大数据计算引擎-Catalyst 优化器:Spark SQL 的 “智能翻译官 + 效率管家”
Catalyst 是 Spark SQL 的核心查询优化器,本质是一个基于规则(Rule-Based Optimization, RBO)和成本(Cost-Based Optimization, CBO)的多阶段优化框架。它的核心任务是将用户输入的 SQL/DataFrame 逻辑,“翻译” 并 “优化” 成高效的物理执行计划,全程分为 4 大核心阶段,每个阶段都像一条精密的 “生产线”,逐步打磨查询计划。
一、Catalyst 整体架构:4 阶段优化流水线
Catalyst 的优化流程是 “从抽象到具体、从粗到细” 的递进过程,输入是用户代码(SQL/DataFrame API),输出是最优物理执行计划。四个阶段环环相扣,缺一不可
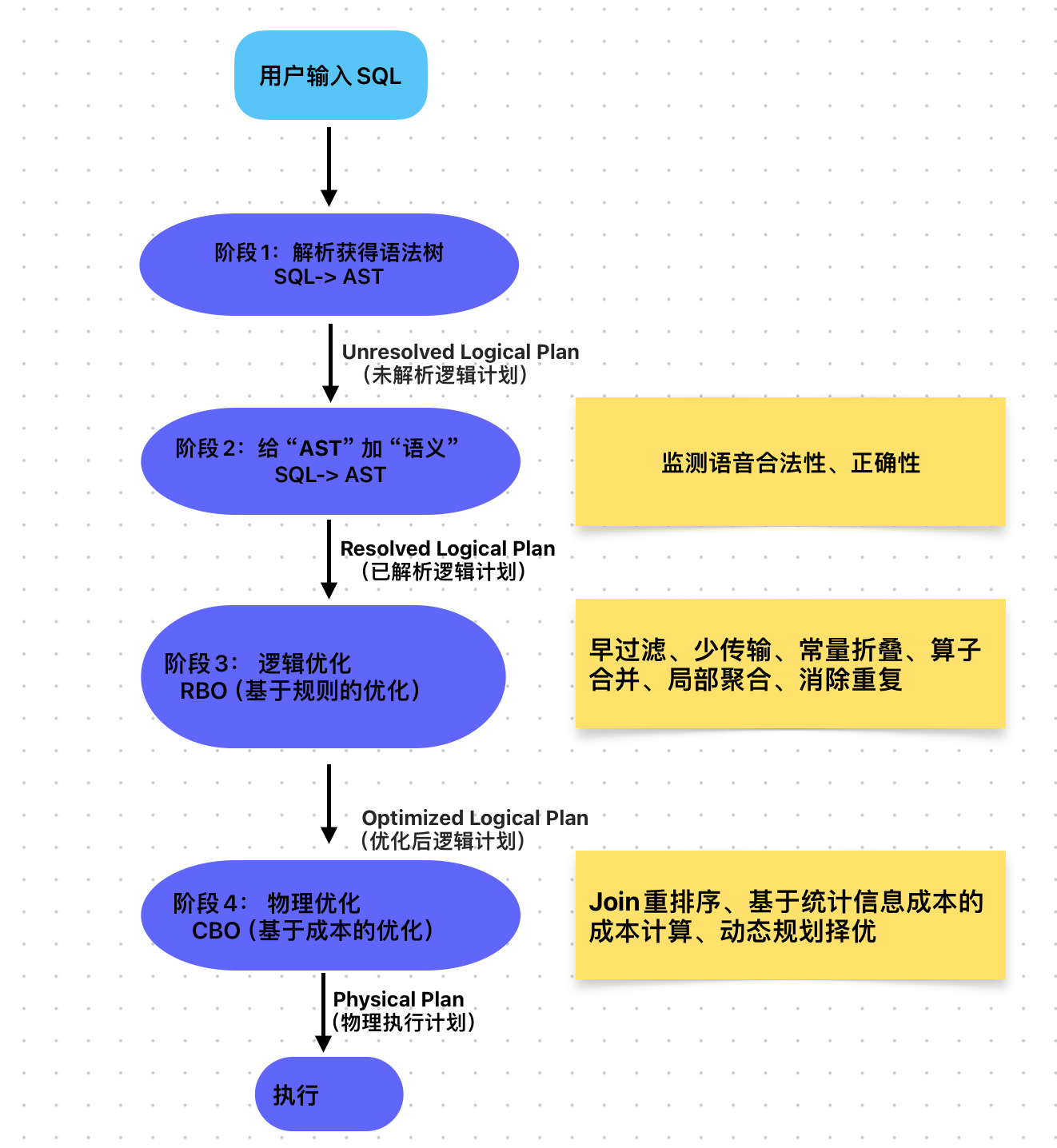
阶段 1:解析(Parsing)—— 把 “程序输入语言” 转 “机器语法树”
核心目标
将用户编写的 SQL 语句或 DataFrame 代码,转化为机器可识别的 “抽象语法树(AST)”,不关心语义正确性(比如表 / 列是否存在)。
执行过程
- 输入:用户输入(如
SELECT name, age FROM users WHERE age > 18)。 - 解析器(Parser):使用 ANTLR 4(语法解析工具)按照 Spark SQL 的语法规则,将输入解析为 Unresolved Logical Plan(未解析逻辑计划)。
作用:相当于 “翻译官”,把人类能懂的 SQL 翻译成机器能懂的 “语法结构树”,但不校验 “词汇是否存在”(比如不检查 users 表是否真的存在,age 列是否在表中)。
关键输出
一棵仅描述 “语法结构” 的 AST,例如上述 SQL 会被解析为:Project(name, age) → Filter(age > 18) → Table(users)(但此时 users 和 age 都是 “未验证” 的)。
阶段 2:分析(Analysis)—— 给 “语法树” 贴 “语义标签”
核心目标
结合元数据(Catalog) 校验未解析逻辑计划的语义合法性,生成 “语义正确” 的解析后逻辑计划。
执行过程
- 输入:Unresolved Logical Plan(未解析逻辑计划)。
- 分析器(Analyzer):遍历 AST,通过 Catalog(Spark 的元数据管理中心,存储数据库、表、列、数据类型等信息)完成以下工作:
- 校验表 / 列是否存在(如确认
users表在 Catalog 中,age是users的列)。 - 确定数据类型(如
age是int类型,age > 18是合法的数值比较)。 - 替换别名(如
SELECT u.name FROM users u中,将u.name替换为users.name)。 - 处理函数(如
COUNT(name)确认COUNT是合法聚合函数)。
- 校验表 / 列是否存在(如确认
关键输出
Resolved Logical Plan(已解析逻辑计划) —— 一棵 “语义合法” 的逻辑计划,此时所有表、列、函数都已通过元数据校验,没有 “无效词汇”。
阶段 3:逻辑优化(Optimization)—— 给 “合法计划” 做 “减法”
核心目标
通过 RBO(基于规则的优化) 对已解析逻辑计划进行 “等价变换”,删除冗余操作、减少数据量,生成 “更高效” 的优化后逻辑计划。
这是 Catalyst 优化的核心环节,Spark 内置了数十条优化规则,按 “作用类型” 可分为以下几类关键规则(附通俗解释):
| 优化规则分类 | 核心作用 | 典型规则示例 |
|---|---|---|
| 数据量削减 | 提前过滤 / 裁剪数据,减少后续计算的数据量(“早过滤,少传输”) | 1. 谓词下推(Predicate Pushdown):将 2. 列裁剪(Column Pruning):仅保留查询需要的列,删除冗余列。例: 3. 动态分区裁剪(DPP):针对分区表,仅扫描符合条件的分区,避免全表扫描(如按日期分区的表,只读指定日期分区)。 4. Limit 下推(Limit Pushdown):将 |
| 操作简化 | 合并 / 删除重复操作,减少计算步骤(“少干活,快干活”) | 1. 常量折叠(Constant Folding):提前计算常量表达式,避免运行时重复计算。例: 2. 合并同类操作:将连续的 3. 排序消除(Sort Elimination):当排序操作( |
| 聚合优化 | 优化聚合操作,减少 shuffle 前的数据量(“先局部,后全局”) | 1. 聚合下推(Aggregate Pushdown):将 2. 局部聚合(Partial Aggregation):对 |
| Join 优化 | 优化 Join 逻辑,减少 Join 前的数据量 | 1. Join 谓词下推:将 Join 条件中的过滤谓词下推到 Join 前的表,减少参与 Join 的数据量。例: 2. 消除笛卡尔积:若 Join 缺少关联条件,且有过滤谓词,自动补充关联条件避免笛卡尔积。 |
关键输出
Optimized Logical Plan(优化后逻辑计划) —— 与原逻辑计划 “语义等价”,但操作更简洁、数据量更小的逻辑计划。
阶段 4:物理优化(Physical Planning)—— 给 “优化逻辑” 选 “最优执行方案”
核心目标
将优化后的逻辑计划转化为可执行的物理计划,并通过 CBO(基于成本的优化) 从多个候选物理计划中选择 “成本最低” 的方案。
执行过程
-
输入:Optimized Logical Plan(优化后逻辑计划)。
-
物理计划生成:遍历优化后的逻辑计划,将每个逻辑操作(如
Join、Aggregate、Filter)转化为多个候选物理操作(物理操作是 Spark 可实际执行的分布式操作)。- 例:逻辑操作
Join可转化为 3 种物理操作:- Broadcast Join:小表广播到所有 Executor,无 shuffle,适合小表 Join。
- Sort Merge Join:两表先排序再合并,适合大表 Join。
- Hash Join:通过哈希表匹配,适合中等规模表 Join。
- 例:逻辑操作
-
CBO 成本评估:
- 核心依赖:表的统计信息(Statistics),包括行数、列基数(不同值的数量)、数据大小、数据分布等(需手动收集:
ANALYZE TABLE users COMPUTE STATISTICS)。 - 成本计算:基于统计信息,计算每个候选物理计划的 “成本”(主要包括 CPU 开销和 IO / 网络传输开销,数据传输成本权重更高)。
- 选择最优:选择成本最低的物理计划作为最终执行计划。
- 核心依赖:表的统计信息(Statistics),包括行数、列基数(不同值的数量)、数据大小、数据分布等(需手动收集:
关键输出
Physical Plan(物理执行计划) —— 可直接被 Spark 转化为 Task 执行的分布式计划(如 BroadcastHashJoin + Filter + Scan 等物理操作的组合)。
二、Catalyst 的 “扩展性”:自定义优化规则
Catalyst 设计的灵活性在于支持自定义优化规则,满足特殊业务场景的优化需求(如自定义函数优化、特定数据源过滤下推等)。
自定义规则的核心逻辑
- 规则类型:继承 Catalyst 的
Rule[LogicalPlan]类,实现apply方法(遍历逻辑计划,对符合条件的节点进行变换)。 - 注入时机:将自定义规则注册到 Catalyst 的优化器阶段(如逻辑优化阶段)。
示例:自定义 “删除无效过滤” 规则
若业务中存在 WHERE 1=1 这类无效过滤条件,可自定义规则自动删除:
// 自定义规则:删除条件为 1=1 的 Filter 操作
class RemoveInvalidFilter extends Rule[LogicalPlan] {def apply(plan: LogicalPlan): LogicalPlan = plan.transform {case Filter(Literal(true, BooleanType), child) => child // 匹配 WHERE 1=1(解析后为 Literal(true)),直接删除 Filter}
}// 注册规则到 Catalyst 优化器
spark.sessionState.optimizer.extendedOperatorOptimizationRules ++= Seq(new RemoveInvalidFilter)三、Catalyst 优化总结
Catalyst 的优化本质是 “先合法,再基于理论高效优化(RBO),基于成本选最优(CBO)” 的三层递进:
- 解析 + 分析:确保 “语法正确 + 语义合法”,避免 “无效查询”。
- 逻辑优化(RBO):通过规则做 “等价变换”,减少数据量和操作数,是 “通用优化”。
- 物理优化(CBO):基于数据统计选 “成本最低” 的执行方案,是 “精准优化”。
推荐内容:
吃透大数据算法-算法地图
大数据计算引擎-从源码看Spark AQE对于倾斜的处理
深入starrocks-怎样实现多列联合统计信息
深入starrocks-多列联合统计一致性探查与策略(YY一下)
大数据计算引擎-全阶段代码生成(Whole-stage Code Generation)与火山模型(Volcano)对比