Google Landmarks Dataset v2 (GLDv2):面向实例级识别与检索的500万图像,200k+类别大规模地标识别基准
项目地址:https://github.com/cvdfoundation/google-landmark?tab=readme-ov-file
arxiv:https://arxiv.org/abs/2004.01804
下载与使用:Google Landmarks Dataset v2 (GLDv2):500万地标图像的识别与检索基准(数据集概览、下载与使用全流程)-CSDN博客
1. 摘要
Google Landmarks Dataset v2(GLDv2)是一个用于大规模实例级地标识别与图像检索的基准数据集,包含超 500 万张图像和200k + 个不同地标实例标签,规模远超以往同类数据集;
其核心特点是模拟真实应用挑战,包括极长尾类分布(57% 类别图像数≤10 张)、99% 的域外测试图像(仅 1% 为目标域地标图)及高类内变异(不同视角、光照、场景的地标图像);
数据主要源自 Wikimedia Commons(含 CC0 / 公有领域授权,确保数据集稳定),构建过程投入超 800 小时人工标注完善真值;
评估上采用µAP(识别任务) 和mAP@100(检索任务) 指标,基线实验显示其在迁移学习中表现优异(如在 Revisited Oxford/RParis 数据集上 mAP 较 GLDv1 提升达 10%),且曾用于 Kaggle 公开挑战赛,为该领域研究提供了贴近实际的评测基准。
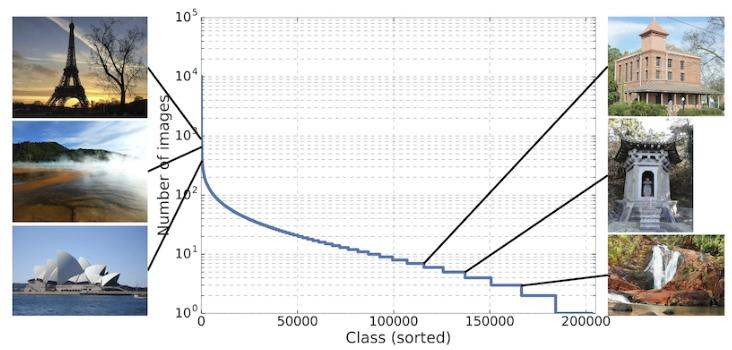
Figure 1: The Google Landmarks Dataset v2 contains a variety of natural and human-made landmarks from around the world. Since the class distribulocal landmarks.1 tion is very long-tailed, the dataset contains a large number of lesser-known
图 1:Google 地标数据集 v2(GLDv2)包含全球范围内多种类型的自然地标和人造地标。由于类别分布呈现极明显的长尾特征,该数据集还包含大量不太知名的本地地标 。
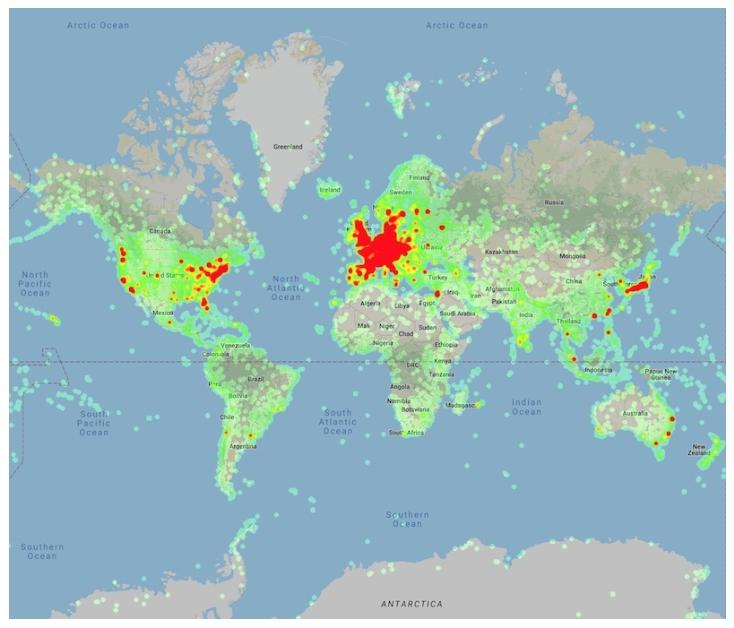
Figure 2: Heatmap of the places in the Google Landmarks Dataset v2.
2. 思维导图(mindmap)
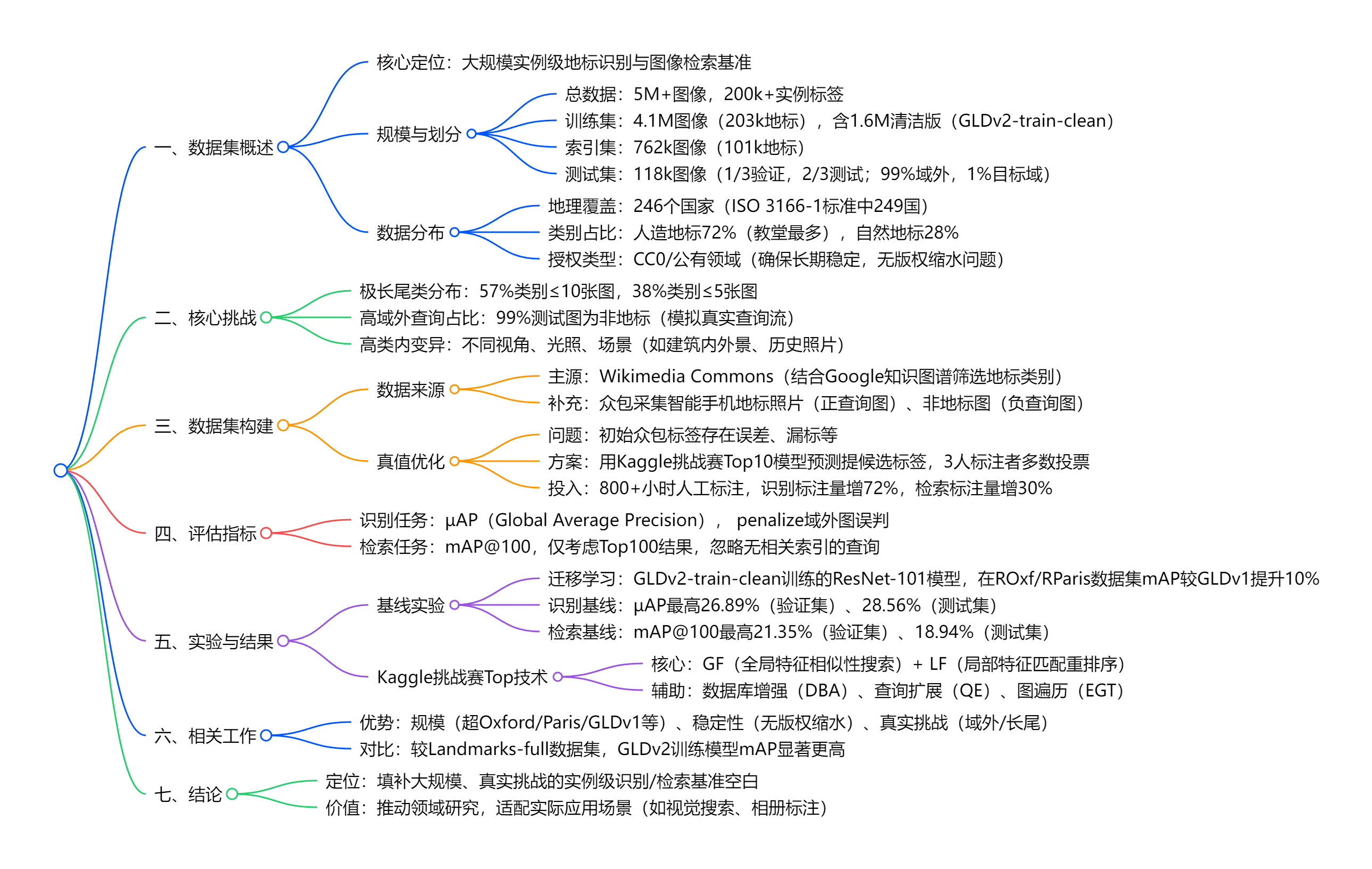
3. 详细总结
1. 引言:数据集提出背景
- 现有问题:传统图像检索 / 实例识别数据集存在规模小(如 Oxford5k 仅 55 个查询图)、场景单一(单城市图像)、缺乏真实挑战(无域外查询、类分布均衡)的问题,无法满足实际应用评测需求。
- 核心目标:构建一个覆盖全球地标、模拟真实应用挑战(如域外查询、长尾分布)的大规模基准数据集,推动实例级识别与检索技术发展。
| Dataset name | Year | # Landmarks | # Test images | # Train images | # Index images | Annotation collection | Coverage | Stable |
|---|---|---|---|---|---|---|---|---|
| Oxford [41] | 2007 | 11 | 55 | - | 5k | Manual | City | Y |
| Paris [42] | 2008 | 11 | 55 | - | 6k | Manual | City | Y |
| Holidays [28] | 2008 | 500 | 500 | - | 1.5k | Manual | Worldwide | Y |
| European Cities 50k [5] | 2010 | 20 | 100 | - | 50k | Manual | Continent | Y |
| Geotagged StreetView [32] | 2010 | - | 200 | - | 17k | StreetView | City | Y |
| Rome 16k [1] | 2010 | 69 | 1k | - | 15k | GeoTag + SfM | City | Y |
| San Francisco [14] | 2011 | - | 80 | - | 1.7M | StreetView | City | Y |
| Landmarks-PointCloud [35] | 2012 | 1k | 10k | - | 205k | Flickr label + SfM | Worldwide | Y |
| 24/7 Tokyo [56] | 2015 | 125 | 315 | - | 1k | Smartphone + Manual | City | Y |
| Paris500k [61] | 2015 | 13k | 3k | - | 501k | Manual | City | N |
| Landmark URLs [7, 22] | 2016 | 586 | - | 140k | - | Text query + Feature matching | Worldwide | N |
| Flickr-SfM [44] | 2016 | 713 | - | 120k | - | Text query + SfM | Worldwide | Y |
| Google Landmarks [39] | 2017 | 30k | 118k | 1.2M | 1.1M | GPS + semi-automatic | Worldwide | N |
| Revisited Oxford [43] | 2018 | 11 | 70 | - | 5k + 1M | Manual + semi-automatic | Worldwide | Y |
| Revisited Paris [43] | 2018 | 11 | 70 | - | 6k + 1M | Manual + semi-automatic | Worldwide | Y |
| Google Landmarks Dataset v2 | 2019 | 200k | 118k | 4.1M | 762k | Crowsourced + semi-automatic | Worldwide | Y |
Table 1: Comparison of our dataset against existing landmark recognition/retrieval datasets. “Stable” denotes if the dataset can be retained indefinitely. Our Google Landmarks Dataset v2 is larger than all existing datasets in terms of total number of images and landmarks, besides being stable.
2. 数据集概述:规模、分布与挑战
2.1 规模与数据划分
| 数据子集 | 图像数量 | 地标类别数 | 核心用途 |
|---|---|---|---|
| 训练集(GLDv2-train) | 4.1M | 203k | 实例识别模型训练 |
| 清洁训练集(GLDv2-train-clean) | 1.6M | 81k | 降低类内噪声,提升训练效率 |
| 索引集 | 762k | 101k | 图像检索任务的候选图像库 |
| 测试集 | 118k | - | 评测(1/3 验证,2/3 测试) |
- 关键说明:训练集与索引集类别重叠率高(92k 共同类别),测试集含99% 域外图像(非地标)和 1% 目标域图像(地标)。
2.2 数据分布特征
- 地理覆盖:涵盖 246 个国家(ISO 3166-1 标准中 249 国),但图像数量依赖 Wikimedia 社区活跃度(如美国、巴西图像数领先)。
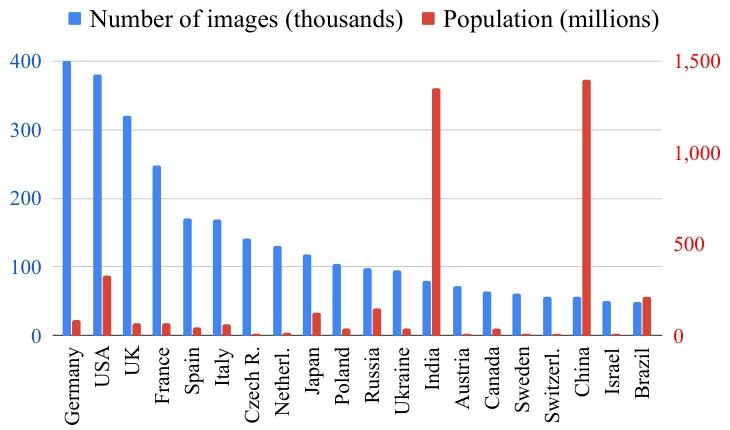
Figure 3: Histogram of the number of images from the top-20 countries (blue) compared to their populations (red).
图 3:前 20 个国家的图像数量直方图(蓝色),并与其人口数量(红色)进行对比。
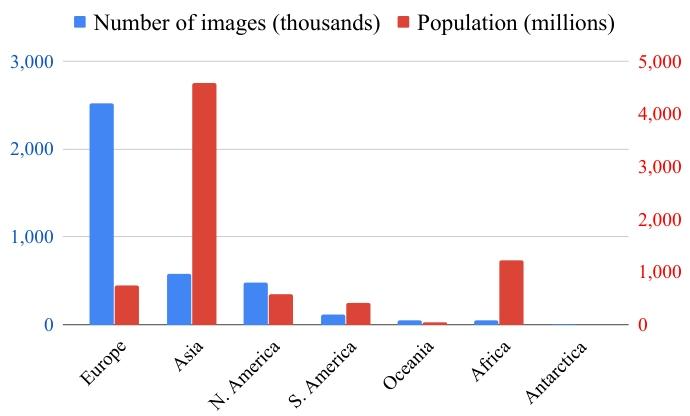
Figure 4: Histogram of the number of images per continent (blue) compared to their populations (red).
图 4:每个大洲的图像数量直方图(蓝色),并与其人口数量(红色)进行对比。
- 类别类型:按 Google 知识图谱分类,72% 为人造地标(教堂最多,其次是公园、博物馆),28% 为自然地标(仅统计图像数>25k 的类别)。
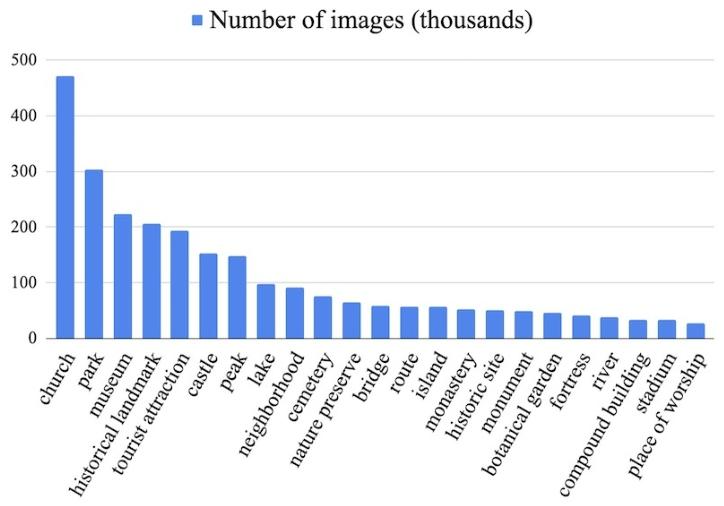
Figure 5: Histogram of the number of images by landmark category. This includes only categories with more than 25k images.
图 5:按地标类别划分的图像数量直方图。该图仅包含图像数量超过 2.5 万的类别。
- 授权稳定性:所有图像采用 CC0 或公有领域授权,可长期保留且无版权风险,避免类似 GLDv1 因版权问题缩水的情况。
2.3 核心挑战(贴近真实应用)
- 极长尾类分布:57% 的类别仅含≤10 张图像,38% 的类别仅含≤5 张图像,需解决极端类别不平衡问题。
- 高类内变异:同一地标图像包含不同视角(航拍 / 近景)、光照(白天 / 夜晚)、场景(室内 / 室外),甚至间接相关图像(如博物馆内的画作)。
- 域外查询主导:99% 测试图为非地标(如动物、产品),评测模型 “拒绝误判” 的能力,符合视觉搜索 APP 的真实查询场景。
3. 数据集构建流程
3.1 数据采集

Figure 6: Left: pipeline for mining images from Wikimedia Commons. Right: the user interface of the re-annotation tool.
- 主数据源:Wikimedia Commons(全球最大众包地标图像库),通过 Google 知识图谱查询 “地标”“旅游景点” 等关键词,关联 Wikipedia 文章与 Wikimedia 类别,下载对应图像(确保单图像关联单一类别)。
- 补充数据源:
- 正查询图:众包人员用智能手机拍摄全球选定地标。
- 负查询图:通过知识图谱查询非地标关键词(如 “动物”“家具”)获取,剔除与训练 / 索引集重复的图像。
3.2 真值标注优化
- 初始问题:Wikimedia 众包标签存在误差(如多地标漏标)、层级歧义(如 “公园内的山” 可标 “山” 或 “公园”)、负样本误判(部分负查询图实际是地标)。
- 优化方案:
- 基于 Kaggle 挑战赛 Top10 团队的模型预测,生成候选标签(避免单一方法偏见)。
- 设计标注工具:左侧展示地标样本图,右侧让标注者判断查询图是否匹配(简化为 “是 / 否” 问题)。
- 质量控制:每张图由 3 名标注者标注,按多数投票确定最终标签。
- 成果:投入 800 + 小时人工,识别任务标注量增加 72%,检索任务标注量增加 30%,部分误判的负样本被修正为正样本。
4. 评估指标设计
| 任务类型 | 指标名称 | 核心计算逻辑 | 适配场景需求 |
|---|---|---|---|
| 实例识别 | µAP(Global AP) | 1. 按预测置信度排序所有结果;2. 计算每个排名的精度(P (i))与正确性(rel (i));3. 加权求和后除以有效查询数(含地标的查询) | penalize 域外图像误判,衡量阈值设置能力 |
| 图像检索 | mAP@100 | 1. 对每个地标查询,仅考虑 Top100 结果;2. 计算 AP@100(精度与正确性加权);3. 所有有效查询的平均值 | 适配实际检索场景(无需返回所有匹配结果) |
5. 实验结果与分析
5.1 基线实验:迁移学习与基础性能
- 迁移学习验证:用 ResNet-101+GeM 池化 + ArcFace 损失训练模型,在独立数据集 Revisited Oxford(ROxf)和 Revisited Paris(RPar)上评测,结果如下:
| 训练数据集 | ROxf mAP(%) | RPar mAP(%) | 关键结论 |
|---|---|---|---|
| GLDv1-train | 66.3 | 80.2 | GLDv2 训练的模型性能显著更优 |
| GLDv2-train-clean | 78.5 | 82.9 | 较 GLDv1 提升约 10% |
| Landmarks-full | 50.8 | 70.4 | 规模小的数据集性能差距大 |
- 识别任务基线(µAP%):
| 模型训练集 | 验证集 | 测试集 |
|---|---|---|
| GLDv2-train-clean | 21.35 | 18.94 |
| GLDv1-train | 17.14 | 18.71 |
| Landmarks-full | 16.30 | 18.71 |
5.2 Kaggle 挑战赛结果(Top3 团队)
- 识别任务(µAP%):
| 团队 | 技术方案 | 测试集 | 验证集 | 标注优化前分数(测试集) |
|---|---|---|---|---|
| smlyaka | GF ensemble→LF→类别过滤 | 69.39 | 65.85 | 35.54 |
| JL | GF ensemble→LF→非地标过滤 | 66.53 | 61.86 | 37.61 |
| GLRunner | GF→非地标检测→GF + 分类器 | 53.08 | 52.07 | 35.99 |
- 检索任务(mAP@100%):
| 团队 | 技术方案 | 测试集 | 验证集 | 标注优化后 Precision@100(测试集) |
|---|---|---|---|---|
| smlyaka | GF ensemble→DBA/QE→分类器重排序 | 37.19 | 35.69 | 6.09 |
| GLRunner | GF ensemble→LF→DBA/QE→分类器 | 34.38 | 32.04 | 6.42 |
| Layer 6 AI | GF ensemble→LF→QE→EGT | 32.10 | 29.92 | 5.13 |
- 关键发现:挑战赛顶尖方案均以GF(全局特征搜索)为基础,结合LF(局部特征重排序)、DBA(数据库增强)、QE(查询扩展) 等技术;标注优化后,识别任务分数显著提升(因修正漏标),检索任务 mAP 无明显变化但 Precision@100 提升(因修正假阳性)。
6. 相关工作:与现有数据集对比
| 数据集名称 | 年份 | 地标数 | 测试图像数 | 训练图像数 | 索引图像数 | 覆盖范围 | 稳定性 | 核心不足 |
|---|---|---|---|---|---|---|---|---|
| Oxford [41] | 2007 | 11 | 55 | - | 5k | 单城市 | 是 | 规模极小,场景单一 |
| Paris [42] | 2008 | 11 | 55 | - | 6k | 单城市 | 是 | 规模极小,场景单一 |
| Google Landmarks [39] | 2017 | 30k | 118k | 1.2M | 1.1M | 全球 | 否 | 版权问题导致数据集缩水 |
| GLDv2 | 2019 | 200k | 118k | 4.1M | 762k | 全球 | 是 | 无显著不足,贴近真实挑战 |
- 结论:GLDv2 在规模(图像数、类别数)、稳定性(版权授权)、真实挑战(域外 / 长尾) 上全面超越现有数据集。
7. 结论
LDv2 是目前最大规模的实例级地标识别 / 检索基准数据集,通过模拟真实应用中的长尾分布、域外查询等挑战,填补了传统数据集的空白;其稳定的版权授权、完善的真值标注和公开的评测代码(https://github.com/cvdfoundation/google-landmark),为该领域技术研发与性能对比提供了可靠基础,同时迁移学习实验证明其可适配其他实例
附录(数据集sample)

Figure 7: Sample classes from the training set (1 of 2).

Figure 8: Sample classes from the training set (2 of 2).

Figure 9: Retrieval task: Query images with a sample of relevant images from the index set (1 of 3).

Figure 10: Retrieval task: Query images with a sample of relevant images from the index set (2 of 3).


Figure 11: Retrieval task: Query images with a sample of relevant images from the index set (3 of 3).(a) Teatro Espanol – Some relevant images that are difficult to retrieve: Architectural drawing, painting of the inside, historical photograph of audience members.(b) Azkuna Zentroa – Detail views and photos showing the construction of the building.

Figure 12: Sample images from the test set.
*** ***
