【JavaEE初阶】1124网络原理
目录
请求的五大部分:
响应的五大部分:
URL组成部分:
报头header
Host
Content-Length
TCP和UDP的差别:
Content-Type
User-Agent(简称UA)
Referer
Cookie机制
HTTP协议中:
请求的五大部分:
- 首行(包含方法、URL、版本号)
- 请求头(由键值对组成)
- 空行(分隔header和正文)
- 正文
响应的五大部分:
- 首行(包含版本头、状态码、状态码描述)
- 响应头(由键值对组成)
- 空行(分隔header和正文)
- 正文
URL组成部分:
协议名://ip地址(域名):端口号/路径?查询字符串
- 其中查询字符串 是由程序员自定义的键值对组成的
urlencode方法:
- GET
- POST
- PUT
- DELETE
- 其中PUT 和 DELETE是Restful api设计风格
GET 和POST的区别:
- 语义不同(GET 是获取,POST是发出)
- GET经常把数据放到URL的 query string 中. POST 经常把数据放到body中
报头header
- 是键值对结构
- 分成很多行,每一行是一个键值对
- 键和值之间使用 :(冒号) (空格)分割
- 键和值都是PFC标准文档规定的
Host
- 表示服务器主机的地址和端口
- Host:xxx,代表着当前访问的服务器或者端口在哪里
- eg:Host:gitee.com(:端口号)
- 绝大部分情况下ip地址和端口号这两个属性是一样的
- 但是也有一些特殊场景下是不一样的,比如使用了代理,但就算使用了代理,也可以通过Host来获取到最原始的目标是啥
HTTP协议中,传输过程可能会涉及加密,其中URL部分是不会被加密的,被加密的是header和body.
服务器收到请求之后做一个最终校验,验证url中的内容和header中加密的内容是否一致
那有同学可能就要问了,登录密码安全吗?
- ->一般登录密码是要在业务层加密的.
- ->依赖HTTPS 这种操作,只能保证传输过程是安全的
- ->但是如果密码就明文保存在服务器上,服务器可能会被黑客攻击,严重的触发拖库,也会造成密码泄露
Content-Length
- 表示body中的数据长度,单位是字节(判断请求中是否有body)
HTTP协议是基于TCP实现的(版本号<=2.0)
所谓的HTTP协议,就是把字符串构造成HTTP约定的格式
HTTP请求的五大部分:
- 首行(包含方法、URL、版本号)
- 请求头(由键值对组成)
- 空行(分隔header和正文)
- 正文
把上面这一串字符串写到tcp socket中
对于TCP来说,一个连接上可以发多个请求
服务器收到数据后要区分:从哪到哪是一个完整的 http 请求数据,具体流程如下:
- 没有body的http请求,读到空行,就认为结束了
- 有body的http请求:
- 先读取首行和header,读到空行
- 解析header中的Content-Length,根据这里的值,接下来再读固定的字节长度
TCP和UDP的差别:
- UDP是面向数据报的
- 读写的基本单位是一个UDP数据报
- 如果某个应用层协议基于UDP,一个UDP数据报就对应一个完整的应用层数据报
- 调用一次receive,就得到一个明确的UDP数据报
Content-Type
- 表示 请求的body中的 数据格式
- 提示了接收方 如何解析body中的数据
HTTP中可以携带的数据类型
HTML test/html 浏览器会解析其标签,把标签转换成页面显示 CSS test/css 浏览器会解析其中的 选择器 和 属性 ,并把这里指定的内容应用到页面样式上 JS application/javascript 浏览器通过js引擎解释并执行js中的逻辑 JSON application/json 浏览器不会做任何处理 图片 image/png
image/jpg
浏览器尝试按照图片的二进制格式 解析出来并显示
请求和响应中都会用到这两个header(Content-Length和Content-Type),如果有body,但是没有这两个属性(哪怕只有一个),都认为是非法的/错误的http报文
User-Agent(简称UA)
User-Agent里表示了用户使用的设备的浏览器和操作系统的情况
先讲讲互联网快速发展的早期:
- 最早,互联网类似于报纸杂志,那时候的浏览器只要能显示文本就行了
- 后来在网页中加入了图片
- 后来加入各种样式
- 后来加入了js,实现各种逻辑
- 后来加入了多媒体
由于互联网快速发展,同一个时间段内,有些用户的浏览器版本比较旧,支持的功能少,有些用户浏览器版本更新,支持的功能多
此时企业面对一个问题:
- 如果服务器支持的功能少,可能就打不过竞争对手
- 如果支持功能多,旧版本浏览器的用户可能就展示不了
因此,服务器要根据用户使用的设备进行区分:
- 首先通过UA中的浏览器版本/操作系统版本,区分出当前用户的设备,最多支持哪些特性
- 老的浏览器,返回功能少的网页,正确显示
- 新的浏览器,返回功能多的网页,体验丰富
- 因此程序员就要维护多套代码(不过2025年了,大家使用的浏览器都大差不差)
UA还有另一个用途:可以用来区分用户设备
- windows/mas => PC
- ios/android => 手机
->根据用户的设备,返回不同版本的页面
前端圈子中"响应式编程",通过css中的"媒体查询"功能,能感知到当前窗口的尺寸(宽度)
通过不同的尺寸,设置不同的样式->那么一个页面就可以适配不同的窗口

Referer
- 描述了当前页面的来源,即这个页面是从哪个页面跳转来的
- 如果直接输入URL或者点击收藏栏,打开的页面是没有Referer的
- eg: Referer: https://www.sogou.com/ (从主页跳转到搜索页,搜索页的Referer)
Referer的作用:
在广告系统中,广告是按点击计费的,要统计某个广告,在一定时间内(比如一个月内)一共被点击了多少次
- 搜狗统计,广告主也统计,两边都统计,然后互相核对数字
- 搜狗的统计方式:点击跳转广告时,先访问搜狗的"计费服务器",在从计费服务器跳转到广告页面,同时一次点击记录一个日志
- 广告主服务器也有日志,统计 广告主服务器日志中 的访问次数 就可以了
- 广告主可能会在多个平台投放广告,此时就用Referer来区分请求来源
是否存在一种情况:有人把Referer给改了?
- 例如原本是搜狗的Referer改成了别人的Referer了
- 2014年的时候这种情况非常普遍->会对广告平台造成一定的损失
是谁改的呢?
- 运营商(运营商劫持)
他们有能力劫持吗?
- 包有的老弟:用户上网的时候,HTTP请求都是要经过运营商的路由器/交换机的,此时,通过一些软件,分析数据流量->把一些广告的http数据报进行修改就行了
劫持动机:
- 运营商也有自己的广告平台(运营商和搜狗/百度是竞争关系)
法律不管吗??
- 2014年,互联网还是新鲜东西,很多关于网络的法律条文是不完善的
- 官司还是要打的,大概率能赢,但是中间的过程会很复杂
于是->
- 百度拉着其他广告平台一起对运营商劫持进行技术反制=>于是HTTPS诞生了
- 2015年的时候,百度牵头,其他广告平台跟进,大家一起把广告平台从HTTP->HTTPS
- HTTPS协议能够有效对HTTP数据报进行了加密(Referer也被加密了)
- HTTPS这条路趟平了以后,其他小公司纷纷跟进
- 2025的今天,互联网上找到纯HTTP的网站,已经很难了
Cookie机制
浏览器展示页面的过程中,页面虽然可以通过js来实现一些逻辑,但是js代码无法访问用户的硬盘(文件系统)->即js无法读写你的硬盘
这是浏览器给js戴上的紧箍咒
如果通过js能够随意修改你的硬盘,那不炸了~~
但是实际开发中,有时候还是希望把某些数据保存到本地硬盘的
因此,浏览器引入了Cookie机制
- cookie就是浏览器允许网页在本地硬盘存储数据的一种机制
- 不让网页直接访问文件系统,而是做了一层抽象(包装)
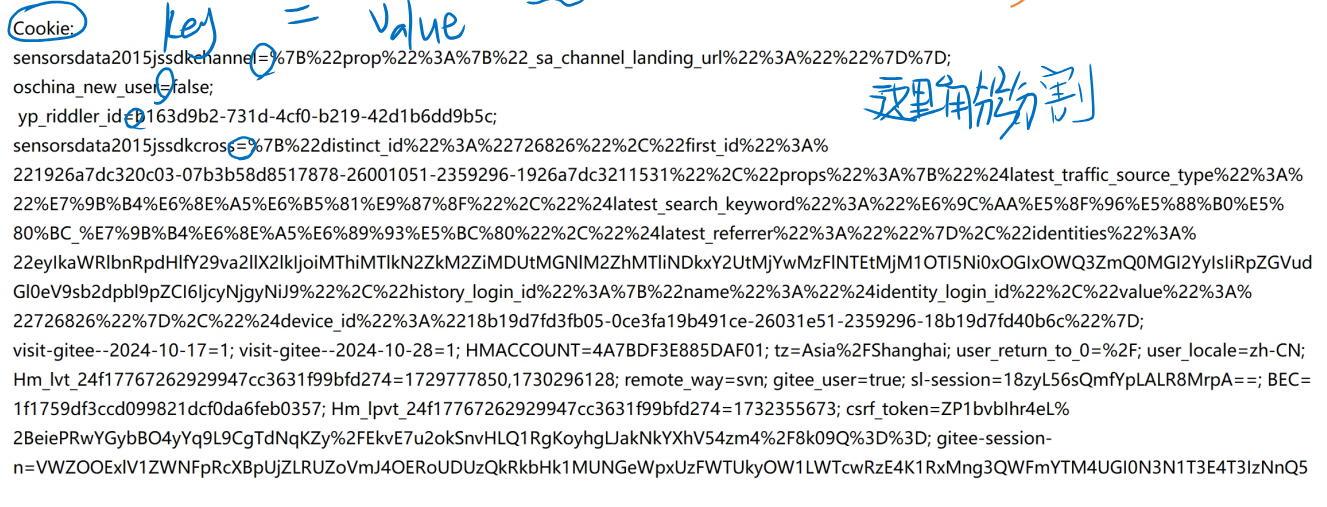
- 浏览器的cookie提供了键值对存储机制(数据以key=value或者key:value的形式存入硬盘)
常见键值对
URL的query string 由程序员自定义 header部分也是键值对 由PFC标准规定 header中Cookie里存的数据也是键值对 由程序员自定义 body是json格式,仍然是键值对 由程序员自定义 这些键值对可以让程序员结合实际情况,基于http,实现更多个性化的功能需求
往服务器中存Cookie的过程:
- 浏览器保存了 执行过程中产生的Cookie之后 (Cookie的键值对内容是由后端开发程序员决定的)
- 在给浏览器发送请求的时候,把这些Cookie键值对 放到请求头(Cookie header)中 ,传输给服务器
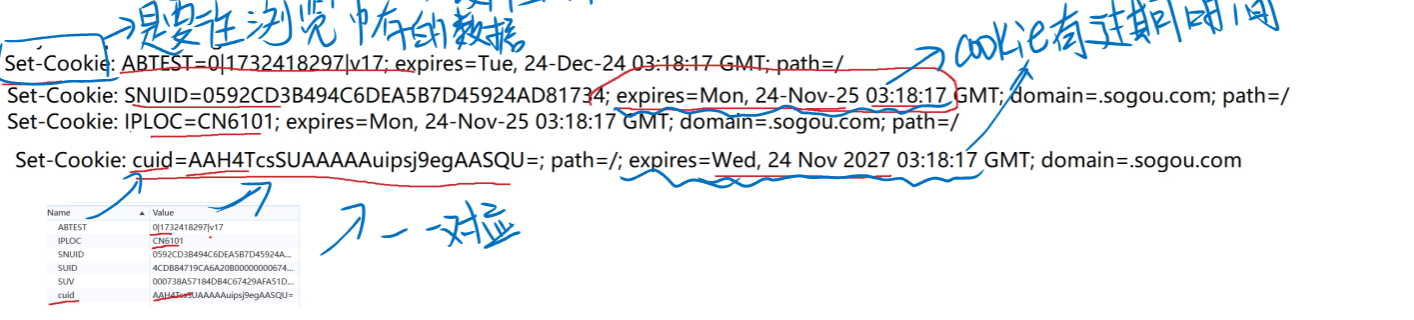
- Set-Cookie:xxxx 往浏览器存数据,xxxx中会包含Cookie的过期时间
Cookie里业务相关的数据都是程序员自定义的
但是有一个典型的场景属于"通用业务"
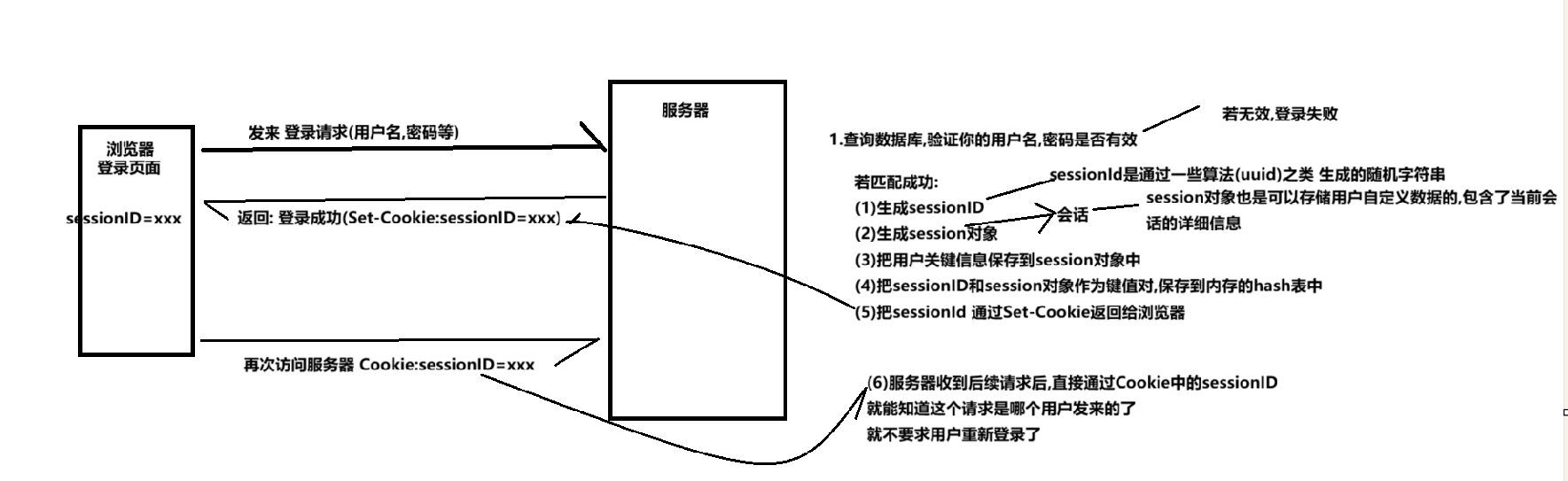
->登录和用户验证
浏览器-服务器之间的联动
区分一下sessionID机制和"记住密码"
- "记住密码"是浏览器自身的行为
Cookie可能会过期,服务器返回Cookie的时候是可以设置有效时间的
如果Cookie中的sessionID过期了,就需要用户重新登录
- 有的网站(例如B站,抖音以娱乐为主),对安全性要求不高,过期时间就长
- 有点网站,对安全性要求很高,过期时间就短
- (比如网银,只要你把页面关闭or几分钟不操作,就会自动过期)
- 必要性:如果你在共用电脑上操作,人离开一下,万一下一个人拿到这个电脑,把你钱转走[狗头]
用户重新登录的时候,是否需要手动输入账号密码,这就是浏览器"记住密码"功能来解决的问题了
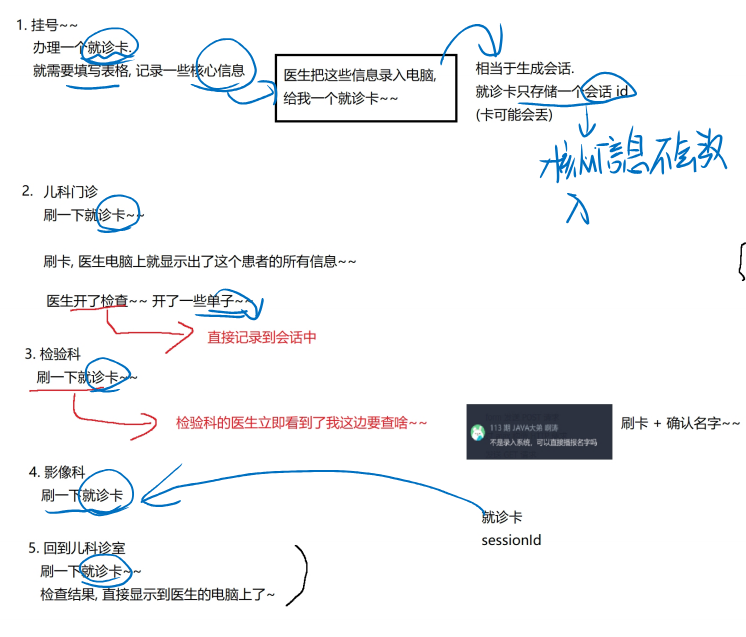
会话和sessionID的作用举个栗子:
END✿✿ヽ(°▽°)ノ✿