16.set和map的使用

一.set和map的介绍


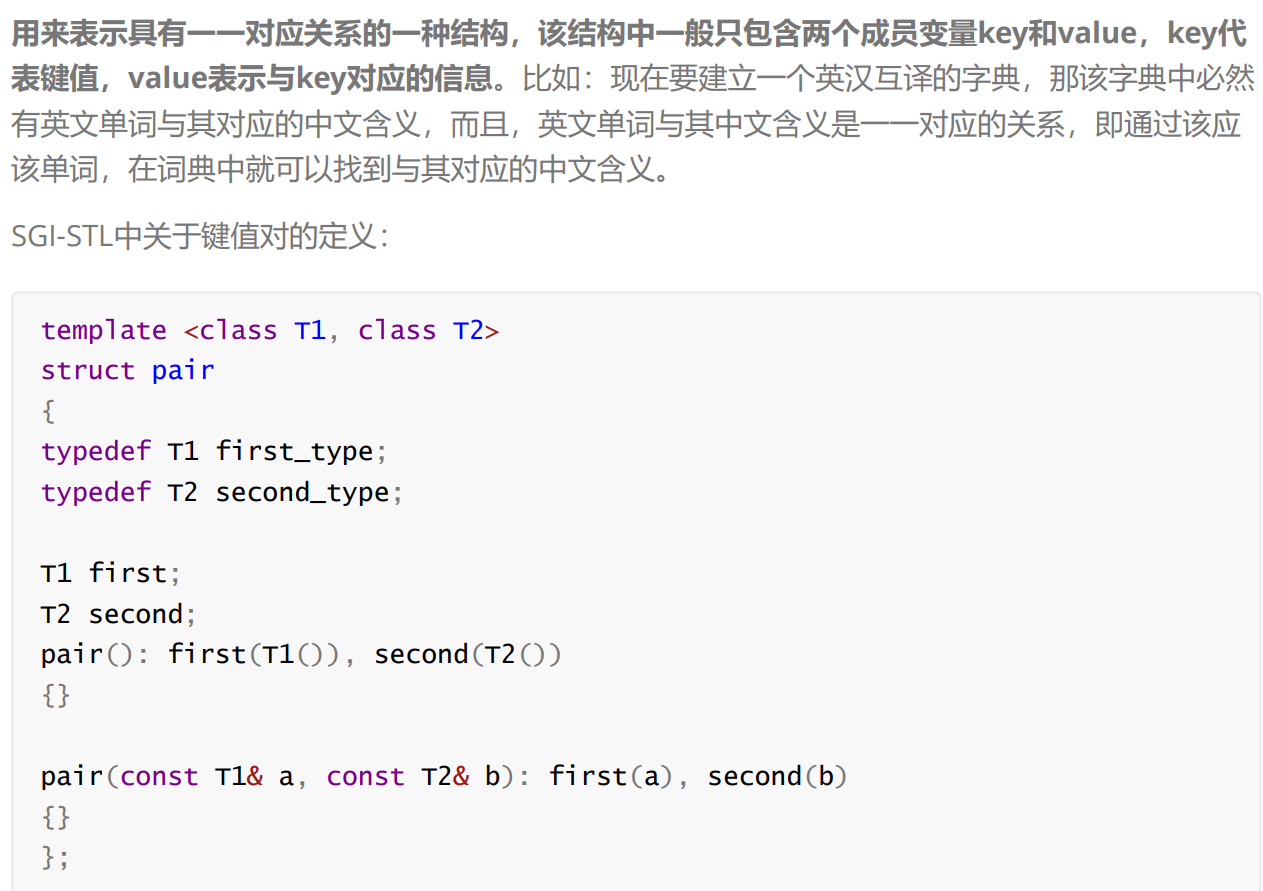
二.键值对
三. 树形结构的关联式容器

四.set
1.set的介绍
https://legacy.cplusplus.com/reference/set/set/

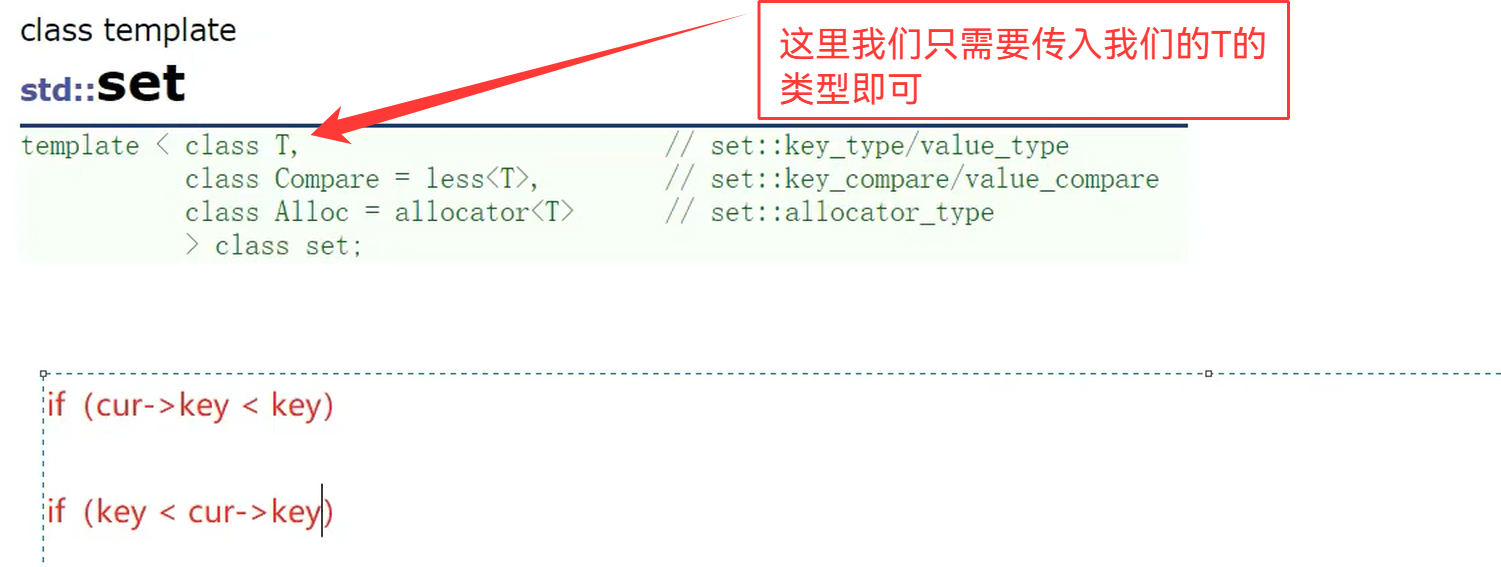
set的底层使用的就是我们的红黑树


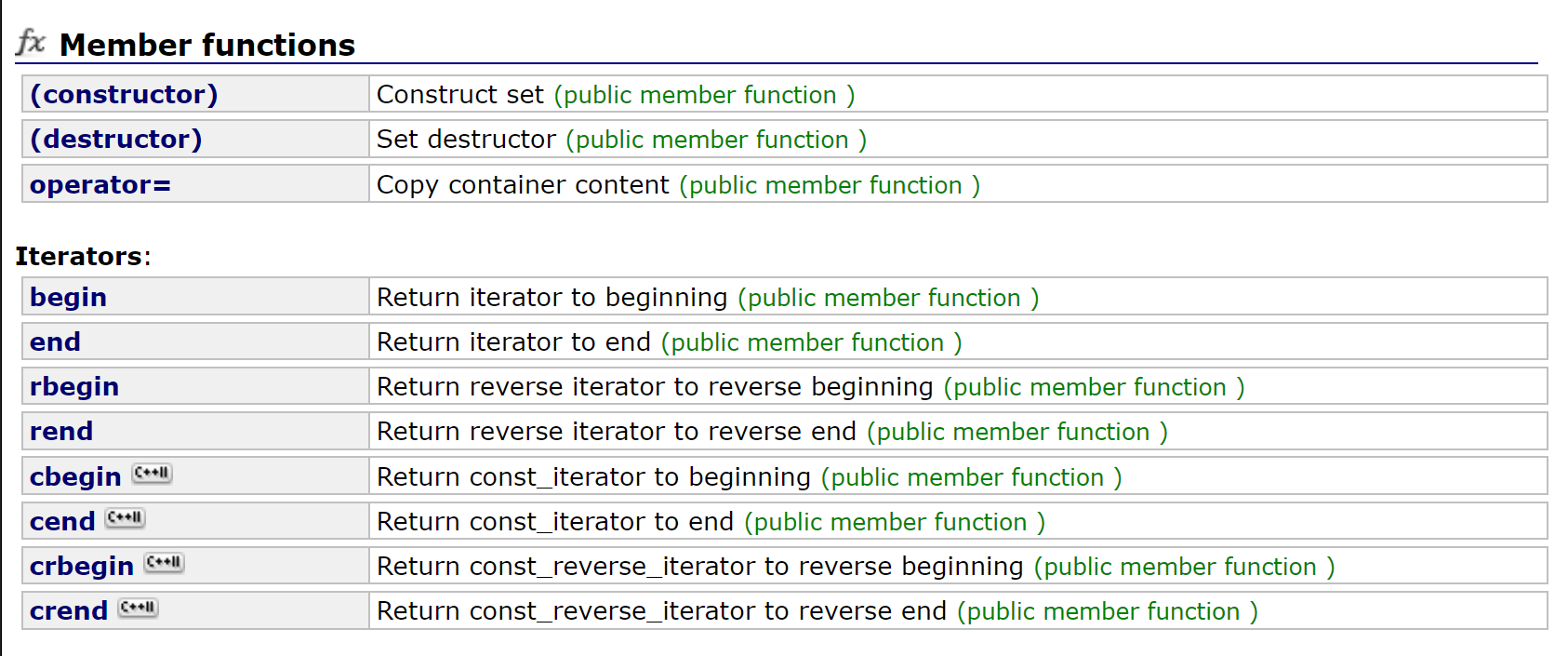
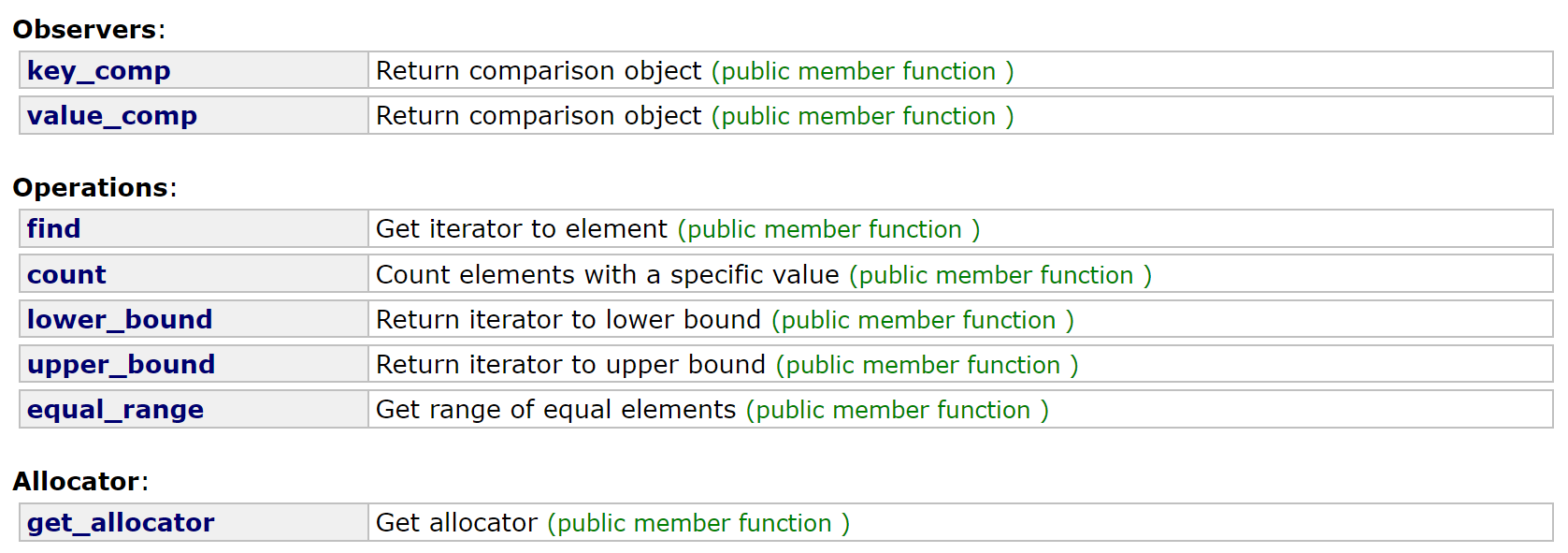
2.set的接口介绍

3.set的使用
#include<set>int main()
{// 去重+排序set<int> s;s.insert(5);s.insert(2);s.insert(7);s.insert(4);s.insert(9);s.insert(9);s.insert(9);s.insert(1);s.insert(5);s.insert(9);//set<int>::iterator it = s.begin();auto it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;
}
我们看到,这里是有序的,而且还是去重的(insert的话有就返回false)
我们这里想到,上次我们实现的二叉搜索树的拷贝和析构没有进行补充,上次文章链接如下:
https://blog.csdn.net/weixin_60668256/article/details/153564158?fromshare=blogdetail&sharetype=blogdetail&sharerId=153564158&sharerefer=PC&sharesource=weixin_60668256&sharefrom=from_link
4.二叉搜索树的拷贝
拷贝这个地方,也是要进行递归拷贝(但是我们的构造函数,不建议写成递归,所以我们写一个Copy来进行拷贝)
Node* Copy(Node* root){if(root == nullptr){return nullptr;}Node* newRoot = new Node(root->_key,root->_value);newRoot->_left = Copy(root->_left);newRoot->_right = Copy(root->_right);return newRoot;}BSTree(const BSTree<K,V>& t){_root = Copy(t._root);}BSTree() = default;(除了上述的拷贝外,我们应该还有写一个默认构造)
5.二叉搜索树的析构
对于析构函数,我们要进行递归进行析构我们的节点(但是,我们一般不建议手动使用析构函数的)
所以,我们写一个Destroy()函数帮我们进行递归析构
//销毁这里,我们要使用后续递归void Destroy(Node* root){if(root == nullptr){return;}Destroy(root->_left);Destroy(root->_right);delete root;}先析构左右两边的树的结构,然后我们再进行析构我们的当前节点
最后,析构函数调用我们的Destroy()进行销毁节点
~BSTree(){Destroy(_root);_root = nullptr;}拷贝测试:
int main()
{kv_of_ltw::BSTree<string, string> dict;dict.Insert("left", "左边");dict.Insert("right", "右边");dict.Insert("insert", "插入");dict.Insert("string", "字符串");kv_of_ltw::BSTree<string, string> copy(dict);return 0;
}
6.删除set最小的值
根据我们二叉树的特性,搜索二叉树的本质(中序遍历是从小到大的顺序)
所以最小的就是s.begin()
// 删除最小值s.erase(s.begin());


7.find查找的区别
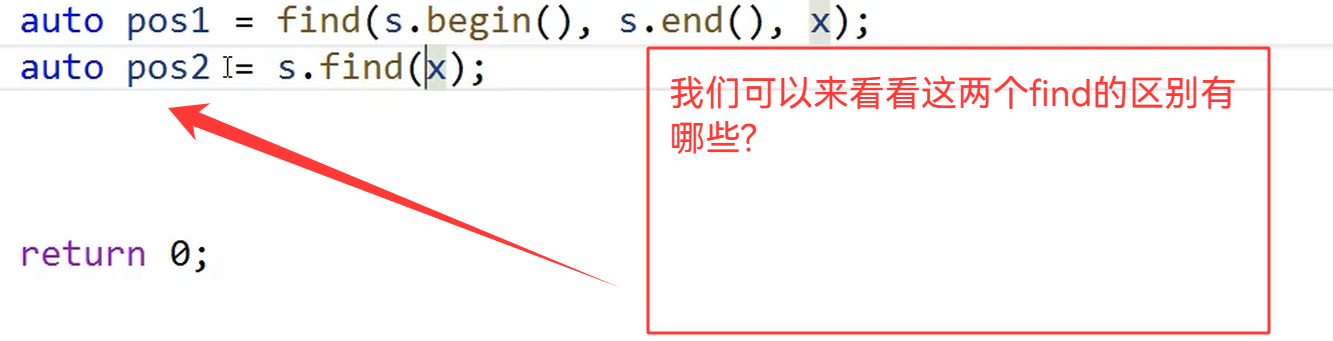
auto pos1 = find(s.begin(), s.end(), x); // O(N)
auto pos2 = s.find(x); // O(logN)
8.lower_bound和upper_bound的使用
lower_bound和upper_bound的时间复杂度是O(logn)
删除[30,60]之间的值
int main()
{std::set<int> myset;std::set<int>::iterator itlow, itup;for (int i = 1; i < 10; i++) myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90// [30, 60]// >= 30itlow = myset.lower_bound(30); //// > 60itup = myset.upper_bound(60); // myset.erase(itlow, itup); // 10 20 70 80 90std::cout << "myset contains:";for (std::set<int>::iterator it = myset.begin(); it != myset.end(); ++it)std::cout << ' ' << *it;std::cout << '\n';return 0;
}五.multiset的使用
1.插入
int main()
{// 排序multiset<int> s;s.insert(5);s.insert(2);s.insert(7);s.insert(4);s.insert(9);s.insert(9);s.insert(9);s.insert(1);s.insert(5);s.insert(9);auto it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;
}
multiset是允许冗余的
这底层还是一个搜索树,如果来了一个相同的值怎么办?
插入左边或者右边都是可以的
如果插入成为这样了,那么我们可以进行旋转操作(后续讲解)

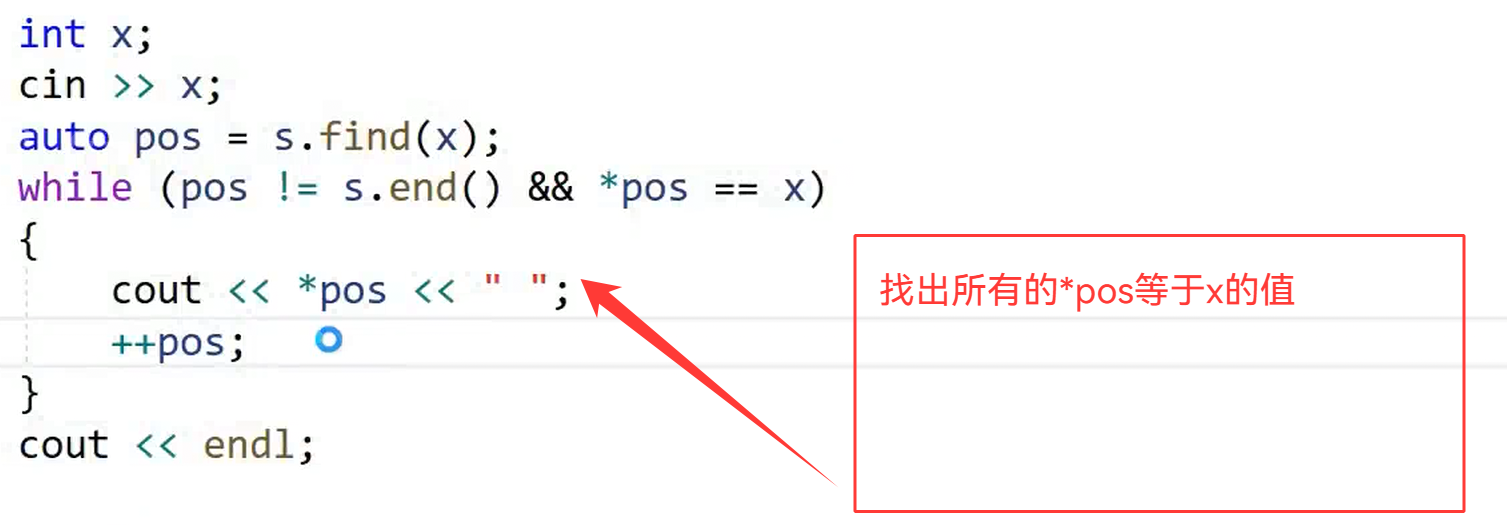
2.find()的返回值


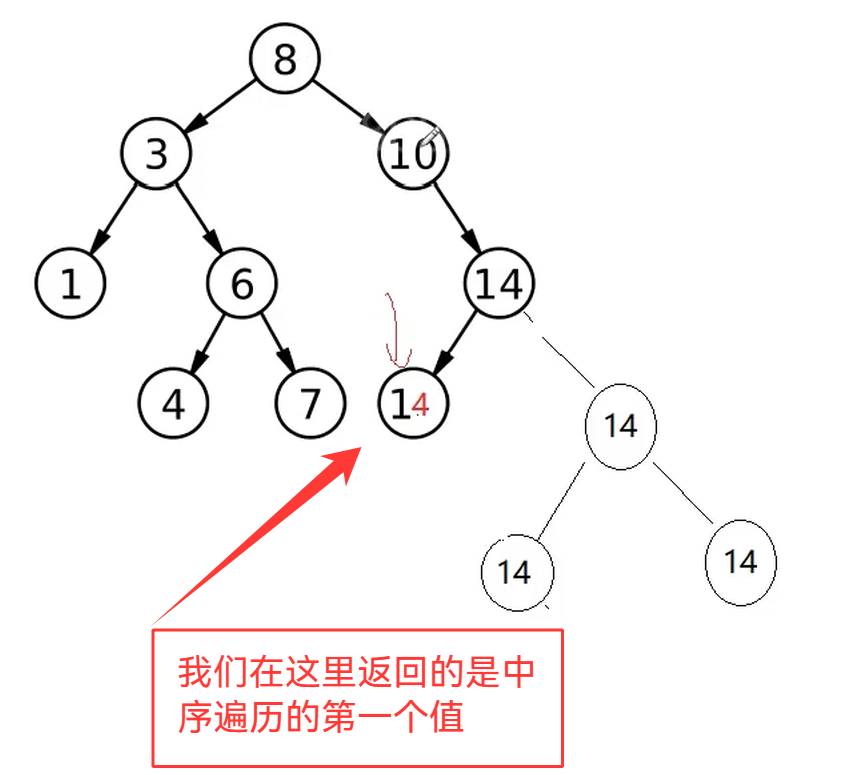
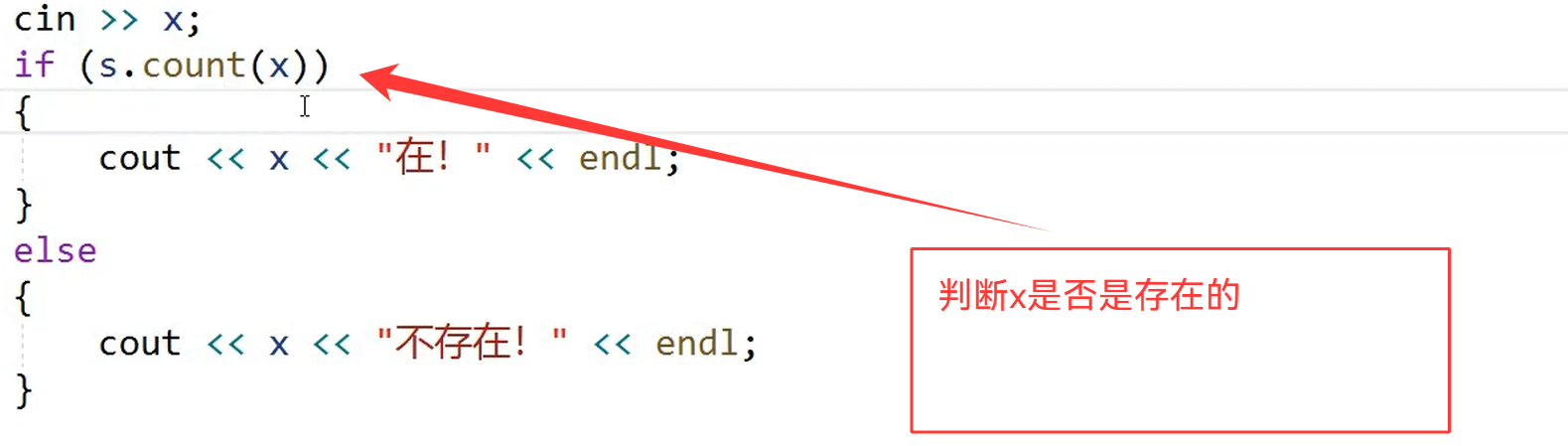
(即使是先找到一个值,我们还不能停)我们要找到最左端的值
3.count()函数
multiset中的count(x)也可以快速的查找到,一共有多少个值
4.erase()函数
s.erase(x);for (auto e : s){cout << e << " ";}cout << endl;
5.equal_range()函数
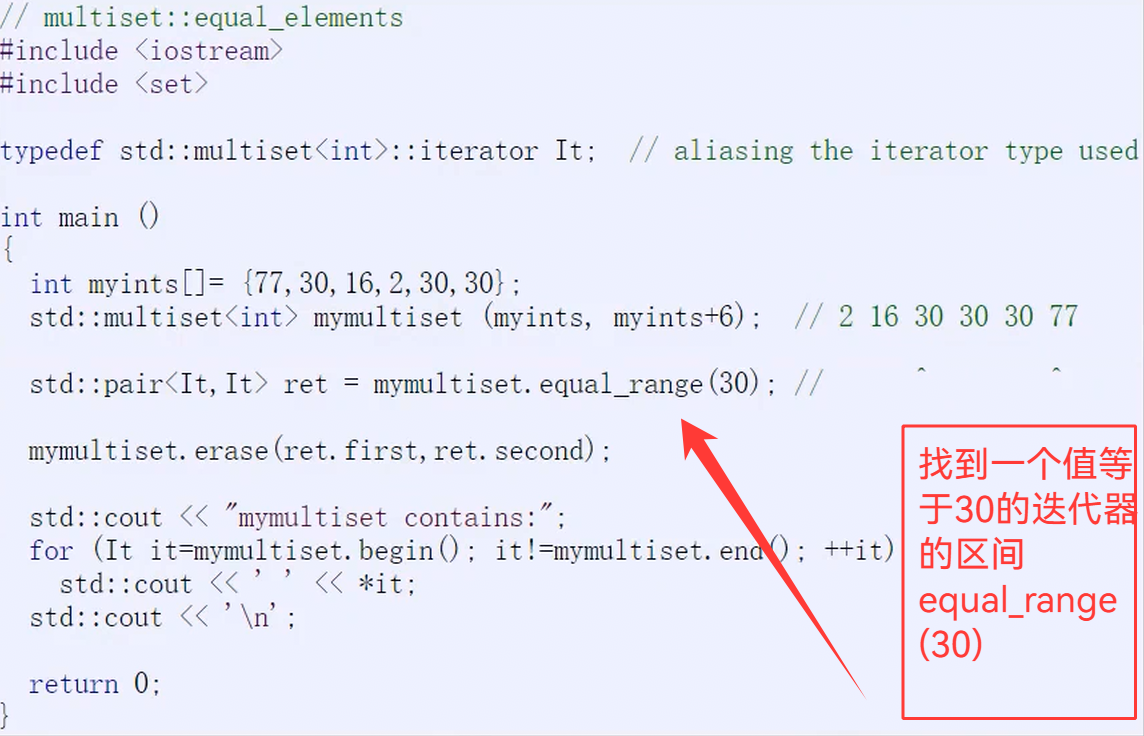
六.map的使用
1.map的介绍
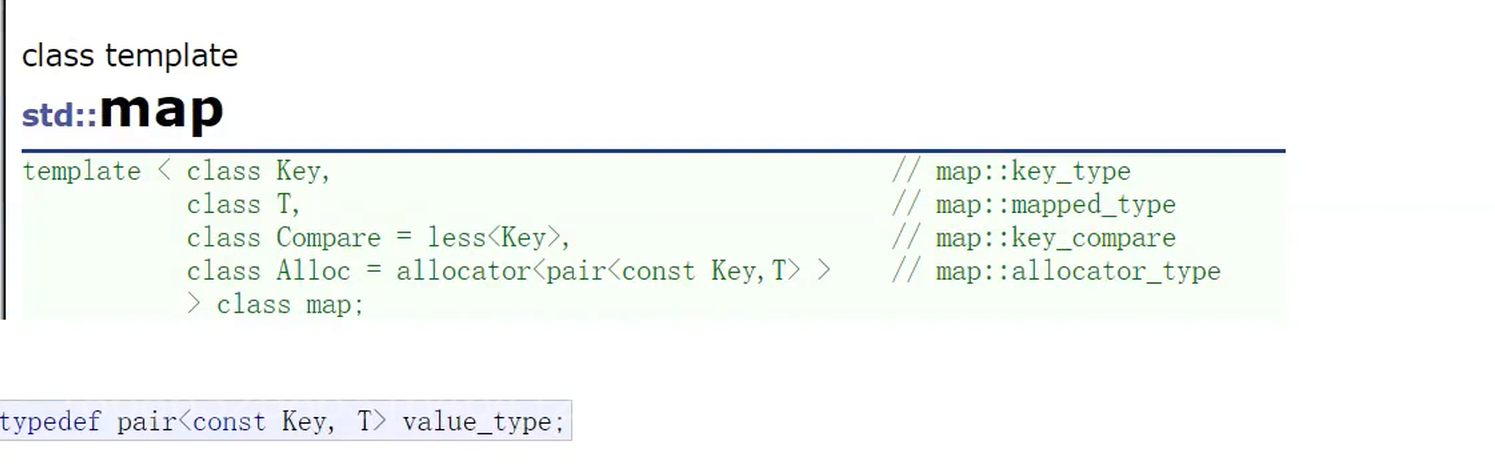
map里面存储的是一个pair
2.map接口的介绍

3.map的使用
我们可以直接使用{}进行构造,支持隐式类型转换
#include<map>int main()
{map<string, string> dict;pair<string, string> kv1("left", "左边");dict.insert(kv1);dict.insert(pair<string, string>("right", "右边"));dict.insert(make_pair("insert", "插入"));//pair<string, string> kv2 = {"string","字符串" };dict.insert({ "string", "字符串" });return 0;
}
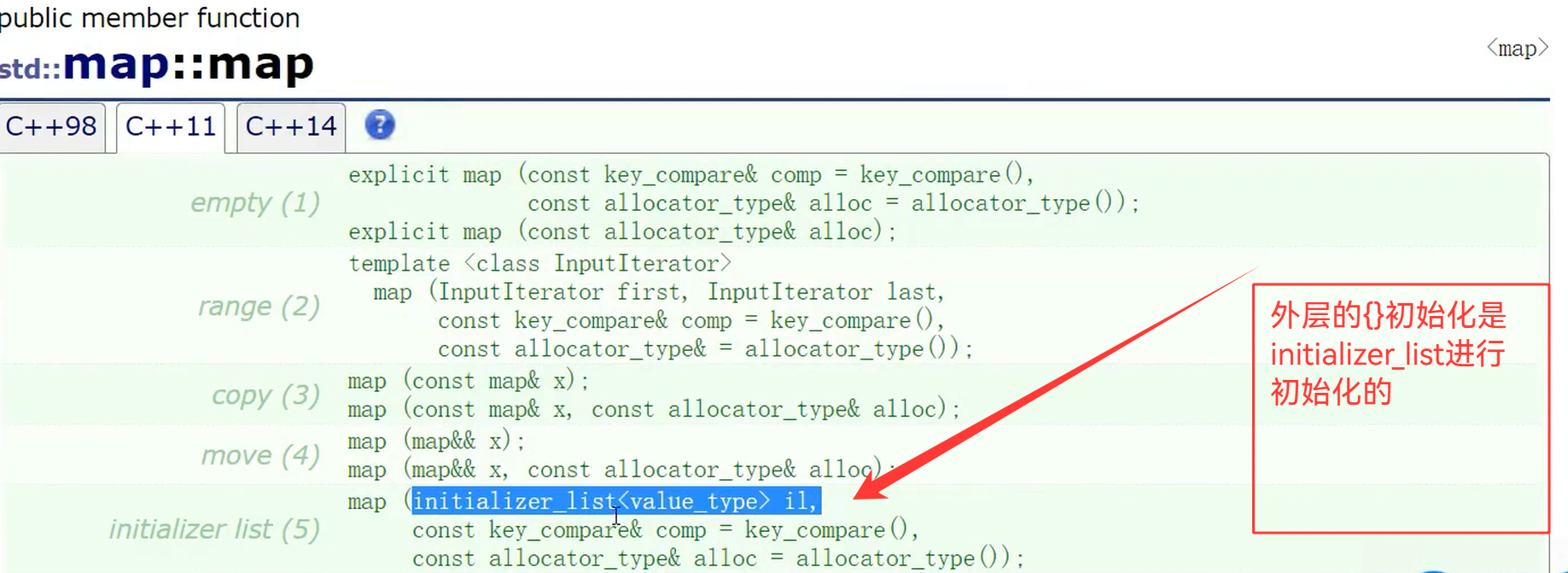
map<string, string> dict = { {"left", "左边"}, {"right", "右边"},{"insert", "插入"},{ "string", "字符串" } };外层的花括号就是我们的initializer_list初始化,内部的花括号就是我们的隐式类型转换
遍历dict里面的数据,如下:
map<string, string> dict = { {"left", "左边"}, {"right", "右边"},{"insert", "插入"},{ "string", "字符串" } };map<string, string>::iterator it = dict.begin();while (it != dict.end()){//cout << (*it).first <<":"<<(*it).second << endl;//cout << (*it).first << ":" << (*it).second << endl;cout << it->first << ":" << it->second << endl;++it;}cout << endl;for (const auto& e : dict){cout << e.first << ":" << e.second << endl;}cout << endl;/*for (auto& [x, y] : dict){cout << x << ":" << y << endl;}cout << endl;*/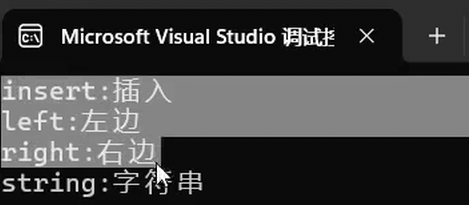
pair里面的内容要使用我们的 first 和 second



我们下面是找str对应的单词,找到,我们要取出ret->second就行
string str;while (cin >> str){auto ret = dict.find(str);if (ret != dict.end()){cout << "->" << ret->second << endl;}else{cout << "无此单词,请重新输入" << endl;}}下面和以前的差不多:
int main()
{string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> countTree;for (const auto& str : arr){// 先查找水果在不在搜索树中// 1、不在,说明水果第一次出现,则插入<水果, 1>// 2、在,则查找到的节点中水果对应的次数++//BSTreeNode<string, int>* ret = countTree.Find(str);auto ret = countTree.find(str);if (ret == countTree.end()){countTree.insert({ str, 1 });}else{ret->second++;}}for (const auto& e : countTree){cout << e.first << ":" << e.second << endl;}cout << endl;return 0;
}4.map的[]
int main()
{string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> countTree;for (const auto& str : arr){countTree[str]++;}for (const auto& e : countTree){cout << e.first << ":" << e.second << endl;}cout << endl;return 0;
}我们可以发现map里面的[]是通过我们的string进行查找,这是怎么做到的呢?
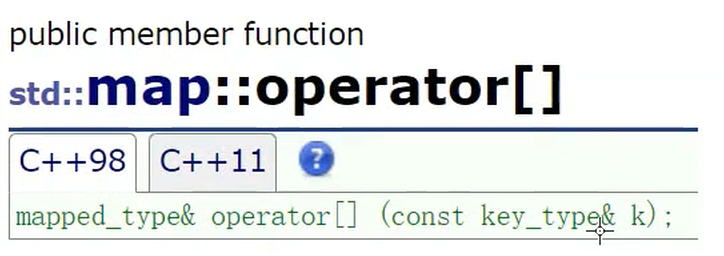
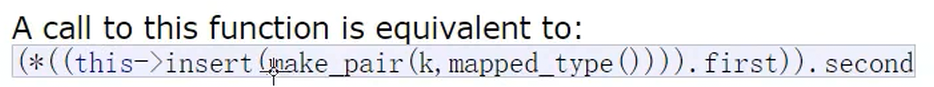

我们来看看,insert()的返回值是什么类型

返回值是pair<iterator,bool>类型的
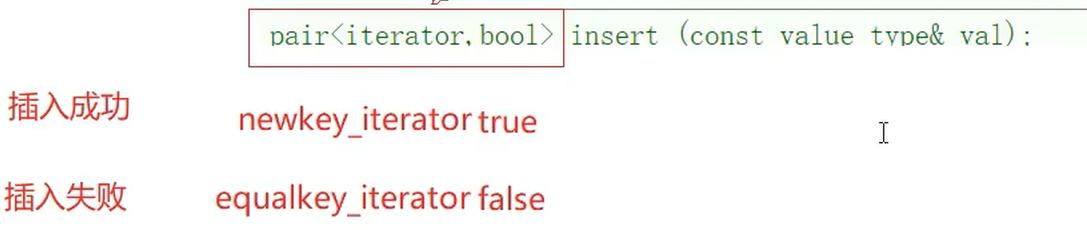
上面那段代码解析出来就是这样的

我们还可以直接使用我们的[]进行内容的插入和修改
int main()
{map<string, string> dict;dict.insert(make_pair("sort", "排序"));// 插入+修改dict["left"] = "左边";// 修改dict["left"] = "左边、剩余";// key不存在->插入 <"insert", "">dict["insert"];// key存在->查找cout << dict["left"] << endl;return 0;
}
int() 就是 0
七.multimap的使用
int main()
{multimap<string, string> dict;dict.insert(make_pair("sort", "排序"));dict.insert(make_pair("sort", "xxxx"));dict.insert(make_pair("sort", "排序"));return 0;
}和map的区别就是multimap是允许key冗余的
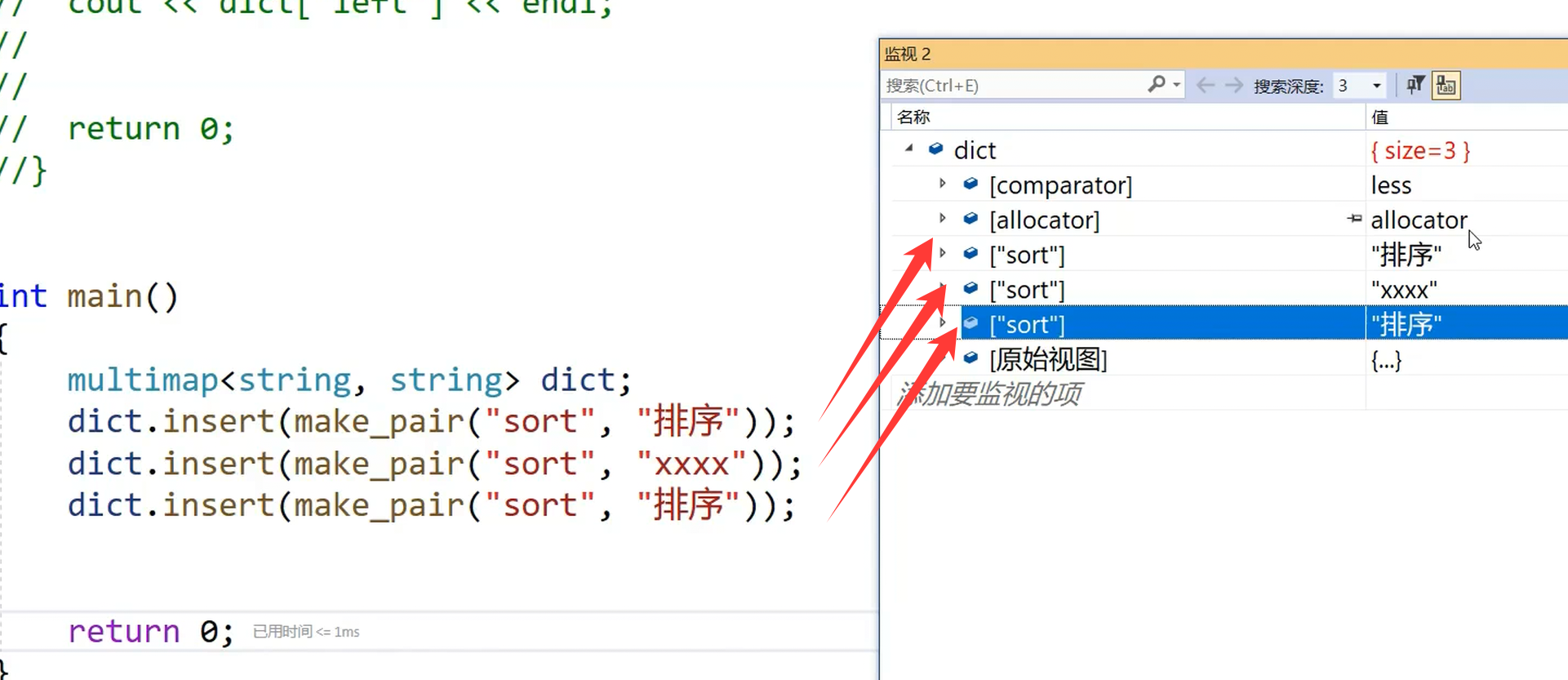
sort分别对应这三个值
所以multimap也不提供[]了,如果提供[],那么有多个值的时候,就不知道返回哪一个了
八.题目
1.
142. 环形链表 II - 力扣(LeetCode)
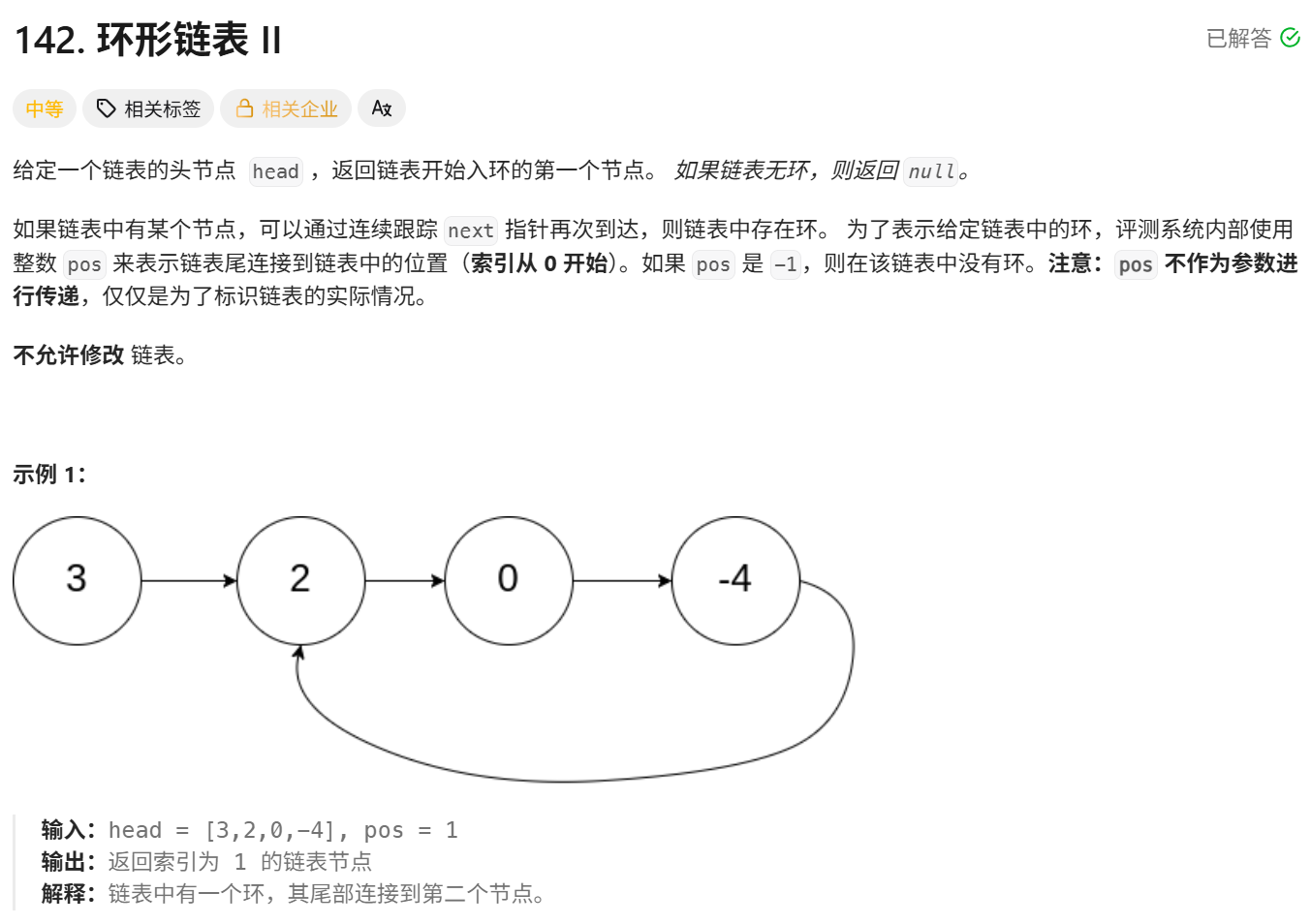
直接使用set数据结构就行:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/
class Solution {
public:ListNode *detectCycle(ListNode *head) {set<ListNode*> s;ListNode* cur = head;while(cur){auto ret = s.insert(cur);if(ret.second == false){return cur;}cur = cur->next;}return nullptr;}
};这个题目还可以进行快慢指针进行解决:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/typedef struct ListNode listnode;
class Solution {
public:ListNode *detectCycle(ListNode *head) {listnode* slow=head,*fast=head;while(fast&&fast->next){slow=slow->next;fast=fast->next->next;if(slow==fast){listnode* meet=slow;while(meet!=head){meet=meet->next;head=head->next;}return meet;}}return NULL;}
};2.
349. 两个数组的交集 - 力扣(LeetCode)


class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {std::set<int> s1(nums1.begin(), nums1.end());std::set<int> s2(nums2.begin(), nums2.end());std::vector<int> ret;auto it1 = s1.begin();auto it2 = s2.begin();while (it1 != s1.end() && it2 != s2.end()) {if (*it1 < *it2) {it1++;} else if (*it1 > *it2) {it2++;} else {ret.push_back(*it1);it1++;it2++;}}return ret;}
};这种算法本质上就是在找 差集和交集 ,时间复杂度是O(n)
3.
692. 前K个高频单词 - 力扣(LeetCode)

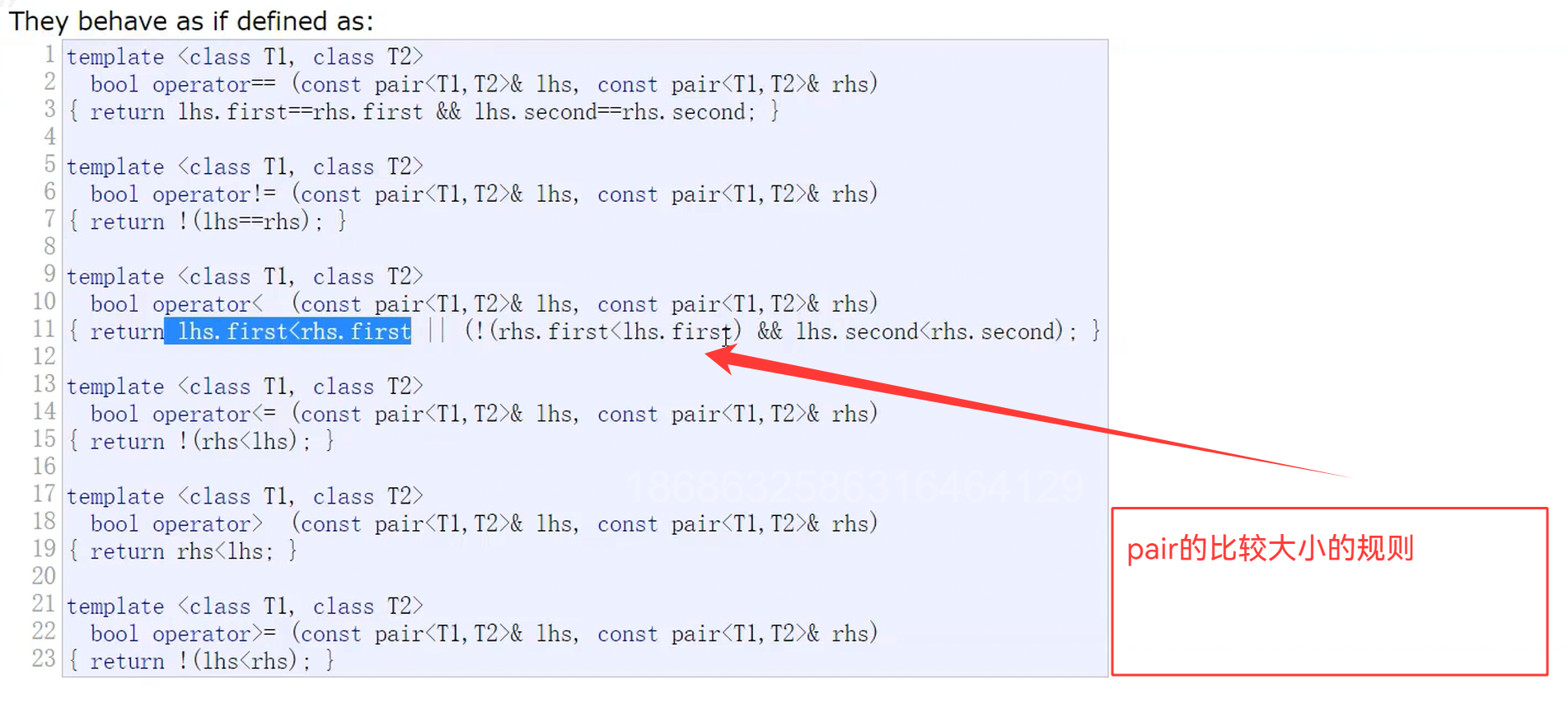
我们可以写一共仿函数,来进行我们想要的规则进行比较
class Solution {
public:struct Compare{bool operator()(const pair<string,int>& x,const pair<string,int>& y){if(x.second != y.second){return x.second > y.second;}return x.first < y.first;}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> countMap;for(auto& e:words){countMap[e]++;}vector<pair<string,int>> v(countMap.begin(),countMap.end());sort(v.begin(),v.end(),Compare());vector<string> strv;for(int i = 0;i < k;i++){strv.push_back(v[i].first);}return strv;}
};因为sort排序是不稳定的,所以会导致我们的顺序错误,我们也可以使用stable_sort(v.begin(),v.end(),Compare())进行排序