第N7周打卡:调用Gensim库训练Word2Vec模型
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、准备工作





二、训练Word2Vec模型
from gensim.models import Word2Vecmodel = Word2Vec(result_stop, # 用于训练的语料数据vector_size=100, # 是指特征向量的维度,默认为100。window=5, # 一个句子中当前单词和被预测单词的最大距离。min_count=1) # 可以对字典做截断,词频少于min_count次数的单词会被丢弃掉, 默认值为5。
三、模型应用
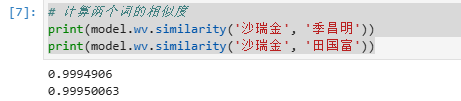
3.1 计算词汇相似性
# 计算两个词的相似度
print(model.wv.similarity('沙瑞金', '季昌明'))
print(model.wv.similarity('沙瑞金', '田国富'))
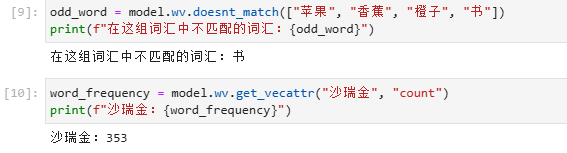
3.2 找出不匹配的词汇

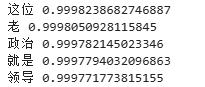
# 选出最相似的5个词
for e in model.wv.most_similar(positive=['沙瑞金'], topn=5):print(e[0], e[1])
3.2 计算词汇的词频
四、总结
Word2Vec 模型学习总结
4.1Word2Vec 是一种非常强大的词嵌入(Word Embedding)技术,通过学习单词的分布式表示,可以将单词映射到高维向量空间中,使得语义相似的单词在向量空间中的距离更近。
4.2主要参数理解
4.2.1vector_size (特征向量维度)
决定了词向量的维度大小
通常设置在50-300之间
维度越高能捕捉更多特征,但也需要更多数据和计算资源
4.2.2window (上下文窗口大小)
控制训练时考虑的上下文范围
较大的窗口能捕捉更多主题信息(文档级语义)
较小的窗口捕捉更多语法/功能信息(局部语义)
4.2.3min_count (最小词频)
过滤低频词的重要参数
设置过低会导致模型学习不常见词的噪声
设置过高会丢失一些有价值但低频的词
4.3模型特点总结
4.3.1分布式表示
将单词表示为稠密向量
解决了传统one-hot表示的高维稀疏问题
4.3.2语义捕捉能力
能够捕捉"国王-男人+女人≈女王"这样的语义关系
相似词在向量空间中距离相近
4.3.3两种训练算法
CBOW (Continuous Bag-of-Words):通过上下文预测当前词
Skip-gram:通过当前词预测上下文(适合小数据集)
实际应用经验
数据预处理很重要
分词质量直接影响模型效果
去除停用词、特殊符号等噪声
考虑词干提取或词形还原
参数调优建议
大数据集可以使用更大的window和vector_size
小数据集建议使用Skip-gram算法
min_count根据语料大小设置,一般5-20
4.3.4模型评估方法
相似词检索:model.wv.most_similar(‘单词’)
词语类比:model.wv.most_similar(positive=[‘女人’, ‘国王’], negative=[‘男人’])
可视化降维检查(如t-SNE)