NExF——建立3D空间上的曝光场辅助重建

https://m-niemeyer.github.io/nexf/index.html
对于实际捕获的曝光条件不一致的情况,建立一个曝光场来专门输出每一个空间点的曝光值,以此来辅助加强重建效果。
abstract
神经场景表示(Neural Scene Representations)的最新进展,使得三维重建与视图合成的质量达到了前所未有的高度。尽管这些方法在经过精心整理的数据集(如常见的基准测试)上能获得高质量结果,但当输入数据存在每张图像的曝光差异(per-image variations)时,效果往往会显著下降。例如,在同时包含室内与室外区域、或有窗户的房间等场景中,这种问题尤为明显。
在本文中,我们提出了一种新的方法——神经曝光场(Neural Exposure Fields, NExF),用于在复杂的真实场景中实现高质量、3D一致的重建与外观建模。核心思想是:训练一个神经场,用于预测每个三维点的最优曝光值,从而在学习场景表示的同时,联合优化场景的曝光。这与传统相机在每张图像或每个像素层面选择曝光不同,NExF 将这一概念推广到三维空间,在3D层面进行曝光优化。
这种设计使得我们能够在高动态范围(HDR)场景中实现准确的视图合成,无需额外的后期处理步骤或多重曝光采集。
我们的主要贡献包括:
- 一种新的神经表示,用于预测三维空间中的曝光;
- 一种联合优化场景表示与曝光场的系统,通过新颖的**神经调控机制(neural conditioning mechanism)**实现;
- 在具有挑战性的真实数据上展示了优越的性能表现。
实验结果表明,我们的方法训练速度更快,并在多个基准上实现了最先进的性能(state-of-the-art results),相较于最佳基线方法提升超过 55%。
1 Introduction
神经场景表示(NeRF 一类)已经让 3D 重建和视图合成的效果达到了新高度,但只要遇到曝光变化大的真实场景(比如室内外交界、有窗户的房间),渲染质量就会明显下降。Neural Exposure Fields (NExF) 正是为了解决这个现实问题。
在真实拍摄的多视角数据里,每张照片的亮度、曝光、色调往往不一样。相机在拍摄时会自动调整曝光,但 NeRF 这种模型默认所有图片曝光一致,结果导致:
- 某些区域过曝/欠曝;
- 渲染出来的颜色不连贯、不真实;
- 影响整个 3D 场景的一致性。
有研究从计算机图形学角度利用曝光信息:目标是复现特定曝光或恢复 HDR 以供后续色调映射(tonemapping)。这些方法依赖额外步骤或专业后处理,并不是直接产出“最接近真实外观且 3D 一致”的场景表示。
另一类方法忽略输入曝光,通过引入 per-image 潜变量(如 GLO 嵌入)来“解释”外观差异(典型:NeRF-W)。这种方法在小幅外观变化下稳健,但遇到剧烈曝光差异时会产生不理想颜色预测与局部过/欠曝。
最近方法(如 Bilarf)学习局部双边映射以解释每图像的变化,但需要额外的处理步骤和目标外观(如艺术家制作的 HDR)作为参考,限制了自动化与通用性。
NExF是把“曝光”也学成一个 3D 神经场。以前相机在 2D 图像层面决定曝光,NExF 则在 3D 空间中为每个点学习最优曝光值,并与场景的辐射场一起训练。这样模型从根本上保证了 3D 一致性,生成的视图自然曝光正确、颜色稳定。
NExF = NeRF + 3D 曝光优化:它让模型自己学会在三维空间中调节曝光,从而在高动态范围场景下也能渲染出色、真实的一致结果。

2 Related Work
2.1Neural Fields for View Synthesis
在视图合成(view synthesis)的背景下,神经辐射场(Neural Radiance Fields, NeRF) [26] 通过基于体渲染(volume rendering)的神经场优化取得了前所未有的成果,其鲁棒性远超以往的基于表面的渲染方法 [31, 45, 52]。这项突破催生了一系列后续工作,在渲染质量 [2–4] 和 渲染速度 [11, 18, 28, 32, 42, 43, 53] 等方面不断改进。由于这些工作性能卓越,本文采用经过修改的 ZipNeRF [4] 作为场景表示。
值得注意的是,我们没有选择 3D Gaussian Splatting (3DGS) [18] 作为场景表示,因为它在复杂数据上表现退化,且在与我们基于 MLP 的神经曝光场 [32] 联合优化时稳定性较差。
2.2Neural View Synthesis Beyond RGB Captures
已有若干研究探索了如何利用神经场进行非传统输入的视图合成。例如,[27, 47] 研究了RAW 数据,[9, 54] 研究了低光照拍摄。与本文相关的工作包括 [6, 13, 15, 16, 47],它们研究如何学习 HDR 表示的色调映射(tonemapping)。
HDRNeRF [15] 将辐射转换到对数域(log domain),通过对 NeRF 进行曝光条件化,实现了出色的 HDR 渲染效果。但 HDRNeRF 依赖商业 2D 色调映射软件 [14],并且缺乏 3D 一致性。
后续的 [16] 在此基础上加入了一个局部曝光预测场,但需要两阶段训练,依赖由已训练的 NeRF 生成的伪真值(pseudo ground truth)监督该模块,因此仅适用于小规模、合成场景。
我们的方法可以端到端训练,通过联合优化 NeRF 与神经曝光场实现学习。此外,我们的模型能够在具有曝光变化的大规模真实场景中,生成高质量且三维一致的结果。
RAW 数据 是相机传感器直接采集的光强信息,还没有经过任何图像处理,因此能反映最真实的光照。用 RAW 数据训练神经辐射场(NeRF)能让模型学习物理上正确的光线分布。
低光照拍摄 则是指光线不足的场景拍摄,例如夜景或昏暗室内。由于曝光不稳定、噪声多,这类数据对 NeRF 的一致性建模提出更高挑战,因此研究者常会在模型中显式地引入曝光或亮度建模机制。
2.3Neural View Synthesis for In-the-Wild Data
早期的视图合成研究主要在合成或干净的真实数据上进行评估,后来一些工作开始转向复杂的真实世界(in-the-wild)数据。
开创性的 NeRF-W [21] 引入了 生成潜变量优化(GLO) [5],用于分离每张图像的外观变化。测试时,通过固定潜变量(通常为零向量)渲染新的视图,以获得 3D 一致的外观。[4] 的后续工作在此基础上改进,通过在 MLP 的瓶颈层中引入仿射 GLO 变换,使结果更加一致。
然而,该方法无法直接控制最终颜色预测,在强曝光变化下会趋向于平均颜色预测,导致部分区域过曝或欠曝(见图 1b)。
Bilarf [49] 则为每个视角优化 3D 双边网格(bilateral grid),在测试时可通过第二阶段优化将目标图像的外观“提升”到 3D 空间中。但该过程内存开销大、耗时高,并且需要一个由专业艺术家或商业 HDR 软件 [1] 创建的参考图像。
相比之下,我们提出的方法通过联合优化神经曝光场与场景表示,能够在设计上保证 3D 一致性与良好的曝光质量,且无需额外的后处理或人工参考图像。

3 Method
图3概括了我们的方法
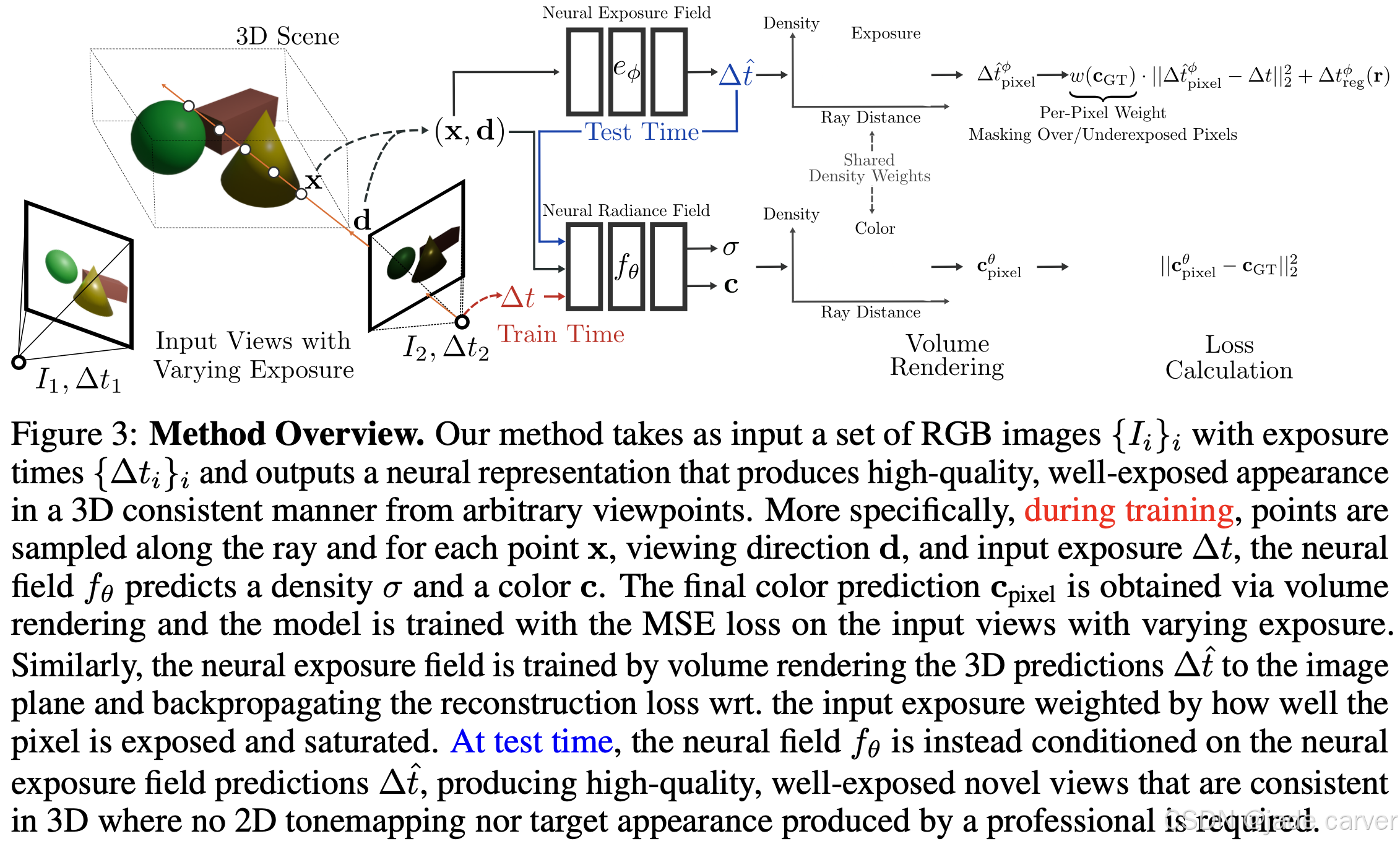
3.1 Neural Radiance Fields



关于zip-nerf的简单补充
https://arxiv.org/pdf/2304.06706
nerf系列文章总结,very nice!https://zhuanlan.zhihu.com/p/614008188
zip- nerf介绍 https://zhuanlan.zhihu.com/p/622325164
Zip-NeRF 是 Google Research 等人在 ICCV 2023 上发表的一篇论文,标题为 “Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields”。Medium+3arXiv+3jonbarron.info+3
属于神经辐射场(NeRF)技术的一个变种,目标是 提升训练速度、提升渲染质量(尤其是减少别名伪影 “aliasing” 问题),并结合近年来 “网格/体素” 表示(grid-based representation)与传统 MLP 表示的优点。


使用Zip-NeRF作为底座的原因
对比其他结构(如 3D Gaussian Splatting, 3DGS)在“复杂数据 + 联合优化”情境下不如 Zip-NeRF 稳定。另外Zip-NeRF 本身具备较好的训练效率和表示能力,作为基底能够更顺利地与 “神经曝光场(Neural Exposure Fields, NExF)” 的机制结合。
潜在曝光调节(Latent Exposure Conditioning)
在许多真实场景的拍摄数据中,每张图像都有不同的曝光时间(exposure),并且这些曝光值(∆t)通常是已知的(作为“真值”提供)。因此,作者将每张图像的曝光值作为额外输入,与原始的 RGB 图像 一起送入模型,用于条件化颜色预测。换句话说,模型不仅看像素和视角,还知道该图像的曝光是多少。
他们遵循了传统的 条件随机场(Conditional Random Field, CRF) 校准方法 [10,15],
在对数辐射度空间(log-radiance domain)中进行曝光调节。但与以往不同的是:以往方法直接在输入或输出层做曝光调节,而作者选择在 MLP 的瓶颈层(bottleneck vector) 进行调节。

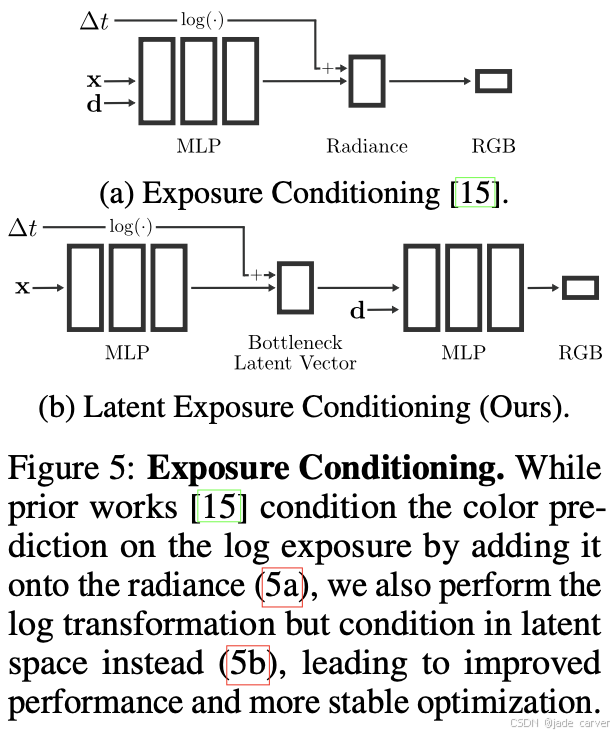
3.2 Neural Exposure Fields






| 项目 | 内容 |
|---|---|
| 核心创新 | 将曝光建模为 3D 函数而非 2D 图像函数 |
| 模型形式 | 一个与场景网络联合训练的 MLP(Neural Exposure Field) |
| 优势 | 跨视角一致的曝光表现,适合高动态范围场景 |
| 损失组成 | (1) 曝光良好性 (2) 色彩饱和度 (3) 空间平滑正则 |
| 关键假设 | 相近的 3D 点应具有相似的理想曝光 |
3.3 Optimization
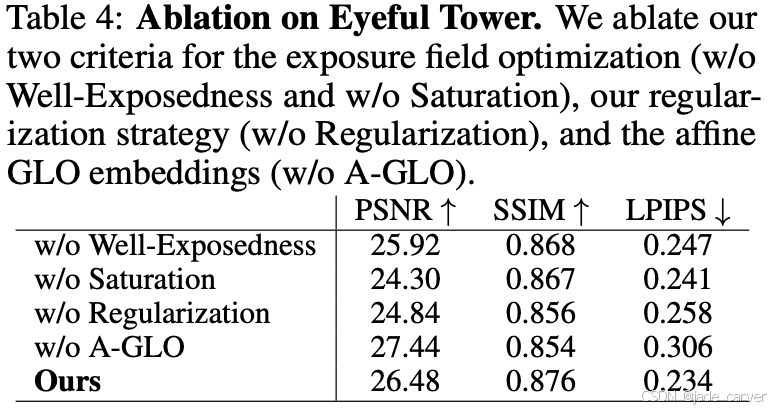
模型的目标是直接从多视角 2D 图像中学习出每个 3D 点的最优曝光,以生成高质量、跨视角一致(3D-consistent)的外观。但是并非所有输入图像的像素都是“曝光良好”的。为避免错误学习,作者提出:仅对那些曝光良好且饱和良好的像素,才将曝光误差的梯度反向传播(backpropagate)到模型。
换句话说,如果某个像素过暗或过曝,则其曝光信息被忽略;只有“高质量像素”参与训练曝光场。这样就不需要假设“所有图像都曝光正确”,只需假设“在某些视角下,大部分3D区域都有良好曝光”。
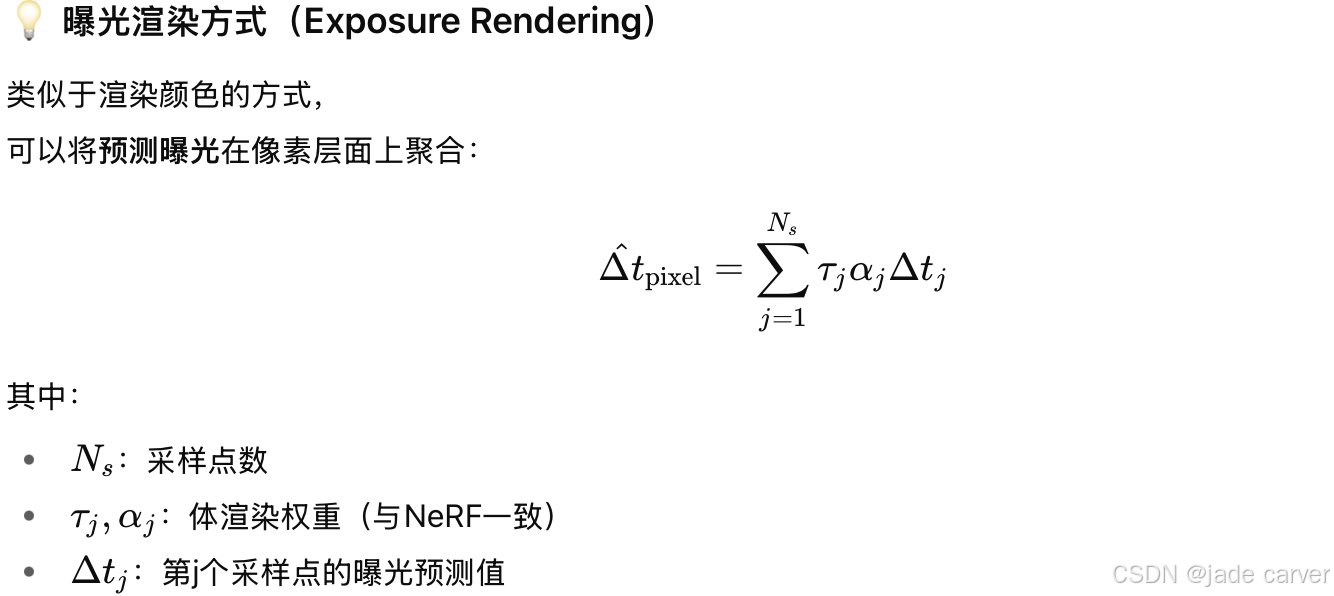



训练数据仅需:多视角 RGB 图像、每张图像的 曝光时间(∆t)
小结:
| 项目 | 内容 |
|---|---|
| 学习目标 | 从2D图像中学习每个3D点的理想曝光 |
| 关键技术 | 选择性反向传播 + 曝光场正则化 |
| 损失函数组成 | 曝光一致性项 + 空间平滑项 |
| 输入需求 | 普通RGB + 曝光值(∆t) |
| 不需要 | HDR ground truth |
| 结果 | 高质量、3D一致、跨曝光鲁棒的渲染效果 |
4 Experiments

Baselines
| 方法 | 类型 | 备注 |
|---|---|---|
| NeRF [26] | 基础体渲染模型 | 无HDR或曝光处理 |
| ZipNeRF [4] | 高效NeRF变体 | 作为作者方法的主干网络 |
| 3DGS [18] | 3D高斯点表示 | 高效实时渲染 |
| NeRF-W [21] | 可处理外界变化(illumination, exposure) | |
| HDRNeRF [15] | 专为HDR学习设计 | |
| HDR-GS [6] | HDR高斯表示方法(唯一需要HDR输入) |
4.1 View Synthesis with Input Exposure

在第一个实验中,我们评估了我们选择的神经场景表示和新型的潛在暴露调节机制的性能。任务是在不同的输入曝光下重建测试视图。ID (in-distribution)” 表示曝光值在训练时出现过的情况,OOD (out-of-distribution)” 表示曝光值未在训练中见过。
在真实场景中,采集不同曝光的RGB图像十分常见,而捕获HDR数据通常只在专业或合成环境中可行。说明模型在实际可用性与性能平衡上具有明显优势。
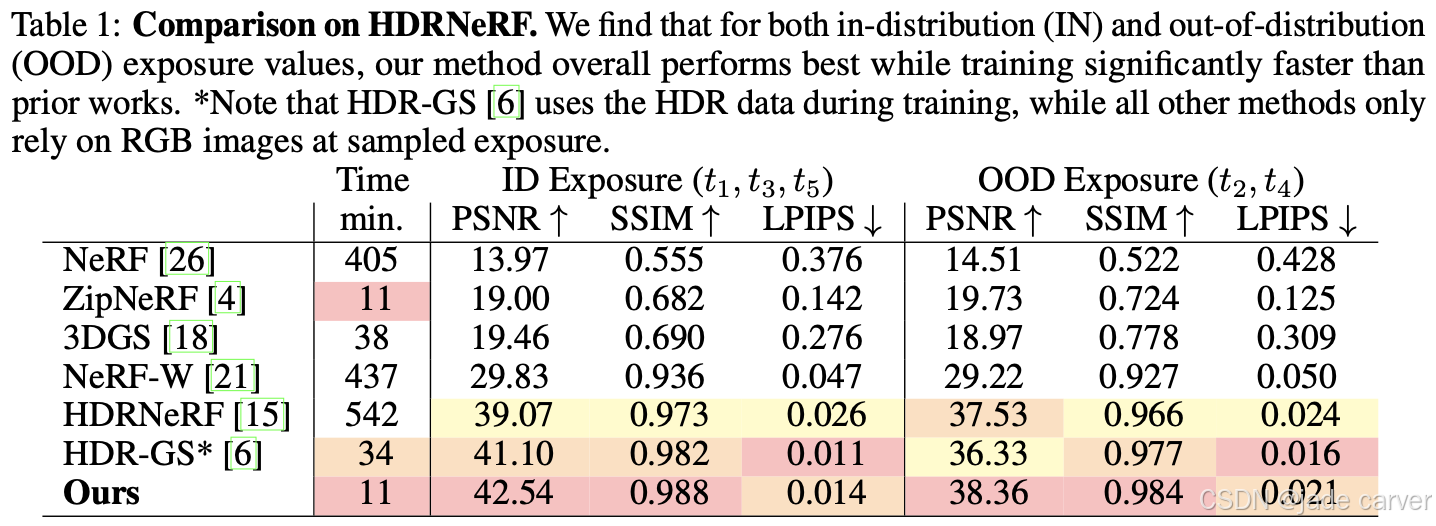
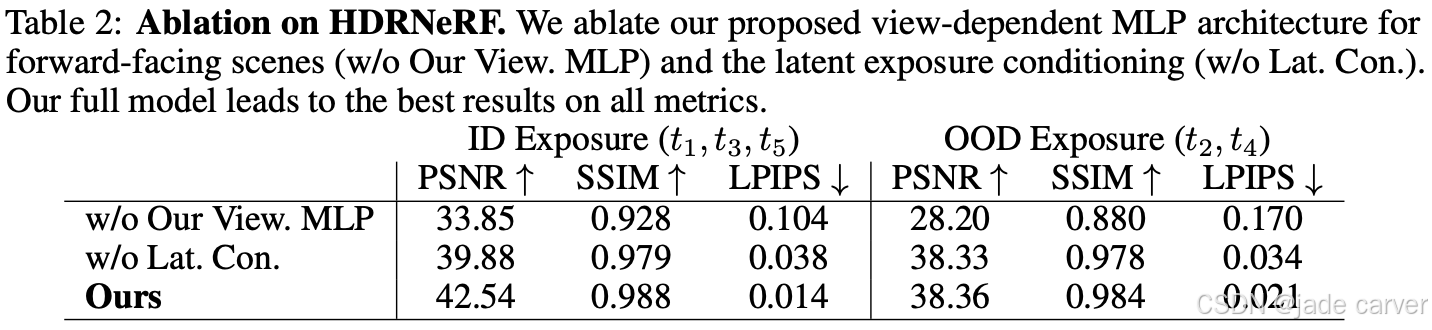
此外,我们还在Tab.2中为曝光重建实验进行了消融研究,以验证重要成分的相关性。我们发现,我们的模型没有与视图相关的MLP参数化(见Sec.3.1)导致结果退化,并倾向于过度拟合输入图像。如果我们在模型中不使用我们的潛在曝光条件,我们会发现质量下降,因为模型的表现力较差,预测视图的清晰度也较差。我们的完整模型在所有指标上都取得了最佳结果。
4.2 View Synthesis with Neural Exposure Field

之前的实验关注 特定曝光值下 的重建;现在的目标是让模型学会 自动调整曝光,使整个场景都曝光得当(不过曝或欠曝),实现全局一致的HDR感知重建。
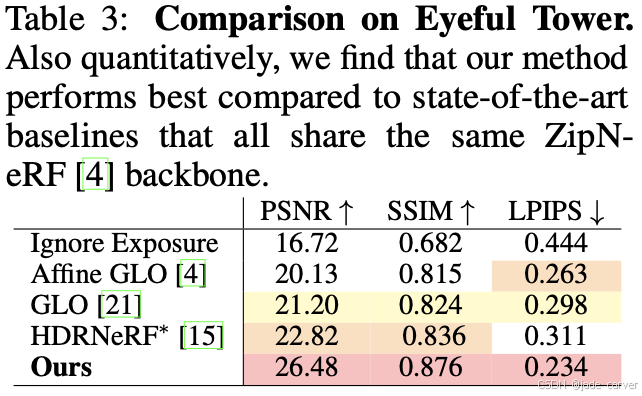
本方法在所有指标(PSNR, SSIM, LPIPS)上均优于所有基线方法(见 Tab. 3)。HDRNeRF* 是第二好的方法(仅用RGB+曝光训练)。



消融实验
真实场景(In-the-Wild Captures)
使用手机拍摄的真实数据(来自 [49] 的 statue 场景),输入图像的曝光差异非常大;本文方法能学习到3D一致的曝光场;生成视觉上自然、曝光均衡的渲染;推理(test time)阶段无需输入曝光值,也不需要由艺术家或HDR软件制作的目标外观。

大面积场景重建(Large-Scale Reconstruction)
测试于 Alameda 场景(ZipNeRF 数据集中的房屋级别场景);所有方法都使用相同 ZipNeRF 骨干网络;
对比发现:
- 忽略曝光 → 渲染完全崩坏;
- 使用 affine GLO → 略有提升,但仍出现过曝/欠曝;
- 本文方法 → 输出在所有区域都曝光均匀、一致且细节清晰;
- 甚至优于Ground Truth(单曝光拍摄)。


3D Exposure 的概念创新
虽然传统上“曝光”是相机相关参数(camera-dependent),
但本文提出的“optimal exposure”是一种空间可变的学习变量(spatially-varying learned variable)。
它不是物理意义上的曝光,而是一个神经学习到的场;类似摄影师在HDR摄影中局部调节曝光;模型学习到每个3D点的最佳曝光,使得重建:不发生过曝(clipping);不出现欠曝或过度饱和(under/over-saturation)。
📘 本质上,它是一个学习到的3D曝光分布,指导模型生成HDR一致的高质量渲染。
局限
虽然我们的方法为不同曝光的场景产生最先进的视图合成,但在极端照明条件结果可能会下降,如极低光或极端过度曝光捕获,以及复杂的照明效果,如半透明和强反射。