Google Landmarks Dataset v2 (GLDv2):500万地标图像的识别与检索基准(数据集概览、下载与使用全流程)
项目地址:https://github.com/cvdfoundation/google-landmark?tab=readme-ov-file
魔塔社区子集:https://www.modelscope.cn/datasets/OmniData/Google_Landmarks_Dataset_v2
arxiv:https://arxiv.org/abs/2004.01804
这个仓库是关于Google Landmarks Dataset v2(GLDv2) 的资源库,主要提供该数据集的下载链接、基线模型、指标计算代码以及相关说明。
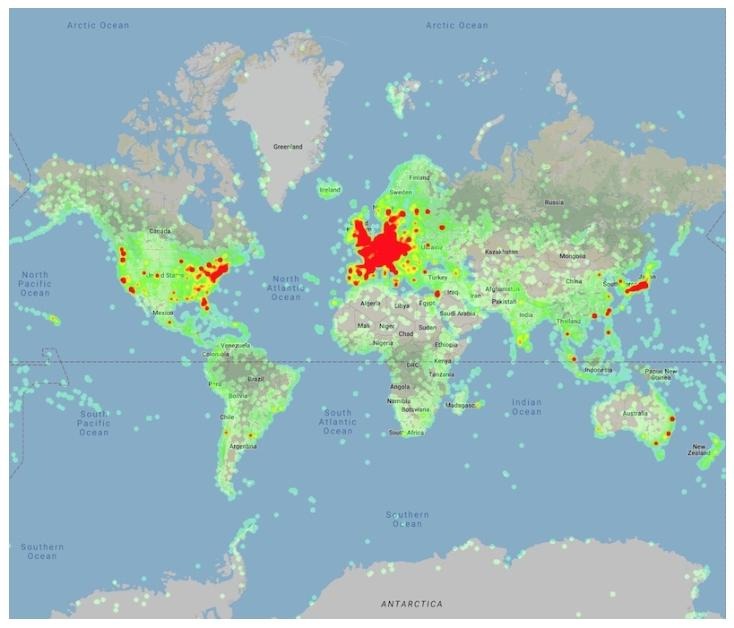
Figure 2: Heatmap of the places in the Google Landmarks Dataset v2.
一、项目概述
1. 数据集概况
- 定位:GLDv2 是谷歌发布的第二个版本地标数据集,包含约 500 万张图像,标注了人造和自然地标的标签,主要用于地标识别和检索任务。
- 版本:当前版本为 2.1,包含多次更新(如 2023 年 5 月新增了层级标签)。
- 关联资源:曾用于 2019 年 Kaggle 的地标识别和检索挑战赛,结果在 CVPR'19 工作坊中讨论,仓库中提供了基于最新 ground-truth 的前 10 名团队成绩。
2. 数据集组成
分为三个子集,每个子集包含图像文件和对应的元数据:
- train 集:4,132,914 张图像,分在 500 个 TAR 文件(每个约 1GB)中,命名为
images_000.tar至images_499.tar。 - index 集:761,757 张图像,分在 100 个 TAR 文件(每个约 850MB)中,命名为
images_000.tar至images_099.tar。 - test 集:117,577 张图像,分在 20 个 TAR 文件(每个约 500MB)中,命名为
images_000.tar至images_019.tar。
Google Landmarks Dataset v2(GLDv2)划分为train、test、index三个子集, 核心是为了适配其两大核心任务 ——“地标识别” 和 “地标检索” 的训练与评估需求 。
- “地标识别”:给定图像,预测其对应的地标 ID
- “地标检索”:给定查询图像,从大规模库中找到同地标图像
| 子集 | 核心作用 | 数据特点 |
|---|---|---|
train | 用于模型训练,让模型学习 “图像→地标特征 / 标签” 的映射关系。 | 包含约 413 万张图像,每张图像均带有landmark_id(地标唯一标识)标注,样本量最大,覆盖的地标类别最广。 |
test | 用于评估模型性能(尤其是 “地标识别” 任务),作为 “未见过的新数据” 检验泛化能力。 | 包含约 11.8 万张图像,不直接提供标注 (需通过recognition_solution_v2.1.csv获取 ground truth),确保评估的客观性(避免模型 “记住” 测试数据)。 |
index | 作为 “地标检索” 任务的 “候选库”(即检索的 “数据库”),用于模拟实际应用中的大规模图库。 | 包含约 76.2 万张图像,带有landmark_id标注,规模介于train和test之间,模拟真实场景中 “从海量图像中检索相似地标” 的需求。 |
-
满足 “训练 - 测试” 的基本逻辑机器学习中,模型不能在训练过的数据上评估(会导致 “过拟合” 误判),因此必须严格区分
train(训练数据)和test(未见过的测试数据)。train提供带标注的样本让模型学习规律,test作为 “全新数据” 检验模型是否真正 “学会”(而非死记硬背)。 -
适配 “检索任务” 的特殊需求地标检索的核心场景是:用户输入一张查询图像(如旅行时拍的某地标),系统从一个大规模图库(如 “全球地标数据库”)中找到同地标图像。
index子集正是模拟这个 “大规模图库”,而test子集中的部分图像会作为 “查询图像”,评估模型从index中检索相似地标的能力(通过retrieval_solution_v2.1.csv提供检索的 ground truth)。
3. 元数据与标签
每个子集提供多种 CSV 格式的元数据文件,包含关键信息:
- 基础信息:图像 ID、URL、landmark_id(地标 ID)等(如
train.csv、index.csv、test.csv)。 - 清洗与归因:如
train_clean.csv(清洗后的图像列表)、train_attribution.csv(图像作者、许可证等信息)。 - 类别与层级标签:如
train_label_to_category.csv(landmark_id 与维基百科类别的映射)、train_label_to_hierarchical.csv(包含层级标签和 “自然 / 人造” 属性)。 - 测试集 ground-truth:如
recognition_solution_v2.1.csv(识别任务答案)、retrieval_solution_v2.1.csv(检索任务答案)。
4. 下载方法
- 直接下载:通过 URL 直接下载 TAR 文件(如 train 集的
https://s3.amazonaws.com/google-landmark/train/images_000.tar)。 - 脚本下载:使用仓库中的
download-dataset.sh脚本,支持并行下载、MD5 校验和自动解压。示例:- 下载 train 集:
mkdir train && cd train && bash ../download-dataset.sh train 499 - 下载 index 集:
mkdir index && cd index && bash ../download-dataset.sh index 99 - 下载 test 集:
mkdir test && cd test && bash ../download-dataset.sh test 19
- 下载 train 集:
5. 相关资源
- 基线模型:提供 ResNet101-ArcFace 基线模型,详见DELF 仓库。
- 指标计算代码:识别和检索任务的指标计算脚本(
compute_recognition_metrics.py、compute_retrieval_metrics.py),位于DELF 仓库。 - 论文引用:使用数据集需引用 CVPR'20 论文和层级标签相关待发表论文(具体格式见仓库)。
6. 版本历史
- 2019 年 4 月:v2.0 发布,包含 train 集。
- 2019 年 5 月:v2.0 补充 test 和 index 集。
- 2019 年 9 月:v2.1 更新 ground-truth,重新计算挑战赛成绩。
- 2023 年 5 月:v2.1 新增地标层级标签。
如需更多细节,可参考仓库的可视化页面或提交 issue 联系维护者。这个仓库是关于Google Landmarks Dataset v2(GLDv2) 的资源库,主要提供该数据集的下载链接、基线模型、指标计算代码以及相关说明。以下是详细介绍:
二、使用项目提供的脚本下载
使用提供的download-dataset.sh脚本下载 Google Landmarks Dataset v2,按照以下步骤操作,脚本会自动完成下载、MD5 校验和文件提取的全流程
1. 脚本功能说明
该脚本用于批量下载数据集的train、test或index子集,支持并行下载以提高效率,且会自动验证文件完整性(通过 MD5 校验和),校验通过后解压文件。
2. 使用前提
- 环境要求:需在支持
bash的环境中运行(如 Linux、macOS 或 Windows 的 WSL)。 - 工具依赖:需安装
curl(用于下载文件)和tar(用于解压文件),确保这两个工具可正常使用。 - 脚本权限:确保
download-dataset.sh具有可执行权限(若没有,可通过chmod +x download-dataset.sh添加)。
3. 核心参数说明
脚本运行时需要传入 2 个参数,格式如下:
bash download-dataset.sh <子集名称> <最大文件索引>- 第一个参数(子集名称):指定要下载的数据集子集,可选值为
train、test、index。 - 第二个参数(最大文件索引):指定该子集的最后一个 TAR 文件的索引(从 0 开始),不同子集对应的值不同:
train集:共 500 个 TAR 文件(images_000.tar至images_499.tar),对应索引为499。test集:共 20 个 TAR 文件(images_000.tar至images_019.tar),对应索引为19。index集:共 100 个 TAR 文件(images_000.tar至images_099.tar),对应索引为99。
4. 具体下载步骤
下载train集(约 500GB)
# 创建并进入train目录(用于存放下载的文件)
mkdir train && cd train
# 运行脚本下载train集(从images_000.tar到images_499.tar)
bash ../download-dataset.sh train 499下载test集(约 10GB)
# 创建并进入test目录
mkdir test && cd test
# 运行脚本下载test集(从images_000.tar到images_019.tar)
bash ../download-dataset.sh test 19下载index集(约 85GB)
# 创建并进入index目录
mkdir index && cd index
# 运行脚本下载index集(从images_000.tar到images_099.tar)
bash ../download-dataset.sh index 995. 脚本执行细节
-
并行下载:脚本默认使用 6 个并行进程(由
NUM_PROC=6控制),可根据网络带宽修改该值(例如改为NUM_PROC=10增加并行数,或NUM_PROC=2减少并行数)。 -
文件校验:
- 脚本会同时下载每个 TAR 文件(如
images_000.tar)和对应的 MD5 校验文件(如md5.images_000.txt)。 - 对下载的 TAR 文件计算 MD5 值,并与校验文件中的值对比,确保文件未损坏。
- 若校验通过,自动执行
tar -xf解压文件;若不通过,会输出错误提示(需重新下载)。
- 脚本会同时下载每个 TAR 文件(如
-
文件存储:解压后的图片会按照固定目录结构存放(如
0/1/2/0123456789abcdef.jpg,其中0123456789abcdef为图片 ID)。
项目提供的脚本download-dataset.sh
#!/bin/bash
# Copyright 2019 David Bishai.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.# Number of processes to run in parallel.
NUM_PROC=6# Dataset split to download.
# Options: train, test, index.
SPLIT=$1# Inclusive upper limit for file downloads. Should be set according to split:
# train --> 499.
# test --> 19.
# index --> 99.
N=$2download_check_and_extract() {local i=$1images_file_name=images_$1.tarimages_md5_file_name=md5.images_$1.txtimages_tar_url=https://s3.amazonaws.com/google-landmark/$SPLIT/$images_file_nameimages_md5_url=https://s3.amazonaws.com/google-landmark/md5sum/$SPLIT/$images_md5_file_nameecho "Downloading $images_file_name and its md5sum..."curl -Os $images_tar_url > /dev/nullcurl -Os $images_md5_url > /dev/nullif [[ "$OSTYPE" == "linux-gnu" || "$OSTYPE" == "linux" ]]; thenimages_md5="$(md5sum "$images_file_name")"elif [[ "$OSTYPE" == "darwin"* ]]; thenimages_md5="$(md5 -r "$images_file_name")"fimd5_1="$(cut -d' ' -f1<<<"$images_md5")"md5_2="$(cut -d' ' -f1<<<cat "$images_md5_file_name")"if [[ "$md5_1" != "" && "$md5_1" = "$md5_2" ]]; thentar -xf ./$images_file_nameecho "$images_file_name extracted!"elseecho "MD5 checksum for $images_file_name did not match checksum in $images_md5_file_name"fi
}for i in $(seq 0 $NUM_PROC $N); doupper=$(expr $i + $NUM_PROC - 1)limit=$(($upper>$N?$N:$upper))for j in $(seq -f "%03g" $i $limit); do download_check_and_extract "$j" & donewait
done6. 注意事项
- 存储空间:确保目标目录有足够空间(
train集约 500GB,test集约 10GB,index集约 85GB)。 - 网络稳定性:下载过程中若网络中断,需重新运行脚本(已下载的完整文件会被校验通过,无需重复下载)。
- 权限问题:若解压时提示权限不足,需确保当前用户对目标目录有写入权限。

Figure 7: Sample classes from the training set (1 of 2).
三、魔塔社区Google_Landmarks_Dataset_v2
1. 简介
GLDv2 的train集包含约 413 万张图像,总大小约 500GB,平均单张图像大小约 120KB-2MB(视分辨率而定)。
ModelScope 平台上由 OmniData 提供的Google_Landmarks_Dataset_v2是谷歌地标数据集 v2 的社区分享版本,数据集大小仅3.05GB,包含从原版中筛选的地标相关图像,支持计算机视觉领域的地标识别、图像检索等任务,提供直接下载和基于 ModelScope 平台的加载调用方式,但页面未明确提及图像数量、完整标注信息及具体筛选规则,需用户下载后进一步确认细节。
魔塔社区Google_Landmarks_Dataset_v2仅包含train/index/test各一项
| 信息类别 | 具体内容 |
|---|---|
| 数据集名称 | Google_Landmarks_Dataset_v2 |
| 提供方 | OmniData(ModelScope 社区用户 / 组织) |
| 关联原版 | Google 官方发布的 Google Landmarks Dataset v2(GLDv2) |
| 数据集体积 | 3.05GB(远小于原版 train 集的 500GB) |
| 存储平台 | ModelScope(阿里达摩院旗下开源模型与数据社区) |
| 数据格式 | 以图像文件为主(页面未明确具体格式,推测为 JPG/PNG 等常见图像格式) |
2. 关键信息缺失点
- 图像数量未明确:页面未标注该版本包含的具体图像张数(原版 train 集为 413 万张),无法判断样本覆盖度。
- 标注信息缺失:未提及是否包含原版的核心标注(如
landmark_id、类别映射、层级标签等),若缺少标注,仅能用于无监督任务或需用户自行标注。 - 筛选规则不透明:未说明图像的筛选标准(如是否为原版的子集、分辨率是否压缩、是否剔除低质量样本等),可能影响数据适用性(如低分辨率图像不适合细节依赖型任务)。
