wordpress网站加密方式网站建设人员叫什么科目
目录
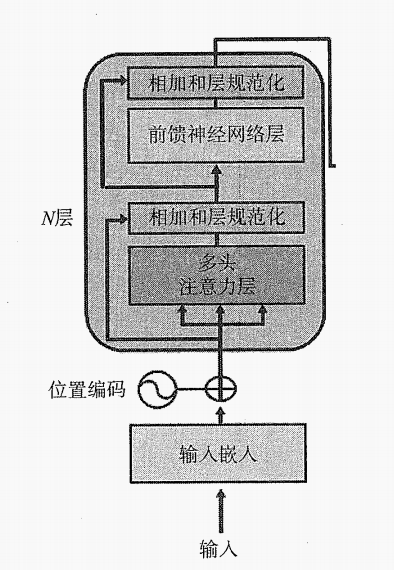
1、Transformer编码器堆叠的每层结构
2、输入嵌入
3、位置编码
4、多头注意力层
4.1、步骤1:表示输入
4.1.1、输入
4.1.2、示意图
编辑
4.2、步骤2:初始化权重矩阵
4.2.1、初始化Query权重矩阵:
4.2.2、初始化Key权重矩阵:
4.2.3、初始化Value权重矩阵:
4.2.4、示意图
4.3、步骤3:将输入向量乘以权重矩阵以获得Q、K和V
4.3.1、将输入向量乘以w_query权重矩阵
4.3.2、将输入向量乘以w_key权重矩阵
4.3.3、将输入向量乘以w_value权重矩阵
4.3.4、示意图
4.4、步骤4:计算中间注意力分数
4.4.1、计算注意力分数:
4.4.2、先计算Q和K
4.4.3、示意图
4.5、步骤5:每个向量的缩放softmax注意力分数
4.5.1、softmax注意力分数公式
4.5.2、计算softmax函数
4.5.3、示意图
4.6、步骤6:计算最终注意力值
4.6.1、计算注意力分数:
4.6.2、先计算Q和K
4.6.3、示意图
4.7、步骤7:将所有输入向量的注意力值相加
4.7.1、所有输入向量的注意力值相加以形成整个输入矩阵
4.7.2、示意图
4.8、步骤8:在512维度重复步骤1-7
4.9、步骤9:得出注意力头的输出
4.10、步骤10:将所有注意力头的输出串联在一起
4.10.1、串联
4.10.2、Z的可视化结果
5、层后规范化
5.1、 层后规范化的整体流程与目的
5.2、 层后规范化的具体公式
6、前馈神经网络子层
1、Transformer编码器堆叠的每层结构
主要讲诉多头注意力,其他的内容请参考:1-大语言模型—理论基础:详解Transformer架构的实现(1)-CSDN博客![]() https://blog.csdn.net/wh1236666/article/details/149443139?spm=1001.2014.3001.5502
https://blog.csdn.net/wh1236666/article/details/149443139?spm=1001.2014.3001.5502
注意力机制从理论到实践:多头注意力_多头注意力机制-CSDN博客![]() https://blog.csdn.net/wh1236666/article/details/149414293?spm=1001.2014.3001.5502
https://blog.csdn.net/wh1236666/article/details/149414293?spm=1001.2014.3001.5502
2、输入嵌入
输入嵌入层是模型的第一部分,主要用于将离散的输入数据,如文本数据中的单词或字符,转换为连续的数值向量形式。这样的转换是必要的,因为深度学习模型需要处理数值数据。此外,嵌入向量还能捕捉和编码单词的语义信息,相似的单词在嵌入空间中会有相似的向量表示,并且在某些情况下,还可以是上下文相关的。同时,嵌入向量通常比原始数据的维度低,有助于减少模型参数数量,减轻过拟合风险,提高训练效率。
3、位置编码
位置编码通过正弦和余弦函数创建,具有以下特性:
-
不同频率的函数:
- 偶数位置使用正弦函数:
- 奇数位置使用余弦函数:
其中,
是位置索引,i 是维度索引,
是嵌入维度。
- 偶数位置使用正弦函数:
-
频率控制: 公式中的
控制了不同维度的频率:
- 低维度(i 较小):频率低,周期长,捕获长距离位置关系。
- 高维度(i 较大):频率高,周期短,捕获短距离位置关系。
-
相对位置表示: 对于任意位置偏移 k,
可以表示为
的线性组合,这使得模型能够学习相对位置关系。
4、多头注意力层
接下来将从10个步骤来讲述注意力机制的关键方面:
我们先将注意力机制的输入从缩小到
,这样更容易可视化和理解
4.1、步骤1:表示输入
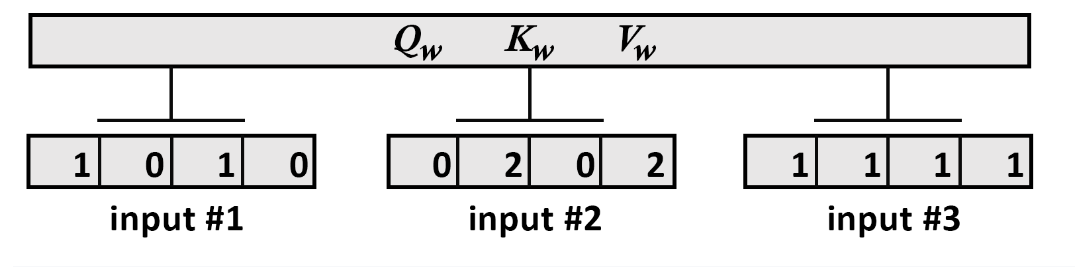
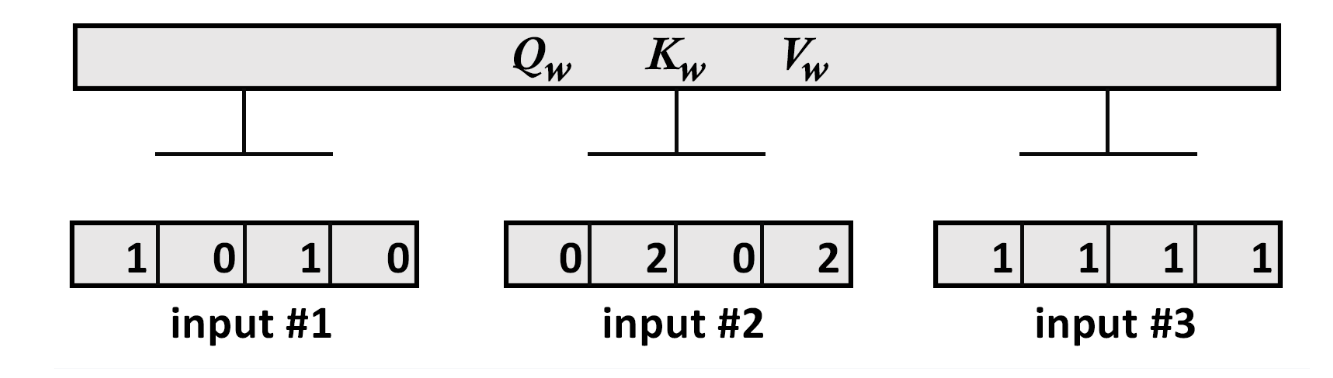
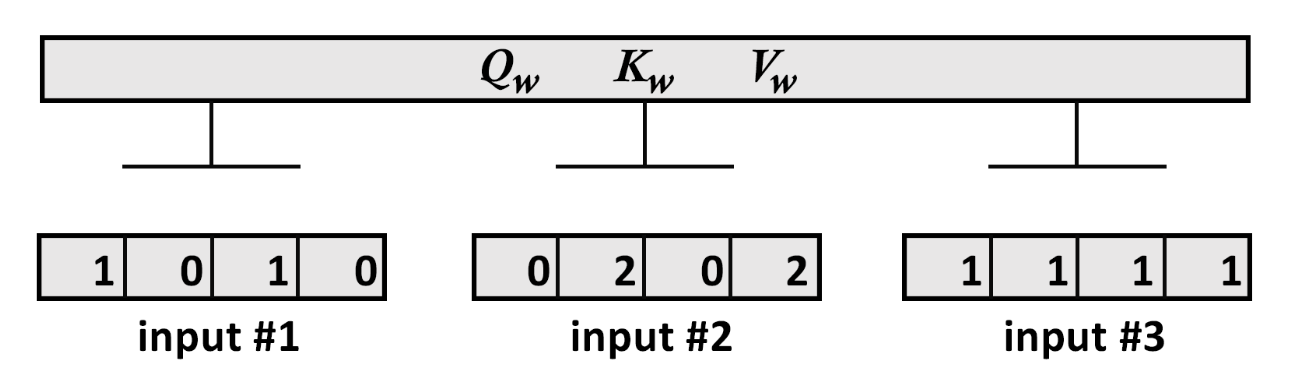
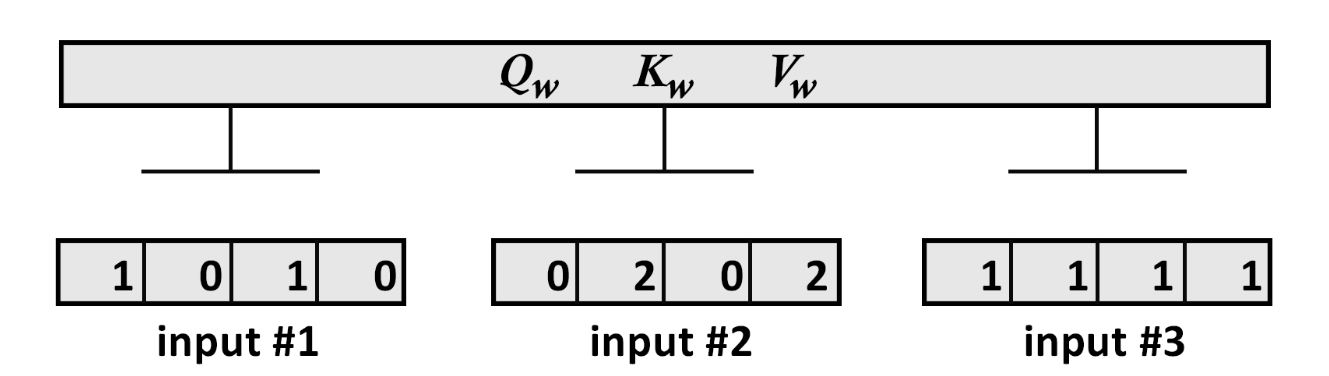
4.1.1、输入
print(" Input : 3 inputs, d_model=4")
x =np.array([[1.0, 0.0, 1.0, 0.0], # Input 1[0.0, 2.0, 0.0, 2.0], # Input 2[1.0, 1.0, 1.0, 1.0]]) # Input 3
print(x)输出展示我们有3个的向量:
Input : 3 inputs, d_model=4
[[1. 0. 1. 0.]
[0. 2. 0. 2.]
[1. 1. 1. 1.]]
4.1.2、示意图

4.2、步骤2:初始化权重矩阵
每个输入有3个权重矩阵:
用于训练 Query
用于训练 Key
用于训练 Value
这3个权重矩阵将应用于此模型中的所有输入。为了更容易可视化和理解,将矩阵缩小到
4.2.1、初始化Query权重矩阵:
print("weights 3 dimensions x d_model=4")
print("w_query")
w_query =np.array([[1, 0, 1],[1, 0, 0],[0, 0, 1],[0, 1, 1]])
print(w_query)输出如下:
weights 3 dimensions x d_model=4
w_query
[[1 0 1]
[1 0 0]
[0 0 1]
[0 1 1]]
4.2.2、初始化Key权重矩阵:
print("w_key")
w_key =np.array([[0, 0, 1],[1, 1, 0],[0, 1, 0],[1, 1, 0]])
print(w_key)输出如下:
w_key
[[0 0 1]
[1 1 0]
[0 1 0]
[1 1 0]]
4.2.3、初始化Value权重矩阵:
print("w_value")
w_value = np.array([[0, 2, 0],[0, 3, 0],[1, 0, 3],[1, 1, 0]])
print(w_value)输出如下:
w_value
[[0 2 0]
[0 3 0]
[1 0 3]
[1 1 0]]
4.2.4、示意图
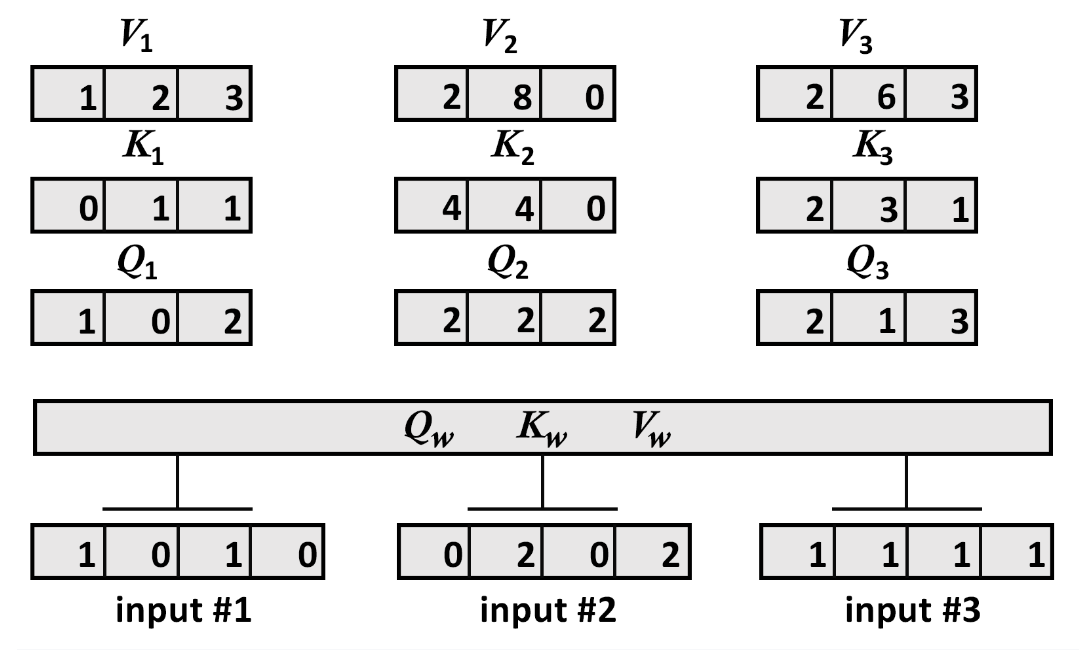
4.3、步骤3:将输入向量乘以权重矩阵以获得Q、K和V
接下来,将假设所有输入都有一个w_query、w_key、和w_value权重矩阵
4.3.1、将输入向量乘以w_query权重矩阵
print("Queries: x * w_query")
Q=np.matmul(x,w_query)
print(Q)输出为,
和
的向量:
Queries: x * w_query
[[1. 0. 2.]
[2. 2. 2.]
[2. 1. 3.]]
4.3.2、将输入向量乘以w_key权重矩阵
print("Keys: x * w_key")
K=np.matmul(x,w_key)
print(K)输出为,
和
的向量:
Keys: x * w_key
[[0. 1. 1.]
[4. 4. 0.]
[2. 3. 1.]]
4.3.3、将输入向量乘以w_value权重矩阵
print("Values: x * w_value")
V=np.matmul(x,w_value)
print(V)输出为,
和
的向量:
Values: x * w_value
[[1. 2. 3.]
[2. 8. 0.]
[2. 6. 3.]]
4.3.4、示意图
4.4、步骤4:计算中间注意力分数
4.4.1、计算注意力分数:
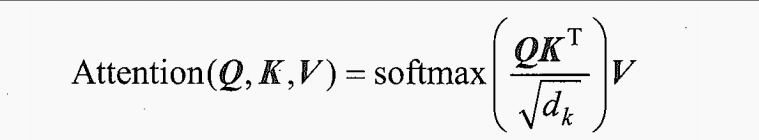
4.4.2、先计算Q和K
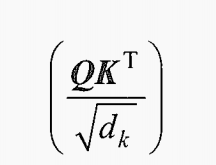
这里我们将 取整为1,然后代入等式的 Q和K部分:
k_d=1 #square root of k_d simplified to 1 for this example
attention_scores = (Q @ K.transpose())/k_d
print(attention_scores)输出为:
[[ 2. 4. 4.]
[ 4. 16. 12.]
[ 4. 12. 10.]]
4.4.3、示意图
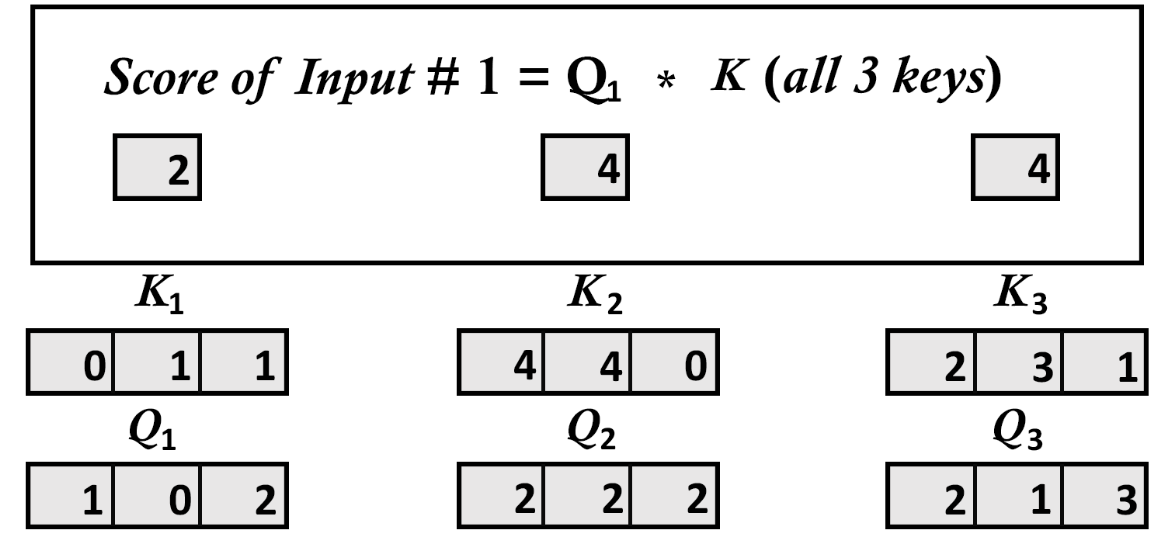
4.5、步骤5:每个向量的缩放softmax注意力分数
4.5.1、softmax注意力分数公式
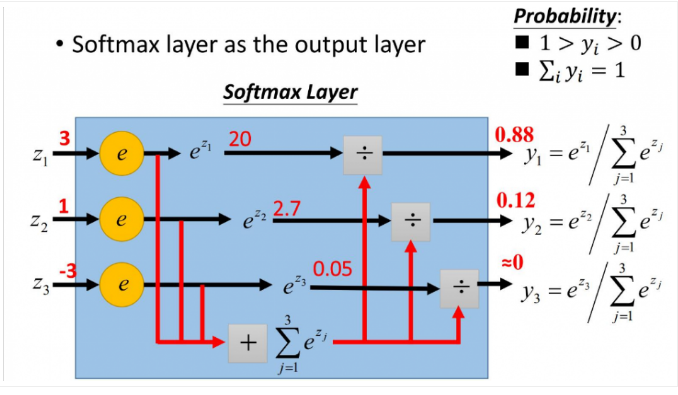
4.5.2、计算softmax函数
现在对每个中间注意力分数应用softmax函数:
print("Scaled softmax attention_scores for each vector")
attention_scores[0]=softmax(attention_scores[0])
attention_scores[1]=softmax(attention_scores[1])
attention_scores[2]=softmax(attention_scores[2])
print(attention_scores[0])
print(attention_scores[1])
print(attention_scores[2])输出为:
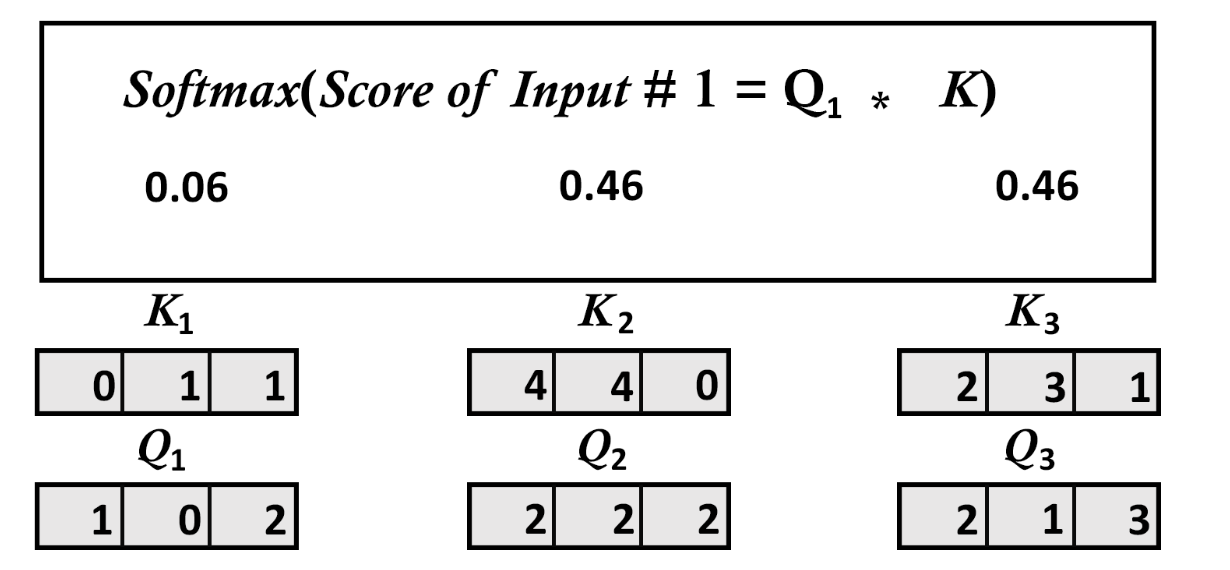
Scaled softmax attention_scores for each vector
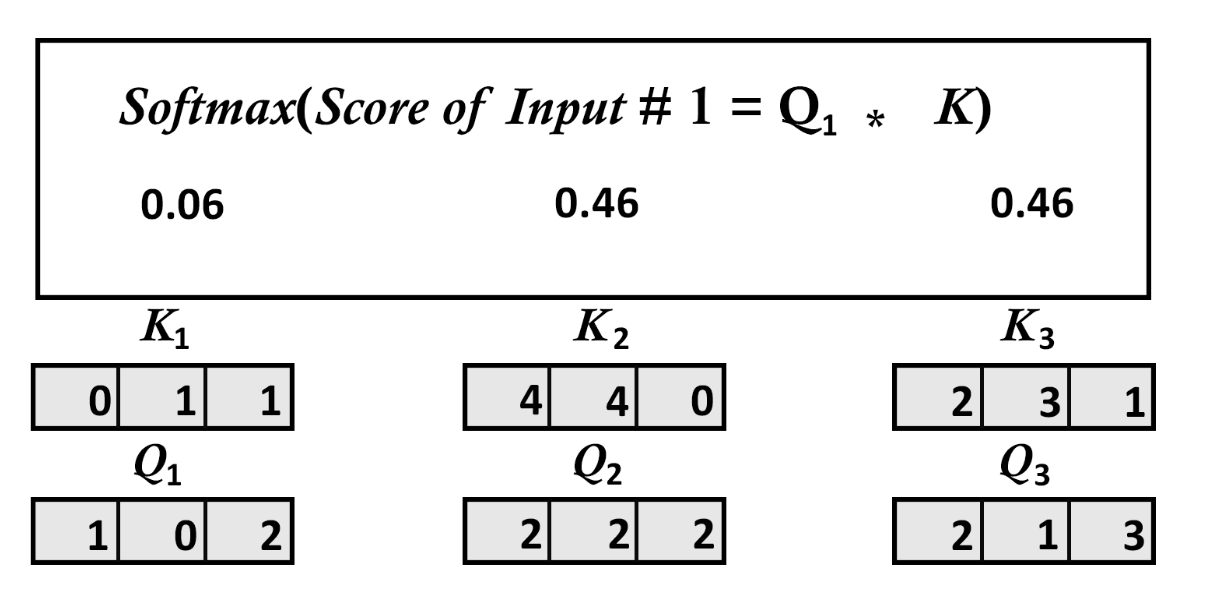
[0.06337894 0.46831053 0.46831053]
[6.03366485e-06 9.82007865e-01 1.79861014e-02]
[2.95387223e-04 8.80536902e-01 1.19167711e-01]
4.5.3、示意图
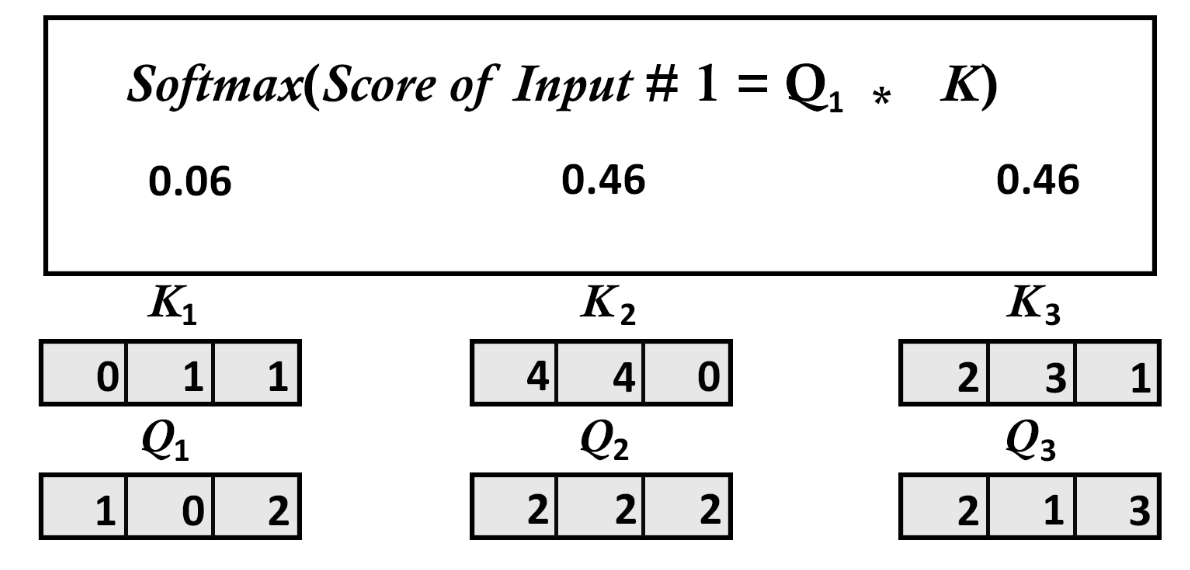
4.6、步骤6:计算最终注意力值
4.6.1、计算注意力分数:
4.6.2、先计算Q和K
print("attention value obtained by score1/k_d * V")
print(V[0])
print(V[1])
print(V[2])
print("Attention 1")
attention1=attention_scores[0].reshape(-1,1)
attention1=attention_scores[0][0]*V[0]
print(attention1)print("Attention 2")
attention2=attention_scores[0][1]*V[1]
print(attention2)print("Attention 3")
attention3=attention_scores[0][2]*V[2]
print(attention3)输出为:
[1. 2. 3.]
[2. 8. 0.]
[2. 6. 3.]
Attention 1
[0.06337894 0.12675788 0.19013681]
Attention 2
[0.93662106 3.74648425 0. ]
Attention 3
[0.93662106 2.80986319 1.40493159]
4.6.3、示意图

4.7、步骤7:将所有输入向量的注意力值相加
4.7.1、所有输入向量的注意力值相加以形成整个输入矩阵
print("summed the results to create the first line of the output matrix")
attention_input1=attention1+attention2+attention3
print(attention_input1)输出为:
summed the results to create the first line of the output matrix
[1.93662106 6.68310531 1.59506841]
4.7.2、示意图
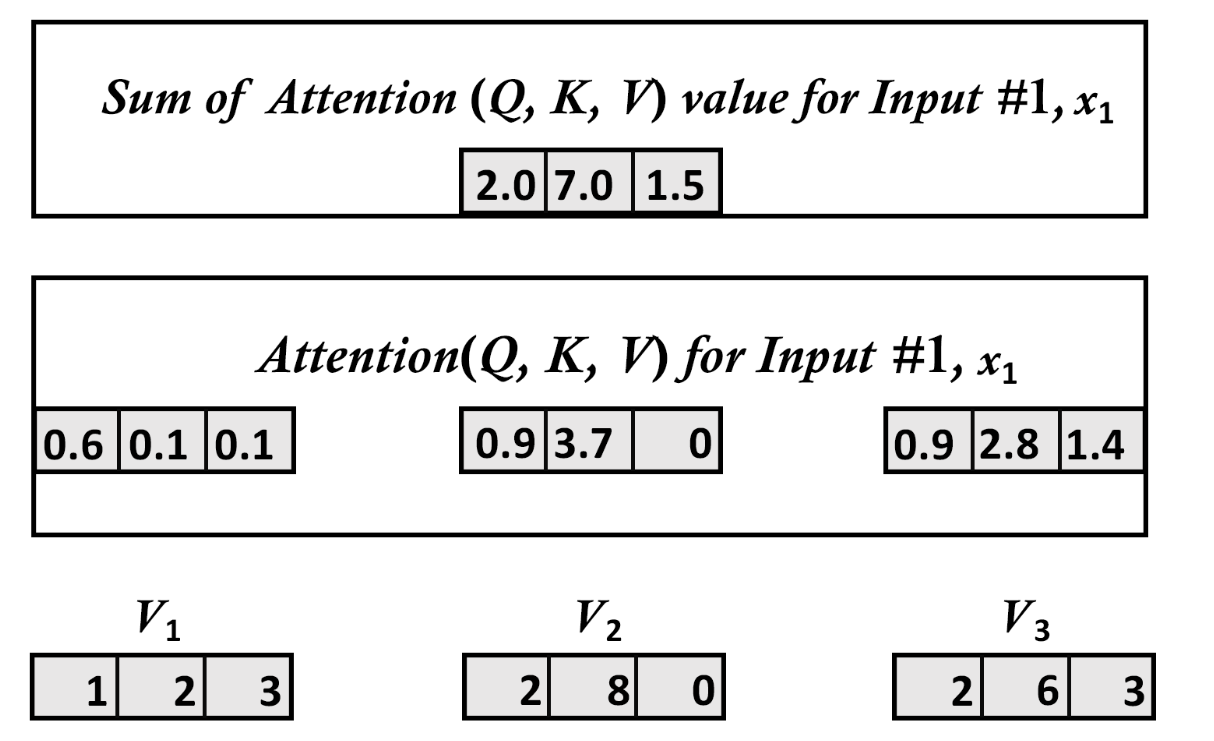
4.8、步骤8:在512维度重复步骤1-7
我们把分成8个注意力头,即
,然后重复步骤1-7:
print(Step 1 to 7 for inputs 1 to 3")
#We assume we have 3 results with learned weights (they were not trained in this example)
#We assume we are implementing the original Transformer paper. We will have 3 results of 64 dimensions each
attention_head1=np.random.random((3, 64))
print(attention_head1)表示注意力头1(
)的3个输出向量:
Step 1 to 7 for inputs 1 to 3
[[0.20216353 0.43707436 0.07130255 0.10509762 0.63655638 0.91845543
0.06511085 0.07839665 0.51316846 0.54571701 0.3358703 0.52092181
0.79275993 0.16141936 0.44289286 0.24053967 0.3109181 0.54028169
0.06520682 0.32269673 0.13930313 0.69075813 0.75375274 0.44131116
0.56119458 0.71839979 0.0468888 0.25340444 0.1991619 0.16644107
0.92459036 0.59387568 0.63877313 0.53316123 0.83347252 0.11372678
0.72663227 0.69516306 0.44438683 0.56273503 0.31350469 0.02059847
0.82681567 0.16856187 0.04148594 0.33847877 0.47074381 0.61881375
0.46843675 0.26956432 0.61479742 0.12607179 0.13802037 0.92223123
0.6391338 0.65150402 0.07907932 0.91520524 0.30195508 0.48254499
0.39480221 0.12666071 0.46255227 0.36424959]
[0.0903881 0.29480922 0.85009611 0.17853338 0.34601251 0.93763393
0.540043 0.7225249 0.63869781 0.52115495 0.66330458 0.23289114
0.01969132 0.01413506 0.14770146 0.245892 0.99449404 0.79260813
0.83122168 0.61600548 0.58212976 0.70024249 0.70131622 0.47308278
0.00833893 0.78465381 0.15448052 0.4692497 0.35703875 0.36804557
0.63645655 0.03685476 0.43474866 0.16320524 0.74648885 0.0686991
0.49476582 0.63160464 0.63877061 0.66446338 0.29745341 0.80195157
0.78390113 0.01826606 0.36892904 0.49703574 0.83830997 0.7709826
0.5701037 0.57189029 0.58778716 0.63042531 0.50316925 0.00485138
0.15201332 0.28931219 0.66304687 0.18097074 0.58243657 0.15468443
0.21620307 0.61108016 0.85660662 0.97462751]
[0.54035374 0.24429728 0.47934195 0.26930656 0.30767629 0.44342124
0.58670726 0.87973315 0.80297698 0.62699596 0.83420321 0.32667907
0.70524241 0.38973909 0.41884684 0.73826175 0.68025396 0.07994067
0.6963917 0.00317974 0.07195525 0.66279553 0.18599549 0.8415708
0.28805445 0.10571825 0.51767025 0.21372909 0.02995637 0.09740333
0.1432304 0.04585444 0.50804904 0.53577774 0.96570255 0.16875654
0.39413961 0.95761106 0.53840123 0.14185747 0.35669164 0.20888907
0.6096804 0.52207146 0.96209511 0.61025325 0.19761878 0.11649753
0.25276215 0.65990242 0.29377752 0.20611366 0.56685083 0.56316098
0.64042987 0.21198724 0.91560529 0.05537728 0.48451921 0.69681557
0.89377765 0.57734016 0.04606235 0.65252354]]
4.9、步骤9:得出注意力头的输出
print("We assume we have trained the 8 heads of the attention sub-layer")
z0h1=np.random.random((3, 64))
z1h2=np.random.random((3, 64))
z2h3=np.random.random((3, 64))
z3h4=np.random.random((3, 64))
z4h5=np.random.random((3, 64))
z5h6=np.random.random((3, 64))
z6h7=np.random.random((3, 64))
z7h8=np.random.random((3, 64))
print("shape of one head",z0h1.shape,"dimension of 8 heads",64*8)展示每个注意力头和8个注意力头加起来的形状:
We assume we have trained the 8 heads of the attention sub-layer
shape of one head (3, 64) dimension of 8 heads 512
现在构成矩阵Z的所有8个子矩阵,拥有了:
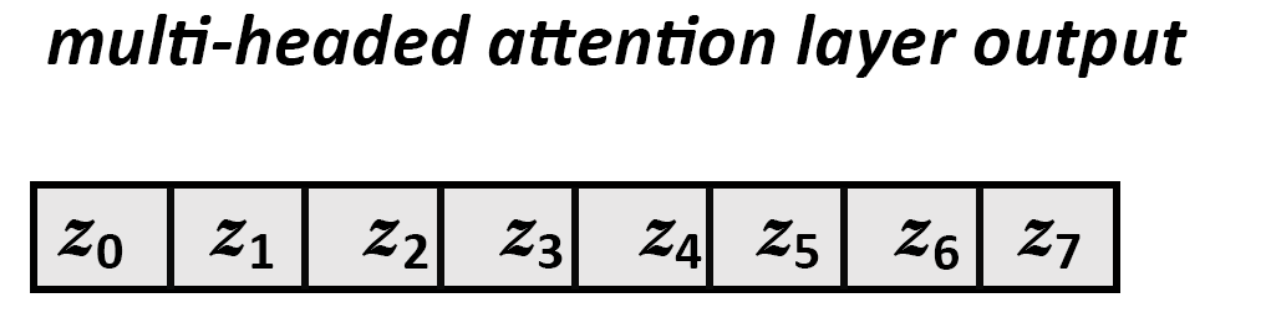
4.10、步骤10:将所有注意力头的输出串联在一起
4.10.1、串联
将按以下等式把所有注意力头的输出串联在一起,以最终输出
print("Concatenation of heads 1 to 8 to obtain the original 8x64=512 output dimension of the model")
output_attention=np.hstack((z0h1,z1h2,z2h3,z3h4,z4h5,z5h6,z6h7,z7h8))
print(output_attention)输出为:
Concatenation of heads 1 to 8 to obtain the original 8x64=512 output dimension of the model
[[0.56468036 0.84093457 0.82947301 ... 0.38060399 0.40217666 0.41135804]
[0.39462287 0.7404385 0.19385572 ... 0.35313777 0.09411459 0.34114942]
[0.25418635 0.6578489 0.75116683 ... 0.88148612 0.91526444 0.80329105]]
4.10.2、Z的可视化结果
5、层后规范化
5.1、 层后规范化的整体流程与目的
- 流程:在 Transformer 中,层后规范化由 “相加函数(对应残差连接,即
)” 和 “规范化函数” 两部分组成 。先将输入 x 与子层(
) ,表示子层本身运算,x 是输入子步骤中可用信息 )的输出相加得到向量 v ,再对 v 做层规范化函数处理。
- 目的:残差连接可确保关键信息不丢失,避免梯度消失或爆炸;层规范化让模型各部分处理过程更一致,有助于稳定训练、加速收敛 。
5.2、 层后规范化的具体公式
层规范化函数定义为:
其中各变量含义:
- v :是 x 与
。
:为维度为 d 的 v 的均值,计算公式:
。
:为维度为 d 的 v 的标准差,先计算方差
,公式:
,标准差
,
是极小正值 )。
:缩放参数,可学习,用于调整规范化后结果的缩放程度。
:偏置向量,可学习,用于调整规范化后结果的偏移。
6、前馈神经网络子层
- 输入:相加和层规范化的输出,维度
- 性质:编码器和解码器中为全连接神经网络,逐位置处理,含两个隐藏层、用 ReLU 激活函数
- 维度:输入输出维度
,内部隐藏层维度
- 等效视角:可视为用大小为 1 的卷积核做两次卷积操作