【Redis】哨兵与对脑裂的情况分析
1. 哨兵
Redis 提供的哨兵用于在主从复制中,自动地实现故障转移,此时无需开发者手动进行主从切换。展开来说,Sentinel 负责监控所有 Redis 节点的工作状态,如果它发现 Master 出现故障(通常由多个 Sentinel 节点协同判断)则自动化地将一个 Slave 提升为 Master,并让其他 Slave 连接该新 Master。故障转移后,Sentinal 还会将新的主从拓扑结构告知客户端。整个过程不需要人工介入。
1.1 使用 Docker 配置主从及哨兵节点

为主从节点配置 docker-compose.yml 文件,放于 redis-data-container 目录,配置如下:
version: '3.7'
services:master:image: 'redis:5.0.9'container_name: redis-masterrestart: alwayscommand: redis-server --appendonly yesports: - 6379:6379slave1:image: 'redis:5.0.9'container_name: redis-slave1restart: alwayscommand: redis-server --appendonly yes --slaveof redis-master 6379 ports: - 6380:6379slave2:image: 'redis:5.0.9'container_name: redis-slave2restart: alwayscommand: redis-server --appendonly yes --slaveof redis-master 6379ports: - 6381:6379为哨兵节点配置 docker-compose.yml 文件,并分别为每个哨兵配置 conf 文件,都放于 redis-sentinel-container 目录,配置如下:
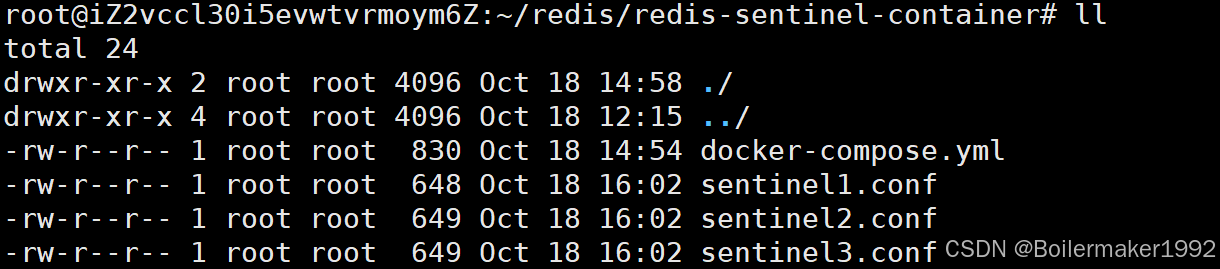
version: '3.7'
services:sentinel1:image: 'redis:5.0.9'container_name: redis-sentinel-1restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel1.conf:/etc/redis/sentinel.confports:- 26379:26379sentinel2:image: 'redis:5.0.9'container_name: redis-sentinel-2restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel2.conf:/etc/redis/sentinel.confports:- 26380:26379sentinel3:image: 'redis:5.0.9'container_name: redis-sentinel-3restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel3.conf:/etc/redis/sentinel.confports:- 26381:26379# 使哨兵节点与主从节点连接到同一个局域网
networks:default:external:name: redis-data-container_default
# 三个哨兵节点的初始配置文件相同
bind 0.0.0.0
port 26379
# sentinel monitor 主节点名(供哨兵内部使用) 主节点 IP(Docker 下写容器名即可) 端口 法定票数
sentinel monitor redis-master redis-master 6379 2
# 心跳包在这段时间内未收到响应则判断节点故障
sentinel down-after-milliseconds redis-master 1000
配置完成后输入 docker ps -a 命令查看容器是否均正常运行:

1.2 哨兵对主从切换的控制
配置完成后,我们输入 docker stop redis-master 指令模拟主节点宕机,再输入 docker-compose logs 指令查看运行日志,看看会发生什么。下面截取的是其中一个 sentinel 在主节点宕机后打印的日志:
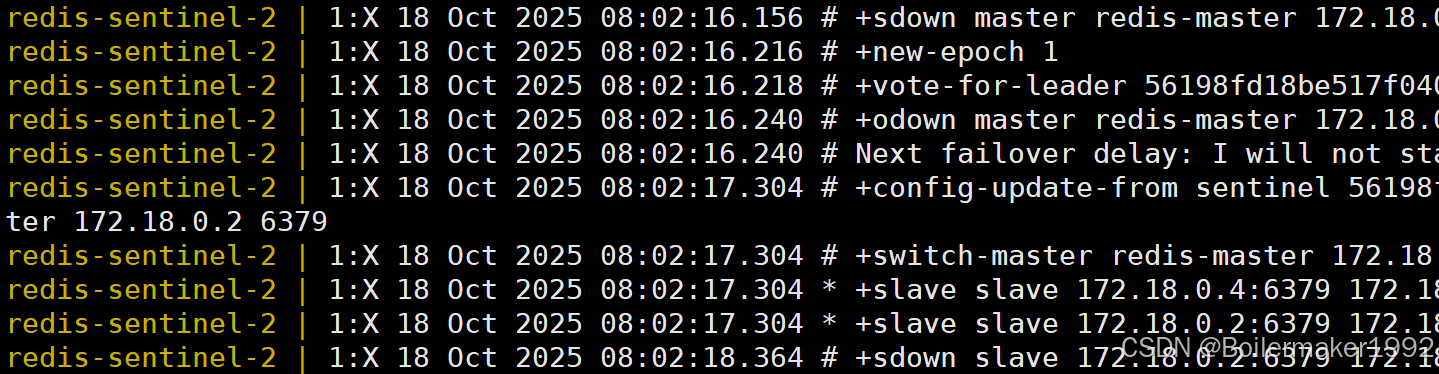
对该日志的逐行解释:

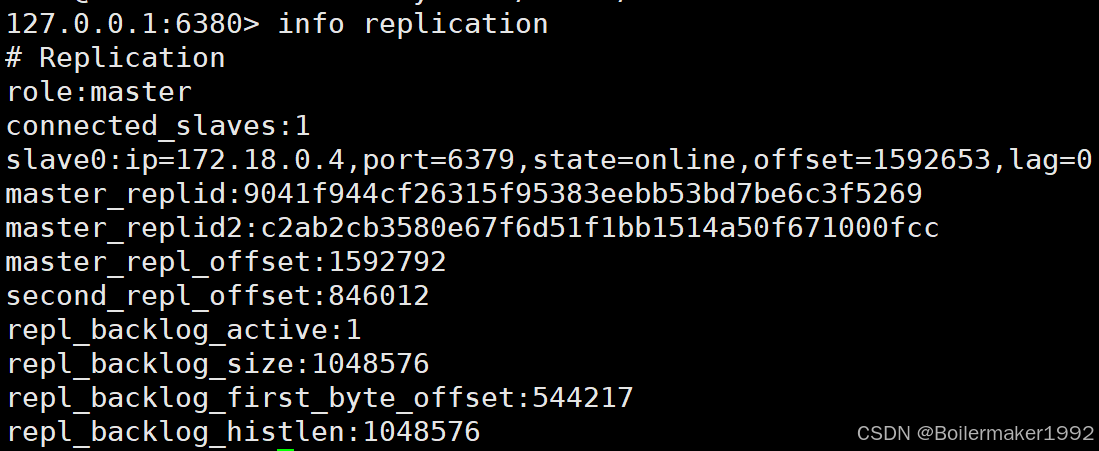
此时,原来的其中一个 Slave 已经变为 Master:
总结一下,哨兵集群是如何控制主从切换的:
1. 对于任何一个 Sentinal,如果它主观认为 Master 下线,并且它得知,半数以上的 Sentinal 也主观认为 Master 下线,则会认定 Master 客观下线。它会立即将纪元加一,要求进行 Leader 选举,并投自己一票。
2. 收到投票请求的 Sentinal,如果它在这个纪元还没有投过票,那么它就会把这一票投给这个发起者。
一般来说,最先认定 Master 客观下线的 Sentinal 大概率能赢得选举,因为它在时间上占据了优势。在它发起 Leader 选举的时候,有些 Sentinal 甚至还未判断出 Master 客观下线,此时这些 Sentinal 相当于收到了比自己纪元大的 Sentinal 的拉票,那么它们也会将票投给它。
一个 Sentinal 要成为 Leader,必须获得至少半数以上的票数,这个机制确保了在同一个纪元内,最多只有一个 Sentinal 能获得多数票。
最极端情况下,三个 Sentinal 都同时把票投给了自己,然后发起拉票请求。此时由于票已经都被投完了(每个纪元中每个 Sentinal 仅能投一次票),不会有 Sentinal 收集到足够的选票,那么选举会失败。Sentinal 会等待一段随机的超时时间后再次发起选举。这个随机性非常重要,它大大降低了再次发生平局的概率。
上面的选举过程是 Raft 算法的应用。
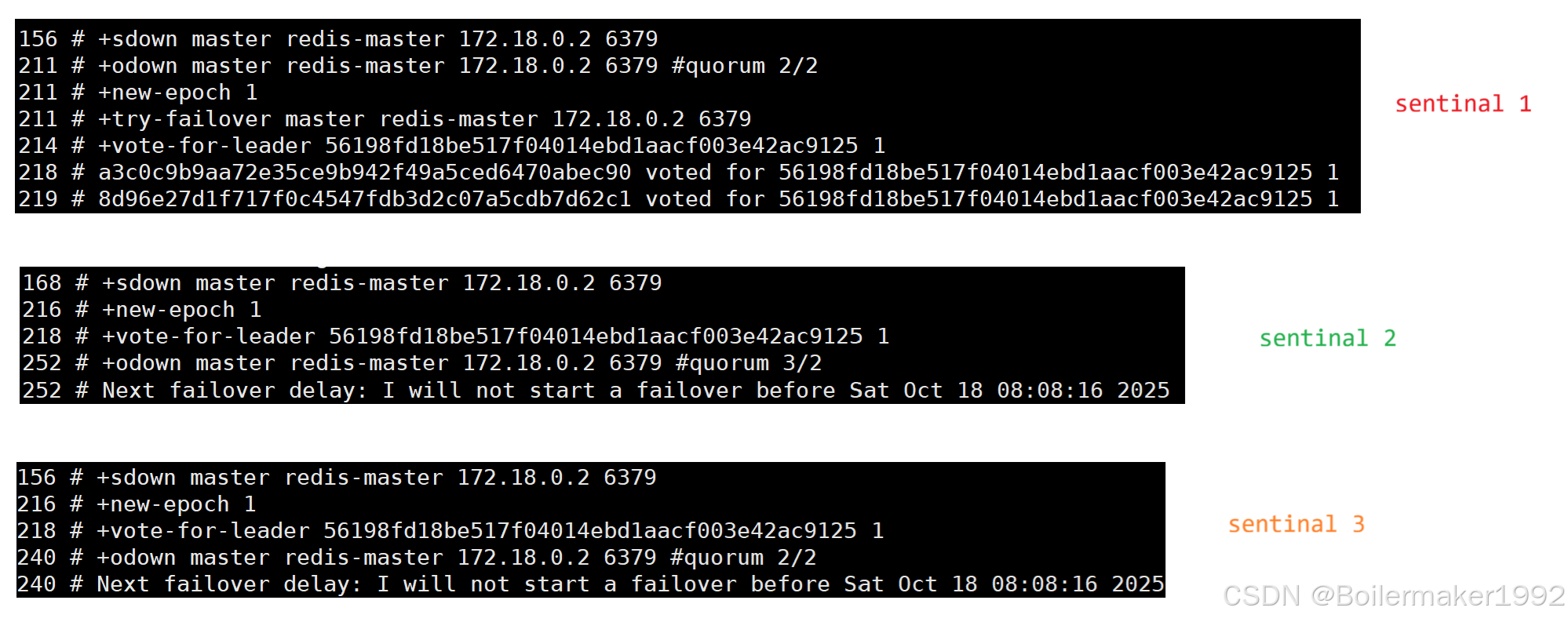
3. 选举出 Leader 后,它就要开始执行故障转移的核心任务:从存活的 Slave 节点中,挑选一个最合适的晋升为新的 Master。它根据下面几个维度来找出最合适的人选:
首先,Leader 检查开发者手动在 redis.conf 中配置的 slave-priority 参数。Leader 会优先选择这个参数值最小的 Slave,默认值均为 100。如果这个值被设置为 0,那么这个 Slave 将永远不会被选为 Master,这用于强制排除某些配置较低的节点。
其次,Leader 检查这些 Slave 的 offset,offset 越大,表示这个 Slave 从旧 Master 那里复制的数据越多,它的数据就越新,越会被选到。
如果 offset 也一样,为了打破平局,Leader 会比较它们的 Run ID,选出字典序最小的那个。
4. 确定人选之后,Leader 向其发送 SLAVEOF no one 命令,将其晋升为新的 Master。随后,通知其他所有 Slave 去 SLAVEOF 这个新 Master,将旧 Master 标记为 Slave。
1.3 奇数个哨兵的好处
这里的奇数至少要大于 1,一个哨兵是没法保证高可用的。
奇数个节点能以最少的节点数量,达到最优的容错能力。
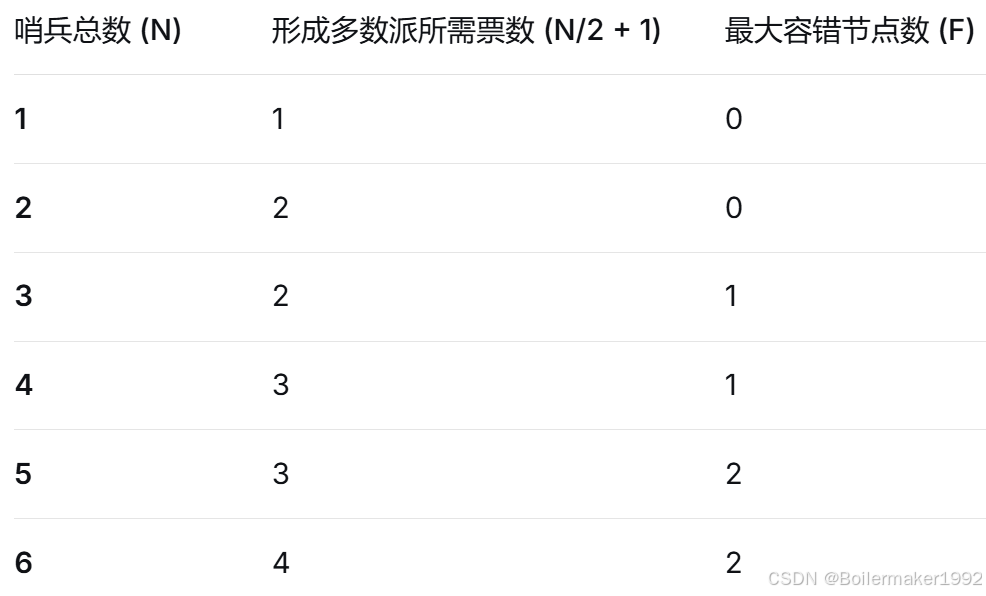
也就是说,奇数个哨兵在提升系统可用性方面的性价比高,但是至于其他好处,我在这里存疑。
1.4 关于脑裂
哨兵可能会引起脑裂:
如下图所示,假设,两个机房出现网络分区,彼此无法正常通信,则机房 2 的哨兵会判断 Master 宕机,并且它们的个数已经达到多数,将选举出一个新的 Master。此时,由于原 Master 其实并没有宕机,与其处于同一网络分区中的客户端仍可以向其执行读写命令,相当于同时有两个 Master 主导写操作。
这段时间内,两个 Master 中的数据存储不一致,更严重的是,如果 Redis 作为缓存,那么落库的数据也会出现问题。
当网络恢复时,机房 1 中的 Master 会收到 SLAVEOF 新 Master 的命令,变为 Slave,此时它在网络分区这段时间中收到的所有写数据都会被丢弃。此时虽然缓存数据一致了,但是数据库中的数据依然有问题。即使数据库中的数据没有因两个 Master 的同时更新而被破坏,缓存状态与数据库状态也出现了严重不一致。
网络分区:分布式系统中的节点被分割成两个或多个无法相互通信的子集。

脑裂是由于网络分区导致的 “假宕机”,因为在机房 2 哨兵的视角来看,它不知道机房 1 中的 Master 是真宕机了还是网络分区。
有的人会说,如果改变一下部署方式,如下图,就不会发生脑裂了。因为机房 2 的哨兵无论如何也构成不了多数,不可能选出新 Master。若情况是机房 1 和机房 2 之间无法通信,那么确实不会发生脑裂,但是这依然有两点问题。

1. 牺牲了跨机房的可用性。如果 Master 机房真的整体出现问题,哨兵集群也一起宕机,完全无法故障转移。这失去了分布式部署的初心。
2. 假设的前提是网络分区不会影响 Master 机房内部通信,但是真实情况里并不是说一个机房里就绝对不会出现网络分区。我们要假设充分随机的网络分区,也就是网络分区可能存在于任何节点之间。
所以,不管奇数个还是偶数个哨兵,不管怎么部署哨兵,都无法避免脑裂。靠谱的做法还是要另外使用一些网络探测的手段来判断节点的具体情况。
尽管如此,Redis 也提供给我们了一些降级策略。你不是怕脑裂时的同时写入导致数据不一致吗,那在有脑裂风险的时候我就不让你写了。当然,具体使不使用这些策略,还是要看业务对数据安全性的要求(这些策略当然会降低可用性)。
在 Master 的配置文件中做如下配置:
min-slaves-to-write:至少有几个从节点与主节点保持连接,主节点才能接受写操作。如果从节点数量少于这个配置值,那么主节点会拒绝写操作。
例如,如果你设置 min-slaves-to-write 1,那么当主节点连接不到任何从节点时,主节点将停止接受写操作。这样做的目的是,确保写操作至少被复制到一个从节点,从而在主节点故障时,数据不会丢失。
min-slaves-max-lag:从节点与主节点的复制延迟(lag)不能超过配置的时间。复制延迟是指从节点最后一次与主节点进行复制操作的时间间隔。如果所有从节点的复制延迟都超过了这个配置值,那么主节点也会拒绝写操作。
这两个配置一起使用,可以确保写操作只有在被一定数量的从节点,在一定的时间内确认的情况下才会进行。