LLAMA-Factory Qwen3-1.7b模型微调
一、LLaMA Factory介绍
-
核心特点:一站式大模型微调工具包,支持几乎所有主流开源大模型(LLaMA 系列、Qwen、ChatGLM、Mistral、Yi 等),集成了多种微调策略(全量微调、LoRA、QLoRA、IA³、Prefix Tuning 等),并提供命令行和 Web UI 操作,对新手友好。
-
优势:配置简单,支持多轮对话数据格式,内置常见数据集(如 Alpaca、ShareGPT 等),可直接对接 Hugging Face 模型和数据集,支持模型评估和部署导出,自定义超参数,界面支持中文、英文等多种语言;
-
适用场景:快速验证微调效果、中小规模数据集微调、多模型对比实验。
-
仓库地址:hiyouga/LLaMA-Factory
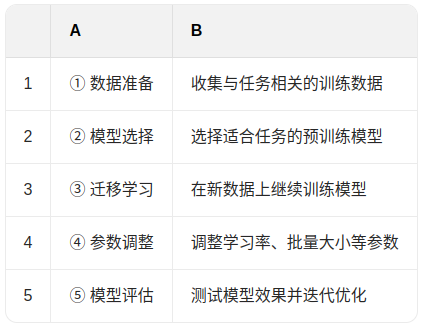
二、微调的过程
三、微调优势
-
资源效率高:相比从头训练,微调所需数据量和计算资源大大减少。
-
📦部署速度快:可以快速适配新任务,加快模型上线进程。
-
✅性能提升明显:在特定任务上显著提高准确性和泛化能力。
-
🌐领域适应性强:帮助模型更好地理解专业领域语言风格。
四、安装LLama-Factory
1、clone 源代码
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git2、安装依赖
cd LLaMA-Factory
pip install -e ".[torch,metrics]"3、检查版本
llamafactory-cli version----------------------------------------------------------
| Welcome to LLaMA Factory, version 0.9.4.dev0 |
| |
| Project page: https://github.com/hiyouga/LLaMA-Factory |
----------------------------------------------------------
4、打开llamafactory可视化界面
llamafactory-cli webui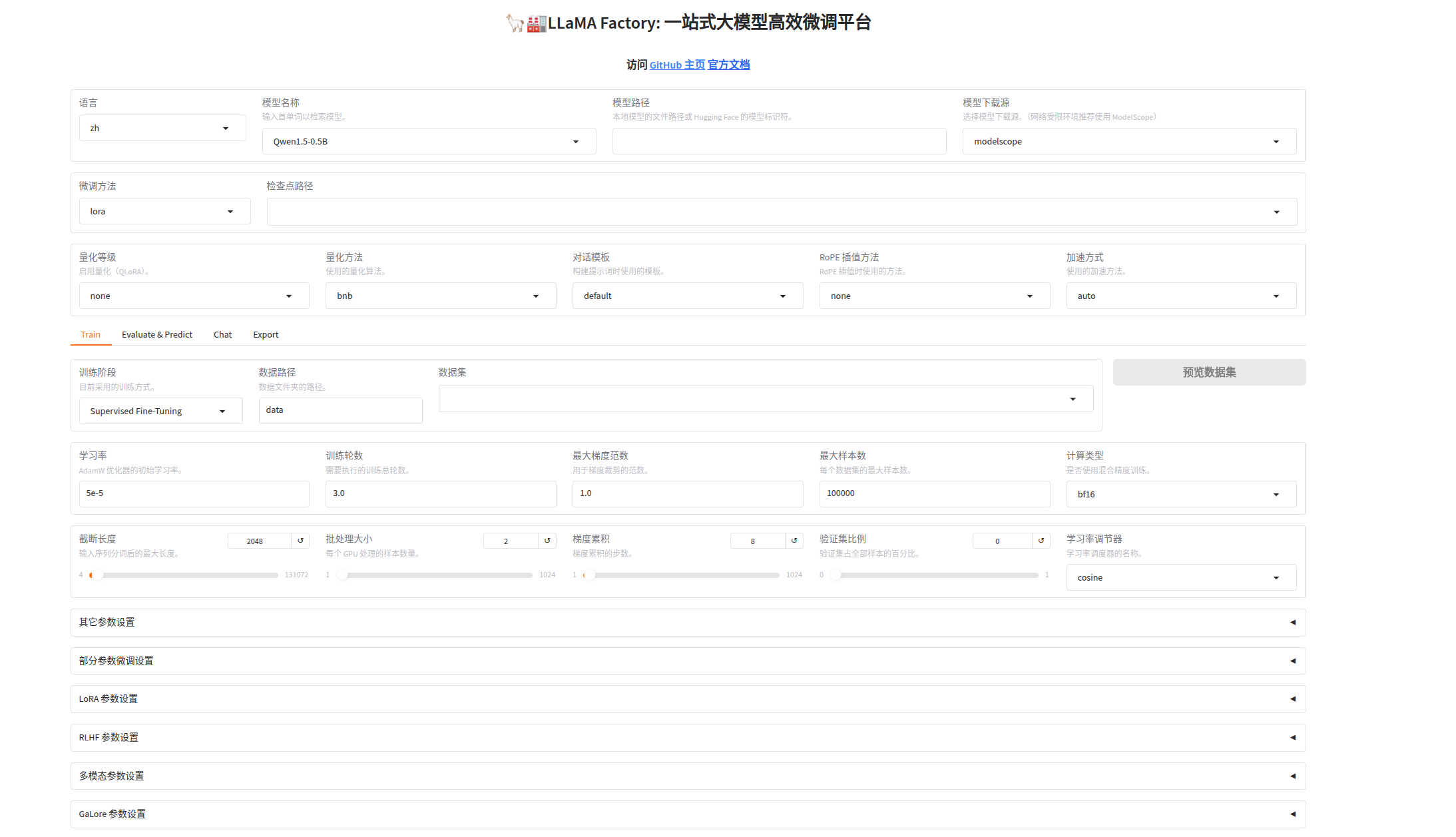
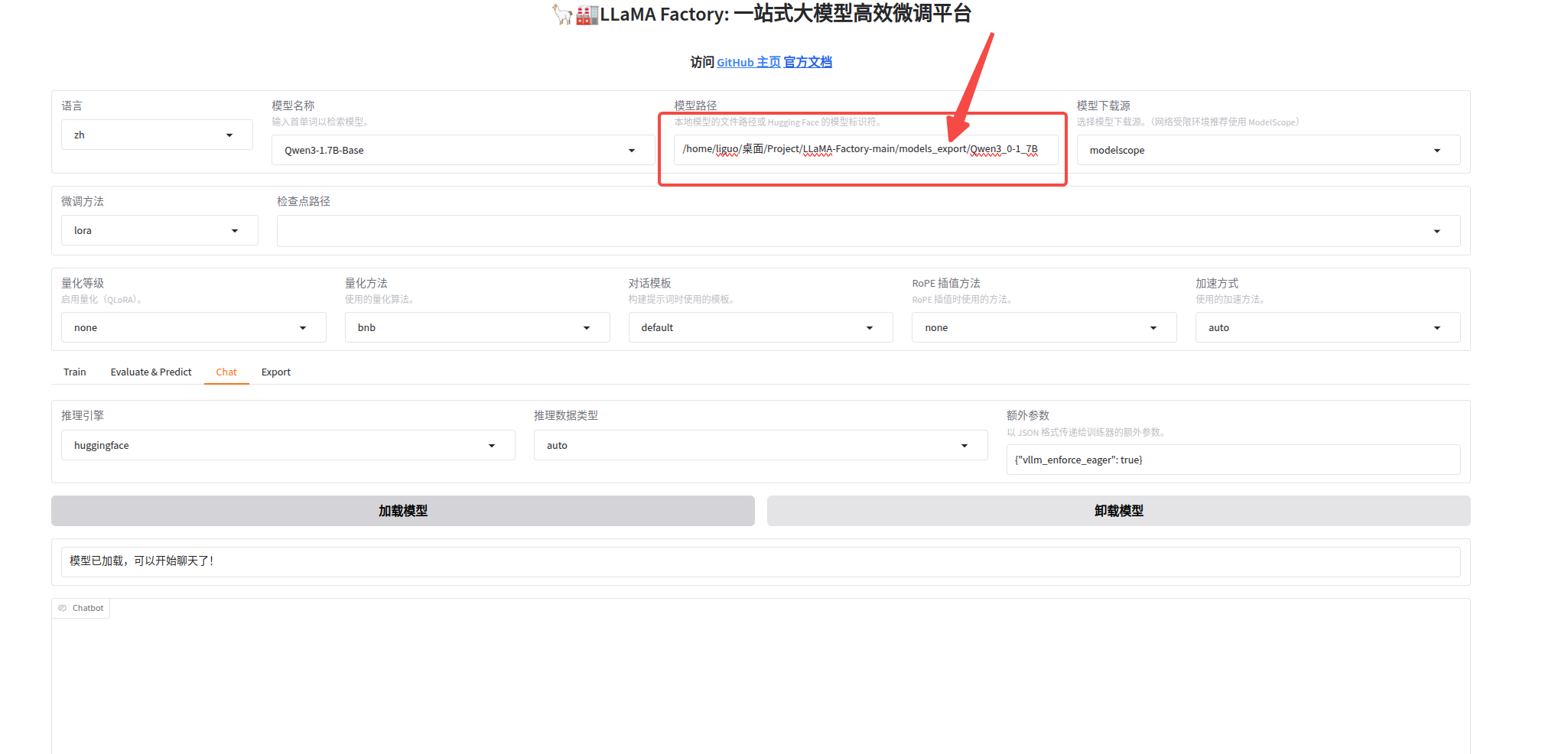
五、模型微调
在ui界面上操作,调整下属四个参数:
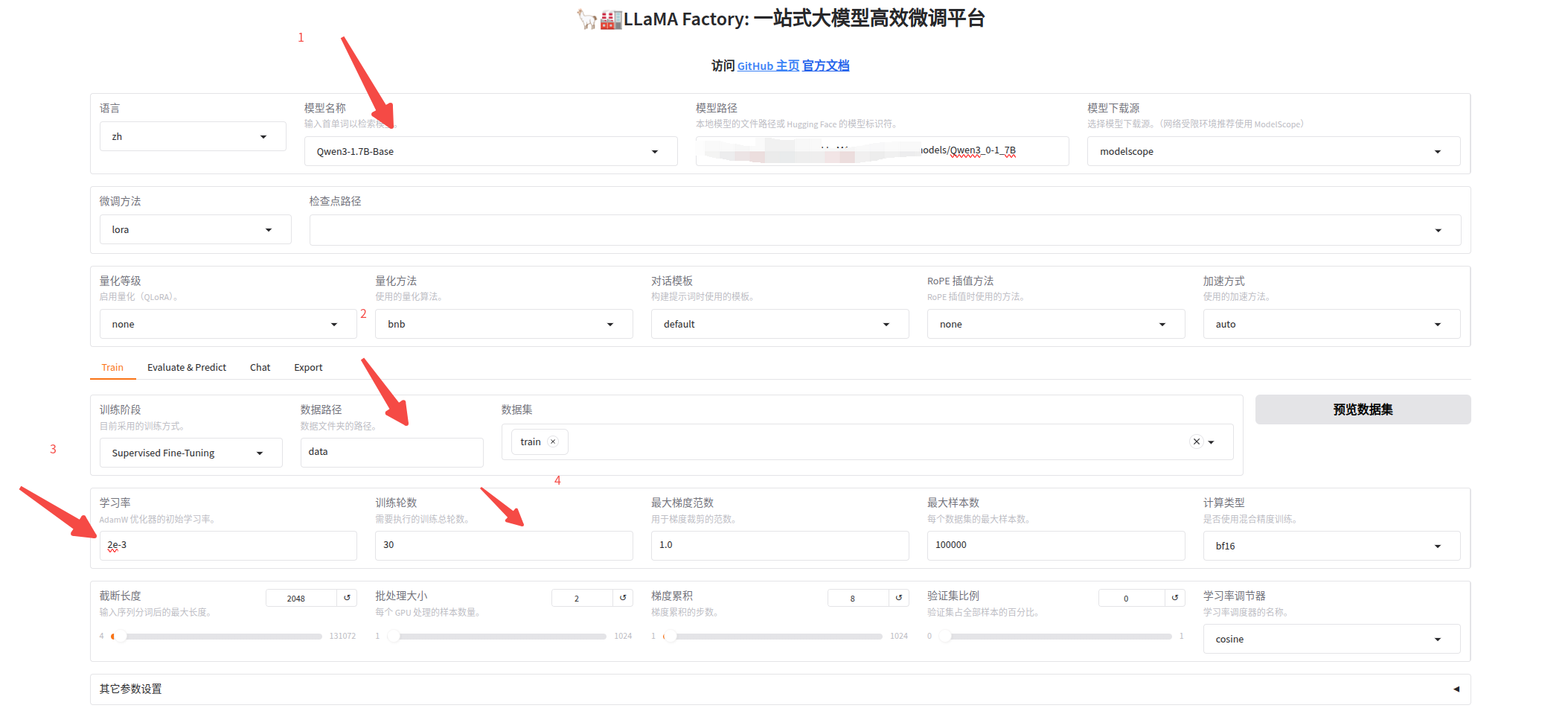
1、选择你要微调的模型,最好提前用modelscope 下载模型,然后模型路径填本地模型所在的路径
https://modelscope.cn/models
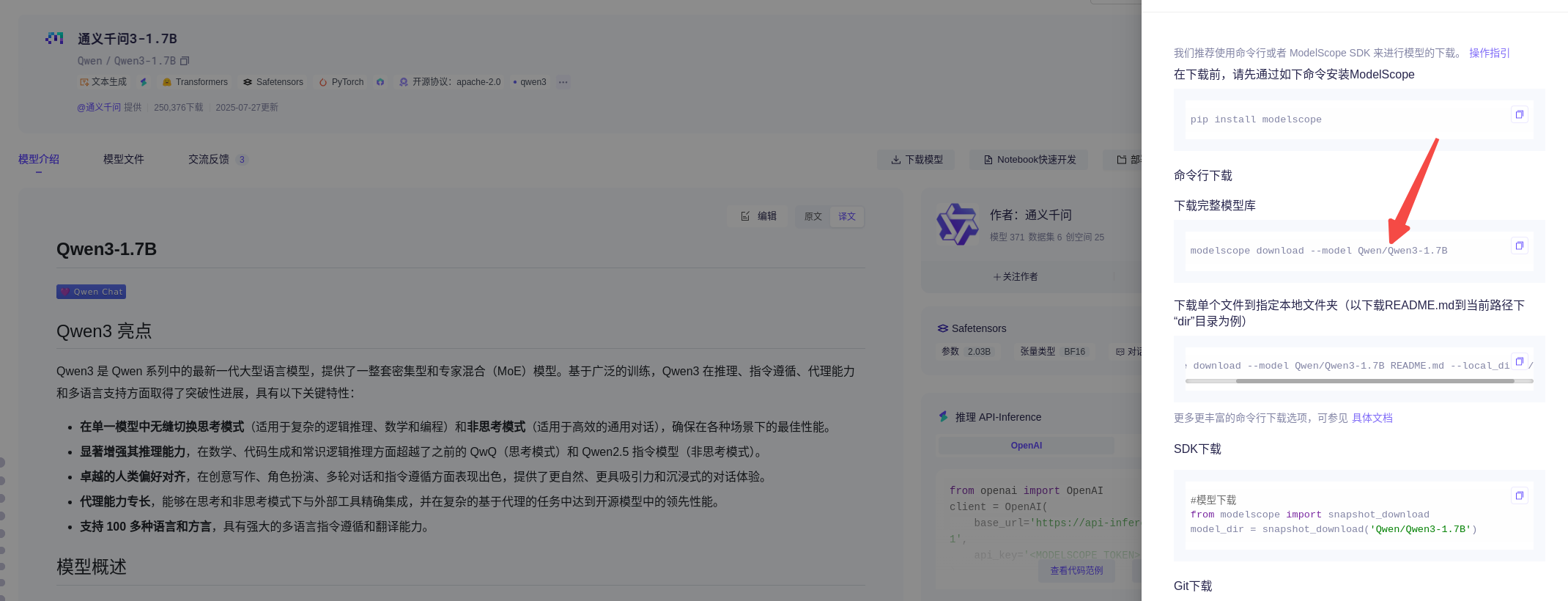
modelscope download --model Qwen/Qwen3-1.7B --local_dir2、选择微调用的数据集,LLaMA Factory本身自带一些数据集,此次用另外一个自定义的数据集,执行命令下载自定义训练集;
wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama_factory/data.zip
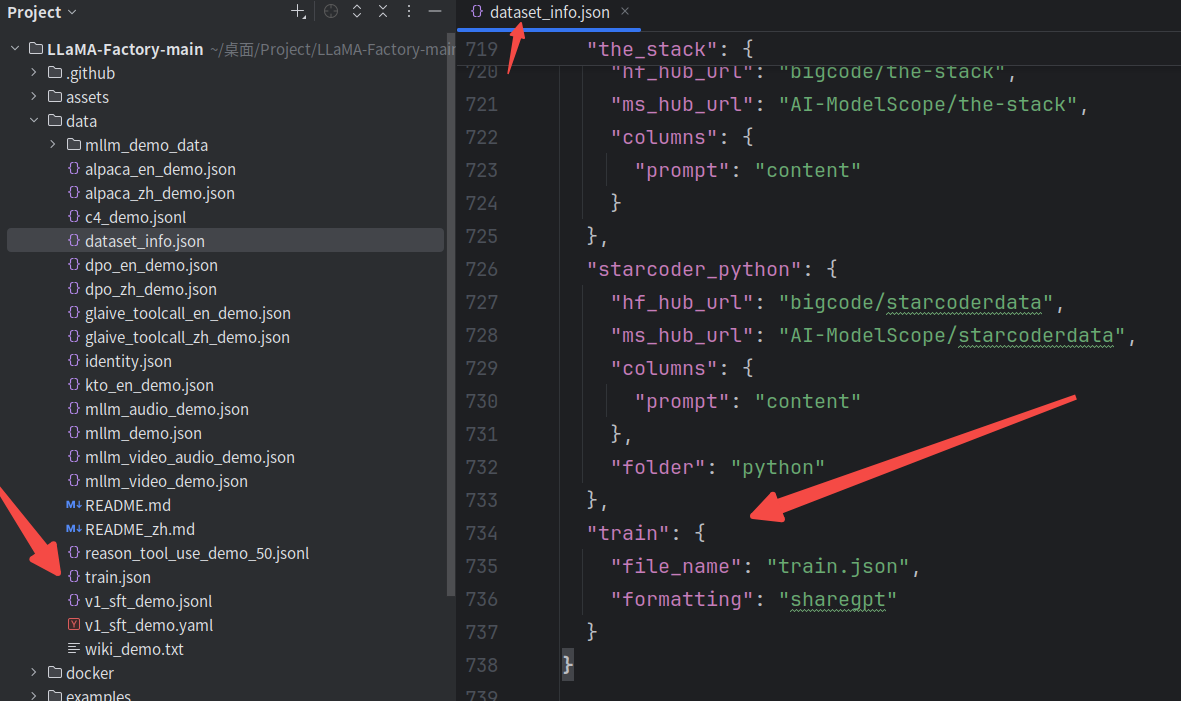
将其中的train.json复制到本地LLaMA Factory中的data路径下,同时,修改dataset_info.json,在底部增加train训练集;在回到ui界面就能看到train训练集的选项了;
3、调整学习率(非必须)
此处将学习率调的较大,主要是想快速验证模型微调后的效果,大概率是过拟合的,但可以微调前后问同一个问题,对比二者的差异;
4、迭代轮次(非必须)
此处轮次也没有设置太大,本身的训练集数据量很小,也只是想尽快出结果,毕竟也只是跑个demo;
六、微调前后模型测试
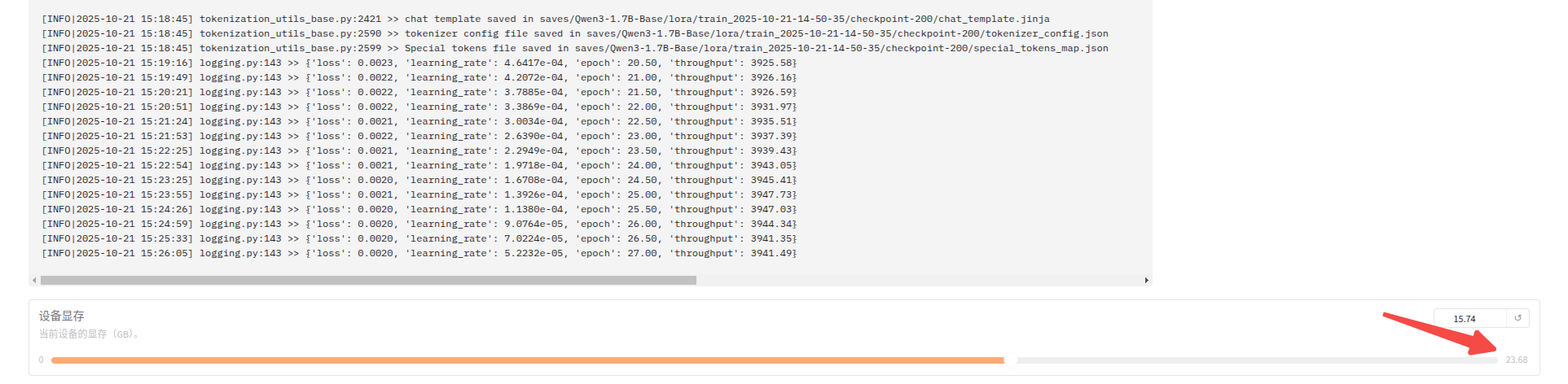
1、ui界面上可以看到实时的训练进度以及loss曲线,也可以在底部看到log日志以及显存使用量;

2、微调前

3、微调后

4、其实微调后的模型的回答更偏向我们微调的数据集,和数据集中的内容有部分一样,所以,可看出模型微调的作用,就是使其回答更靠近我们自定义的数据集;
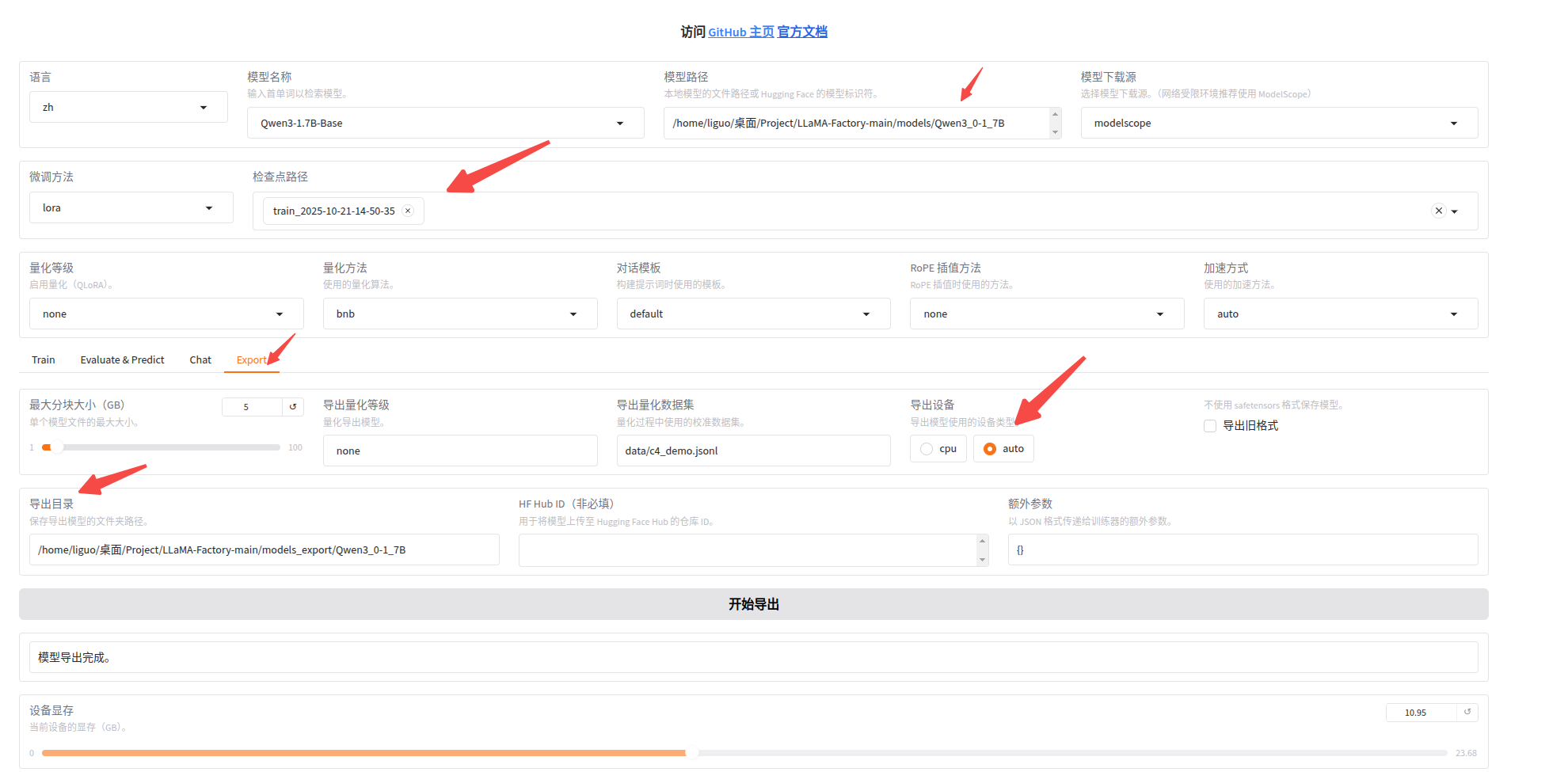
七、导出模型
按照下图选择原始模型路径以及检查点路径,可导出微调后的模型;之后在部署时,可直接使用导出后的模型,即为微调后的模型