网站开发项目经验描述wang域名建的网站
机器学习——感知机
感知机(perceptron)是一种二分类的线性模型,属于判别模型,也称为线性二分类器。输入为实例的特征向量,输出为实例的类别(取+1和-1)。可以视为一种使用阶梯函数激活的人工神经元,例如通过梅尔频率倒谱系数(MFCC)对语音进行分类或通过图像的像素值对图像进行分类。
目录
感知机模型
感知机的几何解释
数据集的线性可分性
感知机学习策略
感知机学习算法
感知机学习算法的原始形式
感知机学习算法的对偶形式
算法的收敛性
感知机算法例题
感知机优缺点
感知机模型
定义 设输入空间(特征空间),输出空间
。输入
表示实例的特征向量,对应于输入空间的点,输出
表示实例的类别,由输入空间到输出空间的函数
称为感知机。
w,b为参数。叫做权值或权值向量(weight vector),b叫作偏置(bias)
符号函数sign的功能是取某个数的符号
感知机模型的假设空间是定义在特征空间中的所有线性分类模型或线性分类器,即函数集合
感知机的几何解释
:对应特征空间
中的一个超平面
,这个超平面将特征空间划分为两个部分,称为分离超平面(separating hyperplane)
b:超平面的截距
w:超平面的法向量

数据集的线性可分性
给定一个数据集,其中
,
,如果存在一个超平面
,能够正确地划分所有正负实例点,则称数据集
为线性可分数据集(linearky separable data set),否则称其线性不可分.
感知机学习策略
假设训练数据集线性可分
学习目标:求得正确划分训练集中所有正负实例点的分离超平面
学习策略:1、确定一个损失函数。2、选取使损失函数最小的参数。
损失函数的选择:误分类点到分离超平面的距离
任一点到超平面的距离公式:
,其中
是
的
范数,
向量的
范数:向量各元素平方和的平方根
定理1:对于误分类数据,有
从而由距离公式和定理1,得
误分类点到超平面的距离公式:
实现了去掉绝对值的工作
所有误分类点到超平面的总距离: ,
为误分类点集合
不必考虑,最终得到损失函数
损失函数:
一 个特定的样本点的损失函数:在误分类时是参数
的线性函数;在正确分类时是0。
因此,
给定训练数据集时,损失函数是
的连续可导函数
感知机学习算法
感知机学习算法的原始形式
输入:训练数据集,其中
,
,学习率
1.任意选取初值
2.任意顺序遍历,计算
,当
,转到步骤3;若对任意
,
,转到输出
3. ,
,转到步骤2.
输出:;感知机
算法采用随机梯度下降法(stochastic gradient descent):
首先任意选取一个超平面,然后用梯度下降法极小化损失函数。极小化过程不是一次使所有误分类点的梯度下降,而是每次随机选取一个误分类点使其梯度下降。
设误分类点集合M固定,损失函数
的梯度为:
对某点
,
的梯度
是增大的方向,故
使损失函数减少。
算法理解:当一个实例点被误分类时,则调整w,b的值,使分类超平面向该误分类点的一侧移动,减少该误分类点与超平面的距离,直至超平面越过该误分类点使其被正确分类
感知机学习算法的对偶形式
感知机学习算法的原始形式和对偶形式与支特向量机学习算法的原始形式和对偶形式相对应
输入:训练数据集,其中
,
,学习率
1.其中
2.任意顺序遍历,计算
,当
,转到步骤3;若对任意
,
,转到输出
3. ,
,转到步骤2
输出:;感知机
对偶形式的基本想法:将
表示为实例
和标记
的线性组合的形式,通过求解其系数来求解
基于原始形式,可设
,则迭代n次后,设第
个实例点由于误分而更新的次数为
,令
,有
,
。
注意:实例点更新次数越多,意味着它离分离超平面越近,意味着越难分类。这样的实例点对于学习结果的影响最大。
Gram矩阵:对偶形式中的训练实例仅以内积的形式出现,将实例间的内积计算出来并以矩阵的形式储存,
,称为Gram矩阵
算法的收敛性
算法原始形式收敛:意味着经过有限次迭代可得到一个将训练数据集完全正确划分的分离超平面
为便于推导,记,扩充输入向量,记
,则有
,
,
(Novikoff)定理 设训练集线性可分,其中
,
,则:
(1)存在满足的超平面
将训练数据集完全正确分开,且存在
,对所有
,
(2)令,则感知机学习算法在训练数据集上的误分类次数k满足不等式
定理表明,当训练数据集线性可分时,经过有限次搜索可以找到将训练数据集完全正确分开的超平面,即算法的原始形式收敛。
感知机算法例题
例1 训练数据集如图所示,正实例点为,
,负实例点为
,试用感知机算法原始形式求感知机模型,令
,
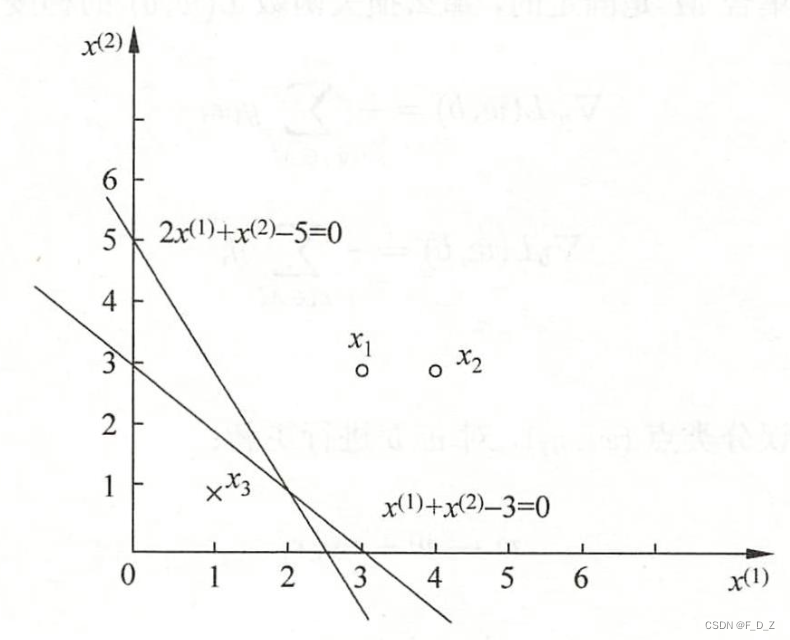
解答:
(1)建模最优化问题:
(2)取初值,
(3)按顺序,对
,
,则
为误分类点。更新
:
,
得到线性模型:
(4)重新选取,对,
,则均为正确分类点,不更新
;
对,
,则
为误分类点,更新
:
,
得到线性模型:
(5)由此不断迭代
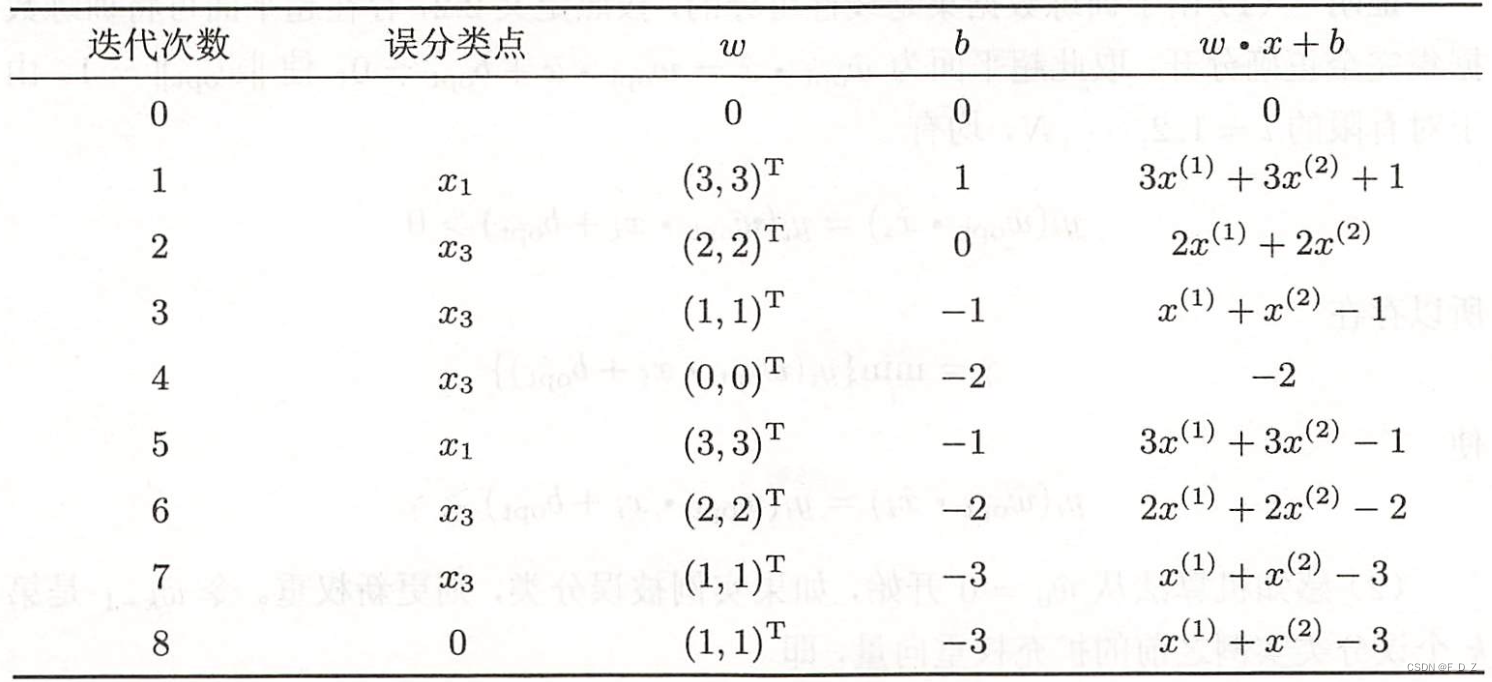
(6)直到,
线性模型:
对所有数据点,则确定分离超平面:
感知机模型
分离超平面
是按照
的取点顺序得到的
例1如果更换取点顺序为
,得到的分离超平面为:
由此,可知结论:感知机算法采用不同的初值或选取不同的误分类点顺序,解可以不同
例2 训练数据集如图所示,正实例点为,
,负实例点为
,试用感知机算法对偶形式求感知机模型,令
,
解答:
(1)取;
(2)计算Gram矩阵
(3)误分条件
(4)参数更新
(5)迭代
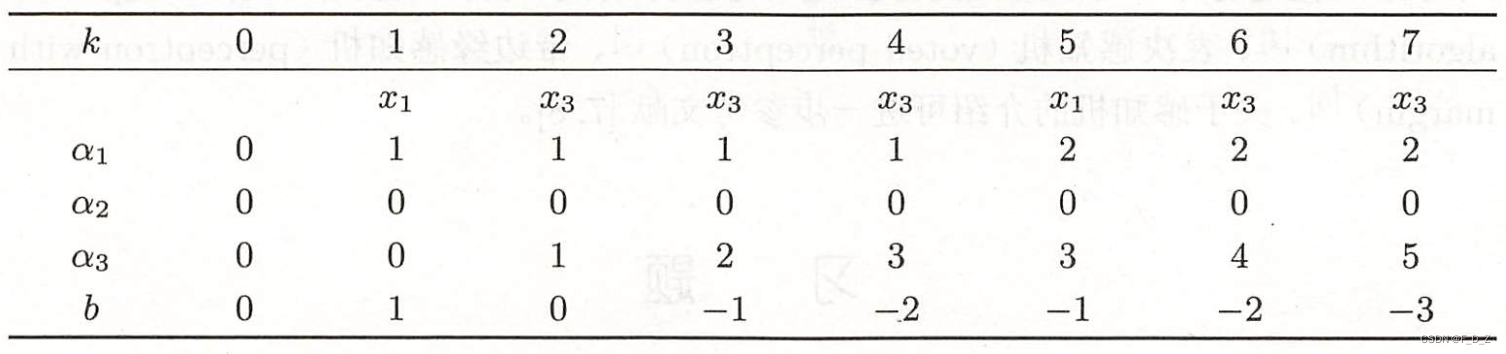
(6)最终得到
则,分离超平面:
感知机模型:
与原始形式一致,感知机学习算法的对偶形式迭代收敛,且存在多个解
感知机优缺点
优点:简单、易于实现、运行速度快
缺点:仅处理线性可分问题,面对多类别多分类问题需要多个分类器导致训练成本增加
在例题的实际操作中可以发现,感知机学习算法存在许多解,这些解既依赖于初值的选择,也依赖于选代过程中误分类点的选择顺序。而为了得到唯一的超平面,需要对分离超平面增加约束条件,这就涉及到了线性支持向量机的想法。