用frontpage做网站保定seo管理

论文地址:https://www.arxiv.org/pdf/2507.18071
背景
自Deepseek-R1爆火之后,强化学习已成为拓展语言模型、增强其深度推理与问题求解能力的关键技术范式。为了持续拓展 RL,首要前提是确保稳定、鲁棒的训练过程。然而,现有的 RL 算法(如 GRPO)在长期训练中会暴露出严重的不稳定性问题并招致不可逆转的模型崩溃,阻碍了通过增加计算以获得进一步的性能提升。
核心思想
本篇论文介绍了一种名为“Group Sequence Policy Optimization(GSPO)”的强化学习算法,用于训练大型语言模型。相较于之前采用基于token重要性比例的方法,GSPO定义了基于序列似然的重要性比例,并进行了序列级别的剪裁、奖励和优化。实验结果表明,GSPO在稳定性和效率上优于GRPO算法,并且能够显著提高Mixture-of-Experts(MoE)RL训练的稳定性。此外,GSPO还有望简化强化学习基础设施的设计。这些优点使得GSPO成为最新的Qwen3模型的重要改进之一。
相较于 GRPO,GSPO 在以下方面展现出突出优势:
- 强大高效:GSPO 具备显著更高的训练效率,并且能够通过增加计算获得持续的性能提升;
- 稳定性出色:GSPO 能够保持稳定的训练过程,并且根本地解决了混合专家(Mixture-of-Experts,MoE)模型的 RL 训练稳定性问题;
- 基础设施友好:由于在序列层面执行优化,GSPO 原则上对精度容忍度更高,具有简化 RL 基础设施的诱人前景。以上优点促成了最新的 Qwen3 模型(Instruct、Coder、Thinking)的卓越性能。
GSPO算法解决了在语言生成任务中的过度偏离策略问题,提高了模型的性能。同时,GSPO-token版本也提供了更高的灵活性,允许针对每个令牌进行个性化的优势调整。
序列级别的优化目标

对 MoE RL 和基础设施的收益
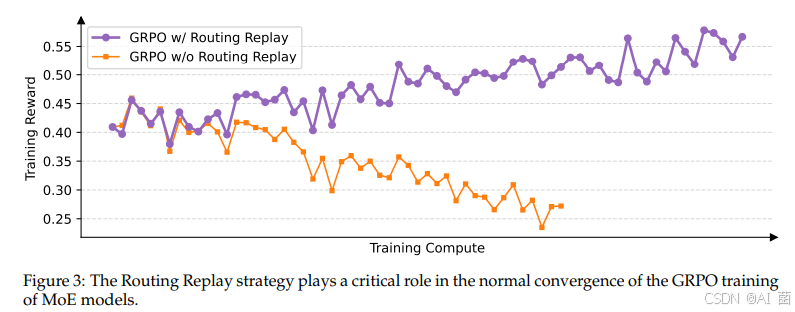
作者发现,当采用 GRPO 算法时,MoE 模型的专家激活波动性会使得 RL 训练无法正常收敛。为了解决这一挑战,过去采用了路由回放(Routing Replay) 训练策略,即缓存πθold\pi_{\theta_\text{old}}πθold中激活的专家,并在计算重要性比率时在 πθ\pi_\thetaπθ 中“回放”这些路由模式。下图可见,Routing Replay 对于 GRPO 训练 MoE 模型的正常收敛至关重要。然而,Routing Replay 的做法会产生额外的内存和通信开销,并可能限制 MoE 模型的实际可用容量。
GSPO 的一大突出优势在于彻底消除了对 Routing Replay 的依赖。其核心洞见在于:GSPO 仅关注序列级别的似然 πθ(yi∣x)\pi_\theta(y_i|x)πθ(yi∣x),而对个别 token 的似然 πθ(yi,t∣x,yi,<t)\pi_\theta(y_{i,t}|x,y_{i,<t})πθ(yi,t∣x,yi,<t) 不敏感。因此,其无需 Routing Replay 等对基础设施负担较大的手段,既简化和稳定了训练过程,又使得模型能够最大化地发挥容量与潜能
此外,鉴于 GSPO 仅使用序列级别而非 token 级别的似然进行优化,直观上前者对精度差异的容忍度要高得多。因此,GSPO 使得直接使用推理引擎返回的似然进行优化成为可能,从而无需使用训练引擎重新计算,这在 partial rollout、多轮 RL 以及训推分离框架等场景中特别有益。
训练效率与性能
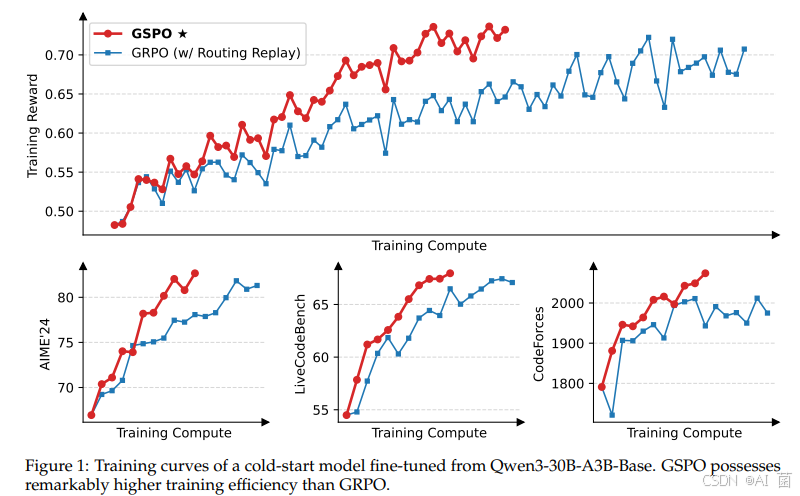
使用基于 Qwen3-30B-A3B-Base 微调得到的冷启动模型进行实验,并绘制其训练奖励曲线以及在 AIME’24、LiveCodeBench 和 CodeForces 等基准上的性能曲线。我们对比 GRPO 作为基线,GRPO 必需采用 Routing Replay 训练策略才能正常收敛而 GSPO 则无需该策略。
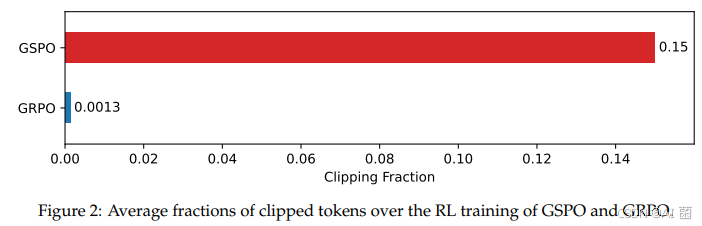
一个有趣的观察是,GSPO 所裁剪的 token 比例比 GRPO 要高上两个数量级(如下图所示),但却具有更高的训练效率。这进一步表明 GRPO 采用的 token 级别的优化目标是有噪和低效的,而 GSPO 的序列级别的优化目标则提供了更可靠、有效的学习信号。
结论
本文提出了一种新的序列策略优化算法——Group Sequence Policy Optimization(GSPO),用于在语言生成任务中实现更好的性能。与之前的算法相比,GSPO通过将响应级别的重要性权重应用于整个响应而不是单个令牌来排除过于“偏离策略”的样本,从而可以更好地匹配序列级奖励和优化目标。