StarRocks-基本介绍(一)基本概念、特点、适用场景

数据库、数据仓库、数据湖区别
数据库
- 数据库负责实时业务操作OLTP(on-line transaction processing),负责实时处理当下的业务操作,比如
下单、支付
数据仓库
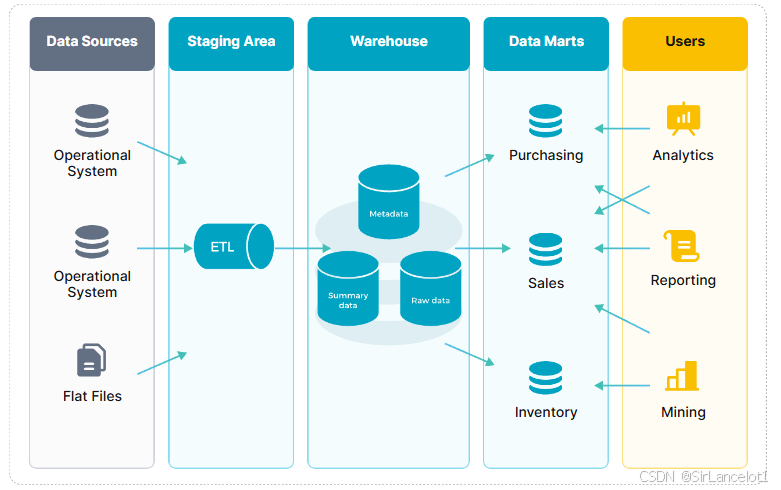
定义
- 数据仓库是一个已经结构化处理的(已经进行过
标签和分类)、反映历史变化的、相对稳定的数据集 - 数据仓库一般存储的是已经从业务系统(比如
ERP、MOM、CRM)中提取、转换、加载(ETL)后的结构化数据
作用
- 数据仓库负责整合分析,负责业务的决策分析OLAP(On-Line Analytical Processing),比如
历史数据分析、趋势分析 - 整合来自多个异构业务系统的数据,解决数据孤岛问题,并确保数据口径一致。
- 为管理层和业务部门提供统一、可信的“单一事实来源”,用于生成标准化的报表和仪表盘。
特点
-
写时建模(Schema-on-Write)
- 数据在被写入到数据仓库之前,就已经定义好了数据结构(表结构、关系、数据类型)
-
已经经过处理
- 数据在进行仓库之前,已经进行过ETL流程,确保了数据一致性、数据质量和准确性
-
高度结构化
- 数据通常已经给被处理成星型模式或者雪花模式,包含事实表和维度表,适合进行复杂的SQL查询和分析处理(OLAP)
-
服务于特定目标
- 主要为商业智能(BI),数据分析和数据可视化服务
-
需要满足高性能分析需求
- 针对已知的、重复性的分析需求,提供快速、稳定的查询响应。
数据湖
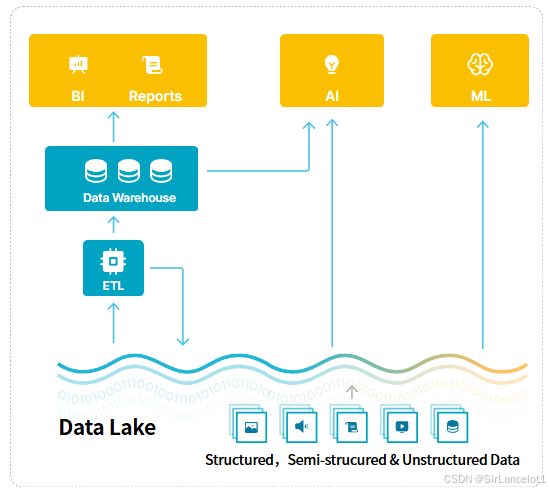
定义
- 数据湖是一个集中式的存储库,可以存储任意规模的原生格式原始数据,包括
- 结构化数据,如关系数据库中的
数据表、Excel电子表格 - 半结构化数据,如
Json、XML、日志、HTML、email - 非结构化数据,如
视频、图片、音频
- 结构化数据,如关系数据库中的
作用
- 数据湖负责存储原始数据。负责存储原始资源/原始数据,为
未来未知的需求做准备 - 遵循“先存储、以备后续处理之需”的原则
特点
-
读时建模(Schema-on-Read)
- 数据存储时不需要预定数据结构,而在读取使用时,才需要结构定义(Schema)
- 就像把一堆文件随意扔进一个仓库,等需要某个文件时,再拿出来整理。
-
原始数据/原生格式
- 保存的是原始数据,保存数据原始格式
- 避免早期处理可能带来的信息损失
-
灵活性高
- 可容纳各种类型的数据,为未来未知的需求保留可能性(如机器学习、大模型、数据分析、可视化等)
-
成本相对较低
- 一般建立在成本较低的分布式存储系统(
Hadoop、HDFS、对象存储S3),存储成本相对数据仓库会低很多
- 一般建立在成本较低的分布式存储系统(
湖仓一体
为什么出现数据湖仓
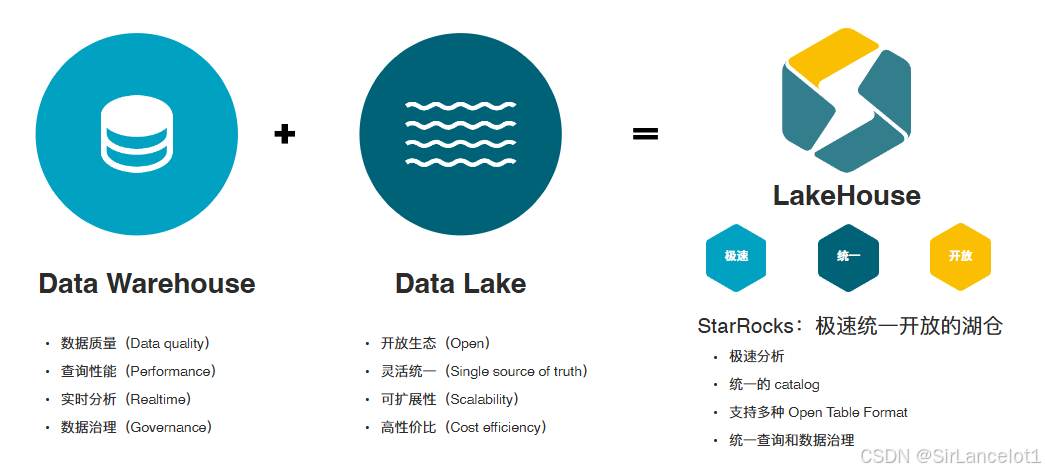
- 在企业实践中,数据湖和数据仓库并非是二选一的关系,而是互补的关系。因此,现代的数据架构在往“湖仓一体”的方向演进
- 而数据湖仓一体,可以很好的结合二者的优势
数据湖仓优势
-
低成本存储
- 在数据湖的低成本存储上,再实现数据仓库的数据管理、优化、事务能力
-
统一存储层
- 将数据湖作为统一存储层,存放所有原始数据
- 在湖上再创建具有数据仓库特性的视图
StarRocks基本介绍

- StarRocks是一款高性能的分布式、分析型数据库/数据仓库/云原生湖仓,采用了先进的
MPP(Massively Parallel Processing,大规模并行处理)架构、向量化引擎
StarRocks特点
优点
-
MPP(大规模并行处理)架构
- 查询任务可以多节点并行执行,实现极高的查询性能
-
向量引擎
- StarRocks计算层采用向量化技术进行数据批量处理,通过列式存储以及配合CPU的SIMD指令,充分发挥CPU并行计算能力,实现亚秒级响应
-
湖仓一体
- 兼容MySQL协议,支持直接分析 Iceberg、Hudi、Hive 等数据湖格式,直接查询湖中数据。
- 便于企业构建统一数据平台,避免数据迁移,提升分析效率
-
查询优化
- 内置成本的优化器(CBO)**,能够对复杂查询进行自动优化,生成最优执行计划,尤其在多表关联查询方面表现卓越。
-
流批一体、实时分析
- 支持高吞吐的实时数据导入,且能对接各种数据源,与 Apache Flink、Apache Paimon 深度集成,支持分钟级甚至秒级的数据新鲜度,满足实时分析需求。
- 在一些实时监控大屏、物流跟踪、实时金融风控领域表现良好
缺点
-
不擅长OLTP
- StarRocks设计目标是OLAP(On-Line Analytical Processing 在线分析处理),不擅长处理OLTP场景(on-line transaction processing 在线事务处理)
- 不适合作为电商交易、用户会员系统等作为核心业务数据库。
-
大规模ETL能力弱
- 采用的MPP架构,导致对硬件性能要更高,进行复杂且数据量巨大的ETL场景时,容易因为内存不足而受限
- 不适合在库内进行复杂且数据量级达到PB级的数据清洗、转换任务
-
批量删除、更新效率低
- 对于大批量的删除。更新支持不够友好
- 需要频繁或大批量修正历史数据的场景(如全量表回溯)会遇到性能瓶颈
-
字符串与数据类型限制
- 字符串类型有长度限制(最长65533字符),时间精度不支持毫秒。
- 处理超长日志内容或需要毫秒级时间戳的场景会受限。
引申问题:MPP架构和向量引擎是什么?
MPP架构
是什么
-
MPP架构是一种大规模并行处理的“宏观战略”,即一种
分布式计算框架分布式计算框架:通过将多个计算节点组织成统一系统,共同完成一个复杂的查询任务,核心思想是“分而治之”
如何工作
-
比如用户发起一个复杂查询,会有以下的执行步骤
SELECT department, SUM(sales) FROM company WHERE month=12 GROUP BY department; -
查询分发:用户将查询语句SQL发送到任意一个StarRocks节点上,这个节点被称之为
协调节点 -
查询规划:
协调节点的查询优化器会生成一个最优的分布式执行计划。分布式执行计划包括- 数据如何在节点内分布和扫描
- 计算任务如何拆分
- 节点之间如何数据交换
-
数据并行扫描
- 因为分布式结构下,一张表的数据有可能是
分片到了多个节点上存储 - 协调节点的
查询优化器会将比如WHERE month = 12这个条件都发给所有的节点 - 所有节点会
同时工作,并行的扫描自己本地的数据,进行对应条件的查找
- 因为分布式结构下,一张表的数据有可能是
-
扫描后局部聚合
- 因为复杂查询中有GROUP BY 分组与SUM聚合,在数据并行扫描时,
每个节点也会在本地进行局部聚合 - 每个节点计算自己本地数据的
SUM(sales),并按department进行局部聚合。Node1 计算:(Engineering, 1000), (Sales, 1500) Node2 计算:(Engineering, 2000), (Sales, 800) Node3 计算:(Engineering, 1200), (Sales, 900)
- 因为复杂查询中有GROUP BY 分组与SUM聚合,在数据并行扫描时,
-
数据交换
- 各个节点将局部聚合结果,按照department 进行
重新分布- 比如所有Engineering部门的都发给Node1,Sales都发给Node2。
- 这个过程称为
数据交换Shuffle,这些Node1、Node2此时称之为最终聚合节点
- 各个节点将局部聚合结果,按照department 进行
-
最终聚合、返回
-
最终聚合节点再次并行工作,对来自各个节点的相同department数据进行全局聚合Node1计算: (Engineering, 1000+2000+1200) = (Engineering,4200) Node2计算:(Sales, 1500+800+900)=(Sales, 3200) -
协调节点从这些节点
收集最终结果,返回给客户端
-
MPP优势
-
接近线性的扩展性
- 可以增加节点以提升集群处理能力,增加节点的提升是接近线性的
-
高性能、高吞吐
- 可以借由大任务拆分成小任务并行,避免了单机瓶颈,多节点执行提高了集群性能与IO计算处理能力
StarRocks适用场景

-
实时数据分析/OLAP多维分析
- 高维业务指标报表,如订单报表、客户分析、用户画像
- 生产过程数据分析
- 质量追溯分析
- 设备运维分析
- 供应链协同分析
- 库存与物流实时分析
-
高并发查询
- 千级并发用户同时在线查询
- SaaS行业用户分析报表
-
湖仓一体化
- 统一数据存储分析平台,整合数据湖和数仓
- 支持联邦查询
- 降低系统复杂度,统一技术栈