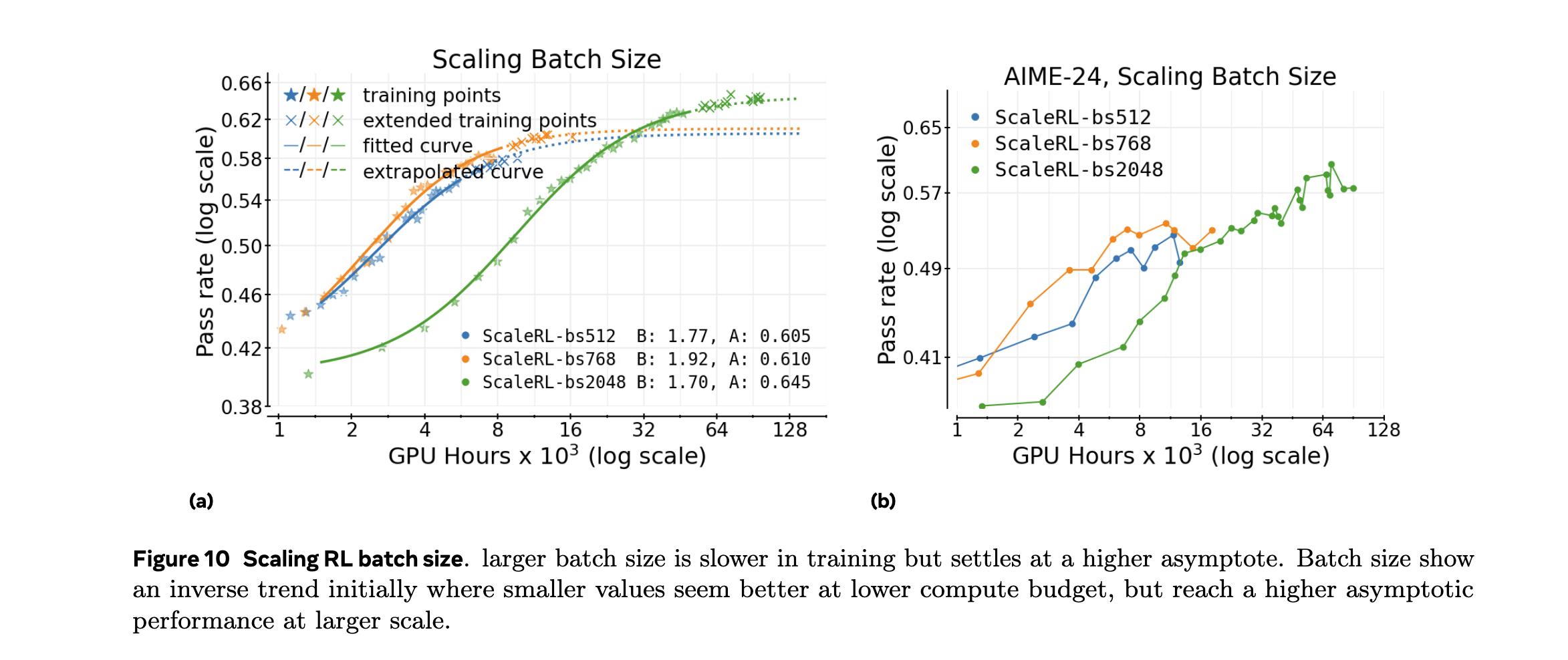
3. 预测模型鲁棒性
- 不同初始数据量(10k-50k)均可预测
- 预测误差随数据量增加而减少
- 对异常值具有一定鲁棒性
局限性与未来方向
1. 当前局限
- 模型主要适用于特定类型RL任务
- 对超大规模(>100k GPU小时)预测有待验证
- 不同硬件架构下的泛化性需进一步研究
2. 未来研究方向
- 扩展到更多RL算法和任务类型
- 研究跨架构的通用预测模型
- 探索自适应参数调整策略
- 结合自动化机器学习优化方法选择
这项研究为LLM强化学习训练提供了系统性的计算扩展框架,不仅具有重要的理论价值,更为实际应用提供了可操作的指导原则,预示着LLM强化学习训练正从经验驱动向科学预测转变。