基于对数灰关联度的IOWGA算子最优组合预测模型
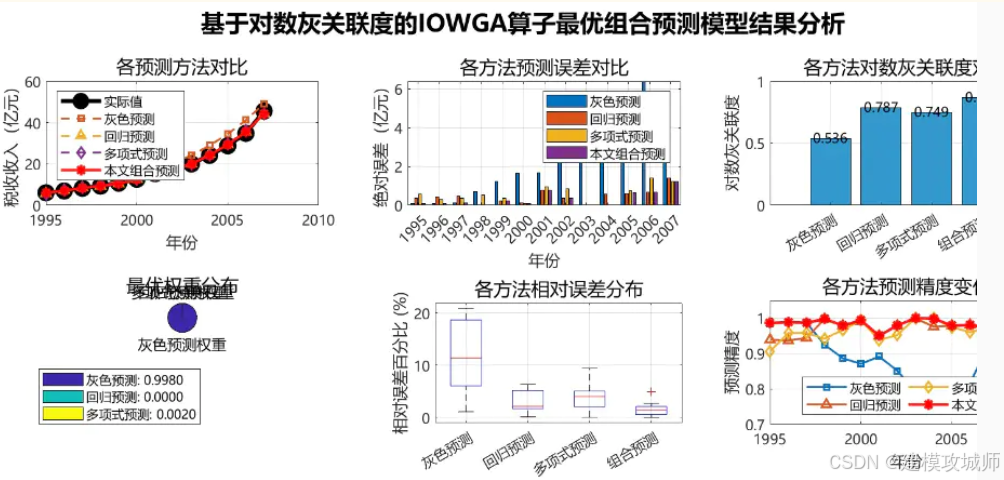
好的,这是一个非常专业和创新的预测模型。基于对数灰关联度的IOWGA算子最优组合预测模型将灰色系统理论、关联分析、信息论和组合优化技术相结合,旨在构建一个更加精确和稳健的预测系统。
下面我将为您详细解析这个模型的核心思想、构建步骤、数学原理以及优势特点。
1. 模型核心思想
该模型的名称可以拆解为几个关键部分来理解其思想:
-
最优组合预测:
- 目标:克服单一预测模型的局限性,综合利用不同模型提供的有用信息,从而提高预测的精度和稳健性。
- 方法:将多个单一的预测模型(如ARIMA、GM(1,1)、神经网络等)的预测结果进行加权组合。
-
IOWGA算子:
- 全称:Induced Ordered Weighted Geometric Averaging,即诱导有序加权几何平均算子。
- 作用:它是确定组合权重的一种高级方法。与简单加权算术平均不同,它:
- 诱导变量:首先根据一个“诱导变量”(如预测精度)对各个单项预测值进行排序。
- 有序加权:然后对排序后的预测值赋予权重,并进行几何平均。
- 优势:几何平均对异常值(特别差或特别好的预测)不如算术平均敏感,能更好地反映预测值的整体趋势。
-
对数灰关联度:
- 作用:它在这里扮演两个关键角色:
- 诱导变量:作为IOWGA算子的排序依据。
- 优化目标:作为组合权重优化模型的目标函数。
- 优势:传统的灰色关联度基于绝对差,而对数灰关联度引入了对数函数,能更好地处理数据比率的变化,对序列的相对变化更为敏感,从而更能刻画序列形态的相似性。
- 作用:它在这里扮演两个关键角色:
综上所述,该模型的核心思想是:
以“各个单项预测模型在不同时点的预测值与实际值的对数灰关联度”作为诱导变量,对预测值进行排序和加权几何平均,并通过优化算法寻找一套最优的权重系数,使得组合预测序列与实际序列的整体对数灰关联度达到最大。
2. 模型构建步骤与数学原理
假设我们有 m 种单项预测方法,对 n 个时间点的数据进行预测。
- 原始序列:( Y = (y(1), y(2), …, y(n)) )
- 第
i种方法的预测序列:( F_i = (f_i(1), f_i(2), …, f_i(n)) ), ( i = 1, 2, …, m ) - 组合预测序列:( \hat{Y} = (\hat{y}(1), \hat{y}(2), …, \hat{y}(n)) )
- 权重向量:( W = (w_1, w_2, …, w_m) ), 满足 ( \sum_{i=1}^{m} w_i = 1 ), ( w_i \geq 0 )
步骤一:计算诱导变量——点对数灰关联度
对于在 t 时刻,第 i 种预测方法的预测值 ( f_i(t) ) 与实际值 ( y(t) ) 的点对数灰关联度 ( \gamma_{0i}(t) ) 计算如下:
-
计算对数差序列:
( \Delta_i(t) = | \ln(y(t)) - \ln(f_i(t)) | = | \ln(\frac{y(t)}{f_i(t)}) | )- 这里取对数的好处是放大了比率接近1时的微小差异,对相对误差更敏感。
-
计算点关联系数:
( \gamma_{0i}(t) = \frac{\min\limits_i \min\limits_t \Delta_i(t) + \rho \max\limits_i \max\limits_t \Delta_i(t)}{\Delta_i(t) + \rho \max\limits_i \max\limits_t \Delta_i(t)} )- 其中 ( \rho ) 是分辨系数,通常取 0.5。
- ( \gamma_{0i}(t) ) 越大,说明在
t时刻,第i种方法的预测值与实际值越接近。
这个 ( \gamma_{0i}(t) ) 就是我们需要的诱导变量。它衡量了每个单项模型在每个时刻的瞬时预测性能。
步骤二:应用IOWGA算子进行组合预测
对于每一个时刻 t,我们进行如下操作:
-
诱导排序:根据
m个单项模型在该时刻的点对数灰关联度 ( \gamma_{0i}(t) ) 从大到小进行排序。关联度越高的预测值,我们认为它在这一时刻越可靠。- 假设排序后,第 ( \sigma_t(1) ) 个模型的关联度最高,第 ( \sigma_t(2) ) 次之,…,第 ( \sigma_t(m) ) 个最低。
- 对应的预测值序列为 ( f_{\sigma_t(1)}(t), f_{\sigma_t(2)}(t), …, f_{\sigma_t(m)}(t) )。
-
几何平均聚合:该时刻的组合预测值为:
( \hat{y}(t) = \prod_{j=1}^{m} (f_{\sigma_t(j)}(t))^{w_j} )- 这里 ( w_j ) 是与排序位置
j绑定的权重,而不是与特定模型绑定的。即,无论哪个模型,只要它在t时刻排在第一位,就用权重 ( w_1 );排在第二位就用 ( w_2 ),以此类推。
- 这里 ( w_j ) 是与排序位置
步骤三:建立以整体对数灰关联度最大为目标的优化模型
我们的目标是找到一组最优的权重 ( W = (w_1, w_2, …, w_m) ),使得组合预测序列 ( \hat{Y} ) 与原始序列 ( Y ) 的整体对数灰关联度 ( \Gamma(Y, \hat{Y}) ) 达到最大。
-
计算整体对数灰关联度:
- 首先计算 ( \hat{Y} ) 和 ( Y ) 的对数差序列:( \Delta_c(t) = | \ln(y(t)) - \ln(\hat{y}(t)) | )
- 然后计算整体关联系数:
( \Gamma(Y, \hat{Y}) = \frac{1}{n} \sum_{t=1}^{n} \frac{\min\limits_t \Delta_c(t) + \rho \max\limits_t \Delta_c(t)}{\Delta_c(t) + \rho \max\limits_t \Delta_c(t)} )
-
建立优化模型:
[
\begin{aligned}
& \max \quad \Gamma(Y, \hat{Y}) \
& \text{s.t.} \quad \begin{cases}
\sum_{j=1}^{m} w_j = 1 \
w_j \geq 0, \quad j = 1, 2, …, m
\end{cases}
\end{aligned}
]- 其中 ( \hat{y}(t) = \prod_{j=1}^{m} (f_{\sigma_t(j)}(t))^{w_j} )。
步骤四:求解优化模型
该优化模型是一个非线性规划问题,因为目标函数 ( \Gamma ) 中含有对数运算和权重 ( w_j ) 的乘积形式(在 ( \hat{y}(t) ) 中)。可以使用智能优化算法进行求解,例如:
- 遗传算法
- 粒子群优化算法
- 模拟退火算法
这些算法能够有效地在复杂的解空间中寻找到使整体关联度最大化的那组权重 ( W^* )。
3. 模型优势与特点
-
动态加权:与固定权重组合模型不同,IOWGA实现了动态加权。在每个时刻,模型都根据各单项模型的瞬时表现(点对数灰关联度)重新排序和赋权,更加灵活和自适应。
-
强调形态相似:对数灰关联度作为目标和诱导变量,使得模型不仅关注预测误差的绝对值,更关注预测值与实际值变化形态的相似性,这通常比单纯的误差最小化更有意义。
-
稳健性强:使用几何平均降低了极端预测值(异常值)对组合结果的负面影响,提高了模型的稳健性。
-
理论基础坚实:综合了灰色系统理论、有序信息聚合理论和最优化理论,模型结构科学严谨。
4. 概念性应用流程
- 准备数据:收集历史年径流数据 ( Y )。
- 单项预测:分别使用多种方法(如GM(1,1), ARIMA, BP神经网络等)进行预测,得到预测序列 ( F_1, F_2, …, F_m )。
- 计算点对数灰关联度:对于每个时刻
t,计算每个单项模型的 ( \gamma_{0i}(t) )。 - 初始化权重:随机生成一组满足约束的权重 ( W )。
- 迭代优化:
- 使用当前的 ( W ),根据IOWGA算子公式计算所有时刻的组合预测值 ( \hat{Y} )。
- 计算 ( \hat{Y} ) 与 ( Y ) 的整体对数灰关联度 ( \Gamma )。
- 使用优化算法(如PSO)更新权重 ( W ),以最大化 ( \Gamma )。
- 输出结果:当达到终止条件(如最大迭代次数)时,输出最优权重 ( W^* ) 和最大关联度 ( \Gamma^* )。
- 进行预测:对于未来时刻,先用各单项模型进行预测,然后利用最优权重 ( W^* ) 和IOWGA算子计算出最终的最优组合预测值。
这个模型通过其精巧的设计,能够有效地整合不同预测模型的优势,尤其适用于像年径流这样具有不确定性、非线性和小样本特性的复杂系统预测问题。