【DeepSeek新开源】DeepSeek-OCR如何用“视觉压缩”革新长文本处理
最近DeepSeek团队刚放出DeepSeek-OCR项目,不再将其视为一个简单的OCR(光学字符识别)工具,而是将其作为一个开创性的实验平台,旨在探索和验证一个激进的理念:我们能否利用视觉模态作为一种超高效的文本信息压缩媒介? 即,将长篇的数字文本“渲染”成一张图像,再用一个强大的视觉语言模型(VLM)从这张图像中“读”出原文。
接下来我们一起看下DeepSeek-OCR从“视觉压缩”的核心哲学,到其创新的DeepEncoder架构和多分辨率支持,再到其庞大的数据工程和训练管线。
1. 引言:跳出文本的传统范式,用视觉为长上下文“降维”
DeepSeek提出了一个极具洞察力的观点:LLM处理长文本的计算瓶颈,源于其一维、离散的token表示。而人类视觉系统,能够以极高的并行度和效率,从一张二维图像中瞬间捕捉海量信息。
核心假设: 将一长串文本信息“渲染”到一张图像上,然后让VLM来“阅读”这张图,所需要的视觉Token数量,可能远远少于原始的文本Token数量。
- 例如: 一篇包含1000个单词(约1300个token)的文档,如果渲染成一张图片,一个高效的VLM可能只需要100个视觉token就能完整地理解其内容,从而实现超过10倍的上下文压缩。
DeepSeek-OCR正是为了验证这一“光学上下文压缩”(Optical Contexts Compression)思想而构建的一个**概念验证(proof-of-concept)模型。它以OCR任务为“试验场”,因为OCR天然地提供了一个压缩(文本->图像)与解压(图像->文本)**的映射,并且其性能可以通过编辑距离等指标进行精确的量化评估。
2. DeepSeek-OCR核心架构:一个“感知-知识-压缩”的三段式编码器
2.1 整体架构:DeepEncoder + MoE解码器
DeepSeek-OCR采用了一个统一的端到端VLM架构,由一个新颖的DeepEncoder和一个高效的MoE解码器组成。
- DeepEncoder (编码器):负责从输入图像中提取特征、进行分词,并压缩视觉表示。
- DeepSeek-3B-MoE (解码器):一个拥有3B总参数、570M激活参数的混合专家模型。负责根据DeepEncoder输出的视觉token和用户提示,生成最终的文本结果。
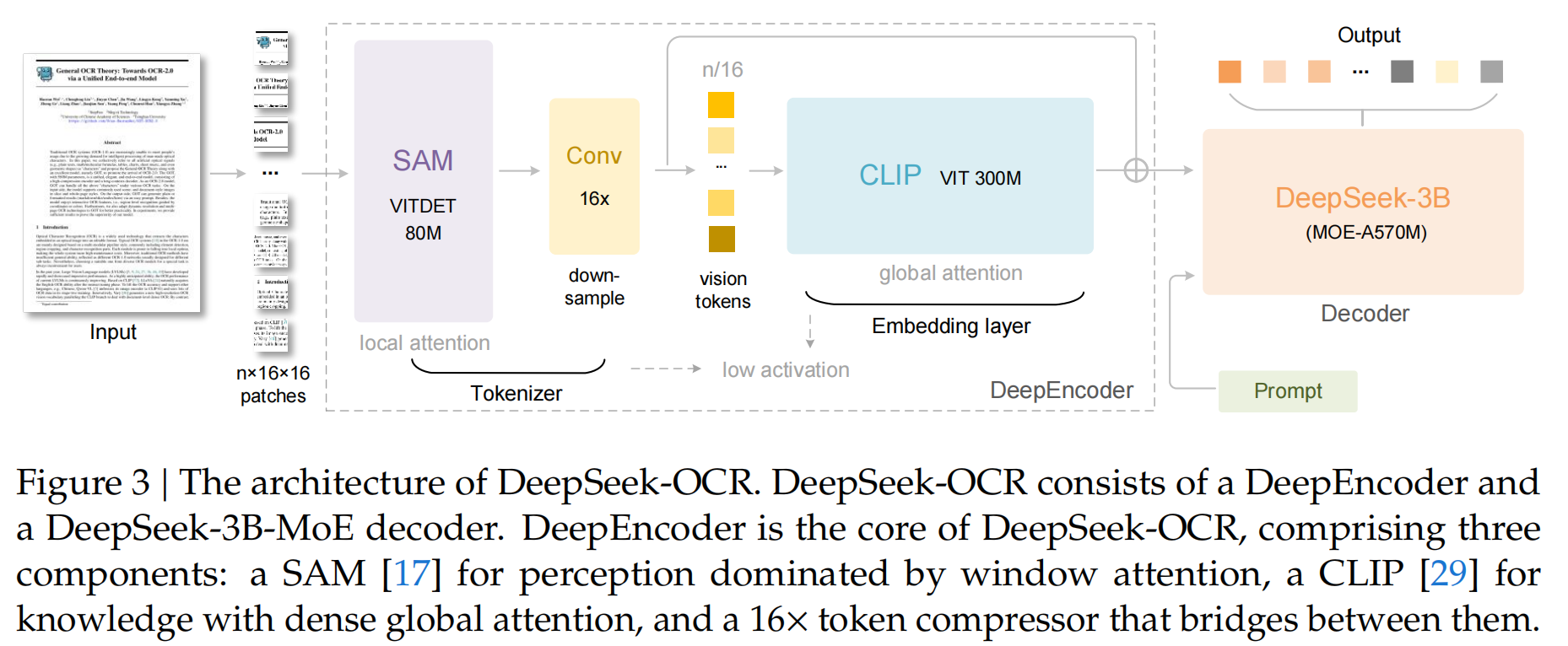
2.2 DeepEncoder详解:SAM与CLIP的强强联合
为了实现高分辨率下的低激活内存和高压缩率,DeepEncoder巧妙地将两个强大的预训练视觉模型串联了起来,形成一个“感知-知识-压缩”的三段式流水线。
-
第一部分:视觉感知层 (Visual Perception)
- 模型