【完整源码+数据集+部署教程】【天线&其他】月球表面状况检测系统源码&数据集全套:改进yolo11-unireplknet
背景意义
随着人类对月球探索的不断深入,了解月球表面的状况变得愈发重要。月球表面存在着多种地形特征,如巨石、陨石坑和平坦地带,这些特征不仅影响着未来的探测任务和人类登陆计划,也对科学研究和资源开发具有重要意义。因此,建立一个高效、准确的月球表面状况检测系统显得尤为必要。传统的图像处理方法在复杂环境下的表现往往不尽如人意,尤其是在处理大量图像数据时,手动标注和分析的效率低下,且容易受到人为因素的影响。
为了解决这一问题,基于改进YOLOv11的月球表面状况检测系统应运而生。YOLO(You Only Look Once)系列模型以其高效的实时目标检测能力而受到广泛关注,尤其是在处理复杂场景时展现出良好的性能。通过对YOLOv11进行改进,结合917张标注图像的数据集,系统能够有效识别和分类月球表面的主要特征,包括巨石、陨石坑和平坦地带。这些类别的准确检测不仅能够为科学家提供关于月球地形的第一手资料,还能为未来的探测任务提供重要的决策支持。
此外,随着人工智能技术的不断发展,基于深度学习的目标检测方法在各个领域的应用日益广泛。将这一技术应用于月球表面状况检测,不仅能够提升探测效率,还能推动相关技术的进步与创新。因此,本研究不仅具有重要的科学价值,也为未来的月球探测任务提供了技术保障,具有深远的意义。通过构建这样一个系统,我们希望能够为月球探索提供更为精准的数据支持,助力人类在太空探索的征程中迈出更坚实的一步。
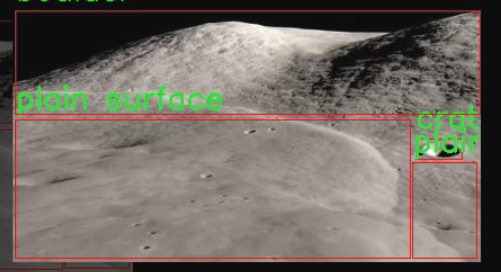
图片效果
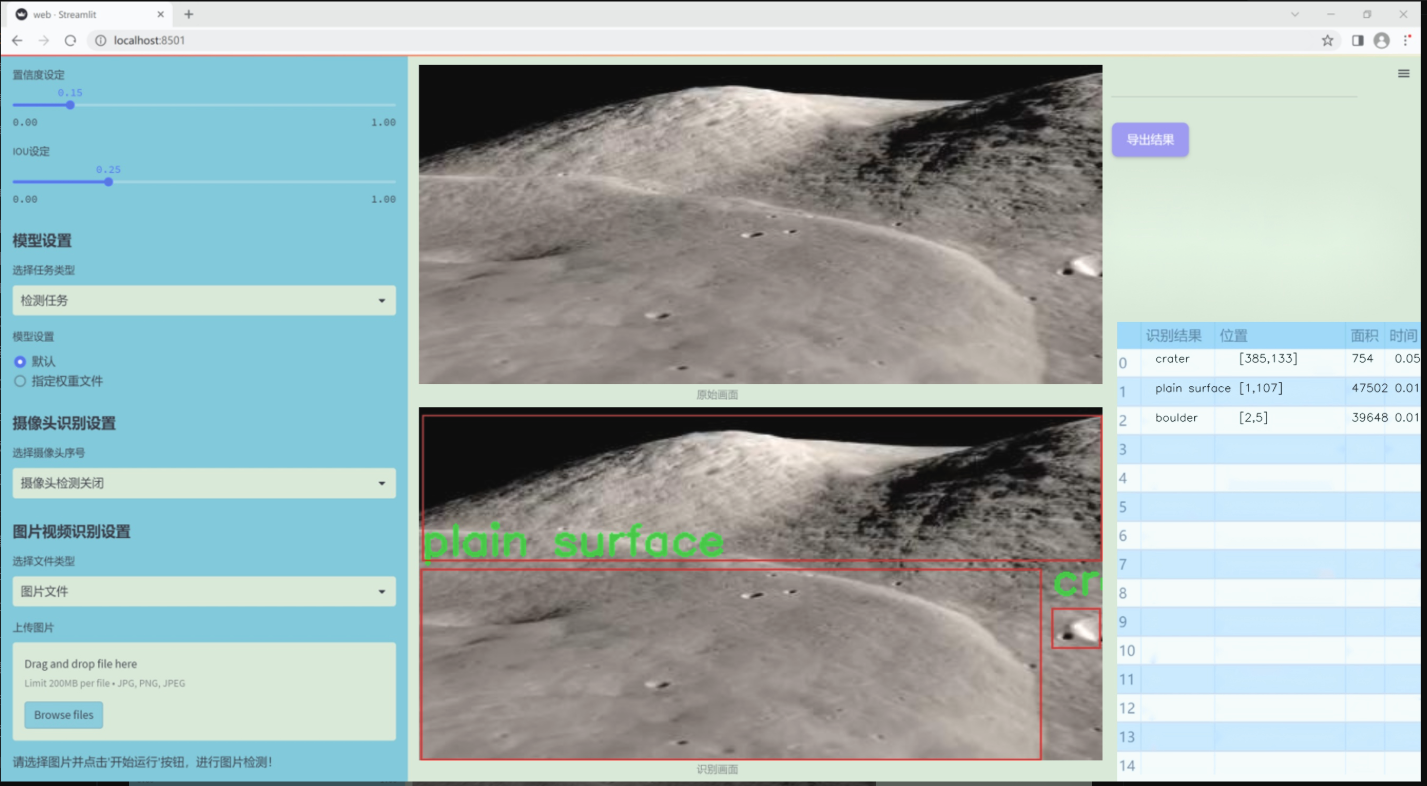
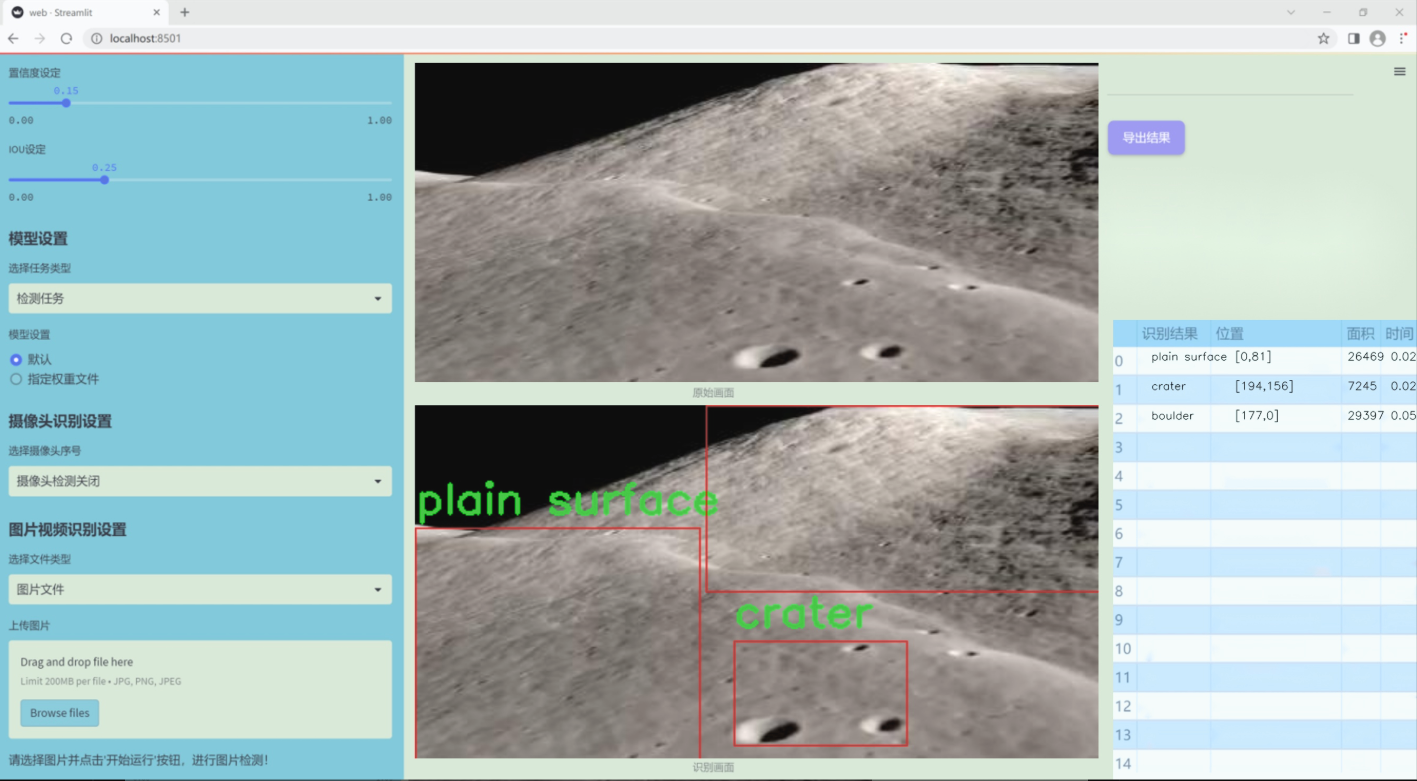
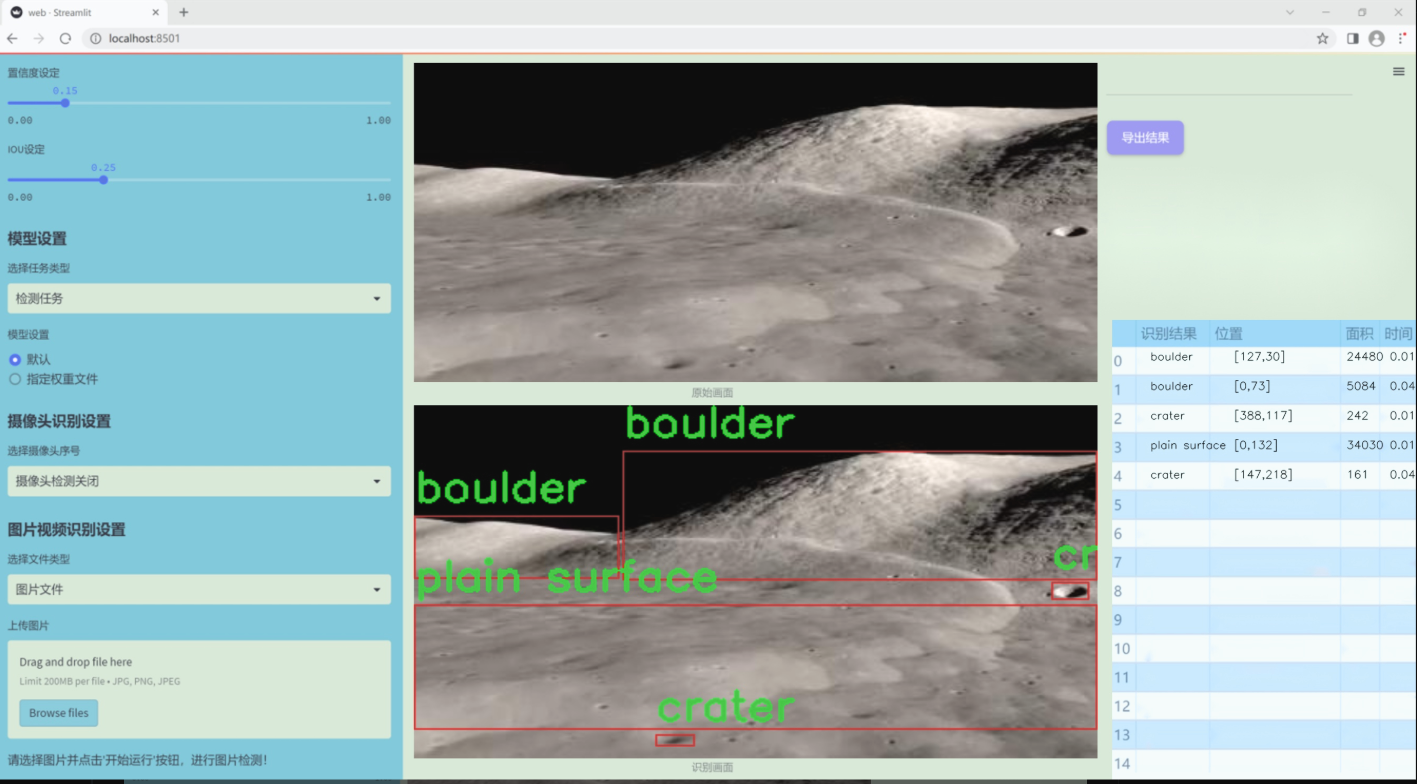
数据集信息
本项目所使用的数据集名为“Hazard Detection”,旨在为改进YOLOv11的月球表面状况检测系统提供支持。该数据集专注于月球表面的不同地形特征,涵盖了三种主要类别:岩石(boulder)、陨石坑(crater)和平坦表面(plain surface)。这些类别的选择基于月球表面的典型特征,能够有效地帮助模型识别和分类不同的地形状况,从而提升探测精度和可靠性。
数据集中包含大量经过精心标注的图像,确保每一类地形都得到了充分的代表性。岩石类图像展示了月球表面上各种大小和形状的岩石,陨石坑类则涵盖了不同深度和直径的坑洞,而平坦表面类则提供了广阔的、相对均匀的地形视图。这种多样性不仅有助于模型学习到各类特征的细微差别,还能增强其在实际应用中的适应能力。
在数据集的构建过程中,研究团队采取了严格的质量控制措施,确保每一张图像的标注准确无误。此外,数据集还经过了多次扩展和优化,以应对不同光照条件和视角变化对模型训练的影响。通过这种方式,数据集不仅为YOLOv11提供了丰富的训练样本,也为后续的模型评估和性能提升奠定了坚实的基础。
综上所述,“Hazard Detection”数据集的设计和构建充分考虑了月球表面状况检测的实际需求,力求为改进YOLOv11提供高质量的训练数据,推动月球探测技术的发展与应用。



核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
class KACNConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, dropout=0.0):
super(KACNConvNDLayer, self).init()
# 初始化参数self.inputdim = input_dim # 输入维度self.outdim = output_dim # 输出维度self.degree = degree # 多项式的阶数self.kernel_size = kernel_size # 卷积核大小self.padding = padding # 填充self.stride = stride # 步幅self.dilation = dilation # 膨胀self.groups = groups # 分组卷积的组数self.ndim = ndim # 数据的维度(1D, 2D, 3D)self.dropout = None # Dropout层初始化为None# 如果dropout大于0,则根据维度选择相应的Dropout层if dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 检查groups参数的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 为每个组创建归一化层self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 创建多项式卷积层self.poly_conv = nn.ModuleList([conv_class((degree + 1) * input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 注册一个缓冲区,用于存储多项式的阶数arange_buffer_size = (1, 1, -1,) + tuple(1 for _ in range(ndim))self.register_buffer("arange", torch.arange(0, degree + 1, 1).view(*arange_buffer_size))# 使用Kaiming均匀分布初始化卷积层的权重for conv_layer in self.poly_conv:nn.init.normal_(conv_layer.weight, mean=0.0, std=1 / (input_dim * (degree + 1) * kernel_size ** ndim))def forward_kacn(self, x, group_index):# 前向传播过程x = torch.tanh(x) # 应用tanh激活函数x = x.acos().unsqueeze(2) # 计算反余弦并增加一个维度x = (x * self.arange).flatten(1, 2) # 乘以阶数并展平x = x.cos() # 计算余弦x = self.poly_conv[group_index](x) # 通过对应的卷积层x = self.layer_norm[group_index](x) # 归一化if self.dropout is not None:x = self.dropout(x) # 应用dropoutreturn xdef forward(self, x):# 主前向传播函数split_x = torch.split(x, self.inputdim // self.groups, dim=1) # 按组分割输入output = []for group_ind, _x in enumerate(split_x):y = self.forward_kacn(_x.clone(), group_ind) # 对每个组进行前向传播output.append(y.clone()) # 保存输出y = torch.cat(output, dim=1) # 将所有组的输出拼接return y
代码说明:
KACNConvNDLayer:这是一个通用的卷积层类,支持任意维度的卷积(1D, 2D, 3D)。它通过多项式卷积和归一化来处理输入数据。
初始化参数:在构造函数中,初始化输入输出维度、卷积参数、分组数等,并创建相应的卷积和归一化层。
前向传播:forward_kacn方法实现了对输入数据的处理,包括激活、反余弦变换、卷积和归一化等步骤。forward方法则负责将输入分组并调用forward_kacn进行处理,最后将所有组的输出拼接在一起。
这个程序文件定义了一个名为 kacn_conv.py 的深度学习模块,主要实现了一个具有多项式卷积特性的神经网络层。文件中包含了一个基类 KACNConvNDLayer 和三个子类 KACNConv3DLayer、KACNConv2DLayer 和 KACNConv1DLayer,分别用于处理三维、二维和一维卷积。
在 KACNConvNDLayer 类的构造函数中,初始化了一些卷积层的参数,包括输入和输出维度、卷积核大小、分组数、填充、步幅、扩张、丢弃率等。根据传入的 dropout 参数,决定是否使用 dropout 层,并根据维度选择相应的 dropout 类型。构造函数还检查了分组数的有效性,并确保输入和输出维度可以被分组数整除。
该类使用 ModuleList 来存储分组的归一化层和多项式卷积层。多项式卷积层的权重使用 Kaiming 正态分布初始化,以帮助网络更好地收敛。
forward_kacn 方法实现了前向传播的具体逻辑。首先对输入进行激活处理,然后进行线性变换,接着通过多项式卷积层和归一化层进行处理,最后如果有 dropout,则应用 dropout。这个方法的输入包括数据和当前的分组索引。
forward 方法负责处理输入数据,将其按分组拆分,然后对每个分组调用 forward_kacn 方法进行处理,最后将所有分组的输出拼接在一起。
子类 KACNConv3DLayer、KACNConv2DLayer 和 KACNConv1DLayer 继承自 KACNConvNDLayer,分别为三维、二维和一维卷积层提供了特定的构造函数,使用相应的卷积和归一化类。
总体而言,这个模块实现了一个灵活的卷积层,可以处理不同维度的数据,并通过多项式卷积和归一化层来增强模型的表达能力。
10.3 val.py
以下是经过简化和注释的核心代码部分,主要保留了与YOLO模型验证相关的功能和流程:
import os
import torch
from ultralytics.engine.validator import BaseValidator
from ultralytics.utils import LOGGER, ops
from ultralytics.utils.metrics import DetMetrics, box_iou
from ultralytics.utils.plotting import output_to_target, plot_images
class DetectionValidator(BaseValidator):
“”"
扩展自BaseValidator类,用于基于检测模型的验证。
“”"
def __init__(self, dataloader=None, save_dir=None, args=None):"""初始化检测模型所需的变量和设置。"""super().__init__(dataloader, save_dir, args)self.metrics = DetMetrics(save_dir=self.save_dir) # 初始化检测指标self.iouv = torch.linspace(0.5, 0.95, 10) # mAP@0.5:0.95的IoU向量self.niou = self.iouv.numel() # IoU数量def preprocess(self, batch):"""预处理YOLO训练的图像批次。"""batch["img"] = batch["img"].to(self.device, non_blocking=True) # 将图像转移到设备batch["img"] = batch["img"].float() / 255 # 归一化图像for k in ["batch_idx", "cls", "bboxes"]:batch[k] = batch[k].to(self.device) # 将其他数据转移到设备return batchdef postprocess(self, preds):"""对预测输出应用非极大值抑制(NMS)。"""return ops.non_max_suppression(preds,self.args.conf,self.args.iou,multi_label=True,max_det=self.args.max_det,)def update_metrics(self, preds, batch):"""更新检测指标。"""for si, pred in enumerate(preds):npr = len(pred) # 当前预测数量pbatch = self._prepare_batch(si, batch) # 准备当前批次的数据cls, bbox = pbatch.pop("cls"), pbatch.pop("bbox") # 获取真实标签if npr == 0:continue # 如果没有预测,跳过predn = self._prepare_pred(pred, pbatch) # 准备预测数据stat = {"conf": predn[:, 4], # 置信度"pred_cls": predn[:, 5], # 预测类别"tp": self._process_batch(predn, bbox, cls) # 计算真正例}self.stats["tp"].append(stat["tp"]) # 更新统计信息def get_stats(self):"""返回指标统计信息和结果字典。"""stats = {k: torch.cat(v, 0).cpu().numpy() for k, v in self.stats.items()} # 转换为numpyif len(stats) and stats["tp"].any():self.metrics.process(**stats) # 处理指标return self.metrics.results_dict # 返回结果字典def plot_predictions(self, batch, preds, ni):"""在输入图像上绘制预测的边界框并保存结果。"""plot_images(batch["img"],*output_to_target(preds, max_det=self.args.max_det),paths=batch["im_file"],fname=self.save_dir / f"val_batch{ni}_pred.jpg",names=self.names,)def _process_batch(self, detections, gt_bboxes, gt_cls):"""返回正确的预测矩阵。"""iou = box_iou(gt_bboxes, detections[:, :4]) # 计算IoUreturn self.match_predictions(detections[:, 5], gt_cls, iou) # 匹配预测与真实标签def save_one_txt(self, predn, save_conf, shape, file):"""将YOLO检测结果保存到txt文件中。"""gn = torch.tensor(shape)[[1, 0, 1, 0]] # 归一化增益for *xyxy, conf, cls in predn.tolist():xywh = (ops.xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # 转换为归一化的xywhline = (cls, *xywh, conf) if save_conf else (cls, *xywh) # 格式化标签with open(file, "a") as f:f.write(("%g " * len(line)).rstrip() % line + "\n") # 写入文件
代码注释说明
DetectionValidator类:这是一个用于YOLO模型验证的类,继承自BaseValidator。
__init__方法:初始化类的实例,设置必要的变量和指标。
preprocess方法:对输入的图像批次进行预处理,包括数据转移和归一化。
postprocess方法:应用非极大值抑制,减少重叠的预测框。
update_metrics方法:更新检测指标,计算真正例和其他统计信息。
get_stats方法:返回当前的指标统计信息。
plot_predictions方法:将预测结果绘制在图像上并保存。
_process_batch方法:计算IoU并匹配预测与真实标签。
save_one_txt方法:将检测结果保存为txt文件,便于后续分析和使用。
以上是代码的核心部分和详细注释,帮助理解YOLO模型的验证过程。
这个程序文件 val.py 是一个用于目标检测模型验证的类,主要基于 Ultralytics YOLO 框架。该文件包含了 DetectionValidator 类,该类继承自 BaseValidator,用于处理目标检测任务的验证过程。
在初始化方法中,类的构造函数设置了一些必要的变量和参数,包括数据加载器、保存目录、进度条、参数和回调函数。它还定义了一些用于计算指标的变量,比如 DetMetrics 对象用于存储检测指标,iouv 是一个表示不同 IoU(Intersection over Union)阈值的张量。
preprocess 方法负责对输入的图像批次进行预处理,包括将图像转换为适合模型输入的格式,并根据需要进行归一化。该方法还处理了自动标注的相关逻辑。
init_metrics 方法用于初始化评估指标,判断数据集是否为 COCO 格式,并设置相关的类映射和统计信息。
get_desc 方法返回一个格式化的字符串,用于总结模型的类指标。
postprocess 方法应用非极大值抑制(NMS)来处理模型的预测输出,以去除冗余的检测框。
_prepare_batch 和 _prepare_pred 方法分别用于准备输入批次和预测结果,以便于后续的指标计算。
update_metrics 方法用于更新当前批次的指标统计,包括计算真阳性、预测类别等,并根据需要保存预测结果到文件。
finalize_metrics 方法设置最终的指标值,包括速度和混淆矩阵。
get_stats 方法返回计算后的指标统计结果,并更新每个类别的目标数量。
print_results 方法打印训练或验证集的每个类别的指标结果,并根据需要绘制混淆矩阵。
_process_batch 方法计算正确的预测矩阵,返回 IoU 计算结果。
build_dataset 和 get_dataloader 方法用于构建数据集和数据加载器,方便后续的验证过程。
plot_val_samples 和 plot_predictions 方法用于绘制验证样本和预测结果,便于可视化分析。
save_one_txt 和 pred_to_json 方法分别用于将检测结果保存为文本文件和 COCO 格式的 JSON 文件,以便于后续的评估和分析。
eval_json 方法用于评估 YOLO 输出的 JSON 格式结果,并返回性能统计信息,支持使用 pycocotools 进行 mAP(mean Average Precision)评估。
总体而言,这个文件实现了一个完整的目标检测模型验证流程,包括数据预处理、指标计算、结果保存和可视化等功能。
10.4 fast_kan_conv.py
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn as nn
定义径向基函数类
class RadialBasisFunction(nn.Module):
def init(self, grid_min: float = -2., grid_max: float = 2., num_grids: int = 8, denominator: float = None):
super().init()
# 在指定范围内生成均匀分布的网格点
grid = torch.linspace(grid_min, grid_max, num_grids)
self.grid = torch.nn.Parameter(grid, requires_grad=False) # 将网格点设置为不可训练的参数
# 设置分母,控制基函数的平滑程度
self.denominator = denominator or (grid_max - grid_min) / (num_grids - 1)
def forward(self, x):# 计算径向基函数的输出return torch.exp(-((x[..., None] - self.grid) / self.denominator) ** 2)
定义快速KAN卷积层基类
class FastKANConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, input_dim, output_dim, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, grid_size=8, base_activation=nn.SiLU, grid_range=[-2, 2], dropout=0.0):
super(FastKANConvNDLayer, self).init()
# 初始化参数
self.inputdim = input_dim
self.outdim = output_dim
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.dilation = dilation
self.groups = groups
self.ndim = ndim
self.grid_size = grid_size
self.base_activation = base_activation() # 基础激活函数
self.grid_range = grid_range
# 验证输入参数的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 创建基础卷积层和样条卷积层self.base_conv = nn.ModuleList([conv_class(input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])self.spline_conv = nn.ModuleList([conv_class(grid_size * input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 创建归一化层self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 初始化径向基函数self.rbf = RadialBasisFunction(grid_range[0], grid_range[1], grid_size)# 初始化 dropout 层self.dropout = Noneif dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)if ndim == 2:self.dropout = nn.Dropout2d(p=dropout)if ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 使用 Kaiming 均匀分布初始化卷积层权重for conv_layer in self.base_conv:nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')for conv_layer in self.spline_conv:nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')def forward_fast_kan(self, x, group_index):# 对输入应用基础激活函数并进行线性变换base_output = self.base_conv[group_index](self.base_activation(x))if self.dropout is not None:x = self.dropout(x) # 应用 dropout# 计算样条基函数spline_basis = self.rbf(self.layer_norm[group_index](x))spline_basis = spline_basis.moveaxis(-1, 2).flatten(1, 2) # 调整维度以适应卷积spline_output = self.spline_conv[group_index](spline_basis) # 通过样条卷积层x = base_output + spline_output # 合并基础输出和样条输出return xdef forward(self, x):# 将输入分割为多个组split_x = torch.split(x, self.inputdim // self.groups, dim=1)output = []for group_ind, _x in enumerate(split_x):y = self.forward_fast_kan(_x.clone(), group_ind) # 对每个组进行前向传播output.append(y.clone())y = torch.cat(output, dim=1) # 合并所有组的输出return y
代码说明:
RadialBasisFunction:定义了一个径向基函数,用于计算输入与预定义网格点之间的关系,输出为基于高斯函数的值。
FastKANConvNDLayer:这是一个通用的卷积层类,支持多维卷积(1D、2D、3D),包含基础卷积和样条卷积的实现。它还支持归一化和dropout操作。
forward_fast_kan:实现了快速KAN卷积的前向传播逻辑,首先通过基础卷积处理输入,然后通过样条卷积处理归一化后的输入,最后将两者的输出相加。
forward:将输入数据分割成多个组,并对每个组调用forward_fast_kan进行处理,最后将所有组的输出合并。
这个程序文件定义了一个用于快速卷积神经网络的模块,主要包括一个径向基函数(Radial Basis Function)和一个快速KAN卷积层(FastKANConvNDLayer),以及其一维、二维和三维的具体实现类。首先,径向基函数类RadialBasisFunction用于生成一组基函数,其输入是一个范围和数量的参数。这个类的forward方法计算输入值与基函数之间的关系,返回一个经过高斯函数处理的结果。
接下来,FastKANConvNDLayer类是一个通用的卷积层实现,支持多维卷积。它的构造函数接受多个参数,包括输入和输出维度、卷积核大小、分组数、填充、步幅、扩张率等。这个类内部创建了基础卷积层和样条卷积层,分别用于处理输入数据和经过径向基函数变换后的数据。它还包含了层归一化和可选的dropout层,用于防止过拟合。
在forward方法中,输入数据首先被分割成多个组,然后对每个组应用forward_fast_kan方法进行处理。这个方法先对输入应用基础激活函数,再通过基础卷积层进行线性变换。接着,经过层归一化和径向基函数的处理后,得到样条基函数的输出,最后将基础输出和样条输出相加,形成最终的输出。
此外,FastKANConv3DLayer、FastKANConv2DLayer和FastKANConv1DLayer类分别继承自FastKANConvNDLayer,用于实现三维、二维和一维的卷积操作。这些类在初始化时指定了相应的卷积和归一化层,确保可以处理不同维度的数据。
整体来看,这个文件实现了一个灵活且高效的卷积神经网络模块,适用于多种输入维度,并通过径向基函数的使用增强了模型的表达能力。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻