Mysql存储引擎
(一)查看mysql存储引擎
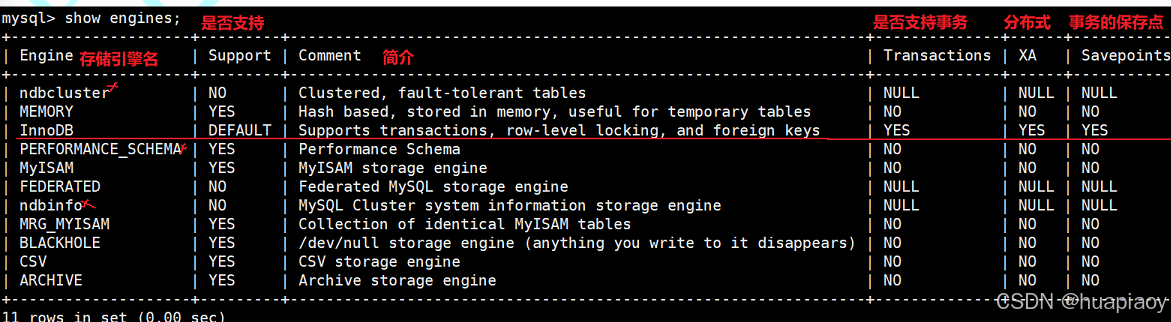
我们可以使用show engines语句来查看我们当前数据库支持哪一些存储引擎,我这里使用的是mysql数据库。
support表示是否支持,值分为:yes,no,default,分别表示支持,不支持,和默认存储引擎
(二)InnoDB存储引擎
InnoDB是一个高可靠性和高性能的通用存储引擎,在mysql5.5版本以后作为默认存储引擎,之前是myisam,我们现在创建一个表时,如果没有指定搜多引擎那么默认就是使用InnoDB存储引擎
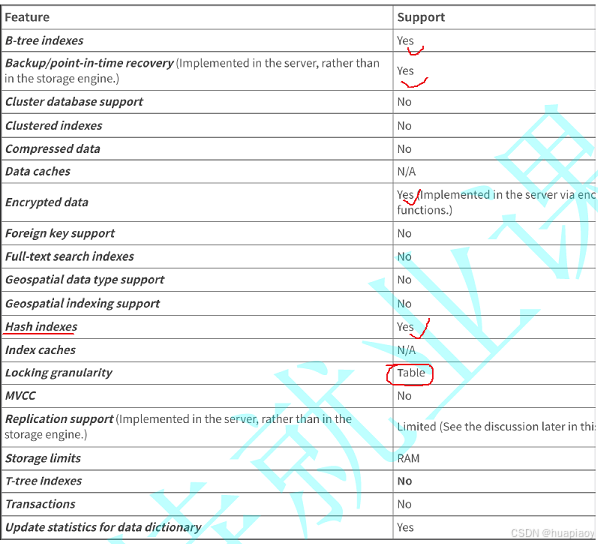
我们来看一下他的特性
InnoDB的特性
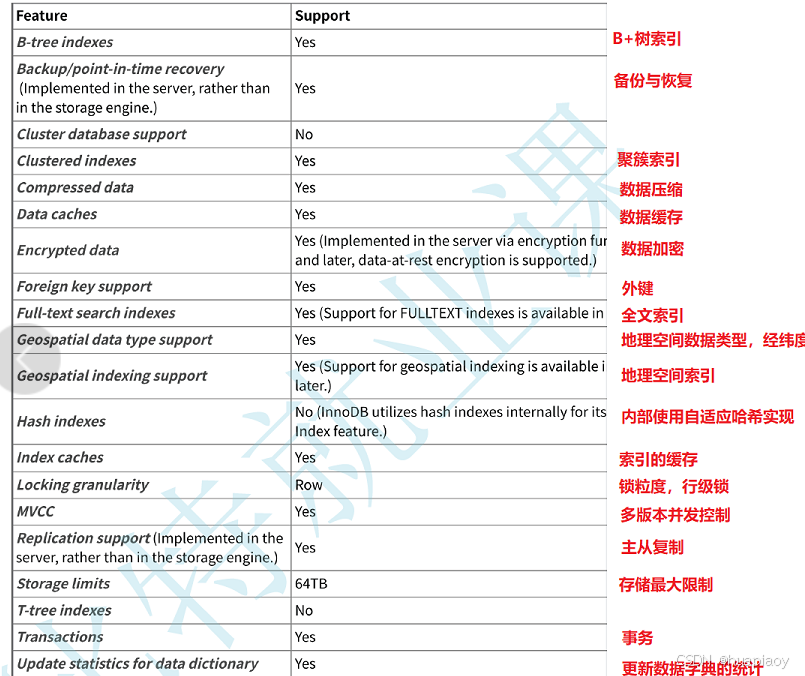
我们这里先简单看一下就可以,一会我们会把他的特性和myisam这个这个存储引擎进行一个对比
这里我们主要记住的就是,底层使用B+树作为索引,同时支持主键索引,外键,全文索引,锁粒度是行级锁(也就是对这一行数据访问时,其他线程是不可以再访问的,需要阻塞),最主要的是他支持事务
InnoDB的优势
1.首先就是支持事务,用来保护用户数据
2.如果发生意外崩溃,我们不需要重启数据库执行任何操作,InnoDB会自动回复崩溃之前提交的更改,并撤销崩溃前正在进行但是没有提交的更改(这里使用的是redolog和双写缓冲区来完成)
3.InnoDB存储引擎维护了一个缓冲池,访问数据库时在内存中缓存表和索引数据,对于经常使用的数据就直接从内存中拿,那池化又会大幅提高我们的效率
4.InnoDB优化了主键查询,通过主键索引,实现通过最少次数的磁盘IO完成对主键的查找
5.为了保证数据完整性支持外键约束,我们插入,更新,删除时,需要对外键也进行操作
6.当从表中反复查询相同行时,自适应哈希索引会自动接管这些查询,此时查询效率和哈希表相同
InnoDB使用时注意事项
1.我们可以为最频繁查询的列指定为主键,如果我们自己没有指定主键,那么会自动给我们隐式创建一个自增id作为主键
2.在每秒提交数百次事务的服务器上,结合存储设备的写入速度,关闭事务的自动提交,增大吞吐量,我们可以更改配置文件,autocommit=off设置,但是设置后每一条指令(update,delete,insert这些都是我们刚刚说的事务),都需要我们手动去commit
3.不要使用lock tables语句,因为我们InnoDB的锁粒度是行级锁,我们本可以在高可靠性的前提下使用行级锁,就不要使用表级锁降低我们的效率了
InnoDB存储引擎使用
我们现在mysql默认是使用InnoDB存储引擎,但是当默认存储引擎不是InnoDB时,当我们想要创建InnoDB表,我们可以在创建表的时候指定默认的存储引擎

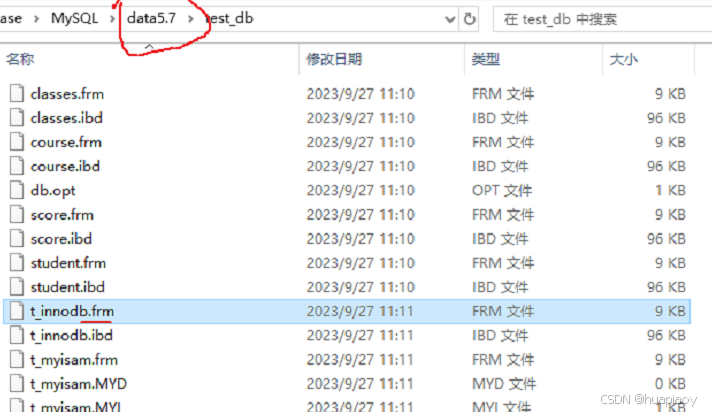
那我们创建了一个InnoDB为存储引擎的表后,我们会在data_dir/test_db这个目录下生成一个用来存储真实数据的物理文件,命名格式为表名.ibd
这里还有一个sdi文件用来存表信息描述文件(JSON格式)
注:这里8.0和5.x还有所不同,因为5.x以及之前的版本还有一个.frm的二进制文件来记录和描述表定义的信息
(三)MyISAM存储引擎
这个存储引擎是5.5之前的存储引擎,使用myisam存储引擎的表占用空间少(因为他不支持事务,不用记录大量事务日志,同时他的索引和数据是分离的,InnoDB的索引和事务是在一个文件的,数据存储格式也比较紧凑),同时他也是一个表级锁,所以限制了读/写操作的性能,通常用于中小型web应用和数据仓库配置中只读或者主要为读的场景
MyISAM存储引擎的特性
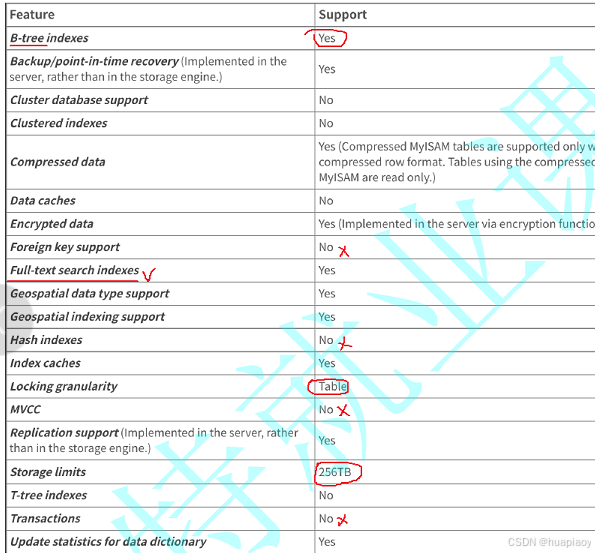
我们可以跟刚刚的InnoDB存储引擎特性比,我们发现还是差了不少的
面试题:
MyISAM与InnoDB的区别:1.InnoDB支持外键,MyISAM不支持
2.InnoDB支持事务,MyISAM不支持
3.InnoDB支持哈希索引,MyISAM不支持
4.InnoDB是行级锁,MyISAM是表级锁
5.InnoDB和MyISAM单表大小不同
MyISAM的主要优势
1.MyISAM表的最大行数比较大,同时每个表最多可创建64个索引,每个索引最多包含16个列(但我们一般用不上这么多)
2.支持并发插入(如果没有空洞,就可以直接在末尾多个线程同时插入数据,如果有空洞就要对表加锁,然后串行执行)
空洞就是因为我们删除myisam表中的记录时,被删除记录所占用的空间并不会立即被操作系统回收产生的浪费空间就叫空洞
3.因为我们索引和数据是两个文件,我们可以指定文件放在不同设备的不同目录中,加快访问速度
4.blog和text数据类型也可以被索引
5.在索引列中允许使用null值
6.表中varchar和char列的长度总和最多可为64kb
7.unique约束长度不受限制
MyISAM存储引擎的使用
因为mysql8.0是InnoDB为默认存储引擎,所以在创建MyISAM表时要手动指定存储引擎

我们创建之后,会根据表名生成三个不同后缀名的文件

.MYD为数据文件,.MYI是索引文件,sdi是表信息描述文件(JSON格式)
在8.0之前是frm这个二进制文件(与innodb不同,innodb5.5之后就改了,而myisam直到8.0才更改)
MyISAM表存储格式
我们刚刚说myisam的表占用空间比较小有一部分原因就是因为我们表存储格式不同
MyISAM有三种不同的存储格式,包括FIXED静态格式和DYNAMIC动态格式,根据使用的列类型自动选择,第三种是压缩格式,只能使用myisampack实用程序生成并且只能是只读格式,当我们表中没有blog或者text数据类型的列,在创建表时,结合ROW_FORMAT选项将表格式设FIXED或者DYNAMIC,使用myisamchk对压缩的MyISAM进行解压操作
1.静态格式表(FIXED)
这个格式是MyISAM的默认格式,当我们不包含varchar,blog,text这种可变长度时使用,每行都是用固定数量的字节存储,个人觉得这个很像数组,因为长度固定,所以可以根据索引中行号×长度能够快速计算出行位置,所以每次读取存取是很搞笑的
特点:
这里之所以可以使用varchar是因为会按照varchar的最大长度来分配空间
2.动态格式表(DYNAMIC)
当表中包含可变长度列时,我们的表格式就位动态存储格式
具有以下特点:


3.压缩格式表
因为他是把我们数据进行了压缩,生成了只读格式数据表,我们来看一下他的特点即可
特点:占用少数磁盘空间,最大限度减少了磁盘使用
压缩表为只读的,不可以在表中更新或者添加数据
(四)MEMORY存储引擎
使用MEMORY存储引擎创建的表,内容存储在内存中,所以他不是持久化的,当停电或者服务器崩溃时,数据就会丢失,因此我们可以使用这个存储引擎做缓存
使用场景:
涉及到需要快速访问的数据,当服务器停止或者重新启动时数据丢失
只读或者已读为主的数据访问场景(有限的更新)
MEMORY存储引擎的特性:
1.不能包含可变长度类型(blog和text)可以把varchar使用固定长度存储
2.支持auto_increment列
3.MEMORY表在所有客户端之间共享
4.支持哈希索引和B+树索引
5.由于使用单线程,在高负载情况下,即使MEMORY是在内存上的存储引擎,他的性能也不一定比InnoDB快
MEMORY存储引擎的使用
我们想使用MEMORY作为存储引擎需要手动指定

因为数据在内存中保存,所以MEMORY表不会在磁盘上生成数据文件,表信息描述文件在.sdi文件中
同时MEMORY存储引擎还可以再创建表时直接加载数据,具体实现如下

如果服务器重启,我们表中的数据会丢失,我们还可以通过--init-file=path来执行我们的sql文件中的命令
内存管理
我们删除单行数据,并不会回收内存,只有在删除整个表时才会回收内存,当不需要内存表的内容时,我们可以通过delete删除所有行,或者使用drop table来删除整个表,就会自动释放这个表的内存,如果我们就像删除这一行的内存,我们要使用alter table engine=memory 命令重建表
max_heap_table_size:同时我们可以通过系统变量来控制内存表最大大小限制,默认为16MB,要控制单个表的大小,我们要在创建表之前,设置一下这个值(不要改变全局max_heap_table_size除非要设置我们所有的内存表都这么大),以下是两个例子

(五)CSV存储引擎
csv是逗号分割值的缩写,本质上就是用纯文本数据来存储表格数据,行中的值使用逗号来分割
创建csv表
同样的我们依旧要手动指定csv为存储引擎

创建CSV表时,会有三个文件,首先是.csv为扩展名的文件,用来使用逗号分隔值的格式保存数据,扩展名为.csm文件,用来存储表的状态和表中的行数,以及.sdi为后缀的表信息描述文件(JSON格式)

那既然csv文件是用文本保存数据,那么我们就可以在csv文件中直接写入数据,但是因为是我们手写可能会出错,我们就可以使用check table和repair table语句来验证或者修复损坏的csv
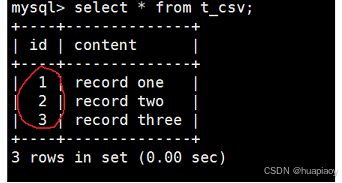
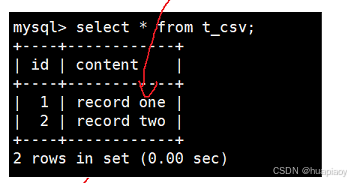
我们先插入两条数据并查询一下

然后我们在里面手动写第三条数据
我们再一次执行查询时,我们是查询不到这个第三条数据的,这是因为我们的csm文件中并没有记录新增的行,所以我们没有查询出来,我们可以使用repair table来验证或者修复损坏的csm,然后我们再次查询
那我们再来一次错误演示,比如我们把csv文件内容修改错误

此时我们再次检查
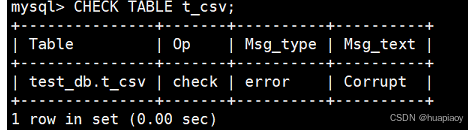 就会发现已经error
就会发现已经error
然后我们进行修复
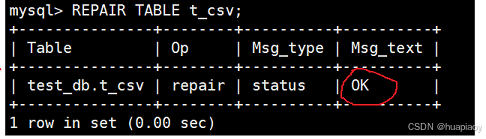
 注意我们这里发现错误数据会把他删除,同时也会删除她之后的所有数据,这里是因为我们正好是最后一个数据没有体现
注意我们这里发现错误数据会把他删除,同时也会删除她之后的所有数据,这里是因为我们正好是最后一个数据没有体现
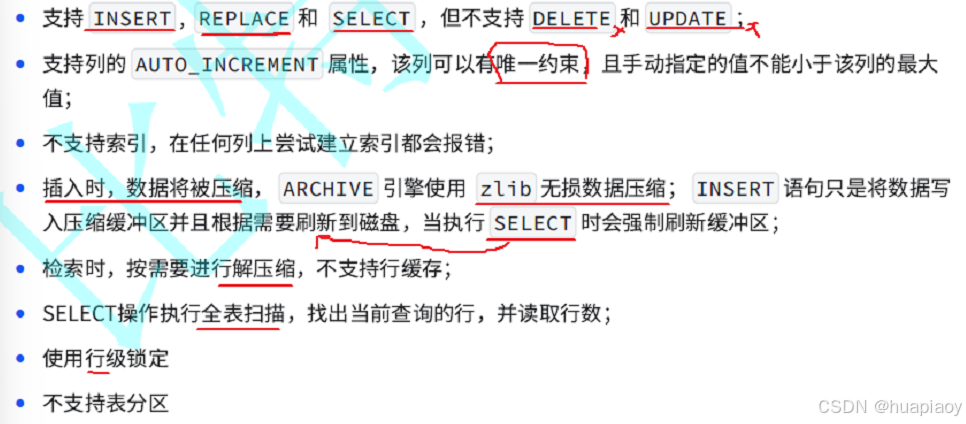
csv存储引擎不支持索引,csv存储引擎不支持分区,使用csv存储引擎创建的表中所有列都必须not null
(六)archive存储引擎(归档)
使用archive存储引擎创建的表,存储大量不被索引的数据且占用空间小,一般用于归档数据的存储。(如果我们有需要存储,但又很少访问的数据可以使用这个存储引擎)
archive的特性:
我们手动指定存储引擎后创建表会生成两个不同后缀的文件,.ARZ为后缀的数据文件,.sdi为后缀的表信息描述文件,ARN文件在优化操作期间可能出现
(七)BLACKHOLE存储引擎
blackhole存储引擎接受数据,但不存储数据,检索时总是返回空结果(一般用来调优时使用)
特性:

用途:
(都是为了调优)
通过比较开启/不开启二进制日志记录的时间,来测量二进制日志的开销
本质上是一个“误操作的存储引擎”,用来查找与存储引擎无关的性能瓶颈
我们使用blackhole存储引擎仍然需要手动指定,因为内部不存储数据,所以只有sdi文件(表信息描述文件)
(八)MERGE存储引擎
MERGE存储引擎又叫mrg_myisam引擎,允许对一系列相同的myisam表分组,把他们作为一个对象引用,这里相同的表就是所有表中的列都是相同数据类型和索引信息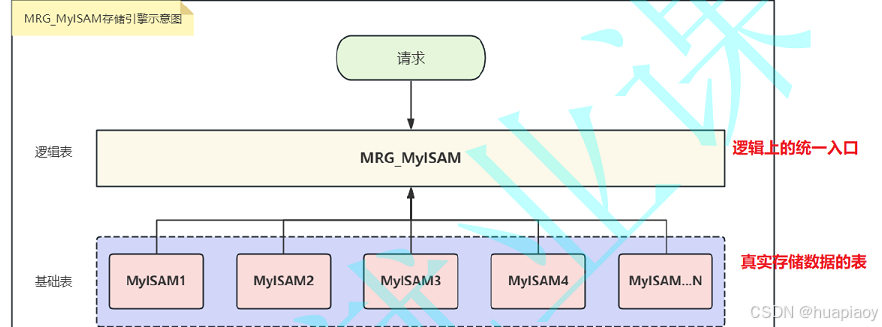
创建merge表
在mysql8.0中InnoDB是默认存储引擎,所以在创建表的时候需要指定存储引擎
创建merge表必须指定union =(list-of-table)选项,表示我们要使用的是哪一些表还可以通过insert_method选项来控制如何对merge表进行插入操作,first或者last值分别表示在第一个或者最后一个表中进行插入,如果没有指定这个选项,或者指定为no就会报错,我们可以指定这个值为一个固定的表名
我们创建完之后会在磁盘存一个.mrg文件,其中包含了包含的myisam表的名称,和插入格式也会存储在里面,.sdi为表信息描述文件
操作merge表
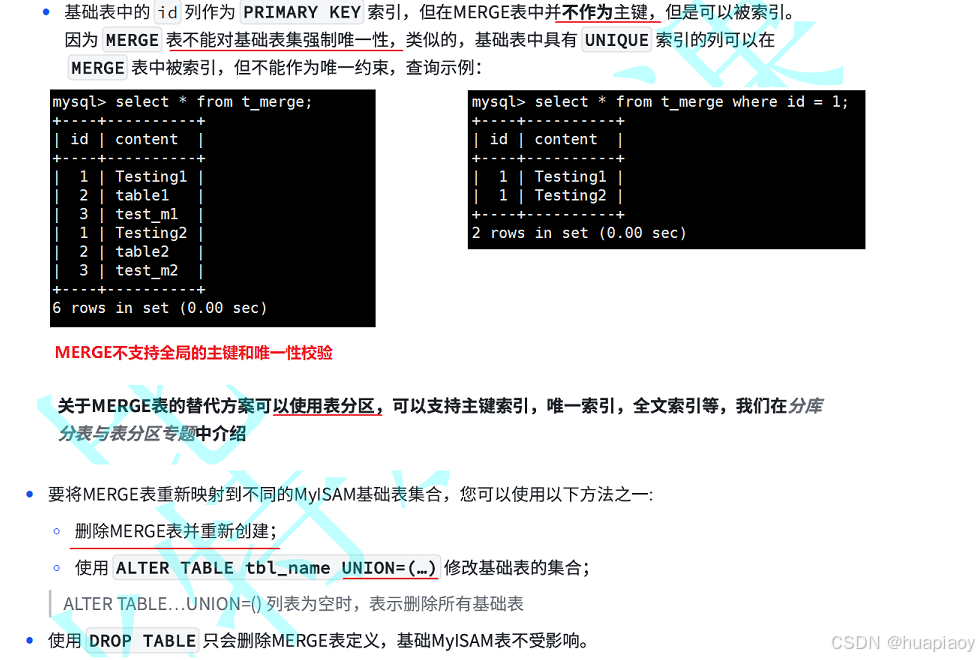
常见面试题
InnoDB和MyISAM的区别
InnoDB是支持事务的,MyISAM是不支持事务的
InnoDB是mysql5.5之后的默认存储引擎,之前则是MyISAM
InnoDB的文件只有两个,一个是sdi,一个是idb(存数据和索引)
MyISAM有三个MYI(存索引),MYD(存数据),sdi(存表信息描述)
InnoDB支持外键,MyISAM不支持
InnoDB支持哈希索引,MyISAM不支持
InnoDB是行级锁,MyISAM是表级锁