C++初阶(14)list
1. list的介绍及使用
1.1 list的介绍
list的文档介绍
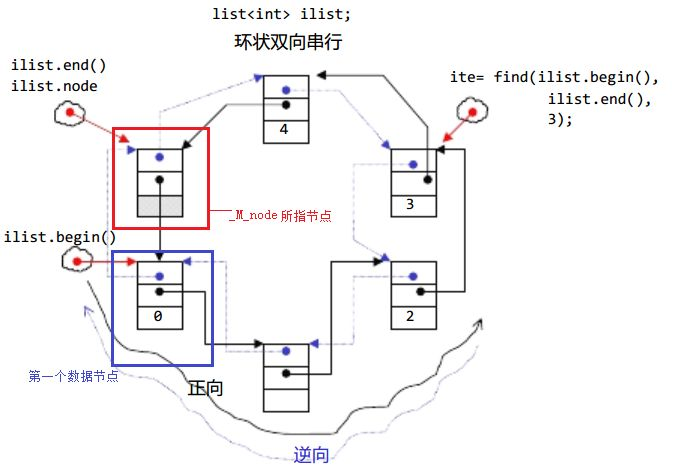
1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。
2. list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向其前一个元素和后一个元素。
3. list与forward_list非常相似:最主要的不同在于forward_list是单链表,只能朝前迭代,已让其更简单高效。
4. 与其他的序列式容器相比(array,vector,deque),list通常在任意位置进行插入、移除元素的执行效率更好。
5. 与其他序列式容器相比,list和forward_list最大的缺陷是不支持任意位置的随机访问,比如:要访问list的第6个元素,必须从已知的位置(比如头部或者尾部)迭代到该位置,在这段位置上迭代需要线性的时间开销;list还需要一些额外的空间,以保存每个节点的相关联信息。(对于存储类型较小元素的大list来说这可能是一个重要的因素)
1.2 list的使用
list中的接口比较多,此处类似,只需要掌握如何正确的使用,然后再去深入研究背后的原理,已达到可扩展的能力。
前面学的string和vector的迭代器都是随机迭代器,支持++,--,+,-。
链表的双向迭代器只支持++,--,不支持+,-。——因为支持+,-效率会变低。
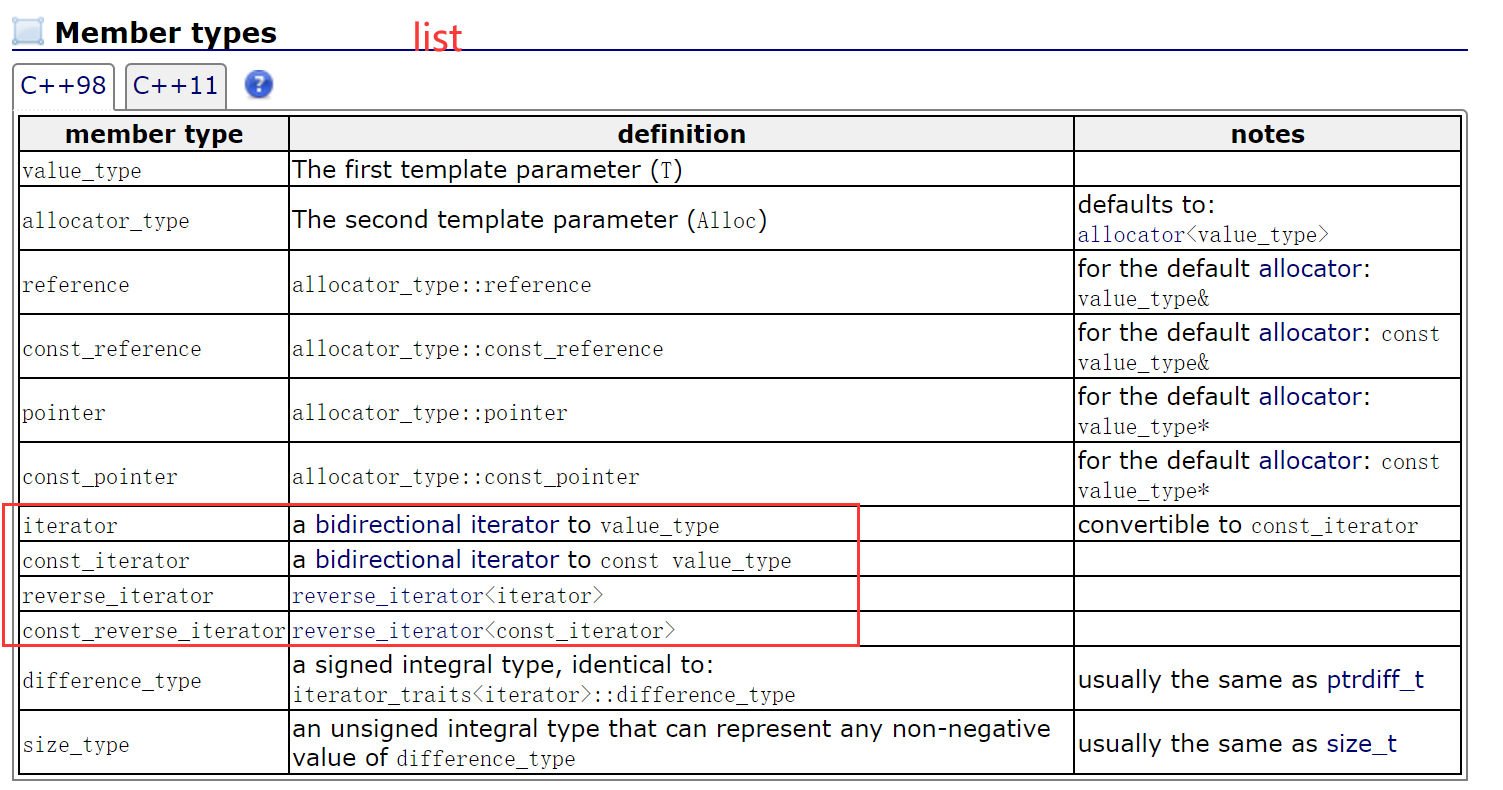
以下为list中一些常见的重要接口。
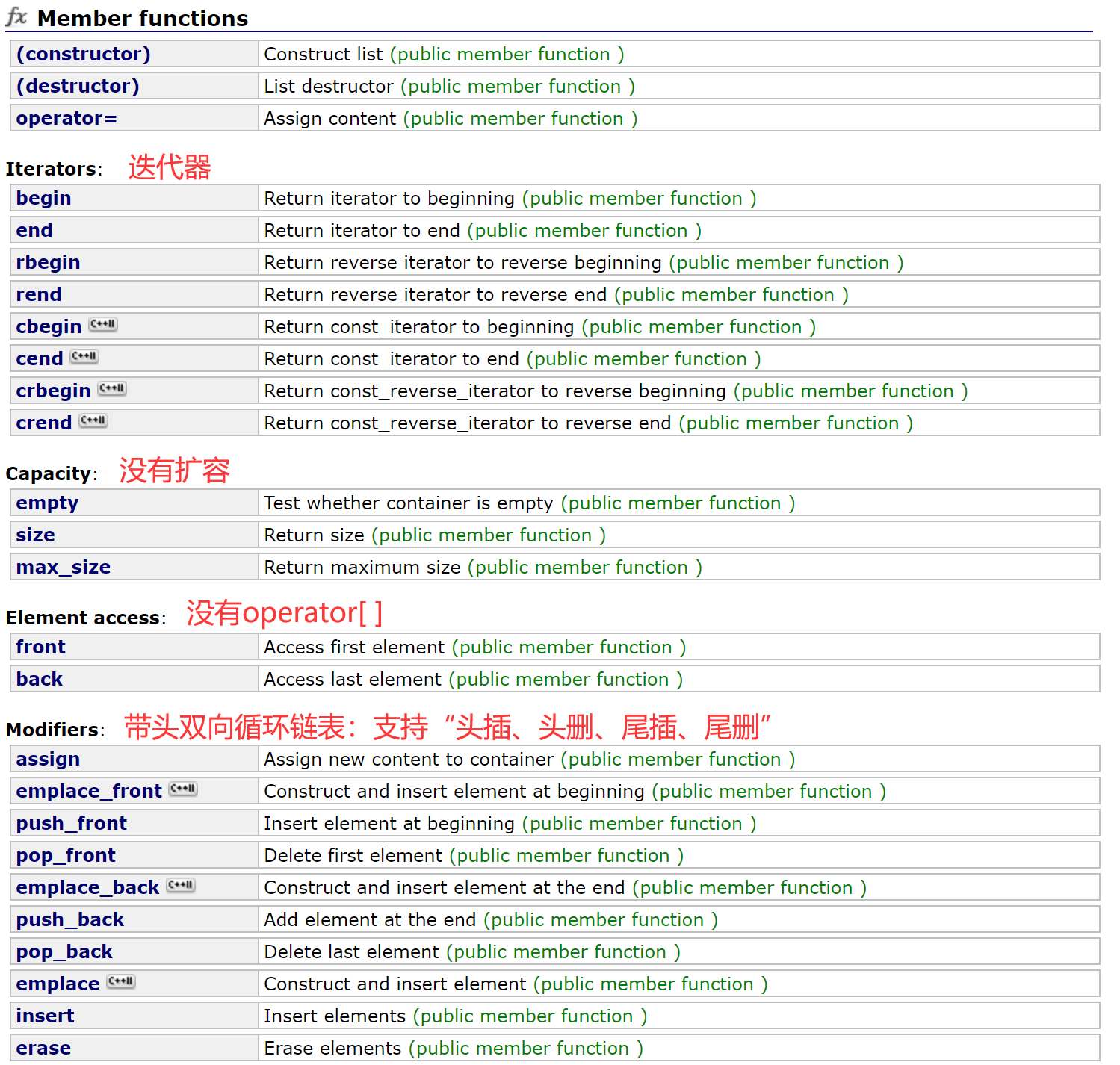
1.2.1 构造函数

【总结】
| 构造函数(constructor) | 接口说明 |
| list (size_type n, const value_type& val = value_type()) | n个值为val的元素来构造 |
| list() | 无参构造(默认构造) |
| list (const list& x) | 拷贝构造 |
| list (InputIterator first, InputIterator last) | 用[first, last)迭代区间中的元素构造list |
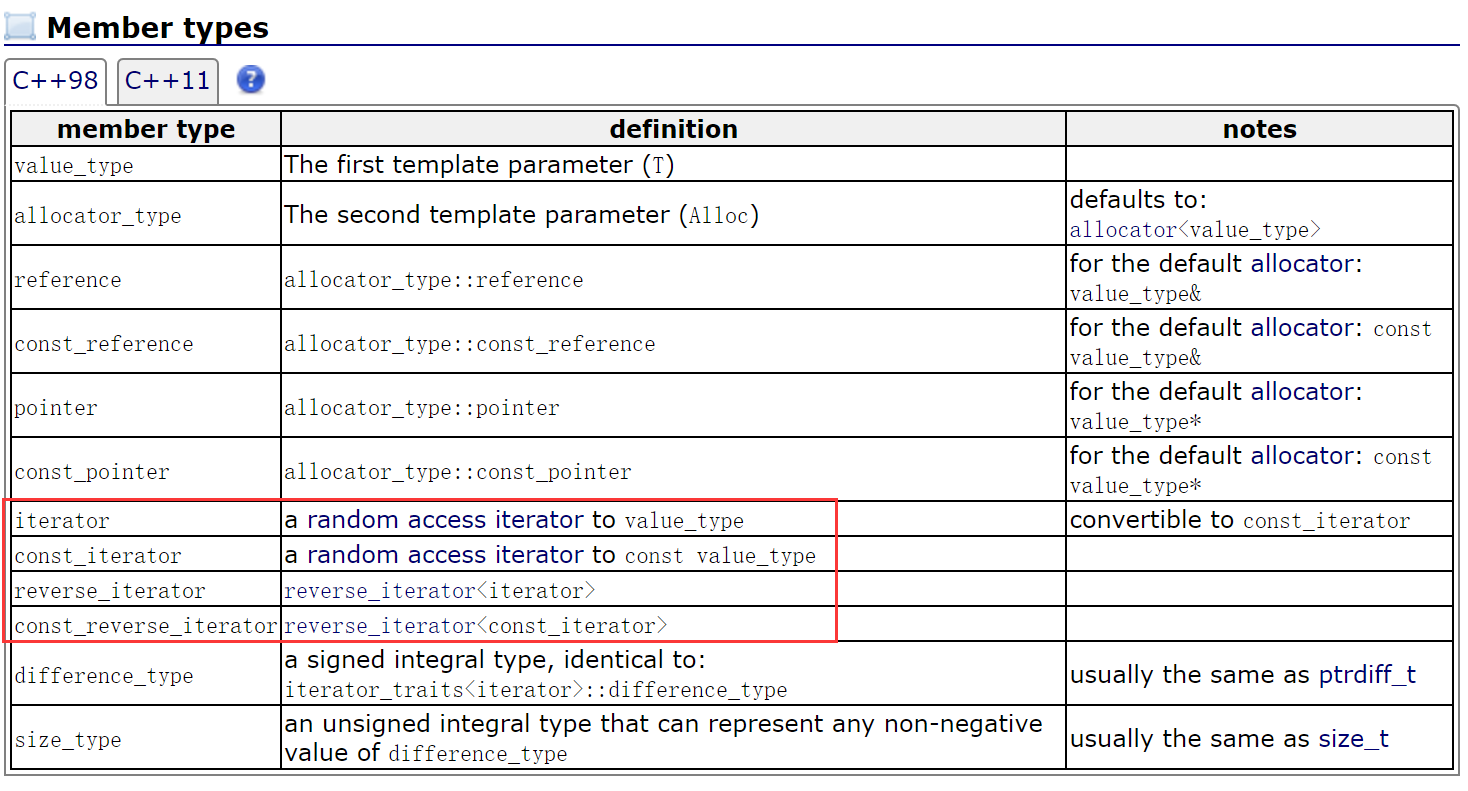
1.2.2 迭代器
此处,大家可暂时将迭代器理解成一个指针,该指针指向list中的某个节点。
| 函数声明 | 接口说明 |
| begin + end | 返回第一个元素、最后一个元素下一个位置的迭代器 |
| rbegin + rend | 返回第一个元素的reverse_iterator,即end位置; 返回最后一个元素下一个位置的reverse_iterator,即begin位置; |
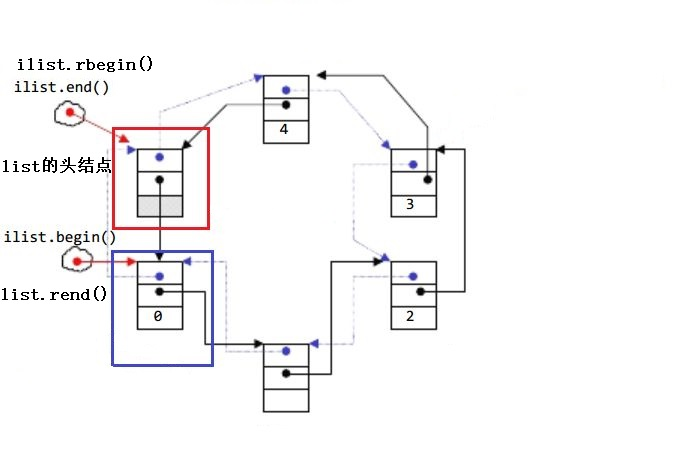
【注意】双向迭代器(支持++、--,不支持+、-)
- begin与end为正向迭代器,对迭代器执行++操作,迭代器向后移动
- rbegin(end)与rend(begin)为反向迭代器,对迭代器执行++操作,迭代器向前移动
1.2.3 容量
| 函数声明 | 接口说明 |
| empty | 检测list是否为空,是返回true,否则返回false |
| size | 返回list中有效节点的个数 |
1.2.4 元素获取
不支持operator[]——效率低,必须从头开始。
| 函数声明 | 接口说明 |
| front | 返回list的第一个节点中值的引用 |
| back | 返回list的最后一个节点中值的引用 |
链表的主流访问方式是迭代器。
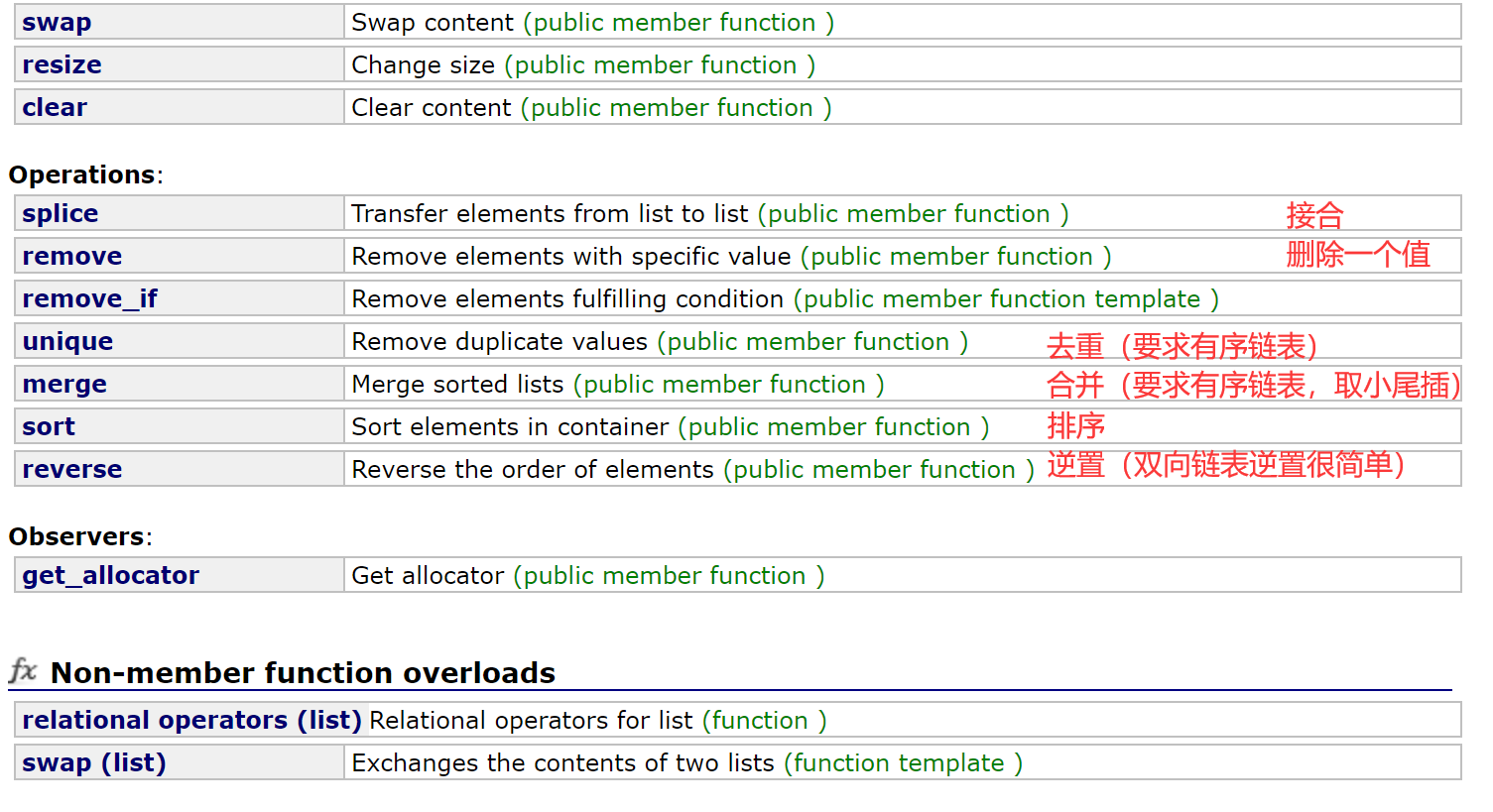
1.2.5 修改
| 函数声明 | 接口说明 |
| push_front | 在list首元素前插入值为val的元素 |
| pop_front | 删除list中第一个元素 |
| push_back | 在list尾部插入值为val的元素 |
| pop_back | 删除list中最后一个元素 |
| insert | 在list position 位置中插入值为val的元素 |
| erase | 删除list position位置的元素 |
| swap | 交换两个list中的元素 |
| clear | 清空list中的有效元素 |
list中还有一些操作,需要用到时大家可参阅list的文档说明。
1.2.6 使用测试
① test1()
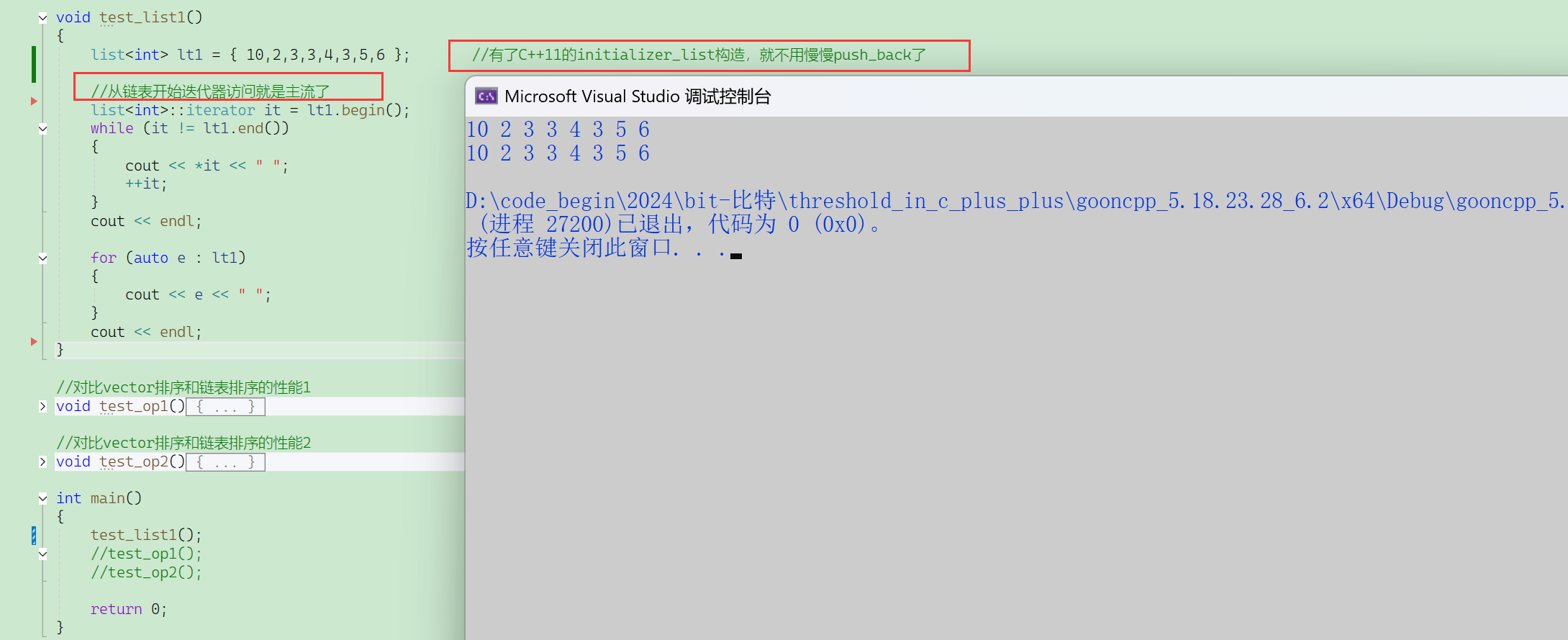
链表不能用sort去排序——因为链表的迭代器不支持-(效率不高)。
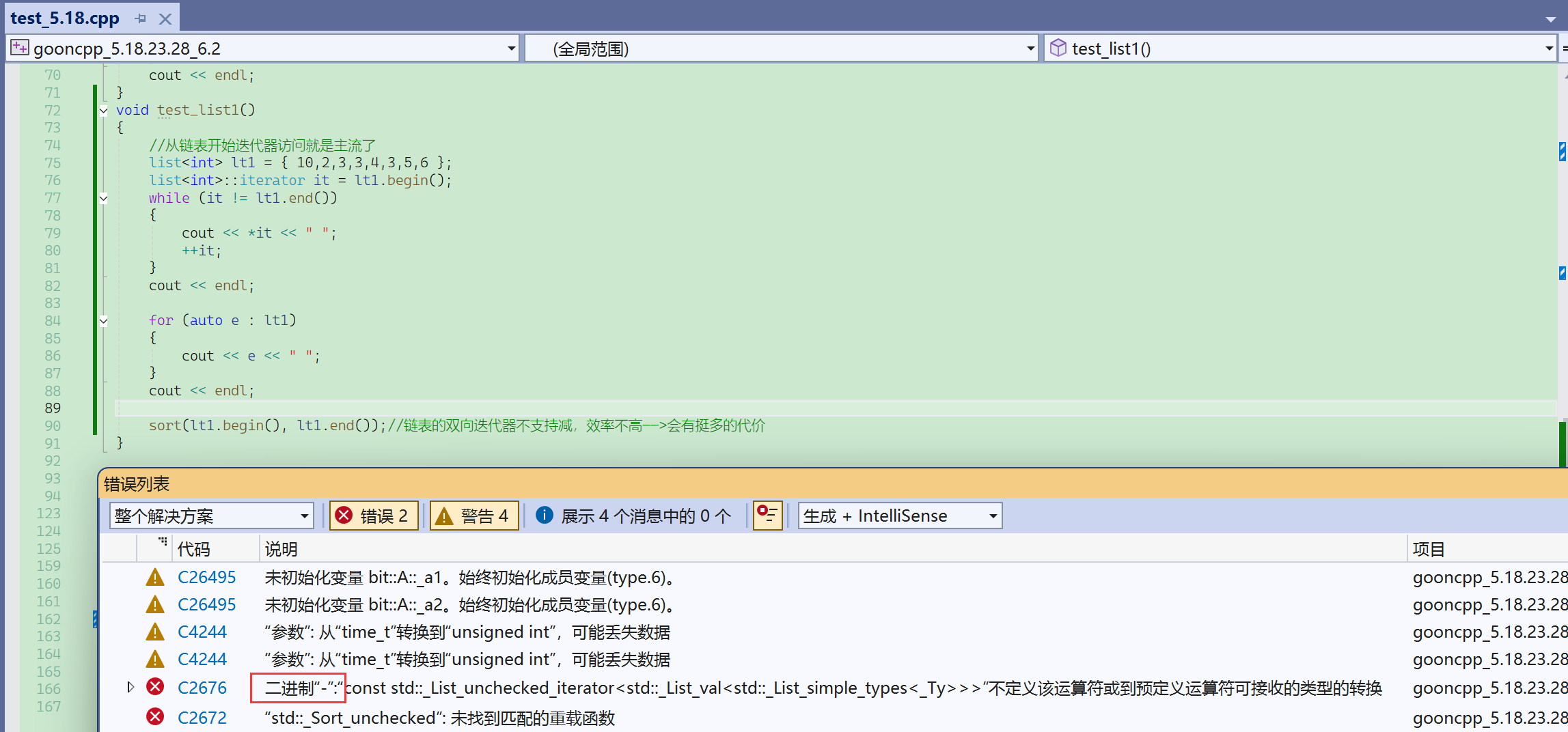
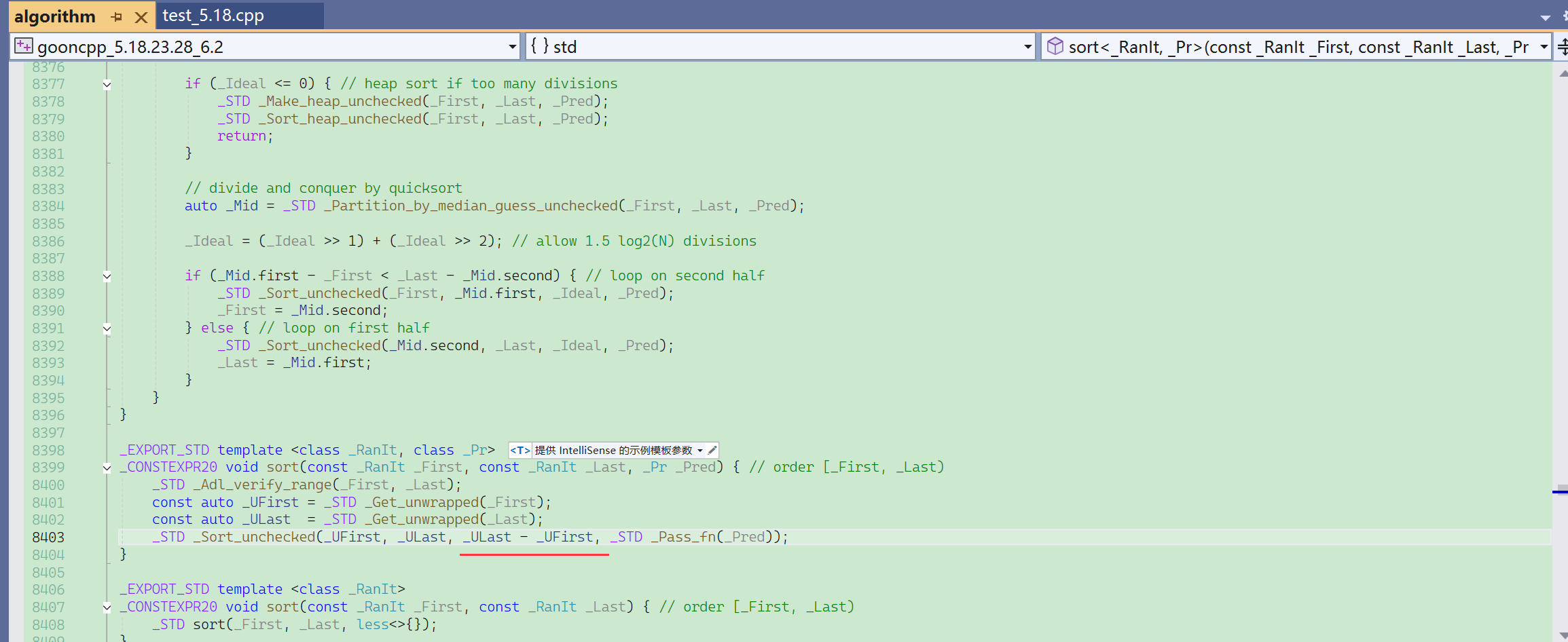
算法库的sort不能排序链表,因为sort的底层是快排,快排需要随机迭代器。
因为快排要走三数取中什么的,必须要支持减。
链表的排序,可以使用自己的成员函数,链表有一些“操作相关的”成员函数,是vector没有的。
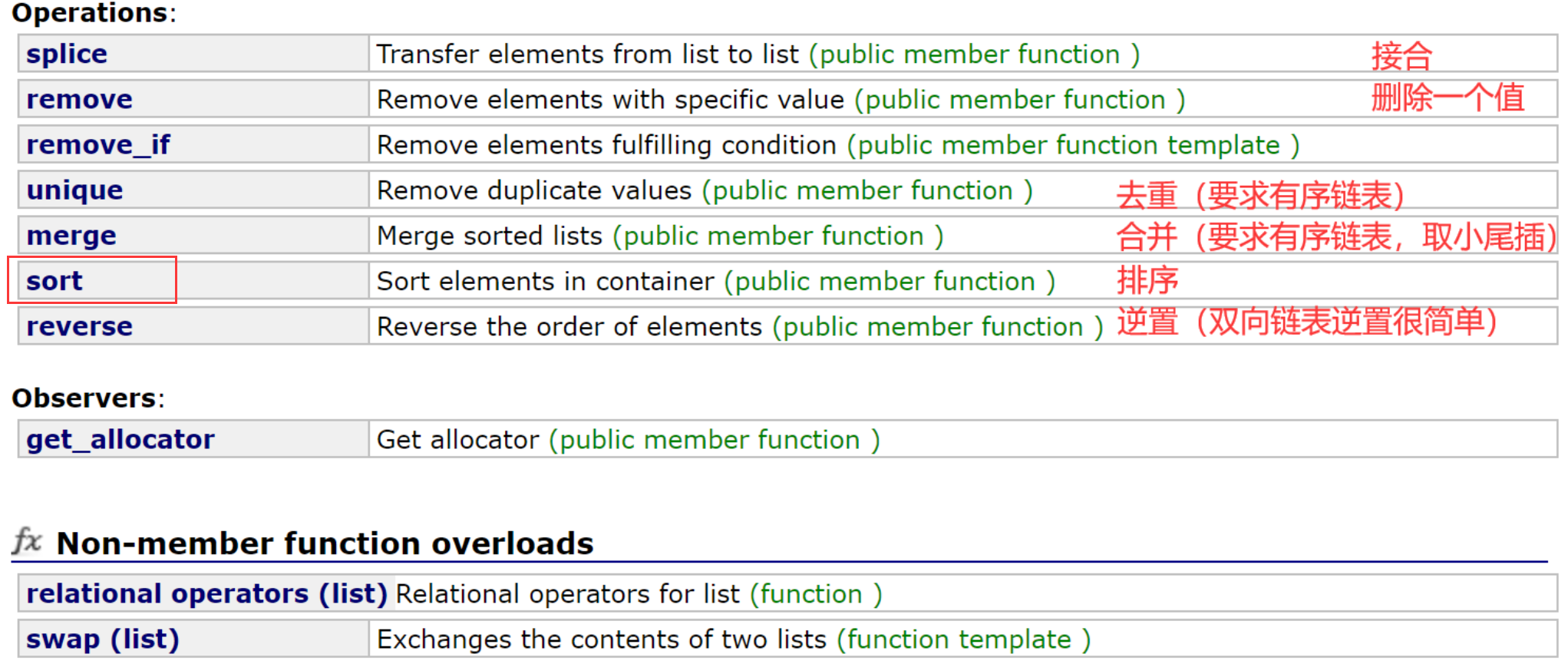
- erase:删除一个特定的位置;
- remove:删除一个特定的值;
排序测试
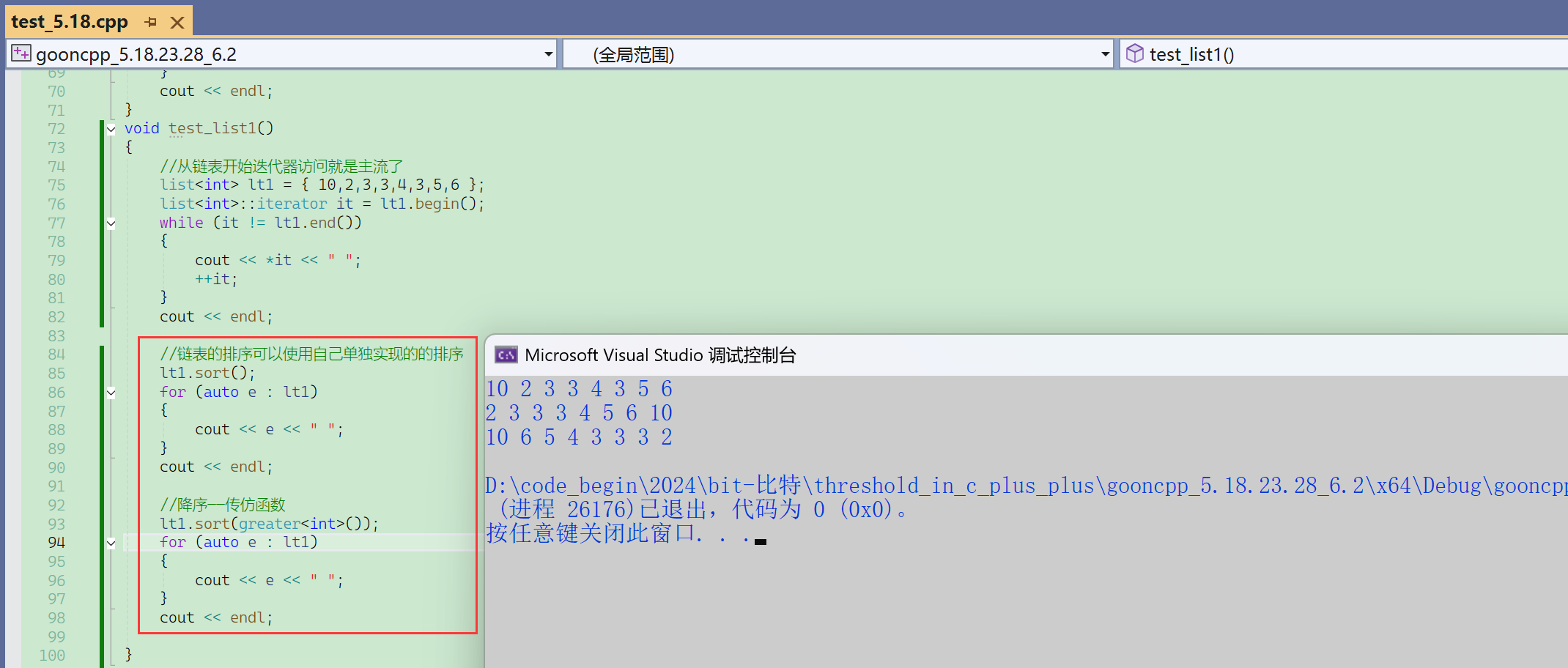
链表的sort底层是归并排序,因为不适合用快排。
去重测试
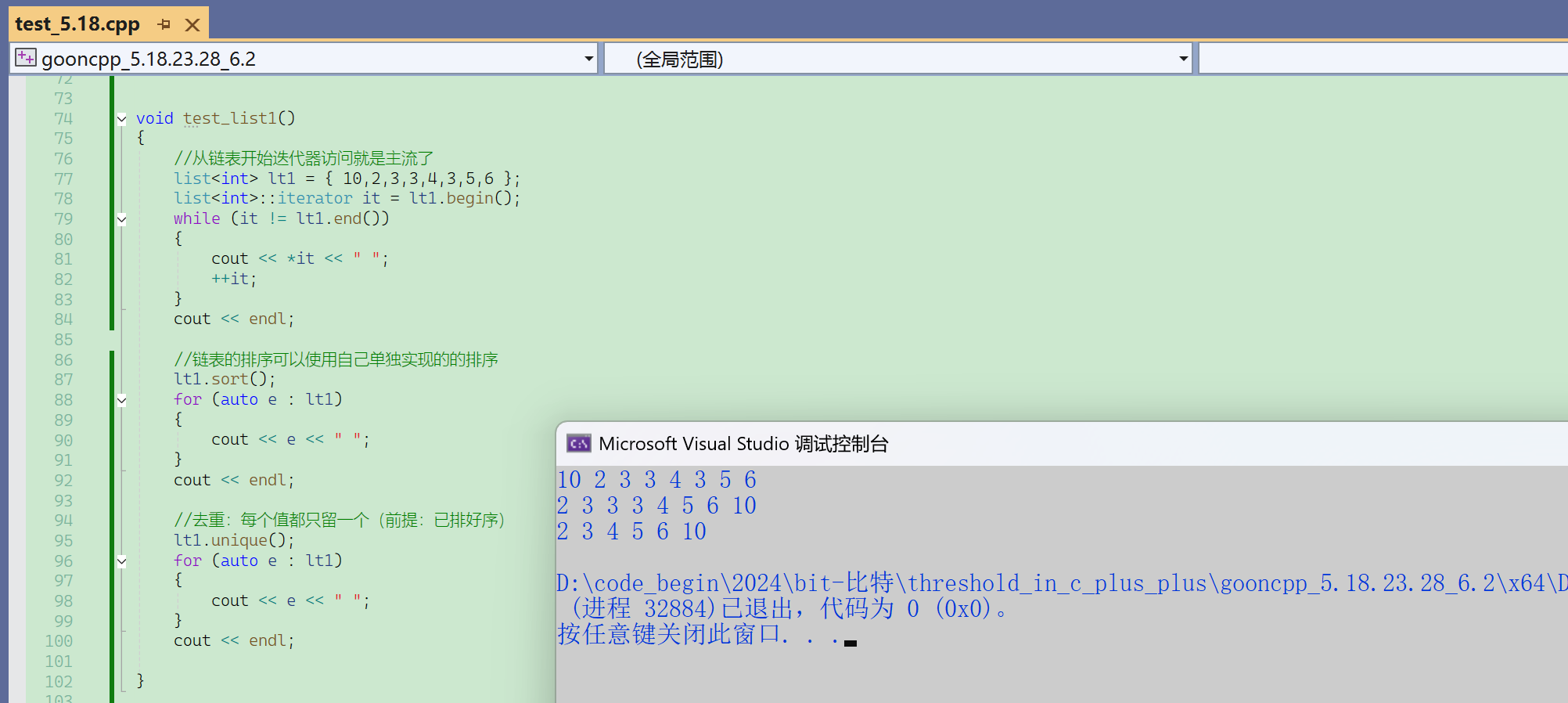

不排序,直接去重,去不干净。
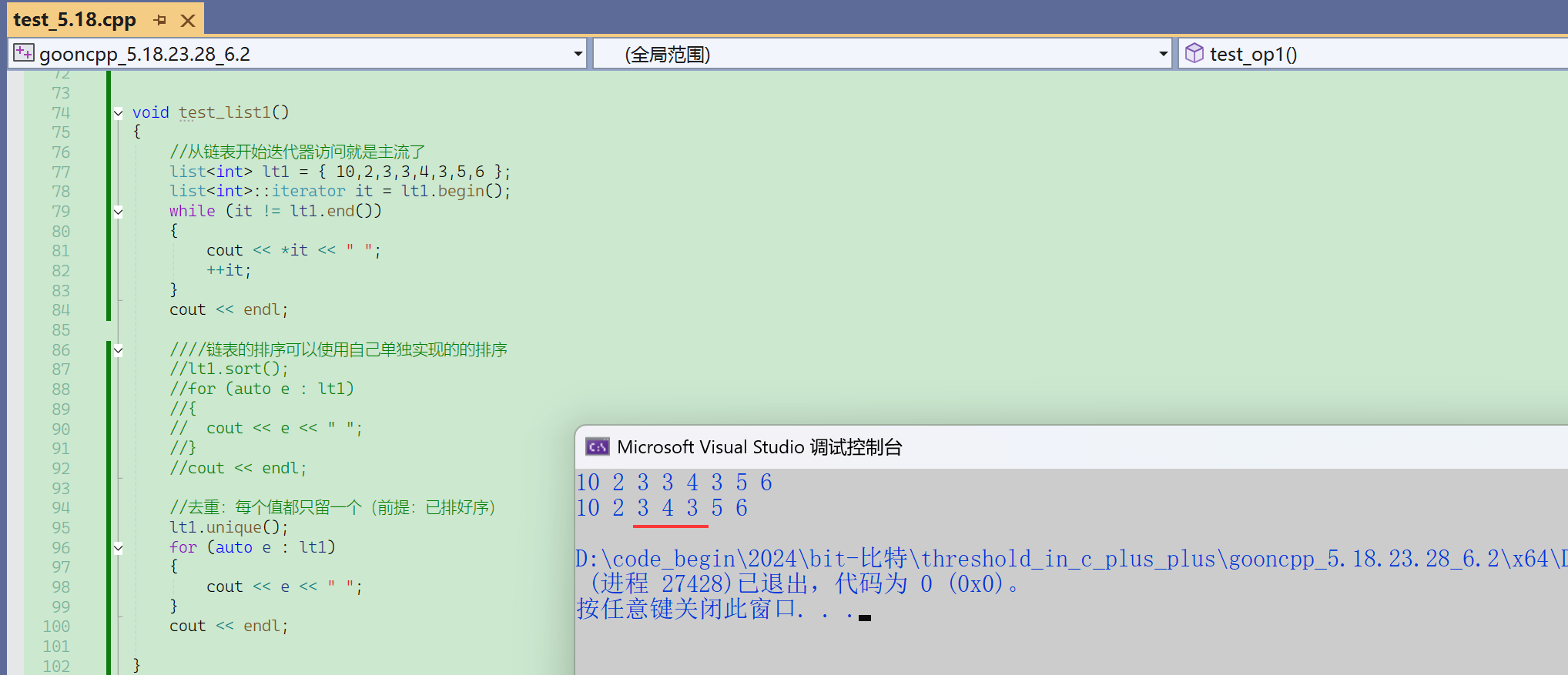
如果无序,但是所有重复的数据都挨着其实也行。
unique()核心的要求就是所有重复的数据都挨着,有序只是其中一种手段。
② test2()
链表这里给了这么多操作,实践中应用却不多,包括链表的排序也是。
因为链表的sort底层是归并排序,效率不高。
- 如果数据量小(不用在乎性能),而且又放在链表里面,用list.sort排序一下也可以。
- 但是如果待排序的数据量大,就最好不要放在链表里面了。
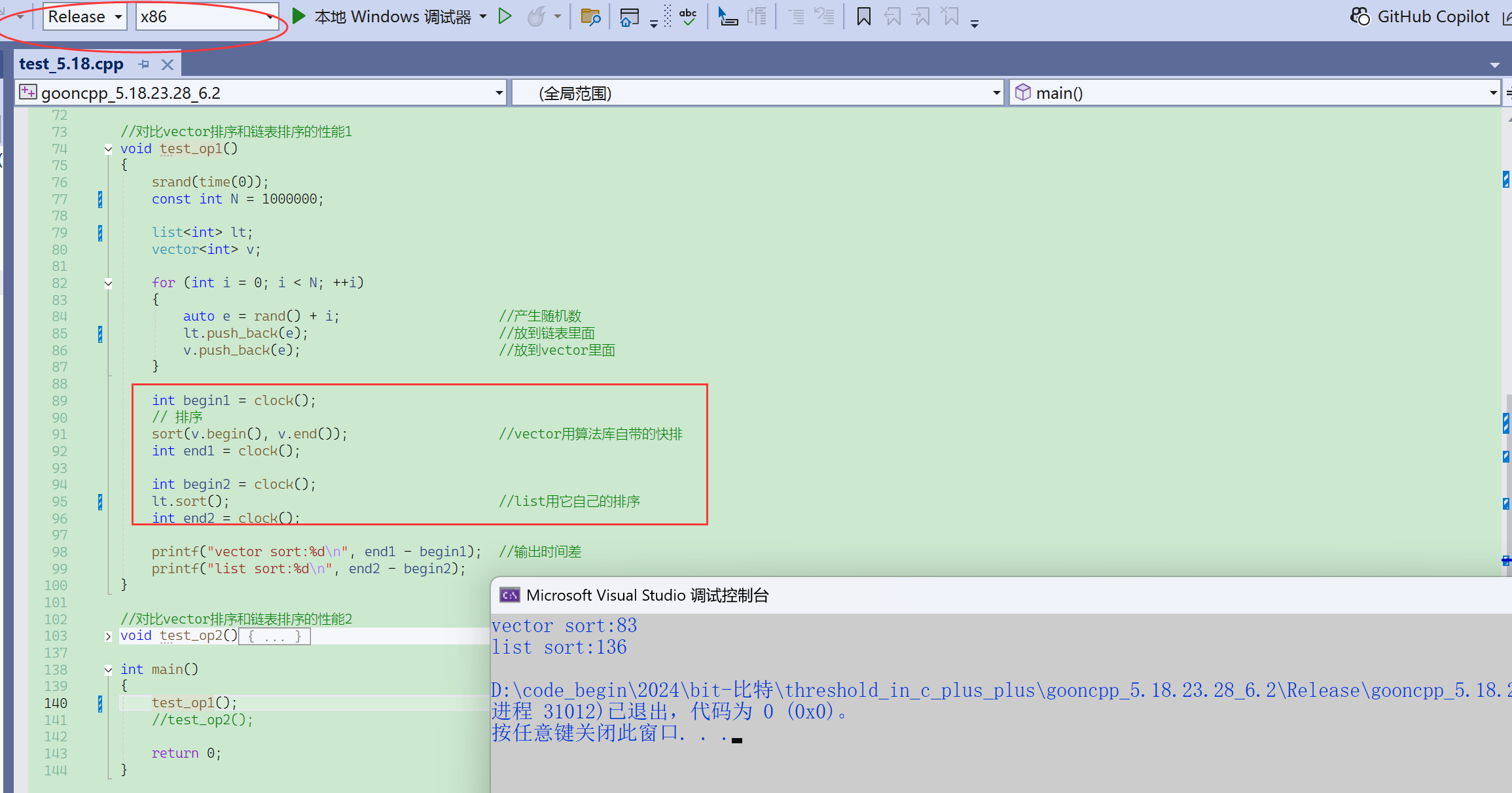
时间复杂度相同,只表示在同一个量级,同一个量级内部,还是有一定的差距的。
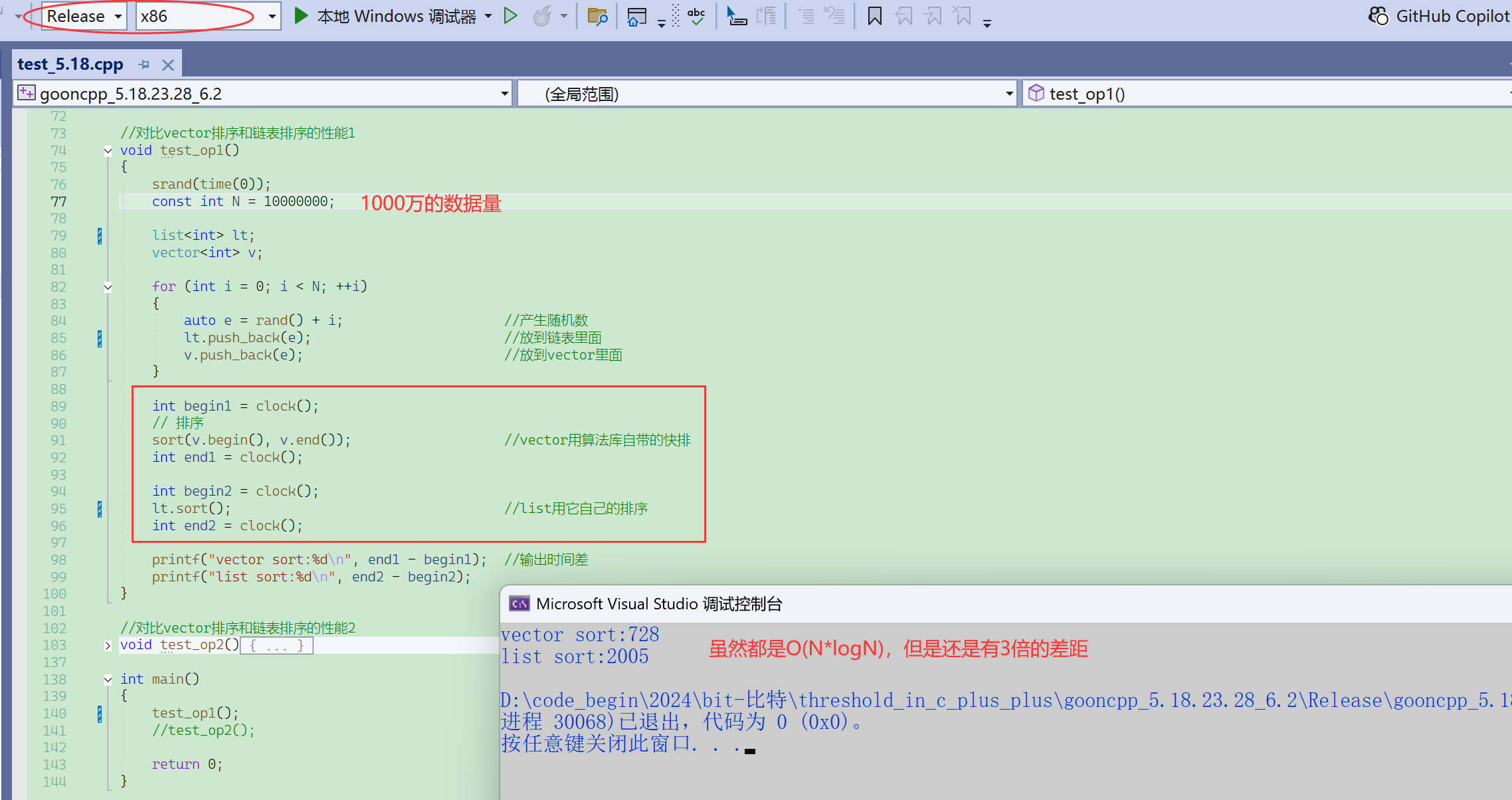
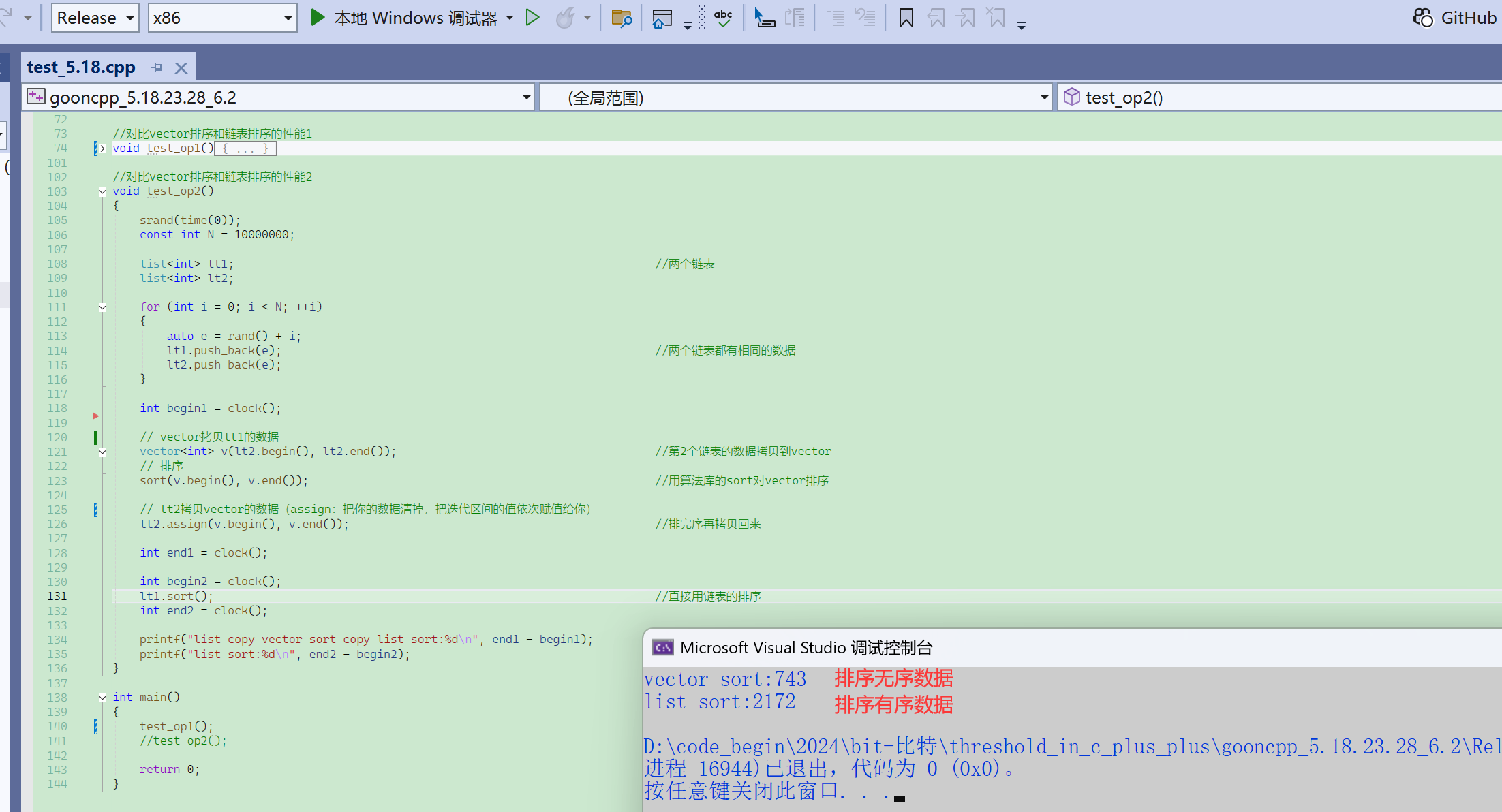
第一个时间是:拷贝+排序+拷贝,才用了链表的排序的1/3的时间。
- 就是说链表的排序,先拷贝到vector,让vector排完了,在拷贝回来,都比list自己排快很多。
- 知道你不行,你拷贝给我,我帮你排完了,再拷贝回给你。
这里的性能差异除了排序算法的差异,还有一个原因就是链表的数据访问确实没那么高效。
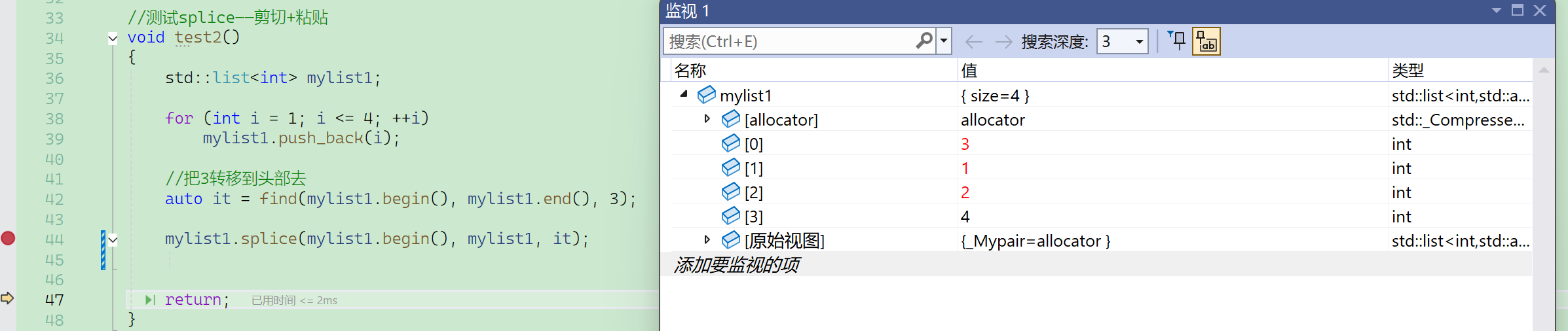
粘接测试-链表间转移
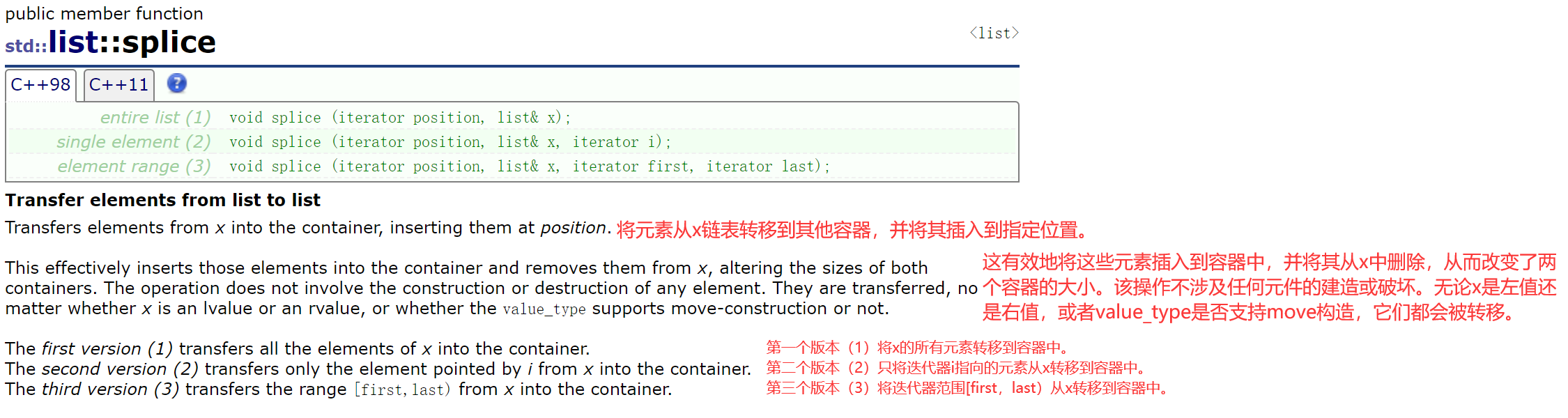
凡是插入position位置的,都是插入到position位置之前。
这个函数不是进行值插入,而是直接进行结点的转移。
① 将x链表的所有结点转移到新容器。
② 将x链表的i位置到结尾的所有结点转移到新容器。
③ 将x链表的[first,last]位置的所有结点转移到新容器。
这个函数用得不多,有些地方会比较好用,所以直接用官网的例程进行测试。

需要注意的是,list2虽然空了,但是这个对象还在,它的生命周期还没结束,只是它管理的结点全部被移走了。
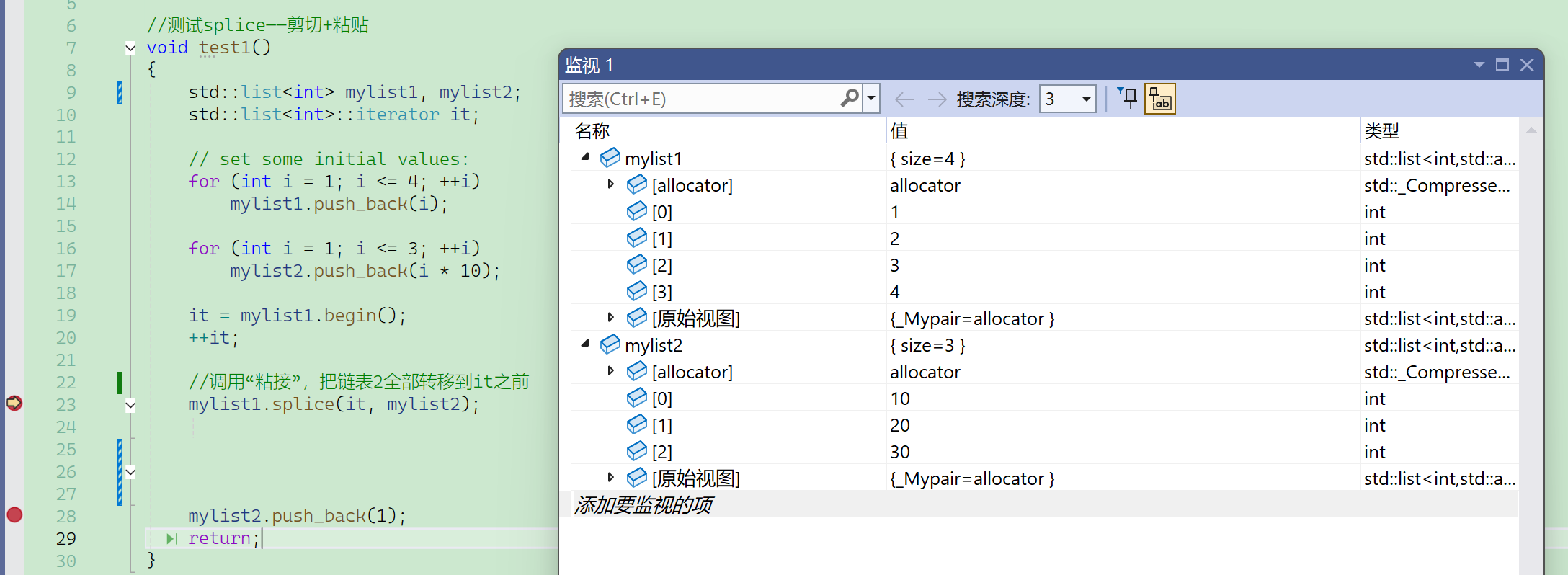
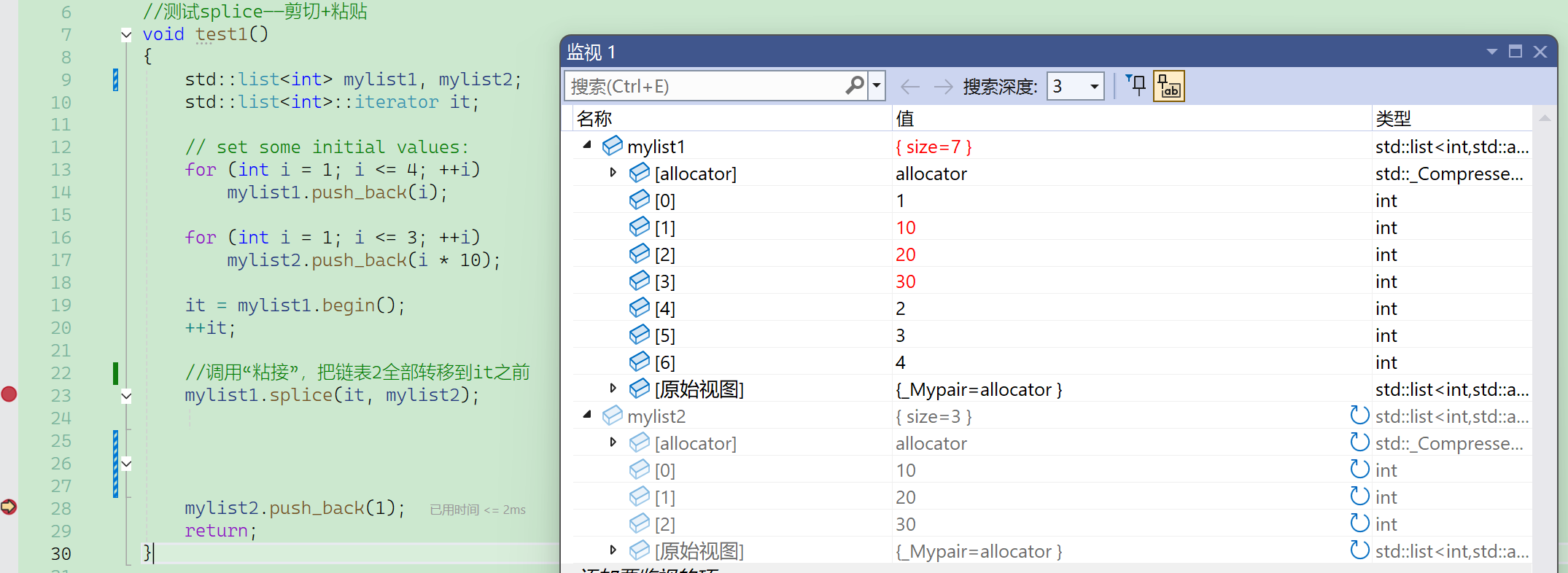
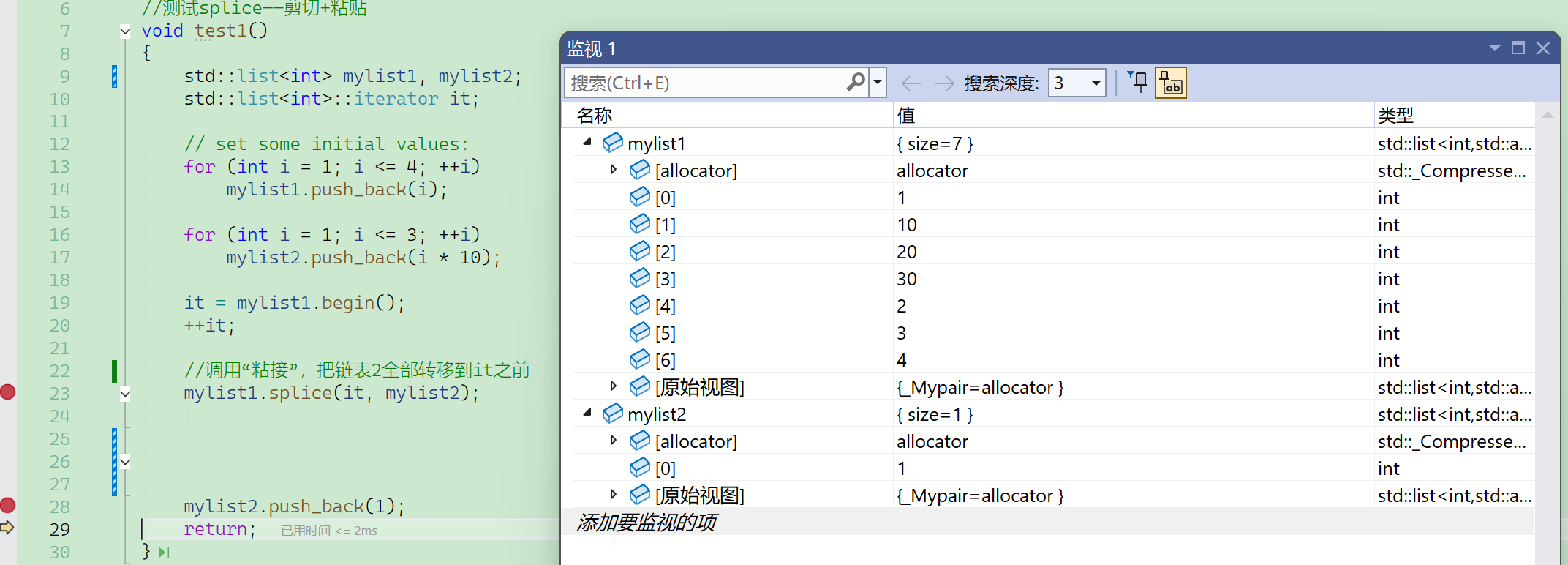
注意到这里mylist2变灰了:
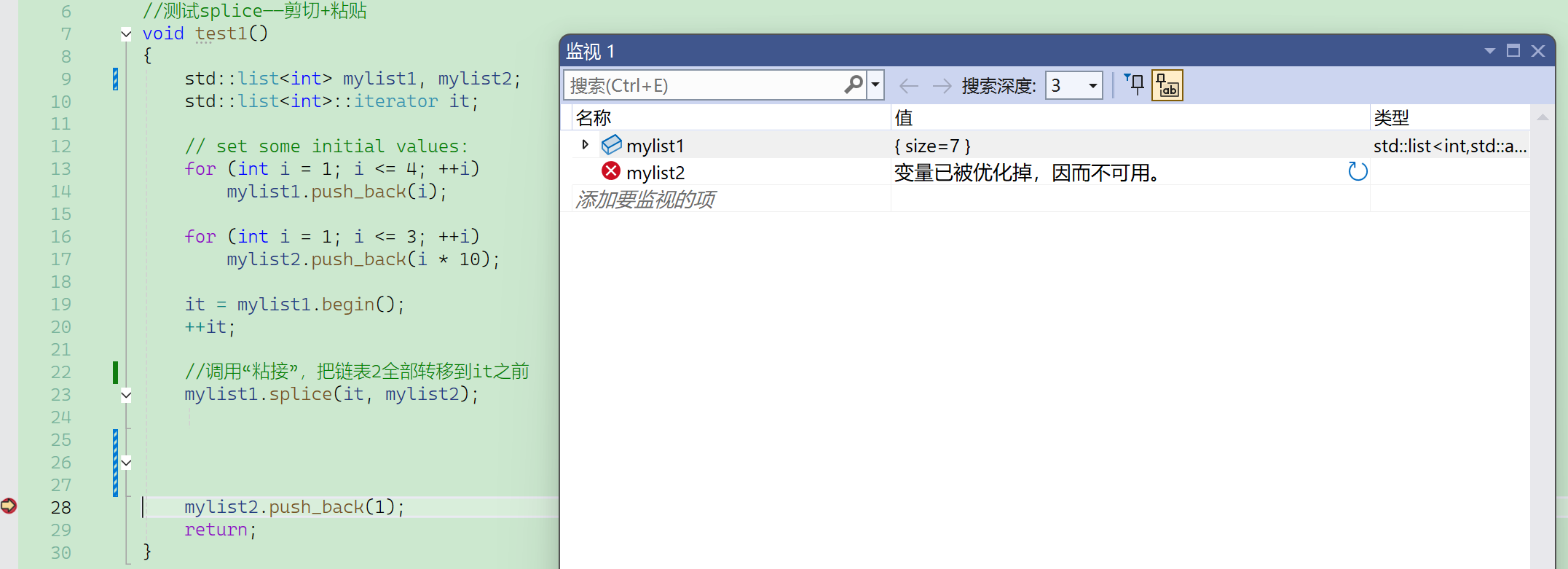
这是VS2022的优化,VS2019还没有。
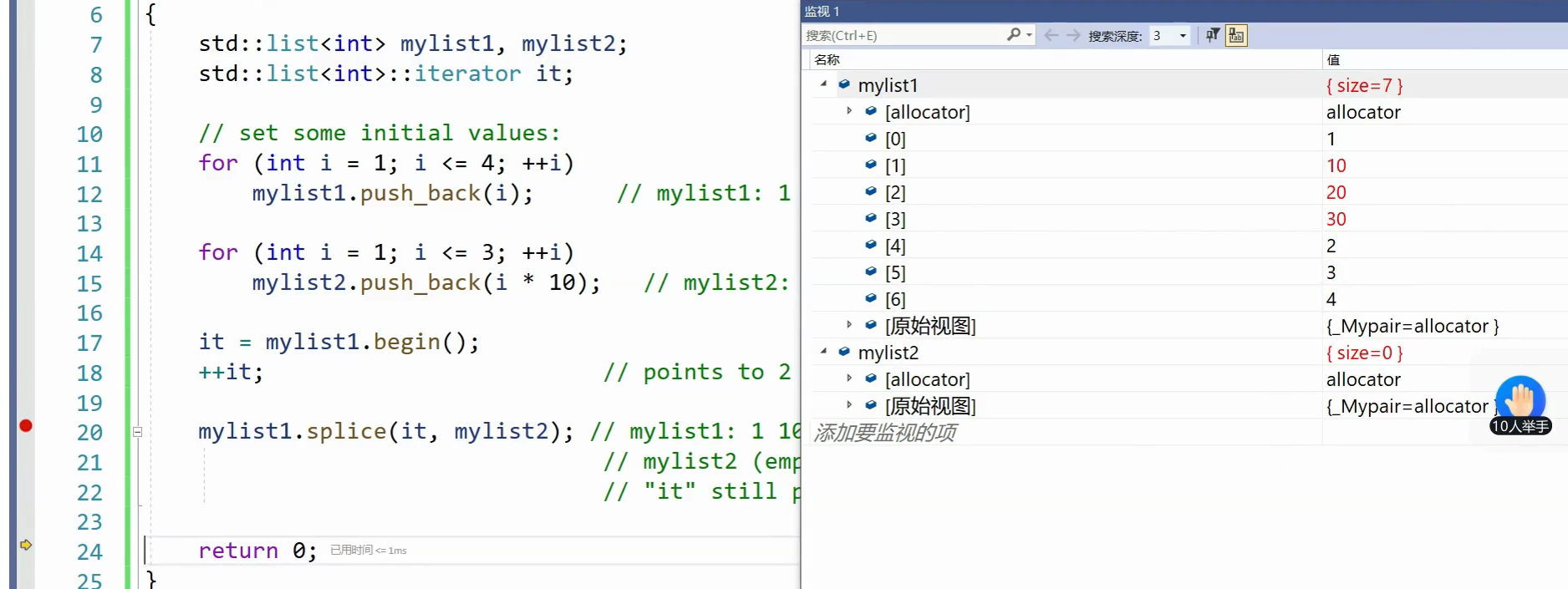
粘接测试-链表内转移

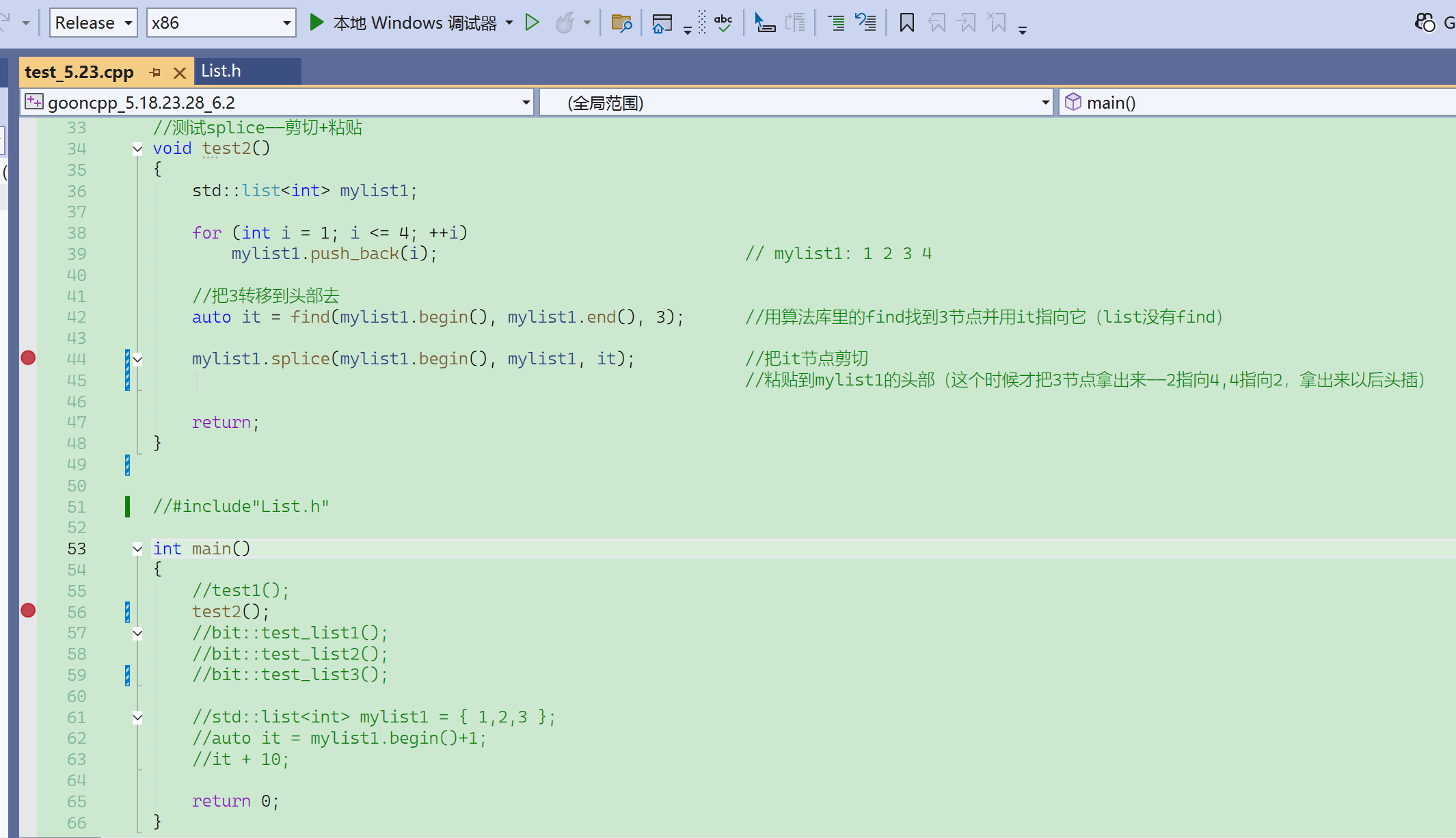
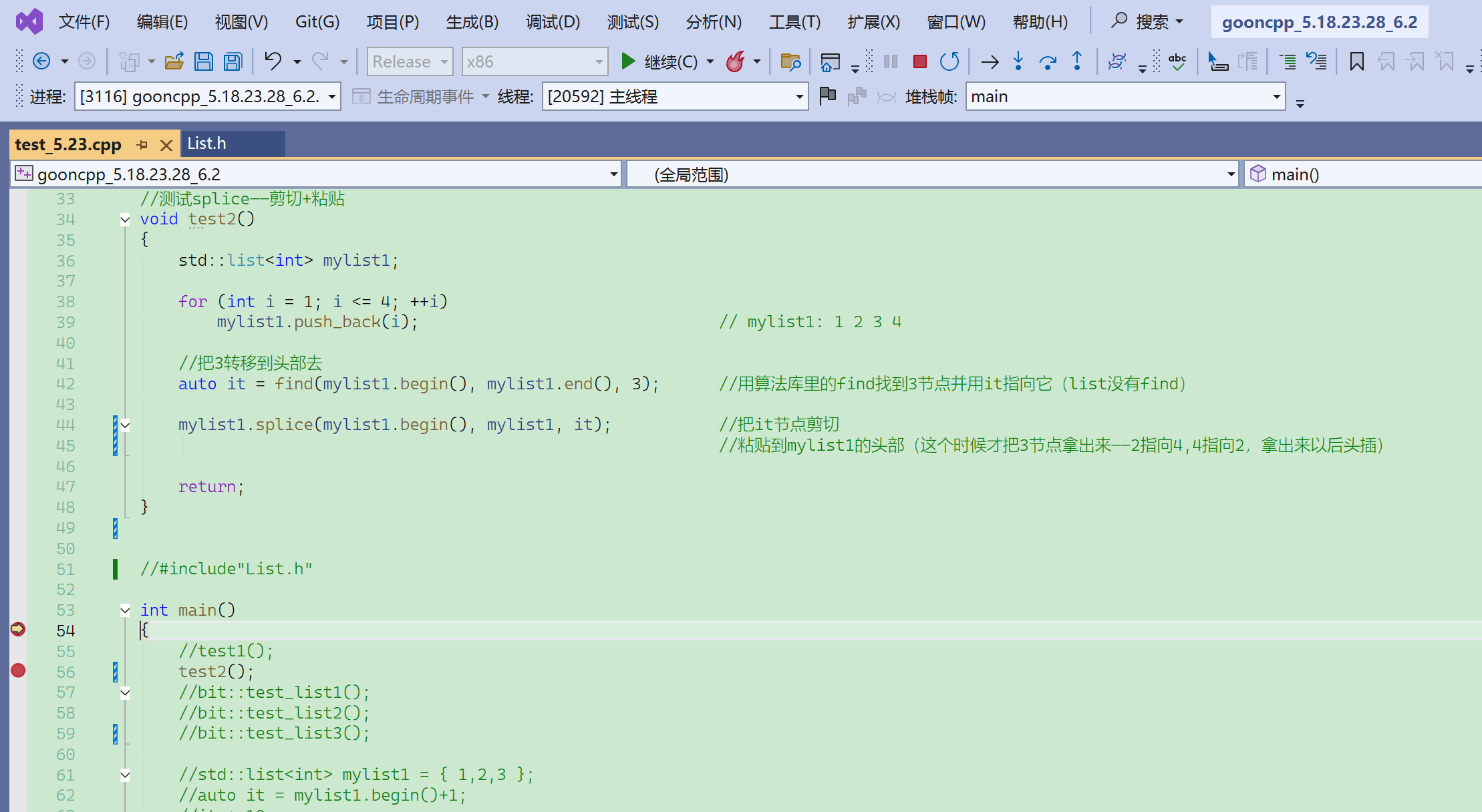
断点自动移位,在test2()按f11也进不去。

1.2.6 list的迭代器失效
前面说过,此处大家可将迭代器暂时理解成类似于指针,迭代器失效即迭代器所指向的节点的无效,即该节点被删除了。
因为list的底层结构为带头结点的双向循环链表,因此在list中进行插入时是不会导致list的迭代器失效的,只有在删除时才会失效,并且失效的只是指向被删除节点的迭代器,其他迭代器不会受到影响。
void TestListIterator1()
{int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };list<int> l(array, array+sizeof(array)/sizeof(array[0]));auto it = l.begin();while (it != l.end()){// erase()函数执行后,it所指向的节点已被删除,因此it无效,在下一次使用it时,必须先给
其赋值l.erase(it); ++it;}
}// 改正
void TestListIterator()
{int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };list<int> l(array, array+sizeof(array)/sizeof(array[0]));auto it = l.begin();while (it != l.end()){l.erase(it++); // it = l.erase(it);}
}2. list的模拟实现
2.0 源码剖析
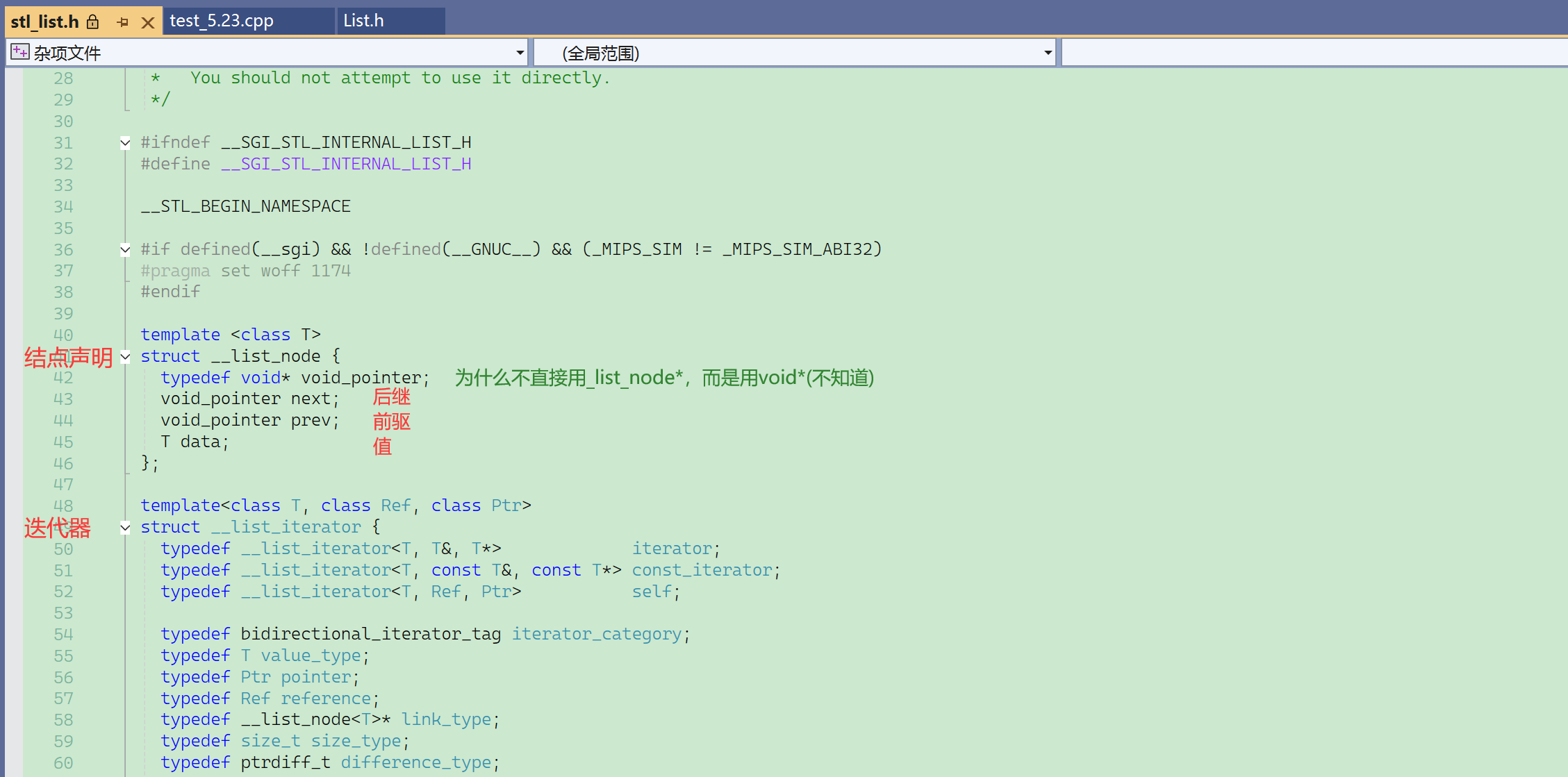
给成void*,用的时候还要强转,自己实现的时候直接给成list_node*就可以了。
另外,注意到这里类的声明使用的都是struct。
下面链表类的声明才是使用class。
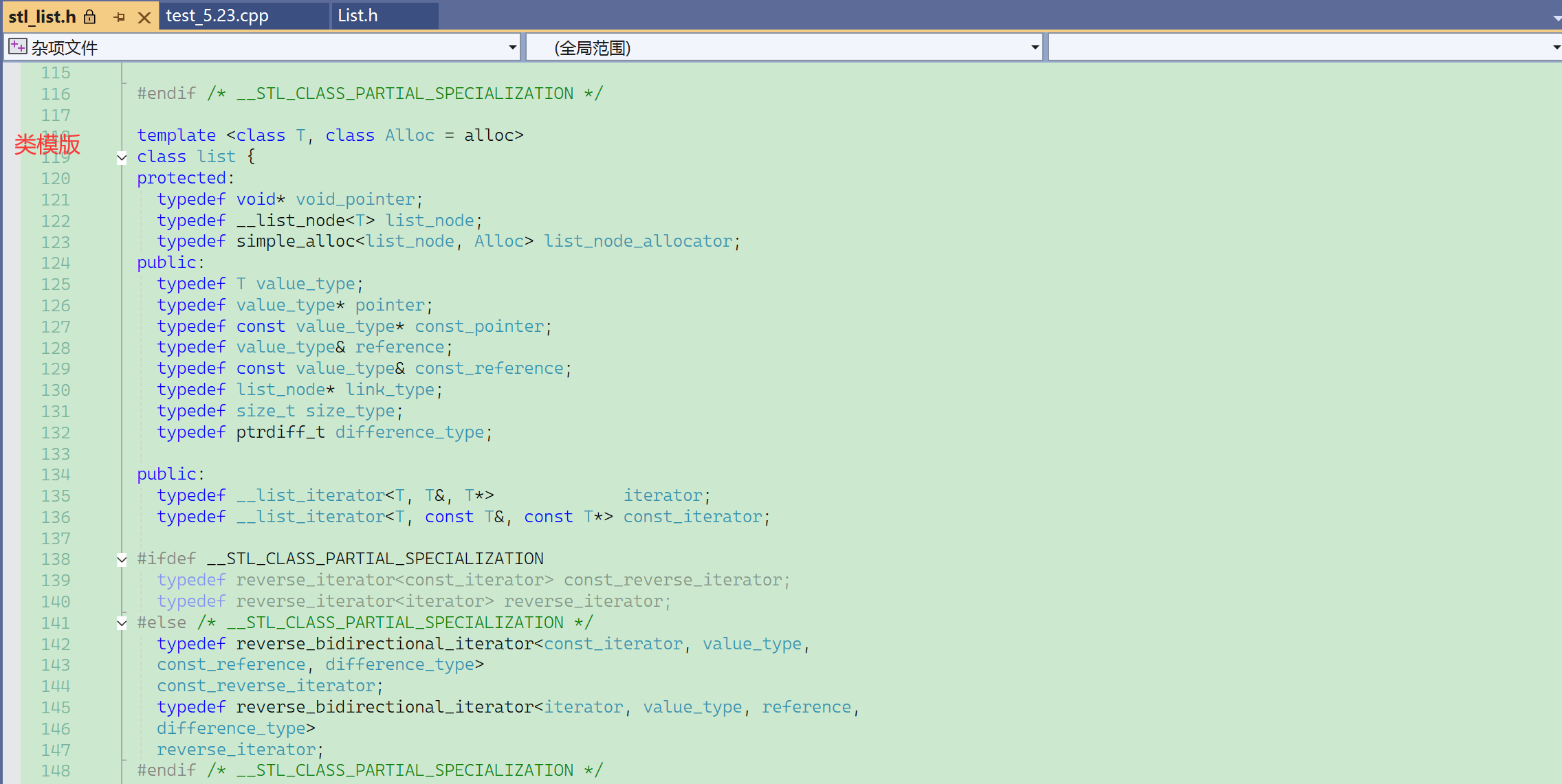
看一个类,首先要去看它的框架,而不是去看细节。
- 成员变量;
- 构造函数;
- 插入;
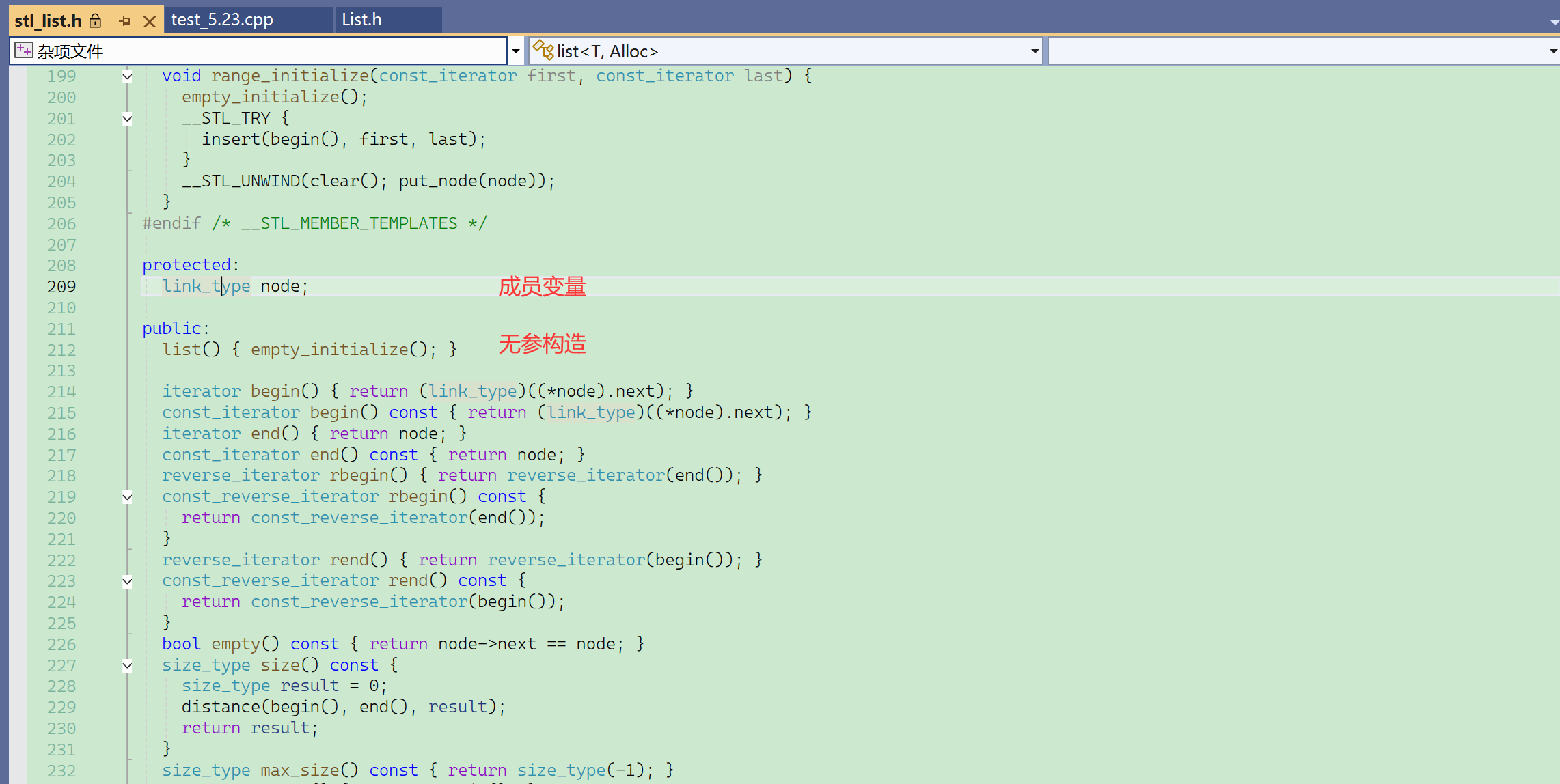
就一个成员变量(成员指针、结点指针),这个类型的含义可以使用“转到声明”进行查看。
无参构造里面调用的函数的具体作用,可以使用“转到定义”进行查看。
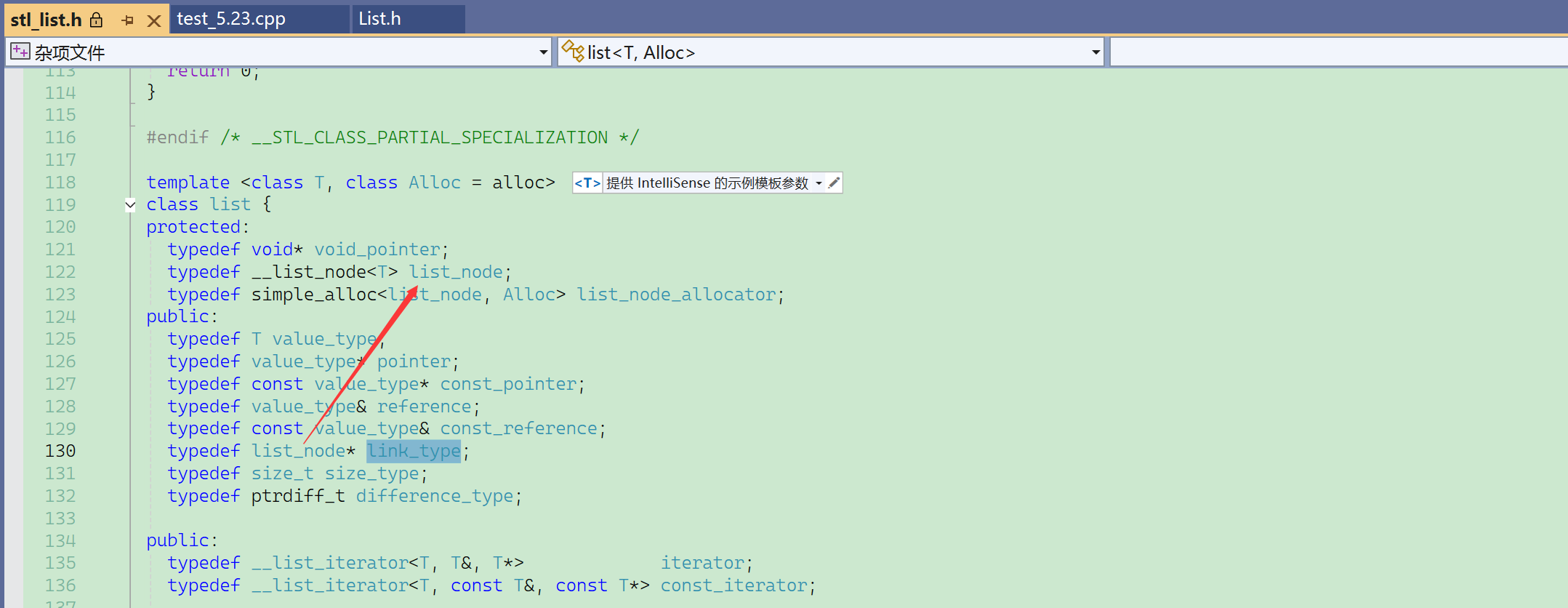
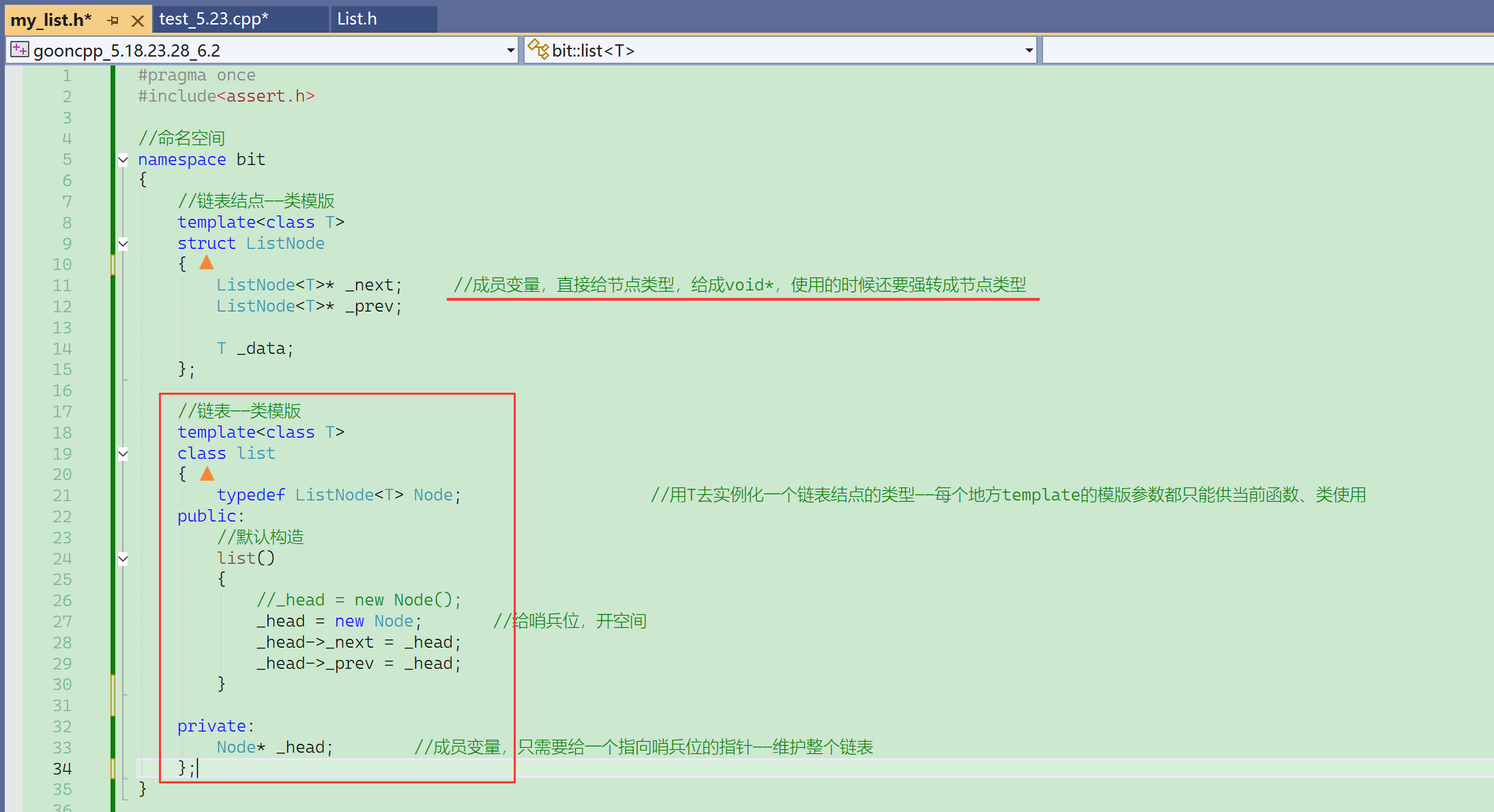
typedef了两层:先把节点类模版重命名。
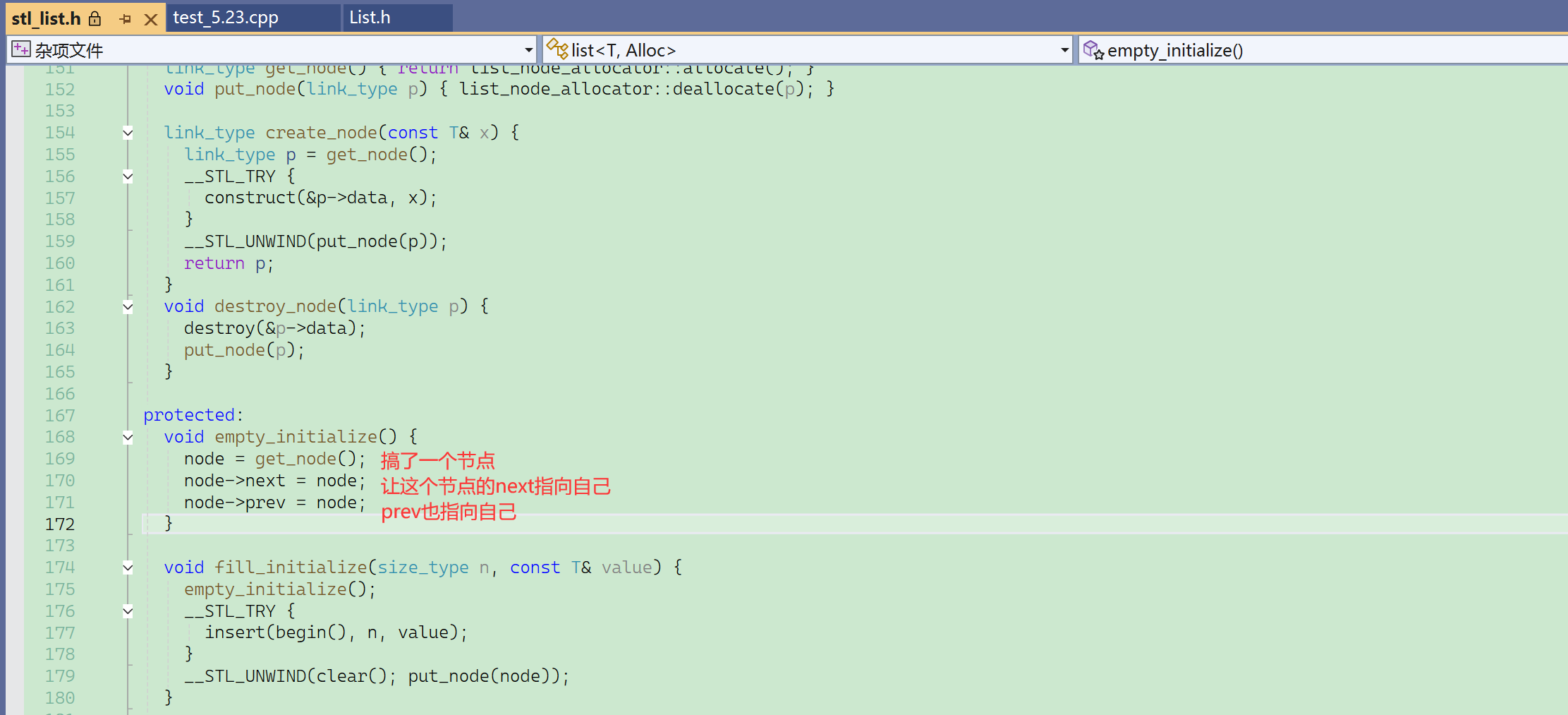
实际上链表的默认初始化就是给了一个哨兵位的头结点。
再来看看这个get_node的转到定义。
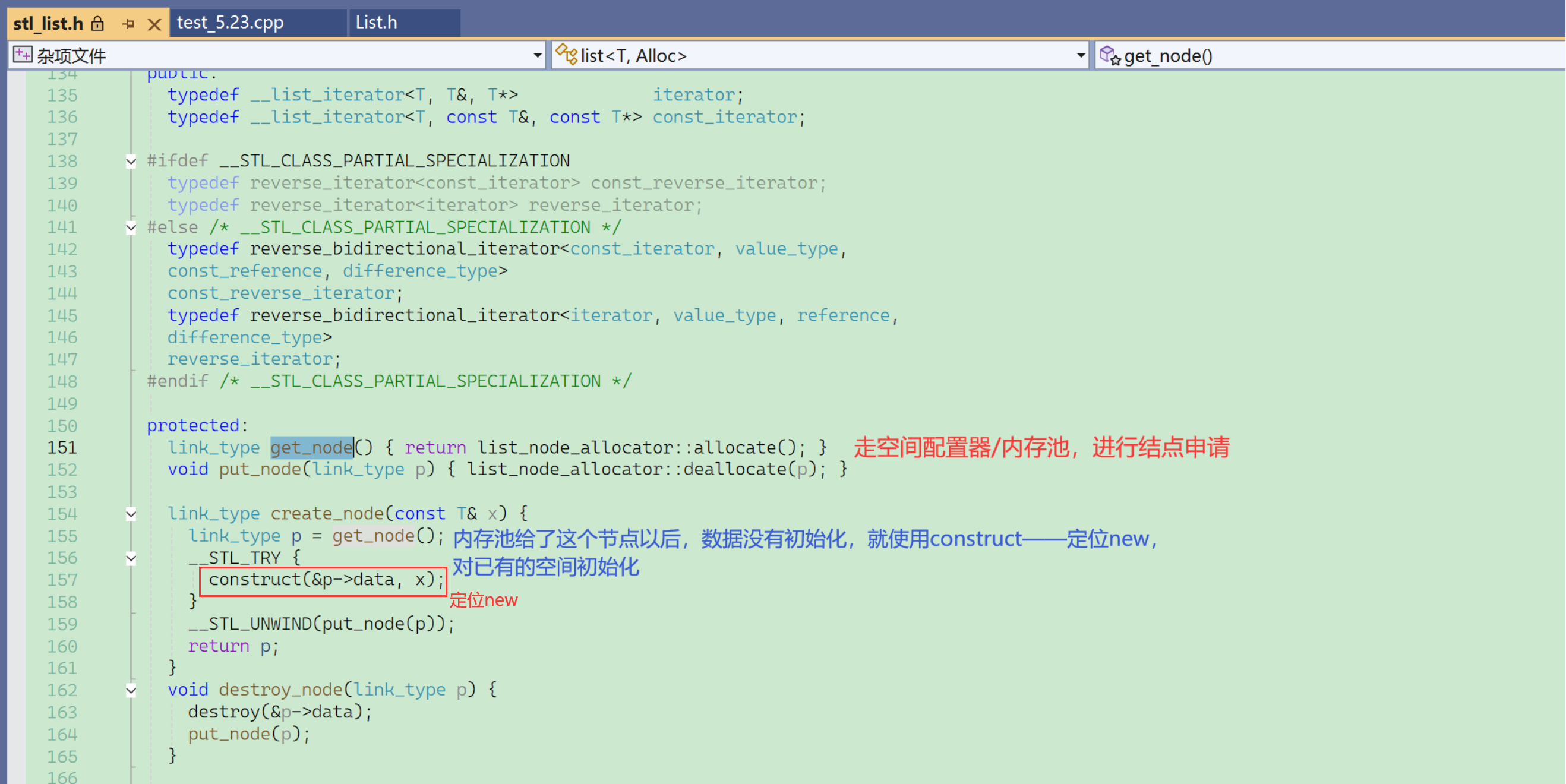
按我们的习惯,申请空间是用malloc或new,但这里是走了一个空间配置器。
C++的STL的所有容器的申请和释放空间,都是走内存池,因为效率方面的考虑。
allocate和construct后面会细看,现在就不再深入地看了。
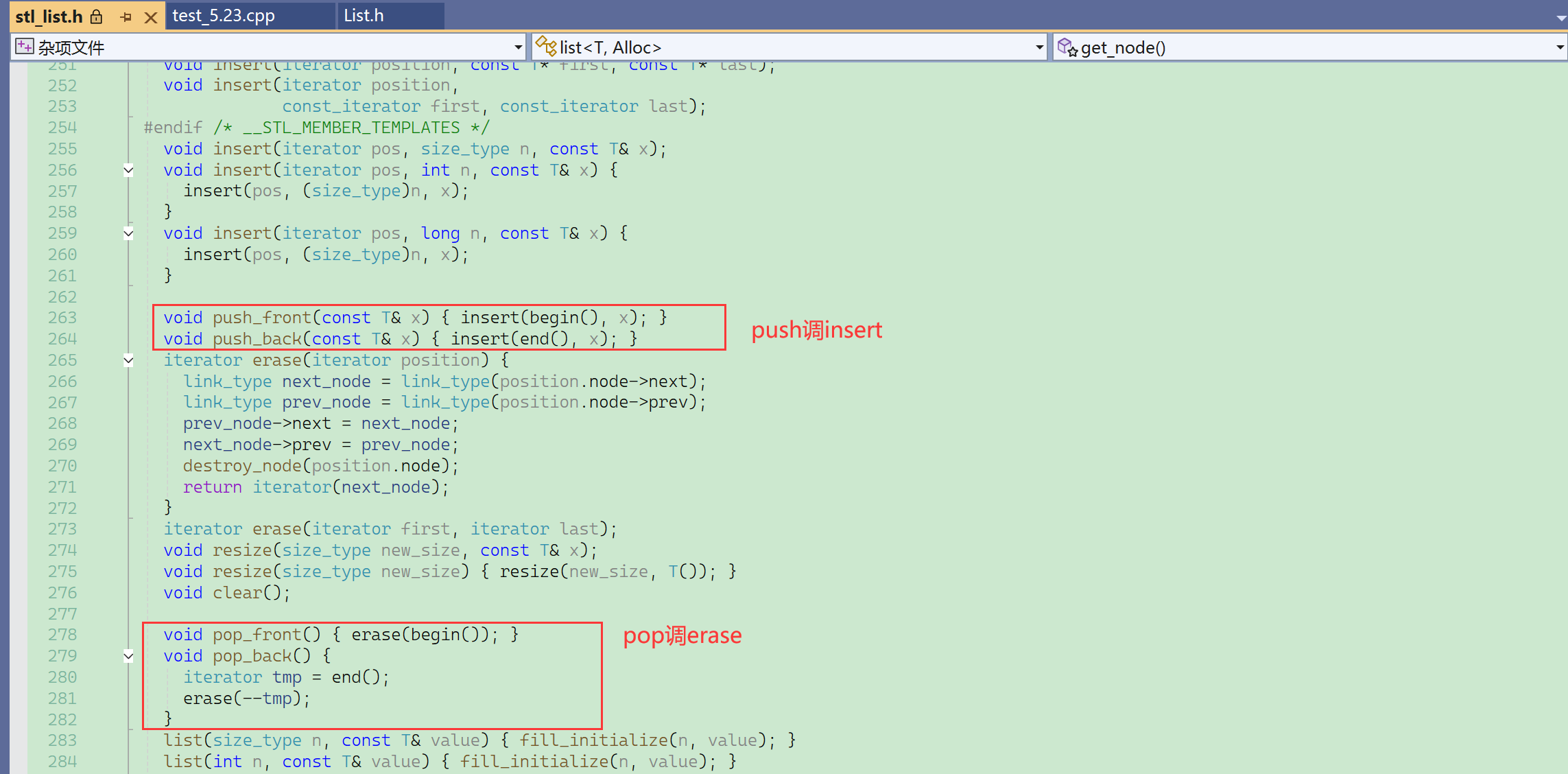
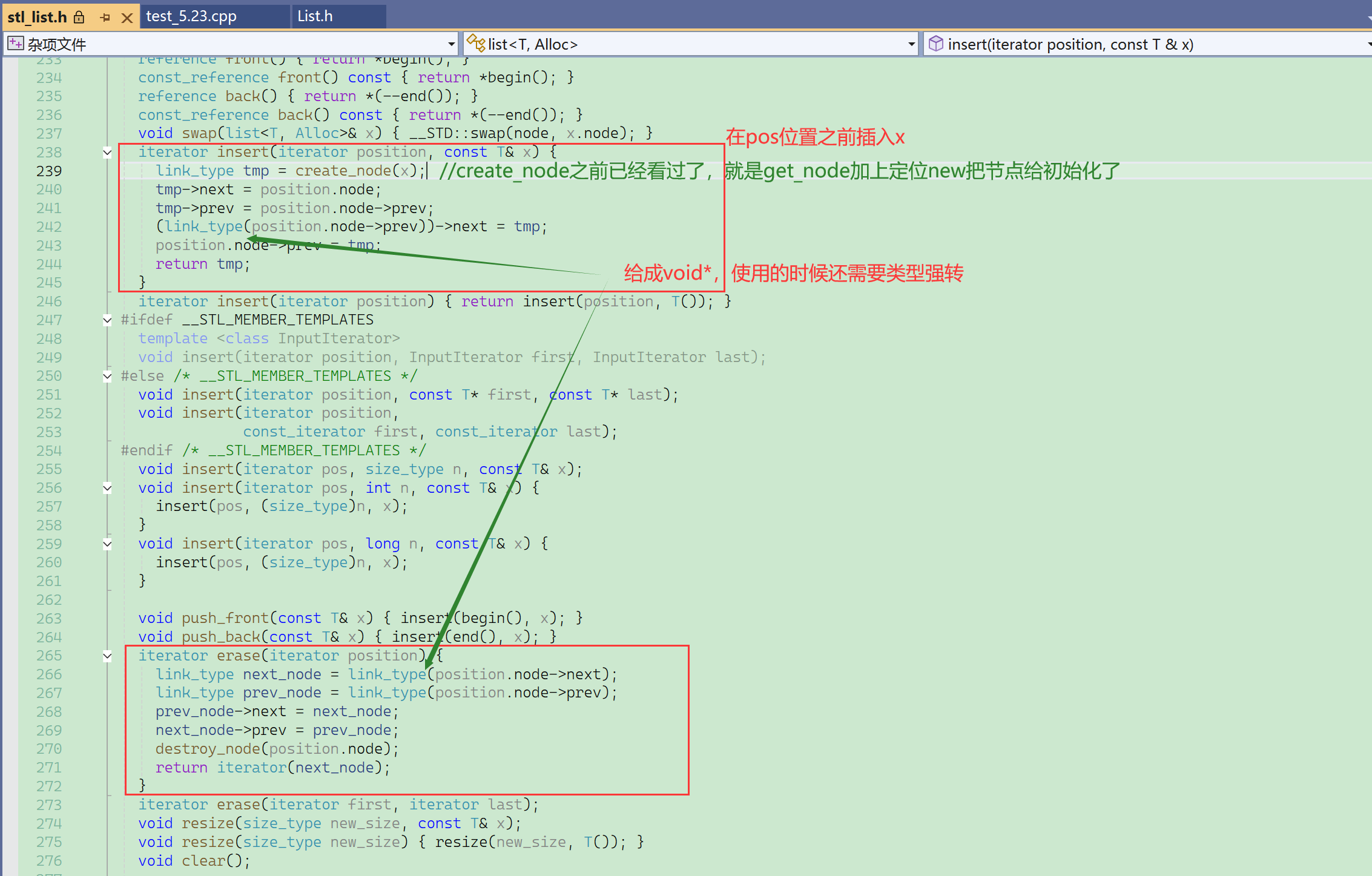
create_node就相当于new node,只不过就是向内存池拿还是向内存拿的区别。
然后就是4行代码进行链表结点插入时的指针的链接。
之前有带头双向循环链表的基础,这块就不再带着大家细看了,直接先上手搭一个链表的框架出来。没有内存池,就直接new就好了。目的只是动态开辟节点。
2.1 模拟实现list
2024.5.23
不需要完全按照这份源码版本来写,可以作一些细节上的修改。比如原版的那么多typedef,就没必要那么细致地跟着它走。
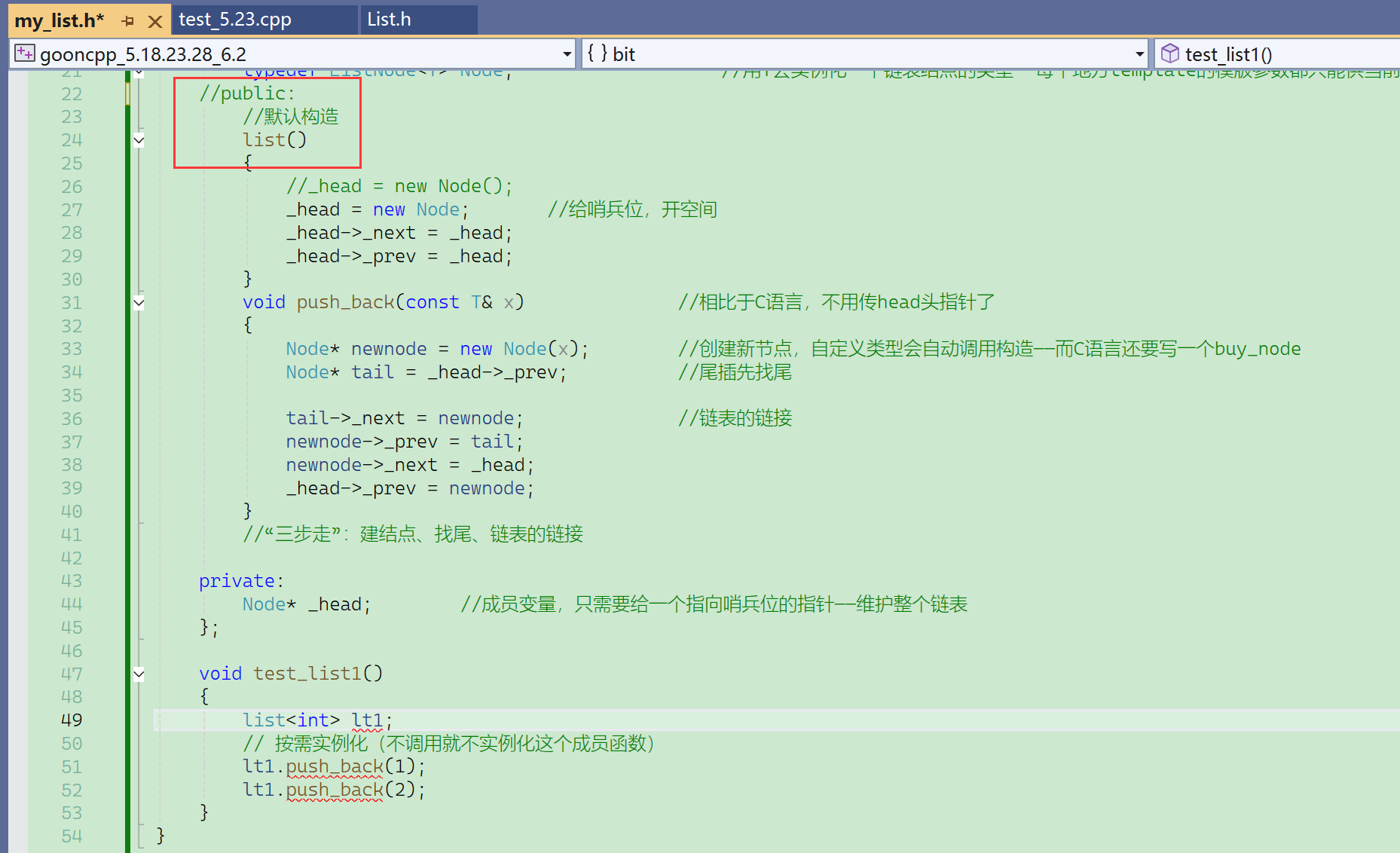
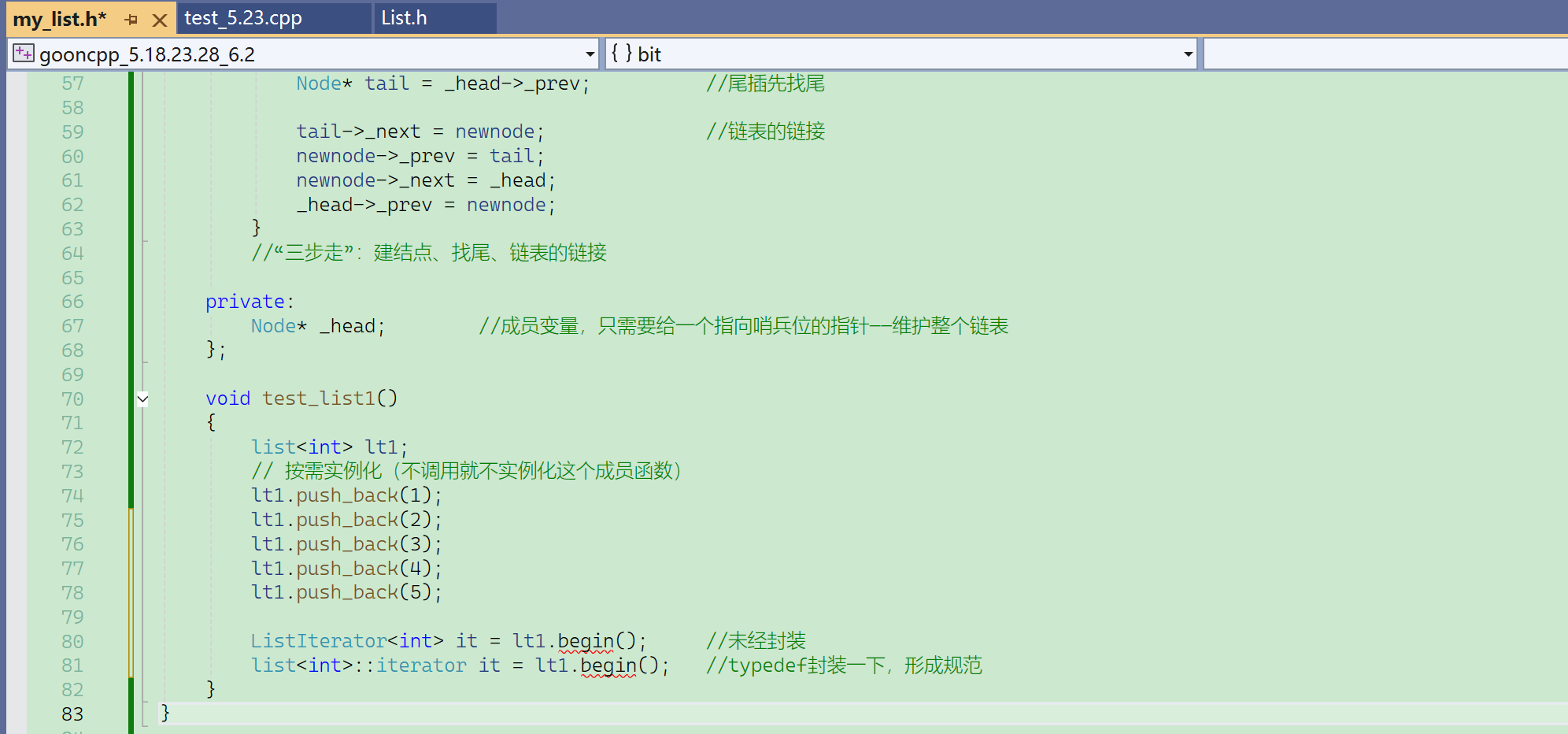
① 默认构造
② push_back
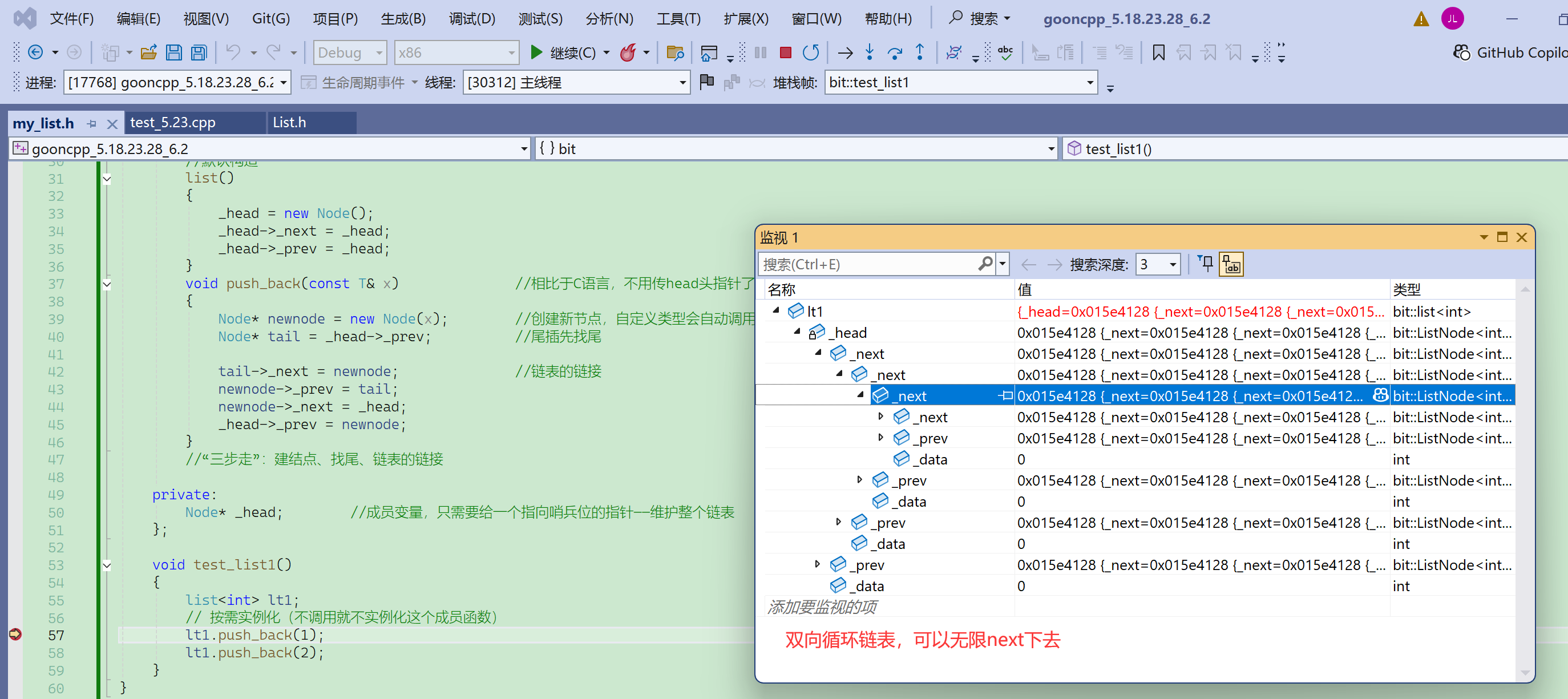
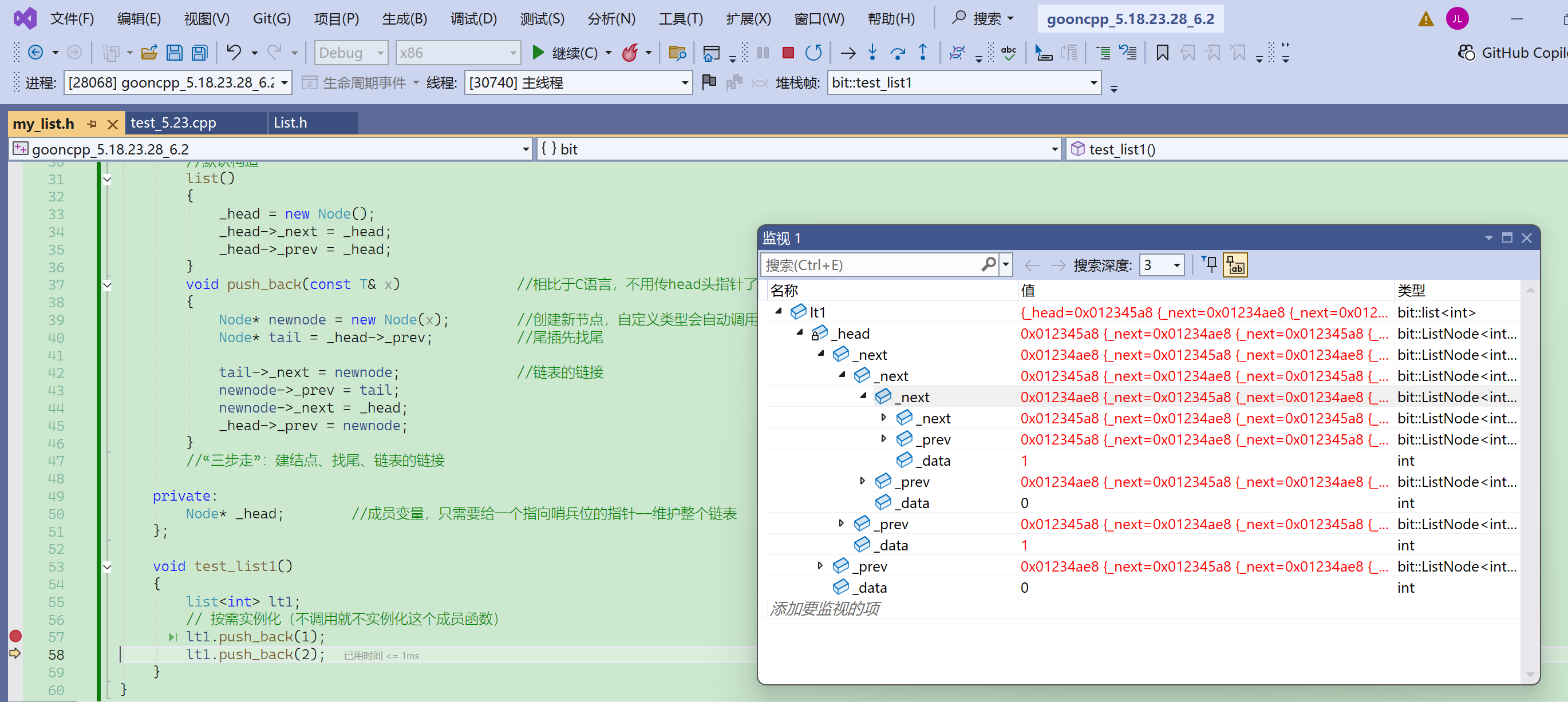
把链表实现成类,那么定义push_back的时候就不需要传二级指针了。
流程:找尾→创建新节点→指针链接。
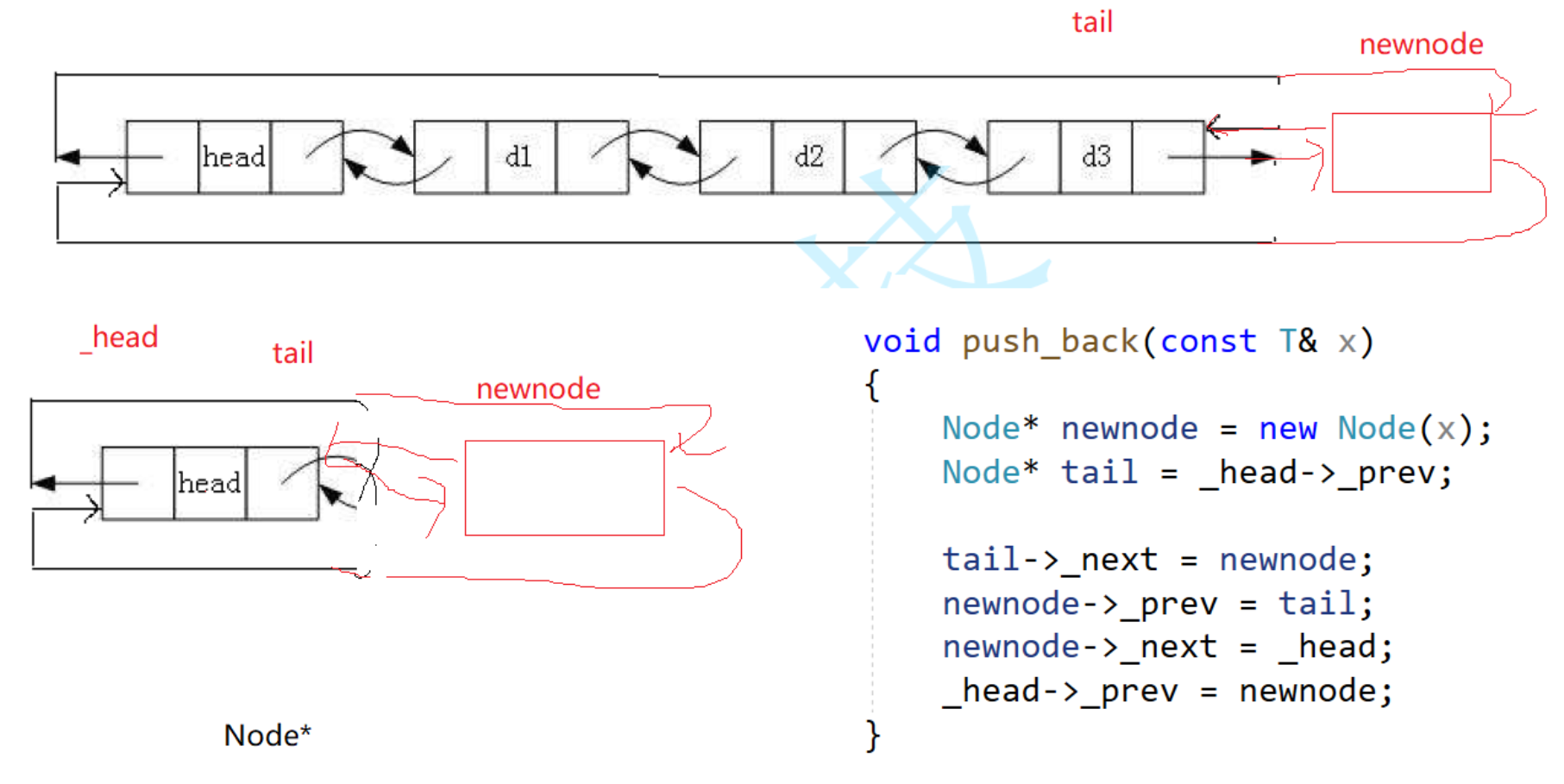
有哨兵位,那么就不需要判断链表为空。
突然忘了new Node(x)的用法了:
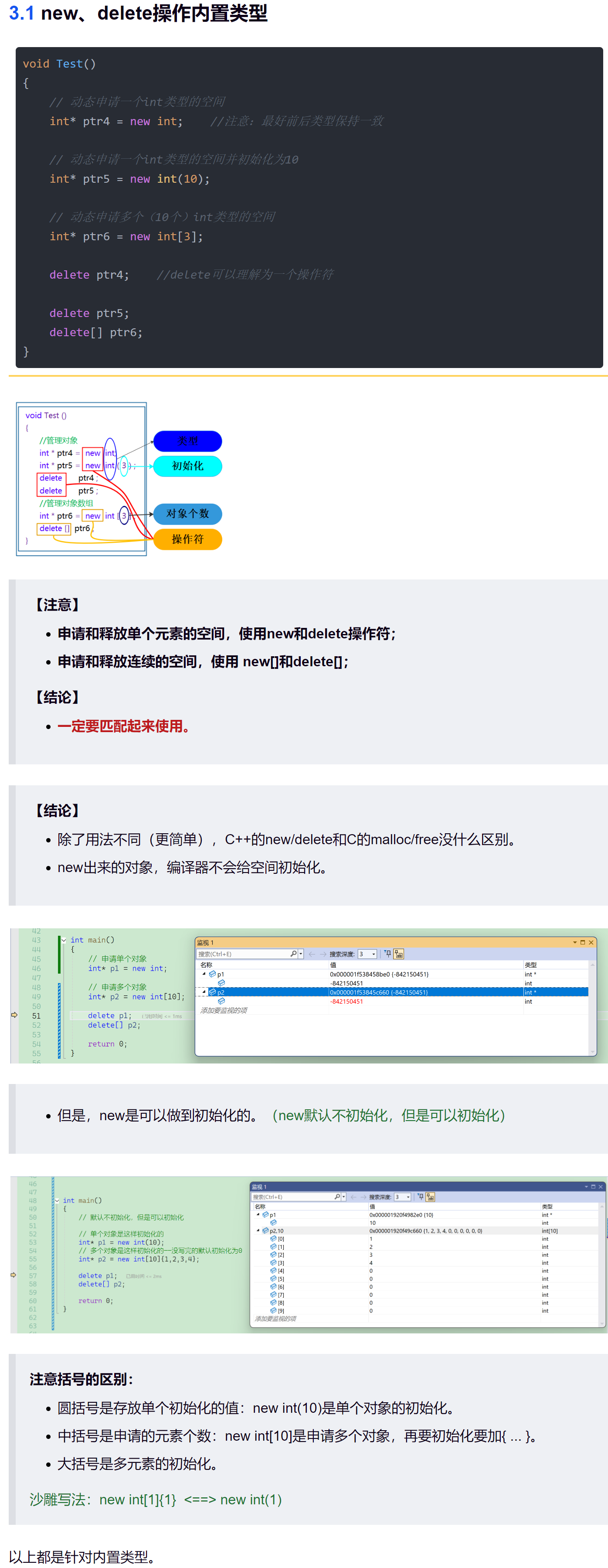
可以看到这里,push_back的实现,相比于C语言,不用传head头指针了。
创建新节点,自定义类型会自动调用构造——而C语言还要写一个buy_node。
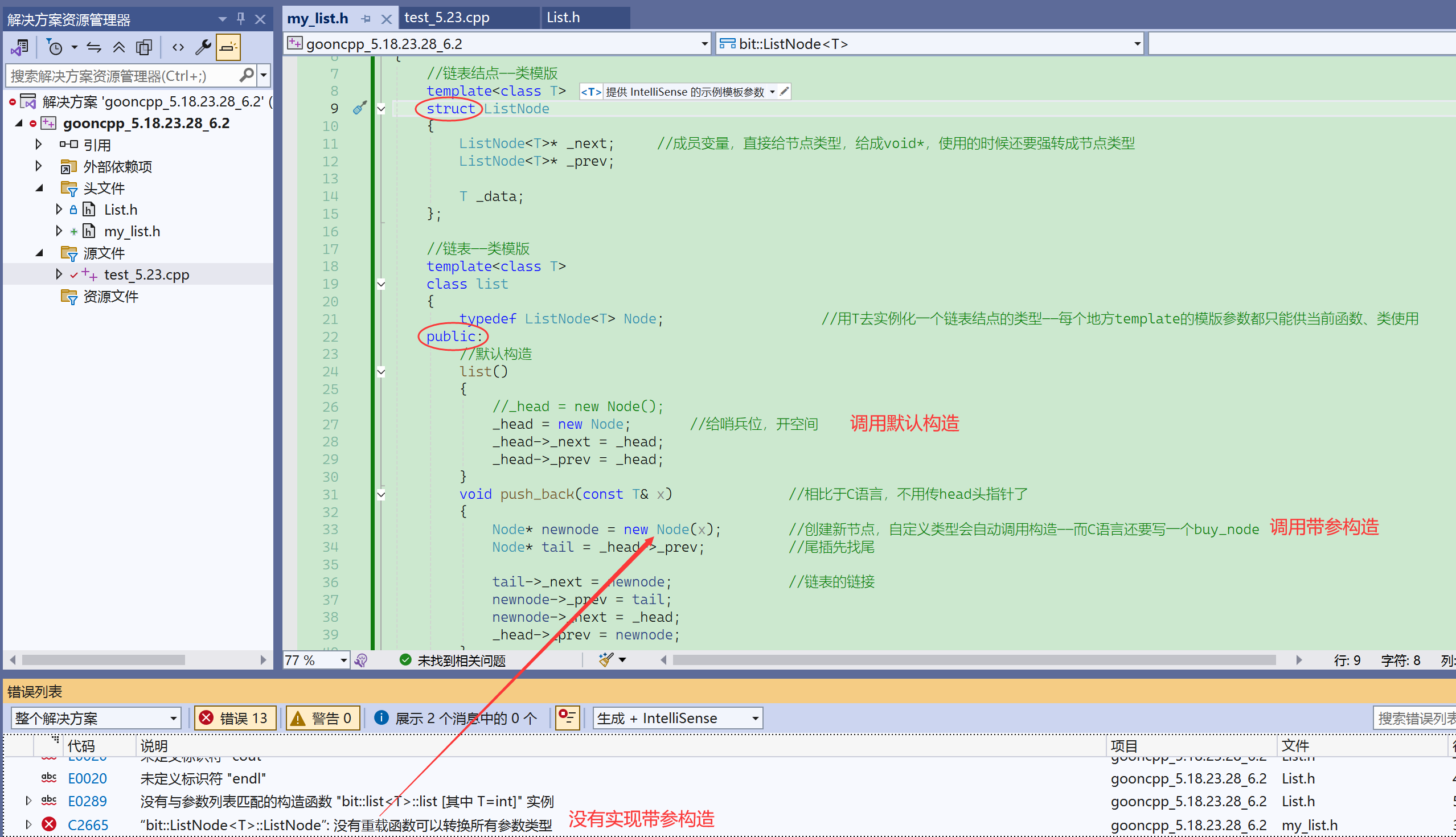
来看看用class会出什么错?
结点写成class,成员变量默认private,实例化对象会调用构造,我们写的构造访问了结点的成员变量——所以这里就是一个访问私有成员变量的问题
编译一下,没有报错。
原因:
①模版不参与编译,实例化之后才参与;
②头文件不参与编译;
(没有#include的话,#include之后在预处理阶段在.cpp展开之后才会参与编译);
模版是不会被细节编译,因为编译模版没有意义,什么时候才会被编译???
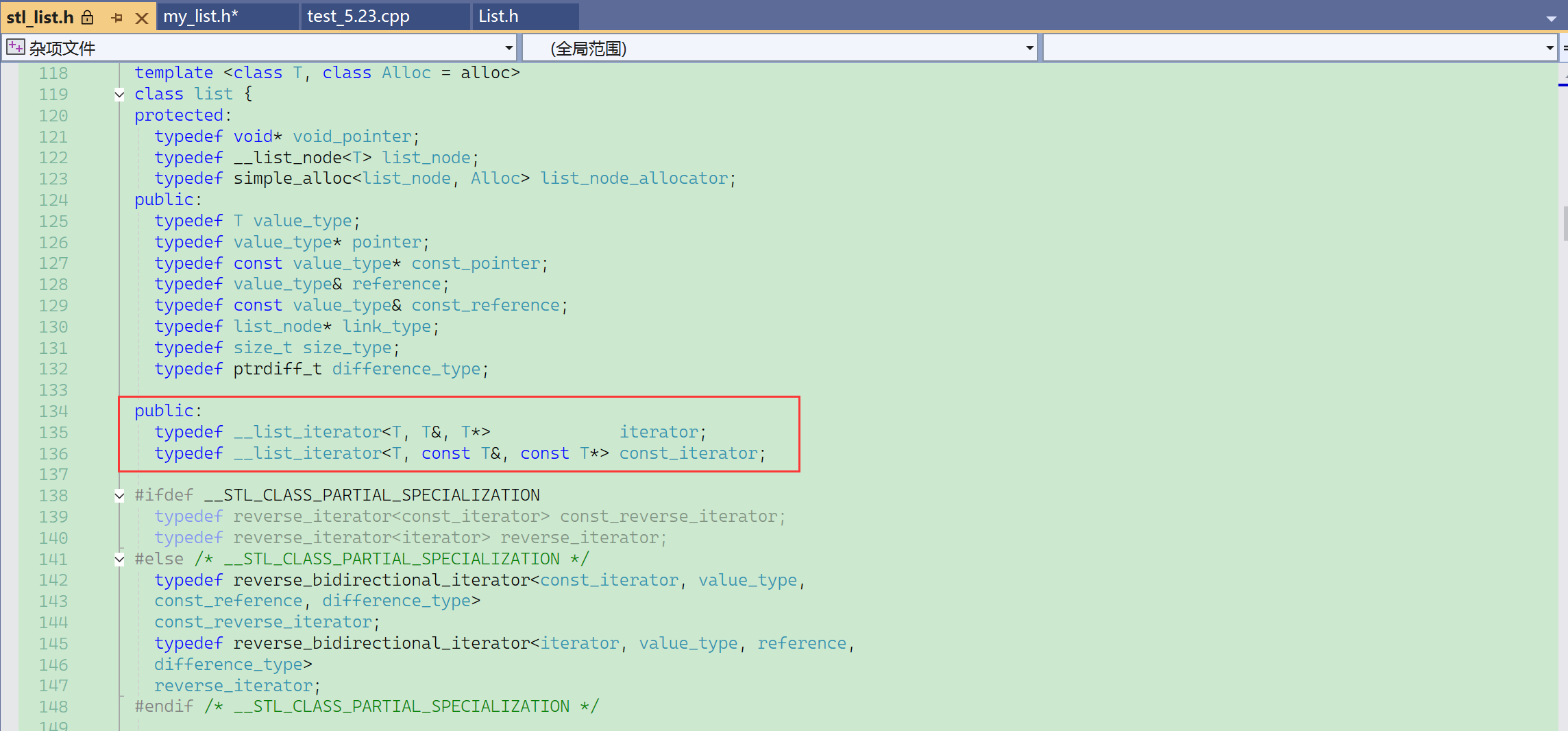
实例化以后。而且实例化出对象后,不是所有成员函数就都实例化了, 而是调用哪个成员函数,才会实例化哪个成员函数——按需实例化。
没包.h也不会报错——.h也不会被编译 .h是在预处理展开到.cpp之后,随.cpp编译。
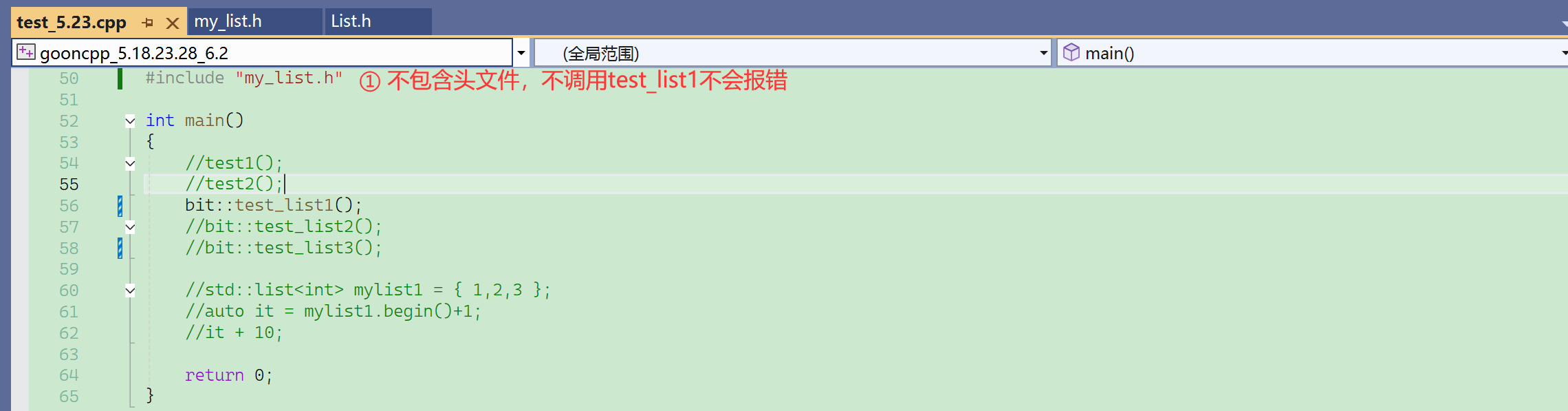
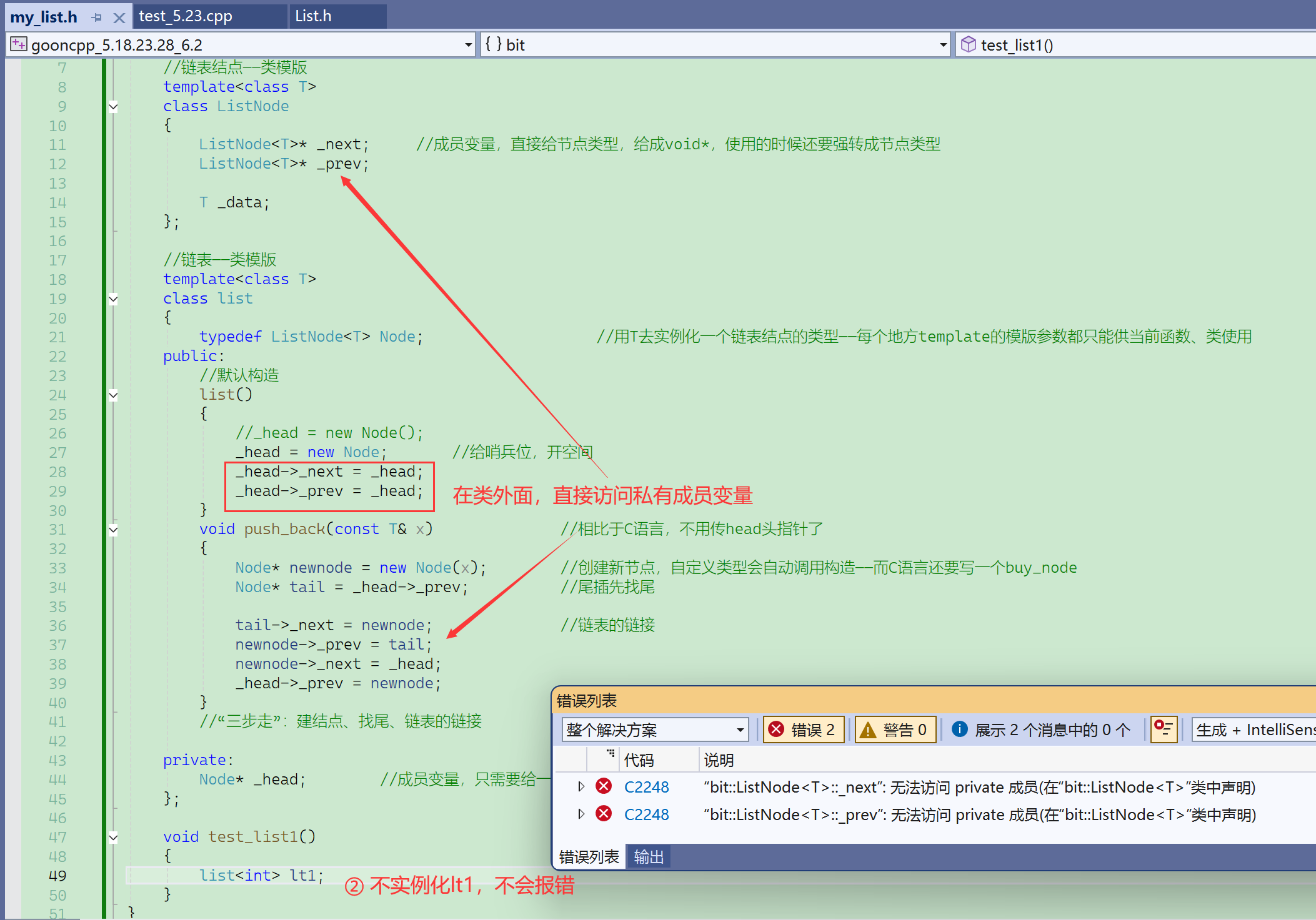
报错也只会报构造函数的错误,push_back也访问了私有,但是push_back没报错,因为没调用。
类的成员函数不调用就不会实例化这个成员函数。
按需实例化:你调用哪些成员函数,才会去实例化这些成员函数。
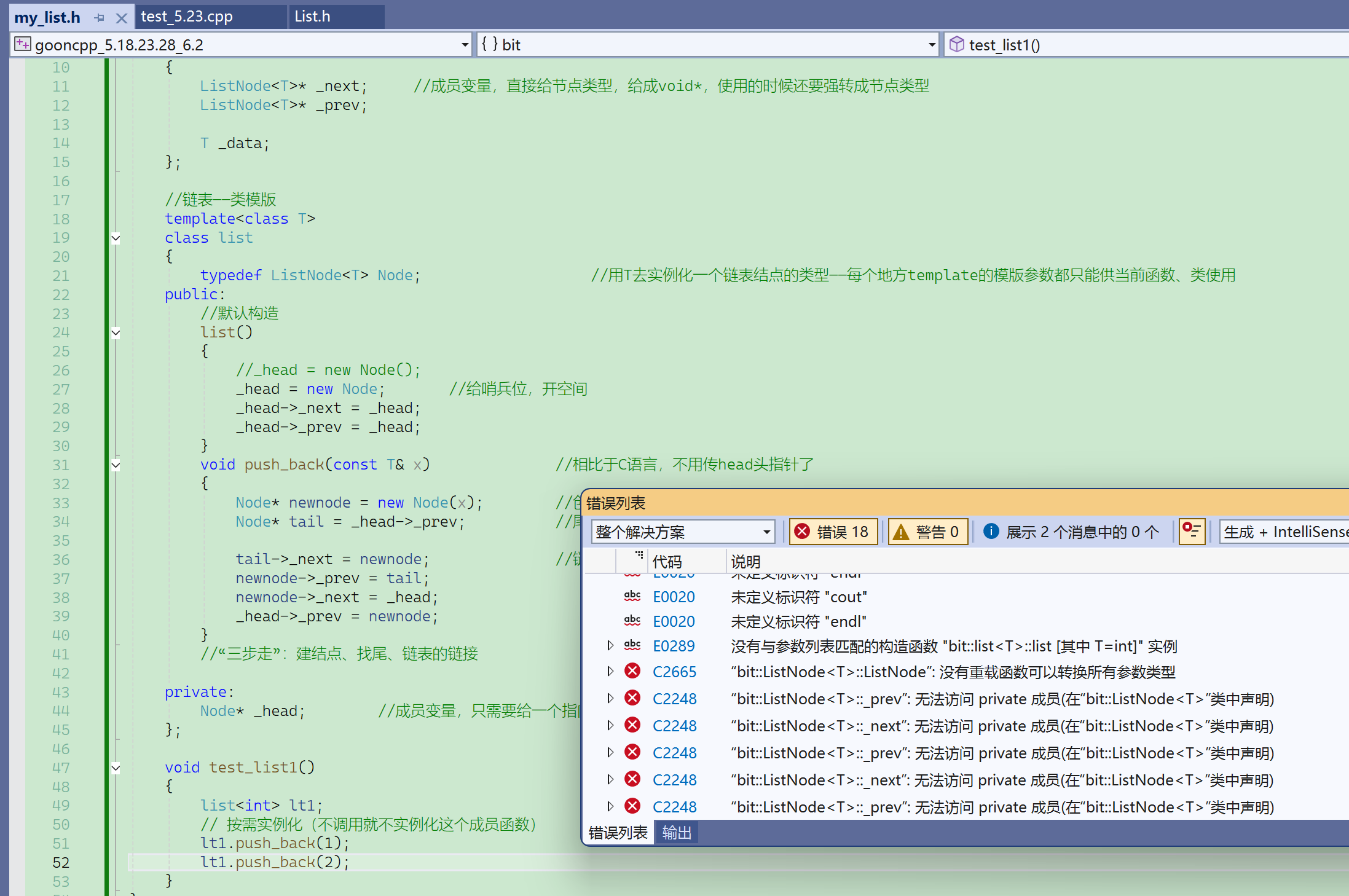
没有实例化的成员函数内可能有一些语法错误,但是不会报错。
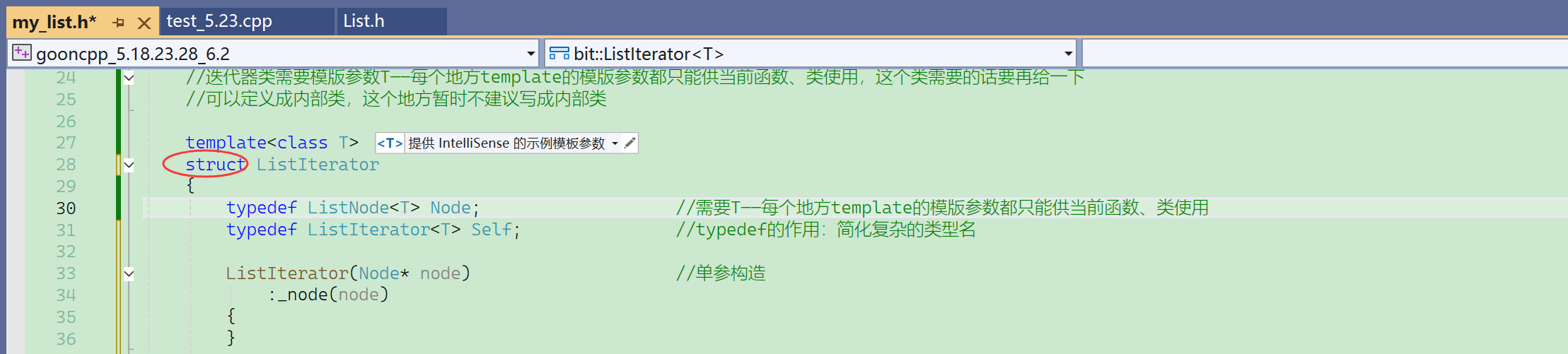
【结论】为什么结点用struct不用class?
因为用了class还得显式写个public,麻烦。不如直接写一个struct。
C++声明一个类既可以使用class,也可以使用struct,只是默认访问限定符不一样。
- C++对于一个不作访问限制,几乎全公有的类喜欢使用struct。
- 对于一个有公有,有私有的类就使用class。
而list里面如果没有public:
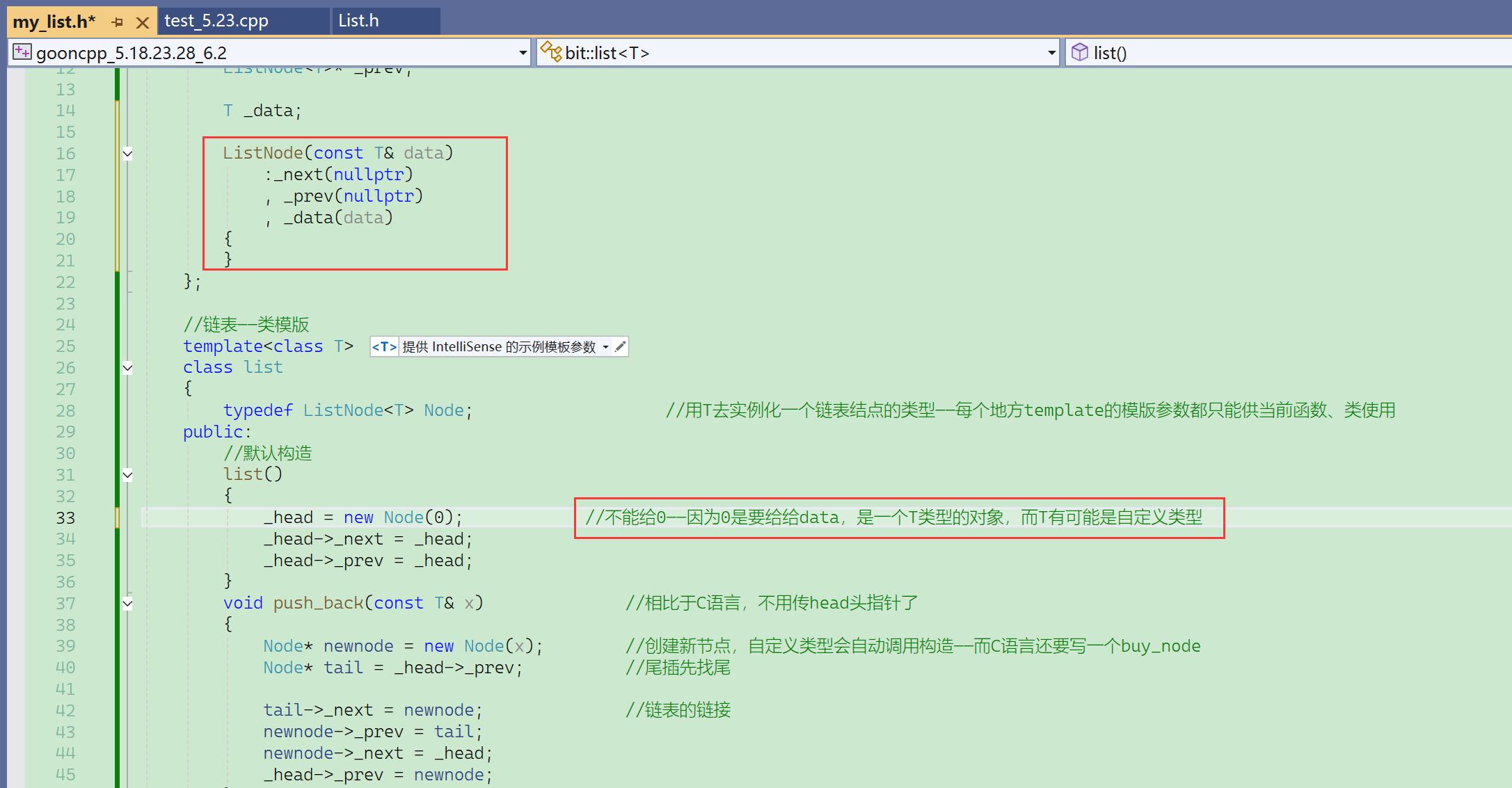
T有可能是int,有可能是double、float、char、string、vector、list……
自定义类型的对象可以考虑使用匿名对象进行初始化。
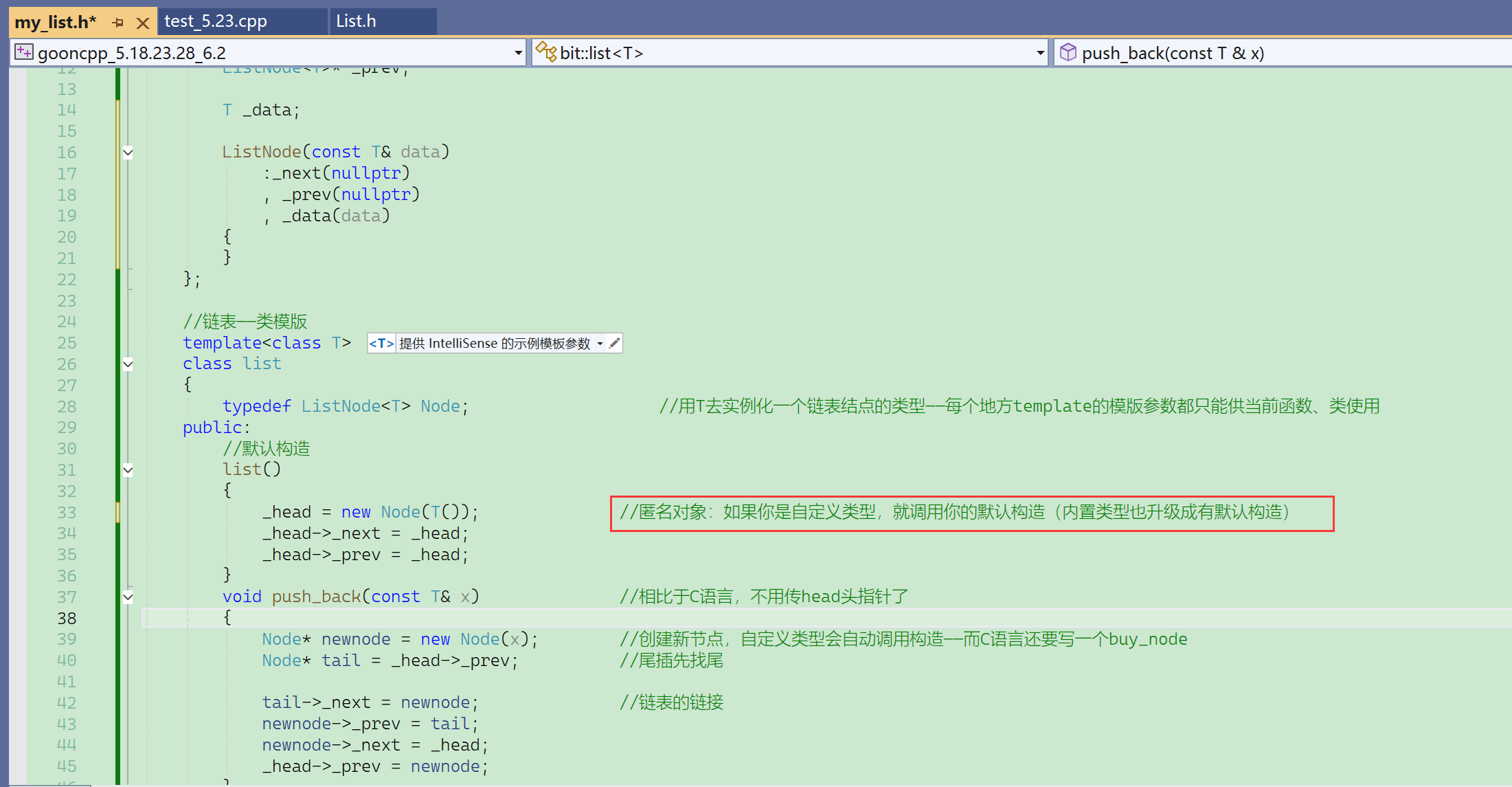
当然这里缺默认构造,可以写成全缺省,自定义类型给缺省值也是使用匿名对象。
③ 测试
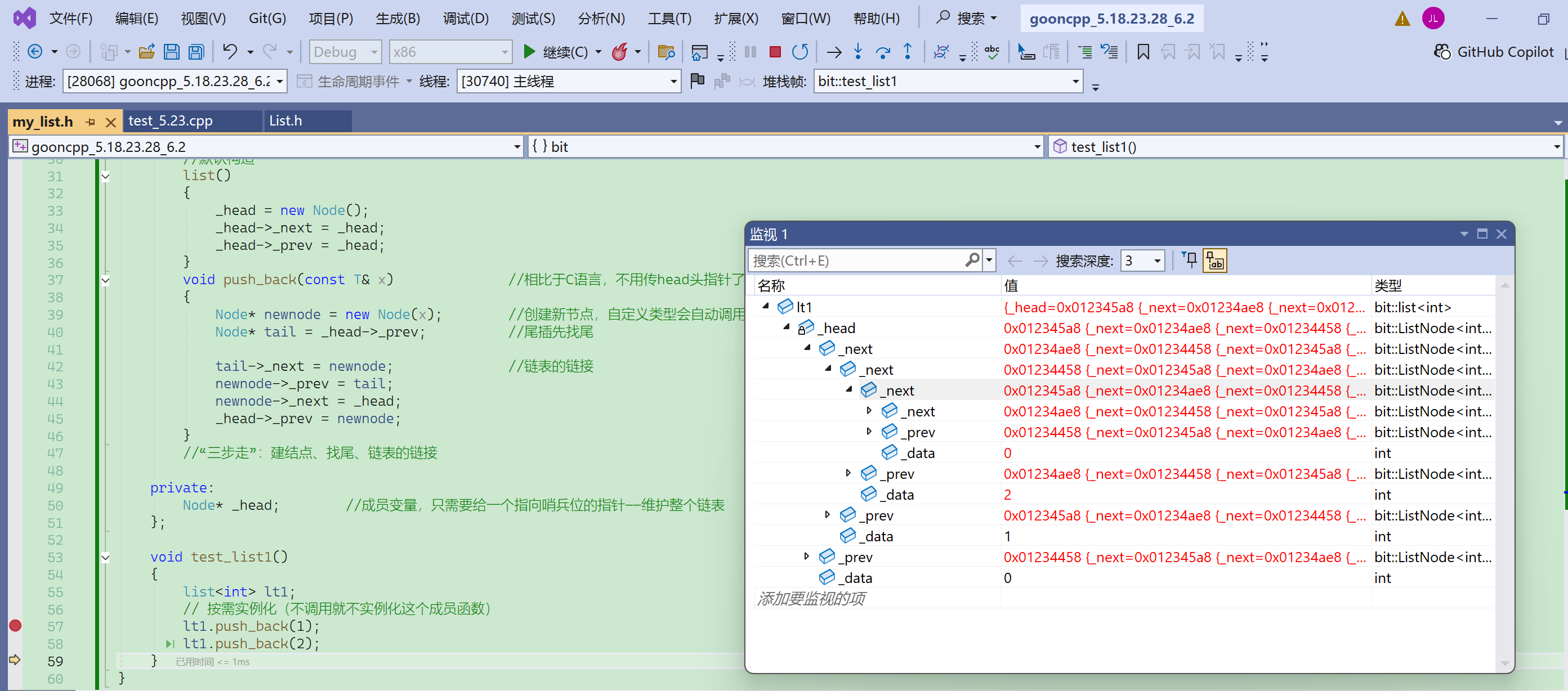
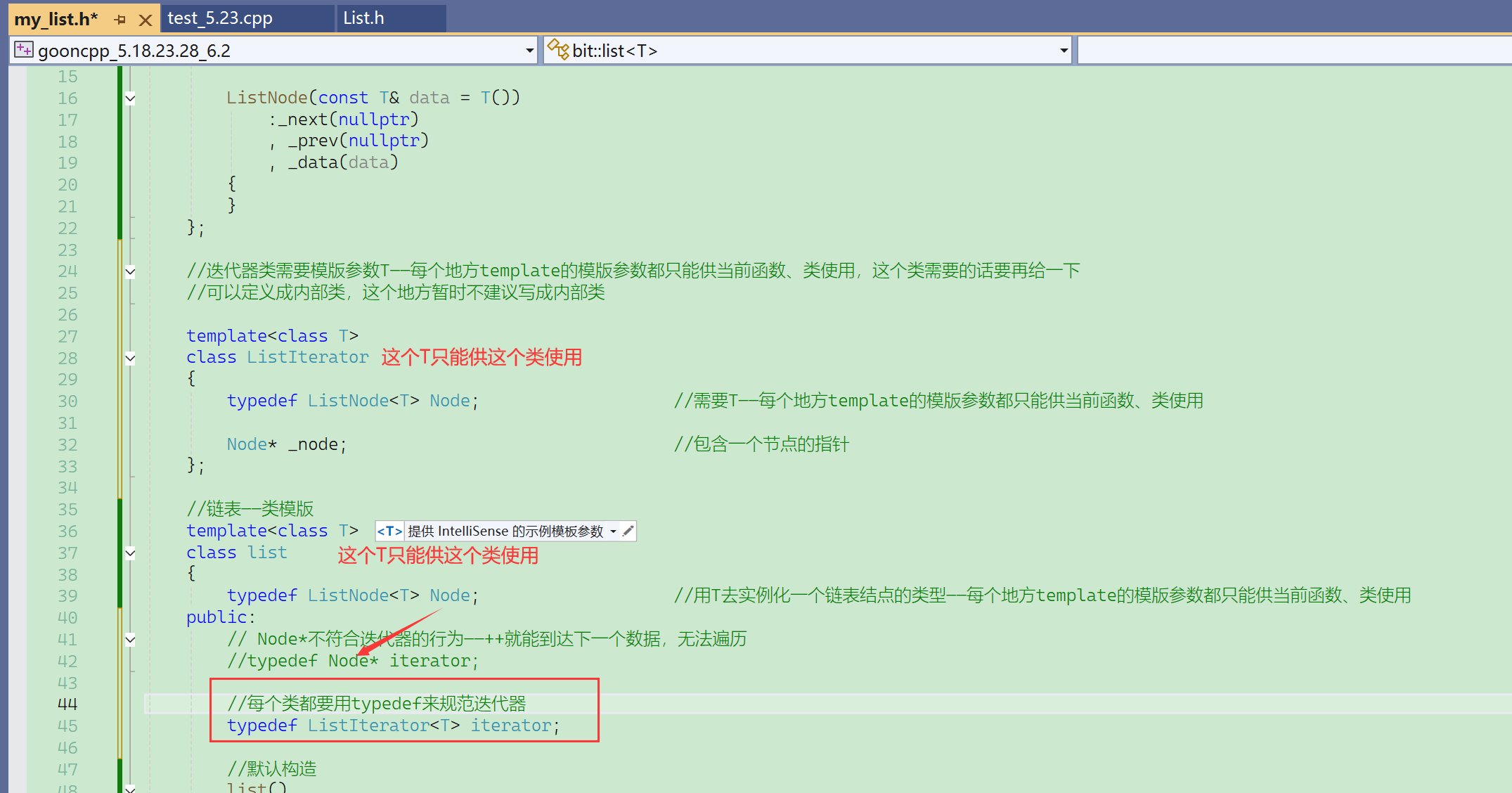
④ 遍历功能——迭代器的实现
(Ⅰ)类型封装
vector的迭代器it可以使用T*,本质是因为++it,会进行指针的++,会直接来到连续的下一个元素空间,而数组是连续的,下一个连续空间正好能访问到下一个元素。
list的迭代器it不能使用Node<T>*,本质是因为++it没法访问到下一个元素。
因为链表的结点,在物理空间上大概率不是连续的。
- 其实有当前结点的指针,可以访问到下一节点,只是需要访问当前结点的成员变量,而不是直接进行简单的++操作。
- 所以可以把迭代器封装成一个类型,然后重载++操作。
用“类”封装以后的意义——一个类可以重载运算符。
这个类型的名称不建议取iterator,因为它在list类的外面,而其他容器也可能在外面有iterator,所以这里这个封装的迭代器的类型最好叫List_Iterator。
之后可以在list类里面,typedef成iterator。
本来使用的是Node*,但是这里Node*的行为不符合我们的要求,所以我们用一个类去封装Node*,然后重载相关运算符,让Node*的使用能够符合我们的要求。
注意迭代器的类型要声明在链表类型声明之前,否则会报错。
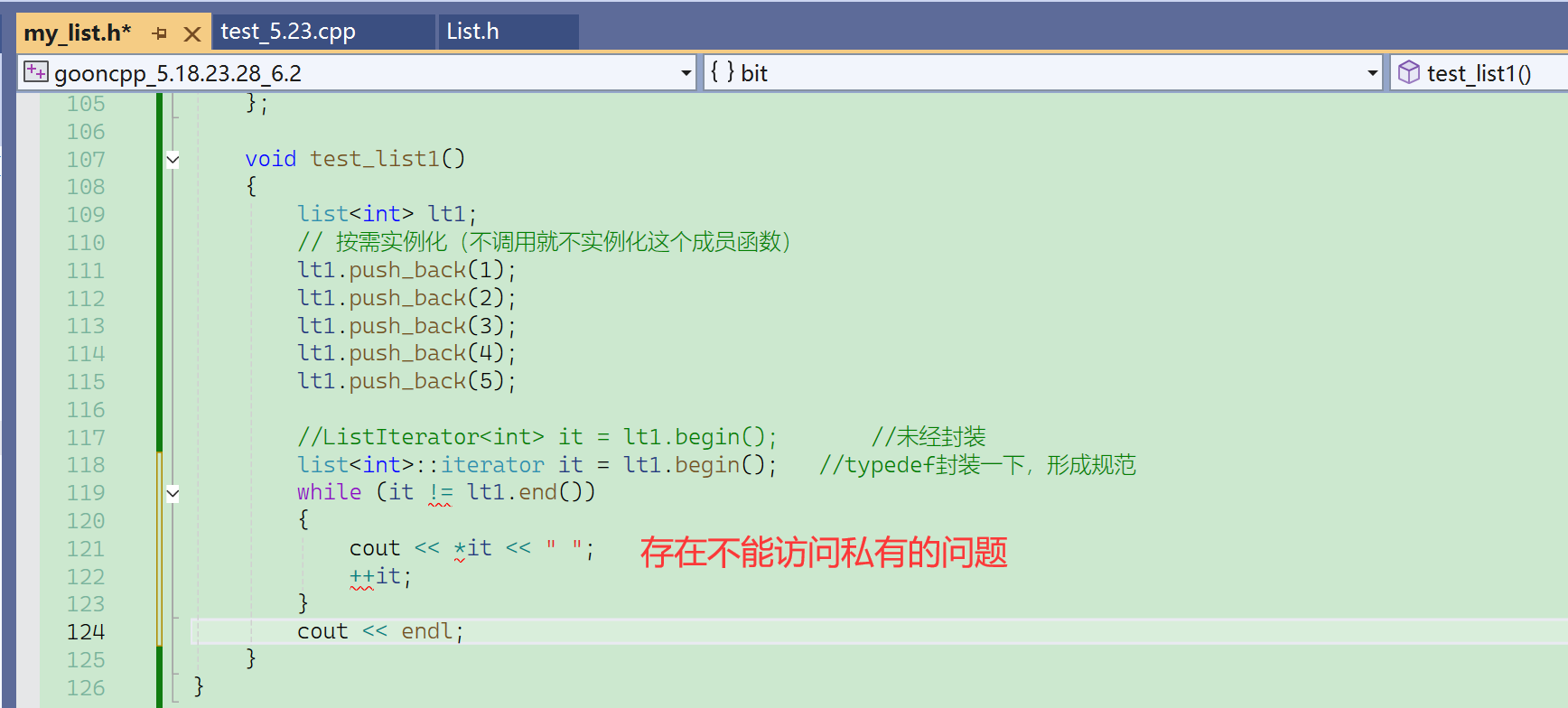
这里的重定义的iterator是public的,在main函数中可以直接使用。
如果不在list中用typedef来规范迭代器,那么在测试函数中,使用迭代器就需要写ListIterator<T>,可以用,但不符合使用习惯。
使用通用的封装名iterator,在不同的平台都通用。
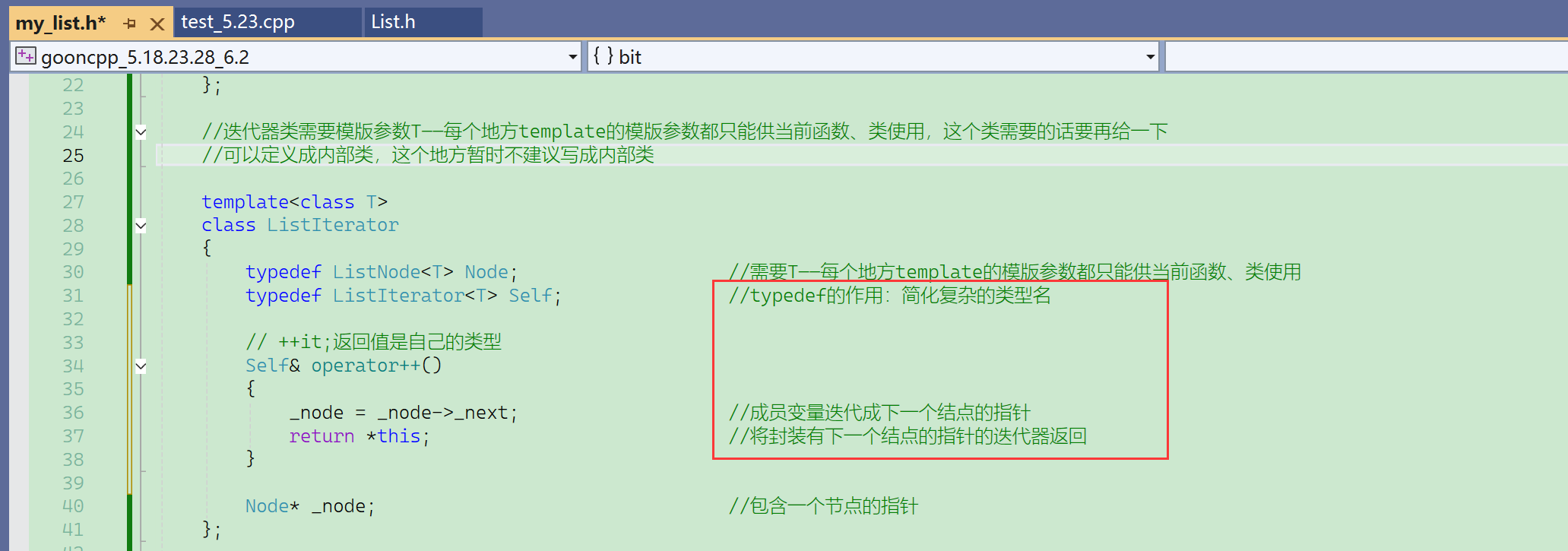
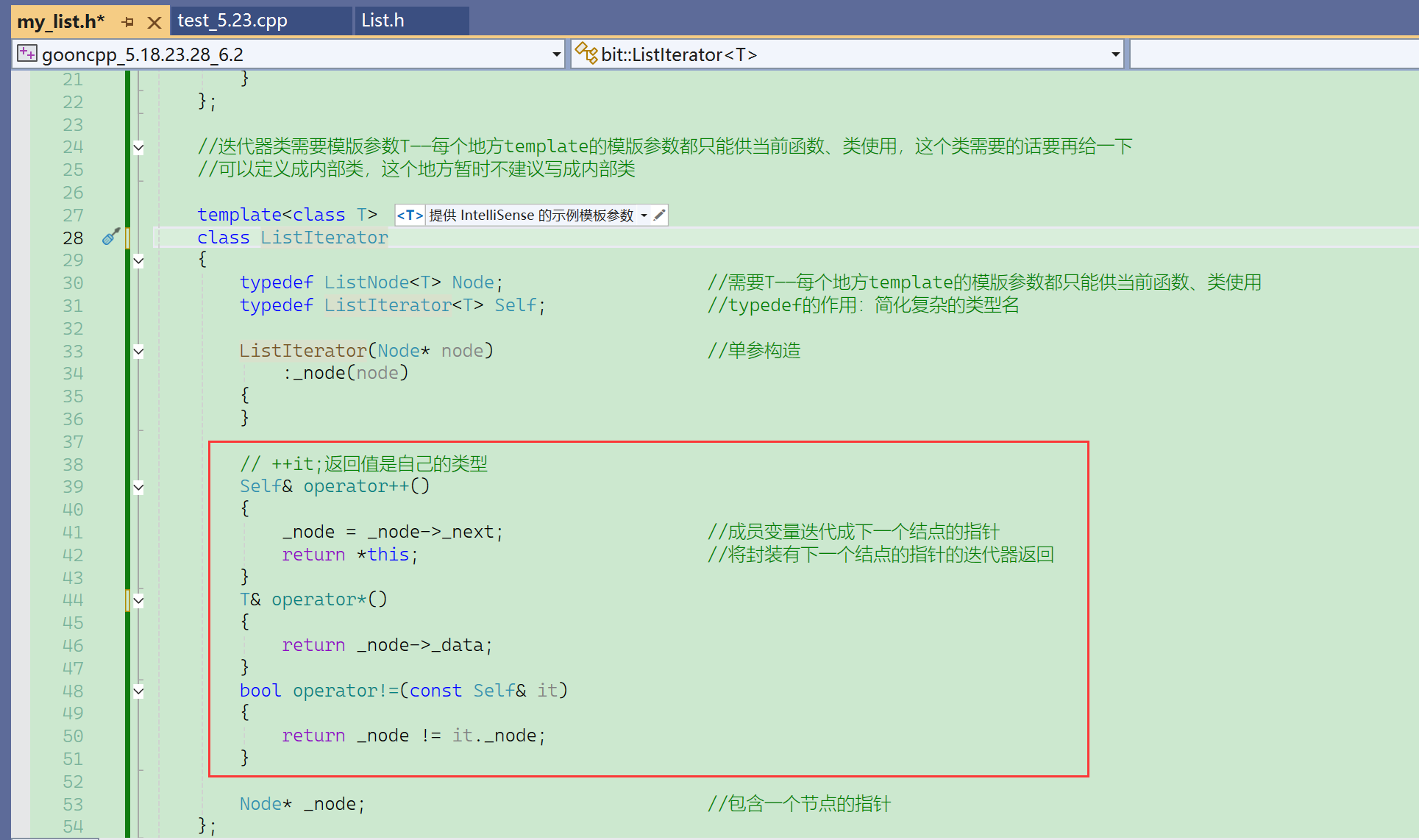
迭代器的构造:用一个结点的指针去构造(迭代器就是封装了一个节点的指针)
迭代器的使用:不等于end→++→解引用→……。
* :
- Node*解引用是Node结点结构体,iterator解引用是想获得那个位置的数据;
- 引用返回确保解引用能够修改;
!=:迭代器的比较,是比较结点的指针。
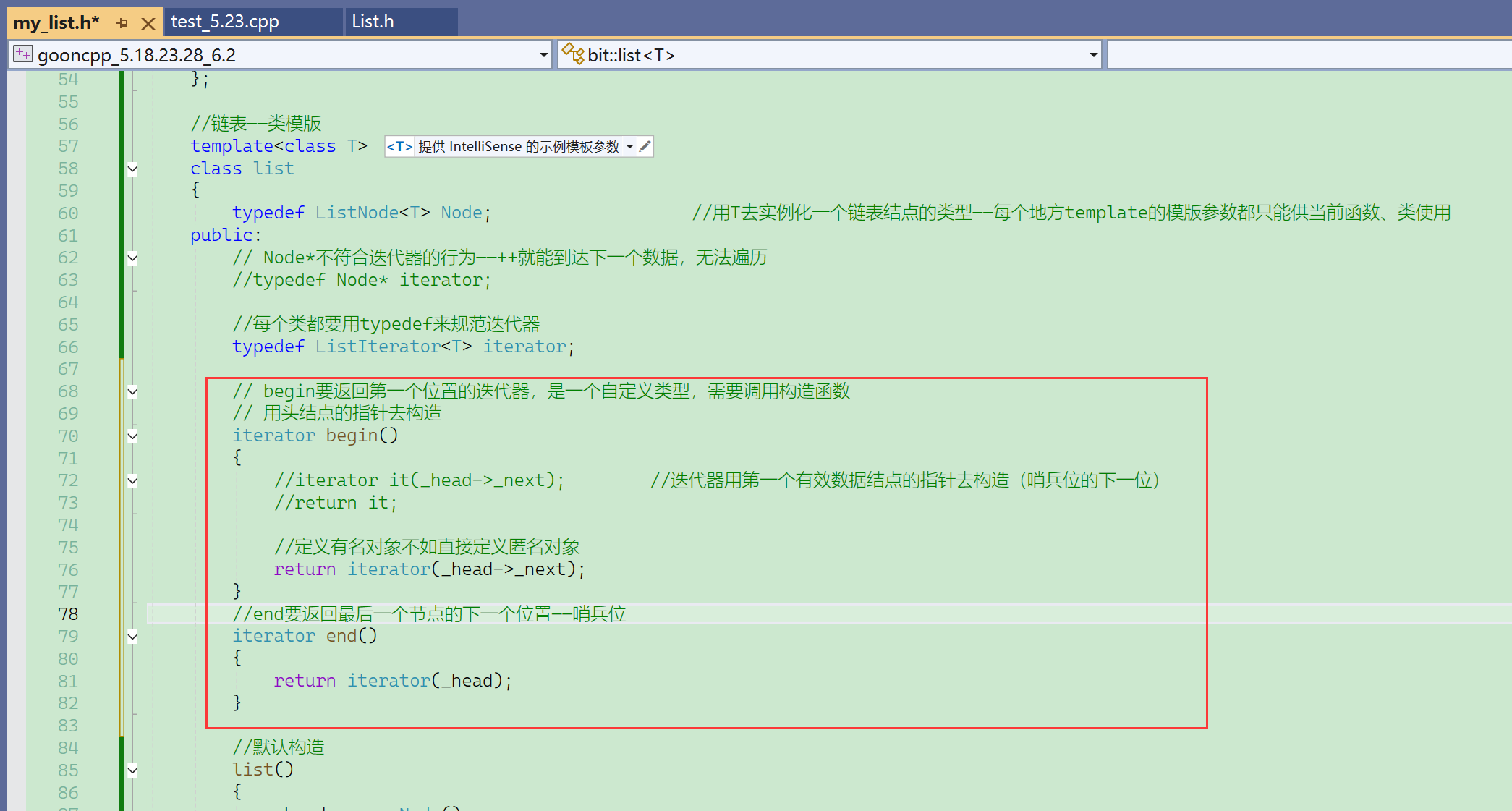
(Ⅱ)begin、end
(Ⅲ)测试
要么class+public,要么struct。
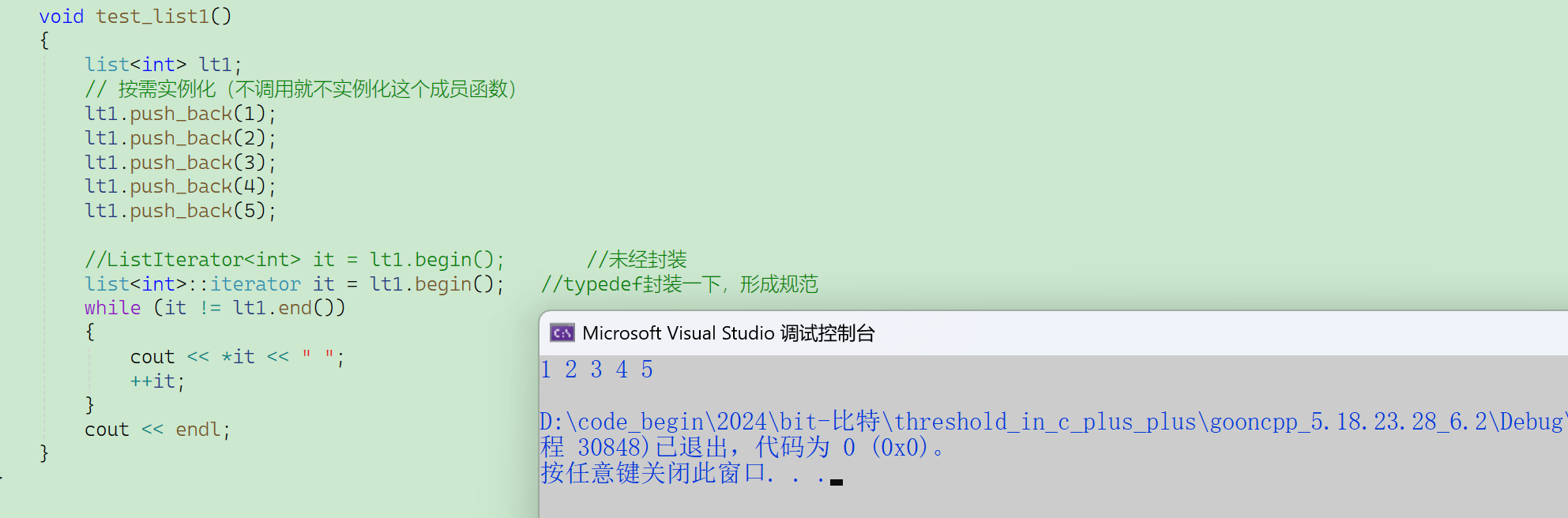
如果链表为空,begin和end都是哨兵位,直接相等,遍历的时候不会进去。
迭代器,用于迭代,能满足!=比较、++迭代、*取数据就可以了,元素指针恰好可以满足这些功能。
本来想使用Node*——ListNode<T>*,但是Node*不符合我们的行为,祖师爷就开了一道门,我们可以通过封装Node*,然后控制运算符重载的方式,去控制一个类型的行为。
用自定义类型去封装Node*指针类型,通过控制运算符重载,去控制Node*的++。
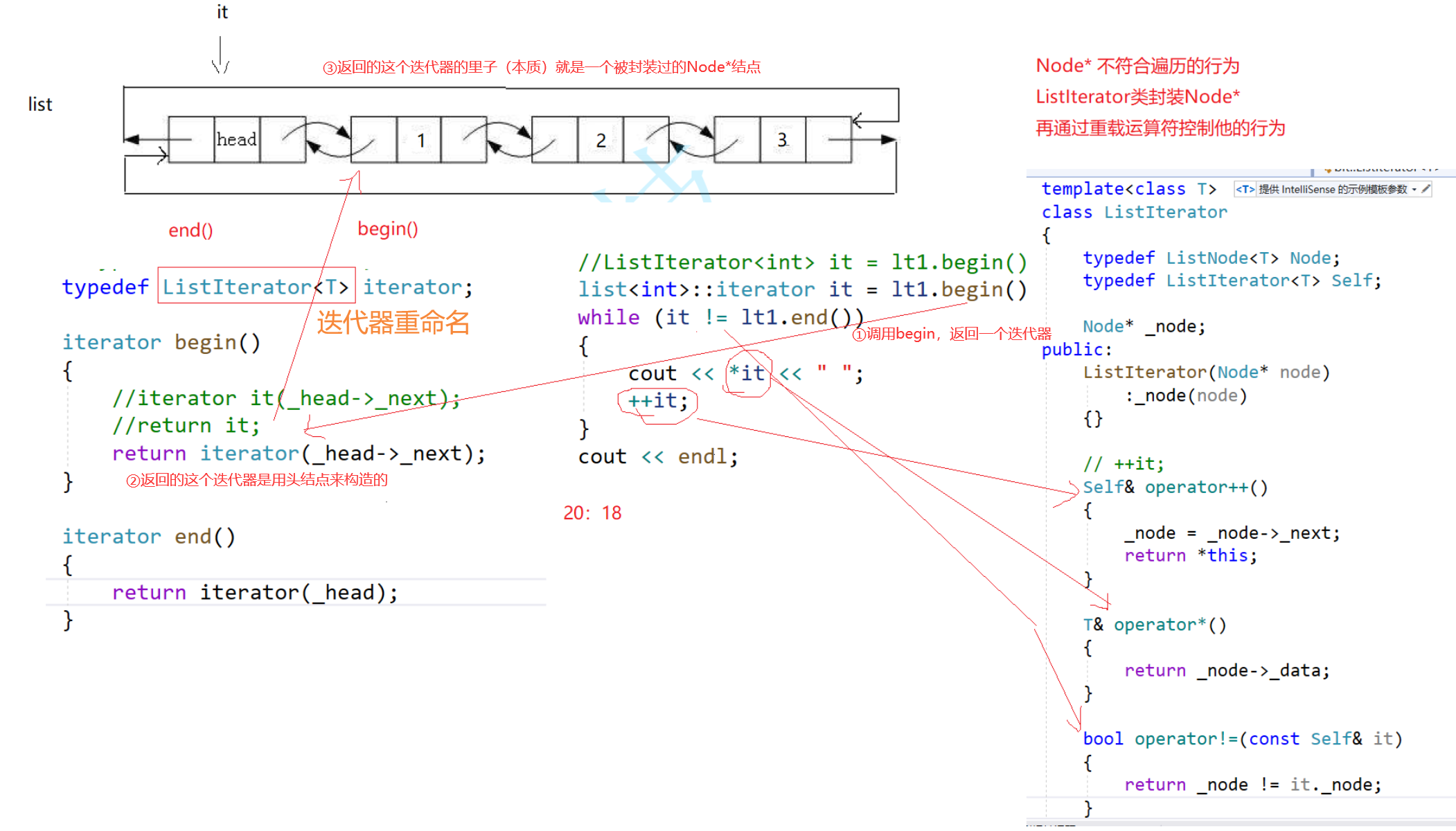
【迭代器】
面子:是一个类
里子:是结点的指针Node*
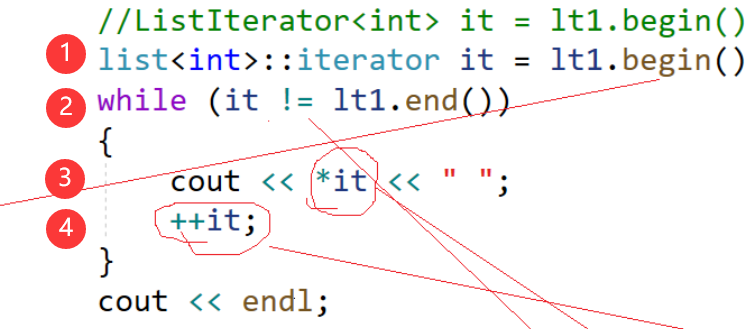

① 调用begin,返回一个迭代器,这个迭代器用头结点指针构造,这个迭代器外层的壳是一个迭代器,内层的里子是一个结点指针。为什么为什么要用这个类去封装结点的指针,因为结点的指针不符合我们的行为。
② it != end(),end是返回最后一个元素的下一个位置的迭代器,等不等是使用结点的指针,即结点的地址进行比较的。
③ 解引用取数据,对Node*解引用也不符合我们的行为,Node*解引用得到的是那个结点,我们要的不是结点,而是结点的值。迭代器模仿的是指针的行为,指针解引用是希望获得数据。所以重载*,返回结点的数据。返回引用,支持修改。
④ ++it,希望往下一个结点去走,但是Node*++不是我们想要的行为,于是重载++,调用重载的++,跳到下一个结点。
运算符重载的高明之处在于,用起来像内置类型,但是它会调用对应的运算符重载。
再总结一下,Node*不符合我们的行为,但是对于内置类型不能重载运算符,只有自定义类型才能重载运算符,operator……的参数至少需要一个自定义类型。
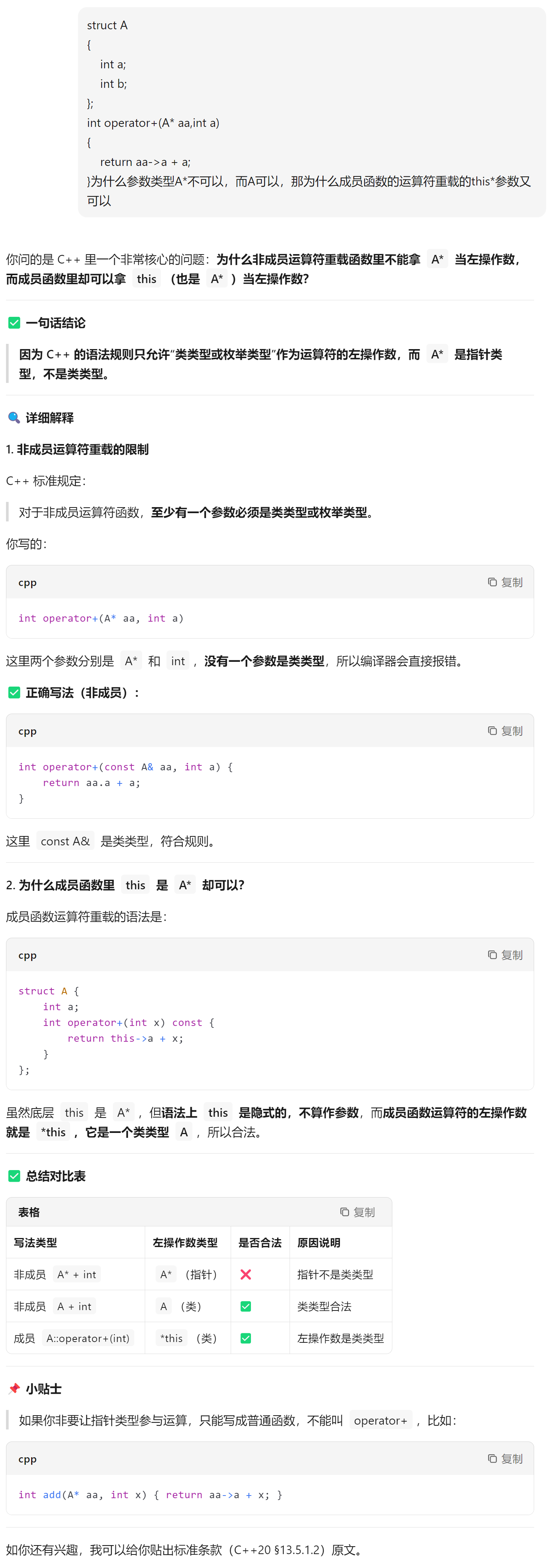

换一个角度,是不是我们真的不能改变内置类型的行为?
也不是,重载一个运算符,不能只针对内置类型,但是可以间接改变,比如Node*,确实不能直接改变解引用和++的行为,但是可以把Node*封装到类里面,再在类里面重载运算符,相当于间接地改变了内置类型Node*的行为。
也就是说内置类型不能直接更改它的行为,但是用一个类封装通过运算符重载可以间接去修改它的行为。
这样的话,就不管你底层是什么,数组、链表、树……,在封装过后,顶层提供了统一的访问方式,begin返回首位置,!=end的最后一个位置,就*取数据,然后++向后迭代……以这样的方式去访问这个容器。
所以迭代器是一个很厉害的设计,本质是一种设计模式。是一种统一的访问方式——不管底层这么样, 封装了以后屏蔽了底层的细节,上层给你提供统一的方式,让你去访问。
这样,链表就一共设计了3个类。不要迭代器至少也是两个类。
- 一个一个的节点就需要一个类,类里面有数据域和指针域;
- 还要整体管控这个链表,需要一个指向哨兵位头结点的指针;
- node*不符合迭代器的行为,所以需要一个类去封装node*,重载它的行为,达到我们的目的;
(Ⅳ)完善迭代器类
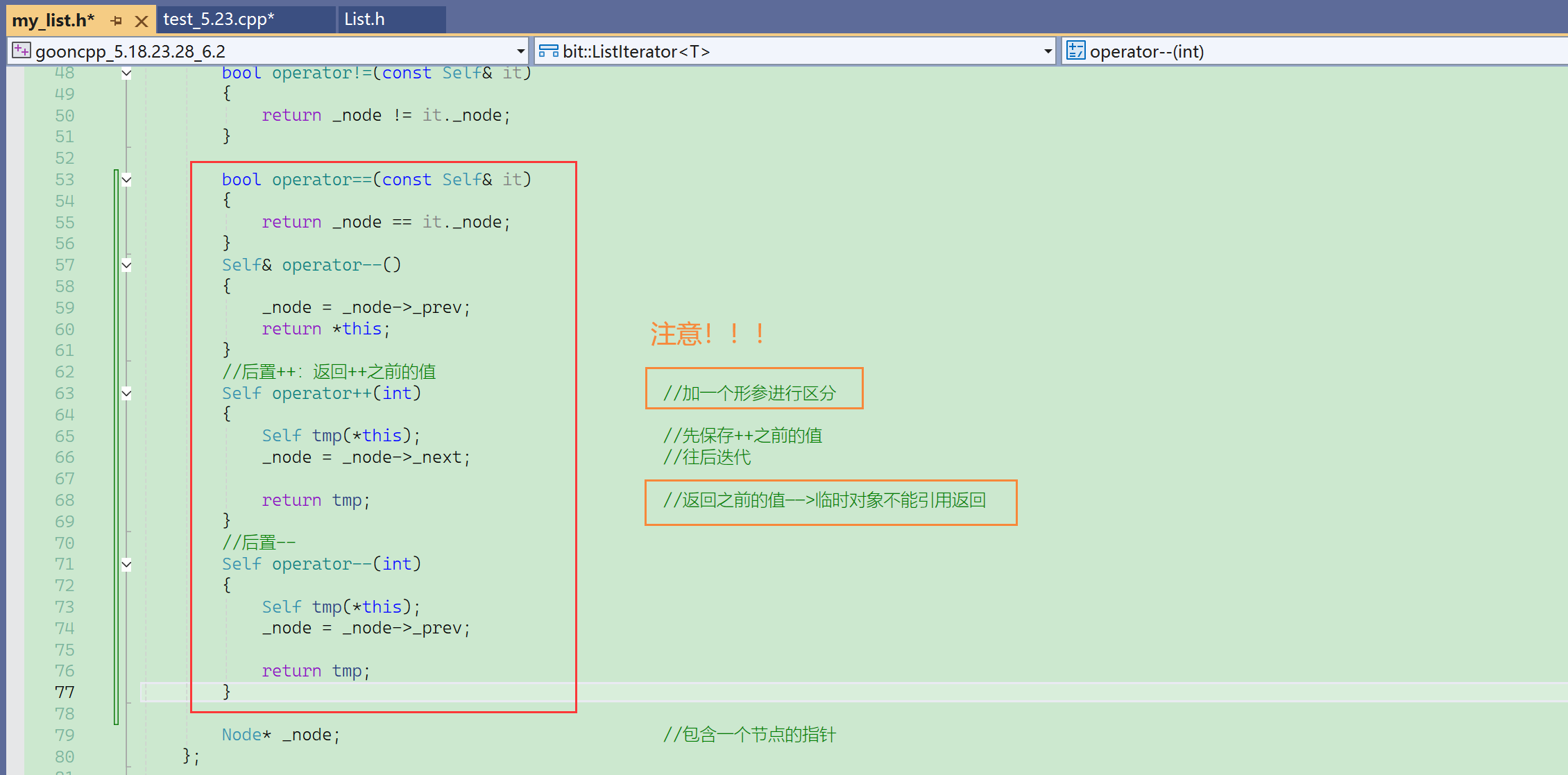
问题1:用不用重载+???——不用支持 it+10这种。
效率不高,时间复杂度O(n),加10就要走10次。
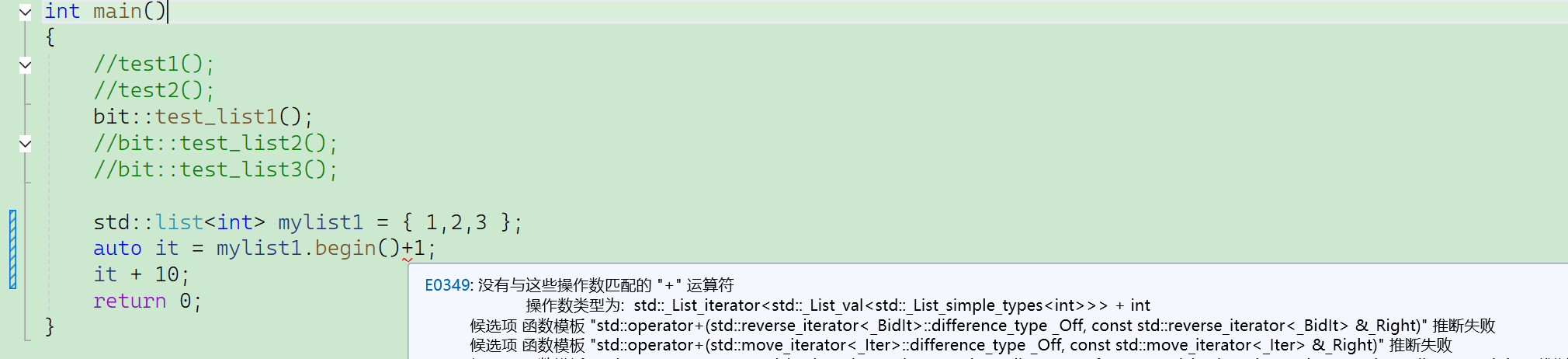
库里面也不支持,没有重载这个运算符。
这里对list的迭代器的定义是一个双向迭代器,支持++、--,但是不支持+和-。
之前string、vector的迭代器使用原生指针,默认是支持+和-的。
问题2:链表的迭代器要不要写析构函数??? 不用写,因为不用把那个节点释放掉。
那个节点不是属于迭代器的,给你迭代器这个节点的原因,是希望你利用这个节点去访问、修改数据,但是你要不要释放这个???——不要。
这个节点是属于链表的,不要越级管理。
问题3:链表的迭代器要不要写拷贝构造、赋值重载???(实现深拷贝)
显然是不需要的,it = lt1.begin()要的就是浅拷贝,指向同一个结点。
深拷贝去指向一个新结点反而错了。成员变量只有内置类型,完成值拷贝即可。
一般一个类不需要显式地写析构,也就不需要显式地写拷贝构造和赋值。
结论:不是说成员变量有指针(管理了内存资源)就要走析构,就要走拷贝构造和赋值。
源码里还重载了operator->
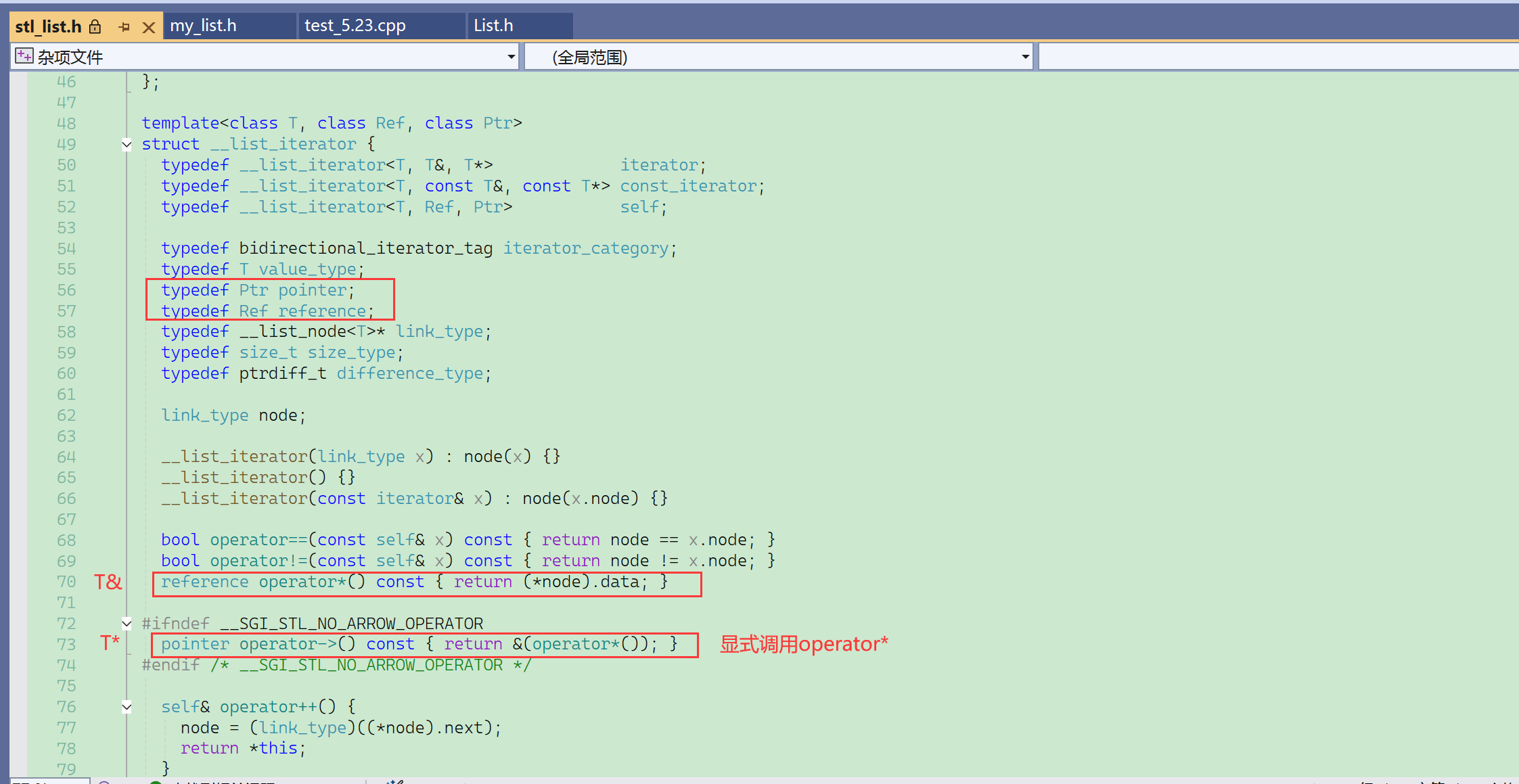
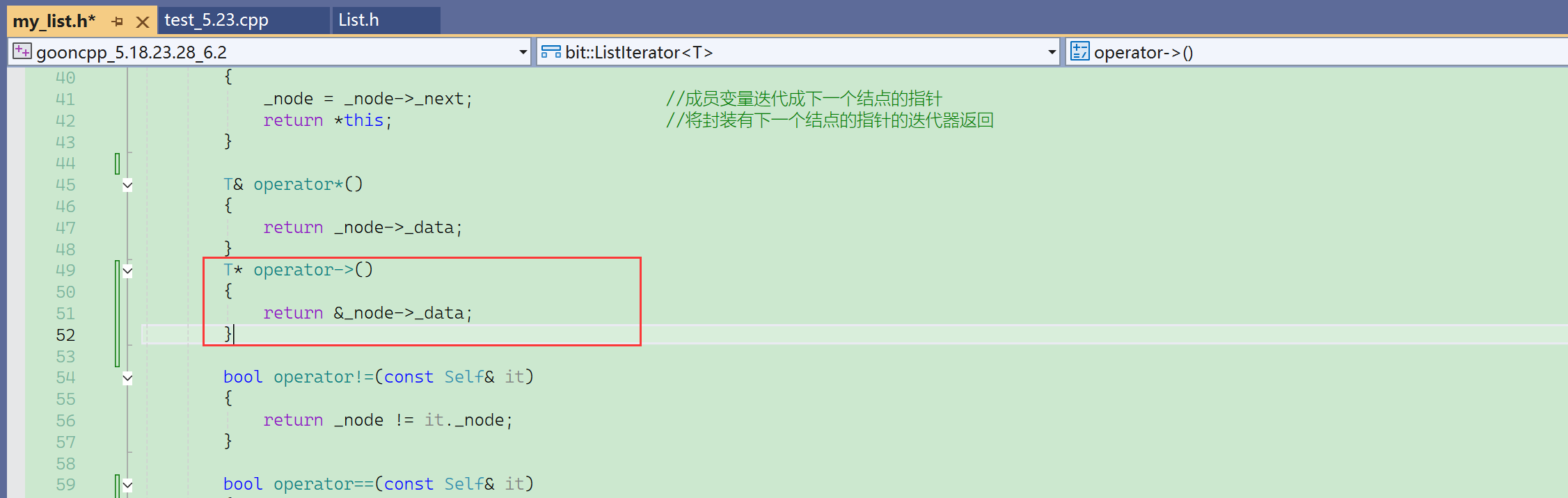
来看看operator->的使用:
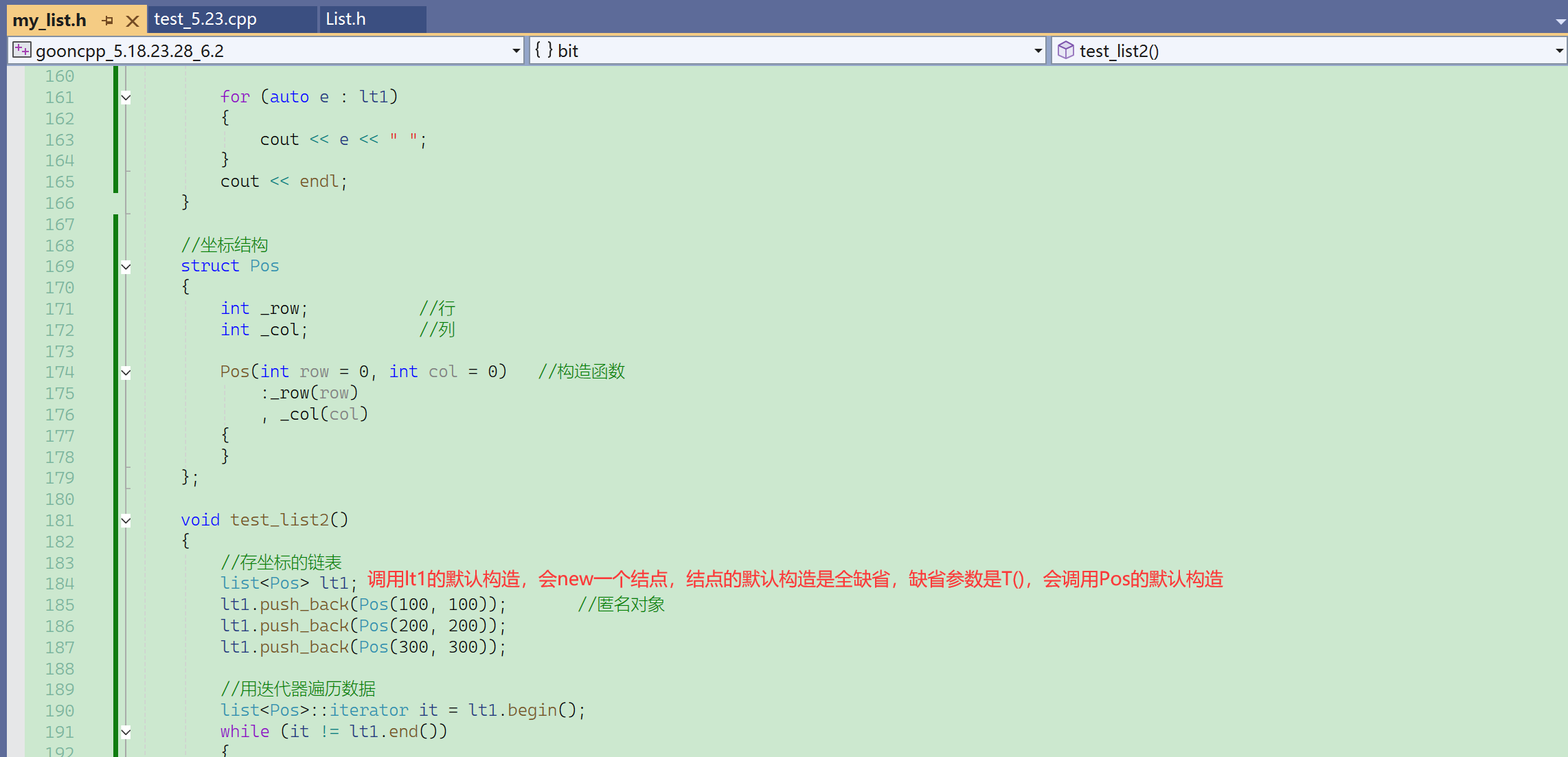
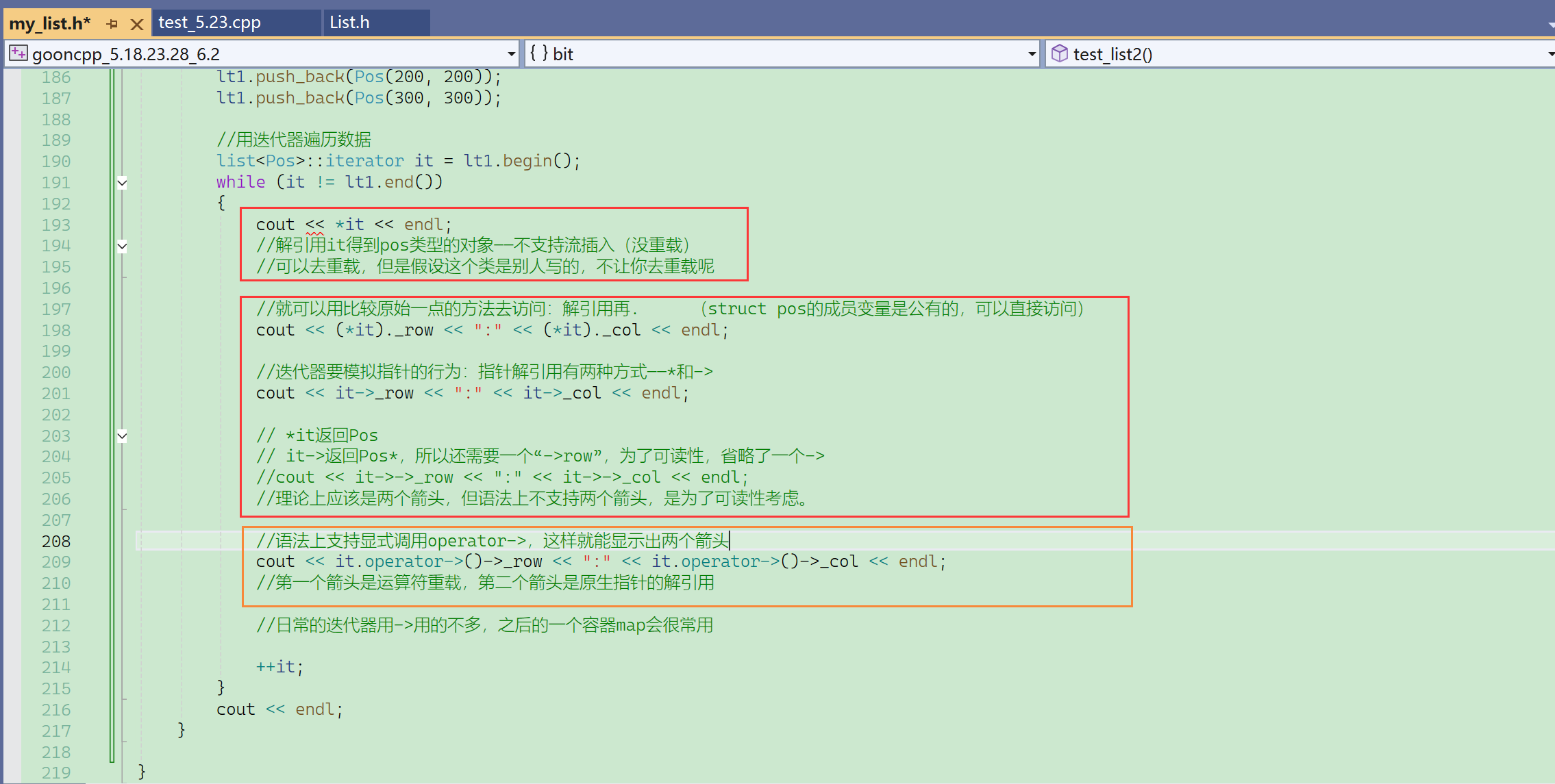
日常的迭代器不怎么会使用到operator->,但是之后的一个容器——map,会经常使用到->重载。
it->row:
- it是迭代器,可以理解为元素的指针,元素是结点,相当于是结点的指针,结点有数据域存Pos,和指针域。
- 所以it其实没有row这个成员,但是却直接通过->访问到了row,是运算符重载的结果。
临时对象、匿名对象的常性和cosnt变量的常性的对比
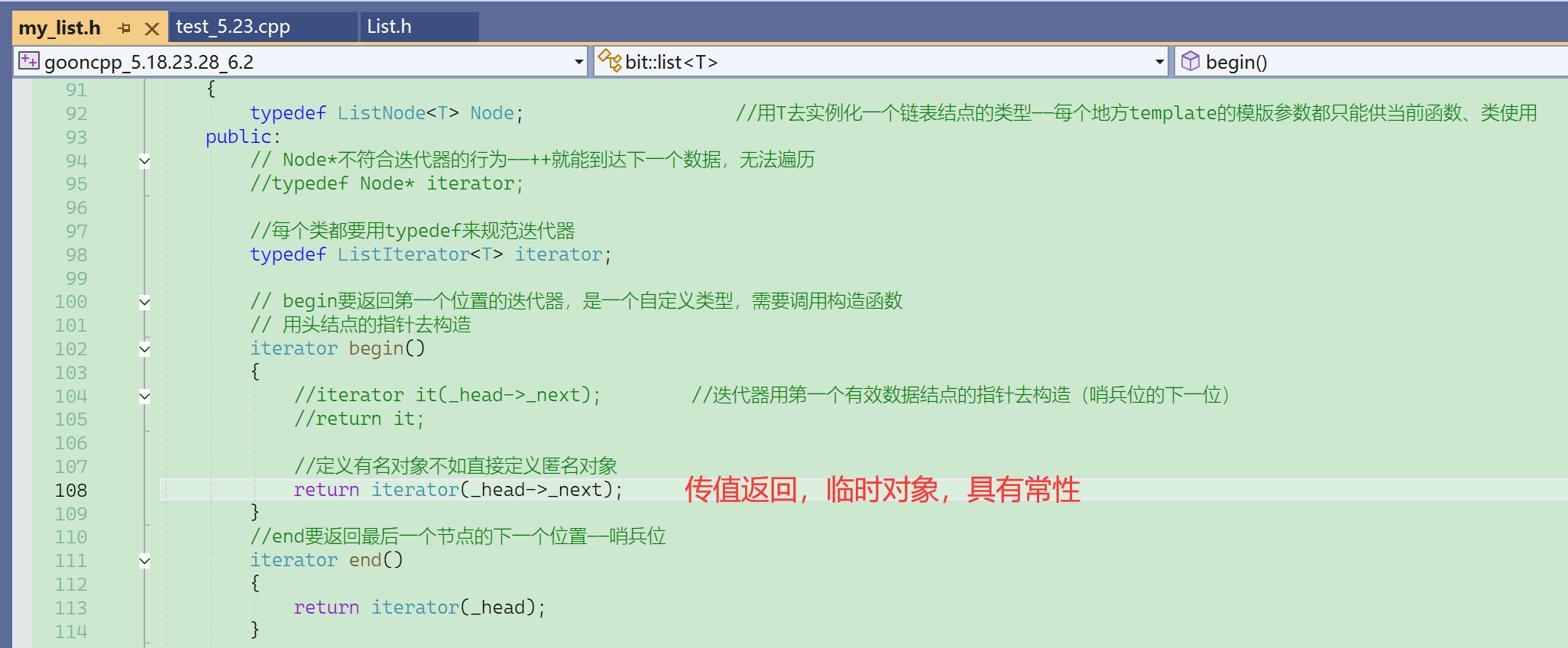
传值返回,不是直接返回这个对象,而是返回它的拷贝,不过编译器可能会优化,合二为一。
这个返回的临时对象具有常性。
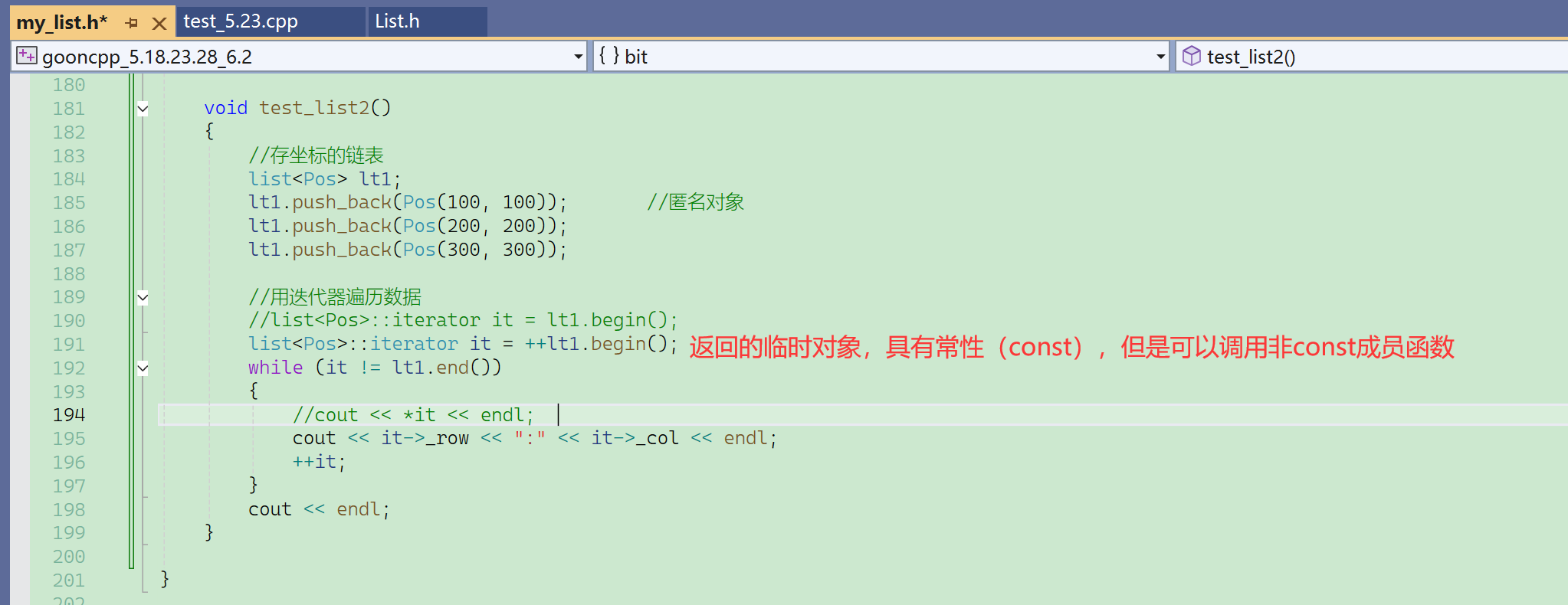
begin的返回值可以直接++: 虽然返回的是临时对象,具有常性,但是这个常性和const iterator it的常性不一样。
临时对象、匿名对象的const常性跟其他const不一样: 它不能直接给给引用,它是临时对象具有常性,但是它可以去调用非const的成员函数。
平时产生的临时对象、匿名对象,虽然具有常性,但是编译器做了特殊处理,它们可以去调用非const的成员函数。它们的const属性比较特别。只限制了不能够给引用。
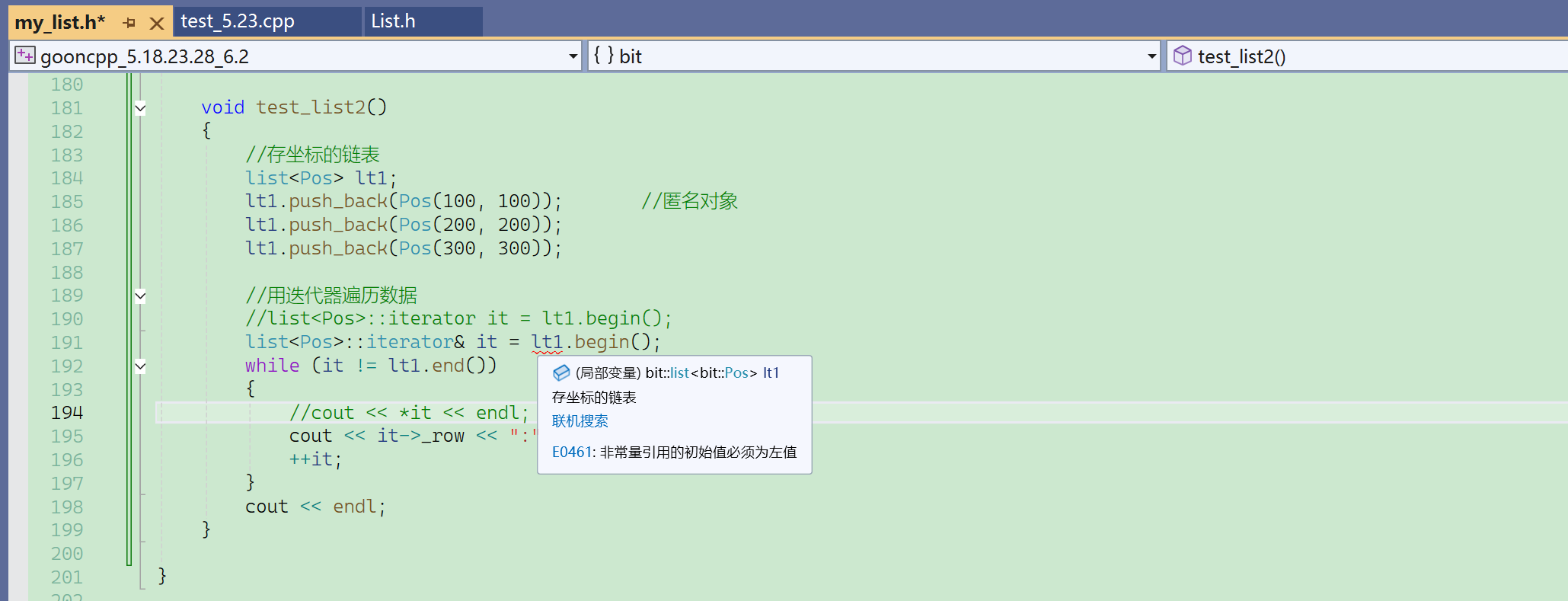
可以引用前置++的返回值。(引用返回)
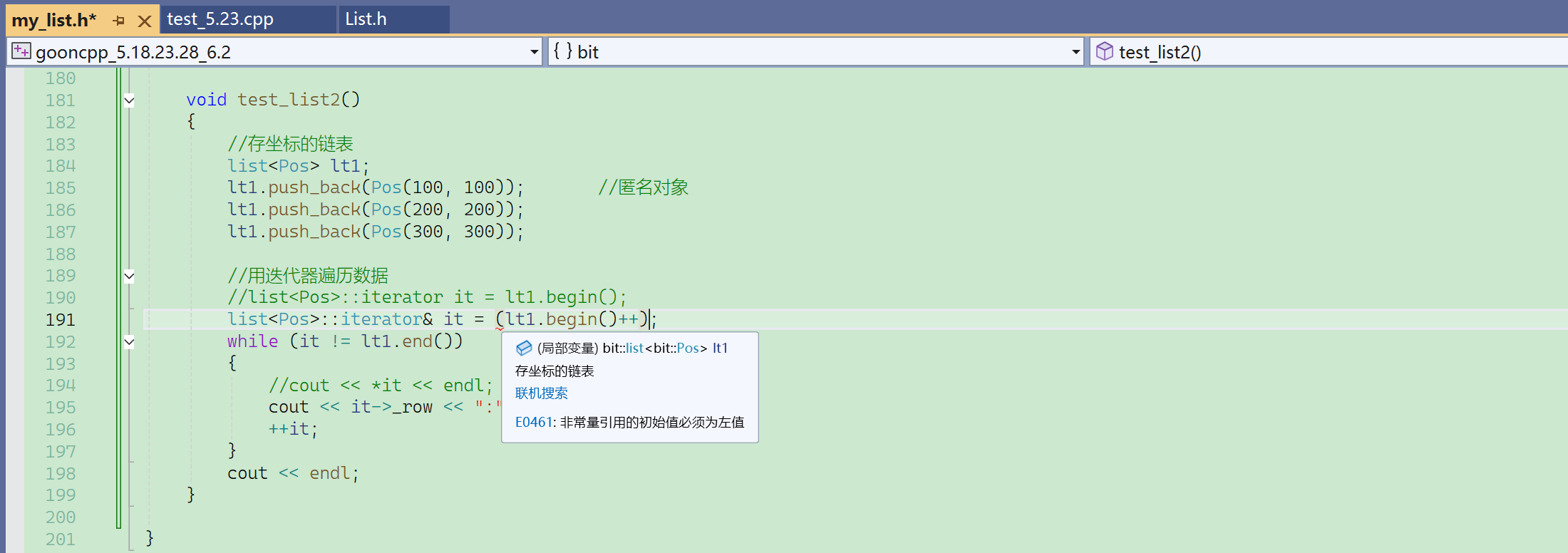
不能引用后置++的返回值。(传值返回)

⑤ const迭代器
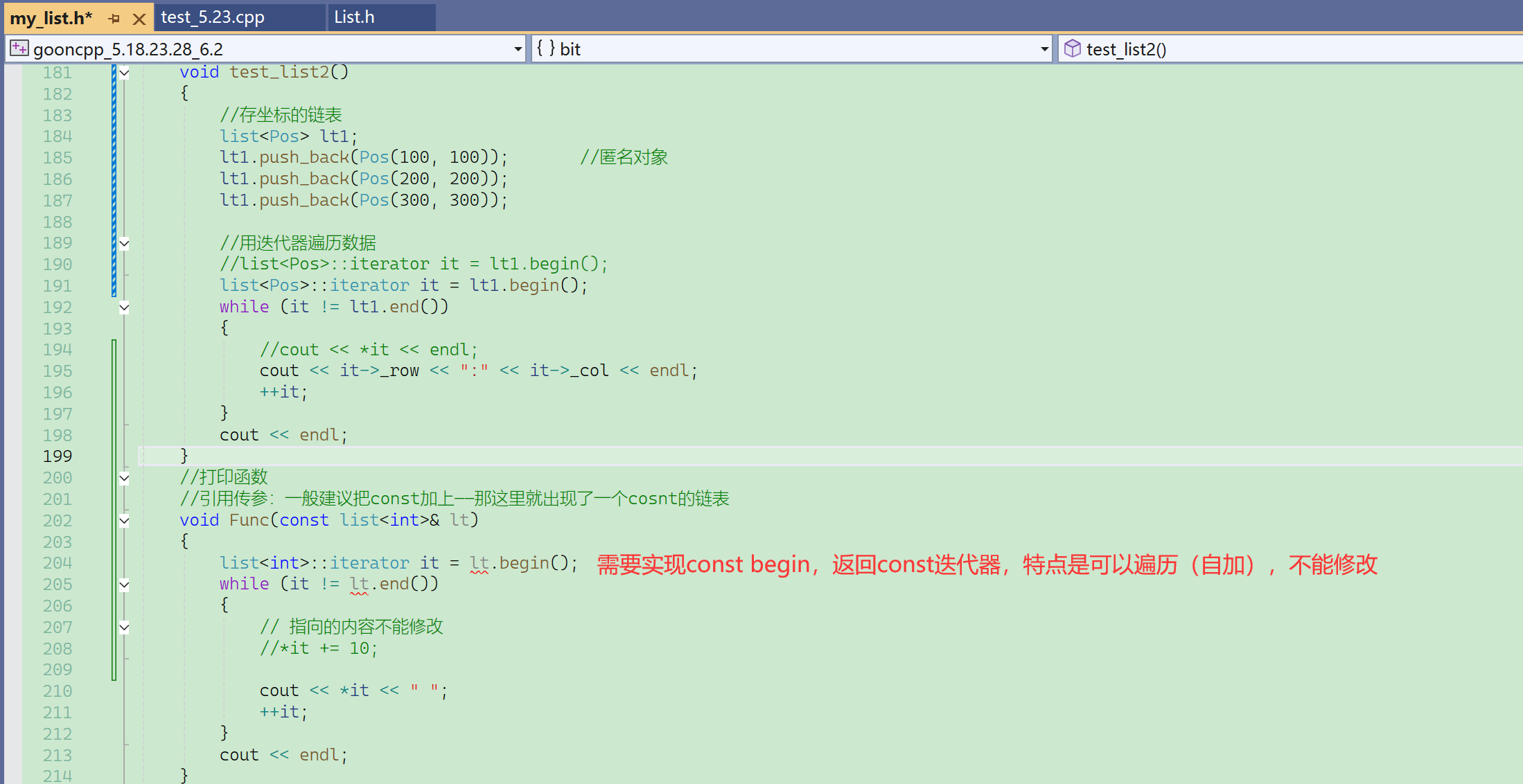
const iterator:const迭代器不能普通迭代器前面加const修饰。
const迭代器的设计目标是:本身可以修改(自加迭代),指向的内容不能修改,类似const T* p
const list<int>::iterator it = lt.begin(); //const迭代器不能这么定义。普通迭代器的前面加个const不能成为const迭代器。
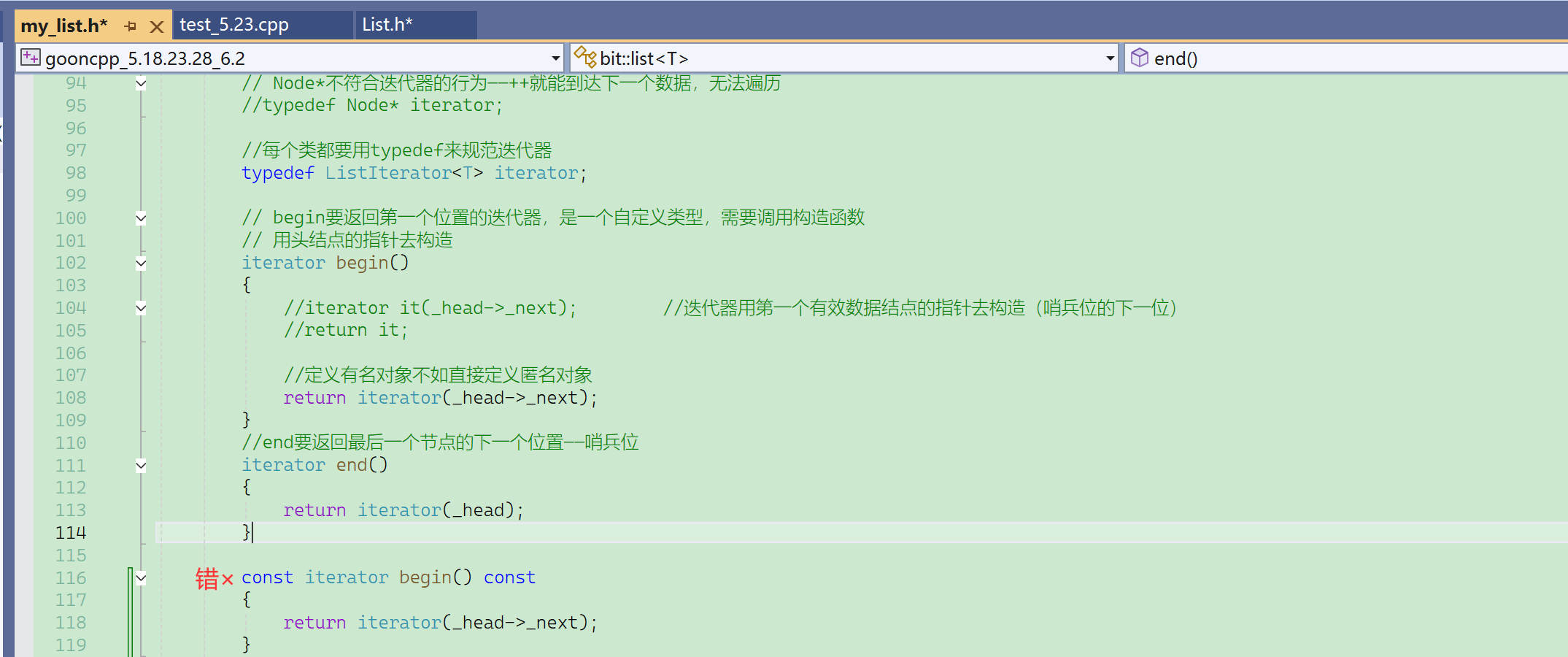
这会导致迭代器自身不能修改,无法++,无法迭代。
所以需要单独写一个类。
迭代器如何控制,自身可以修改、指向的内容不能修改?
迭代器控制修改的核心行为是*重载、->重载,控制他们的返回值是const的就好了。
只需要改一下这两个函数的返回值const T*、const T&,和类名就可以了。
template<class T>
class ListConstIterator
{typedef ListNode<T> Node;typedef ListConstIterator<T> Self;Node* _node;
public:ListConstIterator(Node* node):_node(node){}// ++it;Self& operator++(){_node = _node->_next;return *this;}Self& operator--(){_node = _node->_prev;return *this;}Self operator++(int){Self tmp(*this);_node = _node->_next;return tmp;}Self& operator--(int){Self tmp(*this);_node = _node->_prev;return tmp;}//*itconst T& operator*(){return _node->_data;}const T* operator->(){return &_node->_data;}bool operator!=(const Self& it){return _node != it._node;}bool operator==(const Self& it){return _node == it._node;}
};注意一下,不需要const iterator对象,也就不需要const成员函数。
需要的是一个新设计的类,而这个新设计的类也不会有const对象,也不需要const成员函数。
但是会有const list对象,它会调用const的begin、end,它们的返回值是这个新设计的类。
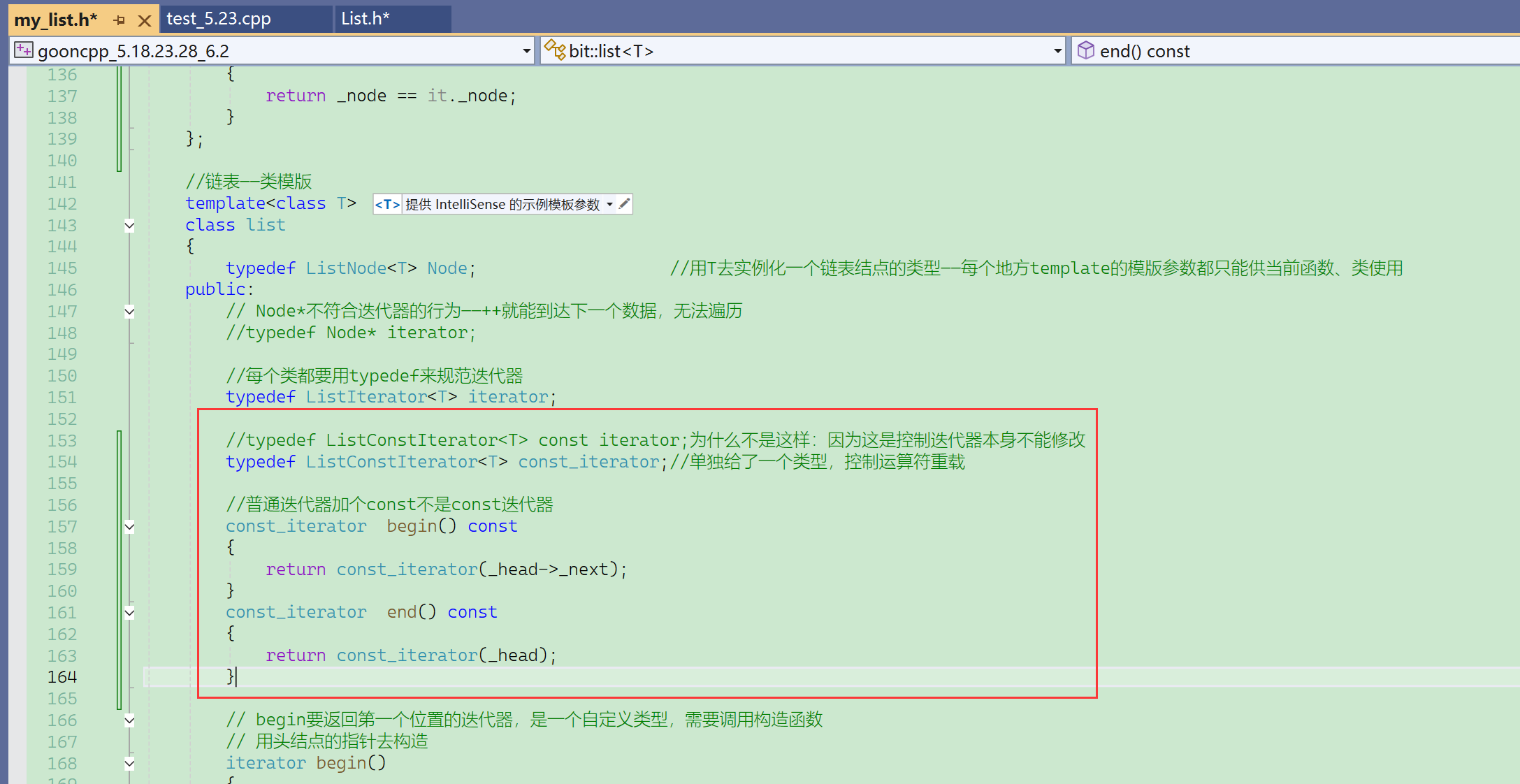
- 普通的list对象,调用普通的begin,返回普通的iterator,可读可写。
- const的list对象,调用const begin,返回const_iterator,它是只读的。
这两个类很重复。
能不能给typedef ListIterator<const T> const_iterator;???
那么所有的T*、T&都会变成const T*和const T&。
显然不可以。
因为_head->next和_head的结点内部,数据域的类型都是普通T。
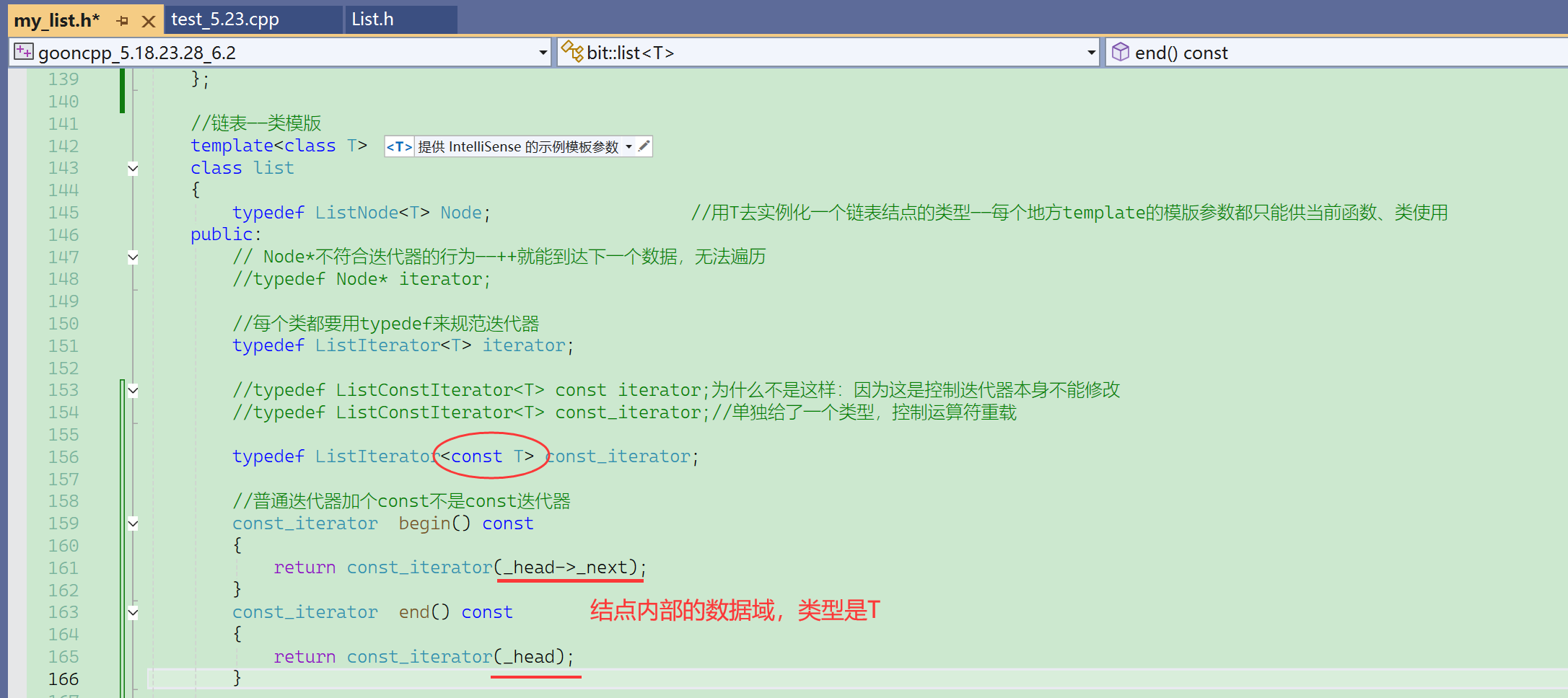
同一个模版ListIterator,给不同的模版参数就是不同的类型,不同的类型传值会发生错误。
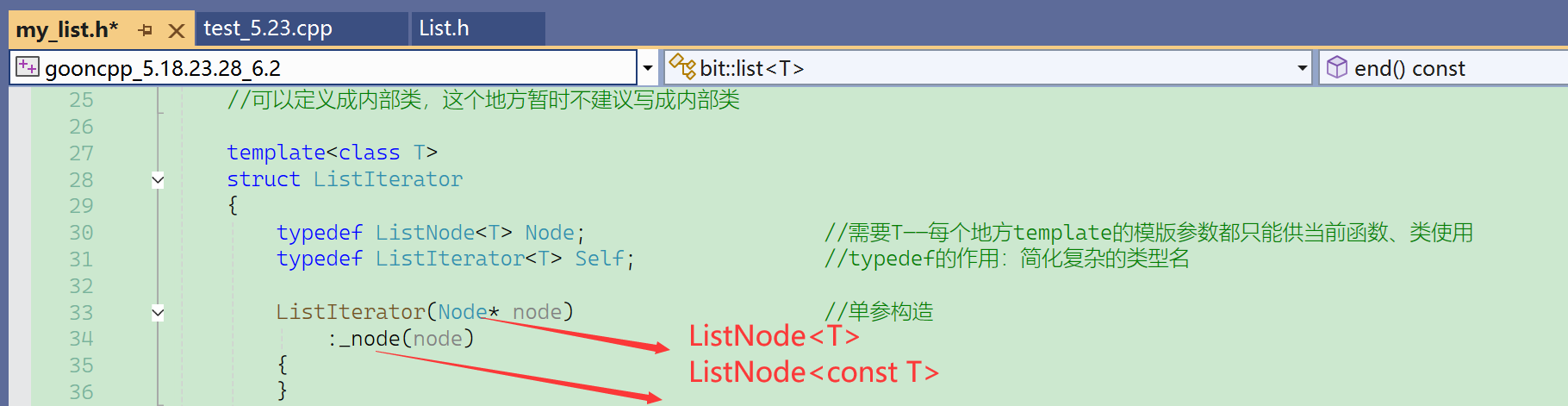
但是虽然不能改T这第一个模版参数,却可以增加ListIterator的模版参数,来达到效果。
第一个模版参数,不仅仅是*和&的返回值在用,其他地方也在用,改变它的影响会比较大。
这里仅仅是这两个返回值不同,可以通过增加模版参数的方式,来加以区分。
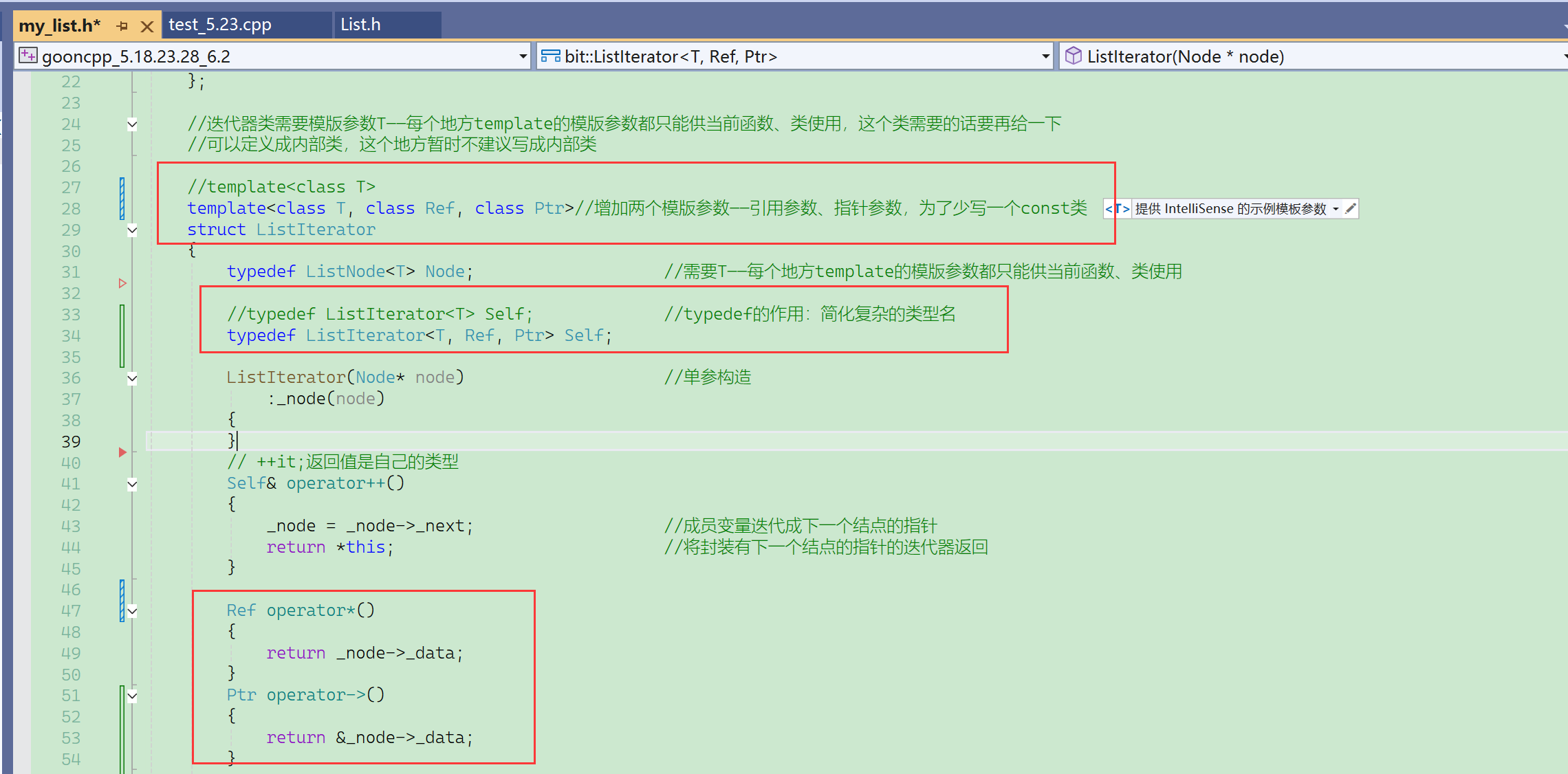
模版的好处:让编译器帮我们干活,大大提高了编程效率(运行效率不变)。
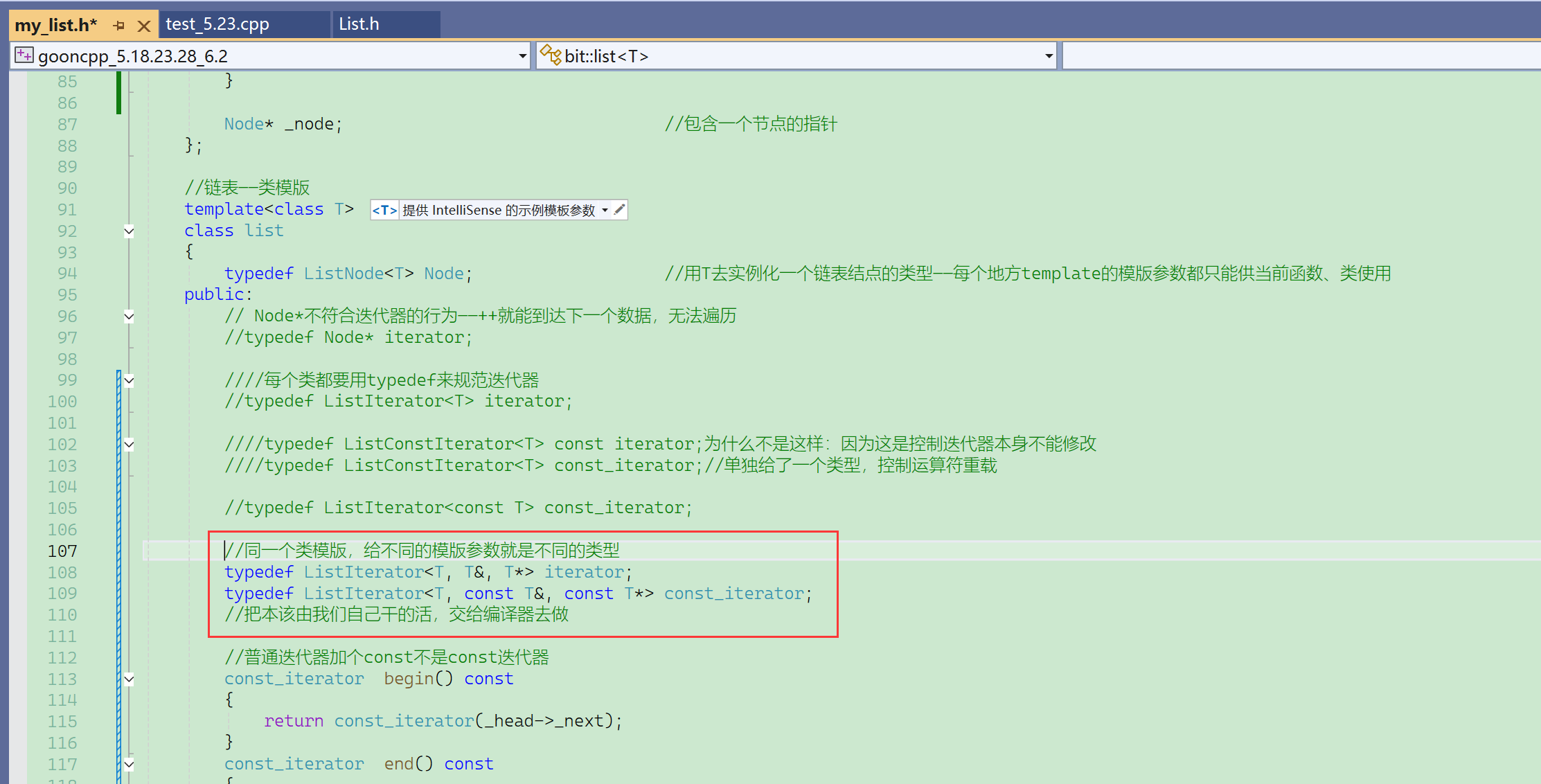
所以这里还是生成了一个新的类,但是不是完全由我们自己从零开始写的一个新类,而是利用模版参数的不同,由编译器帮我们生成的新类。

vector<int>、vector<double>就是两个类,在底层,编译器生成两份相似的代码。
传不同的模版参数,编译器会实例化出不同的两个类。
现在的写法,就是库里面的写法。
⑥ insert
头插、头删、尾插、尾删都差不多,重点是insert和erase,这两个函数写完了,那4个函数可以直接调用,代码复用。
有迭代器,就能拿到那个结点的指针,前提是迭代器用struct或者class加上public。
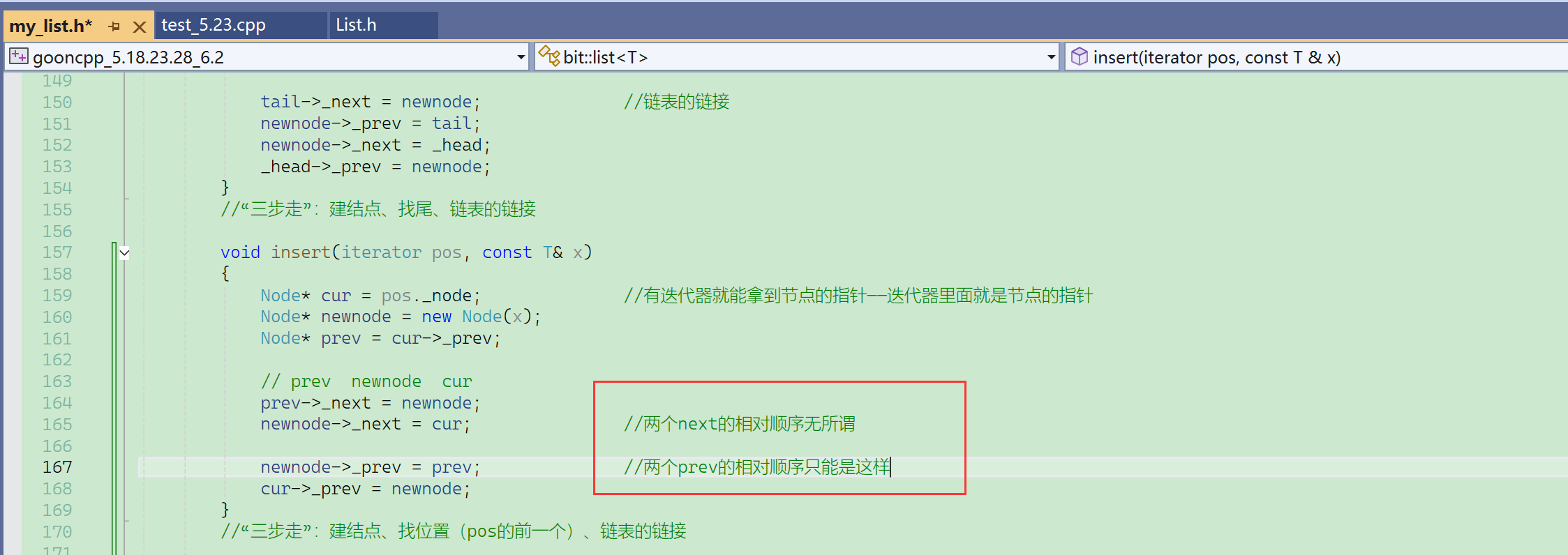
list的insert,在pos位置之前插入,以前C语言的时候传的是结点的指针,现在传的是迭代器。
没有iterator失效的问题,因为没有扩容的概念,不会进行异地数据迁移,pos位置的节点也没有改变。
但是库里面还是给了返回值:返回的是新插入元素的迭代器。
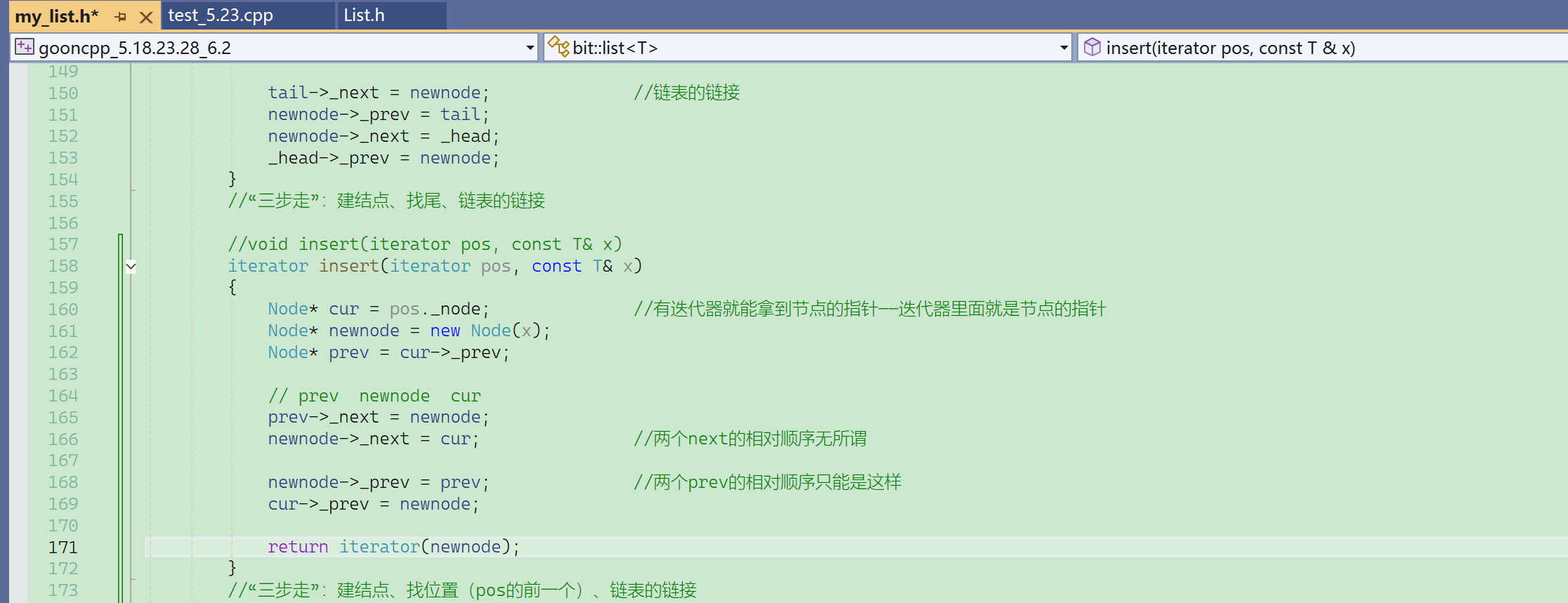
- 由于这里是双向带头循环链表,可以无限next下去,或无限prev下去。
- 那么每个位置都一定有prev,不用考虑prev为空的问题。
⑦ erase
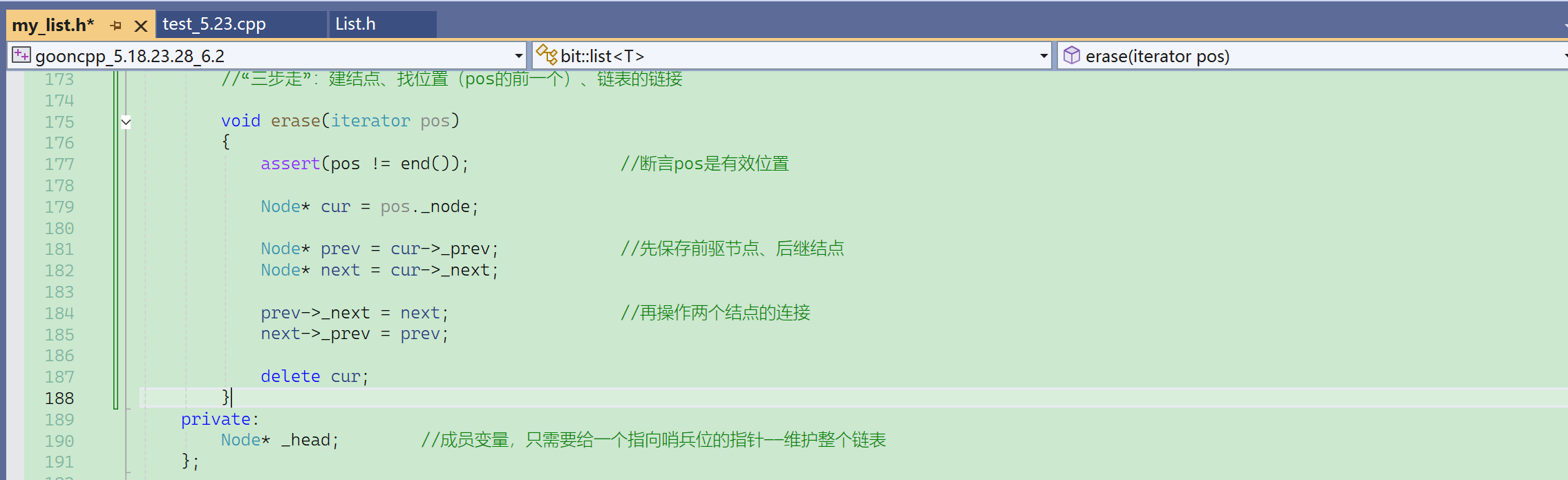
erase 删除pos位置的结点,erase完成后,pos失效了,pos指向节点被释放了。经典的野指针失效问题。
就一定需要给返回值,防止边删边走通不过,返回值给删除位置的下一个位置的迭代器。
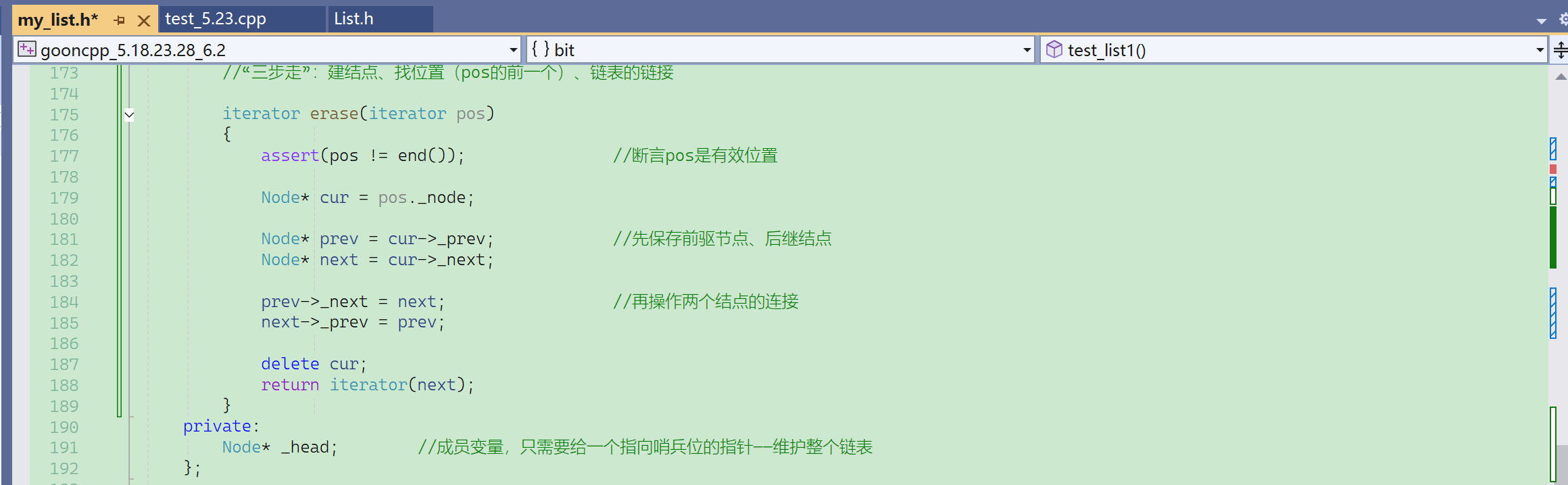
- 为什么断言不跟_head哨兵位比?
- 因为pos是迭代器,迭代器就跟迭代器比。
⑧ 尾插、尾删、头插、头删
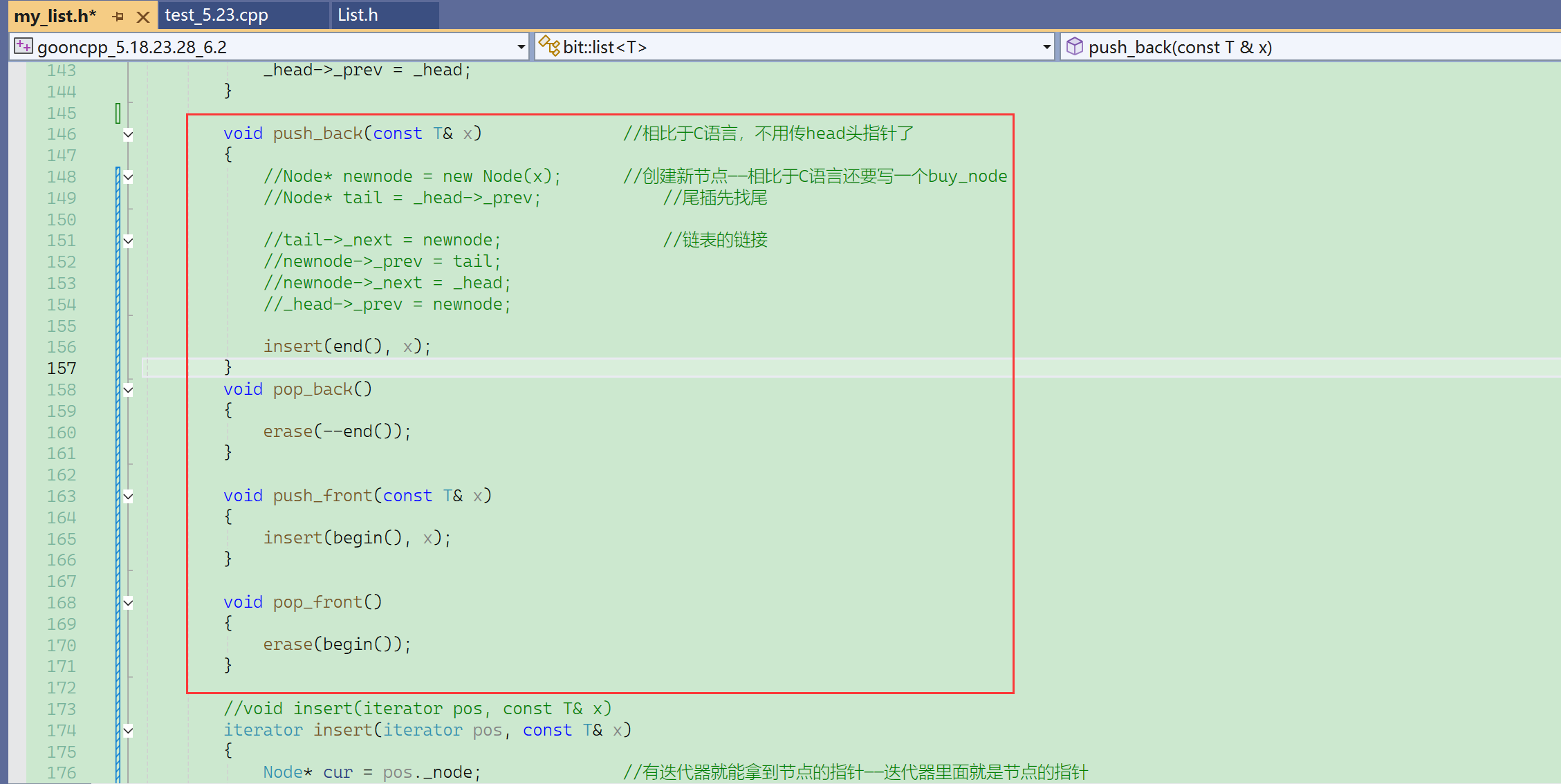
成员函数也公有,成员变量也公有,就可以直接写成struct。
结点、迭代器写成struct:
- 平时接触的是list,这是最外层的封装,而ListNode、ListIterator等类型我们是不用去接触的。(潜藏层)
- 在list里面只有一个封装好的iterator, 这个封装好的iterator的操作*it/++it/it!=...... 在每个平台都是通用的。
- 而it._next->data这样的代码却不是通用的,虽然能通过,但是用到库里的链表的it._nect->data就不行了,因为it的成员变量叫什么我们并不知道。
所以也不存在说放成公有能随便访问的问题。
放成公有,只是为了方便设计者在设计List这个类的时候,使用得更方便。
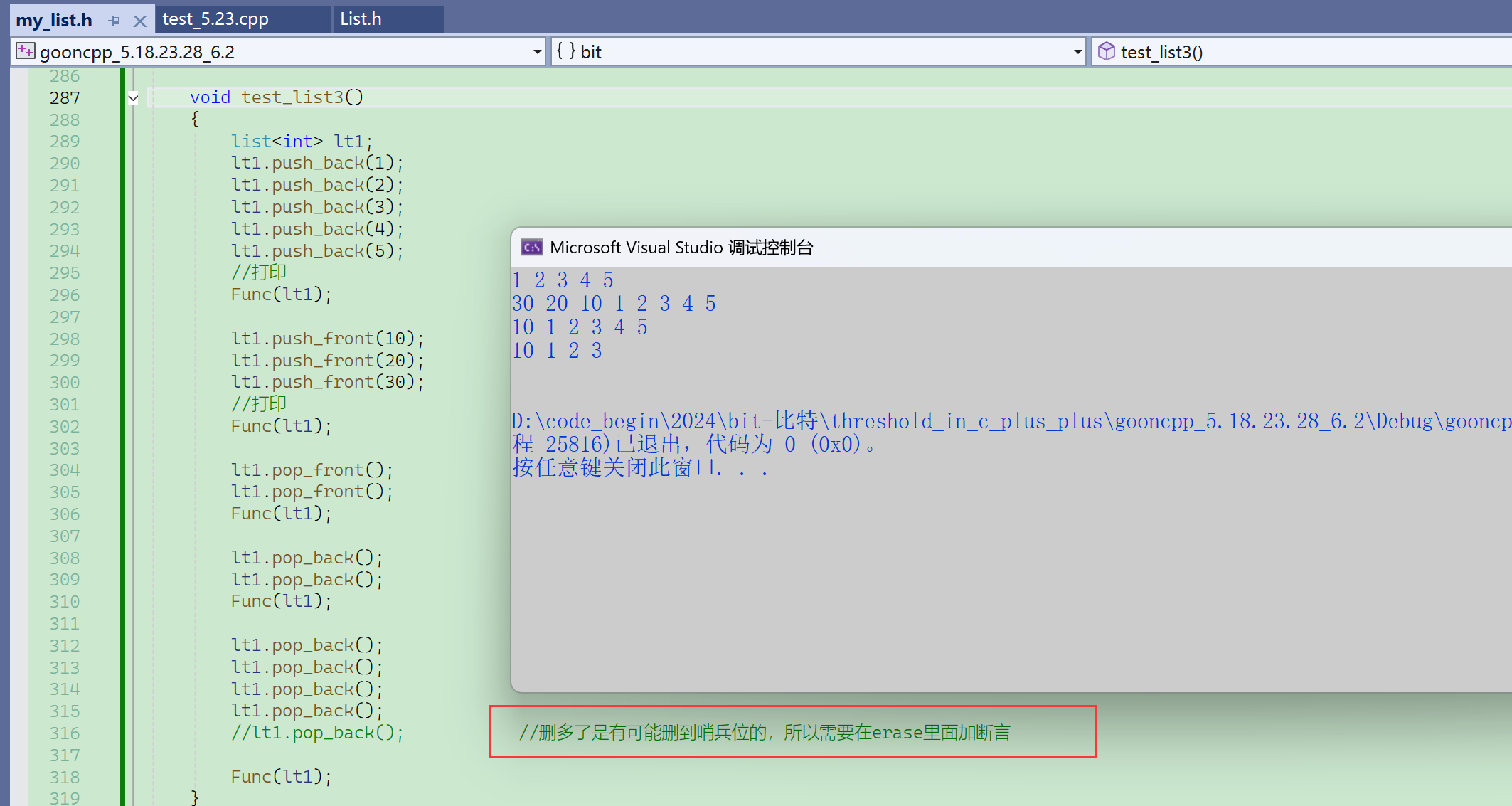
⑨ 测试
之前C语言的代码,带头单链表仅仅检查pos不为空,如果删到哨兵位是检查不出来的。
为了检查哨兵位,除了pos位置,还要传一个哨兵位的指针。而这里有迭代器可以记录哨兵位的位置。
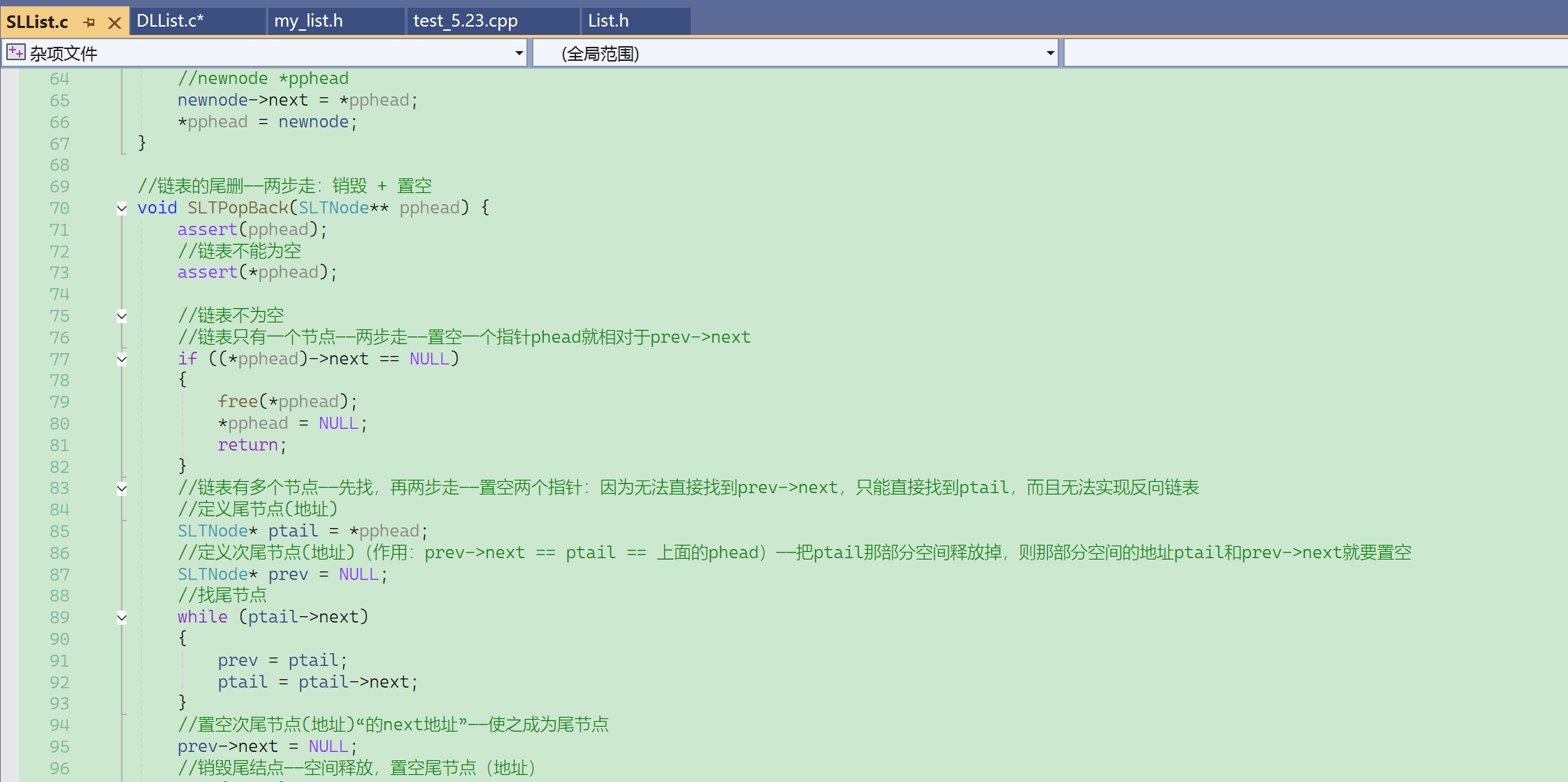
带头双向链表,传pos可以检查哨兵位。
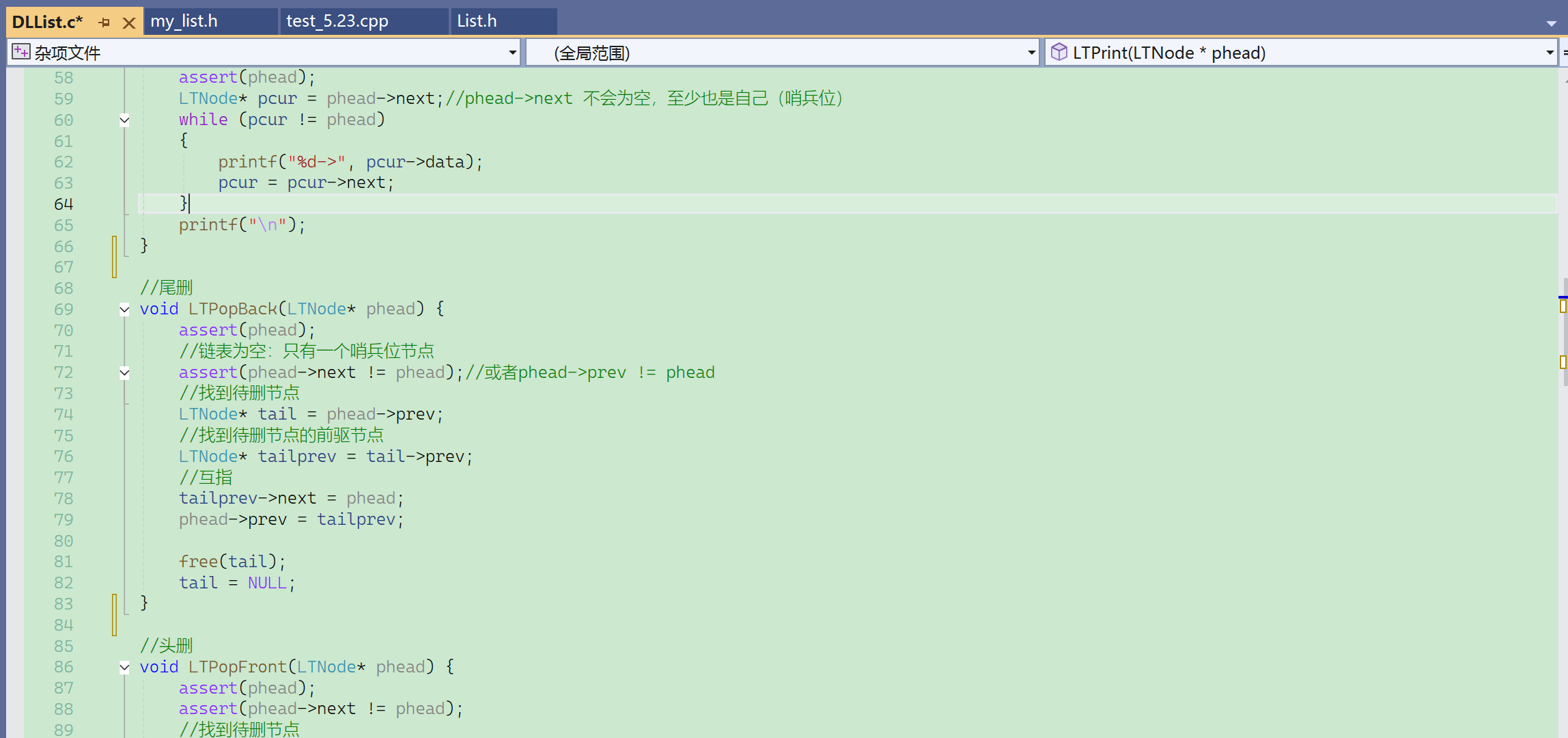
2024.5.28
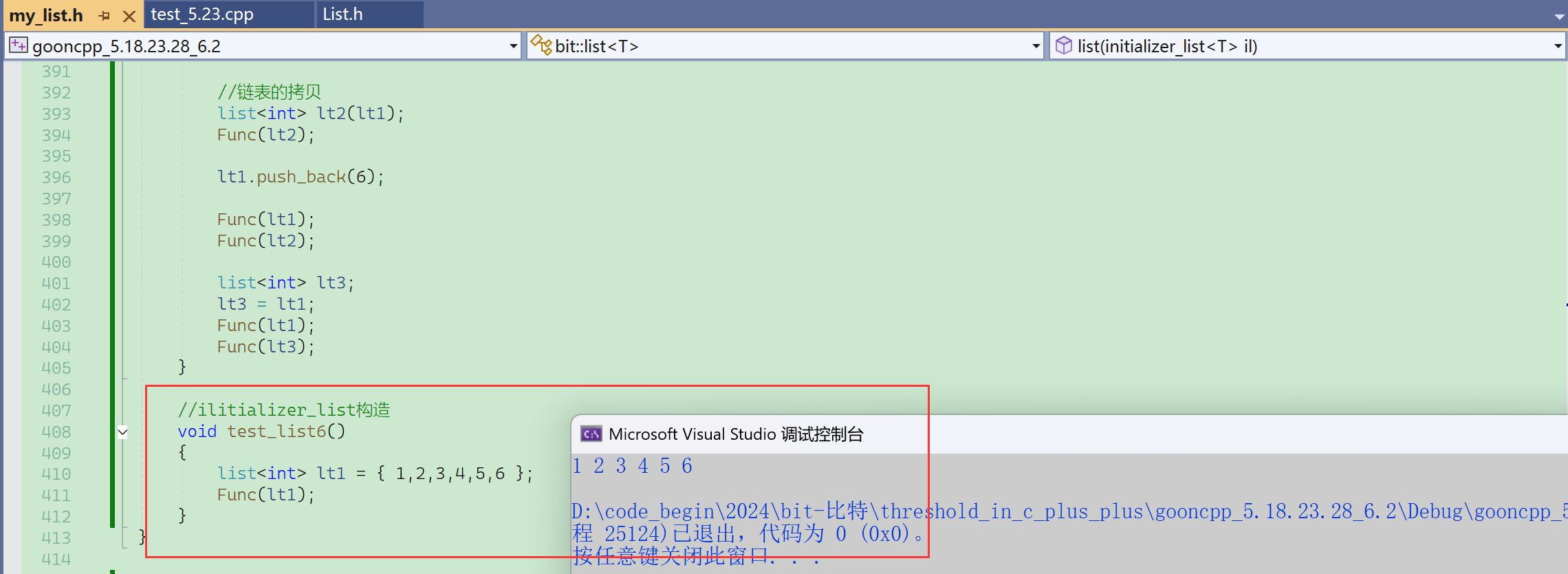
① 链表的拷贝
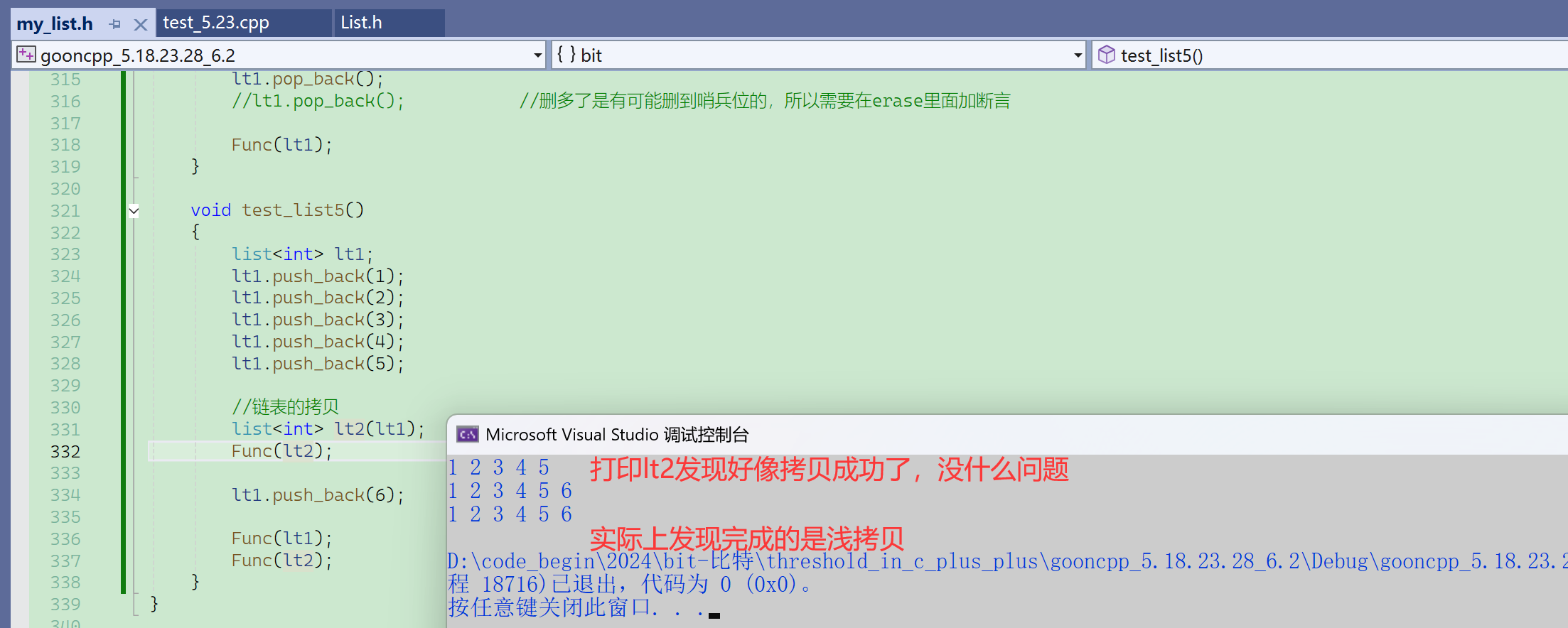
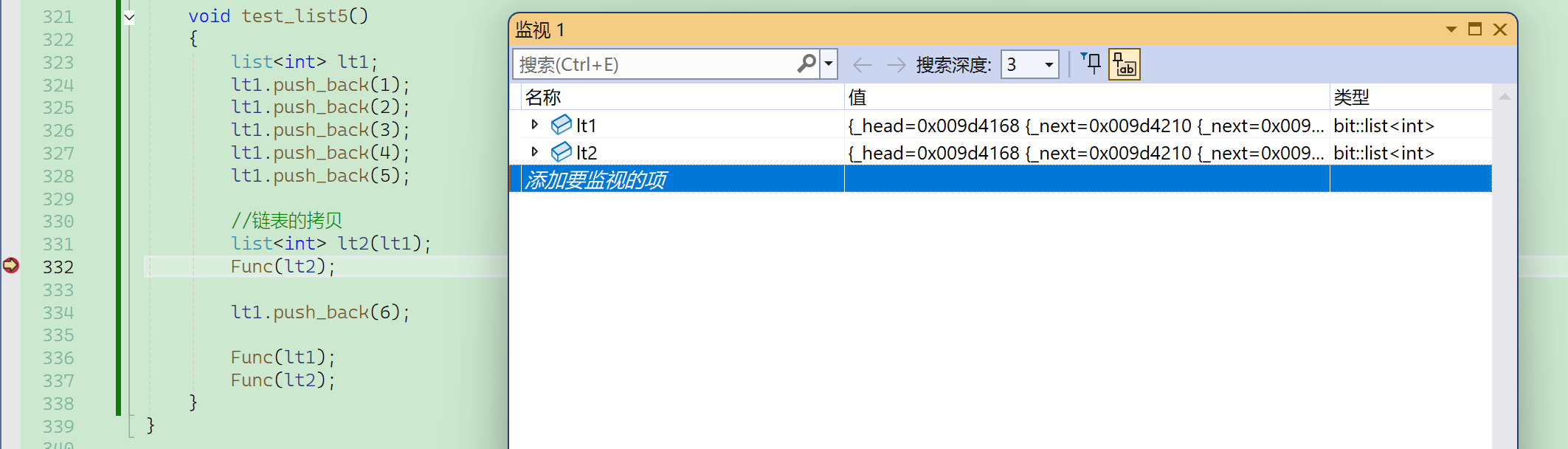
通过调试也能观察到,lt1和lt2的地址,指向的是同一块内存空间。
这里没出错误的原因还在于没有显式实现析构函数,链表只有一个Node*的成员变量,默认生成的析构对内置类型不做处理。补上析构函数,程序就会出错。
(Ⅰ)析构
传统的写法,需要一个结点一个结点地去释放。
这里可以使用复用的方式去写,因为一般的容器都会提供一个clear函数。
clear的作用是清除所有的数据点,但容器的成员变量结构不变。
在链表这里就是清除所有结点,但哨兵位不动。
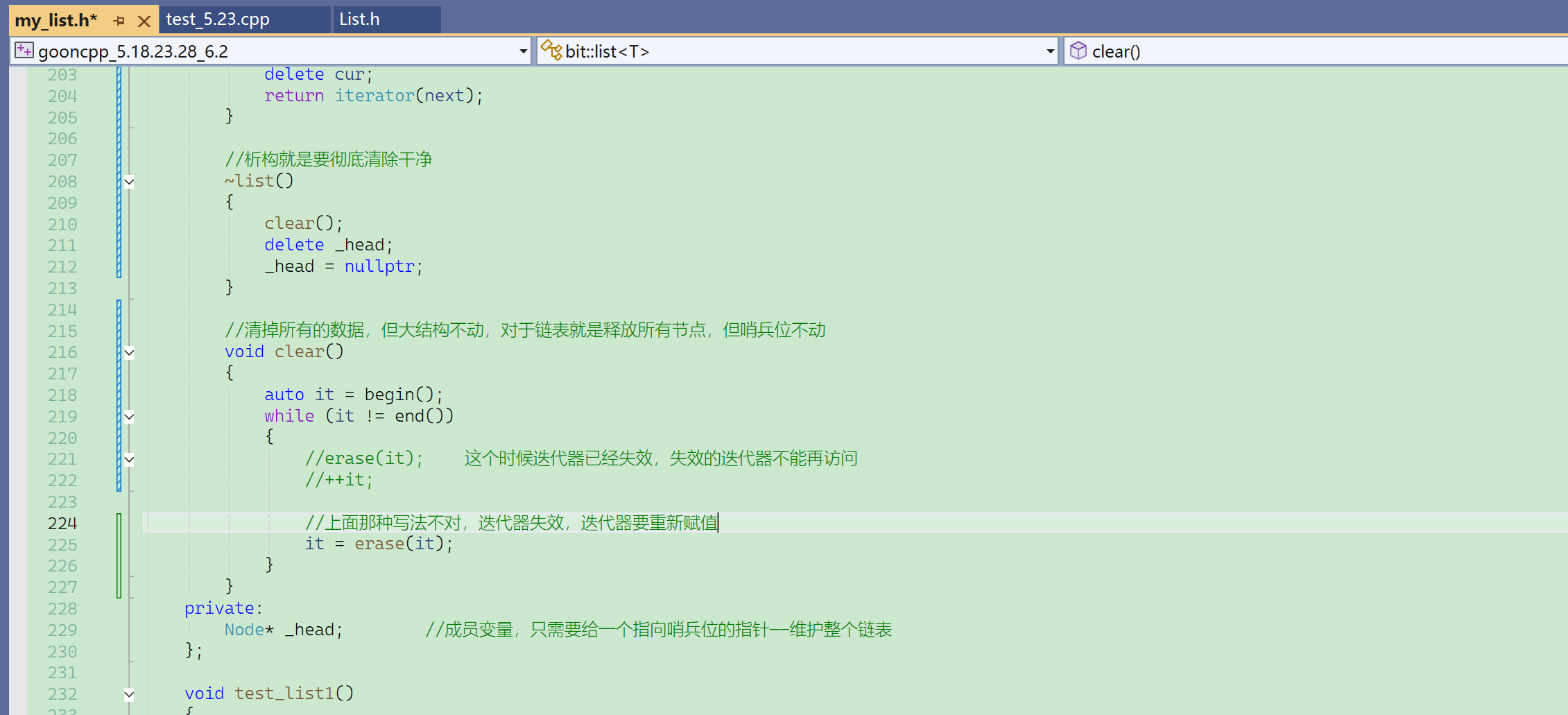
有了析构函数之后,程序再执行就会崩溃。
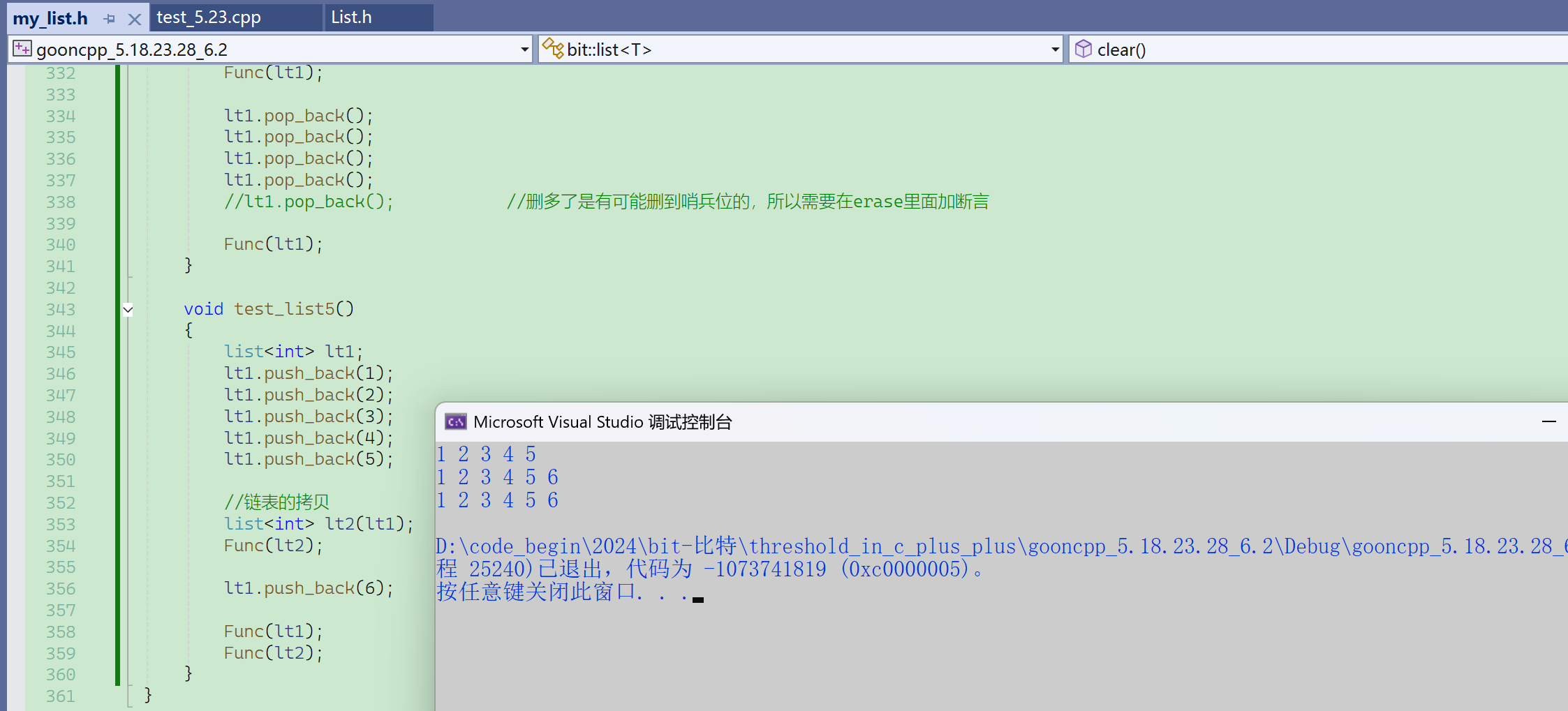
(Ⅱ)拷贝构造
传统的写法是一个结点一个结点地拷贝。insert的前提是有一个哨兵位结点。
这里也可以采用复用的方式。
提供一个空初始化的函数,用于创建头结点。
多个函数都会用到这段代码,就可以拿出来单独封装一个函数。
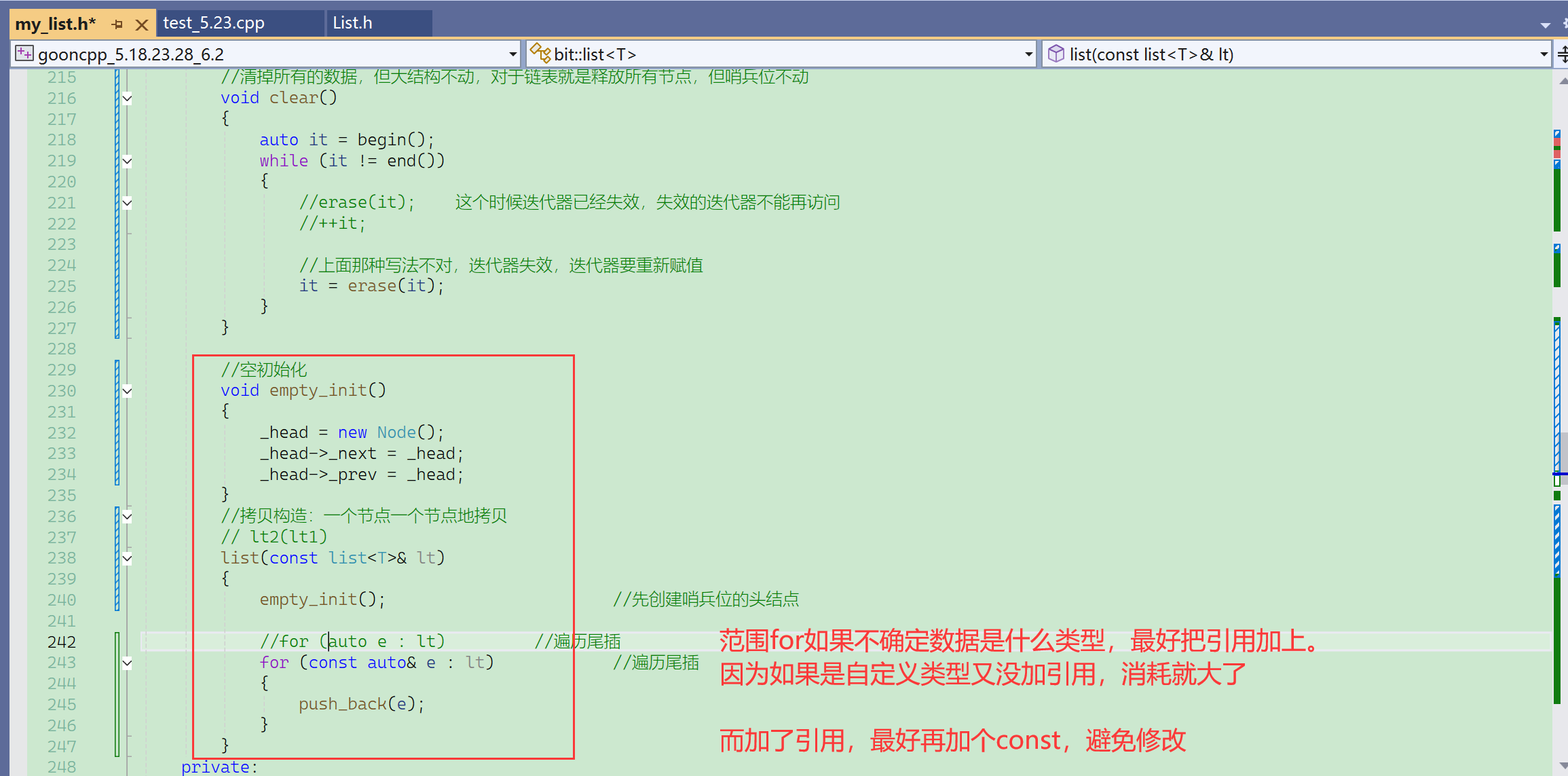
范围for相当于是把*it赋值给e,如果元素是自定义类型,就是拷贝构造了。
所以使用范围for的时候,如果不确定是什么类型,或者说就是自定义类型,那就最好把&加上。
如果确定是int之类的内置类型就无所谓了。
保险起见,加&肯定是更好的。
再来看拷贝就不会出错了。
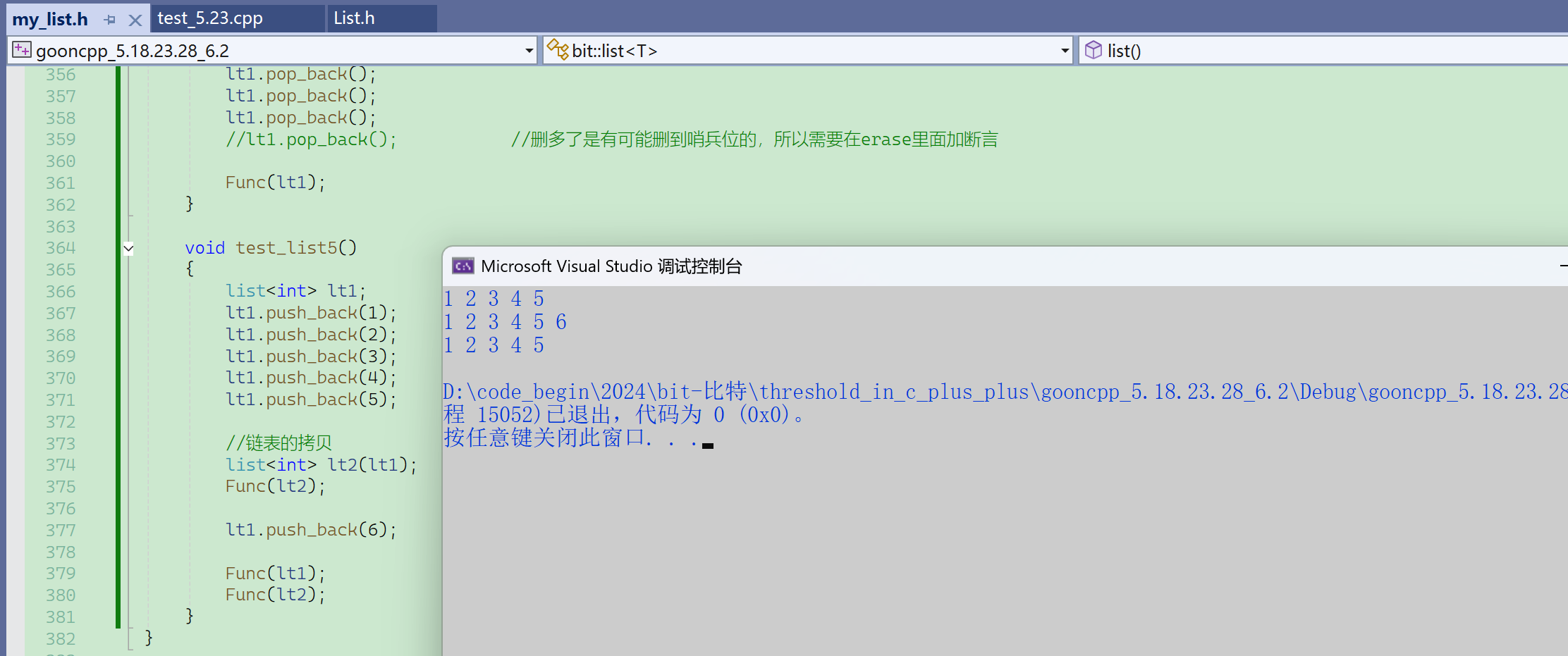
像之前的数组,一个指针指向一片连续的物理空间,拷贝的时候一下把空间开好,一个指针拷贝就好了,没必调用push_back之类的函数。
而现在的链表,以及之后的树,拷贝起来比较麻烦,就可以去复用一些之前写的东西。
(Ⅲ)赋值重载
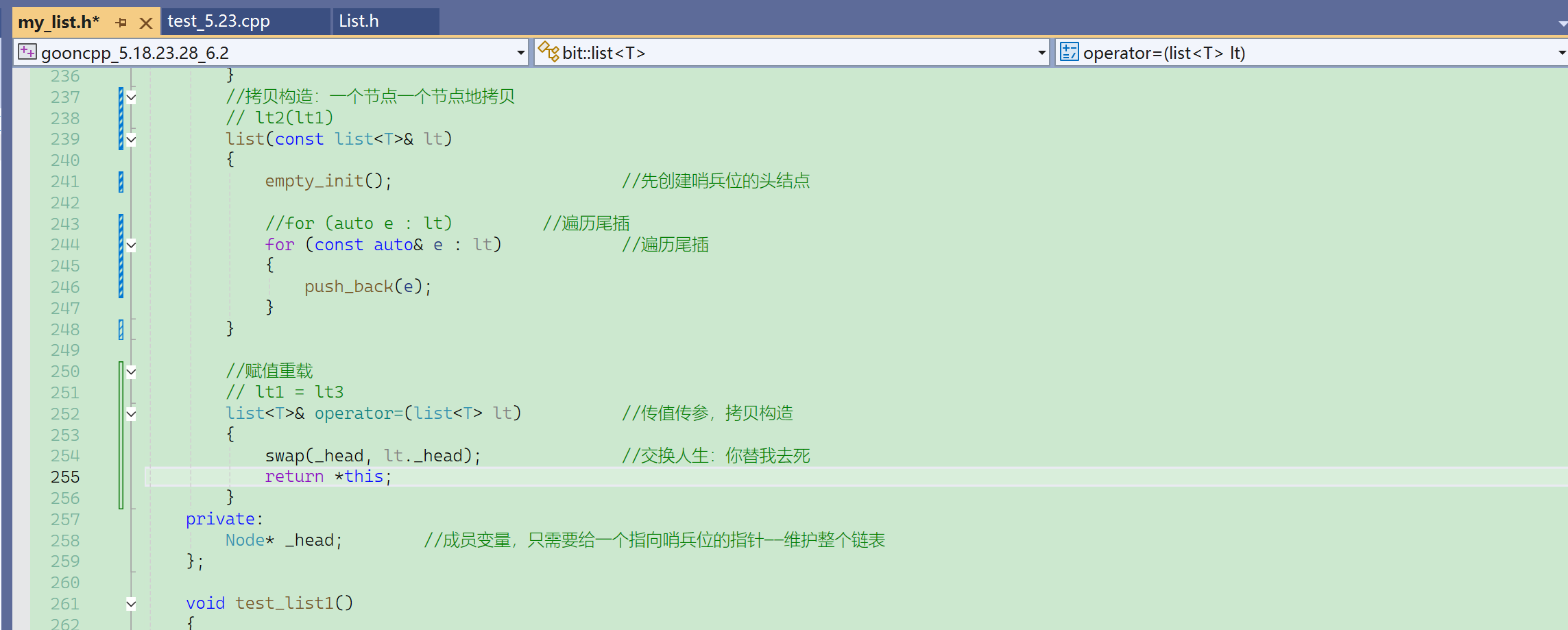
② initializer_list构造
需要实现一个initializer_list的构造。

这里initializer_list的构造的参数,可以不用加引用,这里不存在需要多一重拷贝的问题,花括号直接就可以初始化给它。
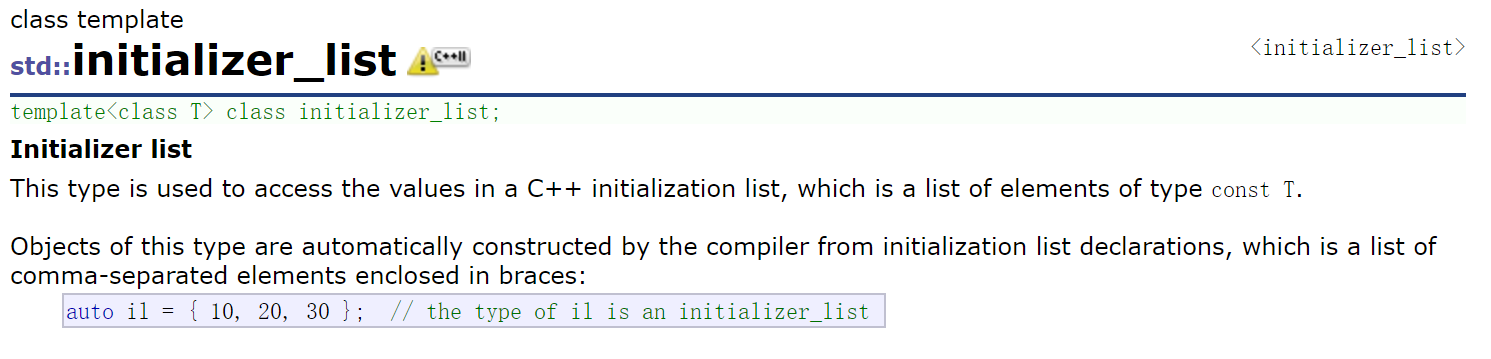
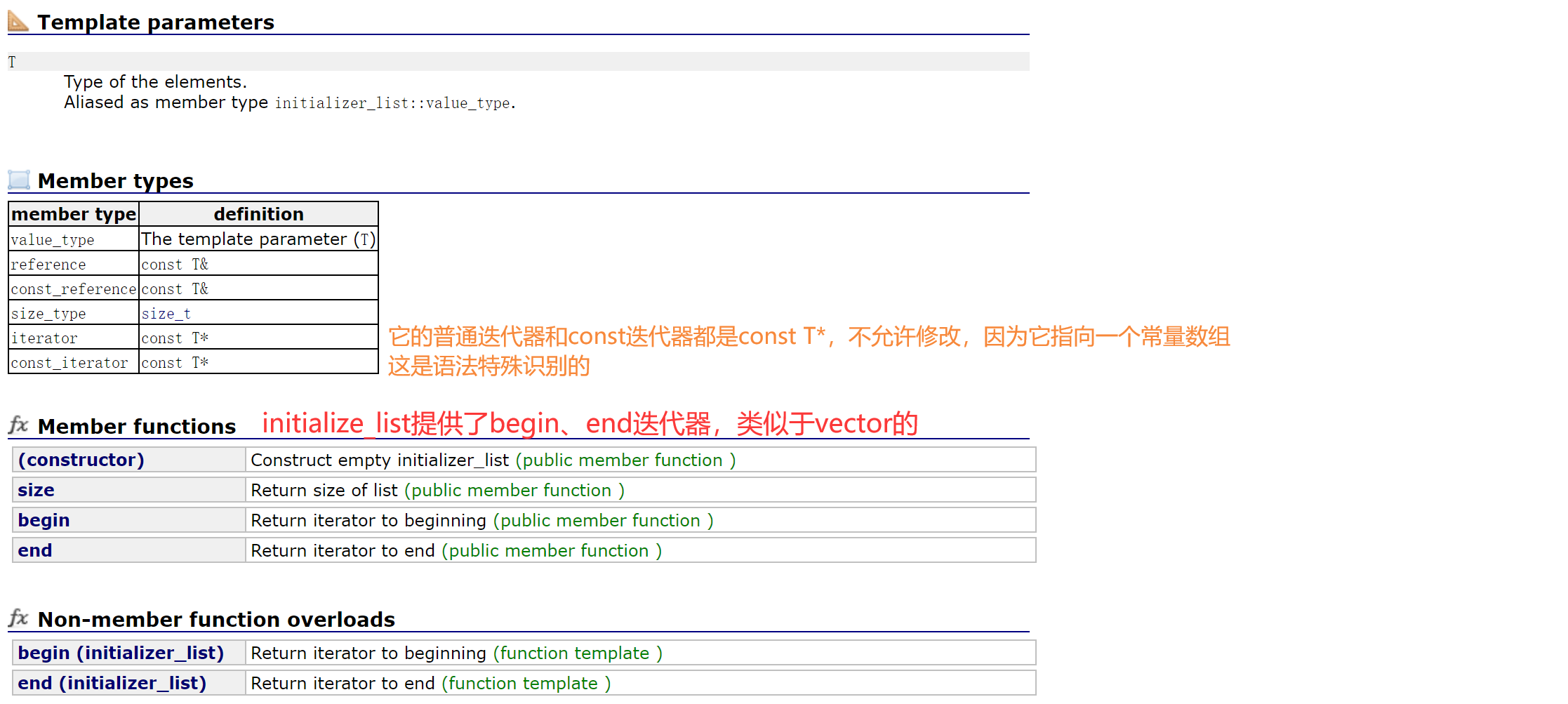
initializer_list可以理解为一个常量数组,它的底层就是两个指针,指向花括号常量数组的开始和结束。32位下sizeof(initializer_list)是8字节。
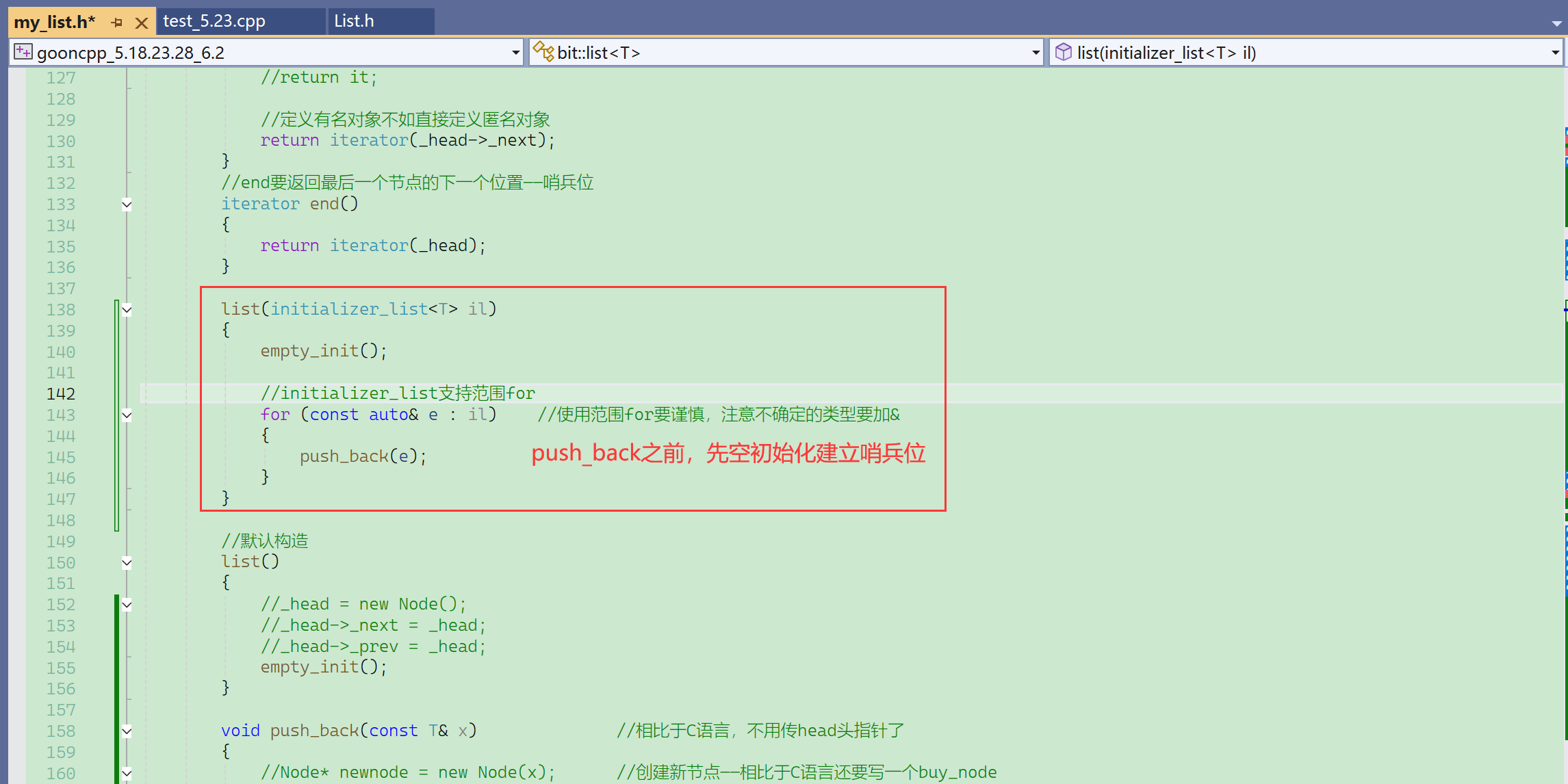
赋值重载不需要先空初始化,因为对象已经创建好了。
其他的一些接口函数就不再一一实现了,都不是那么重要,会使用就可以了。
我们的目的不是要实现一个完善的链表。
链表这部分,最重要的就是“迭代器”。
底层连续的物理空间才可以使用原生指针作迭代器。
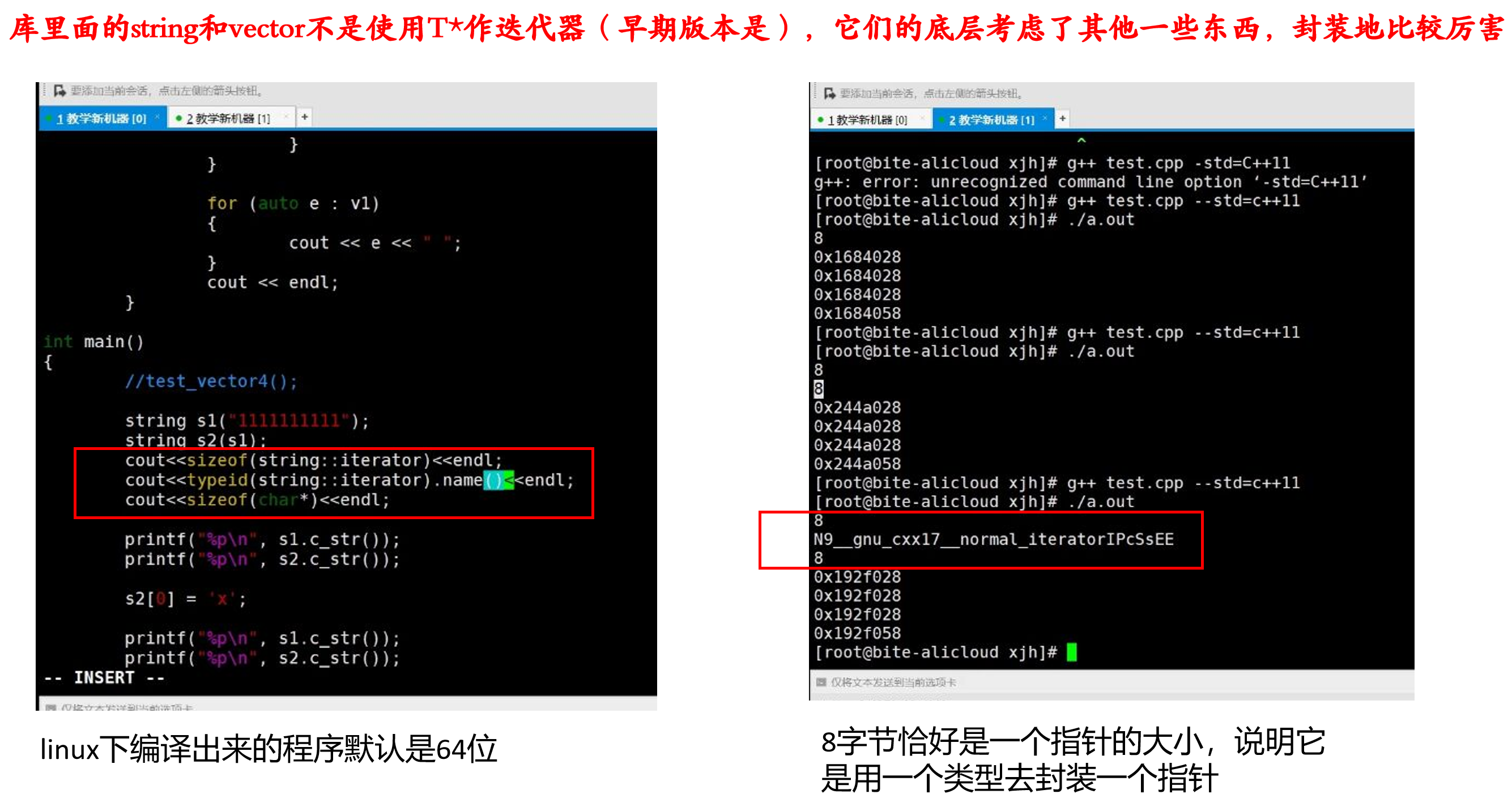
库里面的string和vector不是使用T*作迭代器(早期版本是,比如SGI的STL3.0),它们的底层考虑了其他一些东西,封装地比较厉害。本质还是一个T*,不过类似于链表这里的处理,进行了一个封装。
initializer的迭代器就是原生指针(const T*,修饰不能修改);成员变量也是两个指针,一个指向常量数组的开始,一个指向常量数组的结束。
来会看之前的代码:
会觉得说迭代器不需要手动更新。

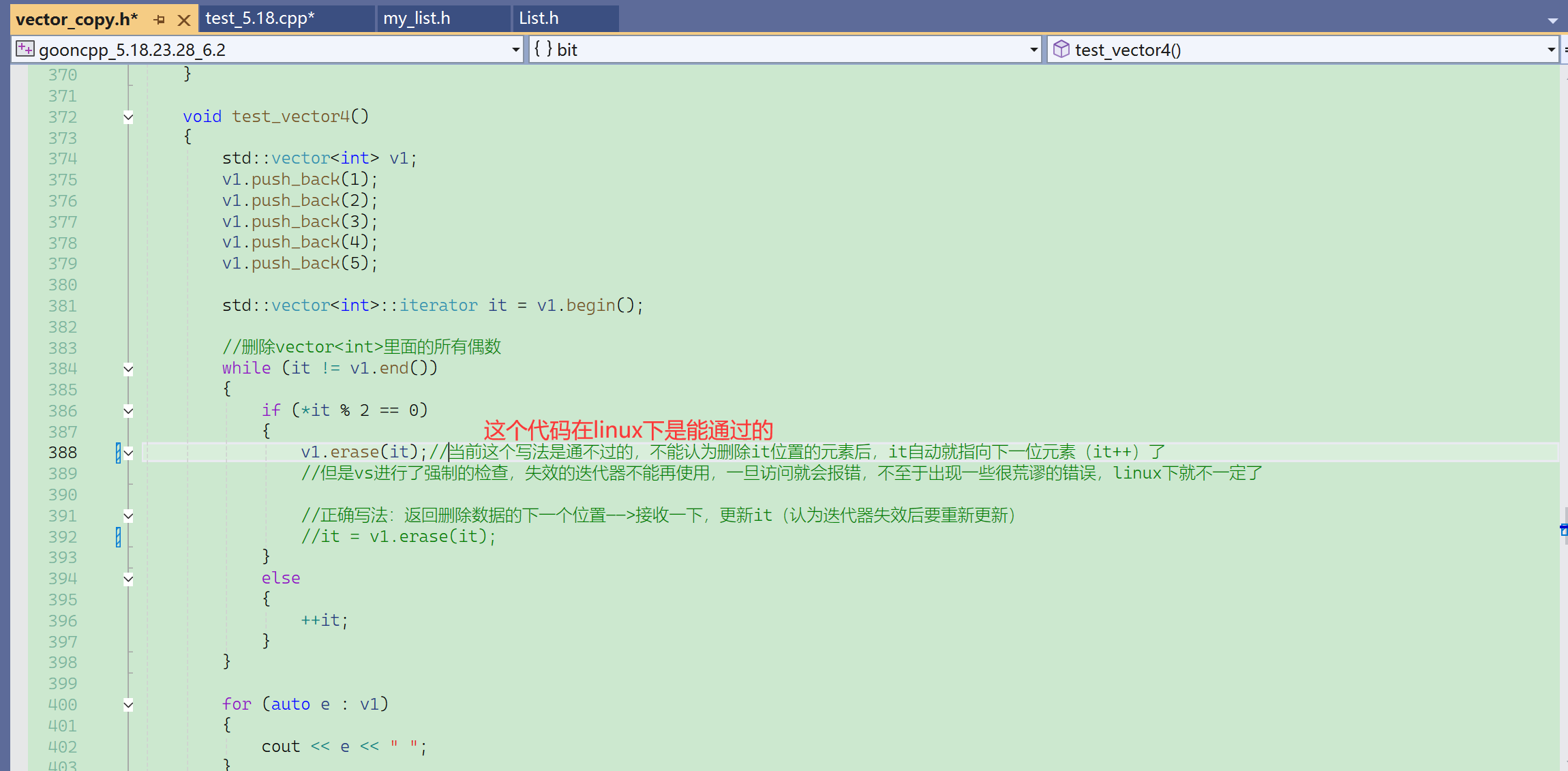
在linux下,能正常输出1,3,5。而linux下的vector的迭代器,也是一个封装过的复杂类型。
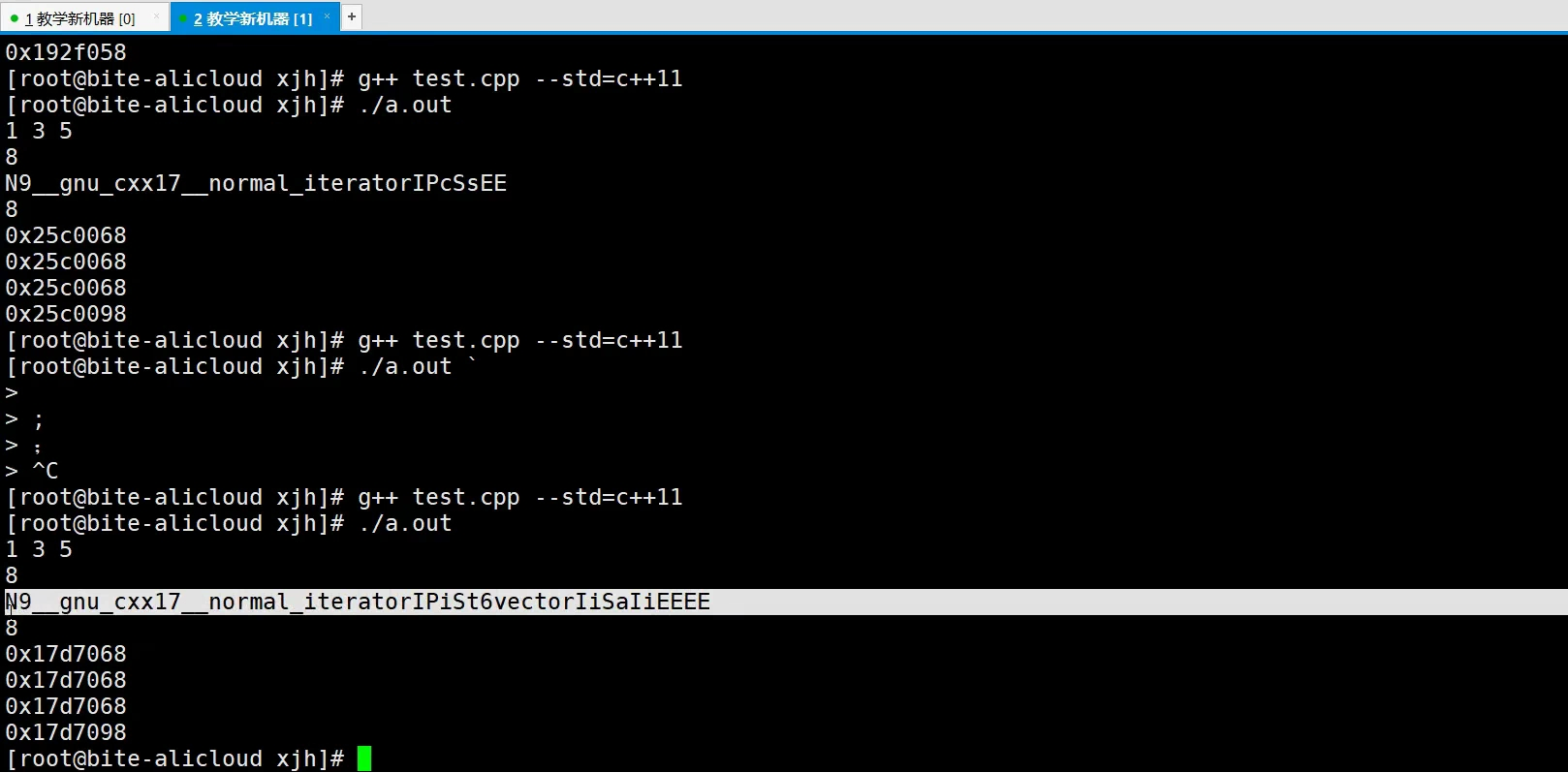
这个复杂类型是8字节,说明它只封装了一个指针。可以看到linux下的封装没做什么额外的功能,和普通的T*没什么区别。
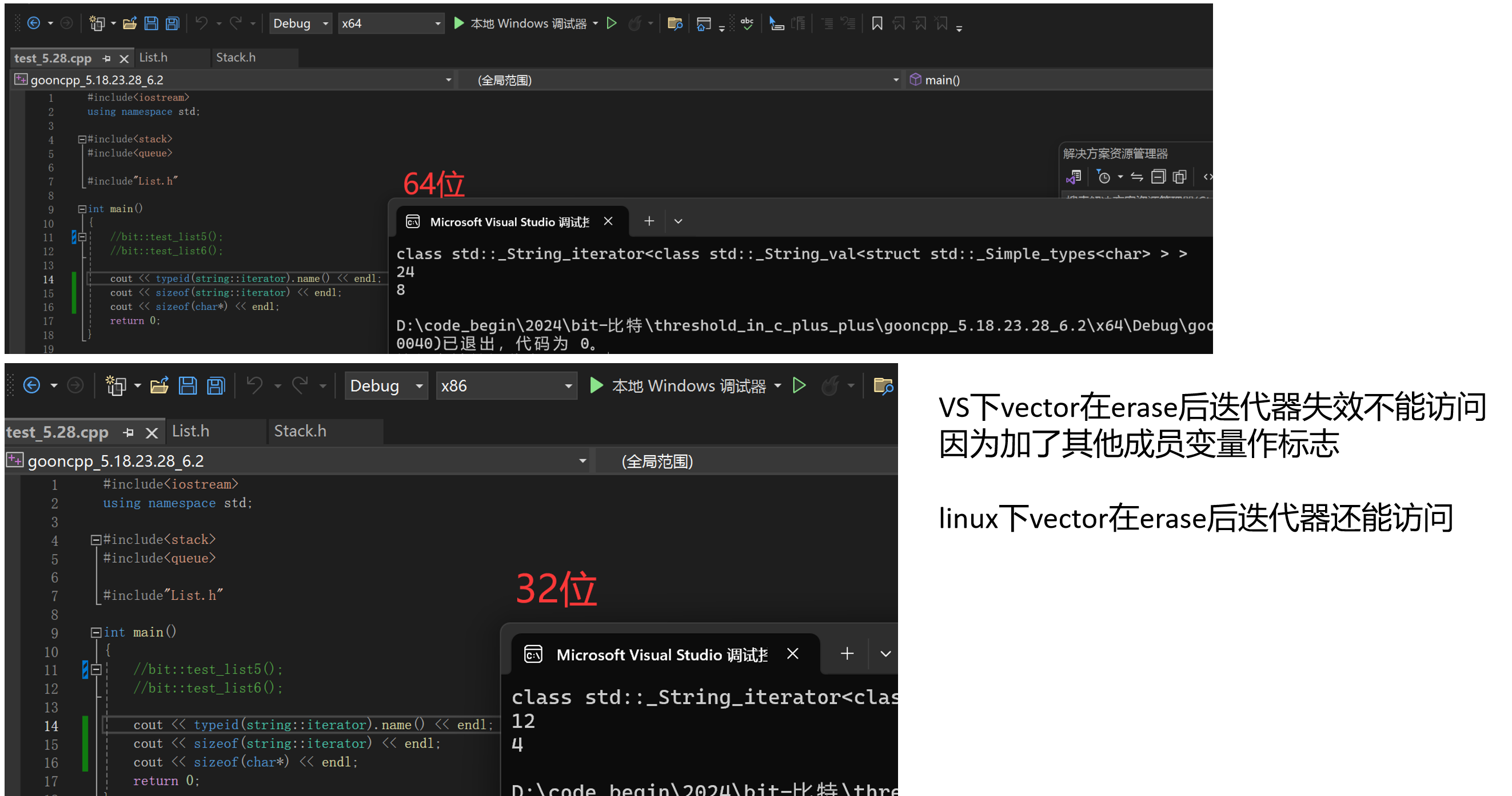
但是VS下面不一样。
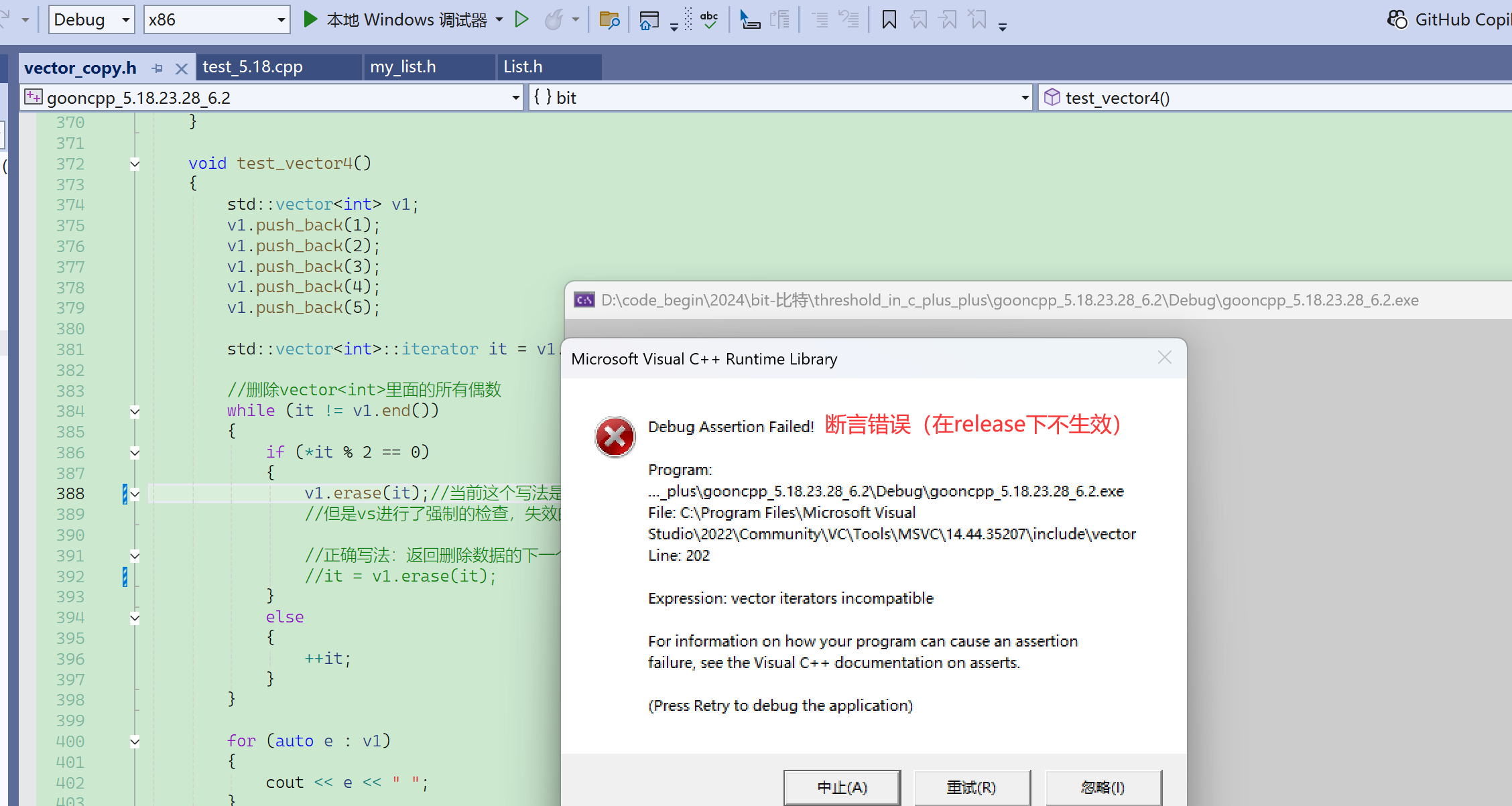
描述:vector的迭代器不兼容。
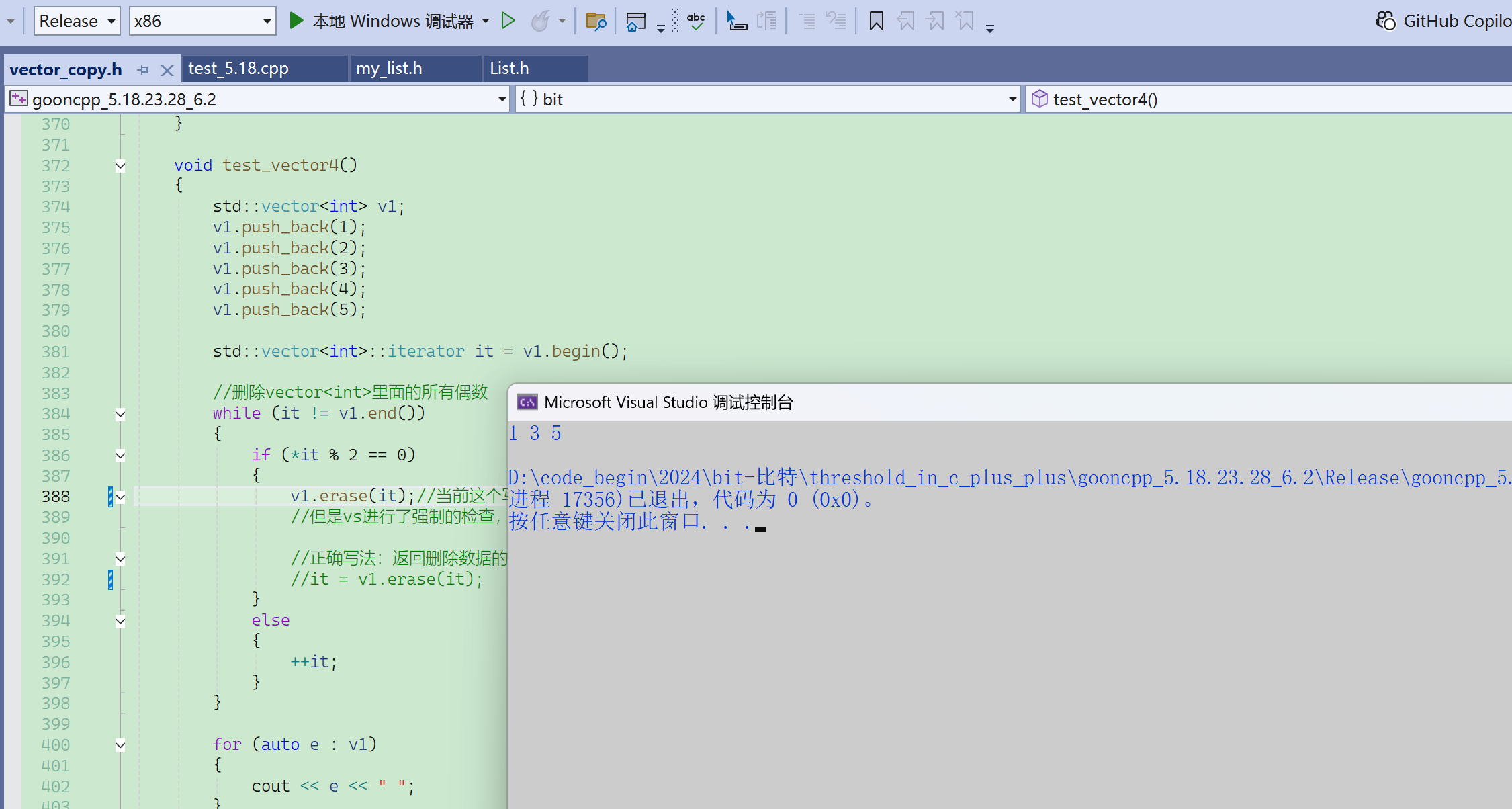
vector的迭代器为什么不是4字节而是12字节(32位),就是因为它做了额外的处理,除了这个指针之外,应该还增加了一些标志,当迭代器有效时标志有效,当迭代器失效时标志失效。
标志失效(false),再访问迭代器就会报断言错误。VS下的自定义类型封装原生指针,给出了更多更丰富的功能,一旦迭代器失效,就不允许再访问了,否则就报断言错误。
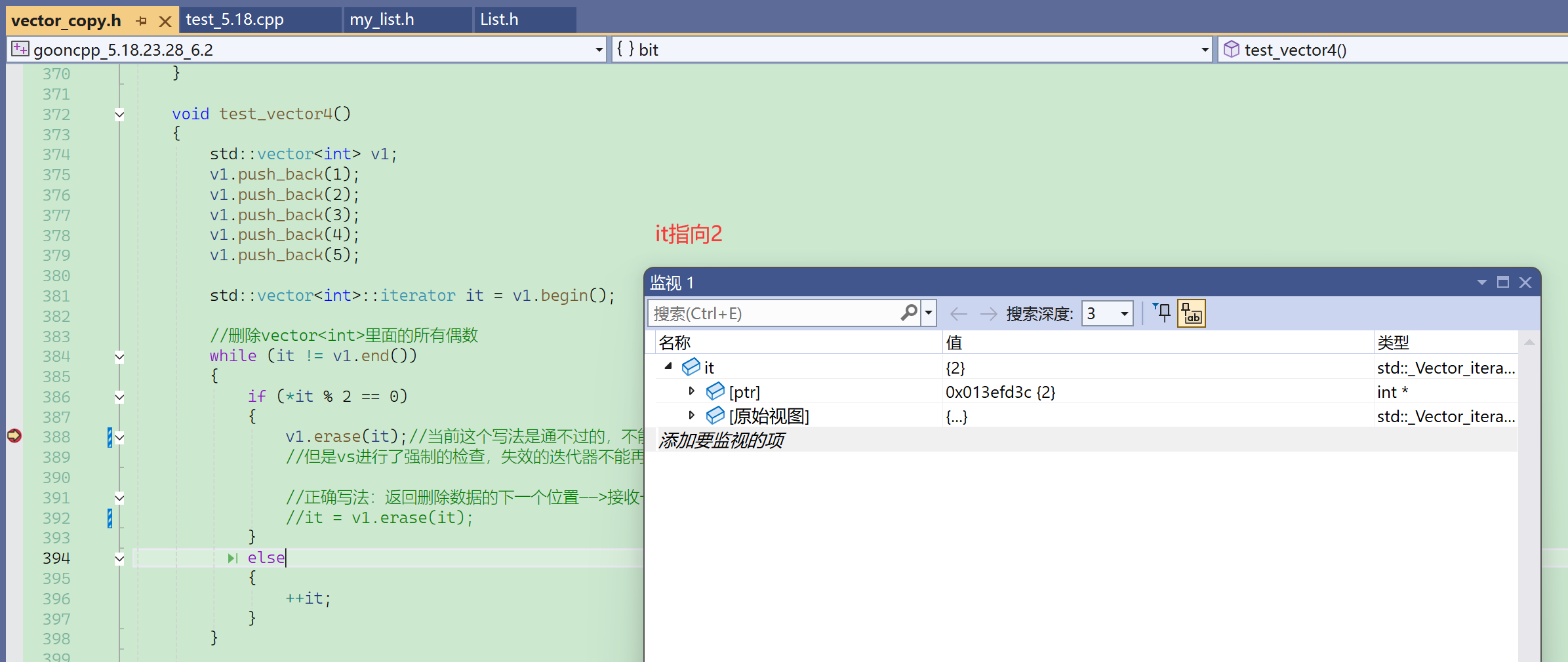
按f10,调试下一步。
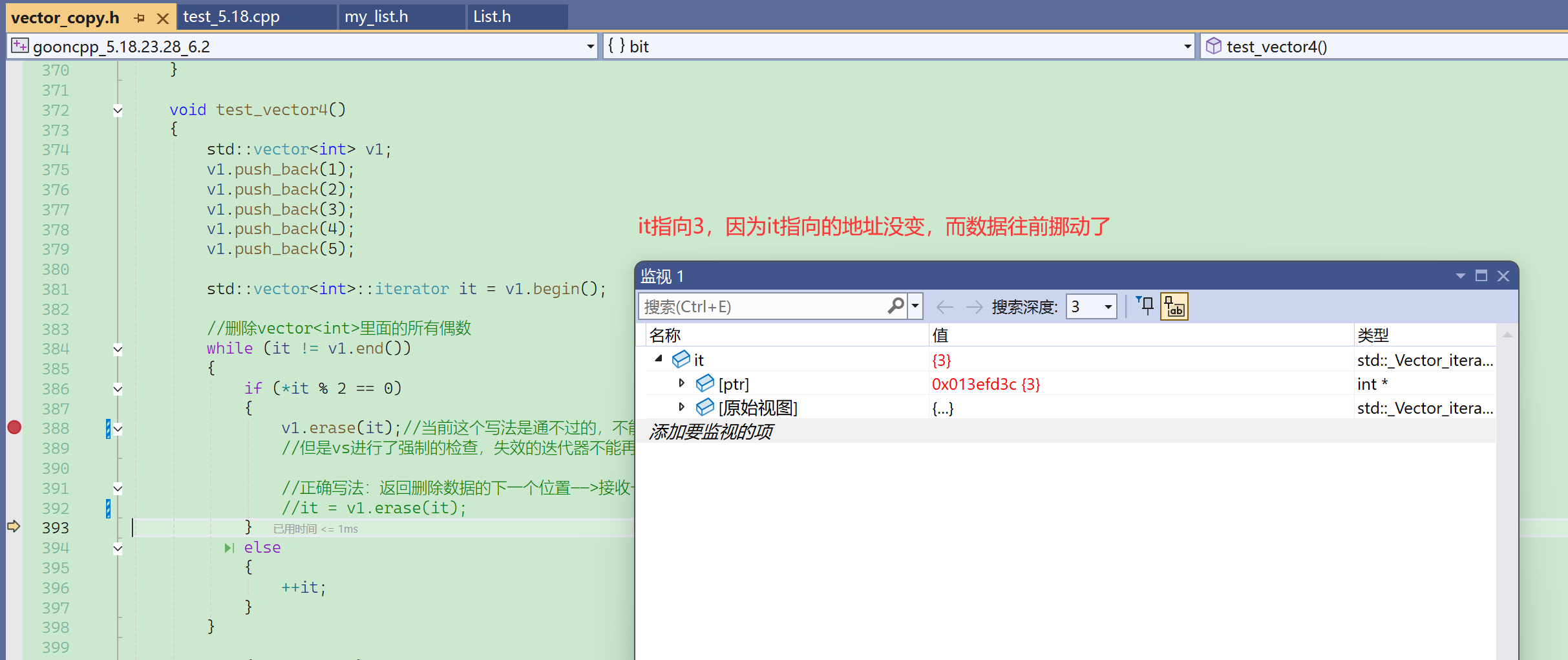
此时还没有报错,迭代器失效后不会立即报错,不使用就不报错。
此时再调用迭代器的解引用、不等于、++……等成员函数,就会遇到false标志,访问失效的迭代器报出断言错误。
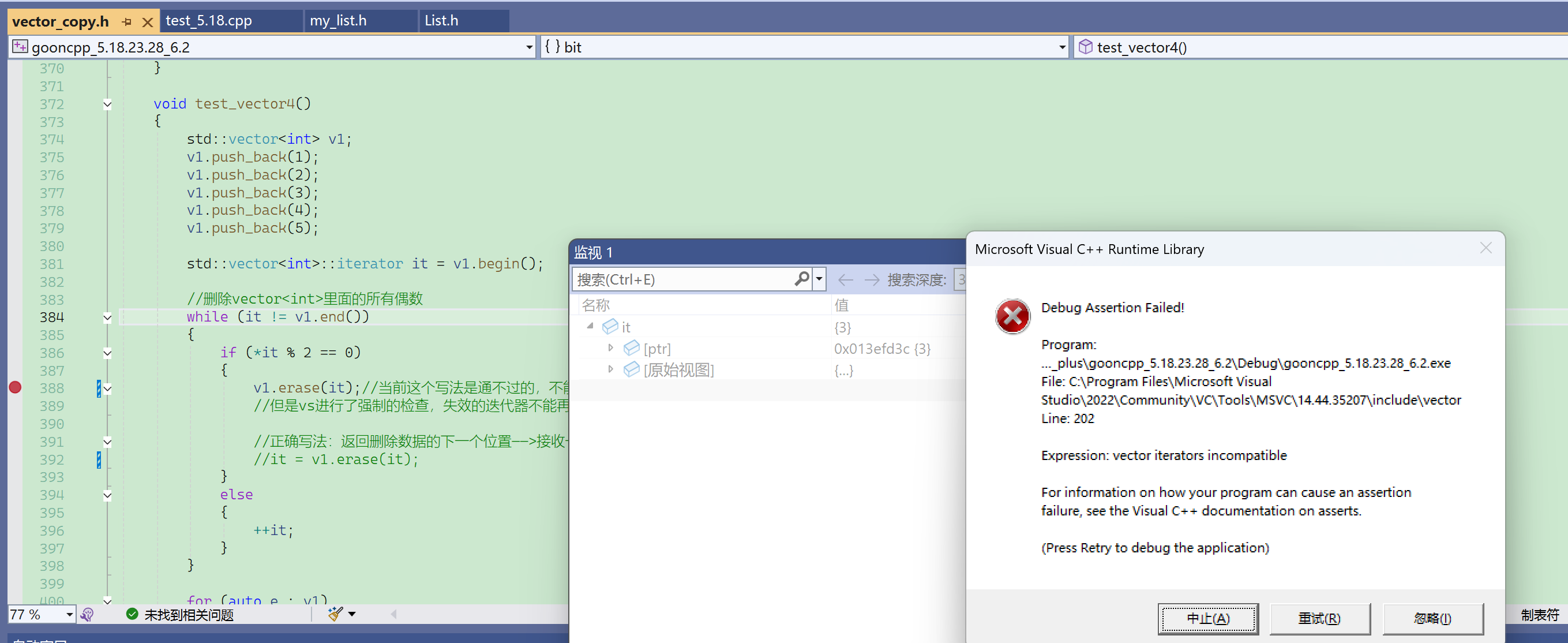
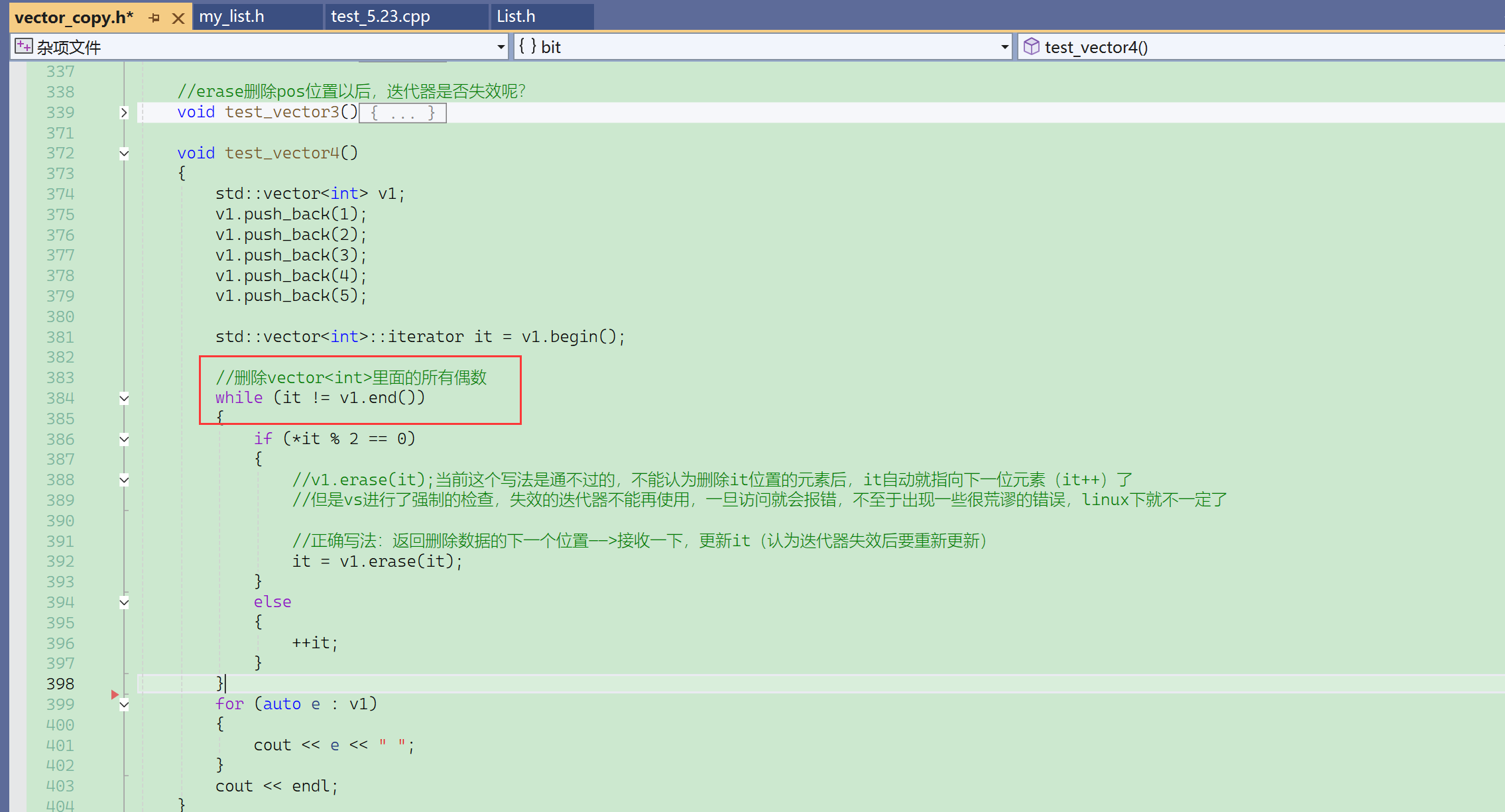
从398行跳到384行后,再按f10就出错了,因为it !=end()会调用迭代器的函数,而迭代器接收到失效的迭代器后,就会报错。
显然vector的迭代器设计这里,VS下的封装效果更好,避免了访问失效的迭代器的错误。这个代码在linux下能正常通过,但实际上有隐藏的bug没有检测出来。
这段代码的问题1在于不是每个平台下都能跑,问题2在于万一erase缩容(异地数据迁移),就一定会出错。
像VS下的这种严格的检验,也只有对原生指针进行自定义类型封装才能做到。
2.2 list的反向迭代器迭代
通过前面例子知道,反向迭代器的++就是正向迭代器的--,反向器的--就是正向迭代器的++,因此反向迭代器的实现可以借助正向迭代器,即:反向迭代器内部可以包含一个正向迭代器,对正向迭代器的接口进行包装即可。
template<class Iterator>
class ReverseListIterator
{// 注意:此处typename的作用是明确告诉编译器,Ref是Iterator类中的类型,而不是静态成员变量// 否则编译器编译时就不知道Ref是Iterator中的类型还是静态成员变量// 因为静态成员变量也是按照 类名::静态成员变量名 的方式访问的
public:typedef typename Iterator::Ref Ref;typedef typename Iterator::Ptr Ptr;typedef ReverseListIterator<Iterator> Self;
public://////////////////////////////////////////////// 构造ReverseListIterator(Iterator it): _it(it){}//////////////////////////////////////////////// 具有指针类似行为Ref operator*(){Iterator temp(_it);--temp;return *temp;}Ptr operator->(){ return &(operator*());}//////////////////////////////////////////////// 迭代器支持移动Self& operator++(){
--_it;return *this;}Self operator++(int){Self temp(*this);--_it;return temp;}Self& operator--(){++_it;return *this;}Self operator--(int){Self temp(*this);++_it;return temp;}//////////////////////////////////////////////// 迭代器支持比较bool operator!=(const Self& l)const{ return _it != l._it;}bool operator==(const Self& l)const{ return _it != l._it;}Iterator _it;
};3. list与vector的对比
vector与list都是STL中非常重要的序列式容器,由于两个容器的底层结构不同,导致其特性以及应用场景不同,其主要不同如下:
| 项目 | vector | list |
| 底 层 结 构 | 动态顺序表,一段连续空间 | 带头结点的双向循环链表 |
| 随 机 访 问 | 支持随机访问,访问某个元素效率O(1) | 不支持随机访问,访问某个元素 效率O(N) |
| 插 入 和 删 除 | 任意位置插入和删除效率低,需要搬移元素,时间复杂度为O(N),插入时有可能需要增容,增容:开辟新空间,拷贝元素,释放旧空间,导致效率更低 | 任意位置插入和删除效率高,不 需要搬移元素,时间复杂度为 O(1) |
| 空 间 利 用 率 | 底层为连续空间,不容易造成内存碎片,空间利用率高,缓存利用率高 | 底层节点动态开辟,小节点容易 造成内存碎片,空间利用率低, 缓存利用率低 |
| 迭 代 器 | 原生态指针 | 对原生态指针(节点指针)进行封装 |
| 迭 代 器 失 效 | 在插入元素时,要给所有的迭代器重新赋值,因为插入 元素有可能会导致重新扩容,致使原来迭代器失效,删 除时,当前迭代器需要重新赋值否则会失效 | 插入元素不会导致迭代器失效, 删除元素时,只会导致当前迭代 器失效,其他迭代器不受影响 |
| 使 用 场 景 | 需要高效存储,支持随机访问,不关心插入删除效率 | 大量插入和删除操作,不关心随 机访问 |