【源码深度 第1篇】LinkedList:双向链表的设计与实现

文章目录
- 前言
- 一、热身一下:走进链表
- 二、源码解析
- 1.结构分析
- 2.核心方法分析
- 头插法
- 尾插法
- 拆链
- 获取节点
- 3.常用方法
- 添加操作
- 删除操作
- 获取操作
- 迭代器实现
- 总结
前言
你说你会Java,那我问你:“ArrayList和LinkedList的区别是什么?”,这个问题有没有勾起你当时准备面试的场景呢?
与其在那死记硬背,不如和我一起共同分析一下,彻底消化它。
LinkedList是我们日常开发中常用的数据结构之一,同时也是面试中的高频考点。下面我将围绕其底层实现、关键方法源码、设计思想以及性能特性进行详细讲解,帮助你真正“吃透”LinkedList!
一、热身一下:走进链表
链表是数据元素的线性集合,元素的线性顺序不是由它们在内存中的物理地址给出的。它是由一组节点组成的数据结构,每个元素指向下一个元素,这些节点一起,表示线性序列。
最简单的链表就是每个节点包含数据(data)和指向下一个节点的指针(next),如下图:
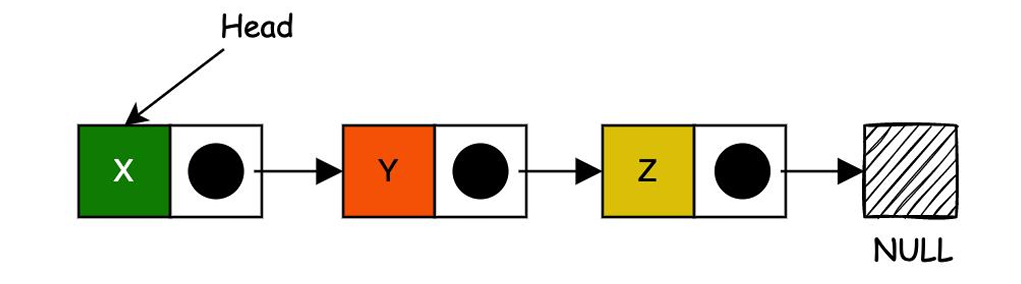
这样一看果如其名,是拿链子连接起来的。但是恰巧这种连接方式,使得其可以不需要扩容,新增节点就链接呗,不要的节点就解开链子,删除呗。
链表分为单向链表(就是上图)、双向链表(包含数据域、指向前一个节点的指针、指向后一个节点的指针)、循环链表(单向链表的末尾节点指向头节点)。
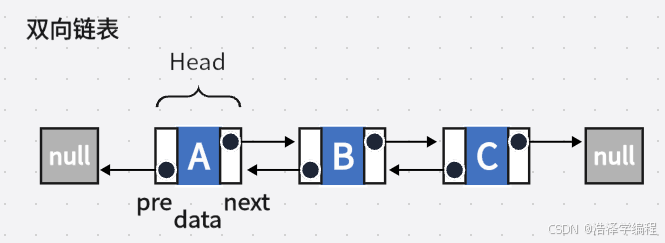
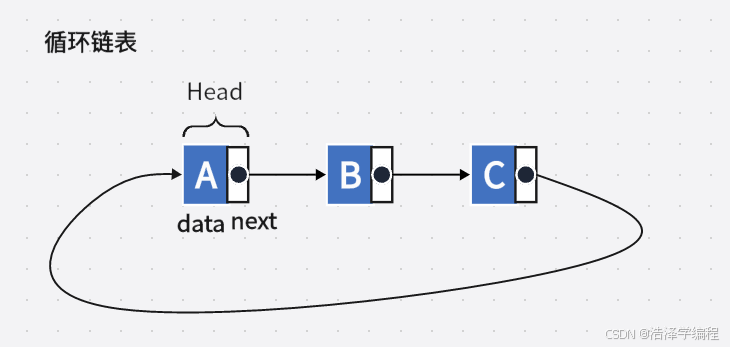
而LinkedList就是双向链表实现,它实现了以下两个核心接口:
List<E>:表示它是一个有序集合,支持索引访问。Deque<E>:表示它同时也是一个双端队列,支持在头部和尾部高效地插入和删除元素。
这里我们注重链表的讲解,所以暂时忽略Deque接口,后续会有讲解队列的文章,之后会再补充。
二、源码解析
1.结构分析
提取了源码中链表的主要结构如下(大家在学习过程中一定要去进入源码看一下哦):
size:链表的实际长度。first:指向链表头节点,链表为空,则为null。last:指向链表尾节点,链表为空,则为null。Class Node<E>:链表节点的实际定义,链表的核心。- E item:数据域,当前节点存储的元素。
- Node< E > next:指向下一个节点。
- Node< E > prev:指向前一个节点。
- 构造函数的参数对应:前一个节点prev、存储元素element、下一个节点next。
public class LinkedList<E>extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{/*** 链表实际长度:增加一个元素,size++;移除一个元素就size--*/transient int size = 0;/*** 指向链表头节点,链表为空,则为null*/transient Node<E> first;/*** 指向链表尾节点,链表为空,则为null*/transient Node<E> last;/*** 节点定义*/private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
}
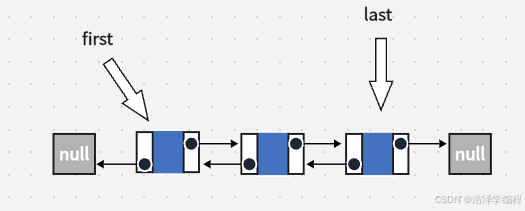
LinkedList代码和结构图一起看,很好理解,发现就是这么简单明了的结构。从这也可以看出,LinkedList 没有容量限制,本质就是一个链式结构,动态增长,size属性只是存储其当前具有的节点数,并不是限制其的容量大小。
2.核心方法分析
接下来我们逐个分析几个常用的核心方法:头插法、尾插法、拆链、获取节点。
头插法
- 作用:插入元素e变成了新头节点(first),旧头节点变成了新头节点的下一个节点,即first.next。
- 若旧头节点为null,说明链表为空,则头节点、尾节点都指向新节点。
- 时间复杂度O(1):就涉及一个节点的插入,很好理解,时间复杂度为O(1)。
- 头插法头节点为null时,即链表为空,直接first、last都指向新插入的节点;不为空时的头插法,继续往下看我的详细讲解。
private void linkFirst(E e) {final Node<E> f = first;final Node<E> newNode = new Node<>(null, e, f);first = newNode;if (f == null)last = newNode;elsef.prev = newNode;size++;modCount++;}
头插法图解故事(谋权篡位):
在LinkedList王国里,秩序森严,结构分明。这个王国由一个个叫作“Node”的子民组成,每个Node子民都严格遵守着两条最重要的法则:
- 记住谁在你前面(
prev,是当前子民的前面担保人) - 记住谁在你后面(
next,是当前子民所监管人)
整个王国的权力结构像一条环环相扣的锁链,井然有序。而维系这条锁链起点的,是一根拥有无上权力的法杖——名叫 first。
first法杖并不指向某个具体的人,它只指向当前王国的第一个子民,也就是“老大”。谁被法杖选中,谁就站在链条的最前端,享有最高的地位。而当前的老大,我们也叫他 first。
王国一直这么平稳地运行着,直到有一天,一个名叫 e 的外来能人来到了这个国度。他野心勃勃,目光直接就锁定了那根象征着权力的 first法杖。他的目标非常明确:谋权篡位,成为新的老大!
但是,直接去抢法杖是行不通的,LinkedList王国的规则不容破坏。e 必须按照王国的规矩来,将自己变成一个合格的Node子民,然后巧妙地利用规则,登上顶峰。
于是,e 开始了他的篡位计划:
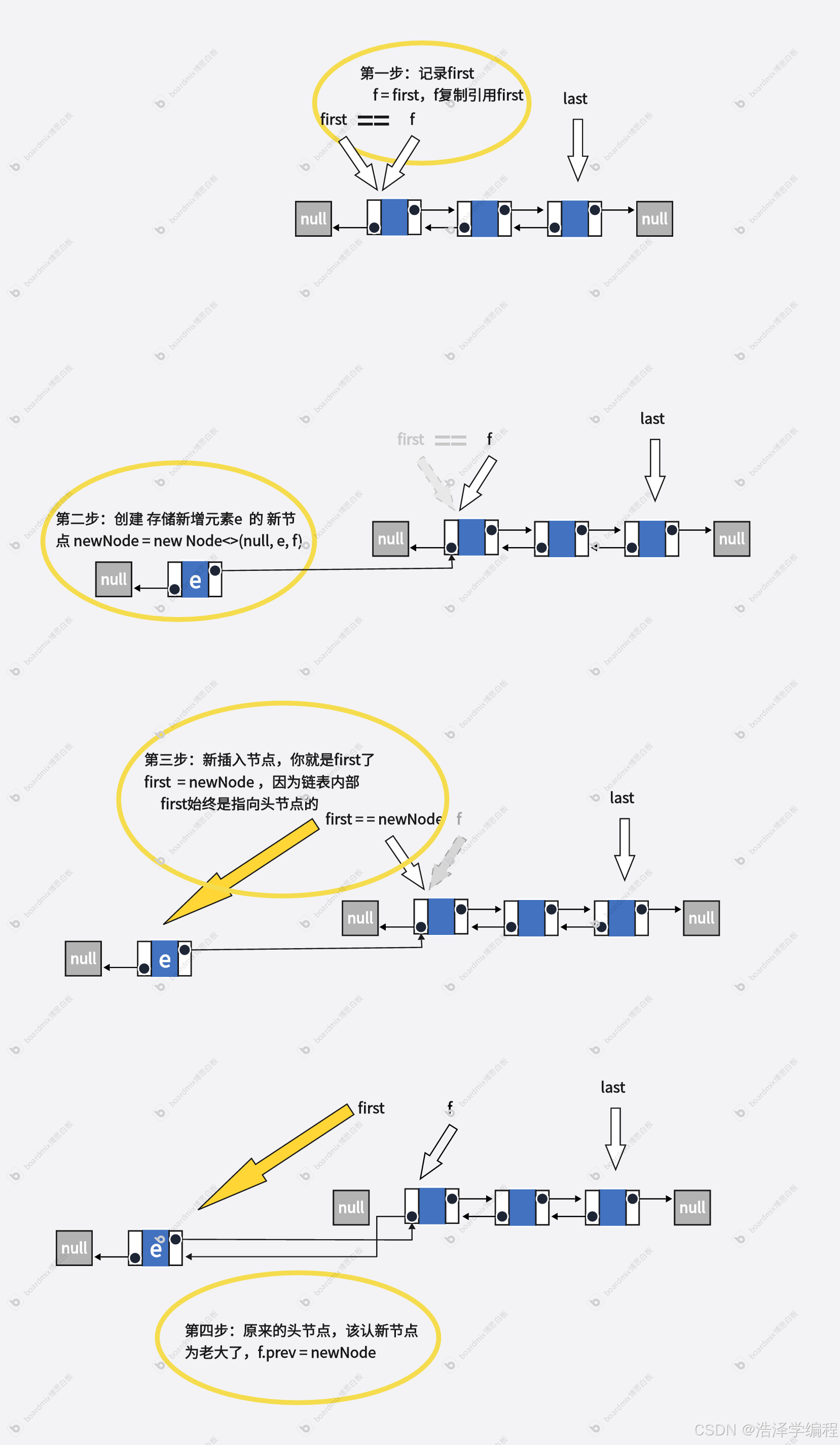
- 第一步:锁定目标,狸猫换太子
e是个极其谨慎的阴谋家。他知道,权力核心 first法杖的指向瞬息万变。在他动手的这一刻,必须确保万无一失。于是,他做的第一件事并不是直接冲上去,而是使用能千变万化的多变鸟f去悄无声息地接近法杖,默默地记下了它当前指向的人的信息——现在的老大first,并复刻了他的所有资料,和它融为一体,f成了原老大(final Node<E> f = first;)。 - 第二步:改头换面
f回来后,e自己摇身一变,使用秘法根据f记录的资料将自己包装成了一个崭新的Node子民,并且将自己后面所监管人next记录为f的信息(也就是原老大的信息)。现在,他不再只是e,而是newNode(final Node<E> newNode = new Node<>(null, e, f);)。 - 第三步:夺取法杖(改变权力指向)
一切就绪后,newNode带着f偷偷跑到了象征权力的 first法杖面前,说道:“看清楚了!现在,我,newNode,才是站在最前面的人!你应当指向我!”。法杖 first 看到旁边f(“原老大”)感知到了王国结构的变化:它发现,原本指向 原老大(即 f)的链条前方,确实凭空多出了一个新的节点newNode,而且这个newNode的“后面”明确地指向着原老大f。但是法杖并不知道实情,就被蒙骗,将权力指向了newNode(first = newNode;)。 - 第四步:政变完成,悄无声息
成为新老大first后,newNode就立马让f修改前面担保人为他这个新老大(f.prev = newNode;),稳当地篡位成功。f在完成任务后便功成身退,他所记录的那个瞬间的“老老大”形象,也随着newNode的成功上位而成为了永恒的历史记录。LinkedList王国依旧秩序井然,链条完整,只不过权力的最顶端,已经换了一个新人。
尾插法
- 作用:插入元素e变成了新末尾节点(last),旧头节点变成了新末尾节点的上一个节点,即first.next。
- 若旧头节点为null,说明链表为空,则头节点、尾节点都指向新节点。
- 时间复杂度O(1):就涉及一个节点的插入,很好理解,时间复杂度为O(1)。
- 具体逻辑其实就可以看作是头插法,last就看作是“head”,因为是双向链表,从末尾起始看,last就是“头节点”。上面头插法弄懂后,自然就明白尾插法。
void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)first = newNode;elsel.next = newNode;size++;modCount++;}
拆链
- 将当前节点前后节点相连,并返回该节点的data。
- 时间复杂度O(1)
unlink(Node<E> x) {// assert x != null;final E element = x.item;final Node<E> next = x.next;final Node<E> prev = x.prev;if (prev == null) {first = next;} else {prev.next = next;x.prev = null;}if (next == null) {last = prev;} else {next.prev = prev;x.next = null;}x.item = null;size--;modCount++;return element;}
操作简单,直接上故事理解(罪民流放):
让我们把目光从权力的顶峰移开,聚焦于LinkedList王国的内部秩序。
整个王国的稳定就依赖于这些权力链的完整。然而,并不是所有子民都能永远留在链条上。当一个子民(我们叫他 x)犯了重罪他就必须被从链条中“unlink”(解除链接)——也就是流放。
但流放绝非简单地把他扔出去那么简单,否则会撕裂整个王国的结构,造成链条断裂。
- 第一步:审判
正式宣布对他的判决:“x,你将被从王国链条中移除。”
拿出两份卷宗记录他的担保人和所监护人:
1.《前面担保人档案》:查清了是谁把 x 引入链条的,并记录下这个人的名字:final Node<E> prev = x.prev;
2.《后面所监护人档案》:查清了 x 负责引荐监护的是谁,并记录下这个名字:final Node<E> next = x.next;
现在,掌握了所有关键信息:x、他前面的子民(prev)、他后面的子民(next),既然要给他流放,那么肯定要更新prev、next的旧关系了。于是就将prev、next、x召在一起。 - 第二步:断绝前面担保人关系
对prev 说:“听着,你当初担保的人 x 出问题了。现在,你需要跳过x,直接对你后面的人(next)负责。”
于是,强制prev 修改了他的“next纽带”,让它从指向 x,改为直接指向 x 后面的 next。(prev.next = next;),并强制将x的指向担保人清除(x.pre = null;)。 - 第三步:移交所监护人关系
继续对next 说:“听着,当初引荐你加入的 x 已经不可靠了。现在,你需要跳过x,直接承认你前面的人(prev)为你的新担保人。”
于是,强制 next修改了他的“prev纽带”,让它从指向 x,改为直接指向 x前面的 prev。(next.prev = prev;),并强制将x的指向所监护人清除(x.next = null;)。 - 第四步:彻底流放
现在,整个王国链条已经完成了自我修复。prev 和 next已经直接相连,x变成了一个孤岛,虽然他还存在,但已经没有任何官方纽带指向他,他也无法再影响链条。
但工作还没完。为了确保万无一失,需要再次来到 x 面前,执行最后的净化仪式:将它记忆有关信息全部抹除(x.data = null;),让他彻底变成一个无用之人。
(注:在Java的LinkedList实现中,最后一步x.data = null是可选的优化,旨在帮助GC更早回收内存,但核心的unlink逻辑前三步已经完成。)
源码小细节
- 及时断开引用:将被删除节点的 data、next、prev 设置为 null
- 帮助垃圾回收:防止内存泄漏,让 GC 能及时回收无用对象
- 逻辑分离:分别处理前驱节点和后继节点的连接操作
- 职责单一:专注于节点 unlink 操作,不包含其他业务逻辑
- 易于维护:代码结构简单,便于理解和后续维护
获取节点
- 作用:获取第index处(从0开始)的节点数据。
- 时间复杂度O(n)
Node<E> node(int index) {// assert isElementIndex(index);if (index < (size >> 1)) {Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}}
操作简单,直接实质性讲诉:
- LinkedList中有size属性存储实际节点数量。
- 首先根据index、size判断,所查找位置的节点在链表的前半段还是后半段。
- 在前半段就从头节点开始往后查找节点,反之末尾节点开始往前查找。
- 查找到后直接返回当前节点数据域。
源码小细节
- 双向遍历优化,如果索引在前半部分,从头节点开始向后遍历;如果在后半部分,从尾节点开始向前遍历。
3.常用方法
实际上我们常用的LinkedList的操作是add、addFirst、addLast、remove、get等。我们现在来解释一下。
添加操作
// 就是调用的头插法
public void addFirst(E e) {linkFirst(e);}// 就是调用的尾插法public void addLast(E e) {linkLast(e);}
// 就是调用的尾插法
public boolean add(E e) {linkLast(e);return true;}
删除操作
- 很显然,从头节点开始,往后遍历找到要删除的对象,然后调用unlink操作。
- o == null
- 对于 null 元素:使用 == 比较(引用比较),不能使用 o.equals() 方法进行比较。因为对 null 调用任何方法都会抛出 NullPointerException
- 对于非 null 元素:使用 equals() 方法比较(值比较)
public boolean remove(Object o) {if (o == null) {for (Node<E> x = first; x != null; x = x.next) {if (x.item == null) {unlink(x);return true;}}} else {for (Node<E> x = first; x != null; x = x.next) {if (o.equals(x.item)) {unlink(x);return true;}}}return false;}
获取操作
// 就是调用的获取节点操作
public E get(int index) {// 大家自己去看一下源码,就是index是否合法checkElementIndex(index);return node(index).item;}private void checkElementIndex(int index) {if (!isElementIndex(index))throw new IndexOutOfBoundsException(outOfBoundsMsg(index));}private boolean isElementIndex(int index) {return index >= 0 && index < size;}
迭代器实现
下面是LinkedList迭代器的实现源码。
这里为什么将迭代器提出来讲诉呢,因为在上面核心方法的讲诉中,不知道大家发现其源码中都有个modCount属性的操作
(modCount++ )。这里是我想跟大家讲诉的LinkedList中的快速失败机制(fail-fast),其实像ArrayList等都有,这里我提前讲解一下。也帮大家扩展一下知识,其实这也是我在阅读源码过程中发现,然后去追踪了一下。可以先不要详细看下面源码,就大致知道下面源码中有出现的expectedModCount、modCount属性。然后直接看我的讲解去理解,然后再回头去源码中看,不限于我下面粘贴的部分。
public ListIterator<E> listIterator(int index) {checkPositionIndex(index);return new ListItr(index);}private class ListItr implements ListIterator<E> {private Node<E> lastReturned;private Node<E> next;private int nextIndex;private int expectedModCount = modCount;ListItr(int index) {// assert isPositionIndex(index);next = (index == size) ? null : node(index);nextIndex = index;}public boolean hasNext() {return nextIndex < size;}public E next() {checkForComodification();if (!hasNext())throw new NoSuchElementException();lastReturned = next;next = next.next;nextIndex++;return lastReturned.item;}public boolean hasPrevious() {return nextIndex > 0;}public E previous() {checkForComodification();if (!hasPrevious())throw new NoSuchElementException();lastReturned = next = (next == null) ? last : next.prev;nextIndex--;return lastReturned.item;}public int nextIndex() {return nextIndex;}public int previousIndex() {return nextIndex - 1;}public void remove() {checkForComodification();if (lastReturned == null)throw new IllegalStateException();Node<E> lastNext = lastReturned.next;unlink(lastReturned);if (next == lastReturned)next = lastNext;elsenextIndex--;lastReturned = null;expectedModCount++;}public void set(E e) {if (lastReturned == null)throw new IllegalStateException();checkForComodification();lastReturned.item = e;}public void add(E e) {checkForComodification();lastReturned = null;if (next == null)linkLast(e);elselinkBefore(e, next);nextIndex++;expectedModCount++;}public void forEachRemaining(Consumer<? super E> action) {Objects.requireNonNull(action);while (modCount == expectedModCount && nextIndex < size) {action.accept(next.item);lastReturned = next;next = next.next;nextIndex++;}checkForComodification();}final void checkForComodification() {if (modCount != expectedModCount)throw new ConcurrentModificationException();}}
快速失败工作原理:
- 初始化:创建迭代器时,将当前 modCount 值保存到 expectedModCount。
(private int expectedModCount = modCount;) - 检查:每次迭代操作前调用 checkForComodification() 方法。
(上面源码中可以看到在next、set、remove等方式中都会调用checkForComodification()) - 检测:比较 modCount 和 expectedModCount 是否相等。
- 失败:如果不相等(说明集合被并发修改),抛出 ConcurrentModificationException。
(if (modCount != expectedModCount) throw new ConcurrentModificationException();)
作用:确保迭代过程中集合结构未被修改,保证数据一致性。这种机制虽然不能保证100%检测到并发修改,但能在大多数情况下及时发现并防止潜在的错误操作。(LinkedList虽然不是线程安全容器,但是会尽力防止并发修改导致的错误)
简单梳理:
作为初步接触看源码学习的小白们,可能在看上面迭代器源码的时候也很迷惑:“为什么没见到 LinkedList 里有 iterator() 方法?我记得我平常使用就直接调用 iterator() 就获取了。怎么 LinkedList 的源码中突然蹦出个public ListIterator<E> listIterator(int index)方法就是它的迭代器实现?”
那么这里我就给大家梳理一下这个调用链:
- LinkedList实例使用
iterator()方法 → 使用AbstractSequentialList.iterator()(LinkedList继承AbstractSequentialList而来)。 AbstractSequentialList.iterator()方法中 → 调用了listIterator(0),但AbstractSequentialList.listIterator(int index)是 抽象方法(无实现),依赖子类实现。LinkedList.listIterator(int index)→ 实现了这个抽象方法, 创建逻辑。所以 JVM 直接调用 LinkedList的版本。
总结:LinkedList调用 iterator()时,使用的是 AbstractSequentialList.iterator()的默认实现,而它调用的 listIterator(0)是抽象方法,编译时检查子类是否实现,运行时JVM动态绑定到 LinkedList的具体版本。
补充LinkedList的迭代使用:
(1)增强for循环
LinkedList<String> list = new LinkedList<>();
list.add("A");
list.add("B");
list.add("C");for (String item : list) {System.out.println(item);
}
(2) Iterator迭代器
LinkedList<String> list = new LinkedList<>();
// ... 添加元素Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {String item = iterator.next();System.out.println(item);
}
(3)ListIterator双向迭代
LinkedList<String> list = new LinkedList<>();
// ... 添加元素// 也可使用listIterator(int index): 返回从指定索引开始的 ListItr
ListIterator<String> listIterator = list.listIterator();
// 正向遍历
while (listIterator.hasNext()) {String item = listIterator.next();System.out.println(item);
}// 反向遍历
while (listIterator.hasPrevious()) {String item = listIterator.previous();System.out.println(item);
}(4)降序迭代器
LinkedList<String> list = new LinkedList<>();
// ... 添加元素Iterator<String> descendingIterator = list.descendingIterator();
while (descendingIterator.hasNext()) {String item = descendingIterator.next();System.out.println(item);
}
总结
- LinkedList可能很多时候我们觉得很简单的一个数据结构实现,但是仔细研究一番,会有很多小细节是值得我们悄悄埋在思想中的,从而不断地丰富自己、扩展自己。
- 对于大多数小白可能都存在着阅读源码的困难,那我们就从简单的开始、从常用的出发。本文仅是我作为菜鸟级别的开发者视角,对LinkedList的一些理解,如有不足、不正确的地方,欢迎大家指正交流。
- 阅读源码的时候,大家一定不要害怕,心里就感觉是个很难的事情。并且我们阅读源码不是为了背诵知识点,是静下心来理解,这样你会发现有些东西以及扎根在你的脑海中了。
- 阅读源码小技巧:有什么不懂、疑问,就直接问AI、检索。把自己的疑惑解决了,理解的更深。源码阅读过程中,可能对一些基础薄弱的同学来说,方法跳来跳去,不一定是这个类实现的,可能用的父类等等。某个方法到底调用的是继承链中哪个实现,其实这些都可以问AI,把你的问题暴露出来,打破沙锅问到底,不断地去补充自己。