【一篇为了Scaling law而整容的文章】Pre-training under infinite compute 论文阅读笔记
本周浅读一篇Topic比较有意思的论文 ↓
Pre-training under infinite compute
这篇论文也算是一篇靠“邪修式”预训练搞出来的 Scaling Law 方向的文章。毕竟《Scaling Laws for Neural Language Models》算是为 LLM 训练指明了一条明路的高价值工作,所以学术界不少团队都喜欢沿着这个思路往下做。但其实这种经验归纳型的研究,前面的坑非常多,这篇文章也确实踩中了一些。
一句话总结
作者尝试了若干邪修方法,去回答这样一个问题:在数据量相对有限(4Btoken)但仍有大量算力可用的情况下, 增加Epoch,Ensamble,蒸馏哪种策略效果更好?
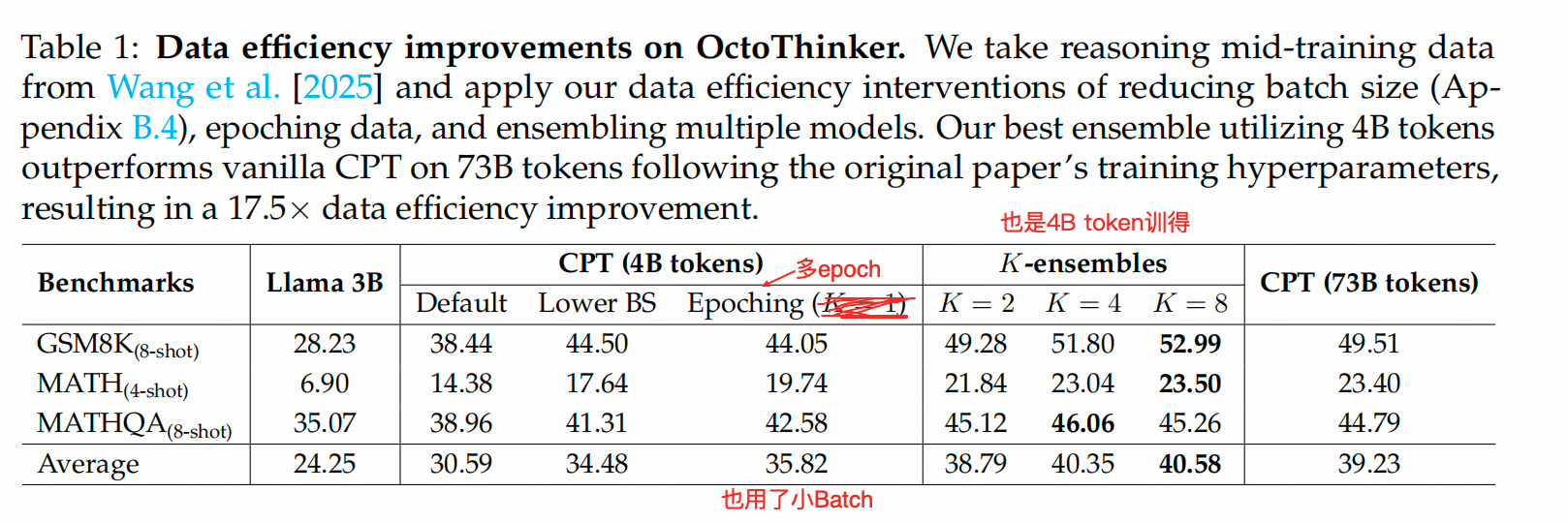
答案是:集成效果最好,在【4B token】上训练的,8个LLama-3.2-3B的集成,下游任务的效果好过一个在【73B token】上训练的LLama-3.2-3B
所谓的邪修指什么
Weight decay从0.1放大到3.2 然后拉长训练epoch
但其实他在Ensamble和蒸馏的时候也都没有用这个配置,只在【单独加长训练epoch数】的时候用了。
关键细节
1. 仅拉长训练Epoch行不行?——当然不行
其实,目前大部分基座Pretrain时,在原始语料上的训练轮数都在2个epoch左右。这篇文章为了对比清楚,还是展示了【单独拉长Epoch数的结果】,不过这两组实验中也出现了本文的第一个踩坑点。
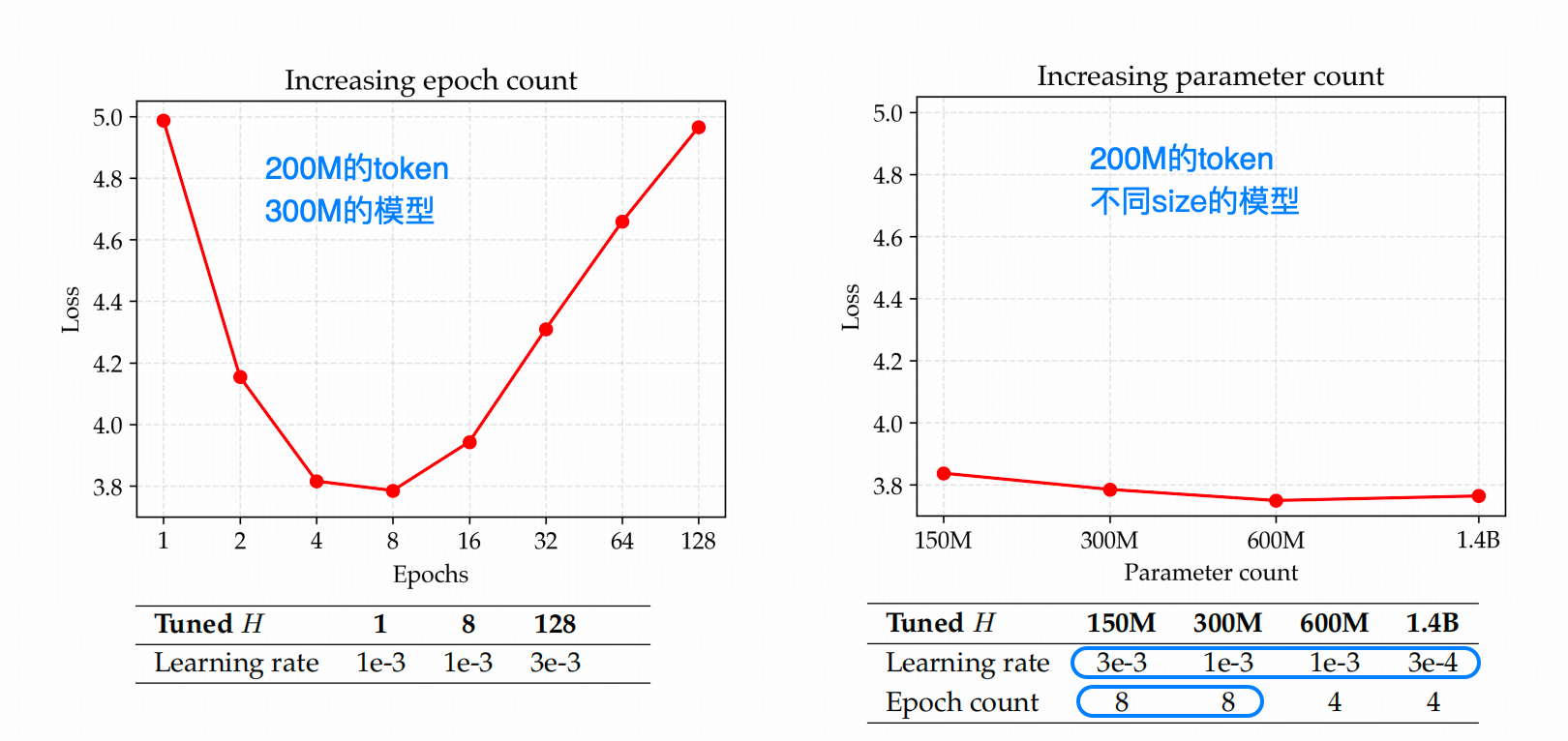
上图中左图,是作者用DCLM这个数据集(一个比较干净的预训练数据集)中的200M token 作为训练数据,在一个300M的模型上做了一个猛加epoch的实验,不出意外的得到了overfit的实验结果。
但这里300M的模型能代表1.4B的模型吗,能代表72B的模型吗?能代表100B以上的模型吗?
另外上图中我用蓝色框画出来了超参的变化,这点其实在经验归纳型的描述中,是一个比较强的干扰因素,一般论文倾向于去证明自己的结论是Robust to different Hyper-parameters的。但是,这轮论文多数讲述中都是以实验测定的最佳超参配置为基础的,而且作者的实验场只有DCLM这个数据集,而且最大的数据量也就到4B,这就没有办法推翻【特例规律化】这一可能谬误。
对比 Scaling Laws for Neural Language Models 里的图↓可信度的差距就比较明显了。 同一个实验,用多少种规模的模型去做,用多少种配置去做,得到的归纳可信度是不一样的。
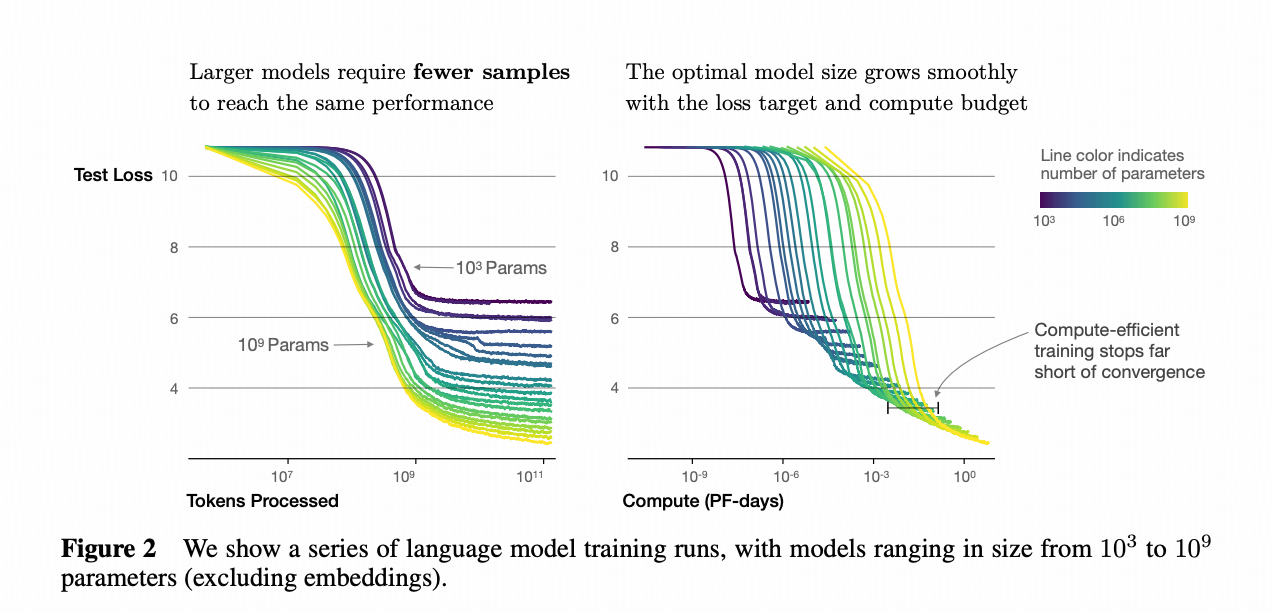
重申一下,不为捧一踩一,学生和机构能用的算力和财力都是不能比的,这篇文章有一些现实条件的局限性这无可非议,但可以在讲述上只提发现了更好的方法,而不一定非常碰“Scaling Law”这个东西。
2. 没法应拉长Epoch吗?——作者想出了一个邪招↑_(ΦwΦ)Ψ 放大Weight Decay
以往放大Weight Decay的研究都是从1e-3放大到1e-2或0.1这个水平,这篇文章直接把Weight Decay干到了3。
下面这条线就可以看出【说话的艺术】了🙄,紫色线的对应epoch数比上面红线的epoch数翻了一倍,对应的超参与之前的实验配置也有所不同。
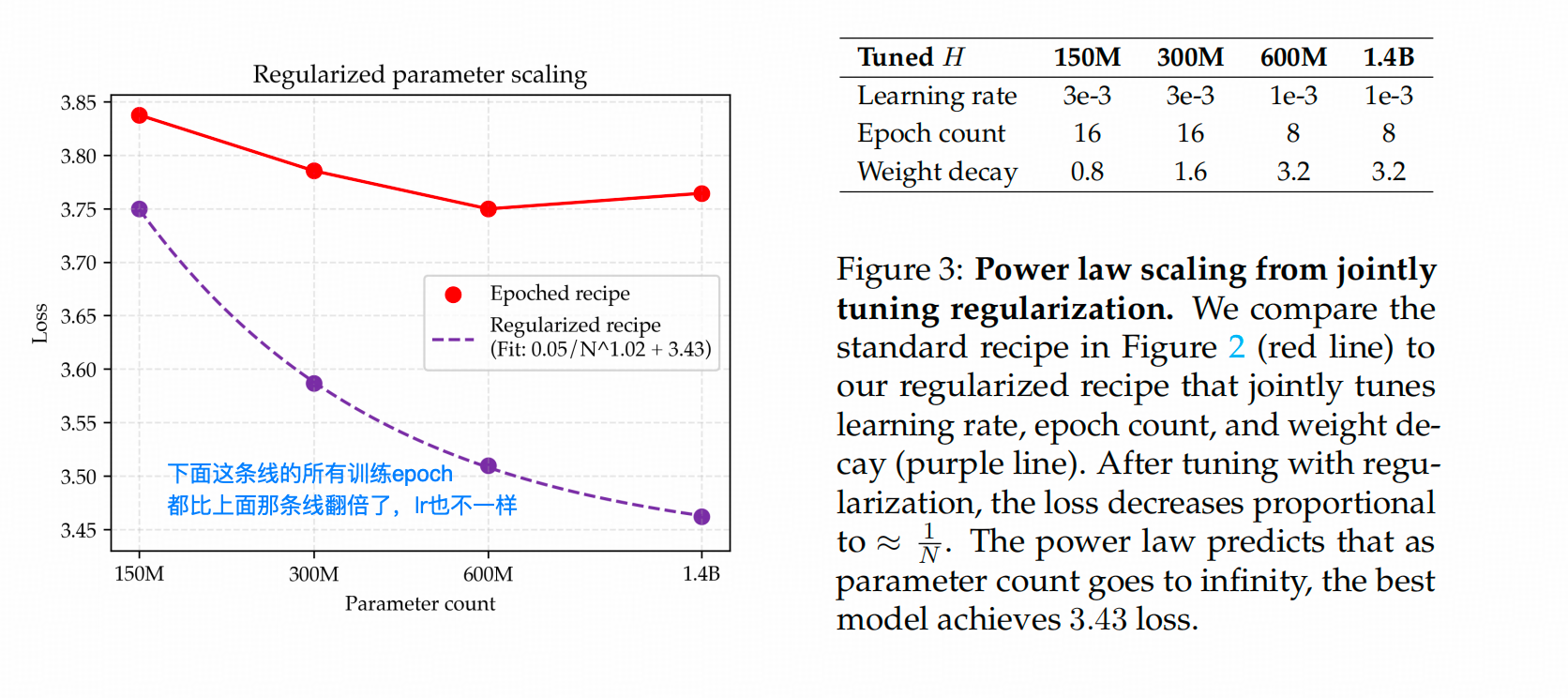
其实就解法的合理性而言,作者的方案是有一定道理的——这么大的Weight Decay,每一步都嘎嘎削gradient带来的影响,这样确实能减缓overfit的到来。
但你这么画图我就非常不满了——不是说不该画这个图,而是这个图对实验配置非常不鲁棒
※ 你怎么保证插值点之外的数据符合你的预期?
※ 你怎么确定饱和值不会来得更高?
※ 如果我在其他配置、不同参数量的情况下,得到的数值落在你的曲线之上或之下,那到底是我的配置有问题,还是你的那条线本身就有问题?
经验归纳类的研究总会遇到这类问题,但作者在文章里其实回避了这个关键点,直接默认这么做是合理的。
3. 忘掉邪修,正常的模型Ensamble就能拿到更好的结果
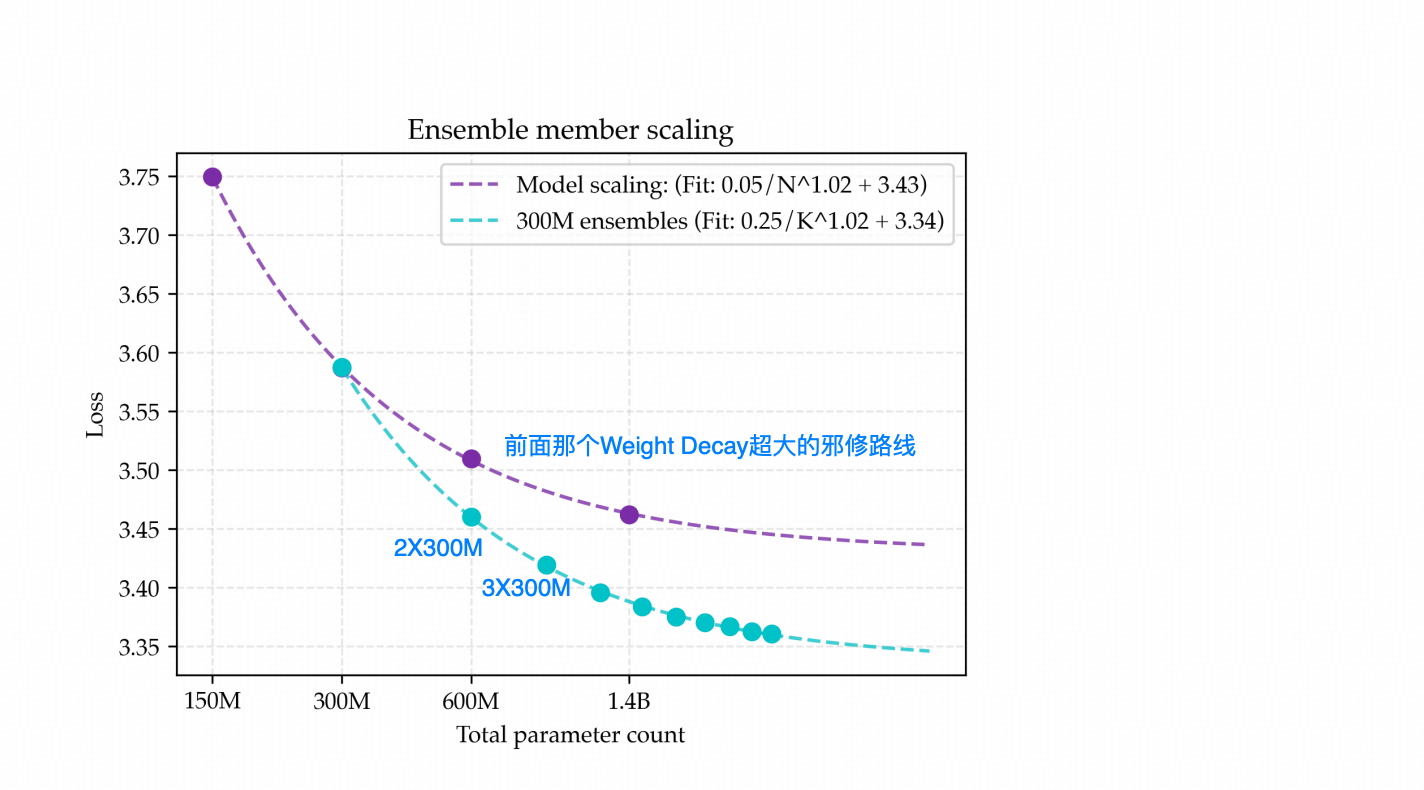
在一个无情的转折之后,作者直接把方案切到了Ensamble上,他做了这样一个实验,还是200M的token量,比较 【多个300M的模型集成】 ,跟【等量参数的单独模型】之间,集成是不是有优势?
——其实答案是【肯定有优势】。
下图中,浅蓝色线是对集成规模从 1 到 8 的情况(每个规模使用独立训练的 300M 模型,并单独调最优超参,包括最优 epoch 数),把对应的 loss 打成点连起来的结果;紫色线则是上一节那条“邪修路线”的模型loss。在参数量相当的情况下,Ensemble 的结果确实更优。
作者在LLama3 上做了continue pretrain,这个实验上,也是8个3B模型的下游效果最好,见下表。
但是下面这个表槽点也很多,只看K=8这列和CPT-73B这列的结果差异就好。作者认为在4B的模型上整出了73B数据上的效果,所以数据效率高。
4. 集成模型+蒸馏——相同参数量,相同数据量,更好的结果……吗?
其实在得到多个集成模型之后,大部分人的第一反应可能都集中在两个点上:
第一:MOE的效果跟集成比如何?
第二:能蒸馏回更小的模型吗?
作者做了蒸馏方面的实验,同时,他的MOE方面的实验——我愿称之为对MOE的侮辱,后面单说。
作者做了两个非常不可比的实验来证明蒸馏效果,而且画了一个真不如不画的图来解释(有的时候写表比画图清楚,但是也容易漏腚😒)
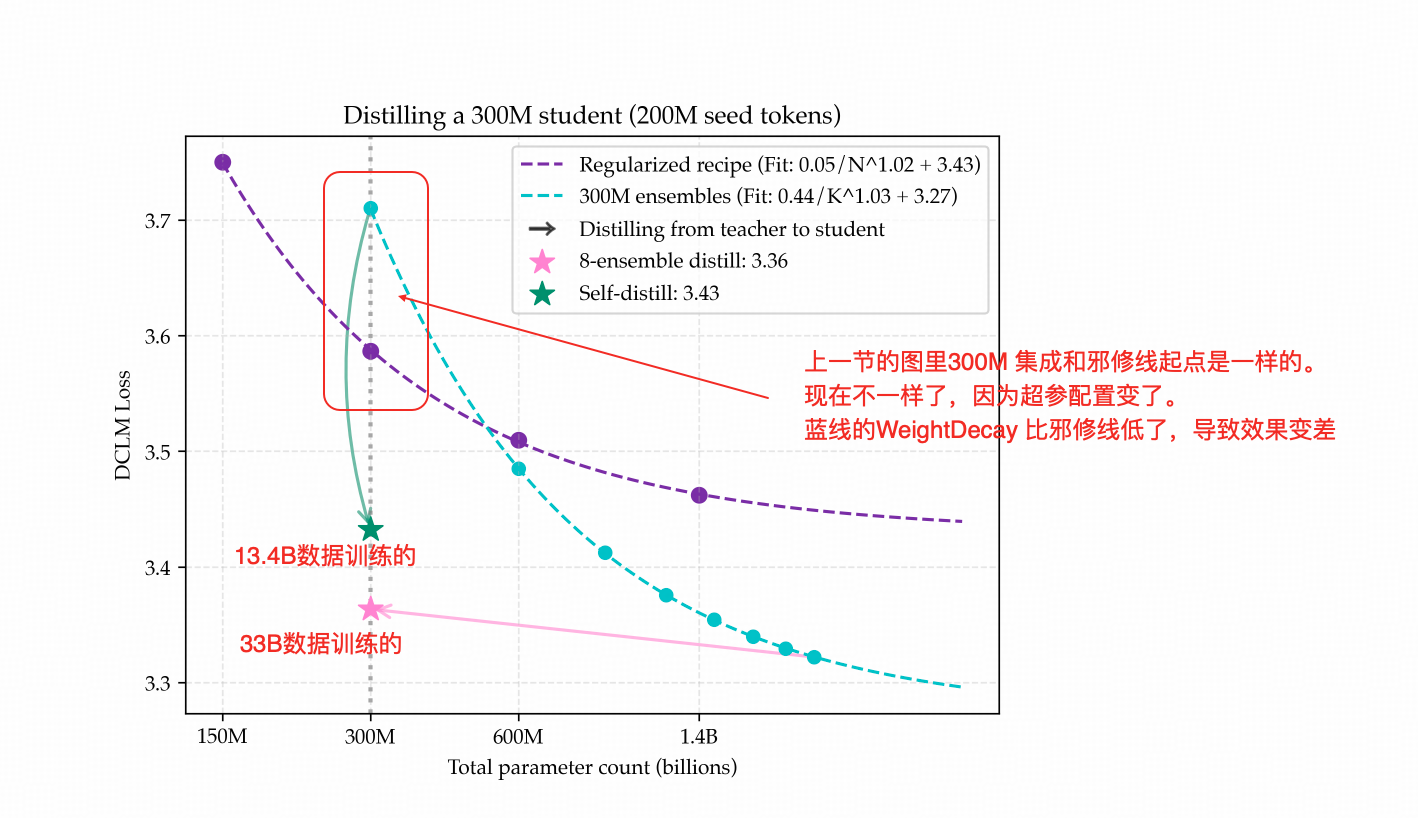
上图中的紫色线是那条延续了两张图的【邪修线】(Weight Decay撑得贼大的)
上图中的蓝色线,作者做了点手脚——上一节的时候300M的点是蓝线和紫线的交点,因为相同配置下 ,1个模型的Ensemble不算Ensemble。
本节的这张图,蓝色线的300M模型的loss却比紫线要高,原因是这张图上的蓝线的Weight Decay调小了,从上张图的1.6改成了0.8。这也是我对这种【基于所谓最优超参画Scaling 拟合图】的做法最难绷的点。
另外,本文这里的【Distillation】指的是硬Distillation,也就是现在常用的,大模型合成数据给小模型学习的方法,而不是Logits牵引分布的方法。
上图中有两个星,绿色星是用1个300M的模型合成了若干数据,在总量13.4B的token(有重复)的训练量下得到,Student模型的loss,而粉色星是在8个300M模型合成了若干数据,在总量33.4B的数据上训练出的Student模型的loss。
合成数据量与混合比
ensemble distill:1:9(real:synthetic),共 16×200 M×(1+9)=33.4 B token
self-distill:1:3(real:synthetic),共 16×200 M×(1+3)=13.4 B token
原文证据 ↓

这两个点其实从训练总token量的角度是完全不可比的。
这里我们得把实验结果和因此得到的实验结论分开看,原文 Section 6 的【实验结果】其实是可以参考的,但整个 Section 6 的【实验结论】我都建议别当真。
至于作者侮辱MOE的实验
他的配置是把:10个300M的模型放在一张运算图上,只前向一次(10个模型并行)和后向一次,在同一批数据中算出10*batch_size的loss,这个loss做平均,然后BP。这个做法跟MOE有一毛钱像吗?这样作者得到的结论我就不说了,没意义。
评价
- 关于作者的内容我有一大部分并没有展示,因为作者试图用在【一个数据集】【一种模型架构】【150M-1.4B】这个区间的【特定超参数】配置的结果来拟合Scaling Law,这点是我认为非常不妥的。
- 作者附录里也展示了很多调参的结果,但是大部分图都不属于没有坑的类型,比如:
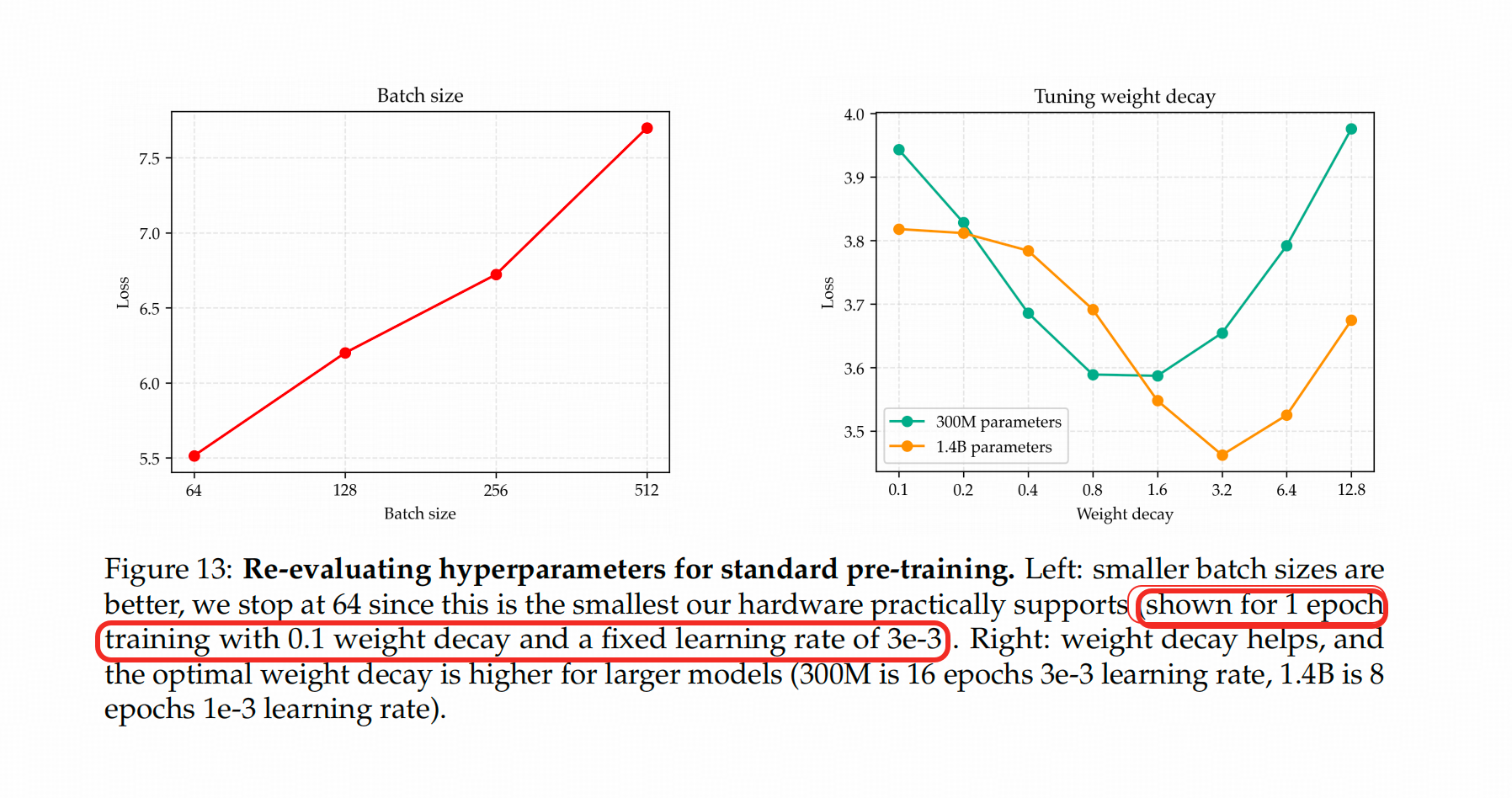
上图左侧的图是 1个epoch的情况下300M这个size的模型在一个特定lr和Weight Decay(还不是作者最终选的组合)的情况下的表现。
- 有三个原因决定我把这个发出来:
- 一来是这个计算量余量比数据量余量更大已经是现实,原本的Scaling Law在当前的阶段确实遇到了很大的挑战,这个方向很好;
- 二来,因为MOE很耀眼,导致Ensemble在大模型嘴里已经成了“传统集成方法”,但实际上模型集成确实有一些MOE不容易达到的优势,值得被讨论;
- 三来,狂拉Weight Decay这种邪修虽然在应用型模型训练场景中不会被用到,但是思路其实挺开阔的(*/ω\*),不是坏事。