【AI论文】CoDA:通过扩散适配实现代码生成语言模型(Coding LM)
摘要:扩散式语言模型具备自回归编码器所缺乏的双向上下文建模与内容填充能力,但现有实用系统仍存在模型臃肿的问题。我们推出CoDA——一款在TPU上训练、参数规模为17亿且训练流程完全开源的扩散式代码生成模型。CoDA通过大规模扩散预训练、代码为中心的中期训练以及指令微调相结合的方式,实现了基于置信度引导的采样策略,使推理延迟保持竞争力。在Humaneval、MBPP和EvalPlus基准测试中,CoDA-1.7B-Instruct模型的性能达到或超越了参数规模达70亿的扩散式模型。此次发布包含模型检查点、评估工具包及TPU训练流程,旨在加速轻量化基于扩散的代码辅助工具的研究进展。Huggingface链接:Paper page,论文链接:2510.03270
研究背景和目的
研究背景:
随着大型语言模型(LLMs)的快速发展,其在自动代码生成领域的应用日益广泛。
传统的自回归(AR)语言模型,如StarCoder和Qwen3-Coder,通过逐个生成代码token的方式实现了高效的代码生成。然而,AR模型在处理长序列代码生成任务时存在局限性,例如错误传播、难以利用双向上下文信息,以及在填充缺失代码段或编辑大段文本时表现不佳。
扩散语言模型(DLMs)作为一种新兴的生成模型,通过迭代去噪过程生成序列,允许并行生成多个token,并具备双向上下文感知能力。
这种特性使得DLMs在代码生成任务中展现出巨大潜力,尤其是在处理代码补全和编辑任务时,DLMs能够利用左右两侧的上下文信息,提高生成代码的准确性和灵活性。然而,现有的DLMs通常需要庞大的模型规模(如7B至8B参数)和大量训练数据(如数百亿token),这限制了其在资源受限环境下的应用。
研究目的:
本研究旨在提出一种轻量级的扩散编码模型(CoDA),通过以下目标解决现有DLMs在代码生成中的局限性:
- 开发高效的小规模DLM:构建一个仅含17亿参数的扩散编码模型,展示紧凑DLM在保持双向解码优势的同时,能够实现交互式延迟。
- 实现竞争性性能:通过在大规模数据集上进行预训练、中间训练和指令微调,使CoDA在代码生成任务中达到或超越更大规模模型的性能。
- 开源训练管道:发布模型权重、评估框架和训练管道,降低社区研究扩散编码助手的门槛。
研究方法
1. 模型架构设计:
CoDA基于Qwen3-1.7B骨干网络,通过扩散目标进行适应,结合了约1800亿token的通用预训练和约200亿token的精选代码数据。
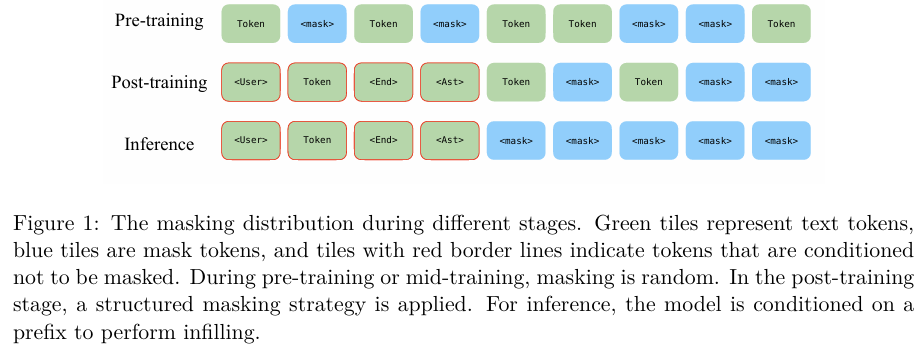
模型采用渐进式掩码策略,包括随机掩码、不可掩码前缀、截断后缀和块掩码,以增强模型对复杂掩码模式的处理能力。
2. 训练数据构建:
训练数据包括约1800亿token的通用预训练数据和约200亿token的精选代码数据。
预训练数据涵盖网页文本、源代码、数学和科学文本等多种来源,确保模型具备广泛的知识和强大的推理能力。
3. 训练策略:
- 预训练(Pre-training):在TPU v4-1024 VM上使用Torch XLA和FSDP进行大规模预训练,采用Adafactor优化器,设置线性学习率调度。
- 中间训练(Mid-training):通过引入高质量文本和代码数据集,增强模型处理复杂代码和文本的能力。
- 后训练(Post-training):在GPU集群上进行监督微调,使模型能够处理真实世界的编码任务。
4. 评估策略:
在多个编码基准测试集上评估CoDA的性能,包括Humaneval、MBPP和EvalPlus等。评估过程中采用pass@1作为主要指标,以全面评估模型在代码生成任务中的表现。
研究结果
1. 性能提升:
CoDA在多个代码生成基准测试集上表现出色,特别是在pass@1指标上,CoDA-1.7B-Instruct模型在Humaneval和MBPP测试集上的性能接近或超过了更大规模的扩散模型(如Dream-7B-Instruct),同时显著优于同规模的AR模型。
2. 效率提升:
通过分层缓存和子块缓存机制,CoDA在保持生成质量的同时,实现了高效的并行解码。
在NVIDIA A100 GPU上,CoDA-1.7B-Instruct的推理时间比Dream-7B-Instruct低39.64%,展示了其在轻量级硬件预算下的高效性。
3. 开放性和可复现性:
通过发布模型权重、评估框架和训练管道,CoDA降低了社区研究扩散编码助手的门槛,促进了相关领域的快速发展。
研究局限
1. 模型规模限制:
尽管CoDA在1.7B参数规模下表现出色,但与更大规模的模型相比,其在处理极复杂代码生成任务时可能仍存在局限性。
2. 数据集偏差:
尽管数据集构建流程力求全面和多样,但仍可能存在偏差,特别是对于某些特定类型的代码生成任务。
3. 推理步数影响:
推理步数的选择对模型性能有显著影响,如何在不同步数下保持稳定性能仍需进一步研究。
未来研究方向
1. 扩大模型规模:
研究更大规模的扩散编码模型,探索其在极复杂代码生成任务中的表现,进一步提升模型性能。
2. 优化数据集:
持续优化和扩展数据集,覆盖更多类型的代码生成任务,特别是那些涉及复杂逻辑和算法实现的任务。
3. 改进推理策略:
研究更高效的推理策略,减少推理步数对模型性能的影响,提高模型在实际应用中的响应速度。
4. 实际应用验证:
在实际开发环境中验证CoDA的有效性和实用性,收集开发者反馈以进一步优化模型设计和交互体验。
5. 跨模态融合:
探索将文本、图像和代码数据相结合的多模态推理任务,研究如何有效地整合不同模态的信息,设计相应的工具集成和奖励监督机制。
6. 持续学习和适应:
研究模型的持续学习和适应能力,使其能够随着新数据和新任务的出现不断优化和改进,保持长期的竞争力和实用性。