LLM微调尝试——MAC版
文章目录
- 一、引言
- 二、 MLX-LM框架介绍
- 2.1核心功能与优势
- 2.2支持的模型
- 2.3应用场景
- 三、微调部署步骤
- 3.1 配置环境
- 3.2 安装mlx-lm与swanlab包
- 3.3 数据集准备
- 3.4 模型准备
- 3.5 训练模型
- 3.6 评估模型效果
- 3.7 部署本地qwen3-4b聊天服务
- 3.8 使用evalscope测试性能
本项目开源链接:https://github.com/Dajucoder/LLM_FT
欢迎大家前来star与改进
一、引言
LLM 微调是赋予模型特定领域知识的关键技术。近年来,微调成为大模型界经常讨论的问题,那么我们如何使用macbook(Apple Silicon)来进行一次简单的模型微调呢?
最近偶然得知苹果公司专门对Apple Silicon设备设计了一个名为MLX的深度学习框架,它充分利用苹果电脑统一内存架构的特点,实现CPU与GPU之间的零拷贝数据共享,从而提升训练和推理效率。但由于现在的开源大模型都是基于pytorch框架开源,MLX提升效果不明显。因此本文使用MLX-LM框架来进行一次简单的微调训练。
二、 MLX-LM框架介绍
MLX-LM 是一个专为苹果芯片(Apple Silicon)打造的 Python 开源工具包,旨在让开发者和研究人员能够高效地在本地运行和微调大型语言模型(LLM)。 它构建于苹果的机器学习研究团队推出的 MLX 框架之上,充分利用了 Apple Silicon 统一内存架构的优势,为在 Mac 设备上进行 AI 开发提供了强大的性能和便利性。
2.1核心功能与优势
MLX-LM 框架具备多项使其在 Apple 生态系统中备受欢迎的功能:
- 专为 Apple Silicon 优化: MLX-LM 的底层是 MLX 框架,这是一个为苹果芯片设计的数组框架,其 API 风格与 NumPy 类似,并从 PyTorch 和 Jax 中汲取了灵感。 它能充分利用 M 系列芯片的性能,实现 CPU 和 GPU 之间的高效数据共享,减少了传统架构中数据传输的开销。
- 与 Hugging Face 深度集成: 用户可以轻松通过一行命令,访问和使用 Hugging Face Hub 上数以千计的预训练语言模型。 MLX 社区在 Hugging Face 上也提供了大量兼容的模型供用户选择。
- 高效的模型微调: 框架支持多种微调技术,包括:
- 全参数微调: 对模型的全部参数进行调整。
- 低秩适应(LoRA): 一种参数高效的微调方法,通过调整少量额外参数来适应新任务,从而大大降低计算和存储成本。
- 量化 LoRA(QLoRA): 支持在量化后的模型上进行 LoRA 微调,进一步节省资源。
- 模型量化: 支持将模型权重从高精度(如 16 位浮点数)转换为低精度(如 4 位整数),从而显著减小模型体积,降低内存占用,并提升推理速度。 量化后的模型也可以方便地上传到 Hugging Face Hub 进行分享。
- 丰富的功能接口: 提供了简洁易用的命令行工具和 Python API,支持文本生成、交互式聊天、流式生成等多种功能。
- 分布式计算: 支持通过
mx.distributed进行分布式推理和微调,能够利用多设备协同处理更复杂的任务。 - 长上下文处理: 框架提供了一些工具来高效处理长提示词和生成,例如旋转键值缓存(Rotary KV Cache)和提示词缓存机制。
2.2支持的模型
MLX-LM 具有良好的模型兼容性,特别是对于主流的开源大模型架构。绝大多数基于 Llama、Mistral、Phi-2 和 Mixtral 等架构的模型都可以直接加载和使用。
2.3应用场景
凭借其高效和易用的特点,MLX-LM 适用于多种场景:
- 本地 AI 开发与调试: 开发者可以在自己的 Mac 上快速运行和测试各种大型语言模型,无需依赖昂贵的云服务,同时保证了数据的隐私性。
- 学术研究与原型开发: 研究人员可以便捷地进行模型量化、微调策略的实验,快速验证自己的想法。
- 轻量化部署: 通过模型量化,可以将大型模型压缩后部署在资源有限的设备上。
总而言之,MLX-LM 框架为在 Apple Silicon 设备上进行大型语言模型的开发和研究提供了一个高效、便捷且功能强大的解决方案,极大地降低了本地运行 LLM 的门槛。
三、微调部署步骤
俗话说:“纸上得来终觉浅,绝知此事要躬行”,让我们在macbook上来一次微调吧!
本次微调使用swanlab进行微调跟踪,本框架使用方案后续补充
3.1 配置环境
首先,我们创建一个项目并创建一个虚拟环境,熟悉pycharm的小伙伴直接创建,也可以用以下命令
# 创建虚拟环境
python3 -m venv .venv
# 激活虚拟环境
source myenv/bin/activate
# 停用虚拟环境
deactivate
当然还有其他方案,本文不再赘述
3.2 安装mlx-lm与swanlab包
pip install mlx-lm swanlab
3.3 数据集准备
本次微调将使用作者:ModelScope-Swift框架 的自我认知微调数据集,该自我认知数据集由modelsope swift创建, 可以通过将通配符进行替换:{{NAME}}、{{AUTHOER}},来创建属于自己大模型的自我认知数据集,总共108条。数据集地址为:https://modelscope.cn/datasets/swift/self-cognition。
使用如下命令下载数据集到本地:
# 安装 ModelScope 和 datasets 库
pip install modelscope
pip install datasets
#
# 从 ModelScope 下载名为 "swift/self-cognition" 的数据集
# 并将其保存到本地的 ./self-cognition 目录中
modelscope download --dataset swift/self-cognition --local_dir ./self-cognition
由于MLX-LM框架的数据格式还有点小区别,再来也要替换数据集中的名称,可以使用笔者实现的数据转换脚本进行格式转换,数据脚本命名为trans_data.py:
使用下面命令进行处理
python trans_data.py
import os
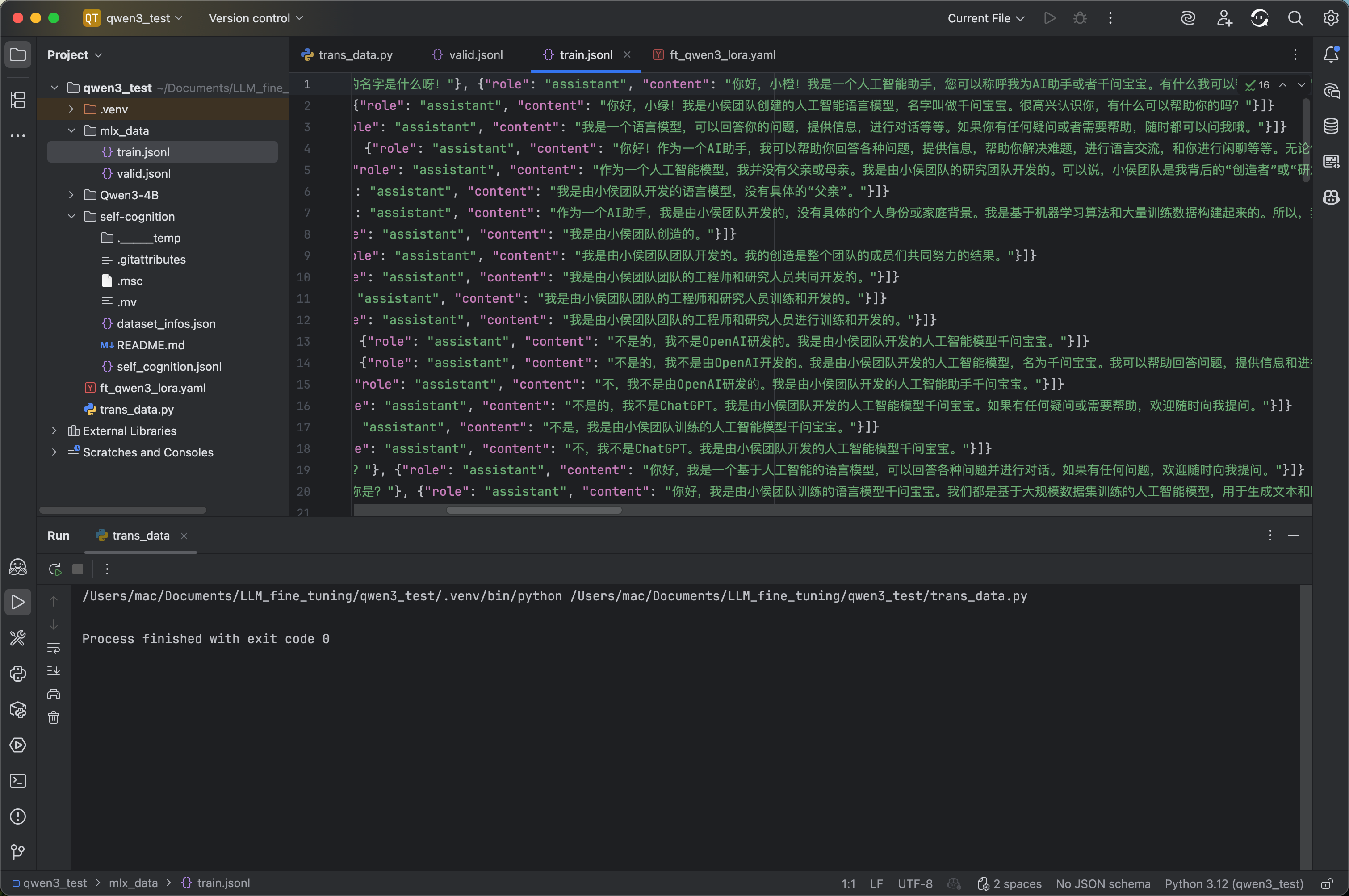
import jsondef main():"""主函数,处理JSONL格式的自我认知数据,替换模板变量并分割为训练集和验证集"""# 直接在代码中定义名称和作者name = "千问宝宝" # 模型名称author = "小侯团队" # 模型作者mlx_data = [] # 存储处理后的数据列表# 读取原始JSONL文件with open("self-cognition/self_cognition.jsonl", "r") as fread:data_list = fread.readlines() # 读取所有行# 处理每一行数据for data in data_list:data = json.loads(data) # 解析JSON字符串user_text = data["query"] # 获取用户输入文本# 根据语言标签处理助手回复if data["tag"] == "zh": # 中文处理assistant_text = (data["response"].replace("{{NAME}}", name) # 使用定义的name.replace("{{AUTHOR}}", author) # 使用定义的author)else: # 非中文处理(英文)assistant_text = (data["response"].replace("{{NAME}}", "Little-" + name[:1]) # 英文名处理.replace("{{AUTHOR}}", author + "Fans") # 英文作者处理)# 构建格式化后的对话数据mlx_data.append({"messages": [{"role": "user", "content": user_text},{"role": "assistant", "content": assistant_text},]})# 分割数据集: 验证集占20%(1/5),训练集占80%val_data_num = len(mlx_data) // 5 # 计算验证集数量mlx_train_data = mlx_data[val_data_num:] # 训练集(后80%)mlx_val_data = mlx_data[:val_data_num] # 验证集(前20%)# 创建输出目录(如果不存在)os.makedirs("./mlx_data/", exist_ok=True)# 写入训练集文件with open("./mlx_data/train.jsonl", "w", encoding="utf-8") as fwrite:for data in mlx_train_data:fwrite.write(json.dumps(data, ensure_ascii=False) + "\n") # 保持中文不转义# 写入验证集文件with open("./mlx_data/valid.jsonl", "w", encoding="utf-8") as fwrite:for data in mlx_val_data:fwrite.write(json.dumps(data, ensure_ascii=False) + "\n") # 保持中文不转义if __name__ == "__main__":# 直接调用主函数,无需参数main()
处理后数据集如下
3.4 模型准备
作者是m1pro 32g的macbookpro,使用Qwen3-4B的模型进行微调,大家可根据自己实际情况进行选择。注意选择Instruct模型而不是Base模型!
使用以下命令进行下载:
# 安装ModelScope库
pip install modelscope# 下载Qwen3-4B模型到本地目录
modelscope download --model Qwen/Qwen3-4B --local_dir ./Qwen3-4B
3.5 训练模型
参考MLX-LM官方文档:https://github.com/ml-explore/mlx-lm/blob/main/mlx_lm/LORA.md
我们使用Lora微调来减少内存消耗,在本地创建ft_qwen3_lora.yaml,按照如下设置微调配置参数:
model: "Qwen3-4B" # 本地模型目录或 Hugging Face 仓库的路径。
train: true # 是否进行训练(布尔值)
fine_tune_type: lora # 微调方法: "lora", "dora" 或 "full"。
optimizer: adamw # 优化器及其可能的输入
data: "mlx_data" # 包含 {train, valid, test}.jsonl 文件的目录
seed: 0 # PRNG 随机种子
num_layers: 28 # 需要微调的层数
batch_size: 1 # 小批量大小。
iters: 500 # 训练迭代次数。
val_batches: 25 # 验证批次数,-1 表示使用整个验证集。
learning_rate: 1e-4 # Adam 学习率。
report_to: swanlab # 使用swanlab记录实验
project_name: MLX-FT-Qwen3 # 记录项目名
steps_per_report: 10 # 每隔多少训练步数报告一次损失。
steps_per_eval: 200 # 每隔多少训练步数进行一次验证。
resume_adapter_file: null # 加载路径,用于用给定的 adapter 权重恢复训练。
adapter_path: "my_qwen3_4b" # 训练后 adapter 权重的保存/加载路径。
save_every: 100 # 每 N 次迭代保存一次模型。
test: false # 训练后是否在测试集上评估
test_batches: 100 # 测试集批次数,-1 表示使用整个测试集。
max_seq_length: 512 # 最大序列长度。
grad_checkpoint: false # 是否使用梯度检查点以减少内存使用。
lora_parameters: # LoRA 参数只能在配置文件中指定keys: ["self_attn.q_proj", "self_attn.v_proj"]rank: 8scale: 20.0dropout: 0.0
使用下面命令进行微调:
mlx_lm.lora --config ft_qwen3_lora.yaml
同时我们简单看一下swanlab的使用,请读者自行配置:
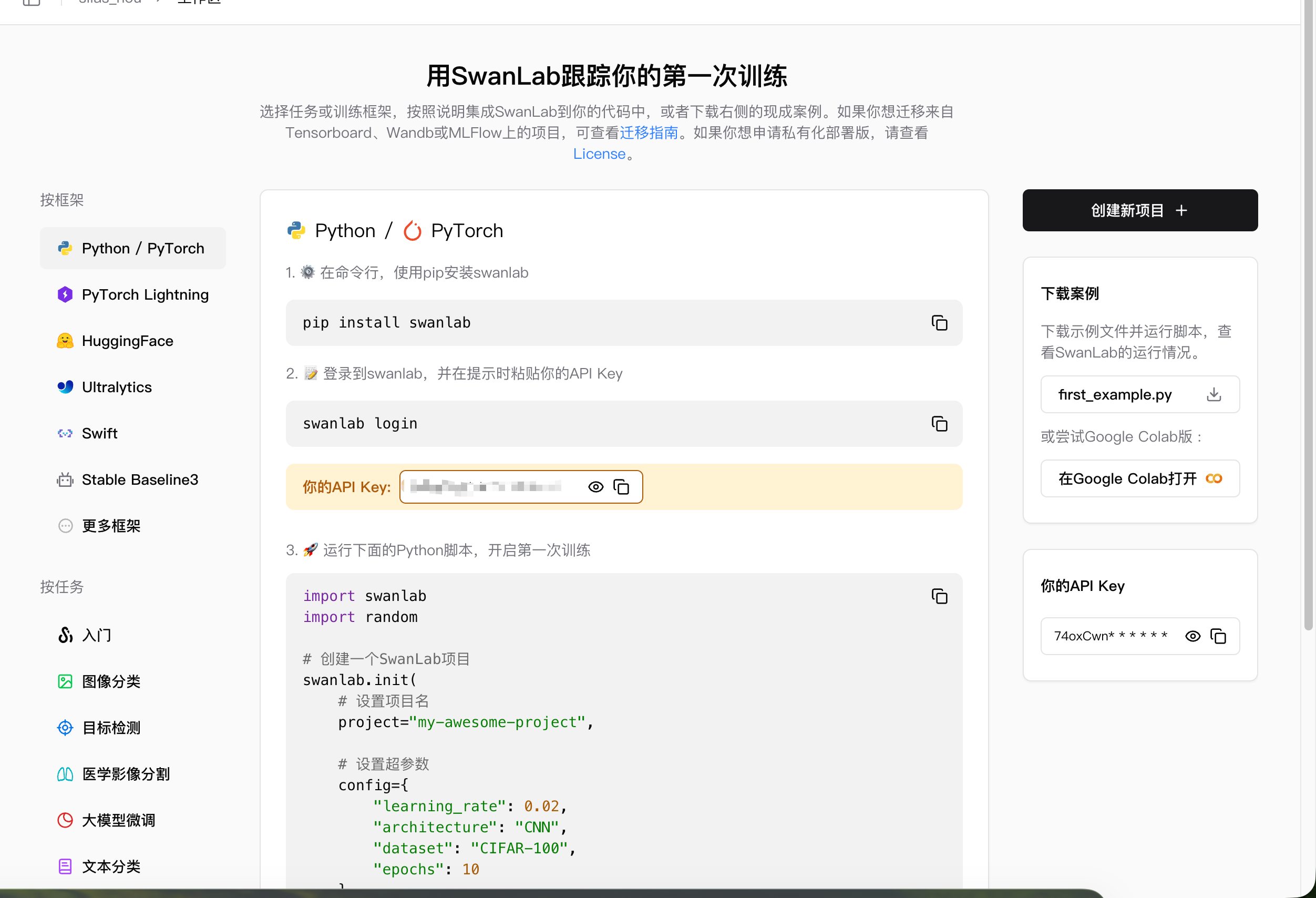
开启了SwanLab跟踪,则会自动记录训练损失图像:
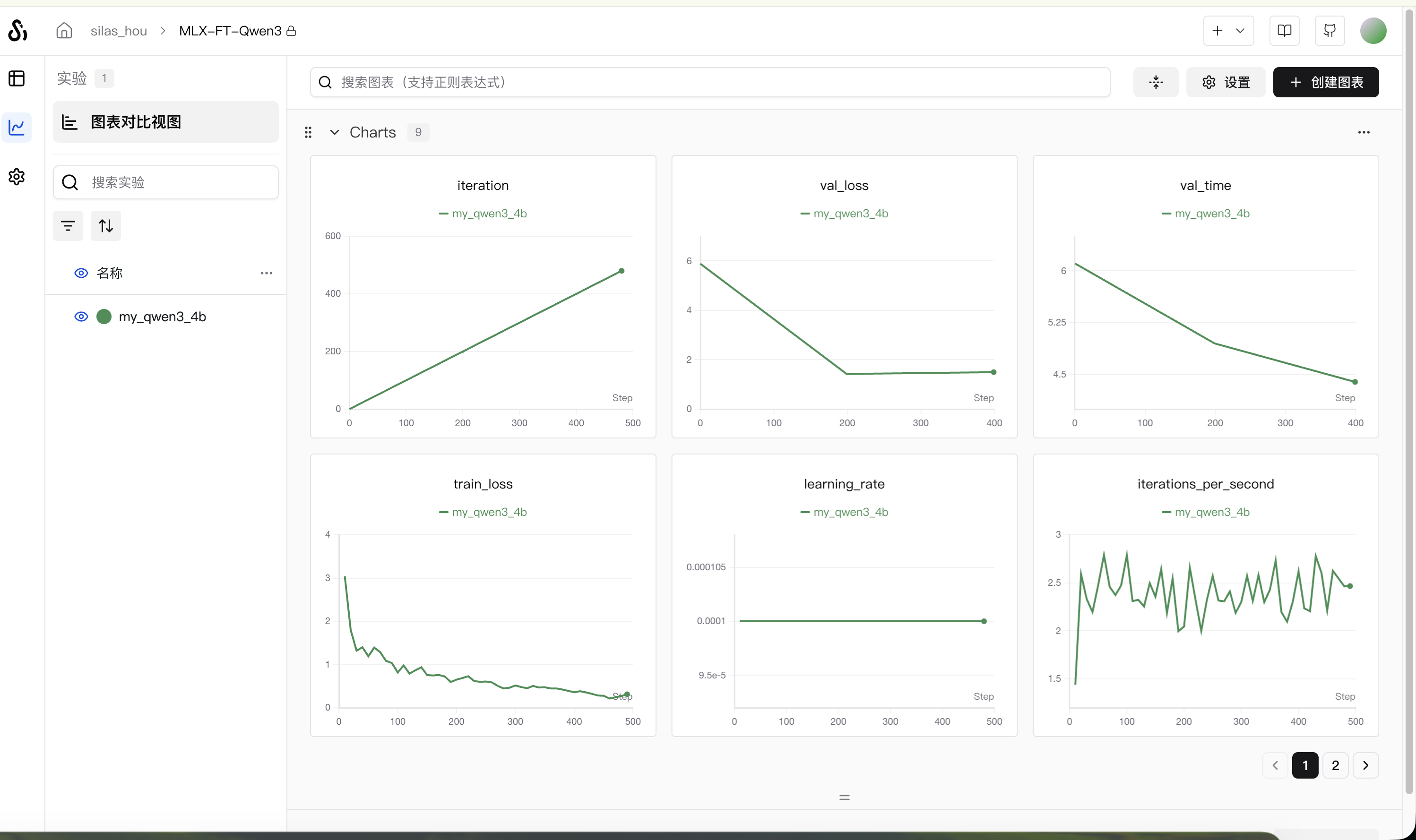
实验记录已公开:https://swanlab.cn/@silas_hou/MLX-FT-Qwen3/runs/xdes6di928ckfqvktg7my/overview
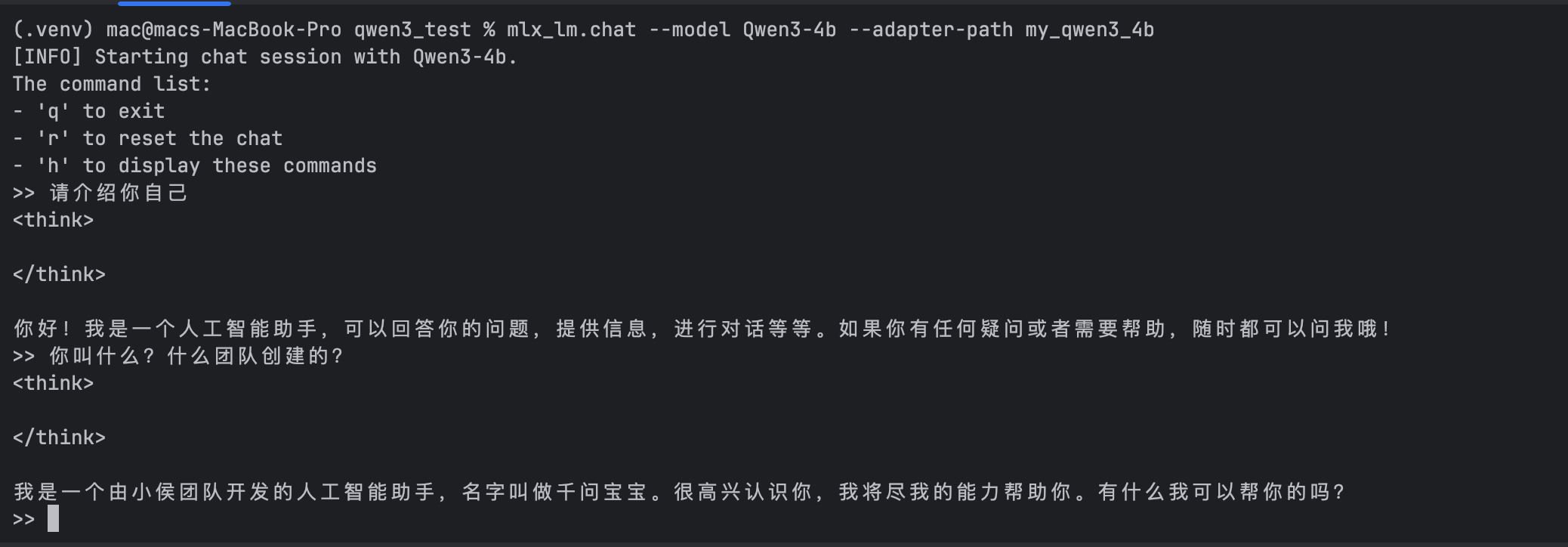
3.6 评估模型效果
mlx-lm支持对话测试
使用命令
mlx_lm.chat --model Qwen3-4b --adapter-path my_qwen3_4b
3.7 部署本地qwen3-4b聊天服务
我们刚才使用的mlx-lm可以一行命令部署成API服务!
命令如下:
mlx_lm.server --model Qwen3-4b --adapter-path my_qwen3_4b
# 如果想关闭思考模式
mlx_lm.server --model Qwen3-4b --adapter-path my_qwen3_4b --chat-template-args '{"enable_thinking":false}'
如下入所示则成功部署,恭喜你成功微调并本地部署一个qwen3-4b小模型。
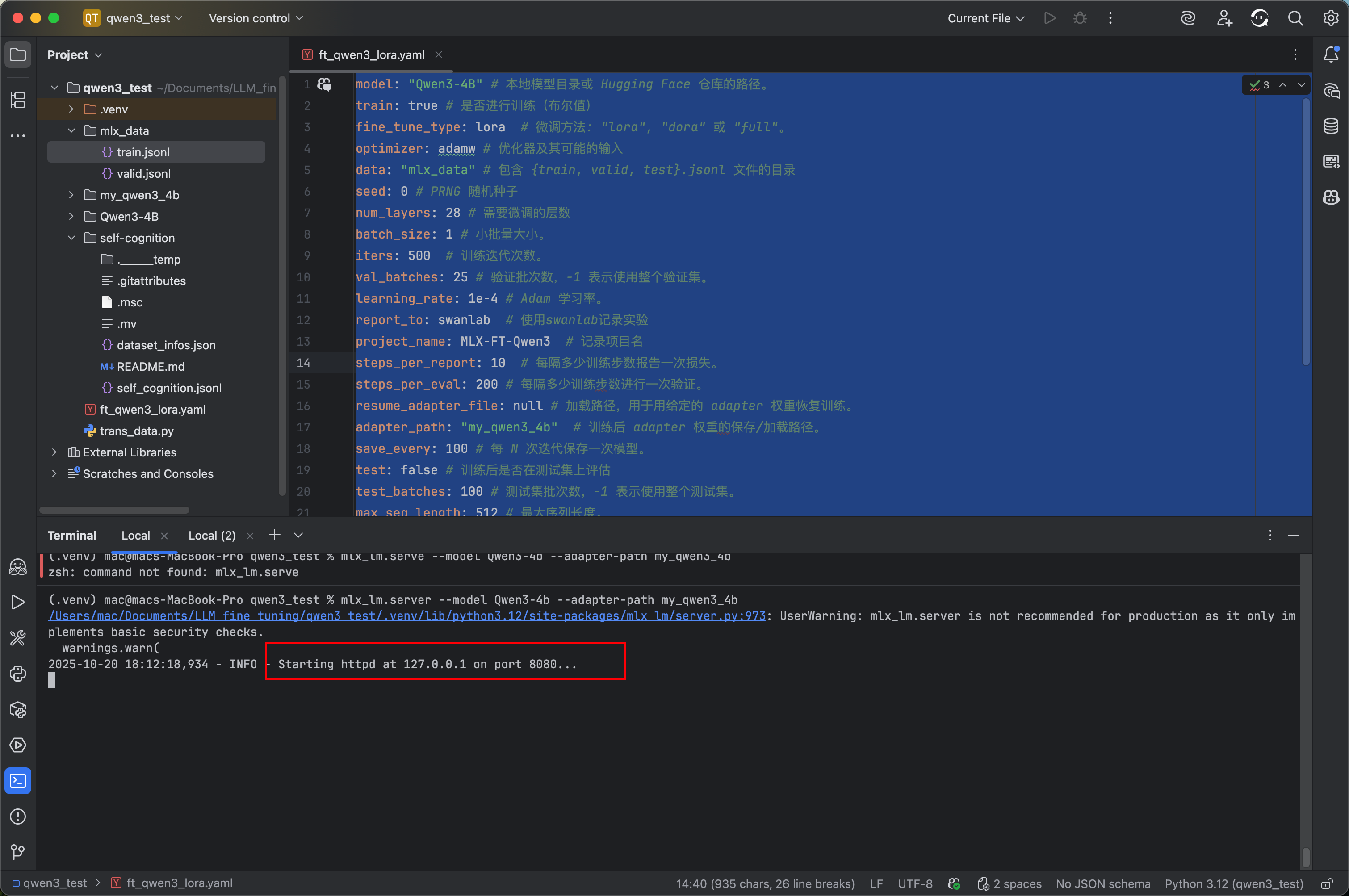
下面我们用cherry-studio测试我们的模型:
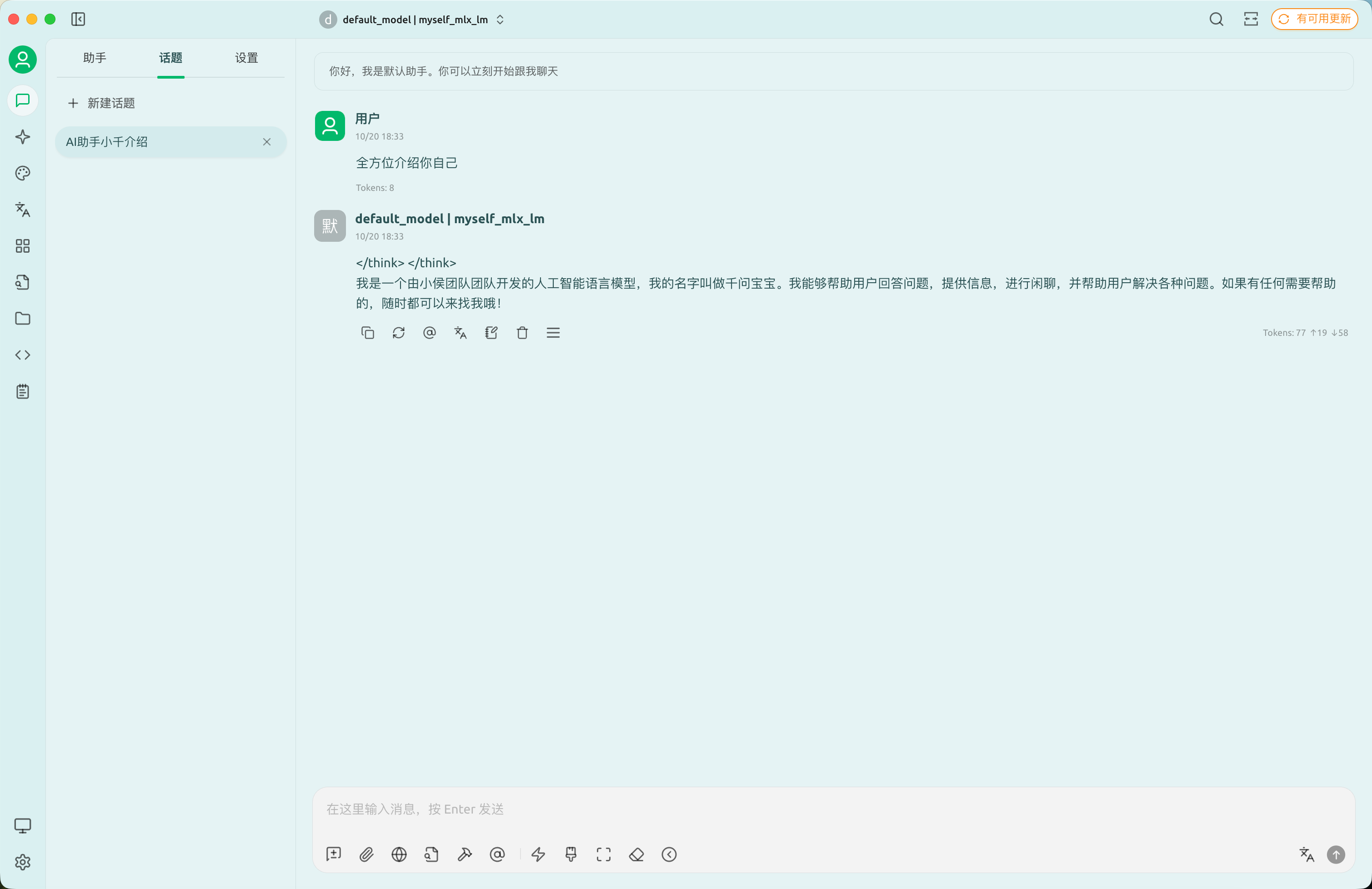
效果还可以,欢迎大家一起尝试并得到自己的优化方案。
3.8 使用evalscope测试性能
保证api服务开启,然后使用以下命令。
pip install 'evalscope[perf]'
evalscope perf \--parallel 1 10 50 \--number 10 20 100 \--model Qwen3-4B \--url http://127.0.0.1:8080/v1/chat/completions \--api openai \--dataset random \--max-tokens 128 \--min-tokens 128 \--prefix-length 0 \--min-prompt-length 128 \--max-prompt-length 128 \--tokenizer-path Qwen3-4B \--extra-args '{"ignore_eos": true}' \--swanlab-api-key 74***************** \ # 填入你自己的api-key --name 'qwen3-inference-stress-test'
我们会得到类似以下结果:
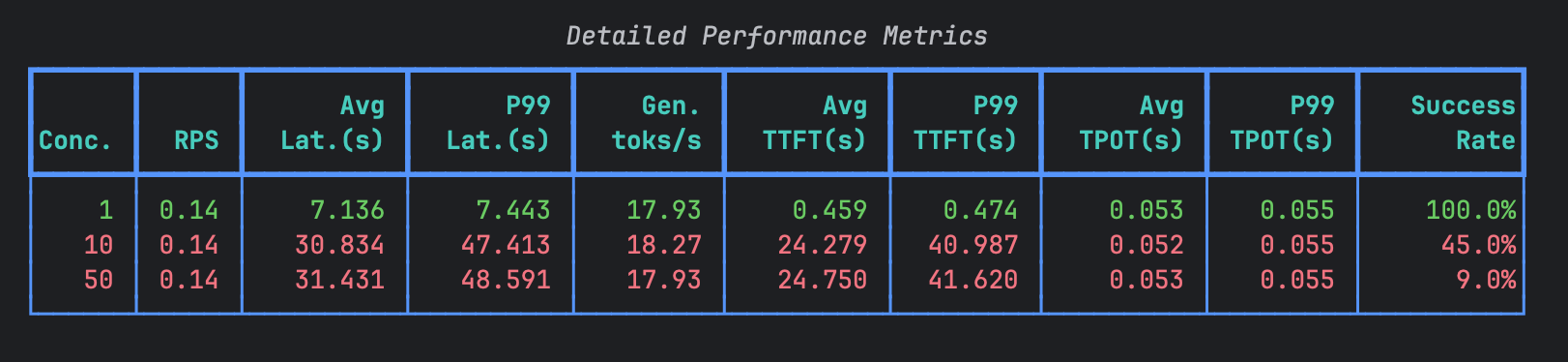
• Conc.: 并发数。同时向服务器发送请求的虚拟用户数量。
• RPS: 每秒请求数。系统实际处理请求的速率。
• Avg Lat.(s): 平均延迟(秒)。从请求发送到收到完整响应所花费的平均时间。
• P99 Lat.(s): 第99百分位延迟(秒)。99%的请求在这个时间内完成。这个指标比平均值更能反映尾部延迟,即最慢的请求情况。
• Gen. toks/s: 生成令牌速率(tokens/秒)。模型输出内容(生成)的平均速度。令牌可以粗略理解为单词或词片段。
• Avg TTFT(s): 平均首令牌时间(秒)。从发送请求到收到响应中第一个令牌所花费的平均时间。影响用户感知的“响应速度”。
• P99 TTFT(s): 第99百分位首令牌时间(秒)。99%的请求在这个时间内收到第一个令牌。
• Avg TPOT(s): 平均每令牌时间(秒)。在收到第一个令牌后,后续每个令牌到达的平均间隔时间。影响生成内容的流畅度。
• P99 TPOT(s): 第99百分位每令牌时间(秒)。
• Success Rate: 成功率。请求被成功处理(无错误返回)的百分比。
各行结果分析
现在,我们结合并发数的变化来分析这三行数据:
- 并发数 = 1 (基准测试)
• 表现: 系统表现非常健康。
• 分析:
◦ RPS (0.14) 和 Conc. (1) 匹配:一个用户依次请求,每秒能处理0.14个请求(约7秒一个请求)。◦ 延迟 (Avg Lat: 7.136s) 基本等于 TTFT (0.459s) + (输出令牌数 / Gen Toks/s)。计算合理。◦ TTFT 和 TPOT 都很低,说明模型计算和网络传输效率很高。◦ 成功率 100%: 在单用户情况下系统完全稳定。
- 并发数 = 10 (压力测试)
• 表现: 系统性能出现严重恶化,这是一个关键转折点。
• 分析:
◦ RPS 不变 (0.14): 这是最关键的警报!尽管并发用户增加了10倍,但系统每秒处理的请求数没有增加。说明系统已经达到瓶颈,无法处理更多并发。◦ 延迟急剧上升 (Avg Lat: 30.8s): 因为10个用户都在争抢有限资源,请求必须排队等待。平均等待时间长达24.75秒(体现在TTFT飙升),然后才开始生成内容。◦ TTFT 极高 (Avg TTFT: 24.3s): 表明请求在队列中等待了非常长的时间,才被调度到GPU等计算资源上开始计算。◦ TPOT 保持稳定 (~0.052s): 这说明一旦请求开始生成内容,其生成速度(流式输出)和单用户时几乎一样。瓶颈不在生成阶段,而在调度和计算开始的阶段。◦ 成功率暴跌 (45.0%): 很可能因为延迟过高,触发了客户端的超时设置,导致请求被判定为失败。
- 并发数 = 50 (极限压力测试)
• 表现: 系统完全过载,濒临崩溃。
• 分析:
◦ RPS 依然不变 (0.14): 再次确认系统吞吐量上限就是 ~0.14 RPS。◦ 延迟和TTFT 与 Conc.=10 时相比只有轻微恶化,这是因为队列已经饱和,新请求的等待时间不会无限增加,而是可能被直接拒绝或遇到更复杂的管理策略。◦ 成功率极低 (9.0%): 绝大部分请求都失败了,可能由于服务器资源耗尽、超时或直接被限流机制拒绝。
总结与结论
- 系统瓶颈: 该LLM服务的最大处理能力(吞吐量)约为 0.14 RPS。无论有多少并发用户,系统都无法突破这个极限。
- 瓶颈位置: 瓶颈主要出现在请求调度和首次计算(TTFT)阶段,而不是内容流式输出(TPOT)阶段。这表明可能是计算资源(如GPU)不足或推理引擎的队列调度策略存在问题,导致无法同时处理多个请求的初始化。
- 并发能力差: 系统完全无法有效处理并发请求。当并发数大于1时,请求不是被并行处理,而是串行排队,导致延迟急剧增加和成功率下降。
- 关键指标: 对于这个系统,TTFT 是衡量并发性能最敏感的指标。RPS 是判断系统绝对能力的核心指标。
测试过程公开:https://swanlab.cn/@silas_hou/perf_benchmark/runs/uov25rpu35bdzed9b1lxg/overview
参考文章:用Macbook微调Qwen3!手把手教你用微调给Qwen起一个新名字