【CVOR】即插即用SCConv:新一代卷积模块,显著提升CNN效率与性能
01 论文介绍

论文标题: SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy
论文地址: https://openaccess.thecvf.com/content/CVPR2023/papers/Li_SCConv_Spatial_and_Channel_Reconstruction_Convolution_for_Feature_Redundancy_CVPR_2023_paper.pdf
02 架构创新
卷积神经网络(CNNs)在计算机视觉领域取得了显著成功,但这通常以巨大的计算和存储资源为代价。一个关键原因是卷积层在提取特征的过程中产生了大量的空间(spatial)和通道(channel)冗余。现有工作大多只关注其中一个维度的冗余,未能系统性地解决问题。
针对此,该论文提出了一种高效的即插即用卷积模块——SCConv(Spatial and Channel reconstruction Convolution),旨在通过双维度重构,同时减少特征图中的空间与通道冗余,从而在降低计算复杂度的同时,提升模型的特征表达能力。
主要贡献概括如下:
- 提出空间重构单元(Spatial Reconstruction Unit, SRU): 利用一种“分离-重构”(Separate-and-Reconstruct)策略,有效抑制特征图中的空间冗余,并增强有效特征的表达。
- 提出通道重构单元(Channel Reconstruction Unit, CRU): 采用“分割-变换-融合”(Split-Transform-Fuse)策略,在减少通道间冗余的同时,显著降低了计算与存储开销。
- 设计了SCConv模块: 将SRU和CRU顺序集成,构成一个可直接替换标准卷积的独立单元,能够轻松嵌入现有CNN架构(如ResNet、DenseNet等),实现性能与效率的双重提升。
03 方法解析
SCConv模块由**空间重构单元(SRU)和通道重构单元(CRU)**顺序连接而成。如下图所示,当SCConv模块被嵌入一个ResNet的瓶颈块(ResBlock)时,它取代了核心的3x3卷积层。
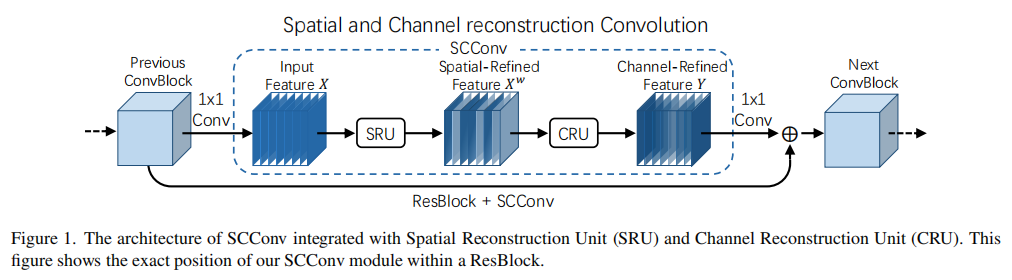
对于一个输入的中间特征 X,它首先通过SRU进行处理,得到空间上被提炼的特征 X'。随后,X' 被送入CRU进行通道维度的重构,最终输出被精炼的特征 Y。整个过程系统性地减少了特征在两个维度上的冗余。
1. 空间重构单元(SRU): 抑制空间冗余
SRU的核心目标是识别并重组特征图中的空间信息,其采用**“分离-重构”(Separate-and-Reconstruct)**机制。
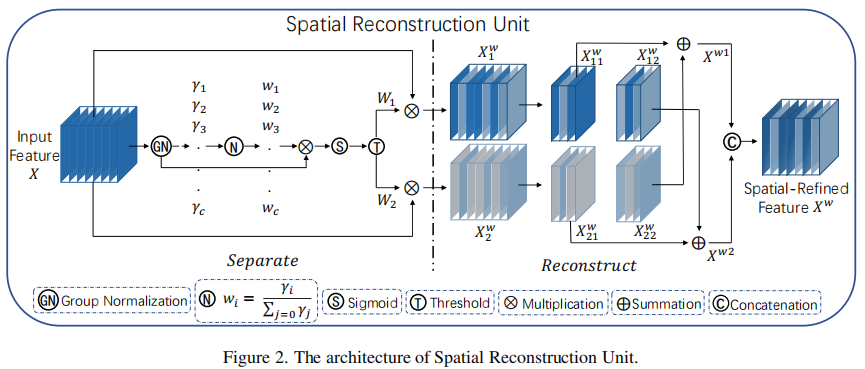
a) 分离(Separate)操作:
此步骤旨在将信息丰富的特征图与信息量较少的(即冗余的)特征图分离开。作者创新性地利用**组归一化(Group Normalization, GN)**中的可学习缩放参数 γ 来评估每个通道特征图的空间信息含量。其假设是:空间内容越丰富,像素值的变化就越大,对应的 γ 值也应更大。
-
权重计算: 首先对输入特征
X进行GN操作。然后,将所有通道的γ值进行归一化,得到每个特征图的重要性权重W_γ。
Wγ={wi}=γi∑j=1Cγj,i,j=1,2,…,CW_{\gamma} = \{w_i\} = \frac{\gamma_i}{\sum_{j=1}^{C} \gamma_j}, \quad i, j = 1, 2, \dots, C Wγ={wi}=∑j=1Cγjγi,i,j=1,2,…,C -
特征分组: 利用一个门控机制(Gated by a threshold, 实验中设为0.5)将
W_γ转换为二值权重W_1(信息丰富)和W_2(信息冗余)。通过将W_1和W_2分别与原始特征X进行元素级乘法,即可将特征图分离为信息丰富的X_w1和信息较少的X_w2两部分。
b) 重构(Reconstruct)操作:
为了增强特征表达并压缩空间信息,SRU并未直接丢弃冗余部分,而是通过一种交叉重构的方式将两部分特征进行融合。
- 交叉融合: 如图2所示,
X_w1的一部分与X_w2的一部分相加,反之亦然。这种方式促进了不同信息层级特征之间的流动与交互。 - 拼接输出: 重构后的两部分特征在通道维度上进行拼接(Concatenation),最终得到空间精炼后的特征
X'。完整的重构过程如下:
{Xw1=W1⊗X,Xw2=W2⊗X,Xw11′⊕Xw22′=Xw1′,Xw21′⊕Xw12′=Xw2′,Xw1′∪Xw2′=X′\begin{cases} X_{w1} = W_1 \otimes X, \\ X_{w2} = W_2 \otimes X, \\ X'_{w11} \oplus X'_{w22} = X'_{w1}, \\ X'_{w21} \oplus X'_{w12} = X'_{w2}, \\ X'_{w1} \cup X'_{w2} = X' \end{cases} ⎩⎨⎧Xw1=W1⊗X,Xw2=W2⊗X,Xw11′⊕Xw22′=Xw1′,Xw21′⊕Xw12′=Xw2′,Xw1′∪Xw2′=X′
通过SRU,模型不仅抑制了空间冗余,还通过重构增强了特征的表达能力,为后续的通道处理提供了更高质量的输入。
2. 通道重构单元(CRU): 减少通道冗余
经过SRU处理后的特征 X',虽然空间冗余得到抑制,但通道间仍存在冗余。CRU通过**“分割-变换-融合”(Split-Transform-Fuse)**策略来解决此问题。
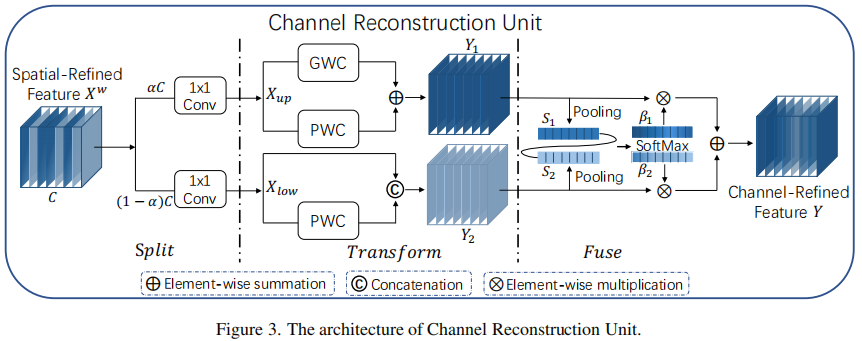
a) 分割(Split):
将输入的空间精炼特征 X' 的通道按比例 α 分为两部分:上路(Upper Part)X_up(αC个通道)和下路(Lower Part)X_low((1-α)C个通道)。随后,使用1x1卷积对两路特征进行通道压缩(压缩比例为 r),以平衡计算成本。
b) 变换(Transform):
两路特征经过不同的变换模块,以低成本方式提取多层次信息。
-
上路变换(Rich Feature Extractor): 此路旨在提取高层级的代表性特征。它并行使用**分组卷积(GWC)和逐点卷积(PWC)**来替代昂贵的标准卷积。GWC减少了参数量,而PWC则补偿了分组带来的信息交流损失。两者的输出相加,得到丰富的特征
Y_1。
Y1=MGXup+MP1XupY_1 = M_G X_{up} + M_{P1} X_{up} Y1=MGXup+MP1Xup -
下路变换: 此路旨在生成补充性的细节特征。它使用廉价的1x1 PWC处理
X_low的一部分,同时直接**重用(reuse)**另一部分X_low。这种设计在几乎不增加额外成本的情况下丰富了特征维度。最终,两者拼接得到特征Y_2。
Y2=MP2Xlow∪XlowY_2 = M_{P2} X_{low} \cup X_{low} Y2=MP2Xlow∪Xlow
c) 融合(Fuse):
为了自适应地合并来自两条路径的特征 Y_1 和 Y_2,CRU采用了类似SKNet的轻量级软注意力机制。
-
全局信息编码: 对
Y_1和Y_2分别进行全局平均池化(Global Average Pooling),得到通道描述符S_1和S_2。 -
注意力权重生成: 通过Softmax函数计算两路特征的重要性向量
β_1和β_2。
β1=eS1eS1+eS2,β2=eS2eS1+eS2,β1+β2=1\beta_1 = \frac{e^{S_1}}{e^{S_1} + e^{S_2}}, \quad \beta_2 = \frac{e^{S_2}}{e^{S_1} + e^{S_2}}, \quad \beta_1 + \beta_2 = 1 β1=eS1+eS2eS1,β2=eS1+eS2eS2,β1+β2=1 -
加权融合: 最后,根据注意力权重对
Y_1和Y_2进行加权求和,得到最终的通道重构特征Y。
Y=β1Y1+β2Y2Y = \beta_1 Y_1 + \beta_2 Y_2 Y=β1Y1+β2Y2
CRU通过这种精巧的设计,用低成本操作(GWC、PWC、特征重用)高效地完成了通道维度的特征提取与冗余压缩。
04 SCConv模块的作用与适用场景
模块综合作用:
- 双维度冗余抑制: SCConv是为数不多的能够同时处理**空间维度(SRU)和通道维度(CRU)**冗余的卷积模块,从而更彻底地提升特征的有效密度。
- 增强特征表达: SRU的“分离-重构”和CRU的“分割-变换-融合”策略,不仅压缩了冗余,更强化了特征的判别性和层次性,实现了性能提升。
- 显著降低复杂度: 相较于标准3x3卷积,SCConv在典型配置下(
α=1/2, r=2, g=2),可以将参数量和FLOPs降低约5倍(P_s / P_sc ≈ 5),同时保持甚至超越基线模型的精度。 - 即插即用与高兼容性: 作为一个独立的计算单元,SCConv可直接替换现有CNN架构中的标准3x3卷积层,无需调整网络结构或引入复杂的训练策略。
适用场景分析:
- 模型轻量化与加速: 当需要在资源受限设备(如移动端、嵌入式系统)上部署CNN模型时,SCConv可作为标准卷积的高效替代品,在保证性能的同时大幅降低计算和存储需求。
- 主流CNN骨干网络性能提升: 可无缝集成于ResNet、DenseNet、ResNeXt等网络中,在图像分类、目标检测等任务上,通过减少特征冗余来提升模型的准确率和效率。
- 高效网络结构设计研究: 对于探索新型轻量化网络结构的研究者,SCConv提供了一种比Depthwise Conv、GhostConv等更全面的冗余压缩方案,可作为构建高效模型的基石。
总结而言,SCConv通过对特征冗余的深刻洞察,设计了在空间和通道两个维度上协同工作的重构单元,实现了计算效率与模型性能的卓越平衡。它作为一个通用且高效的即插即用模块,为设计和优化现代CNN模型提供了强有力的工具。
05 即插即用模块
import torch
import torch.nn.functional as F
import torch.nn as nn
# 定义一个二维组归一化层
class GroupBatchnorm2d(nn.Module):def __init__(self, c_num: int,group_num: int = 16, # 组的数量,默认为16eps: float = 1e-10 # 为了数值稳定性添加到分母的小常数):super(GroupBatchnorm2d, self).__init__() # 调用父类的构造函数assert c_num >= group_num # 确保输入通道数量大于等于组的数量self.group_num = group_num # 设置组的数量self.gamma = nn.Parameter(torch.randn(c_num, 1, 1)) # 初始化缩放参数gammaself.beta = nn.Parameter(torch.zeros(c_num, 1, 1)) # 初始化偏移参数betaself.eps = eps # 设置小常数epsdef forward(self, x): # 前向传播方法N, C, H, W = x.size() # 获取输入张量的尺寸x = x.view(N, self.group_num, -1) # 将张量重新塑形,以便于按组计算均值和标准差 四维 - 三维mean = x.mean(dim=2, keepdim=True) # 计算每组的均值std = x.std(dim=2, keepdim=True) # 计算每组的标准差x = (x - mean) / (std + self.eps) # 归一化x = x.view(N, C, H, W) # 恢复原始形状 3维 - 4维return x * self.gamma + self.beta # 应用缩放和平移# Spatial Reconstruction Unit (SRU)
class SRU(nn.Module):def __init__(self,oup_channels: int, # 输出通道数量group_num: int = 16, # 组的数量gate_treshold: float = 0.5 # 门限值):super().__init__() # 调用父类的构造函数self.gn = GroupBatchnorm2d(oup_channels, group_num=group_num) # 创建GroupBatchnorm2d实例self.gate_treshold = gate_treshold # 设置门限值self.sigomid = nn.Sigmoid() # 初始化Sigmoid激活函数def forward(self, x):gn_x = self.gn(x) # 组归一化 GN层的可训练参数γ衡量特征图中空间信息的不同,空间信息越是丰富,γ越大。w_gamma = self.gn.gamma / sum(self.gn.gamma) # 计算权重化的gamma,反映不同特征图的重要性reweigts = self.sigomid(gn_x * w_gamma) # 计算重加权后的值# 门控机制,获得信息量大和信息量较少的两个特征图info_mask = reweigts >= self.gate_treshold # 信息掩码noninfo_mask = reweigts < self.gate_treshold # 非信息掩码x_1 = info_mask * x # 保留信息部分x_2 = noninfo_mask * x # 保留非信息部分x = self.reconstruct(x_1, x_2) # 重构输出return xdef reconstruct(self, x_1, x_2): # 重构方法# 交叉相乘与cat,获得最终的输出特征:能够更加有效地联合两个特征 并且 加强特征之间的交互x_11, x_12 = torch.split(x_1, x_1.size(1) // 2, dim=1) # 分割x_1x_21, x_22 = torch.split(x_2, x_2.size(1) // 2, dim=1) # 分割x_2return torch.cat([x_11 + x_22, x_12 + x_21], dim=1) # 重构并连接# Channel Reconstruction Unit (CRU)
class CRU(nn.Module):'''alpha: 0<alpha<1 # alpha应该在0到1之间'''def __init__(self,op_channel: int, # 操作通道数量alpha: float = 1 / 2, # 分割比例squeeze_radio: int = 2, # 压缩率group_size: int = 2, # 组大小group_kernel_size: int = 3 # 组卷积核大小):super().__init__() # 调用父类的构造函数self.up_channel = up_channel = int(alpha * op_channel) # 计算上半部分通道数量self.low_channel = low_channel = op_channel - up_channel # 计算下半部分通道数量self.squeeze1 = nn.Conv2d(up_channel, up_channel // squeeze_radio, kernel_size=1, bias=False) # 上半部分压缩卷积self.squeeze2 = nn.Conv2d(low_channel, low_channel // squeeze_radio, kernel_size=1, bias=False) # 下半部分压缩卷积# 上半部分self.GWC = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=group_kernel_size, stride=1,padding=group_kernel_size // 2, groups=group_size) # 组卷积self.PWC1 = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=1, bias=False) # 点卷积# 下半部分self.PWC2 = nn.Conv2d(low_channel // squeeze_radio, op_channel - low_channel // squeeze_radio,kernel_size=1,bias=False) # 点卷积self.advavg = nn.AdaptiveAvgPool2d(1) # 自适应平均池化def forward(self, x): # 前向传播方法# 分割up, low = torch.split(x, [self.up_channel, self.low_channel], dim=1) # 分割输入张量up, low = self.squeeze1(up), self.squeeze2(low) # 应用压缩卷积# 变换Y1 = self.GWC(up) + self.PWC1(up) # 上半部分变换Y2 = torch.cat([self.PWC2(low), low], dim=1) # 下半部分变换# 融合out = torch.cat([Y1, Y2], dim=1)out = F.softmax(self.advavg(out), dim=1) * out # 使用softmax进行通道注意力机制out1, out2 = torch.split(out, out.size(1) // 2, dim=1) # 再次分割return out1 + out2 # 返回融合后的结果# 定义ScConv模块
class ScConv(nn.Module):def __init__(self,op_channel: int, # 操作通道数量group_num: int = 16, # 组的数量gate_treshold: float = 0.5, # 门限值alpha: float = 1 / 2, # 分割比例squeeze_radio: int = 2, # 压缩率group_size: int = 2, # 组大小group_kernel_size: int = 3 # 组卷积核大小):super().__init__() # 调用父类的构造函数self.SRU = SRU(op_channel, # 创建SRU实例group_num=group_num,gate_treshold=gate_treshold)self.CRU = CRU(op_channel, # 创建CRU实例alpha=alpha,squeeze_radio=squeeze_radio,group_size=group_size,group_kernel_size=group_kernel_size)def forward(self, x): # 前向传播方法x = self.SRU(x) # 应用SRUx = self.CRU(x) # 应用CRUreturn x # 返回最终结果if __name__ == '__main__':# 生成随机输入张量input = torch.randn(1, 32, 64, 64) # 创建一个随机输入张量model = ScConv(32) # 创建ScConv模型实例# 执行前向传播output = model(input)print('input_size:', input.size()) # 打印输入张量的尺寸print('output_size:', output.size()) # 打印输出张量的尺寸