Linux 线程控制与同步互斥
一.线程控制
1.使用clone创建轻量级进程
由上一章我们对线程在地址空间和内存中的排布我们知道,线程在用户空间的pthread库中有自己的数据结构tcb,并且每个线程都使用自己独立的栈空间。本节我们就手动使用clone来模拟线程的整个使用过程。
malloc往往会返回一个地址较低的位置,而栈是从高到低向下增长的。
clone就是用自己的方法,传入自己创建的栈,库里面就是对这个过程进行了封装
库中源码申请栈空间使用mmap,mmap可以做文件映射,也可以进行共享内存开辟
#define _GNU_SOURCE#include <sched.h>int clone(int (*fn)(void *), void *stack, int flags, void *arg, .../* pid_t *parent_tid, void *tls, pid_t *child_tid */ );
#include <sched.h>
#include <stdio.h>
#include <iostream>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
#include <pthread.h>#define STACK_SIZE (1024 * 1024) // 1MB 的栈空间// 子进程执行的函数
static int child_func(void *arg)
{while (true){printf("Child process: PID = %d\n", getpid());sleep(1);}return 0;
}int main()
{char *stack = (char *)malloc(STACK_SIZE); // 为子进程分配栈空间if (stack == NULL){perror("malloc");exit(EXIT_FAILURE);}// 使用 clone 创建子进程pid_t pid = clone(child_func, stack + STACK_SIZE, CLONE_VM | SIGCHLD, NULL);if (pid == -1){perror("clone");free(stack);exit(EXIT_FAILURE);}printf("Parent process: PID = %d, Child PID = %d\n", getpid(), pid);// 等待子进程结束if (waitpid(pid, NULL, 0) == -1){perror("waitpid");free(stack);exit(EXIT_FAILURE);}free(stack);return 0;
}
2.线程栈
每个线程都有独立的上下文:有独立的PCB(内核)+TCB(用户层,pthread库内部)
独立的栈:每个线程都有自己的栈,要么是进程自己的,要么是库里创建线程时mmap申请出来的
我们知道,在Linux中的线程是由轻量级进程模拟实现的,因此线程和进程不加区分的统一到了task_struct中,但是它们对待自己的地址空间的stack是有区别的。
1.对于Linux进程,或者说主线程:stack简单理解就是main函数的栈空间,fork创建子进程时会复制父进程的stack空间地址,拥有写时拷贝和动态增长的特性。如果扩充超出该上限则栈溢出,报段错误(发送信号给进程)。进程栈是唯一可访问未映射页而不一定会发生段错误(超出扩充上限才会报错)的结构。
2.对于主线程生成的子线程:它的stack不再是向下生长的,而是实现固定好的一段空间。线程栈一般是调用pthread库中的pthread_create创建的线程,存在于地址空间的共享区中。其中stack一般通过mmap系统调用创建。stack的大小可以自己设定,不过我们一般使用系统默认的大小。
对于子线程的stack,它其实是在进程的地址空间中mmap出来的一块内存区域,原则上是线程私有的,但是同一个进程的所有线程生成时会浅拷贝生成者的task_struct的很多字段,如果愿意,线程中的资源可以被任意其他线程访问。
只要知道栈中某个数据的地址,其他线程也可以进行访问。所谓独占,只要程序员不要随便拿地址出来,这些资源就是由各线程独占的。
我们可以用两个线程做例子:子线程修改全局变量p指针变量,父线程打印出p,它们看到的是同一份资源
#include <sched.h>
#include <stdio.h>
#include <iostream>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
#include <pthread.h>int *p = nullptr;//子线程修改全局变量p的值
void *threadrun(void *args)
{int a = 123;p = &a;while(true) {sleep(1);}
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, threadrun, nullptr);//父线程可以打印全局变量p的值,是同一份资源while(true){std::cout << "*p : " << *p << std::endl;sleep(1);}pthread_join(tid, nullptr);return 0;
}
3.线程封装
我们可以对pthread库的线程相关操作进行封装,实现其类似于C++中的线程操作。
#ifndef _THREAD_H_
#define _THREAD_H_#include <iostream>
#include <string>
#include <pthread.h>
#include <cstdio>
#include <cstring>
#include <functional>namespace ThreadModlue
{static uint32_t number = 1; // bugtemplate<typename T>class Thread{using func_t = std::function<void(T)>; private:void EnableDetach(){std::cout << "线程被分离了" << std::endl;_isdetach = true;}void EnableRunning(){_isrunning = true;}static void *Routine(void *args) // 属于类内的成员函数,默认包含this指针!{Thread<T> *self = static_cast<Thread<T> *>(args);self->EnableRunning();if (self->_isdetach)self->Detach();self->_func(self->_data); // 回调处理return nullptr;}// bugpublic:Thread(func_t func, T data): _tid(0),_isdetach(false),_isrunning(false),res(nullptr),_func(func),_data(data){_name = "thread-" + std::to_string(number++);}void Detach(){if (_isdetach)return;if (_isrunning)pthread_detach(_tid);EnableDetach();}bool Start(){//运行中的线程不能再次启动if (_isrunning)return false;int n = pthread_create(&_tid, nullptr, Routine, this);if (n != 0){std::cerr << "create thread error: " << strerror(n) << std::endl;return false;}else{std::cout << _name << " create success" << std::endl;return true;}}bool Stop(){ //运行中的线程才能stopif (_isrunning){int n = pthread_cancel(_tid);if (n != 0){std::cerr << "create thread error: " << strerror(n) << std::endl;return false;}else{_isrunning = false;std::cout << _name << " stop" << std::endl;return true;}}return false;}void Join(){ //分离的线程不能进行joinif (_isdetach){std::cout << "你的线程已经是分离的了,不能进行join" << std::endl;return;}int n = pthread_join(_tid, &res);if (n != 0){std::cerr << "create thread error: " << strerror(n) << std::endl;}else{std::cout << "join success" << std::endl;}}~Thread(){}private:pthread_t _tid;// 线程idstd::string _name;// 线程名//线程的属性,是否分离、是否运行中bool _isdetach;bool _isrunning;// 线程的返回值void *res;// 线程的回调函数和参数func_t _func;// 线程的参数T _data;};
}#endif重点:
1.当我们在类内创建回调函数Routine时,发现无法使用:原因是routine属于类内成员的函数,默认带有this指针
解决方式:创建一个self对象进行回调
2.子线程的方法Routine最好由外部指派一个任务,因为我们的需求不仅仅是把它作为一个类内成员使用
上面是对线程的封装,我们来使用一下这个封装的线程类。
#include "Thread.hpp"
#include <unistd.h>using namespace ThreadModlue;// 我们可以传递对象吗???class ThreadData{public:pthread_t tid;std::string name;};void Count(ThreadData td){while (true){std::cout << "我是一个新线程" << std::endl;sleep(1);}}int main()
{ThreadData td;Thread<ThreadData> t(Count, td);t.Start();t.Join();Thread t([](){while(true){std::cout << "我是一个新线程" << std::endl;sleep(1);}});t.Start();t.Detach();sleep(5);t.Stop();sleep(5);t.Join();return 0;
}值得注意的是:
1.我们定义了一个数据结构ThreadData,主要是用来表示传给子线程函数的数据类型。
2.在创建Thread时的传参,传入子线程方法Count以及Count的参数ThreadData类型。
3.在给封装的线程传参,使用了lambda表达式传参。
变量由__thread修饰:线程局部存储,不同线程拿到的count虚拟地址是不同的。
线程局部存储有什么用?
当前需要一个全局变量,但不愿意让这个变量让其他线程看到!
注意:线程局部存储只能存储内置类型和部分指针
#include <pthread.h>
#include <iostream>
#include <string>
#include <unistd.h>// 该count叫做线程的局部存储!
__thread int count = 1;
// 线程局部存储有什么用?全局变量,我又不想让这个全局变量被其他线程看到!
// 线程局部存储,只能存储内置类型和部分指针std::string Addr(int &c)
{char addr[64];snprintf(addr, sizeof(addr), "%p", &c);return addr;
}void *routine1(void *args)
{(void)args;while (true){std::cout << "thread - 1, count = " << count << "[我来修改count], "<< "&count: " << Addr(count) << std::endl;count++;sleep(1);}
}void *routine2(void *args)
{(void)args;while (true){std::cout << "thread - 2, count = " << count<< ", &count: " << Addr(count) << std::endl;sleep(1);}
}int main()
{pthread_t tid1, tid2;pthread_create(&tid1, nullptr, routine1, nullptr);pthread_create(&tid2, nullptr, routine2, nullptr);pthread_join(tid1, nullptr);pthread_join(tid2, nullptr);return 0;
}二.线程的同步与互斥
从之前我们线程往同一个显示器文件中打印,我们知道线程存在数据不一致问题。
因为线程是共享地址空间的,这就势必让线程共享大部分资源——公共资源,就会出现各种情况的数据不一致问题。
而对同步与互斥,临界资源的概念在这里不再赘述,详细可以看进程的同步与互斥。
1.线程互斥
本节我们的目标如下:
互斥:先看一种现象——数据不一致
解决这个问题——互斥锁
理解为什么数据会不一致
认识锁相关的接口
理解锁是什么
1.通过模拟抢票,来看数据不一致的现象。
// 操作共享变量会有问题的售票系统代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>int ticket = 1000;void *route(void *arg)
{char *id = (char *)arg;while (1){if (ticket > 0) // 1. 判断{usleep(1000); // 模拟抢票花的时间printf("%s sells ticket:%d\n", id, ticket); // 2. 抢到了票ticket--; // 3. 票数--pthread_mutex_unlock(&lock);}else{break;}}return nullptr;
}int main(void)
{pthread_t t1, t2, t3, t4;pthread_create(&t1, NULL, route, (void *)"thread 1");pthread_create(&t2, NULL, route, (void *)"thread 2");pthread_create(&t3, NULL, route, (void *)"thread 3");pthread_create(&t4, NULL, route, (void *)"thread 4");pthread_join(t1, NULL);pthread_join(t2, NULL);pthread_join(t3, NULL);pthread_join(t4, NULL);
}结果如下:居然出现了负数?
thread 3 sells ticket:0
thread 1 sells ticket:-1
thread 2 sells ticket:-2
根据现有的关于互斥与共享的知识,我们不难分析出:
全局变量ticket是共享资源
临界区代码:
if (ticket > 0) // 1. 判断{usleep(1000); // 模拟抢票花的时间printf("%s sells ticket:%d\n", id, ticket); // 2. 抢到了票ticket--; // 3. 票数--pthread_mutex_unlock(&lock);}2.解决线程互斥——互斥锁mutex
这里先直接给出解决问题的办法,不解释:通过互斥锁mutex实现互斥
注意,加锁要尽量保持较细的粒度,否则可能会出现让一个线程把票都抢光的情况
效果如下:解决了票抢到负数的问题,但我们同时也发现程序运行的速度明显变慢。
thread 1 sells ticket:3
thread 1 sells ticket:2
thread 1 sells ticket:1
3.为什么会出现数据不一致的现象?
不难想到,出现数据不一致跟判断ticket大小,以及ticket- -有关(其实这里最主要的原因是判断大小)。
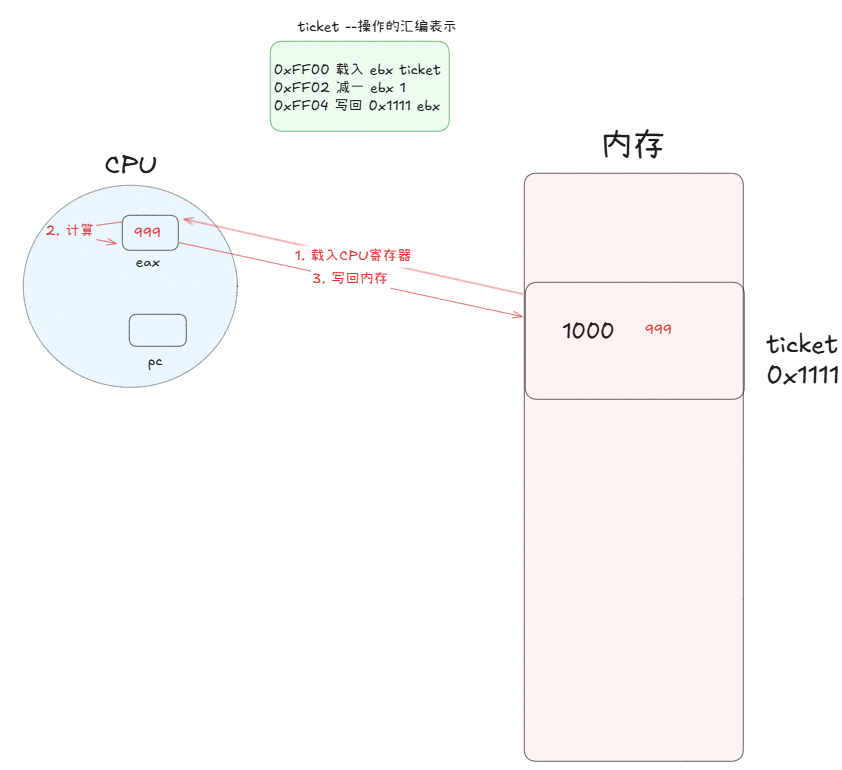
对全局整数变量做–操作,这个操作并不是原子的。为什么?
做- -,核心步骤做三步:
1,将数据加载到CPU的寄存器中
2,CPU对该寄存器的值做计算
3,将计算后的值写回内存
ticket- -看起来只有一句,但这是从C语言角度看的,它在编译时需要形成汇编语言,就会分解成以上至少三步。
CPU以上这一系列操作,本质上是在执行一个线程或进程的代码
PC指针指向下一条执行指令的位置,并且CPU可以识别指令长度,这样PC指针就可以按顺序指向执行指令了。
假设现在有两个线程,A和B都在执行这份代码。
当CPU正在执行第二条,准备执行第三条时,线程A切换了。此时线程就要保存自己的上下文,例如ebx的值和pc寄存器保存的下条指令地址,然后该代码所属的线程/进程进入等待队列。
这时CPU选择另一个线程B,它们执行的是同一个代码(重入),再将ebx的值覆盖为1000,PC指针自动更新
再执行计算。如果线程B在运行时没有被切换,那么他就可以继续执行第三条指令,将运算后的结果(999)写回内存。
这就是一次ticket–!
极端情况下,我们假设循环抢票过程中线程B执行了999次ticket–,此时内存中的ticket变为1,即将执行最后一次ticket–。
假设此时线程B要执行最后一次,结果此时发生了线程切换到A,线程B的上下文被保存:ebx=1,以及PC指针位置。
线程A切换回来,首先要做的是恢复上下文。当前CPU就继续调度执行线程A的代码。不幸的是此时PC指向第三条写回内存的位置,而且ebx值为999;CPU直接执行当前线程A的代码,一瞬间让线程B的工作付诸东流——内存的值被写回999了。
这样,就造成了数据不一致问题!
tips:
这里也就理解了讲解线程信号量时的问题:信号量本质是一个计数器,但我们不能直接用一个整数值表示它,因为整数的加减不是原子的。
原子性是什么?当前来看,就是一条汇编指令。
正面回答:为啥票数会小于0?跟ticket的判断大小有关。
假设ticket被线程安全地减少到1,此时要比较大小本身也是一种逻辑运算,就需要将ticket载入CPU寄存器。
比如现在有四个线程,都载入了CPU,但都被切换走了。然后依次唤醒线程,执行–还会将ticket载入CPU寄存器,这样每次下一个进程的载入数据都是由上个进程计算得到的值,就会出现减少到负数的情况。
在这个代码中,让多个线程都有机会判断ticket值,正是因为那句sleep导致的。

上面这个例子说明了一个问题:
全局资源没有加保护,可能会有并发问题——线程安全问题
而routine函数就是不可重入函数,因为有全局的资源ticket。
多线程中,制造更多的并发,更多的切换,那么问题就转换成——切换的时间点是什么?
1.时间片轮转
2.阻塞IO
3.sleep等休眠
本质上都是陷入内核!
什么是实际选择新的线程,继续调度呢?
从内核态返回用户态的时候,进行检查——熟悉吧?这个操作是和信号的检查再同一个阶段做的。
解决上面的问题,就要使用各种的锁——pthread库提供。
4.认识与锁相关的接口
使用锁有两种方式:
a.全局使用锁:不需要手动释放,程序运行结束自动释放

b.局部使用锁:需要初始化和手动释放
所有线程必须竞争申请锁,多线程都需要先看到锁,锁本身就是一种临界资源——这又绕回了之前信号量的话题,我们需要保证申请锁的操作是原子的。
锁提供的功能本质:执行临界区代码由并行转为串行
我们接着以抢票代码为例来使用锁。
class ThreadData
{
public:ThreadData(const std::string &n, pthread_mutex_lock &lock): name(n),lockp(&lock){}~ThreadData() {}std::string name;pthread_mutex_lock *lockp;
}; pthread_mutex_lock(td->lockp);td->lockp->Lock();if (ticket > 0){usleep(1000);printf("%s sells ticket:%d\n", td->name.c_str(), ticket);ticket--;pthread_mutex_unlock(td->lockp);td->lockp->Unlock();}else{pthread_mutex_unlock(td->lockp);break;}int main(){pthread_mutex_t lock;pthread_mutex_init(&lock, nullptr); // 初始化锁....pthread_mutex_destroy(&lock);
}tips:
进程间的互斥我们也可以通过锁来解决。只需要申请一块共享内存shm,然后将它的类型强转为pthread_mutex_t即可。
通过加锁来限制非临界区和临界区
问题:允许在临界区内切换线程,会出现上面没加锁的问题吗?
不会,因为我当前的线程没有释放锁,我是持有锁的情况下被切换的,其他线程需要等我切换回来执行完代码释放锁,它们才能展开对锁的竞争,进入临界区(其他线程只能干瞪眼)
这也是加锁后代码运行变慢的原因之一。
没有拿到锁的进程,怎么看拿到锁的进程?
要么你还没用,要么你用完了——这些结果才对外面的线程有意义,他们不关心你占用锁的过程在做什么。
这就是原子性。
5.锁的原理
a.硬件级实现:关闭时钟中断
b.软件级实现:也是互斥原理:
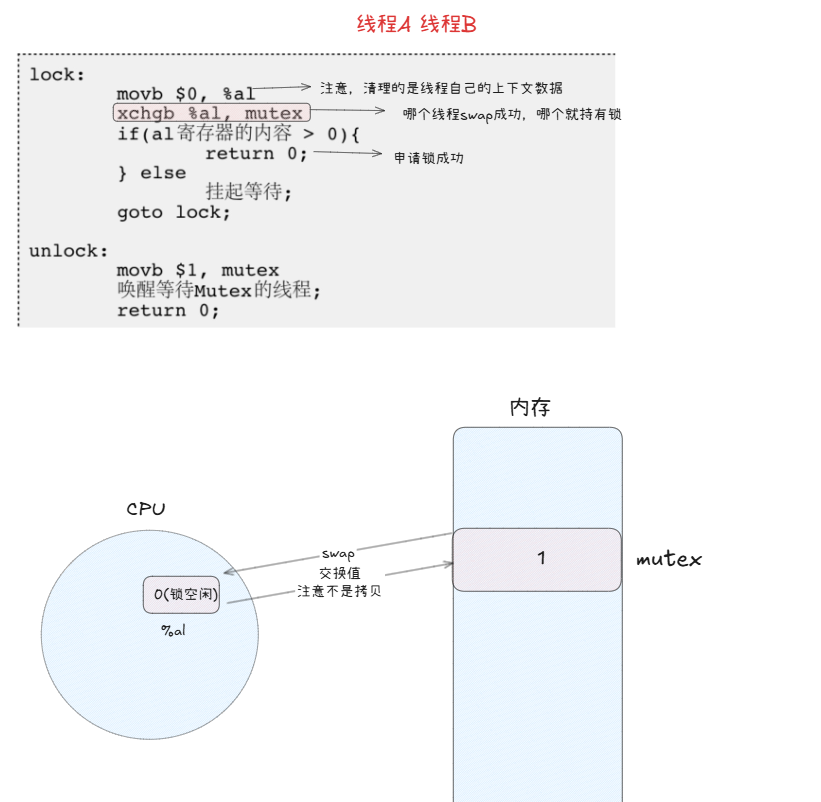
为了实现互斥锁操作,大多数体系结构都提供了swap指令和exchange指令。该指令的作用是把寄存器和内存单元的数据交换。
清理寄存器内容:是自己的上下文!
1. 加锁过程
当一个线程(比如线程A)想要进入临界区时,它会调用 mutex_lock。
// 伪代码实现
void mutex_lock(int *lock) {int key = 1; // 线程将自己的“钥匙”设置为1,表示“我想获得锁”do {swap(lock, &key); // 原子操作:交换 lock 和 key 的值} while (key == 1); // 如果交换后 key 的值为1,说明锁被别人拿着,继续循环等待// 如果 key 为0,则成功获得锁,退出循环,进入临界区
}初始状态:
lock = 0(锁空闲),线程A的key = 1。执行
swap(lock, key):这个操作原子地完成了两件事:
它读取了当前
lock的值(0)。它将自己的
key的值(1)写入到lock中。
最终结果是:
lock变成了1,线程A的key变成了0。
检查
while (key == 1):线程A发现自己的
key现在是0,循环条件不成立。于是线程A跳出循环,成功获得了锁,可以安全地进入临界区。
此时,如果线程B也试图加锁:
初始状态:
lock = 1(因为线程A刚设置了),线程B的key = 1。执行
swap(lock, key):原子操作:
lock(1) 和key(1) 交换。最终结果是:
lock保持为1,线程B的key也变成了1。
检查
while (key == 1):线程B发现自己的
key是1,循环条件成立。于是线程B无法跳出循环,它必须不断地重复执行
swap操作,也就是我们常说的 “自旋等待”。在这种情况下,这个锁也被称为 自旋锁。
swap 指令的精妙之处在于:
线程B在自旋时,它每一次 swap 操作,都是在尝试把自己的 key (1) 和 lock (1) 交换。只要线程A没有释放锁,lock 的值就一直是1,所以每次交换后,线程B的 key 也永远是1,导致它永远在循环中等待。
2. 解锁过程
当线程A离开临界区时,它会调用 mutex_unlock。
// 伪代码实现
void mutex_unlock(int *lock) {*lock = 0; // 简单地将锁变量设置为0,表示锁已释放
}解锁过程非常简单:
线程A执行
*lock = 0。内存中的
lock变量从1变回0。
这对等待的线程B意味着什么:
线程B仍在循环中执行
swap(lock, key)。在某一时刻,当线程B再次执行
swap时:原子操作: 此时
lock是0(线程A已释放),线程B的key是1。交换后:
lock变成了1,线程B的key变成了0。
检查
while (key == 1):线程B发现自己的
key现在是0,循环条件不成立。于是线程B跳出循环,成功获得了锁,可以进入临界区。
总结:
所有的申请锁操作,都跟寄存器有关
线程和进程的切换:CPU内的寄存器硬件只有一套,但CPU寄存器的数据可以有多份,进程/线程各持有一份数据,当前执行流的上下文!
换句话说:如果把一个变量的内容交换到CPU寄存器内部,本质就是把该变量的内容获取到当前执行流的硬件上下文中。
当前CPU寄存器的硬件上下文,其实就是各个寄存器的内容,属于进程/线程私有
我们用swap,exchange指令将内存中的变量,交换到寄存器中,本质是当前进程/线程再获取锁!所以谁申请到,谁持有锁
6.封装锁Mutex
对锁的封装操作就比线程的封装简单许多了。
#pragma once
#include <iostream>
#include <pthread.h>namespace MutexModule
{class Mutex{public:Mutex(){pthread_mutex_init(&_mutex, nullptr);}void Lock(){int n = pthread_mutex_lock(&_mutex);(void)n;}void Unlock(){int n = pthread_mutex_unlock(&_mutex);(void)n;}~Mutex(){pthread_mutex_destroy(&_mutex);}private:pthread_mutex_t _mutex;};class LockGuard{public:LockGuard(Mutex &mutex):_mutex(mutex){_mutex.Lock();}~LockGuard(){_mutex.Unlock();}private:Mutex &_mutex;};
}接着是这个封装Mutex的使用,需要特别强调的是这里RAII风格的互斥锁:它作为while代码块中的一个临时变量,在一次循环结束后就会被自动析构。
#include <iostream>
#include <mutex>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
#include "Mutex.hpp"using namespace MutexModule;int ticket = 1000;
// pthread_mutex_t glock = PTHREAD_MUTEX_INITIALIZER;
// std::mutex cpp_lock;class ThreadData
{
public:ThreadData(const std::string &n, Mutex &lock): name(n),lockp(&lock){}~ThreadData() {}std::string name;Mutex *lockp;
};// 加锁:尽量加锁的范围粒度要比较细,尽可能的不要包含太多的非临界区代码
void *route(void *arg)
{ThreadData *td = static_cast<ThreadData *>(arg);while (1){LockGuard guard(*td->lockp); // 加锁完成, RAII风格的互斥锁的实现if (ticket > 0){usleep(1000);printf("%s sells ticket:%d\n", td->name.c_str(), ticket);ticket--;}else{break;}usleep(123);}return nullptr;
}int main(void)
{// pthread_mutex_t lock;// pthread_mutex_init(&lock, nullptr); // 初始化锁int a = 20;Mutex lock;pthread_t t1, t2, t3, t4;ThreadData *td1 = new ThreadData("thread 1", lock);pthread_create(&t1, NULL, route, td1);ThreadData *td2 = new ThreadData("thread 2", lock);pthread_create(&t2, NULL, route, td2);ThreadData *td3 = new ThreadData("thread 3", lock);pthread_create(&t3, NULL, route, td3);ThreadData *td4 = new ThreadData("thread 4", lock);pthread_create(&t4, NULL, route, td4);pthread_join(t1, NULL);pthread_join(t2, NULL);pthread_join(t3, NULL);pthread_join(t4, NULL);// pthread_mutex_destroy(&lock);return 0;
}2.线程同步
1.线程同步存在的意义
为什么要同步?纯互斥有缺点!
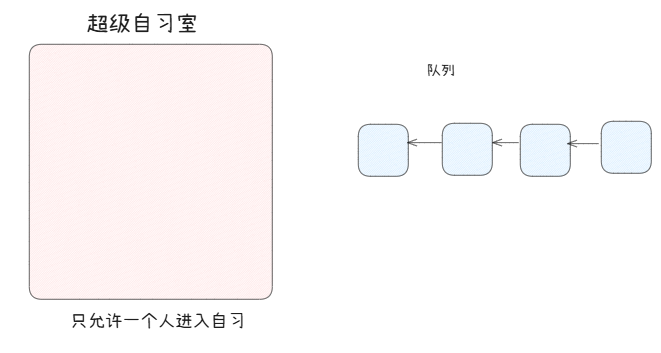
我们假设有一个超级自习室,它在同一时刻只允许一个人拿着钥匙进入自习室进行自习。
当前申请到锁的线程,对锁的竞争力更大,如果你频繁的申请释放锁,其他线程是难以得到锁的(饥饿)。反应再上面的例子中,就容易出现一个线程把票全抢完 的情况
纯互斥有错码?没有,它确实可以解决问题;但是它不高效,也不太公平。
于是:不能立即申请第二次锁,外边的线程必须排队等,之前申请的线程还要申请,就需要拍到队列尾部等待二次申请。
在保证自习室安全的情况下,让所有执行流按一定顺序访问资源。
2.条件变量
1.理解条件变量机制
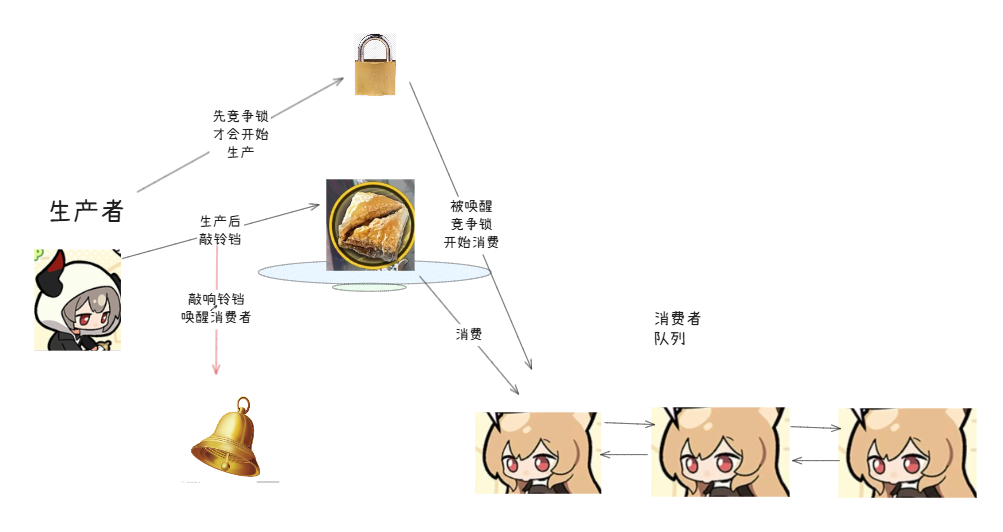
假设有两个人,A向盘子中放食物,B从盘子中拿食物。
不管是放食物还是拿食物,双方都不知道当前盘子中食物的情况,盘子就是临界资源。所以放食物和拿食物的人,都需要申请锁进行操作。
因为双方都不知道盘子里有么有食物,所以这会产生大量的锁竞争。这时,就引入了一个铃铛和等待队列——条件变量。
放食物的人,放完食物,敲一下铃铛;拿苹果的人,如果在申请所发现盘子中没有食物,就插入到等待队列中,当铃铛响起,就唤醒去竞争锁拿食物。
放食物的人放食物后,释放锁后不会立刻去竞争锁,而是敲响铃铛唤醒队列中的人。
2.了解条件变量接口
创建、初始化、销毁条件变量

阻塞队列:在指定的条件变量下等待,引入互斥锁(引入的原因会详细解释)。其中broadcast为唤醒队列中所有的线程,signal为唤醒队列中一个线程。

写一个样例来使用接口:
问题1:使用条件变量,我们需要定义锁:为什么要定义锁?、
pthread_mutex_t glock = PTHREAD_MUTEX_INITIALIZER; // 定义锁, 为什么一定要有锁??
pthread_cond_t gcond = PTHREAD_COND_INITIALIZER; // 定义条件变量
问题2:这里的等待,是需要的时候才需要等,那么什么时候需要等?
void *threadrun(void *args)
{std::string name = static_cast<const char *>(args);while (true){pthread_mutex_lock(&glock);// 直接让对用的线程进行等待?? 临界资源不满足导致我们等待的!pthread_cond_wait(&gcond, &glock); // glock在pthread_cond_wait之前,会被自动释放掉std::cout << name << " 计算: " << cnt << std::endl;cnt++;pthread_mutex_unlock(&glock);}
}比如之前的ticket=0,等待之前就要对资源的数量进行判定。
而判定本身就是在访问临界资源,所以判定一定是在临界区内部的。
换句话说,条件不满足(临界资源不满足)的休眠,也需要在临界区内!
我们此时就能理解为什么wait需要传入一个锁:如果当前竞争到锁的线程发现资源未满足,就会进入等待队列,同时会把锁释放让其他线程进行竞争。
此时我们使用cond_signal接口一次唤醒线程,就可以实现同步了。
while(true)
{std::cout << "唤醒所有线程... " << std::endl;pthread_cond_broadcast(&gcond);// std::cout << "唤醒一个线程... " << std::endl;// pthread_cond_signal(&gcond);sleep(1);
}完整的代码:
#include <iostream>
#include <vector>
#include <string>
#include <unistd.h>
#include <pthread.h>#define NUM 5
int cnt = 1000;pthread_mutex_t glock = PTHREAD_MUTEX_INITIALIZER; // 定义锁, 为什么一定要有锁??
pthread_cond_t gcond = PTHREAD_COND_INITIALIZER; // 定义条件变量// 等待是需要等,什么条件才会等呢?票数为0,等待之前,就要对资源的数量进行判定。
// 判定本身就是访问临界资源!,判断一定是在临界区内部的.
// 判定结果,也一定在临界资源内部。所以,条件不满足要休眠,一定是在临界区内休眠的!
// 证明一件事情:条件变量,可以允许线程等待
// 可以允许一个线程唤醒在cond等待的其他线程, 实现同步过程
void *threadrun(void *args)
{std::string name = static_cast<const char *>(args);while (true){pthread_mutex_lock(&glock);// 直接让对用的线程进行等待?? 临界资源不满足导致我们等待的!pthread_cond_wait(&gcond, &glock); // glock在pthread_cond_wait之前,会被自动释放掉std::cout << name << " 计算: " << cnt << std::endl;cnt++;pthread_mutex_unlock(&glock);}
}int main()
{std::vector<pthread_t> threads;for (int i = 0; i < NUM; i++){pthread_t tid;char *name = new char[64];snprintf(name, 64, "thread-%d", i);int n = pthread_create(&tid, nullptr, threadrun, name);if (n != 0)continue;threads.push_back(tid);sleep(1);}sleep(3);// 每隔1s唤醒一个线程while(true){std::cout << "唤醒所有线程... " << std::endl;pthread_cond_broadcast(&gcond);// std::cout << "唤醒一个线程... " << std::endl;// pthread_cond_signal(&gcond);sleep(1);}for (auto &id : threads){int m = pthread_join(id, nullptr);(void)m;}return 0;
}通过实验我们发现,线程被唤醒的顺序就是入队列的顺序。
3.生产者消费者模型
我们再通过一个例子——生产者消费者模型,来更加深入条件变量。实际上,我们熟悉的管道,就是一种单生产者,单消费者模型。
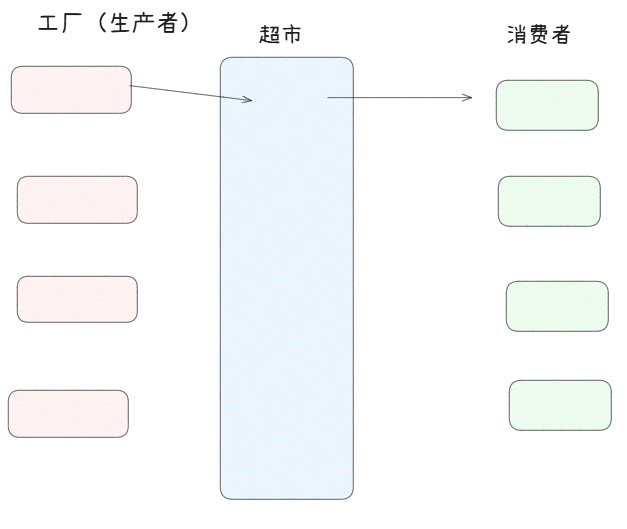
问题:消费者为什么不直接去找工厂?
有成本问题和效率问题,而这个模型的存在也是为了提高生产消费的效率。
超市在这个模型中的作用,属于一个中间的交易场所,它的货架容量有限——相当于一块内存空间,是一种临界资源
生产者和消费者,都由一个一个线程来承担。
生产者消费者模型——本质是一个多线程通信的方式!
在这个模型中,各个角色之间的关系:
生产者之间:竞争,互斥关系
消费者之间:典型的互斥
生产者和消费者之间:为了保护公共资源安全和避免数据不一致,两者互斥和同步
4.基于BlockQueue的生产者消费者模型
在多线程编程中阻塞队列(Blocking Queue)是⼀种常⽤于实现⽣产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放⼊了元素;当队列满时,往队列⾥存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)
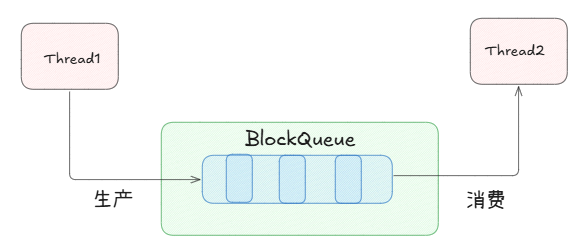
阻塞队列是一个有容量上限的队列,不满足读写条件就会阻塞对应线程。
我们来使用原生的pthread库模拟BlockQueue实现生产者消费者模型。
阻塞队列:BlockQueue.hpp
问题:pthread_cond_wait会不会调用失败?多生产者多消费者时伪唤醒。为了避免这些问题,使用while进行是否满条件判断,代码更健壮
// 阻塞队列的实现
#pragma once#include <iostream>
#include <string>
#include <queue>
#include <pthread.h>const int defaultcap = 5; // for testtemplate <typename T>
class BlockQueue
{
private:bool IsFull() { return _q.size() >= _cap; }bool IsEmpty() { return _q.empty(); }public:BlockQueue(int cap = defaultcap): _cap(cap), _csleep_num(0), _psleep_num(0){pthread_mutex_init(&_mutex, nullptr);pthread_cond_init(&_full_cond, nullptr);pthread_cond_init(&_empty_cond, nullptr);}void Equeue(const T &in){pthread_mutex_lock(&_mutex);// 生产者调用while (IsFull()){// 应该让生产者线程进行等待// 重点1:pthread_cond_wait调用成功,挂起当前线程之前,要先自动释放锁!!// 重点2:当线程被唤醒的时候,默认就在临界区内唤醒!要从pthread_cond_wait// 成功返回,需要当前线程,重新申请_mutex锁// 重点3:如果我被唤醒,但是申请锁失败了?我就会在锁上阻塞等待_psleep_num++;std::cout << "生产者,进入休眠了: _psleep_num" << _psleep_num << std::endl;// 问题1: pthread_cond_wait是函数吗?有没有可能失败?pthread_cond_wait立即返回了// 问题2:pthread_cond_wait可能会因为,条件其实不满足,pthread_cond_wait 伪唤醒pthread_cond_wait(&_full_cond, &_mutex);_psleep_num--;}// 100%确定:队列有空间_q.push(in);// 临时方案// v2if(_csleep_num>0){pthread_cond_signal(&_empty_cond);std::cout << "唤醒消费者..." << std::endl;}// pthread_cond_signal(&_empty_cond); // 可以pthread_mutex_unlock(&_mutex); // TODO// pthread_cond_signal(&_empty_cond); // 可以}T Pop(){// 消费者调用pthread_mutex_lock(&_mutex);while (IsEmpty()){_csleep_num++;pthread_cond_wait(&_empty_cond, &_mutex);_csleep_num--;}T data = _q.front();_q.pop();if(_psleep_num > 0){pthread_cond_signal(&_full_cond);std::cout << "唤醒消费者" << std::endl;}// pthread_cond_signal(&_full_cond);pthread_mutex_unlock(&_mutex);return data;}~BlockQueue(){pthread_mutex_destroy(&_mutex);pthread_cond_destroy(&_full_cond);pthread_cond_destroy(&_empty_cond);}private:std::queue<T> _q; // 临界资源!!!int _cap; // 容量大小pthread_mutex_t _mutex;pthread_cond_t _full_cond;pthread_cond_t _empty_cond;int _csleep_num; // 消费者休眠的个数int _psleep_num; // 生产者休眠的个数
};任务:
可以是类,可以是函数,我们通过模板传入阻塞队列即可
#pragma once
#include <iostream>
#include <unistd.h>
#include <functional>// 任务形式2
// 我们定义了一个任务类型,返回值void,参数为空
using task_t = std::function<void()>;void Download()
{std::cout << "我是一个下载任务..." << std::endl;sleep(3); // 假设处理任务比较耗时
}// 任务形式1
class Task
{
public:Task(){}Task(int x, int y):_x(x), _y(y){}void Execute(){_result = _x + _y;}int X() { return _x; }int Y() { return _y; }int Result(){return _result;}
private:int _x;int _y;int _result;
};主函数Main.cc
#include "BlockQueue.hpp"
#include "Task.hpp"
#include <iostream>
#include <pthread.h>
#include <unistd.h>void *consumer(void *args)
{BlockQueue<task_t> *bq = static_cast<BlockQueue<task_t> *>(args);while (true){sleep(10);// 1. 消费任务task_t t = bq->Pop();// 2. 处理任务 -- 处理任务的时候,这个任务,已经被拿到线程的上下文中了,不属于队列了t();}
}void *productor(void *args)
{BlockQueue<task_t> *bq = static_cast<BlockQueue<task_t> *>(args);while (true){// 1. 获得任务//std::cout << "生产了一个任务: " << x << "+" << y << "=?" << std::endl;std::cout << "生产了一个任务: " << std::endl;// 2. 生产任务bq->Equeue(Download);}
}int main()
{// 扩展认识: 阻塞队列: 可以放任务吗?// 申请阻塞队列BlockQueue<task_t> *bq = new BlockQueue<task_t>();// 构建生产和消费者pthread_t c[2], p[3];pthread_create(c, nullptr, consumer, bq);pthread_create(c+1, nullptr, consumer, bq);pthread_create(p, nullptr, productor, bq);pthread_create(p+1, nullptr, productor, bq);pthread_create(p+2, nullptr, productor, bq);pthread_join(c[0], nullptr);pthread_join(c[1], nullptr);pthread_join(p[0], nullptr);pthread_join(p[1], nullptr);pthread_join(p[2], nullptr);return 0;
}生产者:获得任务,生产任务
消费者:消费任务,处理任务
为什么说生产者消费者模型效率高?生产和消费的过程本来就是串行的,为啥能说提高效率?
我们在消费时,多个线程实际上是串行的从队列中拿任务,而可以并发的处理任务;处理的过程是不影响生产者的工作的!而在任务从派发,获取,处理的整个流程中,真正耗时的是处理任务,而这个过程是并发的
扩展:多生产者多消费者,需要多维护生产者之间,消费者之间的互斥;而目前的代码无需修改,因为在加锁的情况下,无论是生产者还是消费者也只能在同一时刻有一个线程进入。