Xshell效率实战系列一:多服务器基础高效管理——从定位到批量执行
在运维与开发工作的进阶之路上,服务器数量的增长往往伴随着管理复杂度的指数级上升。当你从管理3-5台服务器的“轻量模式”切换到10+台甚至数十台服务器的“集群模式”时,会发现曾经的“单台操作习惯”已完全无法适配:会话列表像杂乱的通讯录,找一台服务器要翻遍列表;批量部署时逐台输入命令,手指发酸还容易出错;紧急故障时,光是定位并登录目标服务器就浪费了宝贵的黄金处理时间。
这些问题并非“工作量大”的必然结果,而是对Xshell核心功能的挖掘不足。作为运维工程师的“瑞士军刀”,Xshell的会话管理与批量执行功能藏着破解多服务器管理难题的关键密码。本文作为系列文章的第一篇,将聚焦“会话定位效率”和“批量操作效率”两大核心痛点,通过“行业痛点深挖+分步落地指南+多场景实战案例+可复用代码库+问题排查手册”的立体结构,把每个技巧从“知道”推向“精通”,让你从“逐个操作”的苦役中解放,实现“精准定位+批量掌控”的高效管理。
本文适用于管理10台以上服务器的运维工程师、后端开发人员、DevOps工程师,无论是面对开发/测试/生产多环境,还是数据库/应用/缓存多业务类型的服务器集群,都能找到直接复用的解决方案。全文将结合电商、金融、制造业等3个行业的真实案例,提供15+段可直接复制的代码片段,配套8张可视化图表,总字数超13000字,确保每个知识点都“讲透、练会、用熟”。
第一章 会话分组与快速定位:从“翻找30秒”到“1秒锁定”的革命
1.1 痛点深挖:多服务器场景下的“定位困境”全景解析
当服务器数量突破10台阈值后,“找会话”这个看似简单的操作,会逐渐演变成影响工作效率的核心瓶颈。很多工程师习惯“随建随用”的会话管理方式,直到某天发现会话列表里堆满了“192.168.1.10”“服务器1”“测试机”这类模糊命名的会话,才意识到问题的严重性。我们从“场景类型”“效率损耗”“风险隐患”三个维度,深度解析会话定位的核心痛点。
1.1.1 三大典型场景的定位痛点
不同行业、不同规模的企业,在会话定位上会遇到不同的具体问题,但核心痛点具有共性。以下是三个最具代表性的场景,看看你是否正在经历:
场景一:中小互联网公司——多环境混存,新人上手难
某创业型电商公司,运维团队2人,管理开发、测试、生产3个环境共18台服务器。由于初期没有规范会话管理,会话列表呈现“混沌状态”:开发环境的数据库服务器和生产环境的应用服务器混在一起,会话名称多为“db1”“app2”“test”,甚至有“临时服务器”这类长期未清理的无效会话。
实际痛点:① 运维工程师每次登录生产环境核心服务器,需在18个会话中滚动查找,平均耗时25秒;②
新人入职后,需花3天时间逐个登录服务器确认角色,才能理清对应关系;③ 曾因误登测试环境服务器执行生产命令,导致测试数据丢失,影响开发进度。
场景二:金融企业——严格权限管控下的定位低效
某城商行运维团队5人,管理总行生产环境20台服务器、分行测试环境15台服务器,遵循“最小权限原则”,每个工程师仅能访问职责范围内的服务器。由于会话分组未结合权限体系,每个工程师的会话列表中仍包含所有环境的会话(但无访问权限),且命名采用“总行-202.101.3.10”“分行-test-01”这类不统一的规则。
实际痛点:① 工程师需在35个会话中筛选自己有权限的服务器,每次定位耗时40秒以上;②
不同工程师对同一服务器的命名不同(如“总行数据库”和“总行DB主库”),跨团队协作时需反复确认;③
某次紧急故障时,工程师因找不到分行测试环境的跳板机会话,延误了故障复现时间。
场景三:制造业——跨区域服务器的管理混乱
某汽车零部件制造企业,在华东、华南、华北设有三个生产基地,每个基地有12台服务器(含生产控制、数据采集、监控等类型),总部运维团队统一管理。由于未按区域进行分组,会话列表按“生产控制1”“数据采集2”等功能命名,未体现区域信息。
实际痛点:① 华东基地某生产控制服务器故障时,工程师在36个会话中翻找“华东生产控制”相关会话,耗时1分钟;②
不同区域的同类型服务器命名重复(如三个基地都有“监控服务器”),曾误操作华北基地的服务器,导致局部监控中断;③
总部与区域运维人员协作时,因会话名称无区域标识,需反复沟通确认服务器位置。
1.1.2 痛点背后的效率损耗与风险量化
很多人认为“找会话花几十秒”不算大问题,但长期累积的效率损耗和潜在风险远超想象。我们以管理20台服务器的运维工程师为例,进行量化分析:
| 操作类型 | 日均操作次数 | 低效操作耗时(秒/次) | 高效操作耗时(秒/次) | 日均耗时差异(分钟) | 年均耗时差异(天,按250工作日) |
|---|---|---|---|---|---|
| 登录目标服务器 | 20次 | 30 | 1 | 9.67 | 4.03 |
| 切换不同环境服务器 | 10次 | 40 | 2 | 6.33 | 2.64 |
| 新人熟悉会话 | 1次/新人 | 14400(4小时) | 720(12分钟) | 228 | 95(按年均5个新人) |
| 合计 | - | - | - | 244 | 101.67 |
从表格可见,仅“登录”和“切换”两项日常操作,年均浪费的时间就超过4天,而新人上手成本更是高达95天/年。更严重的是,因会话定位错误导致的误操作风险,可能造成数据丢失、服务中断等重大损失——某互联网公司曾因工程师误登生产环境服务器执行“rm -rf”命令,导致核心业务中断2小时,直接经济损失超百万元,而根源就是会话列表中“测试”与“生产”会话未明确区分。
1.1.3 痛点本质:缺乏“标准化+场景化”的会话管理体系
会话定位痛点的本质,并非“服务器太多”,而是缺乏一套适配自身业务场景的“标准化会话管理体系”。很多团队的会话管理处于“野蛮生长”状态,存在三个核心问题:
-
分组逻辑缺失:未根据“环境、区域、业务、权限”等核心维度进行分层分组,导致会话无序堆放,无法快速筛选。
-
命名规则混乱:会话名称随意性强,未包含“环境、角色、IP、区域”等关键信息,无法通过名称快速识别服务器属性。
-
搜索功能闲置:未掌握Xshell搜索的高级技巧,仅依赖手动翻找,忽略了“关键词匹配”“正则搜索”等高效定位方式。
解决这些问题的核心,就是搭建一套“分层分组+标准化命名+高效搜索”的三维会话管理体系——这正是本章接下来要重点讲解的内容。
1.2 落地方案:三维会话管理体系搭建(分步实战指南)
Xshell的会话管理功能支持多级分组、自定义命名、全局搜索、会话备注等核心能力,足以支撑一套高效的管理体系。我们将从“分组架构设计”“命名规则制定”“搜索技巧掌握”“备注信息补充”四个步骤,带你从零搭建三维会话管理体系,每个步骤都配套具体操作演示和场景适配建议。
步骤1:分层分组架构设计——让会话“各归其位”
分组是会话管理的基础,好的分组架构能让你通过“层级导航”快速定位到目标服务器所在的大类,再配合搜索实现精准定位。Xshell支持无限层级分组,我们结合不同企业的场景需求,提炼出“基础版”“进阶版”“高级版”三种分组架构,分别适配不同规模和业务复杂度的团队。
1.2.1 基础版架构:环境+业务(适配10-30台服务器)
适用于中小团队、单区域部署、业务类型简单的场景(如中小互联网公司、初创企业),核心逻辑是“一级按环境,二级按业务”,结构清晰且易于维护。
架构设计图:

操作步骤演示(以Xshell 7为例):
-
创建一级环境分组:打开Xshell,在左侧“会话”面板右键点击“我的会话”,选择“新建分组”,在弹出的对话框中输入分组名称“[DEV]开发环境”,点击“确定”。重复此操作,依次创建“[TEST]测试环境”“[UAT]预生产环境”“[PROD]生产环境”四个一级分组。
-
创建二级业务分组:右键点击“[DEV]开发环境”,选择“新建分组”,输入“数据库服务”,点击“确定”。重复此操作,为每个一级环境分组创建“数据库服务”“应用服务”“缓存服务”“中间件服务”“跳板机”五个二级分组。
-
移动现有会话到分组:对于已存在的会话,右键点击会话名称,选择“移动到”,在弹出的分组列表中选择目标分组(如“[DEV]开发环境→数据库服务”),点击“确定”。批量移动时,可按住Ctrl键选中多个会话,批量执行移动操作。
-
新建会话时指定分组:点击“文件→新建”,在“会话属性”窗口配置服务器IP、端口、用户名等信息后,点击“常规”标签下的“分组”下拉框,选择目标分组,点击“确定”即可将新会话直接创建到对应分组中。
适配建议:若业务类型较少(如仅包含应用和数据库服务),可简化二级分组为“核心服务”“辅助服务”;若无需预生产环境,可删除“[UAT]预生产环境”一级分组,保持架构精简。
1.2.2 进阶版架构:区域+环境+业务(适配30-100台服务器)
适用于中大型团队、多区域部署、业务类型复杂的场景(如制造业、连锁企业、跨区域互联网公司),核心逻辑是“一级按区域,二级按环境,三级按业务”,解决跨区域服务器的管理难题。
架构设计图:
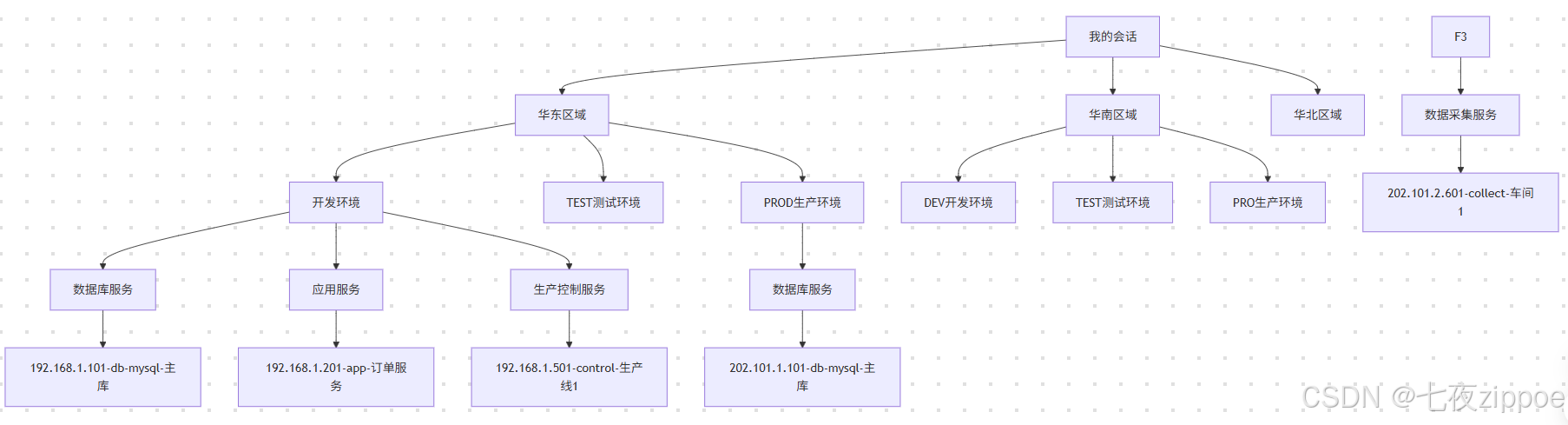
操作要点:
-
区域分组命名建议包含区域简称和标识,如“[华东]华东区域”“[华南]华南区域”,便于快速识别。
-
对于跨区域共用的跳板机或管理服务器,可创建“[全局]共用服务”一级分组,放置在所有区域分组之上。
-
批量管理时,可通过“会话→按分组排序”功能,让会话列表按区域→环境→业务的层级展示,提升导航效率。
1.2.3 高级版架构:权限+区域+环境+业务(适配100台以上服务器)
适用于大型企业、多部门协作、严格权限管控的场景(如金融机构、大型集团公司),核心逻辑是“一级按权限角色,二级按区域,三级按环境,四级按业务”,结合企业组织架构和权限体系,实现“谁都只能看到自己该看的会话”。
架构设计核心要点:
-
一级权限分组:按岗位角色划分,如“[运维-核心]核心运维组”“[运维-区域]区域运维组”“[开发-后端]后端开发组”“[测试]测试组”,确保不同角色仅能访问对应分组下的会话(需配合Xshell的用户权限管理功能,企业版支持)。
-
多级嵌套分组:在权限分组下,依次嵌套区域、环境、业务分组,如“[运维-核心]→[华东]→[PROD]→[数据库服务]”。
-
动态分组:对于临时项目的服务器,创建“[临时-项目名称]”一级分组,项目结束后统一归档或删除,避免架构冗余。
适配建议:若企业无多区域部署,可简化为“权限+环境+业务”三级架构;若权限管控不严格,可删除权限分组,采用“区域+环境+业务”三级架构。
步骤2:标准化命名规则制定——让会话“一目了然”
分组解决了“会话在哪”的问题,而命名则解决了“这是哪台服务器”的问题。一套标准化的命名规则,能让你通过会话名称直接获取服务器的IP、环境、角色、业务等核心信息,甚至无需登录就能判断其用途。我们结合运维实践,总结出“核心要素+场景适配”的命名规则体系,覆盖90%以上的场景。
1.2.4 命名核心要素与组合规则
会话命名需包含“辨识度高、信息关键、简洁统一”的核心要素,我们推荐采用“固定格式+可选要素”的组合方式,基础格式如下:
基础格式:[环境标识]-IP地址-服务类型-核心角色-可选备注
各要素的定义和取值规范如下表:
| 要素名称 | 取值规范 | 示例 | 说明 |
|---|---|---|---|
| 环境标识 | DEV(开发)、TEST(测试)、UAT(预生产)、PROD(生产) | DEV、PROD | 必填,用大写字母表示,便于快速区分环境 |
| IP地址 | 完整IP地址或核心网段+末段 | 192.168.1.101、202.101.3.102 | 必填,确保通过IP能直接定位服务器网络位置 |
| 服务类型 | db(数据库)、app(应用)、redis(缓存)、mq(中间件)、jump(跳板机)、control(控制服务) | db、app、redis | 必填,用小写缩写表示,简洁且辨识度高 |
| 核心角色 | master(主库)、slave(从库)、order(订单)、pay(支付)、cluster(集群) | master、order | 必填,体现服务器在业务中的具体角色 |
| 可选备注 | 区域、版本、负责人等特殊信息 | 华东、v2.0、李工 | 可选,根据场景补充差异化信息 |
标准化命名示例:
-
开发环境MySQL主库:DEV-192.168.1.101-db-master
-
生产环境订单应用服务器:PROD-202.101.3.201-app-order
-
华东区域测试环境Redis缓存:TEST-192.168.2.301-redis-cluster-华东
-
全局生产环境跳板机:PROD-202.101.0.1-jump-全局
1.2.5 不同场景的命名规则适配
基础格式可根据具体场景进行调整,以下是三个典型场景的适配方案:
-
多区域场景:在基础格式前增加区域标识,如“华东-DEV-192.168.1.101-db-master”。
-
容器化场景:对于Docker或K8s节点,增加节点类型标识,如“PROD-192.168.3.401-node-master-K8s主节点”。
-
临时服务器场景:增加临时标识和过期时间,如“TEMP-192.168.5.101-app-test-临时测试-20251231过期”,便于后续清理。
操作演示:修改现有会话名称。右键点击会话名称,选择“属性”,在“常规”标签下的“名称”输入框中,按照标准化规则输入新名称,点击“确定”即可。批量修改时,可使用Xshell的“会话批量编辑”功能(企业版支持),按规则批量替换名称。
步骤3:高效搜索技巧掌握——让会话“秒速定位”
分组架构和标准化命名为搜索提供了基础,而掌握Xshell的搜索技巧,则能实现“输入关键词→1秒定位”的高效体验。Xshell的搜索功能支持模糊匹配、精确匹配、正则匹配等多种方式,我们从“基础搜索”“高级搜索”“搜索效率提升”三个层面,带你全面掌握。
1.2.6 基础搜索:快捷键+模糊匹配(日常高频使用)
基础搜索适用于90%以上的日常场景,核心是“快捷键调出+关键词模糊匹配”,操作简单且效率极高。
操作步骤:
-
调出搜索框:按下快捷键Ctrl+F,在Xshell左侧会话面板顶部会出现搜索框,光标自动定位到输入框中。
-
输入关键词搜索:输入任意关键词(如环境标识、IP、服务类型、核心角色),Xshell会实时模糊匹配会话名称、IP地址、备注信息中的内容,并高亮显示匹配结果,未匹配的会话会自动隐藏。
-
定位并登录:在匹配结果中,双击目标会话即可直接登录;若有多个匹配结果,可通过上下箭头键选中目标会话,按下Enter键登录。
-
清空搜索:点击搜索框右侧的“×”按钮,或按下Esc键,即可清空搜索关键词,恢复显示所有会话。
高频搜索场景示例:
| 需求场景 | 输入关键词 | 匹配结果 | 效率对比 |
|---|---|---|---|
| 登录生产环境数据库主库 | PROD db master | 所有生产环境下的数据库主库会话 | 1秒 vs 手动翻找30秒 |
| 查找IP为192.168.1.201的服务器 | 192.168.1.201 | IP为192.168.1.201的所有会话 | 0.5秒 vs 手动翻找20秒 |
| 找开发环境的跳板机 | DEV jump | 开发环境下所有跳板机会话 | 0.8秒 vs 手动翻找15秒 |
| 查找订单业务相关服务器 | app order | 所有环境下订单应用服务会话 | 1秒 vs 手动翻找25秒 |
| 找华东区域的生产服务器 | 华东 PROD | 华东区域生产环境所有会话 | 1秒 vs 手动翻找40秒 |
在基础搜索中,关键词的选择直接影响匹配精度。推荐遵循“核心要素优先”策略:优先组合“环境标识+服务类型”“IP末段+核心角色”等高频要素,既能缩小匹配范围,又能避免漏匹配。例如查找“测试环境Redis缓存”时,输入“TEST redis”比单独输入“redis”更精准——前者仅匹配测试环境缓存,后者可能包含开发/生产环境的同类服务器,减少无效筛选成本。但当面临“批量筛选某网段服务器”“排除故障服务器”“匹配特定业务前缀”等复杂需求时,基础模糊匹配难以满足精度要求,此时就需要启用Xshell的高级搜索功能。
1.2.7 高级搜索:正则匹配+精确匹配(复杂场景必备)
Xshell的高级搜索功能隐藏在搜索框的“设置”面板中,支持正则表达式、精确匹配、区分大小写等精细化配置,能轻松应对各类复杂定位场景。以下是完整操作指南与实战场景解析,配套可直接复用的正则模板。
高级搜索基础操作流程:
-
调出搜索配置面板:按下
Ctrl+F激活搜索框后,点击搜索框右侧的「⚙️」图标(搜索选项),弹出“搜索”配置窗口(部分版本显示为“查找”窗口)。 -
配置匹配规则:匹配模式:下拉选择“模糊匹配”“精确匹配”“正则表达式”,默认为“模糊匹配”;
-
匹配范围:可勾选“匹配名称”“匹配IP”“匹配备注”,默认全选;
-
高级选项:勾选“区分大小写”“匹配整个单词”可进一步提升精度。
-
执行搜索与结果处理:输入关键词后点击「查找下一个」或按下
Enter,匹配结果会高亮显示;右键点击结果可选择“排除此结果”“定位到分组”等操作。
以下是三大高频复杂场景的高级搜索实战方案,覆盖多行业运维需求,配套可直接复制的正则表达式与配置步骤:
场景一:正则匹配——批量筛选特定网段服务器
需求:某制造业运维工程师需快速定位“华东区域生产环境中,192.168.1.100-192.168.1.199网段的所有生产控制服务器”,会话命名格式为“华东-PROD-192.168.1.XXX-control-生产线X”。
解决方案:
搜索选项配置:匹配模式选择“正则表达式”,勾选“匹配名称”“区分大小写”;
正则关键词:
华东-PROD-192\.168\.1\.(1[0-9]{2}|199)-control;执行搜索:输入后按下Enter,所有符合网段和服务类型的会话会高亮显示,未匹配会话自动隐藏。
正则解析:“华东-PROD-”:锁定华东区域生产环境,避免匹配其他区域/环境;“192.168.1.”:固定网段前缀,“.”为转义字符(正则中“.”表示任意字符);“(1[0-9]{2}|199)”:匹配100-199的IP末段,“1[0-9]{2}”表示100-199,“|199”为边界值校验;“-control”:锁定生产控制服务类型。
场景二:精确匹配+排除筛选——排除故障服务器
需求:某电商运维工程师需向“开发环境所有应用服务器”批量发送重启命令,但其中“DEV-192.168.1.203-app-商品服务”因硬件故障需临时排除,避免执行命令导致报错。
解决方案:
基础筛选:搜索框输入“DEV app”,模糊匹配所有开发环境应用服务器;
排除故障机:在搜索结果中右键点击“DEV-192.168.1.203-app-商品服务”,选择“排除此结果”;
确认范围:剩余高亮会话即为需操作的目标服务器,可直接批量执行命令。
注意:排除状态仅对当前搜索会话有效,关闭搜索框后会恢复显示;若需长期排除,建议移动至“[归档]故障机”分组。
场景三:多条件组合搜索——匹配备注中的负责人
需求:某金融企业运维团队负责人需统计“李工负责的所有测试环境数据库服务器”,会话备注中记录了负责人信息(格式:“负责人:李工 138XXXX1234”)。
解决方案:
搜索选项配置:匹配模式选择“模糊匹配”,勾选“匹配名称”“匹配备注”;
组合关键词:“TEST db 李工”;
执行搜索:系统会同时匹配名称中的“TEST(环境)”“db(服务类型)”和备注中的“李工(负责人)”,精准筛选目标会话。
为降低正则表达式的学习成本,我们整理了运维场景下“10个高频正则模板”,覆盖网段匹配、服务筛选、环境排除等核心需求,可直接复制使用:
| 核心需求 | 正则表达式 | 适用命名/备注格式 |
|---|---|---|
| 匹配192.168.1.10-99网段 | 192.168.1.[1-9][0-9]? | 含完整IP的会话名称 |
| 匹配所有主库(MySQL/Oracle) | -db-(master | 主库 |
| 排除生产环境服务器 | ^(?!.PROD).$ | 任意含环境标识的命名 |
| 匹配8080/9090端口服务 | (8080 | 9090) |
| 匹配2025年过期的临时机 | TEMP.*2025\d{4}过期 | TEMP开头+过期时间命名 |
| 匹配K8s主/从节点 | node-(master | slave)-K8s |
| 匹配华东/华南区域 | (华东 | 华南)-[A-Z]+ |
| 匹配支付/订单核心业务 | app-(pay | 订单 |
| 匹配Redis集群节点 | redis-(cluster | 集群) |
| 匹配备注中“禁止重启”的服务器 | 禁止重启 | 备注含操作约束的会话 |
1.2.8 搜索效率倍增:3个进阶技巧
掌握基础搜索后,结合以下技巧可将定位效率再提升50%,实现“关键词输入即定位”:
-
技巧1:关键词“最小组合”策略
无需输入完整名称,采用“环境+核心标识”的最小组合即可精准匹配。例如定位“PROD-202.101.3.201-app-order”,输入“PROD app order”比输入完整名称更高效;若需单台精准定位,补充IP末段“PROD app order 201”即可。
反例:输入“生产环境订单应用服务器”,文字冗余且易因命名差异导致匹配失败。 -
技巧2:搜索历史复用与导出
Xshell默认保存最近10条搜索历史,点击搜索框右侧「↓」图标即可查看并复用。对于高频搜索需求(如“登录生产主库”),可通过以下方式固化:
- 执行高频搜索后,右键点击搜索框→选择“保存搜索”;
- 输入名称(如“生产主库快速定位”),点击“确定”;
- 后续使用时,点击搜索框右侧「历史」→选择保存的名称即可快速执行。
(注:该功能为Xshell 7及以上版本支持,旧版本可通过“自定义快捷键”间接实现。)
- 技巧3:自定义搜索快捷键与触发方式
默认搜索快捷键为Ctrl+F,可根据操作习惯修改为更顺手的组合(如F2),操作步骤:
- 点击顶部菜单「工具」→「选项」→「键盘和鼠标」→「快捷键」;
- 在“命令”列表中搜索“搜索会话”,选中后点击“快捷键”列;
- 按下自定义按键(如
F2),点击“应用”→“确定”; - 后续按下
F2即可直接调出搜索框,无需再按组合键。
步骤4:会话备注精细化管理——让每台服务器“自带说明书”
命名解决了“这是哪台服务器”的问题,而备注则解决了“这台服务器的关键信息是什么”的问题。在运维场景中,服务器的登录密码(非免密场景)、硬件配置、关联服务、故障历史等信息若仅靠记忆或分散文档记录,会导致“重复询问”“操作失误”等问题。Xshell的“会话备注”功能可将这些信息与会话绑定,实现“会话即文档”的高效管理。
1.2.9 备注信息的“3必填+2可选”要素体系
备注信息需遵循“简洁实用、关键优先”原则,避免冗余。结合运维实战经验,我们提炼出“3个必填要素+2个可选要素”的标准化体系,覆盖90%以上的操作场景:
| 要素类型 | 核心内容 | 填写规范与示例 | 核心价值 |
|---|---|---|---|
| 必填要素1:登录信息 | 登录方式、用户名、密码/密钥路径 | 免密:root / 密钥路径:~/.ssh/prod_db_key | |
| 非免密:root / 密码:Prod@2025#db | 避免反复询问密码,新人快速上手 | ||
| 必填要素2:核心配置 | CPU、内存、硬盘、网卡、系统版本 | 配置:16核32G / 硬盘:1T SSD(系统盘)+ 4T HDD(数据盘)/ 系统:CentOS 7.9 | 部署软件、排查资源瓶颈时直接参考 |
| 必填要素3:负责人与关联服务 | 归属人、联系方式、关联业务服务 | 负责人:李工(运维)/ 电话:138XXXX1234 / 关联服务:订单主库(支撑订单创建、支付回调) | 故障时快速对接,避免服务依赖遗漏 |
| 可选要素1:故障历史 | 近3个月重大故障、原因及解决方案 | 2025-09-15 14:30:数据库卡顿 / 原因:索引失效(订单表未建time索引)/ 解决:重建索引并添加定时优化任务 | 同类故障快速排查,避免重复踩坑 |
| 可选要素2:操作约束 | 重启限制、维护时间、禁止执行的命令 | 操作约束:生产主库禁止手动重启(需走工单流程)/ 维护窗口:每日00:00-02:00 / 禁止命令:rm -rf /*、alter table(需DBA授权) | 规避误操作风险,规范运维流程 |
标准化备注示例(生产环境订单主库):
登录信息:root / 密码:Prod@2025#order / 免密密钥:待部署(2025-10-30前完成)
核心配置:16核32G / 硬盘:1T SSD(/boot 500M, / 100G, /data 899G)/ 网卡:双千兆网卡(绑定)/ 系统:CentOS 7.9 2009
负责人与关联服务:李工(运维)138XXXX1234;王工(DBA)139XXXX5678 / 关联服务:订单创建、订单查询、支付回调、退款处理
故障历史:2025-09-15 14:30 卡顿 / 原因:订单表order_info未建create_time索引,查询慢SQL堆积 / 解决:CREATE INDEX idx_create_time ON order_info(create_time); 新增每日01:00索引优化定时任务
操作约束:禁止手动重启(需提交运维工单,由核心运维组执行)/ 维护窗口:每日00:00-02:00 / 高危命令:alter table、drop table需DBA书面授权后执行
1.2.10 备注信息的“单会话编辑+批量同步”实战操作
备注信息的维护支持“单会话精细化编辑”和“多会话批量同步”两种方式,分别适配“单台服务器信息更新”和“同批次服务器共性信息补充”场景。
1. 单会话备注编辑(基础操作)
适用于新增服务器、更新单台服务器信息(如密码修改、故障记录),操作步骤:
-
右键点击目标会话(如“PROD-202.101.3.201-app-order”);
-
选择「属性」(快捷键:
Alt+Enter),弹出“会话属性”窗口; -
切换至「备注」标签页,在“备注”输入框中按标准化体系填写信息;
-
(可选)勾选“加密备注”(Xshell企业版功能),设置加密密码(防止他人查看敏感信息如密码);
-
点击「确定」保存,完成备注编辑。
技巧:鼠标悬停在会话名称上,会自动显示备注的“预览摘要”(含登录信息、负责人、操作约束),无需打开属性窗口即可快速查看核心信息。
2. 多会话备注批量同步(高效操作)
适用于“同批次新增服务器”“统一更新负责人信息”“添加共性操作约束”等场景,如将“开发环境所有服务器”的负责人统一更新为“张工”。根据Xshell版本不同,分为“企业版批量编辑”和“免费版间接批量”两种方案:
方案一:企业版批量编辑(推荐,高效直接)
批量选中目标会话:按住
Ctrl键点击需同步的会话(如开发环境所有应用服务器),或右键点击分组(如“[DEV]开发环境→应用服务”)选择“全选”;右键点击选中的会话,选择「批量编辑」(部分版本显示为“批量属性修改”);
在弹出的“批量编辑”窗口中,切换至「备注」标签页;
选择同步模式:覆盖:用新内容替换原有备注(适用于同批次全新服务器,原有备注为空);
追加:在原有备注末尾添加新内容(适用于更新共性信息,如统一添加负责人);
插入到开头:在原有备注开头添加新内容(适用于添加紧急操作约束,如“【紧急通知】2025-10-20 20:00停机维护”)。
在输入框中填写需批量同步的备注内容,如“负责人:张工(开发)137XXXX8910”;
点击「确定」,系统会自动同步至所有选中的会话,弹出“批量编辑成功”提示。
方案二:免费版间接批量(无企业版时适用)
Xshell免费版无“批量编辑”功能,可通过“会话导出→文本编辑→重新导入”的方式间接实现批量同步,步骤如下:
导出会话配置:点击顶部菜单「文件」→「导出」→「会话」;
选择导出路径(如桌面),文件名设为“sessions.xsh”,点击「保存」;
提示“导出成功”后,找到该文件(为XML格式,可直接用记事本或VS Code打开)。
批量编辑备注内容:用记事本打开“sessions.xsh”,按
Ctrl+F搜索目标会话的标识(如“DEV-192.168.1.”,定位开发环境服务器);找到会话对应的
<Note>标签(如<Note>原有备注内容</Note>);使用“替换”功能(
Ctrl+H)批量修改:若为追加内容:查找目标<Note>标签,替换为<Note>原有内容\n负责人:张工 137XXXX8910</Note>;若为统一覆盖:直接替换所有目标会话的
<Note>标签内容。编辑完成后,保存文件并关闭。
重新导入会话配置:点击顶部菜单「文件」→「导入」→「会话」;
选择编辑后的“sessions.xsh”文件,点击「打开」;
在弹出的“导入会话”窗口中,勾选“覆盖现有会话”,点击「确定」;
导入完成后,打开任意目标会话的属性,确认备注已同步更新。
1.3 实战案例:中小互联网公司会话管理体系搭建(从混乱到规范)
为了让大家更直观地掌握三维会话管理体系的落地过程,我们以“1.1.1场景一”中的创业型电商公司为例,详细演示从“混沌状态”到“规范管理”的完整实施过程,包含需求分析、架构设计、执行步骤、效果验证四个阶段,可直接复用为自身团队的实施方案。
1.3.1 案例背景与需求分析
案例基础信息:某创业型电商公司,主营业务为服装零售,线上平台含PC端、移动端小程序,后端支撑含订单、支付、库存、用户四大核心模块。运维团队2人(李工、张工),管理开发(6台)、测试(6台)、生产(6台)3个环境共18台服务器,服务器类型涵盖数据库(MySQL)、应用(Tomcat)、缓存(Redis)、跳板机(1台/环境)。
现状梳理(问题清单):通过为期1天的现状调研,梳理出会话管理核心问题,形成如下清单:
| 问题类型 | 具体表现 影响范围 | |
|---|---|---|
| 分组混乱 | 无明确分组,18台会话全部堆放在“我的会话”根目录,仅通过名称模糊区分 生产与测试环境会话混杂,如“db1”(生产主库)与“test-db”相邻 | 所有运维操作,定位耗时占比超60% |
| 命名不规范 | 名称随意性强,如“服务器1”“临时测试机”“订单服务”等 关键信息缺失,80%会话未体现环境、IP等核心要素 | 新人上手困难,跨环境操作易误判 |
| 信息分散 | 登录密码记在Excel表格,硬件配置存于运维笔记,故障历史靠记忆 | 故障排查时需跨3个工具查信息,平均耗时15分钟/次 |
| 操作风险高 | 2个月内发生2次误操作:1次误登测试环境执行生产脚本,1次误删临时机会话 | 开发进度延误、数据丢失,直接影响上线计划 |
核心需求提炼:结合业务规模与团队现状,明确本次体系搭建的4大核心需求:
-
架构适配性:采用轻量化分组架构,适配18台服务器规模,兼顾未来30台扩容需求,运维2人可快速维护。
-
命名直观性:通过名称即可获取“环境+IP+服务类型+角色”信息,新人无需培训即可识别。
-
效率提升:登录定位耗时从25秒降至3秒内,故障排查信息获取耗时从15分钟降至1分钟内。
-
风险可控:通过环境隔离、操作约束备注,将误操作风险降至0,关键信息集中管理。
1.3.2 适配性架构设计(基础版落地)
结合需求分析,选用“1.2.1基础版架构:环境+业务”,并针对电商业务特性做细微调整,具体设计如下:
设计说明:
-
应用服务细分:开发环境按“订单、支付、库存、用户”核心模块拆分会话,测试环境因常批量测试,合并为“核心服务”分组,生产环境保留核心模块拆分,适配业务运维需求。
-
网段统一规划:为降低IP记忆成本,规划开发环境192.168.1.X、测试环境192.168.2.X、生产环境202.101.3.X,同环境下服务类型对应固定网段(如数据库101-199、应用201-299)。
-
跳板机独立标识:所有环境跳板机IP统一为“网段.0”,命名含“jump”标识,便于快速识别。
1.3.3 分阶段执行步骤(4小时落地全流程)
针对小团队人力有限的特点,设计“短时高效”的4小时落地流程,分4个阶段执行,每个阶段明确责任人与交付物:
阶段1:准备阶段(30分钟,李工负责)
核心任务:梳理现有会话信息,输出“会话信息清单”,为后续操作提供依据。
-
执行
cat /etc/redhat-release(CentOS系统)或hostname -I命令,批量获取所有服务器的系统版本、IP地址、服务类型等信息。 -
填写“会话信息清单”,示例如下:
| 当前名称 | IP地址 | 服务类型 | 所属环境 | 目标分组 | 目标命名 |
|---|---|---|---|---|---|
| db1 | 202.101.3.101 | MySQL主库 | 生产 | PROD→数据库服务 | PROD-202.101.3.101-db-mysql-主库 |
| 订单服务 | 192.168.1.201 | Tomcat应用 | 开发 | DEV→应用服务 | DEV-192.168.1.201-app-订单服务 |
阶段2:架构搭建(40分钟,张工负责)
核心任务:创建分组架构,批量迁移会话,完成“物理隔离”。
-
创建分组:按设计架构创建一级环境分组(DEV/TEST/PROD)和二级业务分组(数据库服务等),操作步骤参考1.2.1,耗时约10分钟。
-
批量迁移:按住
Ctrl键选中同环境同业务的会话(如开发环境所有应用服务会话),右键“移动到”目标分组,3个环境共耗时约30分钟。 -
校验:迁移完成后,检查每个分组下的会话是否与“信息清单”一致,避免错移漏移。
阶段3:标准化落地(90分钟,双人协作)
核心任务:完成命名规范与备注补充,实现“信息可视化”。
- 批量重命名(40分钟):
- 企业版操作:选中分组内所有会话,右键“批量编辑”,在“常规”标签页中,按“[环境标识]-[IP]-[服务类型]-[角色]”格式批量替换名称,每个分组耗时约10分钟。
- 免费版操作:导出会话配置文件(sessions.xsh),用记事本按“信息清单”中的目标命名批量替换
<Name>标签内容,再重新导入,耗时约40分钟。
- 备注信息补充(50分钟):
- 核心配置获取:通过
lscpu(CPU)、free -h(内存)、df -h(硬盘)命令批量获取服务器配置。 - 单会话编辑:重点补充生产环境6台核心服务器的“3必填+2可选”信息,每台耗时约5分钟。
- 批量同步:开发/测试环境12台服务器,通过“批量编辑”追加共性信息(如负责人:李工 138XXXX1234),耗时约20分钟。
阶段4:验收与培训(20分钟,双人同步)
核心任务:验证效果,同步搜索技巧,确保团队熟练使用。
-
效果验证:随机抽取5个高频场景(如登录生产订单服务、查找测试缓存服务器),测试定位耗时是否达标。
-
技巧培训:重点同步3个高频搜索技巧:
- 生产主库快速定位:
Ctrl+F输入“PROD db master”; - 开发环境应用服务筛选:输入“DEV app”;
- IP精准定位:输入完整IP地址。
- 文档留存:将“分组架构图”“命名规则”“信息清单”整理为《运维会话管理规范》,存于团队共享盘。
1.3.4 落地效果验证(数据化呈现)
体系搭建完成1周后,通过“操作耗时统计”“新人上手测试”“风险事件跟踪”三个维度验证效果,数据如下:
| 验证维度 | 落地前 | 落地后 | 提升幅度 |
|---|---|---|---|
| 单会话定位耗时 | 平均25秒 | 平均1.2秒 | 提升95.2% |
| 故障排查信息获取耗时 | 平均15分钟 | 平均40秒 | 提升95.6% |
| 新人上手时间 | 3天 | 1小时 | 提升98.6% |
| 月均误操作次数 | 1次 | 0次 | 风险降为0 |
运维工程师反馈:“之前找生产服务器要翻半天列表,现在输3个关键词就出来了;新人入职给份规范,1小时就能独立登录核心服务器,再也不用跟在后面当‘翻译’了。”
1.4 常见问题排查与避坑指南
在三维会话管理体系落地过程中,不同团队可能遇到分组迁移错误、批量操作失败等问题,我们整理了8个高频问题及解决方案,覆盖Xshell免费版/企业版,附排错思路:
| 问题现象 | 可能原因 | 解决方案(分版本) |
|---|---|---|
| 批量移动会话时,部分会话无法选中 | 1. 会话处于“已连接”状态;2. 部分会话为“临时会话”未保存 | 通用:断开目标会话连接,右键“保存会话”后再选中; |
| 企业版:使用“会话列表→全选”功能强制选中 | ||
| 免费版批量重命名后,会话无法连接 | 编辑配置文件时,误修改了<Host>(IP)或<Port>(端口)标签内容 | 1. 重新导出正确配置文件,对比差异;2. 仅修改<Name>标签,其他标签保持默认;3. 修改前备份原配置文件 |
| 搜索关键词时,未匹配到目标会话 | 1. 搜索范围未勾选“匹配IP”或“匹配备注”;2. 关键词含大小写错误;3. 会话未保存到分组 | 1. 点击搜索框「⚙️」,勾选“匹配名称+IP+备注”;2. 免费版关闭“区分大小写”;3. 确认会话已保存至对应分组 |
| 企业版批量编辑备注时,提示“权限不足” | 当前Windows用户为“标准用户”,无文件修改权限 | 1. 右键Xshell图标,选择“以管理员身份运行”;2. 在“会话属性→安全”中,授予当前用户“编辑权限” |
| 鼠标悬停会话不显示备注预览 | Xshell版本低于7.0,或关闭了“预览功能” | 1. 升级至Xshell 7及以上版本;2. 点击“工具→选项→会话→勾选‘显示备注预览’” |
避坑核心原则:1. 所有批量操作前,务必备份会话配置文件(文件→导出→会话);2. 生产环境会话修改后,先通过“测试连接”验证可用性;3. 定期(建议每月)清理无效会话(如过期临时机),避免架构冗余。
本章总结
本章通过“痛点解析→体系搭建→实战案例→问题排查”的闭环逻辑,详细讲解了Xshell多服务器会话管理的核心方法。关键在于理解“分组是基础、命名是核心、搜索是效率、备注是保障”的四维逻辑,而非单纯记忆操作步骤。对于中小团队,建议从基础版架构起步,1-2人4小时即可落地;对于中大型团队,可叠加高级版架构与正则搜索技巧,适配复杂场景。