Kafka零拷贝原理深度解析:从传统拷贝痛点到工作实践优化
在分布式系统中,Kafka作为高吞吐、低延迟的消息中间件,被广泛用于日志采集、实时数据同步、流式计算等核心场景。其高性能的背后,除了分区并行、日志分段等设计,零拷贝(Zero-Copy)技术是支撑大流量数据传输的关键——它直接解决了传统数据拷贝中“CPU空转”“内存带宽浪费”的痛点。本文将从操作系统底层逻辑切入,详细拆解传统拷贝的“四步流程”及存在的问题,再深入讲解Kafka零拷贝的实现原理、系统调用支撑。
一、前置知识:为什么要有“用户态”和“内核态”?
要理解传统拷贝的“四步流程”,首先需要明确操作系统的用户态与内核态隔离机制——这是所有数据传输流程设计的底层逻辑,也是传统拷贝必须多步的核心原因。
- 内核态(Kernel Mode):操作系统内核运行的特权模式,拥有直接操作硬件(磁盘、网卡、内存)的权限,负责IO管理、内存分配、进程调度等核心工作。
- 用户态(User Mode):应用程序(如Kafka、Java服务)运行的非特权模式,不能直接操作硬件,必须通过系统调用(System Call) 向内核“借权”才能完成IO操作。
这种隔离的目的是安全性与稳定性:
- 防止应用程序误操作硬件(如直接写磁盘导致数据损坏);
- 避免单个应用程序占用过多硬件资源(如CPU、内存),影响整个系统稳定性。
正是这种隔离,导致数据在“应用程序”与“硬件”之间传输时,必须经过“内核态”中转——这也是传统拷贝多步流程的根源。
二、传统数据传输的“四步拷贝”:为什么必须这么做?
假设我们有一个场景:Kafka Broker需要读取磁盘上的消息文件,通过网络发送给消费者(如Flink、Spark Streaming)。在没有零拷贝的情况下,数据需要经过4次关键流转,其中包含2次CPU主导的拷贝和2次DMA主导的传输(注:DMA是“直接内存访问”,可绕过CPU直接在硬件与内存间传输数据)。
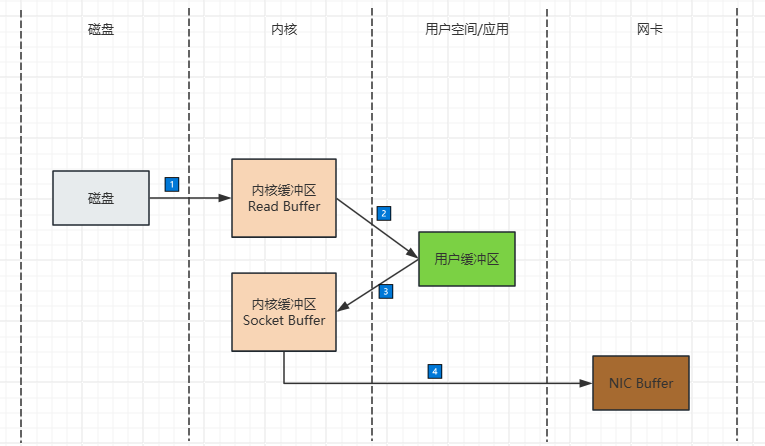
接下来,我们逐步解析每一次拷贝的目的、执行者(CPU/DMA)和必要性:
1. 第一次:磁盘 → 内核缓冲区(DMA传输)
- 执行者:DMA(直接内存访问控制器),无需CPU参与。
- 目的:将磁盘上的Kafka日志数据(二进制文件)读取到内核态的“页缓存(Page Cache)”中。
- 为什么必须?:
- CPU不能直接操作磁盘(硬件操作需内核权限),必须通过DMA完成“磁盘→内存”的传输;
- 页缓存是内核的“IO缓存”,后续若有其他进程读取同一批数据(如多个消费者消费同一条消息),可直接从页缓存获取,避免重复读磁盘(磁盘IO是毫秒级,内存IO是纳秒级,差距10万倍)。
2. 第二次:内核缓冲区 → 用户缓冲区(CPU拷贝)
- 执行者:CPU(完全占用CPU资源)。
- 目的:将内核页缓存中的数据拷贝到用户态的“Kafka应用缓冲区”(如Java的Byte数组)。
- 为什么必须?:
- 用户态应用(Kafka)不能直接访问内核态内存(隔离机制),必须通过系统调用(如
read())让CPU将数据“搬运”到用户空间; - 此时Kafka可以对数据进行业务处理(如解析消息头、过滤无效消息、添加元数据等)。
- 用户态应用(Kafka)不能直接访问内核态内存(隔离机制),必须通过系统调用(如
3. 第三次:用户缓冲区 → Socket缓冲区(CPU拷贝)
- 执行者:CPU(再次占用CPU资源)。
- 目的:将用户态处理后的消息数据,拷贝回内核态的“Socket缓冲区”。
- 为什么必须?:
- 应用程序不能直接操作网卡(硬件操作需内核权限),必须通过Socket接口(系统调用如
write())将数据交给内核; - Socket缓冲区是内核为网络传输设计的“临时缓存”,负责将数据按TCP协议分片、添加头部(IP、TCP头),再等待网卡发送。
- 应用程序不能直接操作网卡(硬件操作需内核权限),必须通过Socket接口(系统调用如
4. 第四次:Socket缓冲区 → 网卡(DMA传输)
- 执行者:DMA,无需CPU参与。
- 目的:将Socket缓冲区中的分片数据传输到网卡的“发送队列”,最终通过网络发送给消费者。
- 为什么不算“传统拷贝”?:
- 这一步是“数据传输”而非“数据复制”——DMA直接将内存中的数据(Socket缓冲区)搬运到网卡硬件,没有在内存中生成新的副本;
- 但它是整个流程的必要环节,因此常被纳入“四步流程”讨论。
三、传统拷贝的工作痛点:高CPU+高内存带宽消耗
传统拷贝的“两次CPU拷贝”(第二步和第三步)会带来严重的性能问题,尤其是在Kafka处理TB级日志、百万级QPS的场景下:
- CPU资源浪费:CPU的核心职责是“业务计算”(如Kafka的分区分配、消费者组协调),但传统拷贝中,CPU需要花费大量时间做“数据搬运”(内核→用户、用户→内核),导致业务处理线程被阻塞,QPS上不去。
- 内存带宽占用:数据在“内核缓冲区→用户缓冲区→Socket缓冲区”之间来回拷贝时,会占用大量内存带宽(数据在内存中重复存储),导致内存命中率下降,甚至引发频繁GC(如Java应用中用户缓冲区的Byte数组频繁创建/回收)。
- 延迟增加:多一次拷贝就多一次数据流转,在高吞吐场景下,累计延迟会显著增加(如传统拷贝单次消息传输延迟可能是零拷贝的2-3倍)。
举个工作中的实际案例:某电商平台用Kafka采集用户行为日志,峰值时每秒产生50万条消息(单条消息1KB)。采用传统拷贝时,CPU使用率长期维持在80%以上,频繁触发限流;启用零拷贝后,CPU使用率直接降至30%以下,QPS提升至80万条/秒——这就是零拷贝的实际价值。
四、Kafka零拷贝:如何消除两次CPU拷贝?
Kafka的零拷贝并非“完全不拷贝”,而是消除了用户态与内核态之间的两次CPU拷贝(传统流程的第二步和第三步),让数据全程在内核态流转。其实现依赖于Linux操作系统的两个核心系统调用:sendfile() 和 mmap(),分别对应“顺序读”和“随机读”场景。
1. 核心原理:数据全程在内核态流转
零拷贝的核心思路是:让应用程序不参与数据拷贝,仅负责“发起请求”,数据的流转全程由内核完成。我们通过文字示意图对比传统流程与零拷贝流程的差异:
| 流程类型 | 数据流向(内核态+用户态) | 拷贝次数(CPU/DMA) |
|---|---|---|
| 传统拷贝 | 磁盘→内核缓冲区(DMA)→用户缓冲区(CPU)→Socket缓冲区(CPU)→网卡(DMA) | 2次CPU拷贝,2次DMA传输 |
| Kafka零拷贝(sendfile) | 磁盘→内核缓冲区(DMA)→Socket缓冲区(内核直接拷贝)→网卡(DMA) | 0次CPU拷贝,2次DMA传输 |
可以看到,零拷贝流程中,数据从“内核缓冲区”直接进入“Socket缓冲区”,完全跳过了用户态——这就消除了两次CPU拷贝。
2. 实现方案1:sendfile()——顺序读场景的最优解
Kafka在读取磁盘日志文件(顺序读,因为Kafka日志是append-only的,消息按顺序写入/读取)时,主要使用sendfile()系统调用。其工作流程如下:
- Kafka通过
sendfile(int out_fd, int in_fd, off_t *offset, size_t count)发起系统调用,参数含义:in_fd:磁盘文件的文件描述符(对应内核缓冲区);out_fd:Socket的文件描述符(对应Socket缓冲区);count:要传输的数据大小。
- 内核收到请求后,直接将“页缓存(内核缓冲区)”中的数据拷贝到“Socket缓冲区”(这一步是内核内部的拷贝,无需CPU参与,由DMA或内存控制器完成);
- DMA将Socket缓冲区中的数据传输到网卡,完成发送。
关键优化:Linux 2.4版本后,sendfile()支持“分散-聚集(Scatter-Gather)”DMA技术,可直接将“页缓存”的数据传输到网卡,连“内核缓冲区→Socket缓冲区”的拷贝都消除了——此时数据流向简化为:磁盘→页缓存(DMA)→网卡(DMA),全程零CPU拷贝。
3. 实现方案2:mmap()——随机读场景的补充
当Kafka需要随机读取日志文件(如消费者回溯消费旧消息,需要跳转到指定offset)时,会使用mmap()(内存映射)系统调用。其原理是:
- 通过
mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset)将磁盘文件的某一段映射到内核的“虚拟内存”中; - 用户态的Kafka应用可以直接访问这段虚拟内存(本质是内核态的页缓存),无需拷贝数据到用户缓冲区;
- Kafka处理完数据后(如解析消息),通过
msync()将修改后的数据同步到Socket缓冲区,再由DMA传输到网卡。
对比sendfile():mmap()允许应用程序直接操作内核内存(虚拟映射),适合随机读场景,但会有少量用户态与内核态的交互(如msync());sendfile()完全由内核主导,适合顺序读场景,性能更优——Kafka会根据读写场景自动选择两种方案。
4. Kafka配置:如何开启零拷贝?
在Kafka中,零拷贝是默认开启的,无需额外配置,但可以通过以下参数优化其性能(server.properties):
socket.send.buffer.bytes:Socket缓冲区大小,默认102400字节(100KB),高吞吐场景可调整为262144字节(256KB);log.segment.bytes:日志分段大小,默认1GB, larger分段更适合sendfile()(减少文件切换次数,提高页缓存命中率);mmap.byte.buffer.size:mmap()的缓冲区大小,默认102400字节,随机读场景可适当增大。
五、零拷贝的工作场景注意事项
虽然零拷贝性能优异,但在实际工作中需要注意其适用场景,避免误用导致性能反降:
-
适合大消息,不适合极小消息:
- 零拷贝的优势在“单条消息较大”(如1KB以上)时更明显;若消息极小(如100字节以下),内核内部的“缓冲区切换”开销可能超过CPU拷贝的开销,此时可考虑“消息批量发送”(如Kafka的
batch.size参数,默认16384字节)。
- 零拷贝的优势在“单条消息较大”(如1KB以上)时更明显;若消息极小(如100字节以下),内核内部的“缓冲区切换”开销可能超过CPU拷贝的开销,此时可考虑“消息批量发送”(如Kafka的
-
避免频繁随机读:
mmap()虽然支持随机读,但频繁的offset跳转(如消费者频繁回溯消费)会导致页缓存命中率下降,建议通过“分区副本”或“日志预加载”优化。
-
文件系统选择:
- 零拷贝依赖内核的页缓存机制,建议使用
ext4或XFS文件系统(支持高效的页缓存管理),避免使用FAT32或NTFS(Windows系统,页缓存效率低)。
- 零拷贝依赖内核的页缓存机制,建议使用
-
监控指标:
- 工作中可通过
iostat -x 1监控磁盘IO(%util指标反映磁盘繁忙程度,零拷贝下应显著降低); - 通过
top监控CPU使用率(us用户态CPU占比应降低,sy内核态CPU占比可能略有上升,但总体CPU使用率下降)。
- 工作中可通过
六、总结
Kafka的零拷贝技术,本质是利用操作系统内核的能力,规避用户态与内核态之间的无效数据拷贝,将CPU资源从“数据搬运”解放到“业务计算”上。其核心价值在高吞吐、大流量的工作场景中尤为突出——它不仅能降低CPU和内存带宽消耗,还能减少延迟,让Kafka支撑起百万级QPS的消息传输。
Studying will never be ending.
▲如有纰漏,烦请指正~~