k8s(十一)HPA部署与使用
文章目录
- 前言
- 一、什么是HPA?
- 二、什么要使用HPA?
- 三、HPA 的核心功能:
- ----------------------------------------------------------------------------------------------------------------------------------
- 一、Kubernetes HPA
- 1.1 HPA 核心原理与依赖组件
- 1.1.1 HPA 工作原理
- 1.1.2 关键依赖组件:metrics-server
- 1.2 metrics-server 部署步骤
- 1.2.1 镜像准备(所有 Node 节点执行)
- 1.2.2 Helm 配置与安装
- 1.2.3 执行安装与验证
- 1.3 HPA 部署与功能测试
- 1.3.1 准备测试镜像与资源(所有节点执行)
- 1.3.2 创建测试 Deployment 与 Service
- 1.3.3 创建 HPA 控制器
- 1.3.4 测试 HPA 自动伸缩功能
- 步骤 1:创建测试客户端并增加负载
- 步骤 2:观察 HPA 伸缩过程
- 步骤 3:验证 Pod 数量变化
- 步骤 4:高性能 CPU 环境的补充测试
- 1.3.5 HPA 伸缩特性说明
- 1.3.7 HPA 基于内存利用率的伸缩配置与实践
- 1.3.7.1 核心逻辑与前提条件
- 1.3.7.2 实操步骤
- 步骤 1:配置 Pod 内存请求
- 步骤 2:创建 HPA 控制器
- 场景 1:仅内存伸缩
- 场景 2:CPU+内存混合伸缩
- 步骤 3:验证与测试
- 1.3.7.3 参数优化(防频繁伸缩)
- 1.3.7.4 生产注意事项
- 1.4 Kubernetes 资源限制配置
- 1.4.1 Pod 级资源限制
- 1.4.1.1 核心参数说明
- 1.4.1.2 配置示例
- 1.4.2 命名空间级资源限制
- 1.4.2.1 计算资源配额
- 1.4.2.2 对象数量配额
- 1.4.3 默认资源限制(LimitRange)
- 1.4.3.1 配置示例
- 1.4.3.2 资源限制优先级说明
- 总结
前言
一、什么是HPA?
在 Kubernetes(k8s)中,HPA 是 Horizontal Pod Autoscaler(水平 Pod 自动扩缩器) 的缩写,它是 k8s 提供的一种自动扩缩容机制,用于根据监控指标(如 CPU 利用率、内存使用率,或自定义指标)动态调整 Deployment、StatefulSet 等工作负载的 Pod 数量。
二、什么要使用HPA?
-
保障服务稳定性
当流量突发增长(如秒杀、活动峰值)时,HPA 能快速扩容 Pod 数量,避免因资源不足导致服务响应变慢或崩溃,确保服务持续可用。 -
提高资源利用率
当流量低谷时,HPA 会自动缩容多余的 Pod,释放 CPU、内存等资源,避免资源浪费,降低集群运行成本(尤其对云环境按资源计费的场景更重要)。 -
减少人工操作成本
传统方式需要人工根据负载手动调整 Pod 数量,效率低且易出错。HPA 实现了完全自动化,解放运维人力,尤其适合大规模集群或动态变化的业务场景。 -
适配业务动态变化
对于流量波动频繁的应用(如电商、社交平台),HPA 能实时响应负载变化,无需提前预估资源需求,灵活性更高。
三、HPA 的核心功能:
当业务负载增加时,HPA 会自动增加 Pod 数量以应对更高的请求压力;当负载降低时,HPA 会自动减少 Pod 数量以节省资源。整个过程无需人工干预,完全由 k8s 集群自动完成。
----------------------------------------------------------------------------------------------------------------------------------
一、Kubernetes HPA
HPA(Horizontal Pod Autoscaling,Pod 水平自动伸缩)是 Kubernetes 中实现 Pod 数量动态调整的核心功能,能基于 CPU 利用率自动伸缩 Replication Controller、Deployment 或 Replica Set 中的 Pod 数量,有效提升集群资源利用率与业务稳定性。
1.1 HPA 核心原理与依赖组件
要顺利部署 HPA,需先理解其工作机制与核心依赖,这是确保后续部署成功的基础。
1.1.1 HPA 工作原理
HPA 的自动伸缩能力基于以下核心逻辑实现:
- 周期性检测:依赖 Master 节点上
kube-controller-manager服务的启动参数horizontal-pod-autoscaler-sync-period(默认 30 秒),周期性检测目标 Pod 的 CPU 使用率。 - 资源对象属性:HPA 本身是 Kubernetes 资源对象,与 RC、Deployment 类似,通过追踪分析目标控制器(如 Deployment)管理的所有 Pod 负载变化,判断是否需要调整 Pod 副本数。
- 数据依赖:需依赖
metrics-server提供的 CPU 等度量数据,无法直接采集 Pod 资源使用情况。
1.1.2 关键依赖组件:metrics-server
metrics-server 是 Kubernetes 集群资源使用情况的聚合器,负责收集节点与 Pod 的资源数据(如 CPU、内存使用率),并通过 resource metrics API 对外提供,供 kubectl top、HPA、scheduler 等组件使用,是 HPA 实现伸缩的“数据来源”。
1.2 metrics-server 部署步骤
部署 HPA 前需先部署 metrics-server,以下是完整操作流程,包含镜像准备、Helm 配置与安装验证。
1.2.1 镜像准备(所有 Node 节点执行)
metrics-server 运行依赖镜像,需先在所有 Node 节点加载本地镜像(避免在线拉取失败):
# 1. 切换到镜像存放目录(需提前将 metrics-server.tar 上传至 /opt 目录)
cd /opt/
# 2. 加载本地镜像
docker load -i metrics-server.tar
1.2.2 Helm 配置与安装
Helm 是 Kubernetes 的包管理工具,通过 Helm 安装 metrics-server 可简化配置流程,需注意仓库地址与配置文件的正确性:
# 1. 创建 metrics-server 工作目录
mkdir /opt/metrics
cd /opt/metrics# 2. 配置 Helm 仓库(移除旧 stable 仓库,添加可用仓库)
helm repo remove stable
# 方式一:添加官方 stable 仓库(国内可能访问缓慢,建议用方式二)
helm repo add stable https://charts.helm.sh/stable
# 方式二:添加国内镜像仓库(推荐,解决访问超时问题)
helm repo add stable http://mirror.azure.cn/kubernetes/charts# 3. 更新 Helm 仓库索引,确保获取最新包信息
helm repo update# 4. 拉取 metrics-server Helm 包(可选,用于查看配置模板)
helm pull stable/metrics-server# 5. 创建自定义配置文件 metrics-server.yaml,解决证书与地址解析问题
vim metrics-server.yaml
metrics-server.yaml 配置内容(关键参数需按如下设置,否则可能无法正常采集数据):
args:
- --logtostderr # 日志输出到标准错误流,便于排查问题
- --kubelet-insecure-tls # 跳过 kubelet 证书验证(测试环境可用,生产环境需配置合法证书)
- --kubelet-preferred-address-types=InternalIP # 优先使用节点内网 IP 访问 kubelet,避免 DNS 解析问题
image:repository: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server # 镜像仓库地址tag: v0.6.4 # 镜像版本
1.2.3 执行安装与验证
# 1. 使用 Helm 安装 metrics-server,指定命名空间为 kube-system(系统组件推荐放此命名空间)
helm install metrics-server stable/metrics-server -n kube-system -f metrics-server.yaml# 2. 查看 metrics-server Pod 运行状态(确保 STATUS 为 Running)
kubectl get pods -n kube-system | grep metrics-server# 3. 验证 metrics-server 功能(需等待 1-2 分钟,让数据采集生效)
# 查看节点资源使用情况
kubectl top node
# 查看所有命名空间 Pod 资源使用情况
kubectl top pods --all-namespaces


如果出现running但是kubectl top node却没有数据
并且使用kubectl logs -n kube-system metrics-server-xxx --tail=200 | grep -i scrape看到的都是以下提示:

可以尝试在所有节点上进行:
vim /var/lib/kubelet/config.yaml
#将anonymous.enabled: 改为true
systemctl restart kubelet
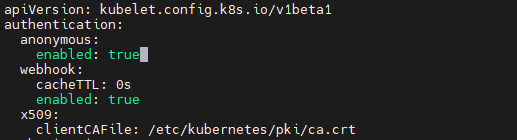
然后删除当前 metrics-server Pod,让 Deployment 重建
kubectl delete pod -n kube-system $(kubectl get pods -n kube-system | grep metrics-server | awk '{print $1}')
metrics-server 默认不带认证信息,请求会被当成匿名的;anonymous.enabled: false 会直接拦了匿名请求,true 则允许匿名请求通过身份验证,再加上原先配好的权限,就能正常采集数据了。
1.3 HPA 部署与功能测试
metrics-server 正常运行后,即可部署 HPA 并测试其自动伸缩功能,以下是完整流程。
1.3.1 准备测试镜像与资源(所有节点执行)
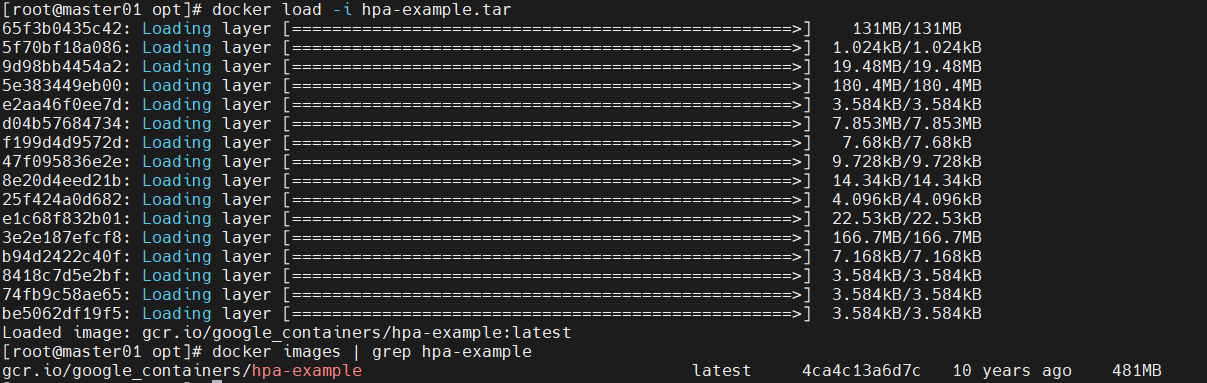
HPA 测试需使用包含 CPU 密集计算代码的镜像,文档提供 hpa-example.tar(谷歌基于 PHP 开发的测试镜像),需先在所有 Node 节点加载:
# 1. 切换到镜像存放目录(提前将 hpa-example.tar 上传至 /opt 目录)
cd /opt
# 2. 加载本地镜像
docker load -i hpa-example.tar
# 3. 验证镜像是否加载成功
docker images | grep hpa-example
1.3.2 创建测试 Deployment 与 Service
需先创建待伸缩的 Deployment(运行 hpa-example 镜像)与对应的 Service(供测试访问),并设置 CPU 请求资源(HPA 基于请求资源计算利用率):
# 1. 创建配置文件 hpa-pod.yaml
vim hpa-pod.yaml
hpa-pod.yaml 配置内容:
apiVersion: apps/v1
kind: Deployment
metadata:labels:run: php-apache # Deployment 标签,用于关联 Service 与 HPAname: php-apache # Deployment 名称
spec:replicas: 1 # 初始 Pod 副本数selector:matchLabels:run: php-apache # 匹配 Pod 标签template:metadata:labels:run: php-apache # Pod 标签,需与 selector 一致spec:containers:- image: gcr.io/google_containers/hpa-example # 测试镜像(国内需替换为镜像仓库,如阿里云镜像)registry.aliyuncs.com/google_containers/hpa-examplename: php-apache # 容器名称imagePullPolicy: IfNotPresent # 优先使用本地镜像,避免重复拉取ports:- containerPort: 80 # 容器暴露端口(与 Service 对应)resources:requests:cpu: 200m # CPU 请求资源(HPA 计算利用率的基准,必须设置,否则 HPA 无法工作)
---
# 配套 Service,用于测试客户端访问 Pod
apiVersion: v1
kind: Service
metadata:name: php-apache # Service 名称
spec:ports:- port: 80 # Service 暴露端口protocol: TCP # 协议类型targetPort: 80 # 映射到 Pod 的端口(与容器暴露端口一致)selector:run: php-apache # 匹配 Pod 标签,关联 Deployment 管理的 Pod
# 2. 应用配置文件,创建 Deployment 与 Service
kubectl apply -f hpa-pod.yaml# 3. 验证 Deployment 运行状态(确保 Pod 为 Running)
kubectl get pods
# 预期输出(Pod 名称后缀会不同):
# NAME READY STATUS RESTARTS AGE
# php-apache-799f99c985-5j5b4 1/1 Running 0 26s
1.3.3 创建 HPA 控制器
通过 kubectl autoscale 命令创建 HPA,指定伸缩规则(CPU 阈值、副本数范围):
# 创建 HPA,关联 php-apache Deployment
# --cpu-percent=50:CPU 利用率阈值为 50%(基于 Deployment 中 Pod 的 CPU 请求资源计算)
# --min=1:最小 Pod 副本数为 1
# --max=10:最大 Pod 副本数为 10
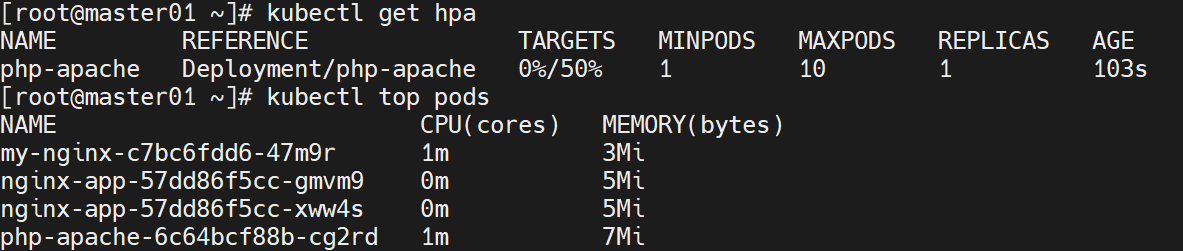
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10# 查看 HPA 状态(需等待 1-2 分钟,让 metrics-server 采集数据,TARGETS 列显示利用率)
kubectl get hpa# 验证 Pod 资源使用情况(初始 CPU 使用率为 0m)
kubectl top pods
1.3.4 测试 HPA 自动伸缩功能
通过创建测试客户端增加 Pod 负载,观察 HPA 是否自动调整 Pod 副本数:
步骤 1:创建测试客户端并增加负载
# 1. 创建 busybox 客户端容器(交互式终端)
kubectl run -it load-generator --image=busybox /bin/sh# 2. 在客户端容器内执行循环请求,增加 php-apache Pod 的 CPU 负载
# while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
# 说明:http://php-apache.default.svc.cluster.local 是 Service 的集群内访问地址,格式为「Service 名称.命名空间.svc.cluster.local」
步骤 2:观察 HPA 伸缩过程
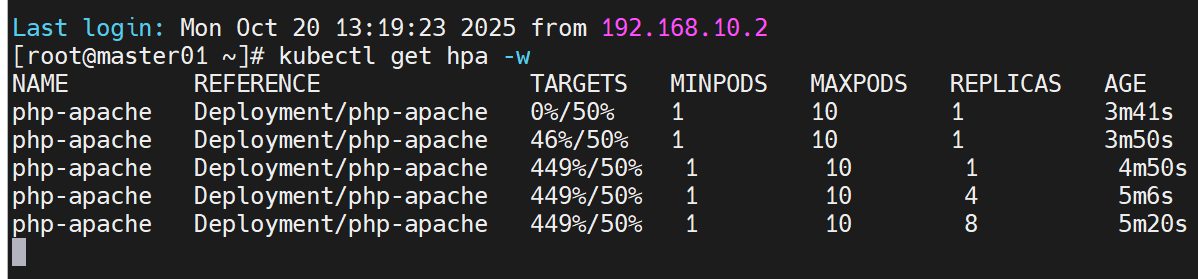
打开新的终端窗口,执行以下命令实时查看 HPA 状态变化:
# -w 参数:实时监控 HPA 状态
kubectl get hpa -w
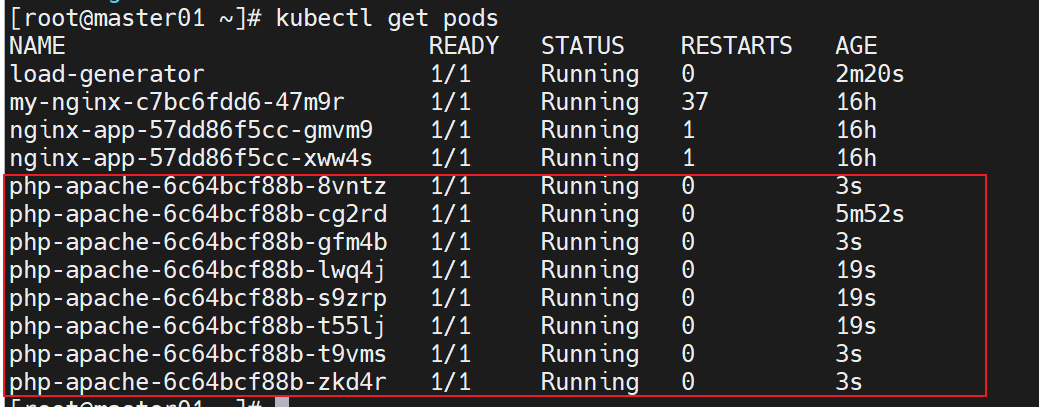
步骤 3:验证 Pod 数量变化
# 查看所有 Pod 状态,确认 php-apache Pod 数量已增加到 10 个
kubectl get pods
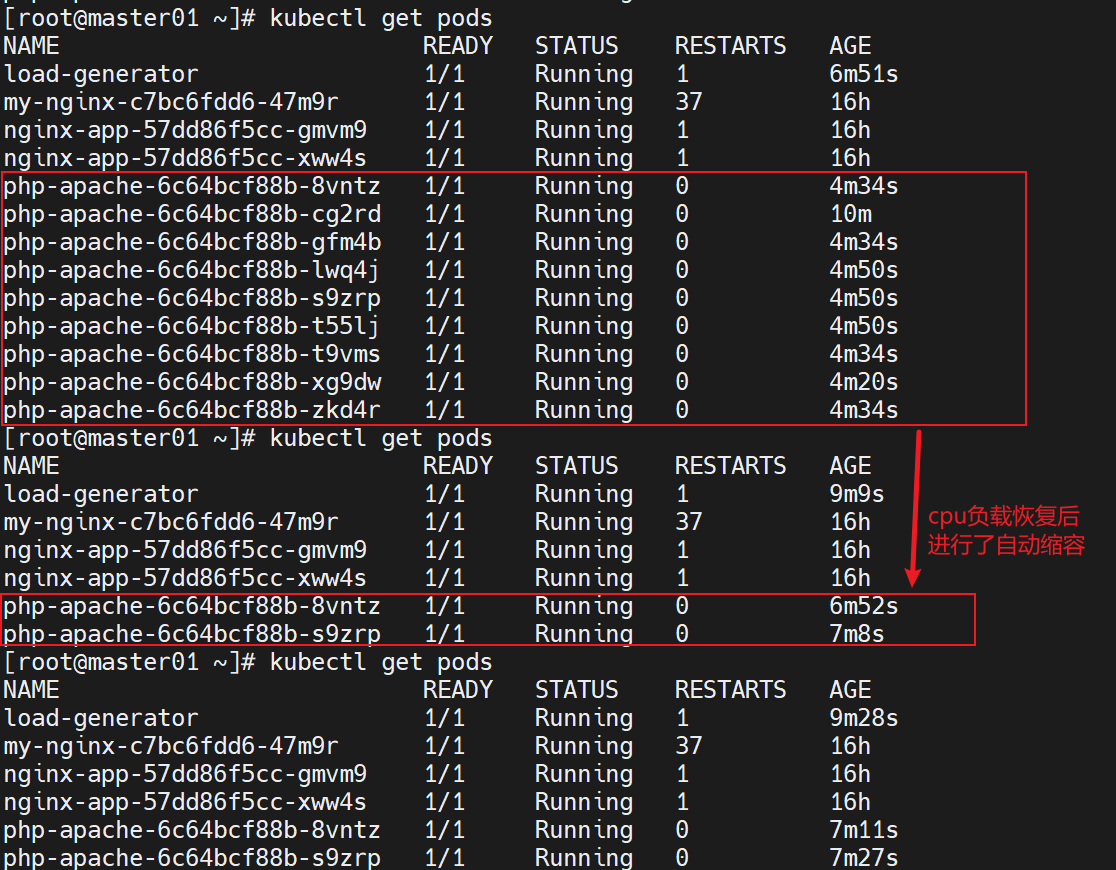
cpu负载下降后,php-apache的pod数量会自动下降

步骤 4:高性能 CPU 环境的补充测试
若节点 CPU 性能较好,单客户端负载无法使 CPU 利用率超过阈值,可再创建一个测试客户端:
# 创建第二个测试客户端
kubectl run -i --tty load-generator1 --image=busybox /bin/sh
# 执行相同的循环请求命令,增加负载
# while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
1.3.5 HPA 伸缩特性说明
HPA 的伸缩行为存在“非对称”特性:
- 扩容快:当 CPU 利用率超过阈值时,Pod 副本数会快速增加,确保业务能及时应对高负载。
- 缩容慢:当 CPU 利用率下降到阈值以下时,Pod 副本数会缓慢减少(而非立即收缩)。
- 原因:防止业务高峰期因网络波动、请求突发等情况导致负载骤升,若快速缩容,剩余 Pod 可能因无法承受高负载而崩溃,影响业务可用性。
1.3.7 HPA 基于内存利用率的伸缩配置与实践
对于数据库、缓存、大数据处理等内存密集型应用,内存占用率是影响稳定性的核心指标(如 Redis 内存不足导致数据淘汰、Elasticsearch 内存溢出触发 OOM)。因此,基于内存利用率配置 HPA 伸缩,是此类应用的关键保障。以下从核心逻辑、实操步骤、参数优化、注意事项四方面,精简梳理配置方案。
1.3.7.1 核心逻辑与前提条件
核心逻辑
- 计算基准:内存利用率 =(Pod 实际内存使用 / Pod 的
resources.requests.memory)× 100%(不基于limits.memory,避免 OOM 风险)。 - 伸缩触发:与 CPU 共享检测周期(默认 30 秒),内存利用率超阈值则扩容(分摊负载),低于阈值则缓慢缩容(防波动)。
前提条件
metrics-server正常运行,能采集 Pod 内存数据(通过kubectl top pods验证)。- Pod 必须配置
requests.memory(无此参数则 HPA 无法计算利用率,显示unknown)。 limits.memory需预留波动空间(建议设为requests.memory的 1.5-2 倍,避免内存骤升触发 OOM)。
1.3.7.2 实操步骤
步骤 1:配置 Pod 内存请求
为待伸缩的 Deployment 补充 requests.memory(以 php-apache 为例):
spec:containers:- image: registry.aliyuncs.com/google_containers/hpa-examplename: php-apacheresources:requests:cpu: 200mmemory: 256Mi # 内存计算基准,必须配置limits:memory: 512Mi # 预留波动空间
应用配置:kubectl apply -f hpa-pod.yaml
步骤 2:创建 HPA 控制器
支持“仅内存伸缩”和“CPU+内存混合伸缩”(生产推荐混合,覆盖更多场景):
场景 1:仅内存伸缩
kubectl autoscale deployment php-apache \
--memory-percent=80 # 内存阈值80% \
--min=2 --max=15 # 副本数范围
场景 2:CPU+内存混合伸缩
kubectl autoscale deployment php-apache \
--cpu-percent=50 --memory-percent=80 # 双阈值(任一超阈值即扩容)\
--min=2 --max=15
步骤 3:验证与测试
- 查看 HPA 状态(
TARGETS显示“当前利用率/阈值”):kubectl get hpa php-apache # 预期输出:TARGETS 列如 20%/50%,30%/80% - 模拟内存负载(进入 Pod 安装
stress工具):kubectl exec -it <pod-name> -- bash apt install -y stress && stress --vm 1 --vm-bytes 200Mi & # 占用200Mi内存 - 实时观察伸缩:
kubectl get hpa php-apache -w,内存超 80% 后副本数会逐步增加。
1.3.7.3 参数优化(防频繁伸缩)
- 阈值设置:内存密集型应用建议 70%-85%(平缓增长设 80%-85%,突发增长设 70%-75%)。
- 缩容延迟:通过注解避免“缩容后内存反弹”:
kubectl edit hpa php-apache metadata:annotations:# 扩容/删除/失败后,300秒内不允许缩容horizontal-pod-autoscaler.scale-down-delay-after-add: "300s"horizontal-pod-autoscaler.scale-down-delay-after-delete: "300s" - 副本数范围:
- 最小副本数:2-3 个(防单 Pod 故障,减少冷启动延迟)。
- 最大副本数:≤(集群可用内存总量 / 单 Pod requests.memory)× 0.8(预留资源)。
1.3.7.4 生产注意事项
- 不依赖
limits.memory计算利用率,避免阈值误判。 - 内存增长快的应用,可将 HPA 检测周期(
horizontal-pod-autoscaler-sync-period)调为 15 秒(需重启kube-controller-manager)。 - 监控异常:通过 Prometheus 监控“伸缩失败”“OOM 重启”“缩容反弹”,及时调整配置。
- 复杂场景可结合 VPA(垂直伸缩):VPA 动态调整
requests.memory,HPA 基于调整后的值实现更精准伸缩。
1.4 Kubernetes 资源限制配置
Kubernetes 通过资源限制防止单个 Pod 或命名空间过度占用资源,保障集群稳定性,主要分为 Pod 级限制与命名空间级限制。
1.4.1 Pod 级资源限制
Kubernetes 基于 cgroup(控制组)实现资源限制,cgroup 是容器的一组内核属性集合,可控制 CPU、内存、设备等资源的使用。默认情况下,Pod 无 CPU 和内存限额,可能导致资源滥用,需通过 resources 的 requests 和 limits 配置限制。
1.4.1.1 核心参数说明
requests:Pod 创建时初始分配的资源(集群会确保节点有足够资源满足requests后才调度 Pod),是 HPA 计算 CPU/内存利用率的基准。limits:Pod 可使用的最大资源值,若超过内存limits,cgroup 会触发 OOM(内存溢出)杀死 Pod;若超过 CPUlimits,Pod 会被限制 CPU 使用( throttled),但不会被杀死。
1.4.1.2 配置示例
spec:containers:- image: xxxx # 业务镜像地址imagePullPolicy: IfNotPresent # 优先使用本地镜像name: auth # 容器名称ports:- containerPort: 8080 # 容器暴露端口protocol: TCPresources:limits: # 资源上限cpu: "2" # 最大 CPU 核心数(2 表示 2 核)memory: 1Gi # 最大内存(1Gi = 1024Mi)requests: # 初始分配资源cpu: 250m # 250 毫核(1 核 = 1000m)memory: 250Mi # 250 兆内存
1.4.2 命名空间级资源限制
当多个团队或业务共享集群时,需为命名空间配置资源配额,防止单个命名空间占用过多集群资源,主要分为“计算资源配额”与“对象数量配额”。
1.4.2.1 计算资源配额
限制命名空间内所有 Pod 的 CPU、内存总使用量,配置示例:
apiVersion: v1
kind: ResourceQuota # 资源类型为 ResourceQuota
metadata:name: compute-resources # 配额名称namespace: spark-cluster # 目标命名空间(需提前创建)
spec:hard: # 硬限制(无法突破)pods: "20" # 命名空间内最大 Pod 数量requests.cpu: "2" # 所有 Pod 的 CPU requests 总和上限requests.memory: 1Gi # 所有 Pod 的内存 requests 总和上限limits.cpu: "4" # 所有 Pod 的 CPU limits 总和上限limits.memory: 2Gi # 所有 Pod 的内存 limits 总和上限
1.4.2.2 对象数量配额
限制命名空间内特定 Kubernetes 对象的数量(如 ConfigMap、Service 等),避免对象过多导致集群管理混乱,配置示例:
apiVersion: v1
kind: ResourceQuota
metadata:name: object-counts # 配额名称namespace: spark-cluster # 目标命名空间
spec:hard:configmaps: "10" # 最大 ConfigMap 数量persistentvolumeclaims: "4" # 最大 PVC(持久化存储声明)数量replicationcontrollers: "20" # 最大 RC(Replication Controller)数量secrets: "10" # 最大 Secret 数量services: "10" # 最大 Service 数量services.loadbalancers: "2" # 最大 LoadBalancer 类型 Service 数量(需云厂商支持)
1.4.3 默认资源限制(LimitRange)
若 Pod 未配置 requests 和 limits,且命名空间也未设置配额,Pod 会使用集群最大资源,存在资源滥用风险。可通过 LimitRange 为命名空间设置 Pod/Container 的默认资源限制,确保所有 Pod 都有基础资源约束。
1.4.3.1 配置示例
apiVersion: v1
kind: LimitRange # 资源类型为 LimitRange
metadata:name: mem-limit-range # 限制名称namespace: test # 目标命名空间
spec:limits:- default: # 对应 Pod 的 limits 默认值(未配置时生效)memory: 512Mi # 默认内存上限cpu: 500m # 默认 CPU 上限defaultRequest: # 对应 Pod 的 requests 默认值(未配置时生效)memory: 256Mi # 默认内存初始分配cpu: 100m # 默认 CPU 初始分配type: Container # 限制类型(支持 Container、Pod、PVC)
1.4.3.2 资源限制优先级说明
Kubernetes 资源限制的生效优先级为:Pod 自身配置 > LimitRange 默认配置 > 命名空间配额限制。
- 若 Pod 已配置
requests和limits,则优先使用 Pod 自身配置,但需满足命名空间配额总和限制。 - 若 Pod 未配置,则使用
LimitRange的默认值。
总结
通过本文的介绍,我们详细了解了 Kubernetes 中 HPA(水平 Pod 自动扩缩器)的核心概念、实现原理、部署流程及实践方法。从依赖组件 metrics-server 的部署与验证,到 HPA 基于 CPU、内存等指标的自动伸缩配置,再到资源限制策略的补充,完整覆盖了 HPA 在实际生产环境中的应用场景。
HPA 作为 Kubernetes 自动运维体系的重要组成部分,其核心价值在于通过动态调整 Pod 数量,在保障服务稳定性与提高资源利用率之间取得平衡。无论是应对流量突发的扩容需求,还是流量低谷时的资源回收,HPA 都能通过自动化机制减少人工干预,降低运维成本,尤其适合大规模集群或动态变化的业务场景。
未来,随着 Kubernetes 生态的不断发展,HPA 的能力也在持续扩展,例如支持更丰富的自定义指标(如请求量、队列长度等业务指标)、与垂直 Pod 自动扩缩器(VPA)结合实现资源的全方位动态调整等。掌握 HPA 的原理与实践,将有助于运维与开发团队更好地应对业务波动,构建高效、稳定、经济的容器化应用集群。