基于文本+视觉混合输入的恶意流量检测方法猜想

一、写作背景:当 O(N²)遇上“肉眼可见的恶意”
2023年,随着大型语言模型(LLM)能力的爆发,许多团队开始探索将其应用于网络安全领域,尤其是恶意流量检测和代码审计。然而,一个始终困扰着安全研究人员的难题,便是LLM处理超长上下文时的高昂代价。
笔者清晰地记得,当时团队在分析一个包含超长混淆编码 Payload 的 Web 请求日志时,纯文本LLM需要消耗数以万计的 Token。每当请求长度增加,其推理延迟便随 O(N²)的复杂度急剧攀升,不仅成本高昂,且难以满足实时检测的低延迟要求。
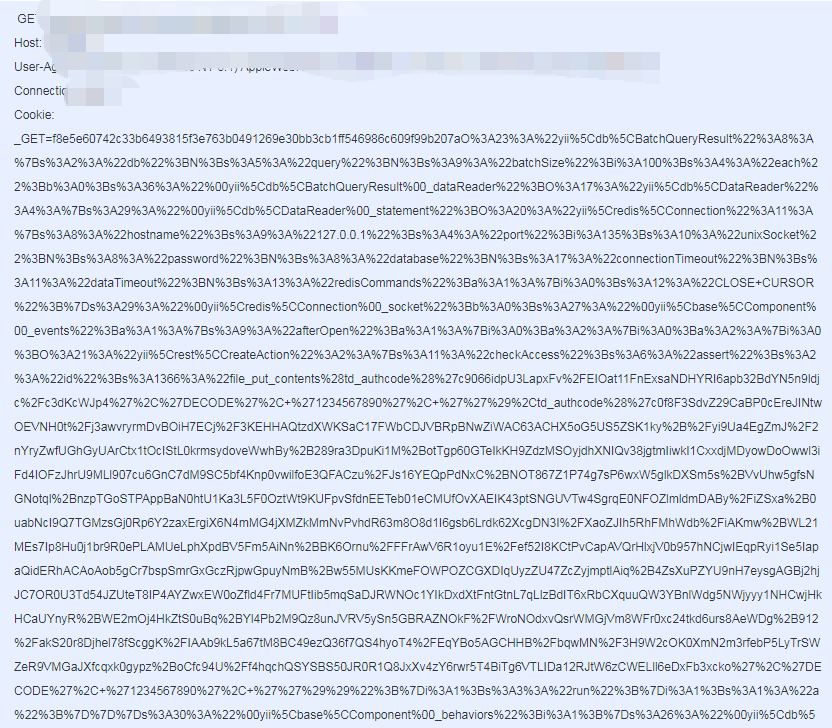
然而,令人感到无奈的是,安全分析师通常