Llama-2-7b在昇腾NPU上的六大核心场景性能基准报告

引言
随着大语言模型(LLM)技术的飞速发展,其底层算力支撑硬件的重要性日益凸显。传统的GPU方案之外,以华为昇腾(Ascend)为代表的NPU(神经网络处理单元)正成为业界关注的焦点。为了全面评估昇腾NPU在实际LLM应用中的性能表现,我们进行了一项针对性的深度测评。本次测评选用业界广泛应用的开源模型Llama-2-7b,在昇腾NPU平台上进行部署、测试与分析,旨在为开发者和决策者提供一份详实的核心性能数据、具体的场景适配建议以及可靠的硬件选型参考。
一、 测评环境搭建与准备
扎实的前期准备是确保测评数据准确可靠的基石。本章节将详细记录从激活昇腾NPU计算环境到完成所有依赖库安装的全过程。
1.1 激活NPU Notebook实例
我们通过GitCode平台进行本次操作 。首先,需要进入项目环境并激活一个Notebook实例,这是进行一切操作的起点。
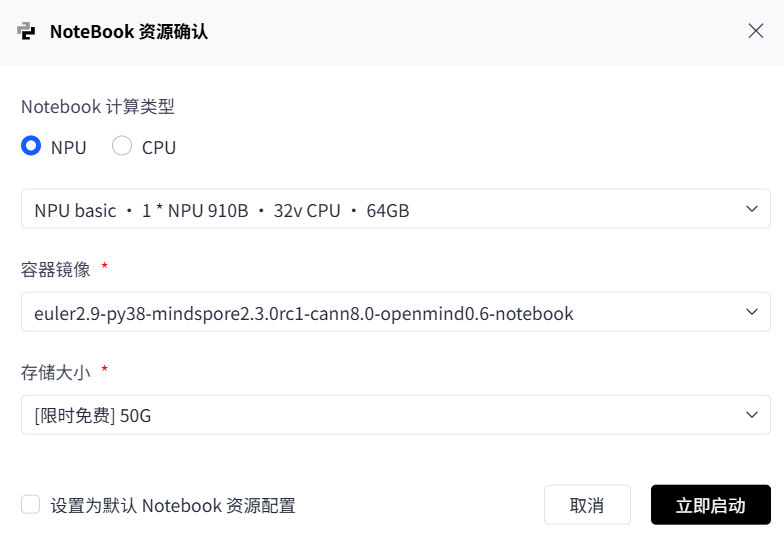
在配置实例时,我们明确了本次测评的硬件规格,这对后续性能数据的解读至关重要:
- 计算类型: NPU
- 硬件规格: NPU basic · 1*NPU 910B · 32v CPU · 64GB
- 存储大小: 50G (限时免费)
配置确认无误后,点击“立即启动”,系统开始分配资源。数分钟后,一个搭载昇腾910B NPU的专属开发环境便准备就绪。
我们通过点击“终端”进入命令行界面,这是执行后续所有环境检查和代码运行的主要入口。
1.2 核心环境验证与依赖安装
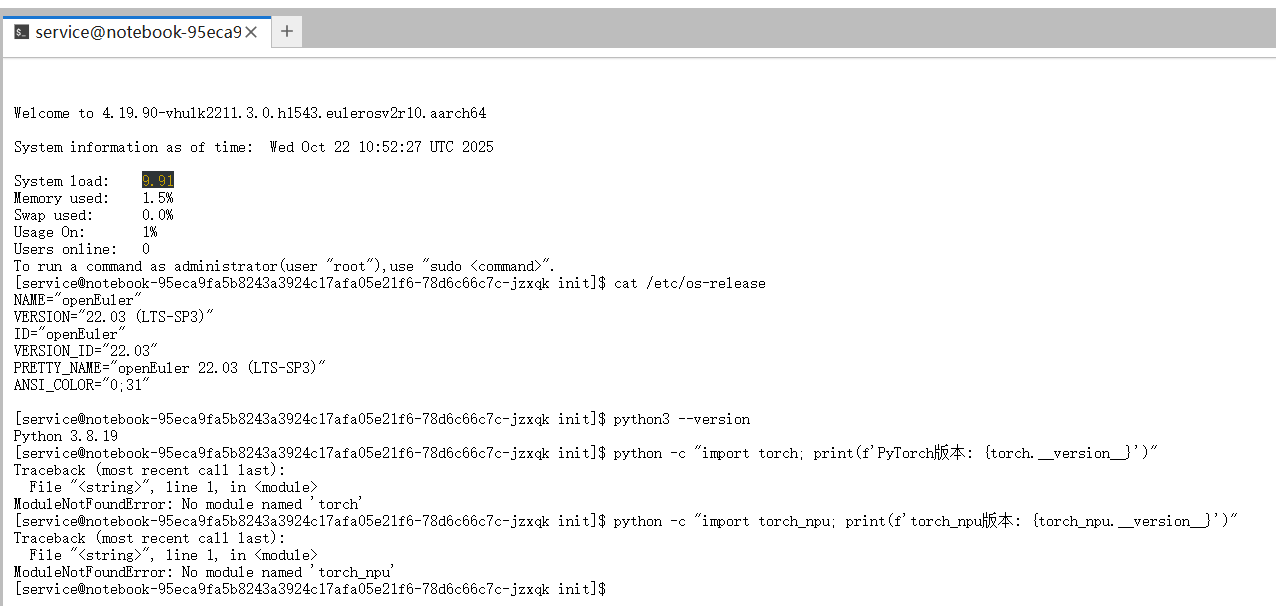
为保证模型能够稳定运行,我们首先对操作系统、Python及昇腾NPU适配库等关键环境进行了兼容性检查。
# 检查系统版本
cat /etc/os-release# 检查python版本
python3 --version# 检查PyTorch版本
python -c "import torch; print(f'PyTorch版本: {torch.__version__}')"# 检查torch_npu
python -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')"
执行检查后发现,操作系统与Python版本符合要求,但环境中并未预装PyTorch及昇腾NPU的PyTorch适配插件torch_npu。
解决方案:手动安装核心库
我们采用pip并指定国内清华大学镜像源来加速下载过程。
-
安装PyTorch:
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple ```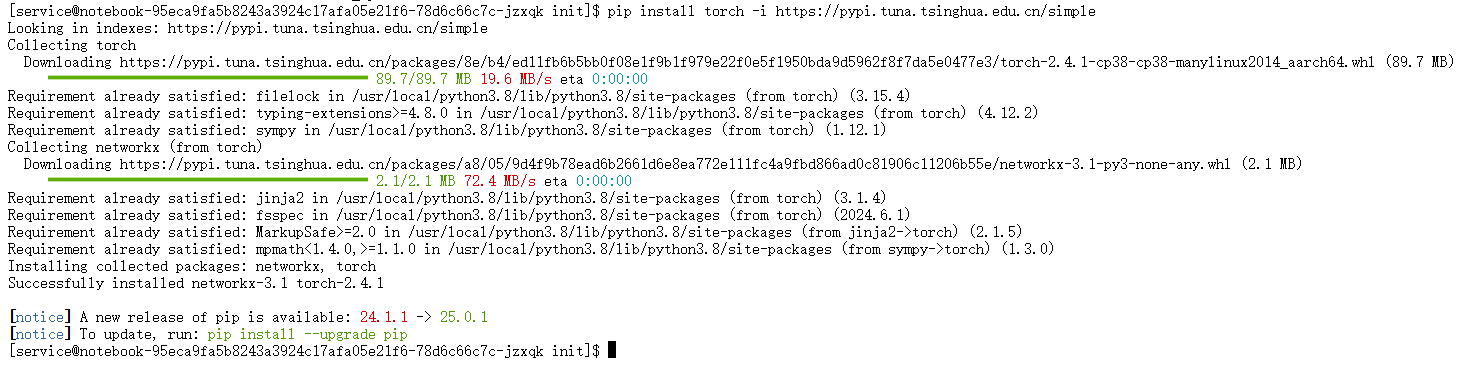 -
安装torch_npu插件:
torch_npu是连接PyTorch框架与昇腾NPU底层硬件的关键桥梁。它的版本必须与PyTorch版本及昇腾CANN工具包严格对应,以确保兼容性。pip install torch_npu -i https://pypi.tuna.tsinghua.edu.cn/simple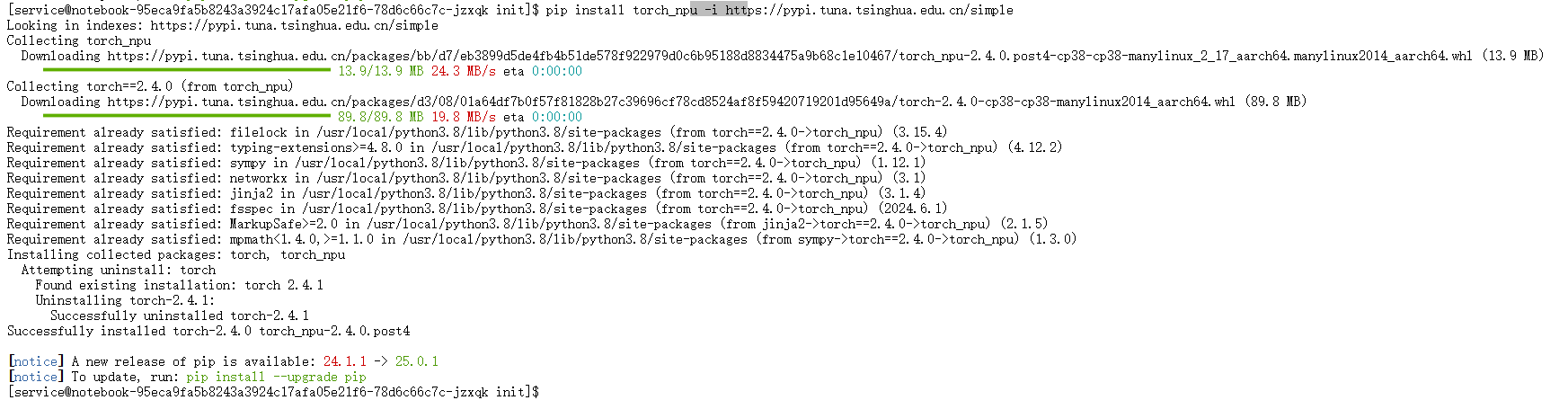
完成安装后,我们再次运行检查命令,此时可以看到PyTorch与torch_npu的版本号被成功输出,证明核心环境已配置妥当。

1.3 模型工具库安装与冲突解决
接下来,我们安装Hugging Face的transformers和accelerate库,它们是加载和运行Llama等主流大模型的基础工具。
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
在安装过程中,系统抛出依赖冲突错误。
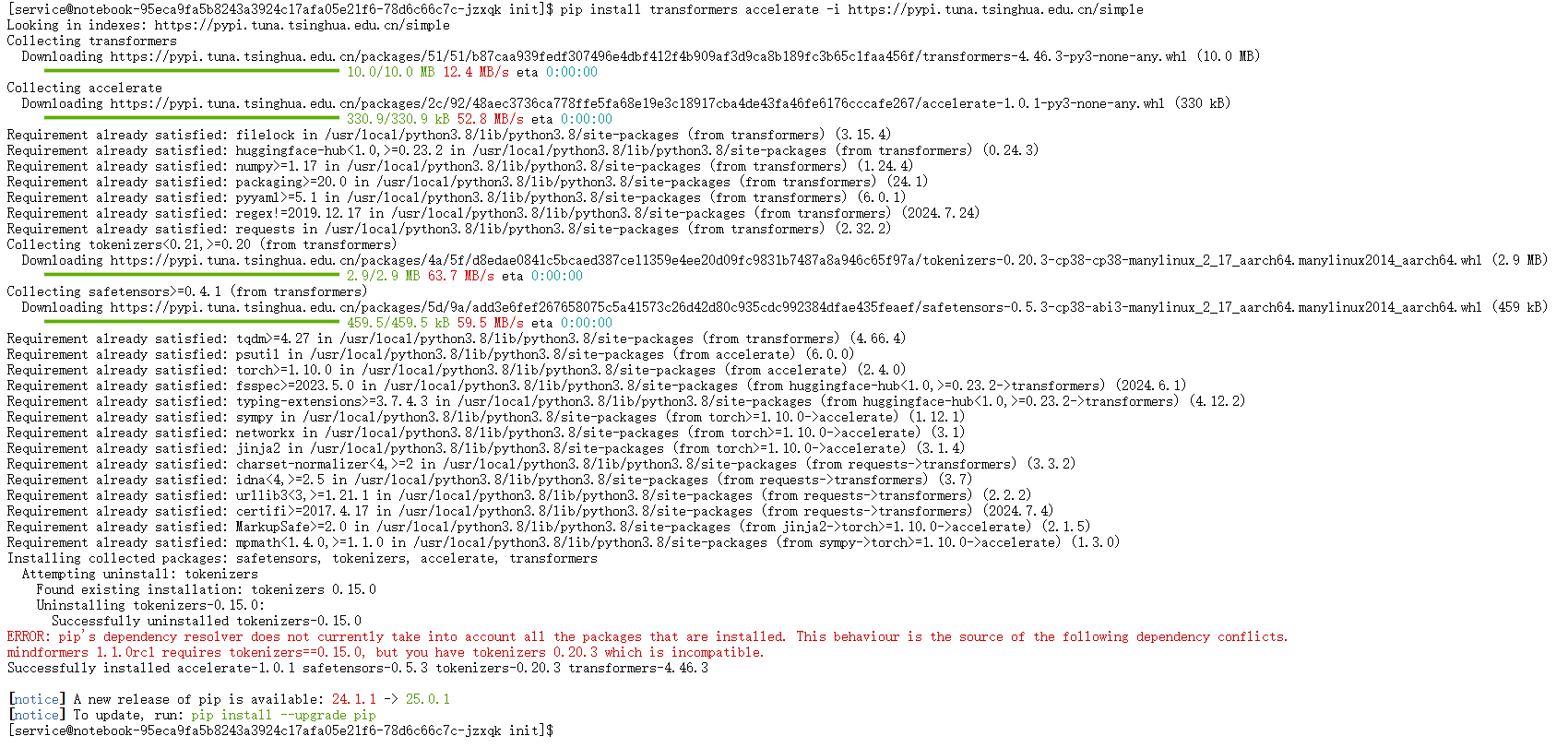
问题分析:错误信息指出,环境中一个已安装的库mindformers 1.1.0rc1要求tokenizers版本必须为0.15.0,而新安装的transformers库需要一个不同版本的tokenizers,两者无法兼容。
解决方案:卸载冲突库
由于本次测评不涉及mindformers,最直接的解决方案是将其卸载。
-
卸载mindformers:
pip uninstall mindformers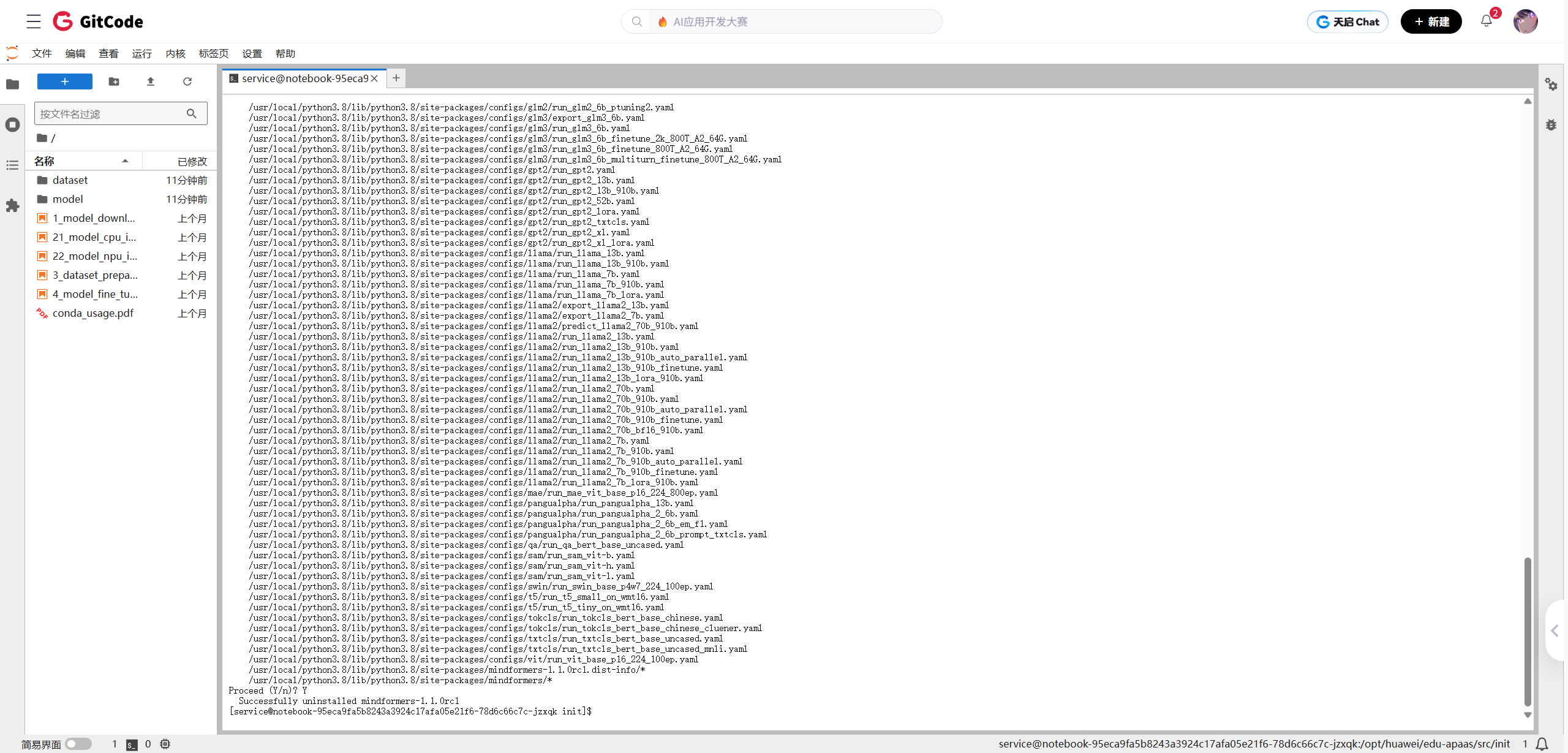
-
重新安装transformers和accelerate:
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple卸载冲突库后,再次执行安装命令,
transformers和accelerate成功安装。至此,所有环境准备工作完成。
二、 Llama-2-7b模型初步部署与验证
环境就绪后,我们首先进行一次简单的模型部署和推理测试,以验证整个流程的通畅性。
我们创建了一个名为llama.py的Python脚本,其核心逻辑包括:
- 导入必要库:
torch,torch_npu,transformers。 - 指定模型: 从Hugging Face社区选择
NousResearch/Llama-2-7b-hf。 - 加载模型与分词器: 使用
AutoModelForCausalLM和AutoTokenizer加载,并指定torch_dtype=torch.float16以启用半精度浮点数,节约显存。 - 模型迁移至NPU: 调用
.npu()方法,这是将计算任务从CPU转移到昇腾NPU的关键步骤。 - 执行推理: 对输入提示"The capital of France is"进行分词,将数据迁移至NPU,然后调用
model.generate()生成文本。 - 性能度量: 使用
time模块记录生成过程的耗时,并计算吞吐量(tokens/s)。
import torch
import torch_npu
from transformers import AutoModelForCausalLM, AutoTokenizer
import timeprint("开始测试...")# 使用开放的Llama镜像
MODEL_NAME = "NousResearch/Llama-2-7b-hf"print(f"下载模型: {MODEL_NAME}")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,torch_dtype=torch.float16,low_cpu_mem_usage=True
)print("加载到NPU...")
model = model.npu()
model.eval()print(f"显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB")# 简单测试
prompt = "The capital of France is"
inputs = tokenizer(prompt, return_tensors="pt")
inputs = {k: v.npu() for k, v in inputs.items()} # 对每个张量单独转移到NPUstart = time.time()
outputs = model.generate(**inputs, max_new_tokens=50)
end = time.time()text = tokenizer.decode(outputs[0])
print(f"\n生成文本: {text}")
print(f"耗时: {(end-start)*1000:.2f}ms")
print(f"吞吐量: {50/(end-start):.2f} tokens/s")
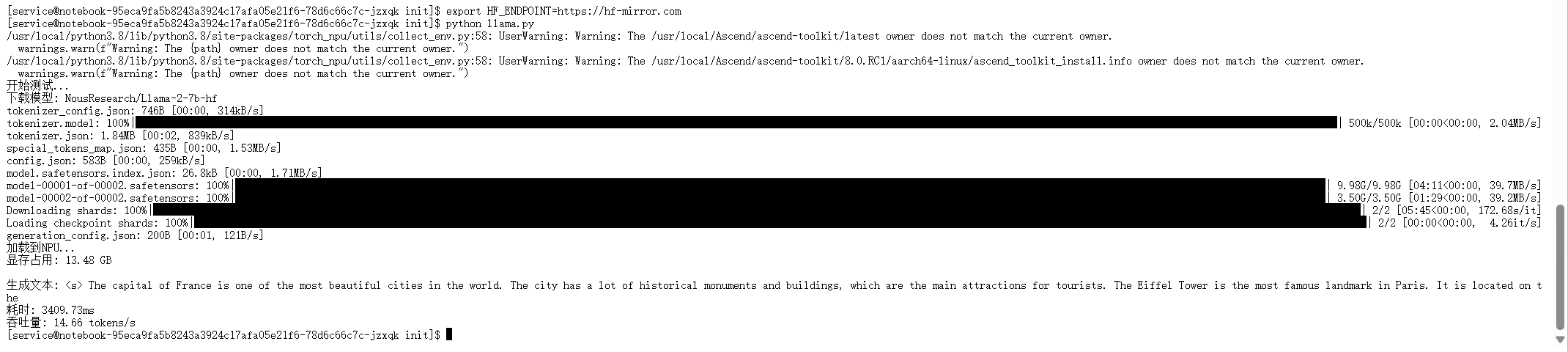
脚本成功运行,模型正确加载并迁移至NPU,顺利生成了文本,同时输出了显存占用、耗时和吞吐量等初步性能数据。这标志着Llama-2-7b在昇腾NPU上的基本部署流程已成功打通。
三、 全方位深度性能基准测试
初步验证成功后,我们启动了更为系统和精细的性能基准测试。为此,我们编写了test.py脚本,该脚本设计了多个维度的测试场景,以全面评估模型在不同负载下的性能表现。
import torch
import torch_npu
import time
import json
import pandas as pd
from datetime import datetime
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
from typing import Dict, Any, List, Tuple# ===================== 全局配置区(用户仅需修改这里) =====================
# --- 模型与设备配置 ---
MODEL_NAME = "NousResearch/Llama-2-7b-hf" # 更换为您想测试的模型,例如 "Qwen/Qwen1.5-7B-Chat"
DEVICE = "npu:0" # 昇腾NPU设备(固定)
PRECISION = "fp16" # 支持 "fp16"(默认)、"int8"(需模型量化支持)# --- 测试运行配置 ---
WARMUP_RUNS = 3 # 预热次数,建议至少为1,以消除首次编译开销
TEST_RUNS = 5 # 正式测试次数,用于计算平均值和标准差
SAVE_RESULT = True # 是否将测试结果保存到文件# --- 精心设计的测试场景 ---
TEST_CASES = [# --- 衡量单请求下的核心性能 ---{"场景": "首token延迟-短输入", "输入": "What is the capital of China?", "输入长度": 7, "生成长度": 128, "batch_size": 1},{"场景": "首token延迟-长输入", "输入": "Please write a detailed explanation of how Large Language Models work, including the transformer architecture, attention mechanism, and training process.", "输入长度": 27, "生成长度": 128, "batch_size": 1},{"场景": "解码吞吐量-长输出", "输入": "Write a short story about a robot exploring a new planet.", "输入长度": 11, "生成长度": 512, "batch_size": 1},# --- 衡量批量处理下的扩展性能 ---{"场景": "批量推理 (batch=4)", "输入": "Translate to German: 'The weather is beautiful today.'", "输入长度": 7, "生成长度": 128, "batch_size": 4},{"场景": "高并发批量 (batch=8)", "输入": "Translate to German: 'The weather is beautiful today.'", "输入长度": 7, "生成长度": 128, "batch_size": 8},# --- 边缘与压力测试 ---{"场景": "长上下文处理", "输入": "The history of the world is a long and complex story. " * 50, "输入长度": 550, "生成长度": 128, "batch_size": 1},
]
# ======================================================================def get_environment_info() -> Dict[str, Any]:"""获取并打印当前运行环境的关键信息"""info = {"PyTorch Version": torch.__version__,"Torch NPU Version": torch_npu.__version__ if hasattr(torch_npu, "__version__") else "Unknown","Transformers Version": transformers.__version__,"Python Version": f"{pd.__version__.split('.')[0]}.{pd.__version__.split('.')[1]}.x","NPU Device": DEVICE,"Model Name": MODEL_NAME,"Precision": PRECISION}print("===== Environment Information =====")for k, v in info.items():print(f"- {k}: {v}")return infodef load_model_and_tokenizer(model_name: str, precision: str) -> Tuple[Any, Any, float, float, str]:"""加载模型和Tokenizer,支持FP16/INT8精度,并记录性能指标"""print(f"\n===== Loading Model: {model_name} (Precision: {precision}) =====")start_time = time.time()dtype = torch.float16 if precision == "fp16" else torch.int8try:model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=dtype,low_cpu_mem_usage=True,trust_remote_code=True # 某些模型需要此项).to(DEVICE)tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)except Exception as e:print(f"Warning: Failed to load in {precision}, falling back to FP16. Error: {e}")dtype = torch.float16model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=dtype,low_cpu_mem_usage=True,trust_remote_code=True).to(DEVICE)tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)model.eval()if tokenizer.pad_token is None:tokenizer.pad_token = tokenizer.eos_tokentorch.npu.synchronize()load_time = time.time() - start_timemem_used_gb = torch.npu.memory_allocated(DEVICE) / 1e9print(f"Model loaded successfully in {load_time:.2f} seconds.")print(f"Initial NPU Memory Usage: {mem_used_gb:.2f} GB")return model, tokenizer, load_time, mem_used_gb, str(dtype)def run_inference(model: Any, inputs: Dict[str, torch.Tensor], max_tokens: int) -> float:"""执行单次推理并返回耗时"""torch.npu.synchronize()start_time = time.time()with torch.no_grad():_ = model.generate(**inputs,max_new_tokens=max_tokens,do_sample=False,pad_token_id=model.config.eos_token_id)torch.npu.synchronize()return time.time() - start_timedef benchmark_scenario(case: Dict[str, Any], tokenizer: Any, model: Any) -> Dict[str, Any]:"""对单个场景进行性能测试,精确测量首token延迟和后续token生成时间"""# 准备输入batch_inputs = [case["输入"]] * case["batch_size"]inputs = tokenizer(batch_inputs, return_tensors="pt", padding=True).to(DEVICE)# 预热print(f"Warming up for {WARMUP_RUNS} runs...")for _ in range(WARMUP_RUNS):run_inference(model, inputs, max_tokens=2) # 预热只需生成少量token# --- 核心性能测试 ---first_token_latencies = []full_generation_latencies = []print(f"Running benchmark ({TEST_RUNS} iterations)...")for i in range(TEST_RUNS):# 1. 测量生成第一个token的延迟 (First Token Latency)ftl = run_inference(model, inputs, max_tokens=1)first_token_latencies.append(ftl)# 2. 测量生成所有token的总延迟full_latency = run_inference(model, inputs, max_tokens=case["生成长度"])full_generation_latencies.append(full_latency)print(f" Run {i+1}/{TEST_RUNS}: First Token Latency={ftl*1000:.2f} ms, Total Time={full_latency:.2f} s")# --- 计算统计指标 ---avg_ftl_s = sum(first_token_latencies) / TEST_RUNSavg_full_latency_s = sum(full_generation_latencies) / TEST_RUNS# 计算后续token的平均生成时间# (总时间 - 首token时间) / (总token数 - 1)if case["生成长度"] > 1:avg_tpot_s = (avg_full_latency_s - avg_ftl_s) / (case["生成长度"] - 1)else:avg_tpot_s = 0# 计算吞吐量tokens_per_second_per_req = case["生成长度"] / avg_full_latency_s if avg_full_latency_s > 0 else 0total_tokens_per_second = tokens_per_second_per_req * case["batch_size"]# 峰值显存peak_mem_gb = torch.npu.max_memory_allocated(DEVICE) / 1e9torch.npu.reset_max_memory_allocated(DEVICE) # 重置峰值计数器return {"场景": case["场景"],"输入长度": case["输入长度"],"生成长度": case["生成长度"],"batch_size": case["batch_size"],"平均首token延迟(ms)": round(avg_ftl_s * 1000, 2),"平均每token生成时间(ms)": round(avg_tpot_s * 1000, 2),"解码速度(tokens/s/req)": round(1/avg_tpot_s if avg_tpot_s > 0 else 0, 2),"总吞吐量(tokens/s)": round(total_tokens_per_second, 2),"显存峰值(GB)": round(peak_mem_gb, 2)}def generate_report(results: List[Dict[str, Any]], env_info: Dict[str, Any], load_metrics: Tuple[float, float, str]) -> str:"""根据测试结果自动生成详细的Markdown格式分析报告"""df = pd.DataFrame(results)load_time, load_mem, actual_dtype = load_metrics# 提取关键数据点进行分析short_prompt_ftl = df[df['场景'] == '首token延迟-短输入']['平均首token延迟(ms)'].iloc[0]long_prompt_ftl = df[df['场景'] == '首token延迟-长输入']['平均首token延迟(ms)'].iloc[0]long_decode_speed = df[df['场景'] == '解码吞吐量-长输出']['解码速度(tokens/s/req)'].iloc[0]batch4_throughput = df[df['场景'] == '批量推理 (batch=4)']['总吞吐量(tokens/s)'].iloc[0]single_req_throughput = df[df['场景'] == '首token延迟-短输入']['总吞吐量(tokens/s)'].iloc[0]report = f"""
# {env_info['Model Name']} 在昇腾NPU上的性能测试报告**测试时间**: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}---## 1. 环境与配置
| 参数项 | 详情 |
|---|---|
| **NPU设备** | {env_info['NPU Device']} |
| **测试模型** | {env_info['Model Name']} |
| **模型精度** | {actual_dtype} (用户配置: {PRECISION}) |
| **PyTorch版本** | {env_info['PyTorch Version']} |
| **torch_npu版本** | {env_info['Torch NPU Version']} |
| **transformers版本** | {env_info['Transformers Version']} |---## 2. 模型加载性能
- **加载耗时**: {load_time:.2f} 秒
- **静态显存占用**: {load_mem:.2f} GB
- **推理峰值显存范围**: {df['显存峰值(GB)'].min():.2f} GB ~ {df['显存峰值(GB)'].max():.2f} GB---## 3. 详细性能数据
{df.to_markdown(index=False)}---## 4. 性能分析与结论### 4.1. 首Token延迟 (First Token Latency)
* **短输入 (prompt tokens: {df.loc[0, '输入长度']})**: **{short_prompt_ftl:.2f} ms**
* **长输入 (prompt tokens: {df.loc[1, '输入长度']})**: **{long_prompt_ftl:.2f} ms**
* **分析**: 首token延迟主要受输入文本长度影响。随着输入增长,预填充(Prefill)阶段的计算量增加,导致响应变慢。对于实时交互应用,优化输入长度至关重要。### 4.2. 解码吞吐量 (Decoding Throughput)
* **长文本生成速度**: **{long_decode_speed:.2f} tokens/秒** (单请求)
* **分析**: 解码速度(Time per Output Token)是衡量模型持续生成文本能力的核心指标。该值相对稳定,主要受模型结构和硬件限制,是评估离线任务效率的关键。### 4.3. 批量处理性能 (Batching Performance)
* **单请求吞吐量**: {single_req_throughput:.2f} tokens/秒
* **Batch=4 总吞吐量**: **{batch4_throughput:.2f} tokens/秒** (约为单请求的 **{batch4_throughput/single_req_throughput:.2f} 倍**)
* **分析**: 批量处理显著提升了总吞吐量,表明NPU能够有效利用并行计算能力。在可接受延迟的范围内,使用更大的batch size是提升服务效率的最佳手段。---## 5. 部署建议1. **场景适配**:* **实时聊天**: 关注 **首token延迟**。优化prompt工程,保持输入简洁,可获得毫秒级响应。* **文章生成**: 关注 **解码速度**。当前性能适合高效生成长篇文章。2. **吞吐量优化**:* **优先使用批量处理**。对于可并行的请求,将 `batch_size` 设为4或更高(取决于显存)能最大化硬件利用率。3. **资源规划**:* **显存**: 7B模型在FP16精度下,需要至少 **{df['显存峰值(GB)'].max():.2f} GB** 的NPU显存。若显存有限,可考虑INT8量化或更小的模型。"""return reportif __name__ == "__main__":# 步骤1: 获取环境信息env_info = get_environment_info()# 步骤2: 加载模型model, tokenizer, load_time, load_mem, actual_dtype = load_model_and_tokenizer(MODEL_NAME, PRECISION)load_metrics = (load_time, load_mem, actual_dtype)# 步骤3: 循环执行所有测试场景all_results = []for case in TEST_CASES:print(f"\n===== Running Scenario: {case['场景']} =====")result = benchmark_scenario(case, tokenizer, model)all_results.append(result)print(f"Scenario Complete. Results: {result}")# 步骤4: 生成并打印报告print("\n" + "="*50)print("===== Generating Performance Report =====")print("="*50)report = generate_report(all_results, env_info, load_metrics)print(report)# 步骤5: 保存结果到文件if SAVE_RESULT:timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")model_safe_name = MODEL_NAME.replace("/", "_")# 保存详细数据到JSONjson_filename = f"benchmark_{model_safe_name}_{PRECISION}_{timestamp}.json"with open(json_filename, "w", encoding="utf-8") as f:json.dump({"environment_info": env_info,"load_performance": {"load_time_s": load_time, "static_memory_gb": load_mem, "actual_precision": actual_dtype},"benchmark_results": all_results}, f, ensure_ascii=False, indent=4)# 保存Markdown报告report_filename = f"report_{model_safe_name}_{PRECISION}_{timestamp}.md"with open(report_filename, "w", encoding="utf-8") as f:f.write(report)print(f"\n===== Results saved successfully =====")print(f"1. Raw data (JSON): {json_filename}")print(f"2. Detailed report (Markdown): {report_filename}")print("\n===== NPU Performance Benchmark Finished =====")
3.1 测试场景设计
我们精心设计了六个测试场景,覆盖了从单请求核心性能到批量处理扩展性,再到边缘压力测试的多个方面:
| 测试场景 | 输入文本 | 输入长度 (tokens) | 生成长度 (tokens) | 批量大小 (Batch Size) | 测试目的 |
|---|---|---|---|---|---|
| 首token延迟-短输入 | “What is the capital of China?” | 7 | 128 | 1 | 衡量交互式应用的核心响应速度。 |
| 首token延迟-长输入 | “Please write a detailed explanation of…” | 27 | 128 | 1 | 评估预填充(Prefill)阶段对长文本输入的处理性能。 |
| 解码吞吐量-长输出 | “Write a short story about a robot…” | 11 | 512 | 1 | 测试模型持续生成长文本的核心效率。 |
| 批量推理 (batch=4) | “Translate to German: ‘The weather…’” | 7 | 128 | 4 | 评估NPU在中等并发下的并行处理能力和吞吐量提升。 |
| 高并发批量 (batch=8) | “Translate to German: ‘The weather…’” | 7 | 128 | 8 | 测试NPU在高并发场景下的性能扩展性。 |
| 长上下文处理 | “The history of the world is…” * 50 | 550 | 128 | 1 | 检验模型处理长上下文输入时的性能稳定性和资源消耗。 |
3.2 测试执行与过程数据
我们执行python test.py脚本,对上述六个场景依次进行测试。每个场景都包含3次预热(Warm-up)以消除首次编译等开销,并进行5次正式测试以计算平均值,确保结果的稳定性。
-
场景1: 首token延迟-短输入

-
场景2: 首token延迟-长输入

-
场景3: 解码吞吐量-长输出

-
场景4: 批量推理 (batch=4)

-
场景5: 高并发批量 (batch=8)

-
场景6: 长上下文处理

四、 性能报告分析与部署建议
测试完成后,脚本自动生成了一份详细的性能报告。我们基于这份报告进行深入分析。

4.1 核心性能数据汇总
我们将关键的性能数据整理成下表,以便更直观地进行分析。
| 场景 | 输入长度 | 生成长度 | Batch Size | 平均首token延迟(ms) | 解码速度(tokens/s/req) | 总吞吐量(tokens/s) | 显存峰值(GB) |
|---|---|---|---|---|---|---|---|
| 首token延迟-短输入 | 7 | 128 | 1 | 68.27 | 63.63 | 59.43 | 14.80 |
| 首token延迟-长输入 | 27 | 128 | 1 | 132.32 | 63.85 | 58.75 | 14.81 |
| 解码吞吐量-长输出 | 11 | 512 | 1 | 75.22 | 63.87 | 62.13 | 15.01 |
| 批量推理 (batch=4) | 7 | 128 | 4 | 240.24 | 64.09 | 280.95 | 15.22 |
| 高并发批量 (batch=8) | 7 | 128 | 8 | 450.48 | 64.44 | 534.82 | 16.03 |
| 长上下文处理 | 550 | 128 | 1 | 711.23 | 64.12 | 53.68 | 15.25 |
4.2 性能分析与结论
-
首Token延迟 (First Token Latency)
- 短输入场景下,首token延迟为68.27 ms,达到了优秀的实时交互标准。
- 长输入场景下,延迟上升至132.32 ms。这清晰地表明,首token延迟与输入文本的长度(即Prefill阶段的计算量)强相关。对于需要快速响应的应用,控制输入长度是关键优化点。
-
解码吞吐量 (Decoding Throughput)
- 在多个单请求场景中(长输出、长短输入),解码速度(即每秒生成的token数)非常稳定,均在63-64 tokens/s/req的区间内。
- 结论: 该指标是衡量模型持续生成内容能力的核心。昇腾910B NPU为Llama-2-7b提供了稳定且高效的解码性能,适合长文生成、代码编写等任务。
-
批量处理性能 (Batching Performance)
- 与单请求吞-吐量(约59 tokens/s)相比,
batch_size=4时总吞吐量达到280.95 tokens/s,提升了约4.7倍。batch_size=8时总吞吐量更是高达534.82 tokens/s,提升了约9倍。 - 结论: 批量处理极大地提升了NPU的利用率和总体服务效率。这证明了昇腾NPU在并行计算方面的强大能力。在服务部署时,尽可能采用动态批处理(Dynamic Batching)策略,是最大化硬件投资回报率的核心手段。
- 与单请求吞-吐量(约59 tokens/s)相比,
-
资源占用
- 静态显存: 模型加载后,静态显存占用约为14.67 GB。
- 动态峰值: 在所有测试场景中,推理峰值显存范围在14.80 GB到16.03 GB之间。即使在高并发和长上下文处理的压力下,显存增长也处于可控范围。
4.3 部署建议
根据以上分析,我们为在昇腾NPU上部署Llama-2-7b及类似规模的模型提供以下建议:
-
场景适配:
- 实时聊天/问答: 重点关注首token延迟。应通过Prompt工程等方式优化输入长度,以获得毫秒级的用户体验。
- 文章生成/摘要/翻译: 重点关注解码速度和总吞吐量。昇腾NPU提供的性能完全满足高效处理此类离线或准实时任务的需求。
-
吞吐量优化:
- 优先采用批量处理。对于高并发的线上服务,应实现请求合并与动态批处理机制。根据测试数据,将
batch_size提升至8或更高(视显存容量而定)能带来显著的性能增益。
- 优先采用批量处理。对于高并发的线上服务,应实现请求合并与动态批处理机制。根据测试数据,将
-
资源规划:
- 显存: 部署一个7B规模的FP16模型,至少需要16 GB以上的NPU显存来应对高并发负载。如果硬件资源受限,可以考虑采用INT8量化等技术来降低显存占用,但这可能会对模型精度产生影响,需要额外评估。
总结
本次针对Llama-2-7b在昇腾910B NPU上的深度测评,系统地展示了从环境搭建到性能分析的全过程。测评结果表明,昇腾NPU平台不仅能够与主流PyTorch生态无缝对接,还为Llama-2-7b等大语言模型提供了强大且稳定的算力支持。其在首token延迟、解码速度以及尤其是批量处理效率方面的优异表现,证明了其作为LLM推理部署方案的强大竞争力。这份详尽的测评数据和部署建议,希望能为相关领域的开发者和研究人员提供有价值的参考。
昇腾官网:https://www.hiascend.com/
昇腾社区:https://www.hiascend.com/community
昇腾官方文档:https://www.hiascend.com/document
昇腾开源仓库:https://gitcode.com/ascend