【完整源码+数据集+部署教程】【天线&化学】航拍图屋顶异常检测系统源码&数据集全套:改进yolo11-ContextGuided
背景意义
随着城市化进程的加快,建筑物的数量不断增加,屋顶作为建筑的重要组成部分,其安全性和功能性日益受到关注。屋顶异常现象,如积水、锈蚀、裂缝等,不仅影响建筑物的美观,更可能导致结构性损害,进而影响居民的安全和生活质量。因此,及时有效地检测屋顶异常现象显得尤为重要。传统的屋顶检查方法通常依赖人工巡检,效率低下且容易受到天气、时间等因素的影响,无法实现实时监测和高效评估。
近年来,随着无人机技术的迅速发展,航拍图像的获取变得更加便捷和高效。结合深度学习技术,尤其是目标检测算法的应用,为屋顶异常检测提供了新的解决方案。YOLO(You Only Look Once)系列算法因其高效的实时检测能力而受到广泛关注。特别是YOLOv11的推出,进一步提升了目标检测的精度和速度。然而,现有的YOLOv11模型在特定领域的应用上仍存在一定的局限性,尤其是在处理复杂的屋顶异常检测任务时。
本研究旨在基于改进的YOLOv11模型,构建一个高效的航拍图屋顶异常检测系统。通过对现有数据集的深入分析,我们将聚焦于屋顶异常的多种类型,包括排水口有无、设备存在、裂缝、积水等情况。数据集中包含76幅图像,涵盖了多种异常类型,能够为模型的训练和测试提供丰富的样本。通过对模型的改进和优化,我们期望能够提高检测的准确性和鲁棒性,从而为建筑物的维护和管理提供科学依据。
综上所述,本研究不仅具有重要的理论意义,也将为实际应用提供切实可行的解决方案,推动建筑物屋顶检测技术的发展,为城市安全和可持续发展贡献力量。
图片效果
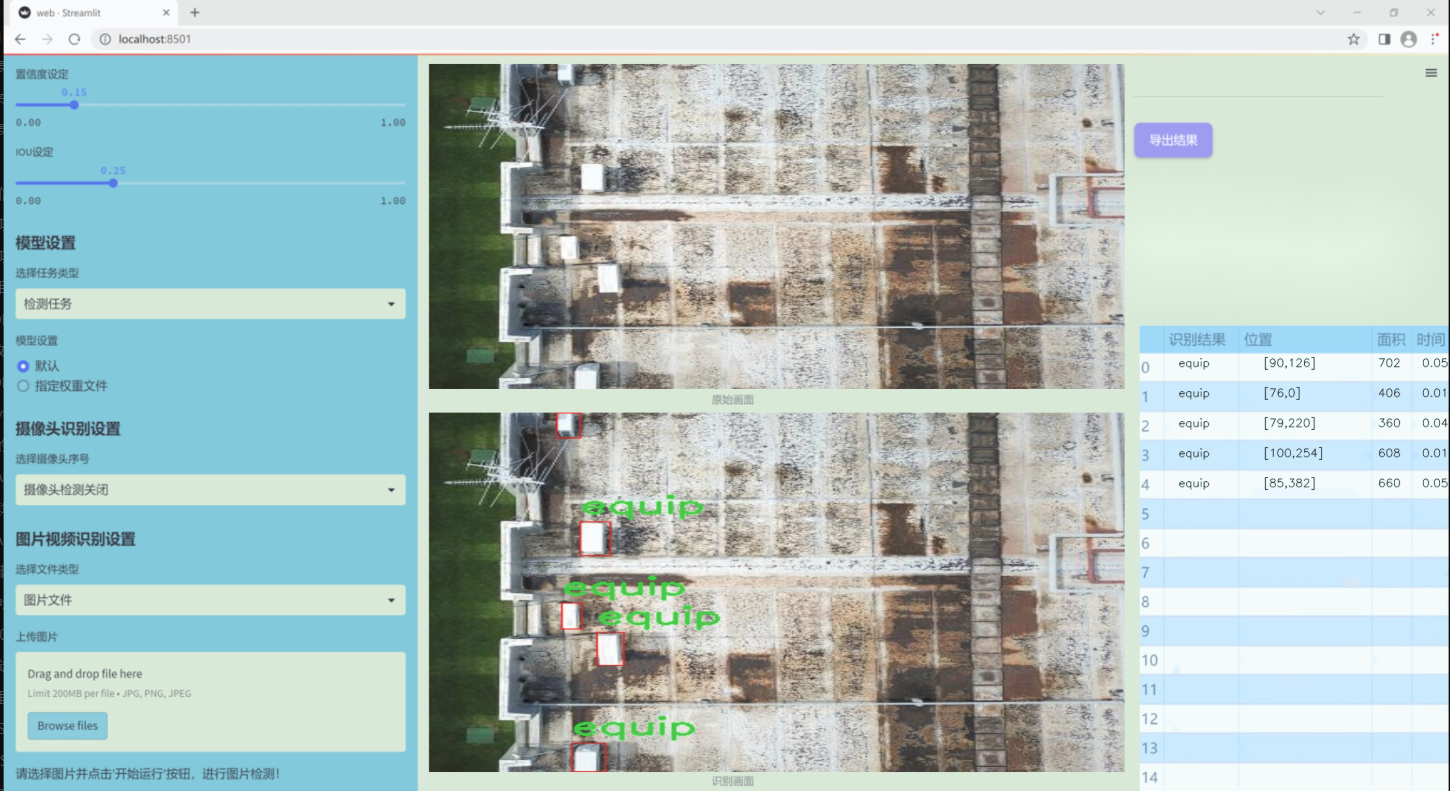
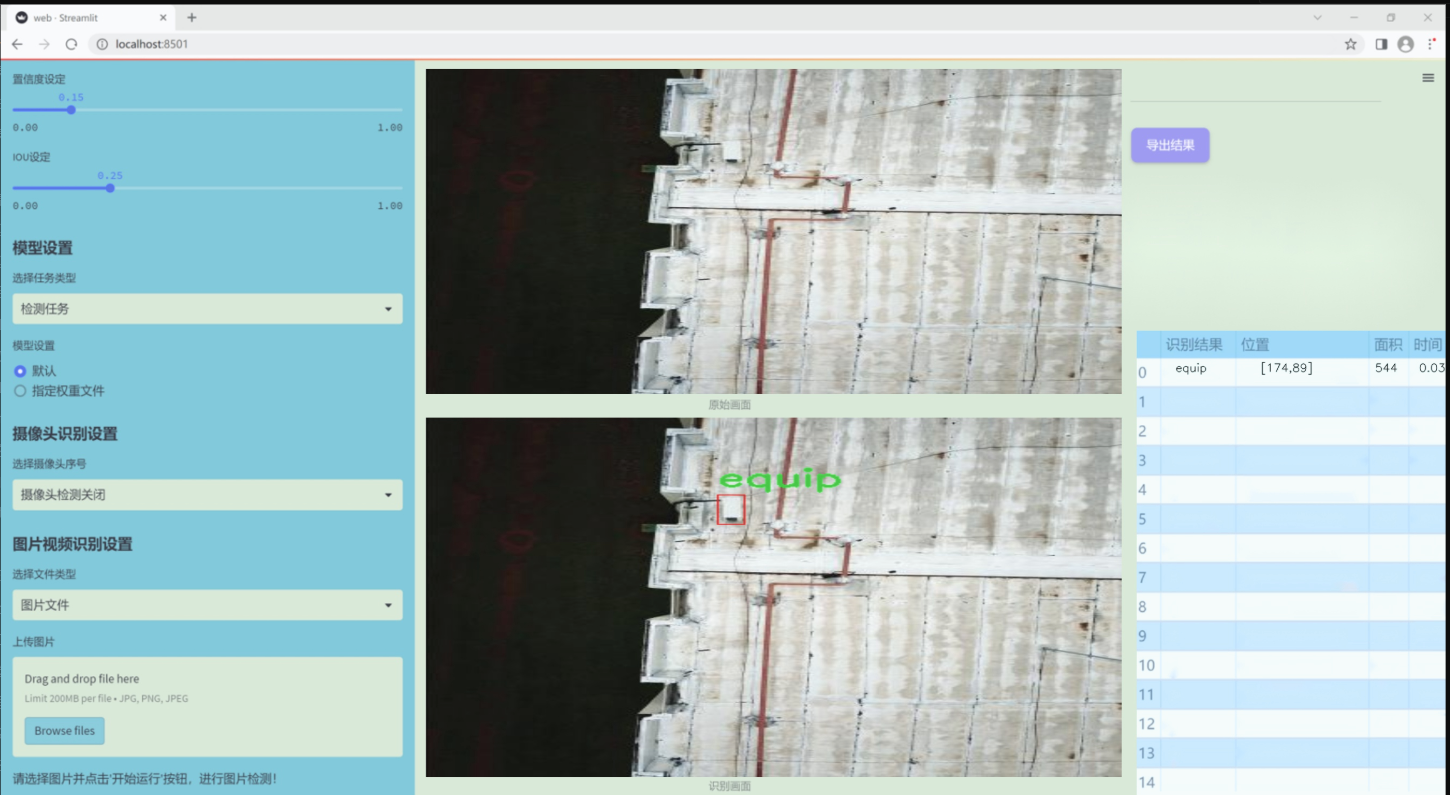
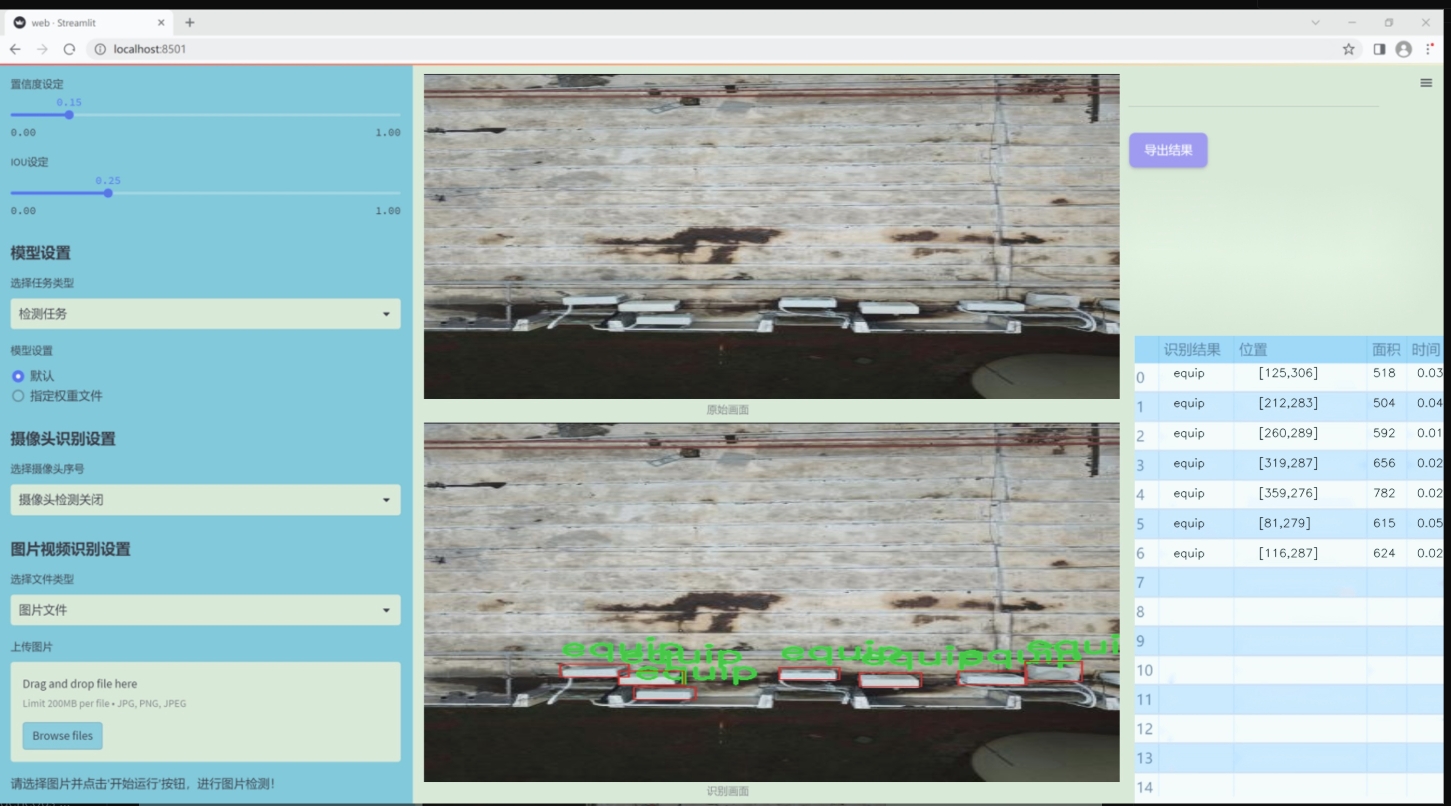
数据集信息
本项目所使用的数据集名为“Roof inspection anomalies”,旨在为改进YOLOv11的航拍图屋顶异常检测系统提供高质量的训练数据。该数据集专注于屋顶检查过程中可能出现的异常情况,尤其是与设备相关的异常。数据集中包含了一个类别,即“equip”,该类别涵盖了与屋顶设备相关的各种异常现象。这些异常可能包括设备的损坏、老化、错位等问题,这些问题在航拍图像中可能表现为特定的视觉特征。
“Roof inspection anomalies”数据集的构建过程注重数据的多样性和代表性,确保所收集的图像能够涵盖不同类型的屋顶、不同的天气条件以及不同的拍摄角度。这种多样性使得模型在训练过程中能够学习到更为丰富的特征,从而提高其在实际应用中的鲁棒性和准确性。数据集中的图像均为高分辨率航拍图,能够清晰地展示屋顶的各个细节,便于模型识别和分类。
在数据标注方面,所有图像均经过专业人员的仔细标注,确保每个异常都被准确识别和标记。这种高质量的标注不仅提升了数据集的可靠性,也为后续的模型训练提供了坚实的基础。通过对“Roof inspection anomalies”数据集的深入分析和应用,我们期望能够显著提升YOLOv11在屋顶异常检测任务中的性能,推动航拍图像分析技术的发展,为建筑维护和安全检查提供更为有效的解决方案。





核心代码
以下是代码的核心部分,并附上详细的中文注释:
import torch
import torch.nn.functional as F
from einops import rearrange
def build_selective_scan_fn(selective_scan_cuda: object = None, mode=“mamba_ssm”):
“”"
构建选择性扫描函数,支持不同的模式。
:param selective_scan_cuda: CUDA实现的选择性扫描函数
:param mode: 选择的模式
:return: 选择性扫描函数
“”"
class SelectiveScanFn(torch.autograd.Function):@staticmethoddef forward(ctx, u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False):"""前向传播函数:param ctx: 上下文对象,用于保存状态:param u: 输入张量:param delta: 增量张量:param A, B, C: 权重张量:param D: 可选的张量:param z: 可选的张量:param delta_bias: 可选的增量偏置:param delta_softplus: 是否使用softplus激活:param return_last_state: 是否返回最后状态:return: 输出张量或输出和最后状态"""# 确保输入张量是连续的if u.stride(-1) != 1:u = u.contiguous()if delta.stride(-1) != 1:delta = delta.contiguous()if D is not None:D = D.contiguous()if B.stride(-1) != 1:B = B.contiguous()if C.stride(-1) != 1:C = C.contiguous()if z is not None and z.stride(-1) != 1:z = z.contiguous()# 调整B和C的维度if B.dim() == 3:B = rearrange(B, "b dstate l -> b 1 dstate l")ctx.squeeze_B = Trueif C.dim() == 3:C = rearrange(C, "b dstate l -> b 1 dstate l")ctx.squeeze_C = True# 检查输入形状的有效性assert u.shape[1] % (B.shape[1]) == 0 # 调用CUDA实现的前向函数out, x, *rest = selective_scan_cuda.fwd(u, delta, A, B, C, D, z, delta_bias, delta_softplus)# 保存必要的状态以用于反向传播ctx.save_for_backward(u, delta, A, B, C, D, z, delta_bias, x)last_state = x[:, :, -1, 1::2] # 获取最后状态return out if not return_last_state else (out, last_state)@staticmethoddef backward(ctx, dout):"""反向传播函数:param ctx: 上下文对象:param dout: 上游梯度:return: 输入张量的梯度"""u, delta, A, B, C, D, z, delta_bias, x = ctx.saved_tensors# 调用CUDA实现的反向函数du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda.bwd(u, delta, A, B, C, D, z, delta_bias, dout, x, None, False)# 返回输入张量的梯度return (du, ddelta, dA, dB, dC, dD if D is not None else None, None, ddelta_bias if delta_bias is not None else None)def selective_scan_fn(u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False):"""封装选择性扫描函数的调用"""return SelectiveScanFn.apply(u, delta, A, B, C, D, z, delta_bias, delta_softplus, return_last_state)return selective_scan_fn
def selective_scan_ref(u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False):
“”"
选择性扫描的参考实现
:param u: 输入张量
:param delta: 增量张量
:param A, B, C: 权重张量
:param D: 可选的张量
:param z: 可选的张量
:param delta_bias: 可选的增量偏置
:param delta_softplus: 是否使用softplus激活
:param return_last_state: 是否返回最后状态
:return: 输出张量或输出和最后状态
“”"
# 将输入转换为浮点数
u = u.float()
delta = delta.float()
if delta_bias is not None:
delta = delta + delta_bias[…, None].float()
if delta_softplus:
delta = F.softplus(delta)
# 初始化状态
batch, dim, dstate = u.shape[0], A.shape[0], A.shape[1]
x = A.new_zeros((batch, dim, dstate))
ys = []# 计算增量和权重的乘积
deltaA = torch.exp(torch.einsum('bdl,dn->bdln', delta, A))
deltaB_u = torch.einsum('bdl,dn,bdl->bdln', delta, B, u)# 进行选择性扫描
for i in range(u.shape[2]):x = deltaA[:, :, i] * x + deltaB_u[:, :, i]y = torch.einsum('bdn,dn->bd', x, C)ys.append(y)# 将结果堆叠成张量
y = torch.stack(ys, dim=2) # (batch dim L)
out = y if D is None else y + u * rearrange(D, "d -> d 1")
if z is not None:out = out * F.silu(z)return out if not return_last_state else (out, x)
其他函数如selective_scan_easy和test_speed可以根据需要保留或删除
代码说明:
build_selective_scan_fn: 构建选择性扫描函数,支持不同的模式。内部定义了SelectiveScanFn类,包含前向和反向传播的实现。
forward: 实现前向传播,处理输入的连续性,调用CUDA实现的前向函数,并保存必要的状态以供反向传播使用。
backward: 实现反向传播,调用CUDA实现的反向函数,返回输入张量的梯度。
selective_scan_ref: 参考实现的选择性扫描,使用PyTorch的基本操作实现,适用于不使用CUDA的情况。
以上是代码的核心部分和详细注释,其他函数可以根据具体需求进行选择性保留。
这个文件 test_selective_scan_speed.py 主要是用来测试和评估选择性扫描(Selective Scan)算法的速度和性能。代码中包含了多个函数和类,主要分为几个部分。
首先,文件导入了一些必要的库,包括 torch 和 pytest,以及一些用于处理张量的库(如 einops)。这些库提供了构建和操作深度学习模型所需的基础功能。
接下来,定义了一个名为 build_selective_scan_fn 的函数,该函数接受一个 CUDA 实现的选择性扫描函数和一些参数。这个函数内部定义了一个名为 SelectiveScanFn 的类,继承自 torch.autograd.Function,用于实现选择性扫描的前向和反向传播逻辑。在 forward 方法中,输入张量会被处理并进行一系列的变换和检查,确保它们的形状和数据类型符合要求。根据不同的模式(如 mamba_ssm、sscore 等),调用相应的 CUDA 函数进行计算,并将结果返回。
backward 方法则实现了反向传播的逻辑,计算梯度并返回。这部分代码使用了条件语句来处理不同的模式和输入情况。
接下来,定义了几个选择性扫描的参考实现函数,如 selective_scan_ref 和 selective_scan_easy,这些函数实现了选择性扫描的具体算法逻辑,主要是通过张量运算来完成。它们的输入和输出格式与前面的函数相似。
文件中还定义了 test_speed 函数,用于测试不同选择性扫描实现的速度。该函数设置了一些参数,如数据类型、序列长度、批量大小等,并生成随机输入数据。然后,它会调用不同的选择性扫描实现,并记录每次运行的时间,以评估它们的性能。
最后,test_speed 函数被调用以执行速度测试。测试结果会输出到控制台,显示每个实现的前向和反向传播的耗时。
总体来说,这个文件的核心目的是实现和测试选择性扫描算法的性能,使用了 PyTorch 的自动微分功能来支持深度学习模型的训练和推理。
10.2 dynamic_snake_conv.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
class DySnakeConv(nn.Module):
def init(self, inc, ouc, k=3) -> None:
super().init()
# 初始化三个卷积层
self.conv_0 = Conv(inc, ouc, k) # 标准卷积
self.conv_x = DSConv(inc, ouc, 0, k) # 沿x轴的动态蛇形卷积
self.conv_y = DSConv(inc, ouc, 1, k) # 沿y轴的动态蛇形卷积
def forward(self, x):# 前向传播,连接三个卷积的输出return torch.cat([self.conv_0(x), self.conv_x(x), self.conv_y(x)], dim=1)
class DSConv(nn.Module):
def init(self, in_ch, out_ch, morph, kernel_size=3, if_offset=True, extend_scope=1):
“”"
动态蛇形卷积
:param in_ch: 输入通道数
:param out_ch: 输出通道数
:param kernel_size: 卷积核大小
:param extend_scope: 扩展范围(默认1)
:param morph: 卷积核的形态,分为沿x轴(0)和y轴(1)
:param if_offset: 是否需要偏移,False时为标准卷积
“”"
super(DSConv, self).init()
# 用于学习可变形偏移的卷积层
self.offset_conv = nn.Conv2d(in_ch, 2 * kernel_size, 3, padding=1)
self.bn = nn.BatchNorm2d(2 * kernel_size) # 批归一化
self.kernel_size = kernel_size
# 定义沿x轴和y轴的动态蛇形卷积self.dsc_conv_x = nn.Conv2d(in_ch,out_ch,kernel_size=(kernel_size, 1),stride=(kernel_size, 1),padding=0,)self.dsc_conv_y = nn.Conv2d(in_ch,out_ch,kernel_size=(1, kernel_size),stride=(1, kernel_size),padding=0,)self.gn = nn.GroupNorm(out_ch // 4, out_ch) # 组归一化self.act = Conv.default_act # 默认激活函数self.extend_scope = extend_scopeself.morph = morphself.if_offset = if_offsetdef forward(self, f):# 前向传播offset = self.offset_conv(f) # 计算偏移offset = self.bn(offset) # 批归一化offset = torch.tanh(offset) # 将偏移限制在[-1, 1]之间input_shape = f.shapedsc = DSC(input_shape, self.kernel_size, self.extend_scope, self.morph) # 初始化DSCdeformed_feature = dsc.deform_conv(f, offset, self.if_offset) # 进行可变形卷积# 根据形态选择相应的卷积if self.morph == 0:x = self.dsc_conv_x(deformed_feature.type(f.dtype))else:x = self.dsc_conv_y(deformed_feature.type(f.dtype))x = self.gn(x) # 组归一化x = self.act(x) # 激活函数return x
class DSC(object):
def init(self, input_shape, kernel_size, extend_scope, morph):
self.num_points = kernel_size # 卷积核的点数
self.width = input_shape[2] # 输入特征图的宽度
self.height = input_shape[3] # 输入特征图的高度
self.morph = morph # 卷积核形态
self.extend_scope = extend_scope # 偏移范围
# 定义特征图的形状self.num_batch = input_shape[0] # 批次大小self.num_channels = input_shape[1] # 通道数def deform_conv(self, input, offset, if_offset):# 进行可变形卷积y, x = self._coordinate_map_3D(offset, if_offset) # 计算坐标图deformed_feature = self._bilinear_interpolate_3D(input, y, x) # 双线性插值return deformed_featuredef _coordinate_map_3D(self, offset, if_offset):# 计算3D坐标图# 省略具体实现细节passdef _bilinear_interpolate_3D(self, input_feature, y, x):# 进行3D双线性插值# 省略具体实现细节pass
代码说明:
DySnakeConv 类是一个卷积模块,包含标准卷积和两个动态蛇形卷积(分别沿x轴和y轴)。
DSConv 类实现了动态蛇形卷积的具体逻辑,包括偏移学习和特征变形。
DSC 类负责计算坐标图和进行双线性插值,以实现可变形卷积的效果。
代码中使用了多个卷积层、批归一化和激活函数,以实现深度学习中的特征提取和变形处理。
这个程序文件 dynamic_snake_conv.py 实现了一个动态蛇形卷积(Dynamic Snake Convolution)的神经网络模块,主要用于图像处理任务。代码中定义了两个主要的类:DySnakeConv 和 DSConv,以及一个辅助类 DSC。
在 DySnakeConv 类中,构造函数初始化了三个卷积层:conv_0、conv_x 和 conv_y。其中,conv_0 是标准卷积,而 conv_x 和 conv_y 是动态蛇形卷积,分别沿着 x 轴和 y 轴进行处理。forward 方法接收输入张量 x,并将三个卷积的输出在通道维度上拼接,形成最终的输出。
DSConv 类实现了动态蛇形卷积的具体逻辑。构造函数中,定义了输入和输出通道数、卷积核大小、形态(morph)、是否使用偏移(if_offset)以及扩展范围(extend_scope)。它使用一个卷积层 offset_conv 来学习偏移量,并定义了两个卷积层 dsc_conv_x 和 dsc_conv_y,分别用于处理 x 轴和 y 轴的动态卷积。forward 方法中,首先通过 offset_conv 计算偏移量,然后使用 DSC 类生成的坐标图进行变形卷积,最后通过相应的卷积层、归一化和激活函数处理得到输出。
DSC 类负责生成坐标图和进行双线性插值。它的构造函数接收输入形状、卷积核大小、扩展范围和形态。_coordinate_map_3D 方法根据偏移量生成新的坐标图,支持动态调整。_bilinear_interpolate_3D 方法实现了对输入特征图的双线性插值,生成变形后的特征图。deform_conv 方法则将上述两个步骤结合,完成动态卷积的核心操作。
整体来看,这个文件实现了一个灵活的卷积模块,能够根据输入特征图的特征动态调整卷积核的位置和形状,从而提高模型对图像特征的捕捉能力。
10.3 kaln_conv.py
以下是代码中最核心的部分,并附上详细的中文注释:
from functools import lru_cache
import torch
import torch.nn as nn
from torch.nn.functional import conv3d, conv2d, conv1d
class KALNConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, conv_w_fun, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1, dropout: float = 0.0, ndim: int = 2):
super(KALNConvNDLayer, self).init()
# 初始化参数self.inputdim = input_dim # 输入维度self.outdim = output_dim # 输出维度self.degree = degree # 多项式的阶数self.kernel_size = kernel_size # 卷积核大小self.padding = padding # 填充self.stride = stride # 步幅self.dilation = dilation # 膨胀self.groups = groups # 分组卷积的组数self.base_activation = nn.SiLU() # 基础激活函数self.conv_w_fun = conv_w_fun # 卷积权重函数self.ndim = ndim # 数据的维度(1D, 2D, 3D)self.dropout = None # Dropout层# 根据维度初始化Dropout层if dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 检查参数的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 创建分组卷积层self.base_conv = nn.ModuleList([conv_class(input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 创建分组归一化层self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 初始化多项式权重poly_shape = (groups, output_dim // groups, (input_dim // groups) * (degree + 1)) + tuple(kernel_size for _ in range(ndim))self.poly_weights = nn.Parameter(torch.randn(*poly_shape))# 使用Kaiming均匀分布初始化卷积层和多项式权重for conv_layer in self.base_conv:nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')nn.init.kaiming_uniform_(self.poly_weights, nonlinearity='linear')@lru_cache(maxsize=128) # 使用LRU缓存以避免重复计算Legendre多项式
def compute_legendre_polynomials(self, x, order):# 计算Legendre多项式P0 = x.new_ones(x.shape) # P0 = 1if order == 0:return P0.unsqueeze(-1)P1 = x # P1 = xlegendre_polys = [P0, P1]# 使用递推公式计算更高阶的多项式for n in range(1, order):Pn = ((2.0 * n + 1.0) * x * legendre_polys[-1] - n * legendre_polys[-2]) / (n + 1.0)legendre_polys.append(Pn)return torch.concatenate(legendre_polys, dim=1)def forward_kal(self, x, group_index):# 前向传播,计算基于卷积和多项式的输出base_output = self.base_conv[group_index](x) # 基础卷积输出# 归一化输入x到[-1, 1]范围x_normalized = 2 * (x - x.min()) / (x.max() - x.min()) - 1 if x.shape[0] > 0 else x# 应用Dropoutif self.dropout is not None:x_normalized = self.dropout(x_normalized)# 计算Legendre多项式legendre_basis = self.compute_legendre_polynomials(x_normalized, self.degree)# 使用多项式权重进行卷积poly_output = self.conv_w_fun(legendre_basis, self.poly_weights[group_index],stride=self.stride, dilation=self.dilation,padding=self.padding, groups=1)# 合并基础输出和多项式输出x = base_output + poly_output# 归一化和激活if isinstance(self.layer_norm[group_index], nn.LayerNorm):orig_shape = x.shapex = self.layer_norm[group_index](x.view(orig_shape[0], -1)).view(orig_shape)else:x = self.layer_norm[group_index](x)x = self.base_activation(x)return xdef forward(self, x):# 前向传播,处理输入xsplit_x = torch.split(x, self.inputdim // self.groups, dim=1) # 按组分割输入output = []for group_ind, _x in enumerate(split_x):y = self.forward_kal(_x.clone(), group_ind) # 计算每组的输出output.append(y.clone())y = torch.cat(output, dim=1) # 合并所有组的输出return y
代码说明
KALNConvNDLayer类:这是一个通用的N维卷积层,支持1D、2D和3D卷积。它可以根据输入参数动态创建卷积层和归一化层。
初始化方法:设置卷积层、归一化层和多项式权重,并进行必要的参数检查。
compute_legendre_polynomials方法:计算Legendre多项式,使用LRU缓存以提高效率。
forward_kal方法:实现前向传播逻辑,计算基础卷积输出和多项式输出,并进行归一化和激活。
forward方法:处理输入数据,按组进行分割,并调用forward_kal进行计算,最后合并输出。
这个程序文件定义了一个名为 KALNConvNDLayer 的神经网络层及其变体,主要用于实现基于 Legendre 多项式的卷积操作。该层可以处理不同维度的数据(1D、2D、3D),并且具有可调的参数以适应不同的应用场景。
首先,KALNConvNDLayer 类的构造函数接受多个参数,包括卷积类型、归一化类型、输入和输出维度、卷积核大小、分组数、填充、步幅、扩张、丢弃率等。构造函数中对输入参数进行了有效性检查,确保分组数和输入输出维度的合理性。接着,它创建了多个基础卷积层和归一化层,并初始化了多项式权重,使用 Kaiming 均匀分布来提高训练的起始效果。
该类还定义了一个缓存的函数 compute_legendre_polynomials,用于计算 Legendre 多项式。这个函数使用递归关系生成多项式,并通过缓存机制避免重复计算,从而提高效率。
在前向传播方法 forward_kal 中,首先对输入进行基础卷积操作,然后将输入归一化到 [-1, 1] 的范围,以便于计算 Legendre 多项式。接着,计算归一化后的输入的 Legendre 多项式,并使用多项式权重进行线性变换。最后,将基础卷积输出和多项式输出相加,经过归一化和激活函数处理后返回结果。
forward 方法将输入数据按照分组进行拆分,并对每个分组调用 forward_kal 方法进行处理,最后将所有分组的输出拼接在一起。
此外,文件中还定义了三个类 KALNConv3DLayer、KALNConv2DLayer 和 KALNConv1DLayer,分别继承自 KALNConvNDLayer,用于实现 3D、2D 和 1D 的卷积层。这些类在初始化时调用父类构造函数,传入相应的卷积和归一化类型,简化了不同维度卷积层的创建过程。
整体而言,这个程序文件提供了一种灵活的方式来实现基于 Legendre 多项式的卷积操作,适用于多种维度的数据处理,具有良好的扩展性和可配置性。
10.4 dyhead_prune.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DyReLU(nn.Module):
“”"
动态ReLU激活函数模块,能够根据输入动态调整激活值。
“”"
def __init__(self, inp, reduction=4, lambda_a=1.0, K2=True, use_bias=True, use_spatial=False,init_a=[1.0, 0.0], init_b=[0.0, 0.0]):super(DyReLU, self).__init__()self.oup = inp # 输出通道数self.lambda_a = lambda_a * 2 # 动态调整参数self.K2 = K2 # 是否使用K2self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化层self.use_bias = use_bias # 是否使用偏置if K2:self.exp = 4 if use_bias else 2 # 根据是否使用偏置设置exp值else:self.exp = 2 if use_bias else 1# 确定压缩比例squeeze = inp // reduction if reduction == 4 else _make_divisible(inp // reduction, 4)# 定义全连接层self.fc = nn.Sequential(nn.Linear(inp, squeeze), # 第一个全连接层nn.ReLU(inplace=True), # ReLU激活nn.Linear(squeeze, self.oup * self.exp), # 第二个全连接层h_sigmoid() # 使用h_sigmoid激活)# 如果使用空间注意力机制,定义相应的卷积层self.spa = nn.Sequential(nn.Conv2d(inp, 1, kernel_size=1), # 1x1卷积nn.BatchNorm2d(1), # 批归一化) if use_spatial else Nonedef forward(self, x):"""前向传播函数"""# 处理输入x_in = x[0] if isinstance(x, list) else xx_out = x[1] if isinstance(x, list) else xb, c, h, w = x_in.size() # 获取输入的尺寸# 通过平均池化层获取特征y = self.avg_pool(x_in).view(b, c)y = self.fc(y).view(b, self.oup * self.exp, 1, 1) # 通过全连接层# 根据exp值计算输出if self.exp == 4:a1, b1, a2, b2 = torch.split(y, self.oup, dim=1)a1 = (a1 - 0.5) * self.lambda_a + self.init_a[0] # 动态调整a1a2 = (a2 - 0.5) * self.lambda_a + self.init_a[1]b1 = b1 - 0.5 + self.init_b[0]b2 = b2 - 0.5 + self.init_b[1]out = torch.max(x_out * a1 + b1, x_out * a2 + b2) # 计算输出elif self.exp == 2:if self.use_bias:a1, b1 = torch.split(y, self.oup, dim=1)a1 = (a1 - 0.5) * self.lambda_a + self.init_a[0]b1 = b1 - 0.5 + self.init_b[0]out = x_out * a1 + b1else:a1, a2 = torch.split(y, self.oup, dim=1)a1 = (a1 - 0.5) * self.lambda_a + self.init_a[0]a2 = (a2 - 0.5) * self.lambda_a + self.init_a[1]out = torch.max(x_out * a1, x_out * a2)elif self.exp == 1:a1 = ya1 = (a1 - 0.5) * self.lambda_a + self.init_a[0]out = x_out * a1# 如果使用空间注意力机制,计算空间注意力if self.spa:ys = self.spa(x_in).view(b, -1)ys = F.softmax(ys, dim=1).view(b, 1, h, w) * h * wys = F.hardtanh(ys, 0, 3, inplace=True) / 3out = out * ys # 加入空间注意力return out # 返回最终输出
class DyDCNv2(nn.Module):
“”"
带有归一化层的可调变形卷积模块,主要用于DyHead。
“”"
def __init__(self, in_channels, out_channels, stride=1, norm_cfg=dict(type='GN', num_groups=16, requires_grad=True)):super().__init__()self.with_norm = norm_cfg is not None # 是否使用归一化bias = not self.with_norm # 根据是否使用归一化决定是否使用偏置self.conv = ModulatedDeformConv2d(in_channels, out_channels, 3, stride=stride, padding=1, bias=bias) # 定义可调变形卷积if self.with_norm:self.norm = build_norm_layer(norm_cfg, out_channels)[1] # 构建归一化层def forward(self, x, offset, mask):"""前向传播函数"""x = self.conv(x.contiguous(), offset, mask) # 进行卷积操作if self.with_norm:x = self.norm(x) # 如果使用归一化,进行归一化处理return x # 返回输出
class DyHeadBlock_Prune(nn.Module):
“”"
DyHead模块,包含三种类型的注意力机制。
“”"
def __init__(self, in_channels, norm_type='GN', zero_init_offset=True,act_cfg=dict(type='HSigmoid', bias=3.0, divisor=6.0)):super().__init__()self.zero_init_offset = zero_init_offset # 是否初始化偏移为零self.offset_and_mask_dim = 3 * 3 * 3 # 偏移和掩码的维度self.offset_dim = 2 * 3 * 3 # 偏移的维度# 根据归一化类型选择归一化配置norm_dict = dict(type='GN', num_groups=16, requires_grad=True) if norm_type == 'GN' else dict(type='BN', requires_grad=True)# 定义三个不同的空间卷积模块self.spatial_conv_high = DyDCNv2(in_channels, in_channels, norm_cfg=norm_dict)self.spatial_conv_mid = DyDCNv2(in_channels, in_channels)self.spatial_conv_low = DyDCNv2(in_channels, in_channels, stride=2)# 定义偏移和掩码的卷积层self.spatial_conv_offset = nn.Conv2d(in_channels, self.offset_and_mask_dim, 3, padding=1)# 定义尺度注意力模块self.scale_attn_module = nn.Sequential(nn.AdaptiveAvgPool2d(1), # 自适应平均池化nn.Conv2d(in_channels, 1, 1), # 1x1卷积nn.ReLU(inplace=True), # ReLU激活build_activation_layer(act_cfg) # 构建激活层)self.task_attn_module = DyReLU(in_channels) # 任务注意力模块self._init_weights() # 初始化权重def _init_weights(self):"""权重初始化函数"""for m in self.modules():if isinstance(m, nn.Conv2d):normal_init(m, 0, 0.01) # 正态初始化卷积层if self.zero_init_offset:constant_init(self.spatial_conv_offset, 0) # 初始化偏移为零def forward(self, x, level):"""前向传播函数"""# 计算DCNv2的偏移和掩码offset_and_mask = self.spatial_conv_offset(x[level])offset = offset_and_mask[:, :self.offset_dim, :, :] # 提取偏移mask = offset_and_mask[:, self.offset_dim:, :, :].sigmoid() # 提取掩码并进行sigmoid处理mid_feat = self.spatial_conv_mid(x[level], offset, mask) # 中间特征sum_feat = mid_feat * self.scale_attn_module(mid_feat) # 加权特征summed_levels = 1 # 记录已求和的层数# 如果有低层特征,进行处理if level > 0:low_feat = self.spatial_conv_low(x[level - 1], offset, mask)sum_feat += low_feat * self.scale_attn_module(low_feat)summed_levels += 1# 如果有高层特征,进行处理if level < len(x) - 1:high_feat = F.interpolate(self.spatial_conv_high(x[level + 1], offset, mask),size=x[level].shape[-2:],mode='bilinear',align_corners=True)sum_feat += high_feat * self.scale_attn_module(high_feat)summed_levels += 1return self.task_attn_module(sum_feat / summed_levels) # 返回最终的任务注意力输出
以上代码主要实现了动态激活函数和可调变形卷积模块,结合注意力机制,能够在深度学习模型中提高特征提取的灵活性和有效性。
这个程序文件 dyhead_prune.py 是一个用于深度学习的 PyTorch 模块,主要实现了动态头(Dynamic Head)中的一些组件,特别是与注意力机制和卷积操作相关的部分。以下是对代码的详细讲解。
首先,文件导入了必要的库,包括 PyTorch 和一些深度学习相关的模块。接着,定义了一个辅助函数 _make_divisible,用于确保某个值能够被指定的除数整除,同时还考虑了最小值的限制。这在构建神经网络时,通常用于调整通道数等参数,以便与硬件资源相匹配。
接下来,定义了几个激活函数类,包括 swish、h_swish 和 h_sigmoid。这些类继承自 nn.Module,并实现了相应的前向传播方法。swish 是一种新的激活函数,h_swish 和 h_sigmoid 则是对 ReLU 和 Sigmoid 的改进版本,适用于特定的网络结构。
DyReLU 类是一个动态激活函数模块,它根据输入的特征图动态调整激活值。该模块的构造函数接受多个参数,包括输入通道数、缩减比例、初始化参数等。它使用全连接层来计算激活系数,并可以选择性地使用空间注意力机制。前向传播方法中,首先对输入进行池化,然后通过全连接层计算出动态参数,最后根据这些参数调整输入特征图的输出。
DyDCNv2 类实现了带有归一化层的可调变形卷积(Modulated Deformable Convolution),它使用了 ModulatedDeformConv2d,并根据需要添加了归一化层。前向传播方法中,输入特征图与偏移量和掩码一起传递,以计算输出。
DyHeadBlock_Prune 类是动态头的一个模块,结合了多种注意力机制。它的构造函数中定义了多个卷积层和注意力模块,初始化权重时采用了正态分布。前向传播方法中,首先计算偏移量和掩码,然后通过不同的卷积层处理输入特征图,最后结合多层特征图的输出,使用任务注意力模块进行最终的特征融合。
整体来看,这个文件实现了动态头的关键组件,利用动态激活函数和可调变形卷积来增强模型的表达能力,适用于复杂的视觉任务。通过引入注意力机制,模型能够更好地关注输入特征中的重要部分,从而提高性能。
注意:由于此博客编辑较早,上面“10.YOLOv11核心改进源码讲解”中部分代码可能会优化升级,仅供参考学习,以“11.完整训练+Web前端界面+200+种全套创新点源码、数据集获取”的内容为准。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻