《ARM64体系结构编程与实践》学习笔记(五)
高速缓存
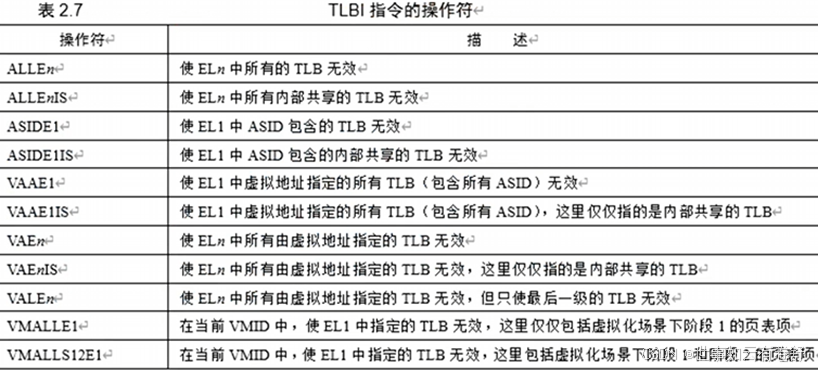
1.cache(armv8.6手册的B2.4、D4.4和D5.11章节),高速缓存的基本结构如下图所示:
- 地址:上图以32位地址为例,处理器访问高速缓存时的地址编码,分成3个部分,分别是偏移量(offset)域、索引域和标记(tag)域(tag其实就是访问目标地址的高位部分)
- 高速缓存行:高速缓存中最小的访问单元,包含一小段主存储器中的数据。常见的高速缓存行的大小是32字节或64字节
- 索引(index):高速缓存地址编码的一部分,用于索引和查找地址在高速缓存的哪一组中
- 组(set):由相同索引的高速缓存行组成
- 路(way):在组相连的高速缓存中,高速缓存分成大小相同的几个块,如上图中的每个4x4的矩形为一路,上图中共有4路
- 标记(tag):高速缓存地址编码的一部分,通常是高速缓存地址的高位部分,用于判断高速缓存行缓存的数据的地址是否和处理器寻找的地址一致
- 偏移量(offset):高速缓存行中的偏移量。处理器可以按字(word)或者字节(byte)来寻址高速缓存行的内容。
2.高速缓存cache所使用的地址可有以下三种情况:
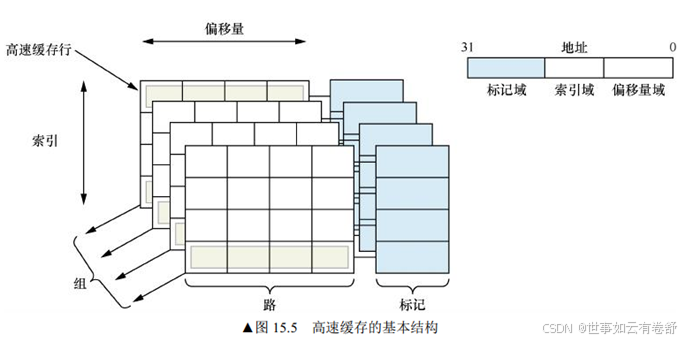
- 只使用物理地址(PIPT Physical index Physical Tag):使用物理地址索引域和物理地址的标记域相当于是物理高速缓存。使用物理高速缓存的缺点就是处理器在查询MMU和TLB后才能访问高速缓存,增加了流水线的延迟时间,如下图所示:
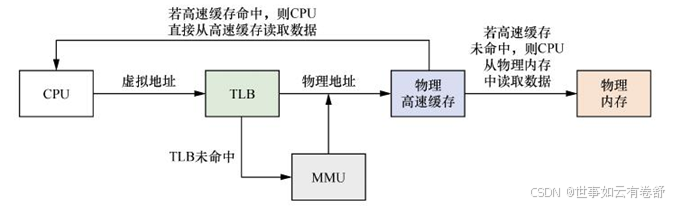
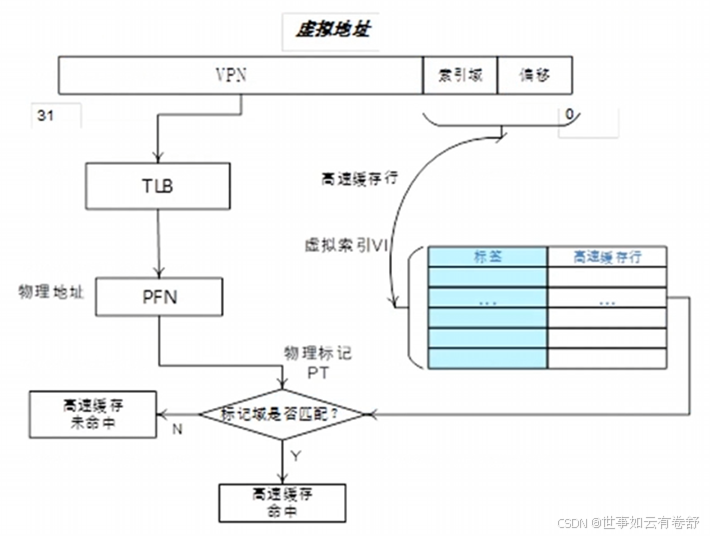
- 使用虚拟地址(VIVT Virtual Index Virtual Tag),使用虚拟地址的索引域和虚拟地址的标记域,相当于是虚拟高速缓存处理器在寻址时,首先把虚拟地址发送到高速缓存,若在高速缓存里找到需要的数据,就不再需要访问TLB和物理内存。如下图所示:
采用虚拟地址的高速缓存会引入重名问题和同名问题,重名问题:在操作系统中,多个不同的虚拟地址有可能映射相同的物理地址,由于采用虚拟高速缓存架构,那么这些不同的虚拟地址会占用高速缓存中不同的高速缓存行,但是它们对应的是相同的物理地址。举个例子,VA1和VA2都映射到PA,在cache中有两个cache line缓存了VA1和VA2当程序往VA1写入数据时,VA1对应的高速缓存行以及PA的内容会被更改,但是VA2还缓存着旧数据,这样一个物理地址在虚拟高速缓存中就保存了两份数据,这样会产生歧义。同名问题:相同的虚拟地址对应着不同的物理地址,因为操作系统中不同的进程会存在很多相同的虚拟地址,而这些相同的虚拟地址在经过MMU转换后得到不同的物理地址,这就产生了同名问题。同名问题最常见的地方是进程切换,当一个进程切换到另外一个进程时,新进程使用虚拟地址来访问高速缓存的话,新进程会访问到旧进程遗留下来的高速缓存,这些高速缓存数据对于新进程来说是错误和没用的。解决办法是在进程切换时把旧进程遗留下来的高速缓存都置为无效,这样就能保证新进程执行时得到一个干净的虚拟高速缓存。
- VIPT(Virtual Index Physical Tag):使用虚拟地址索引域和物理地址的标记域,这种方式也可能存在别名问题。在 ARMv8中,数据缓存通常是PIPT的,但也可能VIPT的。VIPT如下图所示:
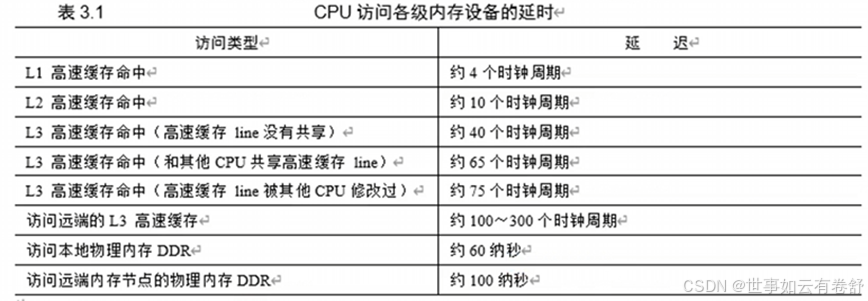
3.多级cache访问延迟如下表所示,表中的远端是指NUMA(Non-Uniform Memory Access,非一致性内存访问,NUMA是一种适用于多处理器系统的内存架构,在该架构下,内存被划分为多个节点,每个节点有自己的处理器和本地内存,参考ARM64体系结构编程与实践P226):
4.在ARM多核处理器架构中,SCU (Snoop Control Unit) 是一个关键组件,用于在多个处理器核心之间实现缓存一致性,它是保证数据一致性的重要硬件模块,尤其在支持多核共享内存的系统中。SCU不包含L1指令cache的一致性,SCU仅仅是一个cluster之内的cache一致性。
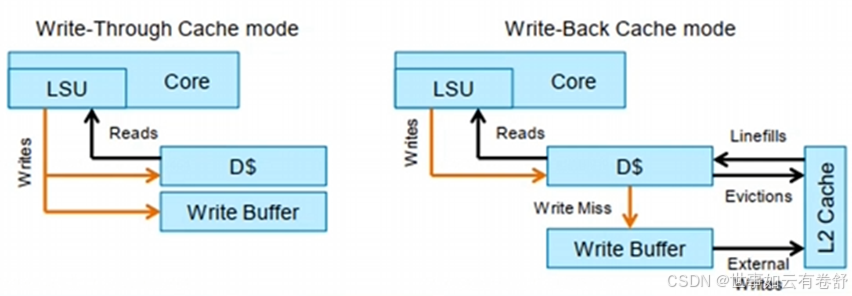
5.cache的策略可分为以下几种:首先分为cacheable和non-cacheable两类,cacheable类中又有以下相关的属性:read/write-allocate(当read/write miss的时候才分配一个新的cache line,如果当前cache中没有空闲的cache line,则根据替换算法进行替换)、write-back cacheable(回写模式,数据直接写入当前高速缓存,而不会继续传递,当该高速缓存行被替换出去时,被改写的数据才会更新到下一级高速缓存或主存储器中,该策略增加了高速缓存一致性的实现难度,但是有效降低了总线带宽需求,cache line会变成dirty data)、write-through cacheable(写直通模式,进行写操作时,数据同时写入当前的高速缓存、下一级高速缓存或主存储器中,写直通模式可以降低高速缓存一致性的实现难度,其最大的缺点是消耗比较多的总线带宽)、Shareability。
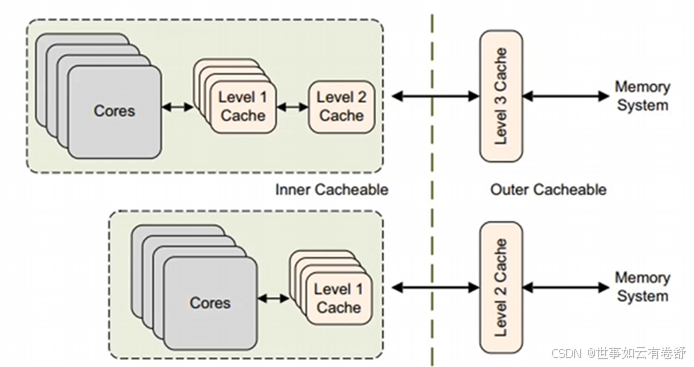
只有normal memory类型的内存才可以是cacheable的,device memory是无法被cache的。对于normal memory,可以设置为inner或者outer shareable的(device memory不存在这种说法),对于高速缓存cache到底是inner还是outer是根据具体设计来定的,但通常将CPU IP集成的caches视为inner,将通过BUS总线外接的cache视为outer,如下图所示(可参考ARMv8.6手册的B2.7.1节):
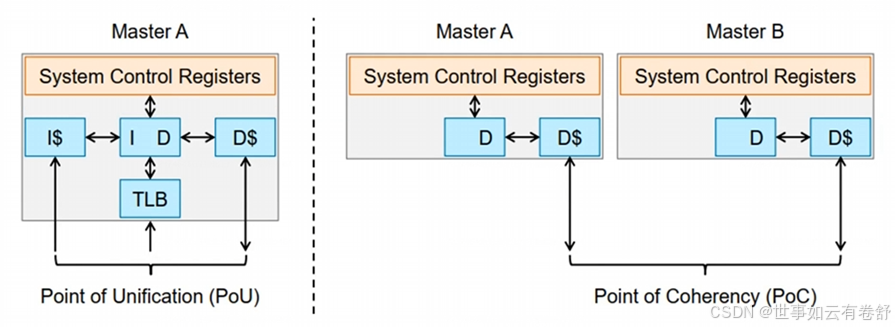
6.PoU(Point of Unification):表示一个CPU中的指令cache,数据cache还有MMU,TLB等看到的是同一份的内存拷贝。可以有两种角度来理解PoU,第一种是PoU for a PE,是说保证PE看到的I/D cache和MMU是同一份拷贝,大多数情况下,PoU是站在单核系统的角度来观察的;第二种是PoU for inner share,意思是说在inner share里面的所有PE都能看到相同的一份拷贝。PoC(Point of Coherency):系统中所有的观察者例如DSP,GPU,CPU,DMA等都能看到同一份内存拷贝。如下图所示(图中的Master即DSP,GPU,CPU,DMA等有能力访问内存的设备)。PoU和PoC主要对以虚拟地址(VA)为目标的缓存维护指令有意义,因为这些指令依赖于内存地址映射(通过MMU)来操作具体的缓存内容。以组(set)或路(way)为基础的缓存维护指令(如物理地址为目标的指令)直接操作特定缓存级别,而不考虑PoU或PoC。如下图:
7.Cache的维护:Cache的管理的操作包括以下三类:无效(invalidate)整个高速缓存或者某个高速缓存行。高速缓存上的数据会被丢弃;清除(clean)整个高速缓存或者某个高速缓存行。相应的高速缓存行会被标记为脏,数据会写回到下一级高速缓存中或者主存储器中;清零(zero)操作。Cache管理的对象可分为以下三类:ALL即整块高速缓存;VA即某个虚拟地址;set/way即特定的高速缓存行或者组和路。Cache管理的范围可分为上文提到的PoC和PoU。Cache命令的格式如下图所示:
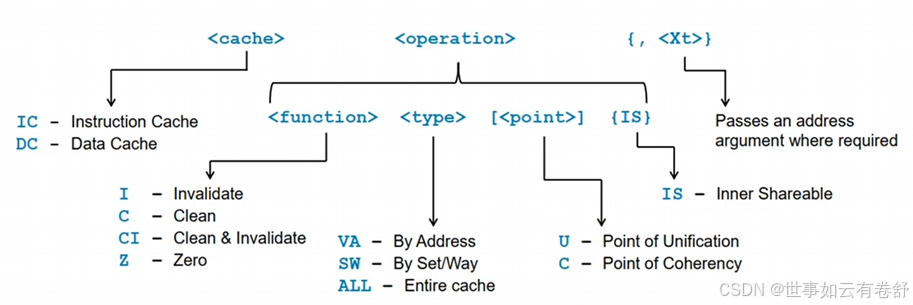
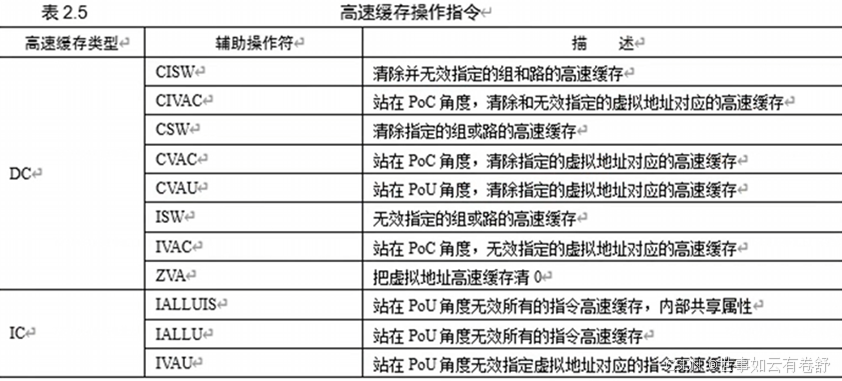
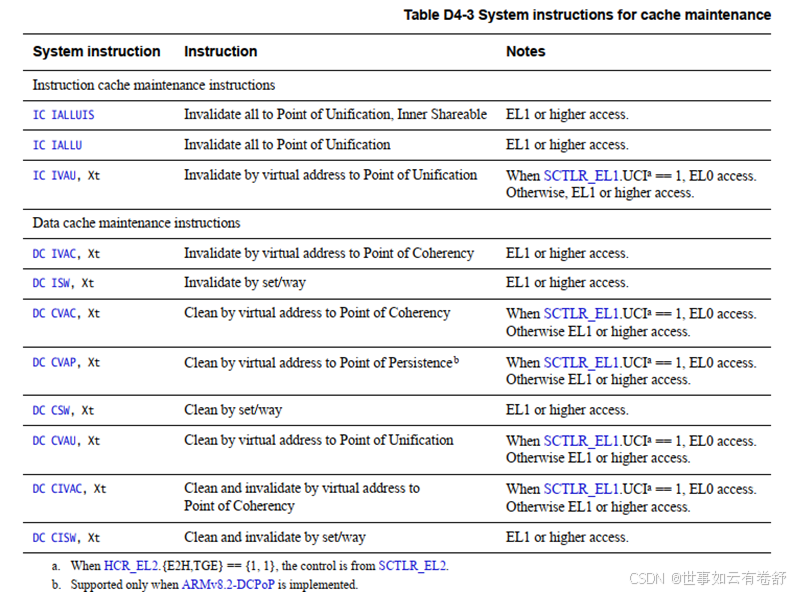
IC和DC分别表示针对指令Cache和数据Cache。function部分即Cache的管理的操作,CI是指先将对应的Cache写回下一级缓存或主存再使其失效。type部分即Cache管理的对象。后面的Xt寄存器可以传递一些参数,例如传递一个VA。ARMv8具体支持的Cache指令如下图所示(参考ARMv8.6手册第D4.4.8节)
8.当我们在做cache指令管理的时候,通常需要获取以下信息:系统支持多少级cache、cache line是多少、每一级cache它的set和way是多少、对于zero操作,多少data可以被zeroed,可通过下图所示的寄存器获取上述信息(参考ARM64体系结构编程与实践P243和实验15),先通过向CSSELR_EL1写入想要查询的cache,然后读取CCSIDR_EL1寄存器的值即可获取相关信息:

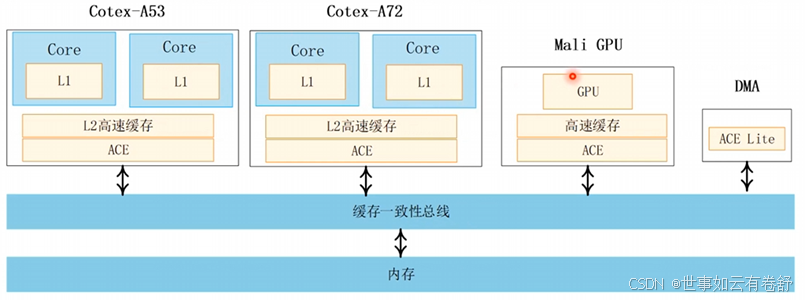
9.Cache一致性(armv8.6手册的B2.4章节):Cortex-A8是单核的,没有cache一致性问题,但是依然有CPU和DMA之间的一致性问题,它的cache管理指令仅仅作用于单核;Cortex-A9支持多核,硬件上支持cache一致性,它的cache管理指令会广播到其他CPU核心,Cortex-A15时开始出现大小核的架构,不仅要考虑一个cluster内各个核之间的cache一致性还要考虑各个cluster之间的一致性问题。如下图:
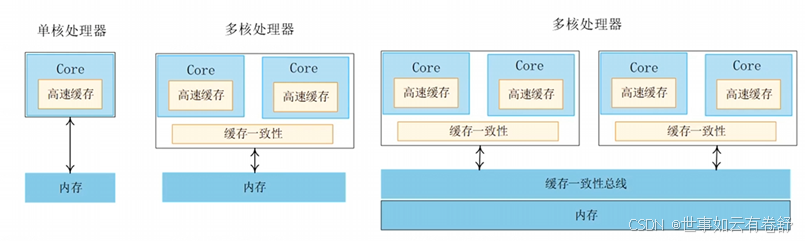
下图是一个大小核系统,共有两个簇,每个簇内的一致性由ACE实现(AXI Coherency Extensions,这是AMBA 4支持的协议),所有簇以及GPU、DMA等之间的一致性由缓存一致性总线实现:
cache一致性具体可通过下图所示的三种方式实现:

目前一般都是采取硬件维护cache一致性,对于简单的处理器,AMBA4提供了CCI实现系统级缓存一致性,如下图所示:

对于复杂的处理器,AMBA5提供了CCN实现系统级缓存一致性,如下图所示:

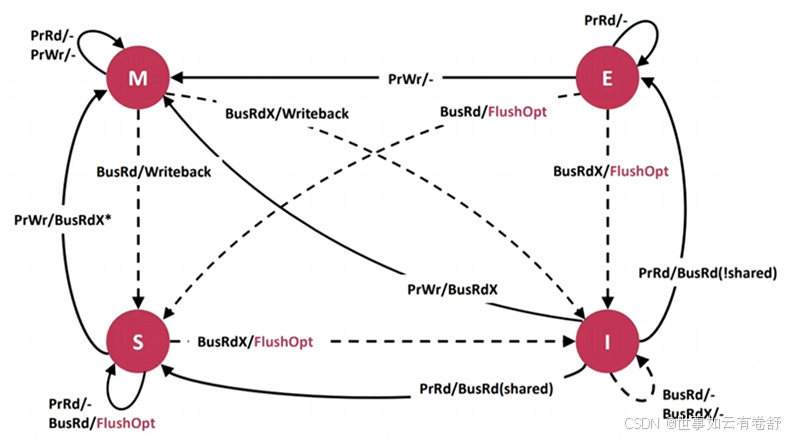
10.Cache一致性协议主要有以下两类:监听协议(snooping protocol):每个高速缓存都要被监听或者监听其他高速缓存的总线活动;目录协议(directory protocol):全局统一管理高速缓存状态。目前主要使用监听协议,1983年,James Goodman提出Write-0nce总线监听协议,后来演变成目前最流行的MESI协议。MESI协议给每个cache line定义了4个状态:修改(Modified)、独占(Exclusive)、共享(shared)、失效(Invalid),修改状态的数据是脏的,和内存不一致,脏的cache line后面会被写到内存,其后的状态变成共享态,如下图:
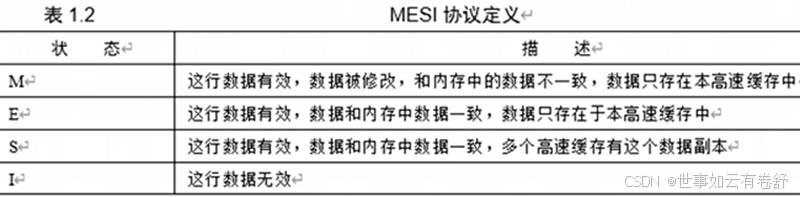
MESI协议有以下操作:
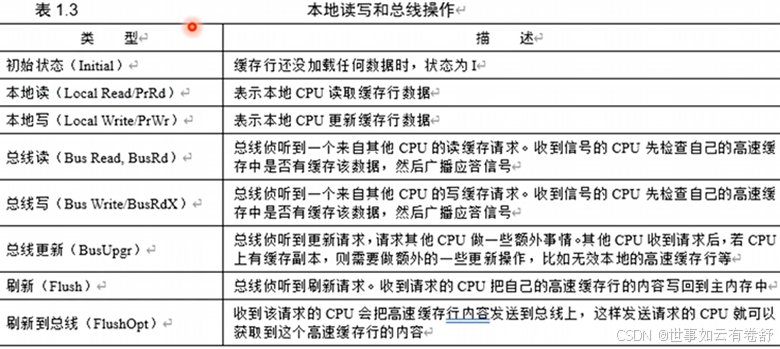
MESI协议状态图如下图所示,下图是针对单个当前处于不同状态的CPU在发出某个信号后可能成为的状态,或在收到相应信号之后如何进行应答,又可能转换为何种状态。其中实线表示主动发出信号,线上标注即发出的信号,主动发出的信号只能是PrRd或PrWr(根据当前状态可能会转换成BusRd或BusRdX信号)。虚线表示被动收到信号和应答,线上标注为接受信号/应答信号,Writeback表示将相应的缓存内容写回内存,FlashOpt表示将相应的缓存内容传播到总线上,虚线和实线可能有重合的情况:
11.高速缓存伪共享(Cache False Sharing)是一种性能瓶颈现象,发生在多核处理器的并行程序中。当多个线程或处理器核心访问共享的内存区域时,如果这些线程并非访问相同的变量,但它们访问的内存地址恰好位于同一个缓存行(Cache Line)内,就可能导致高速缓存伪共享。在现代处理器中,缓存行通常是64字节。当多个线程访问缓存行中的不同变量时,虽然这些变量彼此没有直接的共享关系,但由于它们位于同一个缓存行中,处理器会认为这些变量需要同步。这会导致处理器频繁地刷新缓存并引起内存访问延迟,从而降低程序性能。解决伪共享的常见方法包括:内存填充(Padding):在不同变量之间加入空白空间,确保它们不在同一个缓存行中;对齐数据:确保线程访问的变量对齐到缓存行的边界,避免多个线程访问同一个缓存行;减少共享内存的使用:尽可能使线程操作独立的内存区域。
12.DMA(Direct Memory Access,直接内存访问)缓存一致性问题是指当外部设备通过DMA直接访问内存时,可能会导致CPU高速缓存和内存之间的数据不一致。可通过以下方式解决:缓存刷新(Cache Flushing):在执行DMA操作之前,CPU需要确保缓存中的数据被写回到内存,以避免数据不一致;缓存失效(Cache Invalidation):在DMA操作完成后,CPU缓存中的数据可能需要失效(清除),以确保之后对该内存区域的访问能从主内存中获取最新的数据;非缓存区(Non-Cached Memory):在DMA传输过程中,可以将DMA操作涉及的内存区域标记为非缓存区域,这样可以避免缓存不一致问题,确保每次访问的数据都是从内存直接读取。
13.self-modifying code(自修改代码):是指程序在运行时修改自身的代码,这种代码通常会在执行过程中动态地改变程序的指令或数据,以便根据特定条件或需求调整其行为。指令cache和数据cache是分开的,指令cache一般是只读的。self-modifying code在执行过程中修改自己的指令时,会把要修改的指令加载到数据cache中,CPU修改新指令,所以数据cache中缓存了最新的指令,但此时旧指令还在指令cache中,造成不一致。解决思路为依次执行以下步骤:使用cache clean操作,把cache line的数据写回到内存、使用DSB指令保证其他观察者看到clean操作已经完成、无效指令cache、使用DSB指令确保其他观察者看到无效操作已经完成、使用ISB指令让程序重新预取指令(可参考armv8.6手册的B2.4.4节),如下图所示,图中第一句STR命令会造成data cache和指令cache不一致,后续的指令可解决这个不一致性的问题:

TLB
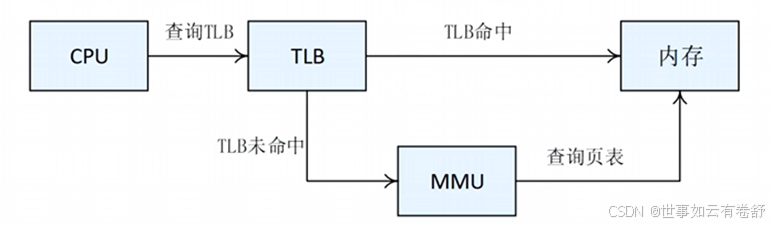
1.TLB(armv8.6手册的D5.9和D5.10章节),TLB是cache的一种,记录了最新使用的VA到PA的转换结果,如下图:
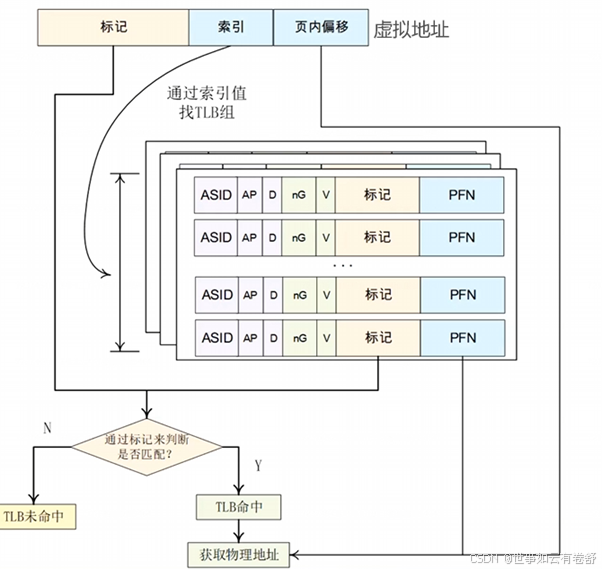
TLB也支持全相连、直接映射和组相连三种映射方式。下图为组相连示意图:
2.TLB(Translation Lookaside Buffer)同名问题:在使用虚拟内存管理的系统中,由于不同的进程或地址空间可以共享相同的虚拟地址,但它们映射到不同的物理地址时,可能会引发的缓存一致性或数据访问错误问题。如果在进程切换时,两个进程具有相同的虚拟地址,那么后面的进程可能会使用前面进程遗留在TLB中的虚拟地址到物理地址的转换表项,造成错误。以上问题可以通过ASID(Address Space Identifier)解决:内核空间是所有进程共享的空间,这部分空间的VA到PA的转换是不会变化的,用户地址空间是每个进程独立的地址空间,所以可以将TLB分为全局类型的TLB和进程独有类型的TLB,可以用ASID机制实现进程独有类型的TLB。
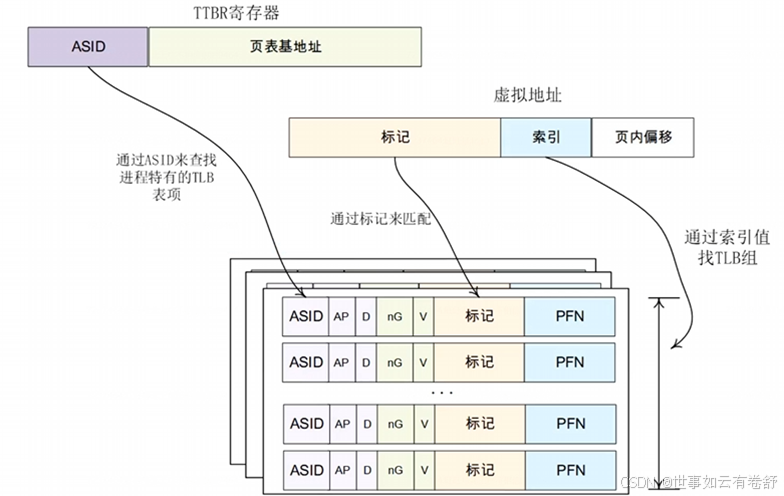
3.ARMv8的ASID是存储在TTBR0_EL1或TTBR1_EL1中的,具体存储在哪个寄存器中可以通过TCR寄存器的A1域进行设置,ASID支持8位或16位,分别支持256和65536个ID,当加入了ASID之后,在进行TLB查询时还要进行ASID匹配,如下图所示:
Linux内核里面的ASID:Linux内核里为每个进程分配两个ASID,即奇、偶数组成一对。当进程运行在用户态时,使用奇数ASID来查询TLB;当进程陷入内核态运行时,使用偶数ASID来查询TLB(参考ARM64体系结构编程与实践P279)。硬件ASID的分配通过位图来分配和管理,进程切换的时候,需要把进程持有的硬件ASID写入到TTBR1 EL1寄存器里。当系统中所有的硬件ASID加起来超过硬件最大值时会发生溢出,需要刷新全部TLB,然后重新分配硬件ASID。如下图所示:
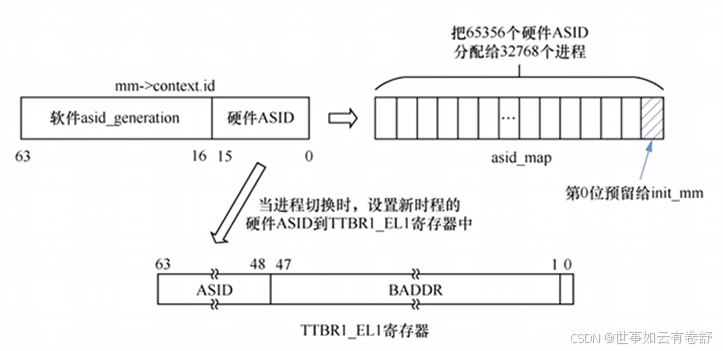
Linux使用两个ASID是为了安全考虑(即KPTI,Kernel Page Table Isolation),在使用KPTI机制之前,进程页表页表项中第11位nG位(TLB表项中也有对应的nG位)用来表示当前页是全局的(内核)还是进程独有的(用户),对于进程独有的页面在访问TLB时才需要查看ASID是否匹配。
4.ARMv8提供了TLBI指令,格式如下:TLBI <type><level>{IS} {,<Xt>},其中type可以取以下值(EL0没有独立的TLB,它通过EL1访问内核的映射;EL1、EL2和EL3都有各自的TLB,用于管理不同特权级别的内存映射):
- ALL-整个TLB
- VMALL-所有的TLB entry(stage 1, for current guest os)
- VMALLS12-所有的TLB entry(stage1&2 for current guest os)
- ASID-和ASID匹配的TLB entry,ASID由Xt寄存器来指定
- VA-虚拟地址指定的TLB entry,Xt指定虚拟地址以及ASID
- VAA-虚拟地址指定的TLB entry,Xt指定了虚拟地址,但是不包括ASID
level为En,即异常等级(n可以是1、2或3),IS表示inner share,Xt是由虚拟地址和ASID组成的参数,其中Bit[63:48]是ASID,Bit[47:44]是TTL,用于指明使哪一级的页表保存的地址无效,若为0表示需要使所有级别的页表无效,Bit[43:0]是虚拟地址的Bit[55:12]。具体如下图所示: