REFRAG技术详解:如何通过压缩让RAG处理速度提升30倍
RAG(检索增强生成)现在基本成了处理长文档的标准流程,但是它问题也很明显:把检索到的所有文本段落统统塞进LLM,这样会导致token数量爆炸,处理速度慢不说,还费钱。
meta提出了一个新的方案REFRAG:与其让LLM处理成千上万个token,不如先用轻量级编码器(比如RoBERTa)把每个固定大小的文本块压缩成单个向量,再投影到LLM的token嵌入空间。
他在论文中说可以提速30倍,我们来看看是怎么做的:
输入序列长度大幅缩短,每个文本块变成一个向量而不是几十个token。计算可以重用,块嵌入在检索阶段就能预计算好,避免重复编码。注意力机制变得更稀疏,LLM现在只需要关注块级别的信息,而不是每个token。
更有意思的是,REFRAG保留了自回归解码的灵活性。它可以在上下文的任意位置进行压缩,通过一个学习策略将压缩嵌入和真实token嵌入混合使用。在实际应用中,基于强化学习的选择策略会挑选少数"重要"块展开为完整token序列,其他块继续保持压缩状态。这和传统RAG形成鲜明对比——后者会把每个检索段落的每个token都完整输入解码器,在无关或冗余文本上浪费大量计算资源。
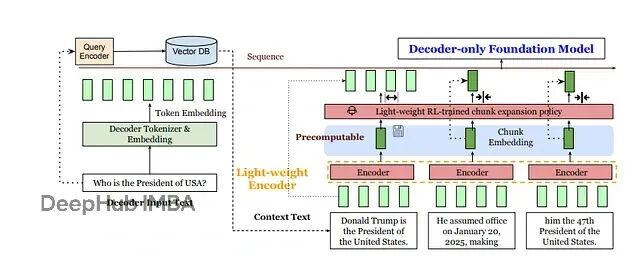
REFRAG的整体流程非常好理解。检索到的上下文先被拆分成固定大小的块,送入轻量编码器;强化学习策略决定哪些块需要展开为完整token;最后解码器接收查询token和块嵌入的混合输入。
技术架构剖析
REFRAG模型结合了decoder-only LLM(LLaMA、GPT这类)和轻量级编码器(RoBERTa)。给定查询(token x1…xq)和检索上下文(xq+1…xT),系统将上下文拆分为L个大小为k的块。编码器处理每个块Ci生成向量ci = M_enc(Ci),线性投影层φ随后将每个ci映射到解码器嵌入空间,产生与词向量同维度的向量ei^(enc)。
解码器输入变为原始查询嵌入{e1, …, eq}加上投影块嵌入集合{e1^enc, …, eL^enc}。效果就是上下文被"压缩"了:s个上下文token变成L=s/k个嵌入。Lin等人的实验表明,解码器输入大约减少k倍。
一个强化学习策略(小型神经网络)接着动态选择部分块,将其完整token嵌入用来替代单向量形式。这种"选择性展开"只把最关键的文本注入解码器,其余部分维持压缩状态。最终结果是内存和注意力中的嵌入数量显著减少,生成速度明显提升。
工作流程解析
REFRAG系统的实际运行过程包含六个主要步骤:
检索阶段使用标准检索器(FAISS索引或DRAGON+)从大型语料库获取查询的top-K相关段落,和常规RAG没什么区别。每个段落被切分为固定长度块,通常16-32个。
块编码环节将每个块送入轻量编码器。一般取[CLS]或池化输出作为块向量,这些向量可以预计算或缓存来提升效率。
投影步骤通过可学习线性层将块向量映射到LLM的token嵌入空间(维度d_emb)。投影后每个块用一个d_emb维嵌入表示,解码器可以像处理普通token一样注意这些块向量。
策略感知部分用强化学习训练的策略网络检查所有块嵌入(可能包括查询),选择一个子集(比如25%)进行展开。未选中的块保持单一嵌入形式。策略训练目标是最大化答案质量,使用负的下一token困惑度作为奖励信号。
展开操作针对策略选择的每个块,将其单一嵌入替换为原始token嵌入序列,需要把这些token嵌入传入解码器。
解码生成最后,解码器LLM接收混合序列:查询token + 部分块嵌入 + 展开token。它正常应用自注意和交叉注意,但由于许多块以单一嵌入形式存在,输入序列大大缩短,LLM随后自回归生成答案。
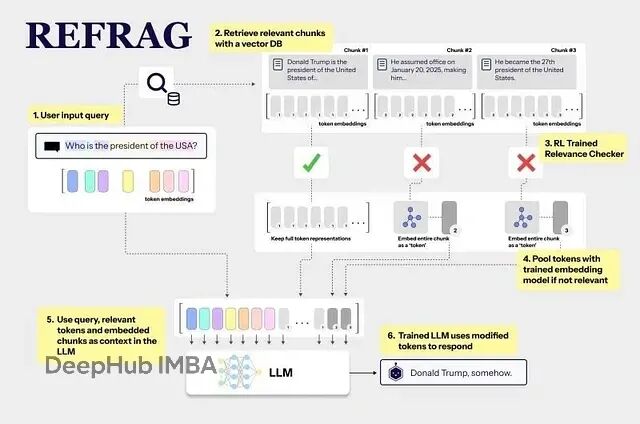
也就是说REFRAG压缩上下文块来减小输入大小,智能选择哪些块真正需要完整token细节,然后展开这少数几个。这套流程在实际应用中效果相当显著:16倍压缩率(k=16)下,REFRAG的首token时间(time-to-first-token)比完整上下文的基线LLaMA快约16.5倍,准确性几乎没有损失。
下面是个简化的PyTorch实现示例,展示如何为文档QA任务构建REFRAG核心逻辑。这里用Hugging Face Transformers来编码上下文块、投影向量、并通过
inputs_embeds
送入因果LM。这只是概念验证,完整REFRAG系统需要按上述方法训练编码器/投影器和强化学习策略。
import torch
from transformers import AutoTokenizer, AutoModel, AutoModelForCausalLM # Load models (small examples for illustration)
encoder_tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
encoder_model = AutoModel.from_pretrained("bert-base-uncased")
decoder_tokenizer = AutoTokenizer.from_pretrained("gpt2")
decoder_model = AutoModelForCausalLM.from_pretrained("gpt2") # Example retrieved passages (context) for a query
context_docs = [ "Albert Einstein developed the theory of relativity in 1905.", "He received the Nobel Prize in 1921 for his services to theoretical physics.", "Later, he introduced the equation E = mc^2 in 1905."
] # 1. Encode each chunk into a vector (CLS token embedding)
chunk_embeddings = []
for doc in context_docs: inputs = encoder_tokenizer(doc, return_tensors="pt", truncation=True, max_length=128) with torch.no_grad(): outputs = encoder_model(**inputs) cls_vec = outputs.last_hidden_state[:, 0, :] # [CLS] token embedding chunk_embeddings.append(cls_vec) # shape [1, hidden_size] # 2. Project chunk embeddings to decoder embedding size
proj = torch.nn.Linear(chunk_embeddings[0].size(-1), decoder_model.config.n_embd)
projected_chunks = [proj(vec) for vec in chunk_embeddings] # list of [1, n_embd] # 3. Prepare query tokens and embeddings
query = "Who won the Nobel Prize for physics in 1921?"
q_inputs = decoder_tokenizer(query, return_tensors="pt")
with torch.no_grad(): q_embeds = decoder_model.transformer.wte(q_inputs["input_ids"]) # [1, len_q, n_embd] # 4. Combine query embeddings and projected chunk embeddings
# (Here we pretend *no* RL expansion: use all chunks as embeddings.)
combined_embeds = torch.cat([q_embeds] + projected_chunks, dim=1) # [1, total_len, n_embd] # 5. Generate answer with the decoder using inputs_embeds
generated = decoder_model.generate(inputs_embeds=combined_embeds, max_length=50) print(decoder_tokenizer.decode(generated[0], skip_special_tokens=True))
代码逻辑很直接:用BERT编码器压缩每个段落,线性层映射到GPT-2嵌入维度,调用
generate(..., inputs_embeds=...)
让GPT-2处理这些向量。LLM把这些向量当作特殊"伪token"处理。在完整REFRAG设置中,你需要用强化学习策略选择的实际token嵌入来替换或增强
projected_chunks
。
核心组件详解
检索器部分通常使用稠密检索器或向量索引(FAISS)从语料库获取K个相关段落。REFRAG不改变这个步骤,检索文本的方式和RAG一样。Lin等人在Wikipedia/CommonCrawl(4亿段落)上使用DRAGON+稠密检索器。
编码器采用轻量级架构(RoBERTa)处理文本块,输出固定大小向量(通常用[CLS] token或均值池化)作为块嵌入。持续预训练(CPT)期间,编码器会和投影层一起训练,学习压缩信息并最小化损失。
投影层是可学习线性层,将块嵌入转换为LLM的token嵌入空间,确保维度匹配。这让解码器注意块向量时就像处理普通词向量。
**解码器(生成器)**使用标准decoder-only LLM(LLaMA、GPT-2)自回归生成答案。REFRAG中解码器词汇表和结构不变,只是看到更短的输入:查询token加上块向量(以及展开的token)。
选择性压缩策略通过小型策略网络(MLP)决定哪些块保持单一嵌入,哪些展开为完整token。策略用REINFORCE训练:当展开某些块能降低困惑度(提高下一token准确性)时给予奖励。随时间推移,策略学会将"易压缩"上下文保持嵌入形式,只展开关键部分。
**持续预训练(CPT)**在部署前用专门的预训练方案对齐编码器与解码器。首先学习从嵌入重建文本:冻结解码器,编码块并训练投影让解码器能恢复原始token。然后通过课程学习逐步增加难度(从1个块到2个,再到更多)。这确保编码器真正捕获块含义。最后对编码器/解码器端到端微调(RAG QA、对话等任务),同时训练强化学习策略。
解码机制在标准RAG中,每个输出token都会注意所有查询和段落token。REFRAG解码时,解码器注意查询token + L个块嵌入 + 展开token。由于许多块以单一向量存在,注意力工作量大幅减少。Lin等人观察到RAG上下文呈现"块对角"稀疏性(不同块间交互少),REFRAG利用这点跳过大部分冗余token注意力。
LangChain集成思路
LangChain已经有Embeddings、VectorStore、LLM、Chains等抽象,REFRAG需要在此基础上添加几个新组件:
文档块化功能,将检索文档拆分为固定大小块。编码器+投影器模块,压缩每个块为单个嵌入并投影到LLM嵌入空间。策略网络,决定哪些块展开(传入完整token)或保持压缩。LLM的混合上下文输入处理,包含查询+压缩块嵌入+展开完整token。编码器、投影器、策略的训练流程,让压缩+展开在生成时表现良好。
LangChain默认不直接支持在LLM上下文中混合任意嵌入与完整token嵌入(特别是"可展开"策略)。但HF Transformers支持
inputs_embeds
,可以构建这个功能。
需要构建的组件包括:
ChunkEncoder
接收文本块返回嵌入,
Projector
线性层映射块嵌入空间到LLM token嵌入空间,
PolicyNetwork
给定查询嵌入与块嵌入输出每个块展开分数或选择掩码,
Retriever
与
VectorStore
获取候选文档并可选拆分为块,自定义链/LLM包装器构造混合输入、处理展开、然后用
inputs_embeds
调用LLM。
fromtypingimportList, Tuple
importtorch
importtorch.nnasnn
fromtransformersimportAutoTokenizer, AutoModel, AutoModelForCausalLM
fromlangchain.embeddingsimportEmbeddings
fromlangchain.vectorstoresimportFAISS
fromlangchain.schemaimportDocument
fromlangchain.llms.baseimportLLM # 1. ChunkEncoder + Projector + Policy Network classChunkEncoder(nn.Module): def__init__(self, encoder_model_name: str, chunk_size: int): super().__init__() self.tokenizer=AutoTokenizer.from_pretrained(encoder_model_name) self.encoder=AutoModel.from_pretrained(encoder_model_name) self.chunk_size=chunk_size defchunkify(self, text: str) ->List[str]: # simple split by whitespace / fixed tokens, you could use tokenizer toks=self.tokenizer(text, return_tensors="pt", truncation=False)["input_ids"][0] chunks= [] foriinrange(0, toks.size(0), self.chunk_size): chunk_ids=toks[i : i+self.chunk_size] chunk_text=self.tokenizer.decode(chunk_ids, skip_special_tokens=True) chunks.append(chunk_text) returnchunks defforward(self, chunk_texts: List[str]) ->torch.Tensor: # returns embeddings of shape (num_chunks, encoder_hidden_size) encodings=self.tokenizer(chunk_texts, padding=True, truncation=True, return_tensors="pt") outputs=self.encoder(**encodings) # e.g. use .pooler_output or CLS token # if model has pooler: ifhasattr(outputs, "pooler_output"): returnoutputs.pooler_output # (batch, hidden_size) else: # fallback: mean pooling last=outputs.last_hidden_state # (batch, seq, hidden) returnlast.mean(dim=1) classProjector(nn.Module): def__init__(self, input_dim: int, output_dim: int): super().__init__() self.linear=nn.Linear(input_dim, output_dim) defforward(self, chunk_embs: torch.Tensor) ->torch.Tensor: returnself.linear(chunk_embs) # maps into LLM emb dim classPolicyNetwork(nn.Module): def__init__(self, emb_dim: int, hidden_size: int=256): super().__init__() self.net=nn.Sequential( nn.Linear(emb_dim*2, hidden_size), nn.ReLU(), nn.Linear(hidden_size, 1) ) defforward(self, query_emb: torch.Tensor, chunk_embs: torch.Tensor) ->torch.Tensor: # query_emb: (emb_dim,), chunk_embs: (num_chunks, emb_dim) # produce a score per chunk q=query_emb.unsqueeze(0).expand(chunk_embs.size(0), -1) # (num_chunks, emb_dim) inp=torch.cat([q, chunk_embs], dim=1) scores=self.net(inp).squeeze(-1) # (num_chunks,) returnscores # 2. Using LangChain components classRefragChain: def__init__( self, retriever, # a LangChain retriever chunk_encoder: ChunkEncoder, projector: Projector, policy: PolicyNetwork, llm_model_name: str, llm_tokenizer_name: str, expand_ratio: float=0.25, # fraction of chunks to expand max_new_tokens: int=128 ): self.retriever=retriever self.chunk_encoder=chunk_encoder self.projector=projector self.policy=policy self.llm_tokenizer=AutoTokenizer.from_pretrained(llm_tokenizer_name) self.llm=AutoModelForCausalLM.from_pretrained(llm_model_name) self.expand_ratio=expand_ratio self.max_new_tokens=max_new_tokens defanswer(self, query: str) ->str: # 1. Retrieve documents docs: List[Document] =self.retriever.get_relevant_documents(query) # 2. Split into chunks chunk_texts= [] chunk_doc_map= [] # to know which chunk came from which doc fordindocs: chunks=self.chunk_encoder.chunkify(d.page_content) forcinchunks: chunk_texts.append(c) chunk_doc_map.append(d) # 3. Encode chunks & project chunk_embs=self.chunk_encoder(chunk_texts) # (C, enc_dim) projected=self.projector(chunk_embs) # (C, llm_emb_dim) # 4. Compute query embedding (using chunk_encoder as proxy or separate) # optionally, use same encoder withtorch.no_grad(): q_enc=self.chunk_encoder([query]) # (1, enc_dim) q_proj=self.projector(q_enc).squeeze(0) # (llm_emb_dim,) # 5. Policy: select top-k chunks to expand scores=self.policy(q_proj, chunk_embs) # (C,) k=max(1, int(self.expand_ratio*len(chunk_texts))) topk_idx=torch.topk(scores, k).indices.tolist() # 6. Prepare LLM input embeddings # a) tokenize query q_tok=self.llm_tokenizer(query, return_tensors="pt", truncation=True) q_tok_ids=q_tok["input_ids"] q_embeds=self.llm.get_input_embeddings()(q_tok_ids) # (1, q_len, llm_emb_dim) # b) For each chunk: if in topk, tokenize fully, else use projected embedding chunk_input_embeds_list= [] fori, c_textinenumerate(chunk_texts): ifiintopk_idx: # expand fully tok=self.llm_tokenizer(c_text, return_tensors="pt", truncation=True) emb=self.llm.get_input_embeddings()(tok["input_ids"]) # (1, chunk_len, emb_dim) else: # compressed: treat projection as one "special token embedding" emb=projected[i].unsqueeze(0).unsqueeze(1) # (1,1, emb_dim) chunk_input_embeds_list.append(emb) # concatenate embeddings: query + all chunk embeddings/expanded all_chunk_embeds=torch.cat(chunk_input_embeds_list, dim=1) # e.g. (1, total_chunkified_length, emb_dim) full_input_embeds=torch.cat([q_embeds, all_chunk_embeds], dim=1) # 7. Generate out=self.llm.generate( inputs_embeds=full_input_embeds, max_new_tokens=self.max_new_tokens ) answer=self.llm_tokenizer.decode(out[0], skip_special_tokens=True) returnanswer
from langchain.llms.base import LLM
from langchain.schema import LLMResult class RefragLLM(LLM): def __init__(self, refrag_chain: RefragChain): self.refrag_chain = refrag_chain def _call(self, prompt: str, stop: List[str] = None) -> str: return self.refrag_chain.answer(prompt) @property def _identifying_params(self): return {"refrag": True}
实际部署时需要注意几个关键点:训练/加载预训练的ChunkEncoder + Projector + Policy,示例中用的是随机或未训练组件,REFRAG需要预训练让压缩嵌入保留相关信息。对齐嵌入空间,确保投影后的嵌入在LLM注意时表现良好。设计RL奖励信号来训练策略,衡量展开特定块如何提高生成质量或降低困惑度。调整学习和压缩率,平衡k(块大小)和展开比例,理解性能权衡。
性能评估
REFRAG在多个长上下文任务上进行了全面评估,涵盖开放域QA、多选推理、对话和摘要等场景。
数据集覆盖相当广泛,包括RAG基准(NaturalQuestions、FEVER、TQA等)、常识推理(HellaSwag、Winogrande等)和对话/摘要任务。实验同时模拟强检索场景(只有真正top-K相关段落)和弱检索场景(大量候选中包含不相关段落)。
基线对比涵盖具有完整上下文或截断到匹配token数的LLaMA-2,以及之前的长上下文方法如CEPE和REPLUG。RAG QA任务上,研究者对LLaMA进行微调确保公平比较。
评估指标从两个维度衡量:推理速度用首token时间(TTFT)和每迭代token时间(TTIT),以及整体吞吐量(token/秒);准确性通过验证集困惑度和QA任务准确率(精确匹配/F1等)来评估。
实验结果相当令人印象深刻。REFRAG在大多数情况下实现巨大加速且准确性无损。在超长上下文的16倍压缩(k=16)下,REFRAG的TTFT比LLaMA快约16.5倍。k=32时TTFT达到约32.9倍LLaMA(≈30.85倍报告值),与论文声称的30.85倍加速基本吻合。困惑度和下游准确性基本保持不变。
在检索质量较弱的任务中,REFRAG甚至超越LLaMA性能,因为相同延迟预算下它能包含更多上下文。论文表3和图4显示REFRAG在16个RAG任务的强/弱设置中都能匹配或超越LLaMA。消融实验还表明,REFRAG的强化学习驱动选择性压缩优于简单启发式方法(比如丢弃低困惑度块)。
总的来说,REFRAG在大上下文场景下实现了超过30倍的生成加速且无准确性下降,有效地在延迟受限情况下将LLM上下文扩展约16倍。
局限性与改进空间
REFRAG最大的问题就是训练开销。因为他需要额外预训练和微调,编码器、投影层、策略都要单独训练(通过重建和课程学习任务),复杂度远超即插即用的RAG。
并且系统复杂性明显增加。新增编码器、投影层、策略网络等组件,依赖强化学习进行块选择,工程工作量大且可能需要精细调优(策略学习率等)。参考实现涉及很多超参数(块大小k、展开比例p、学习率等)。
虽然REFRAG在检索不完美时有帮助,但依然需要检索到相对相关的块。如果检索完全失效,单纯压缩无法弥补缺失的知识,也就是说他还是要以来第一步检索的准确性。
最后就是极高压缩率可能导致信息丢失,强化学习策略虽然能通过展开关键部分来缓解,但速度与保真度间仍需要权衡。实验显示REFRAG在16-32倍压缩范围内保持准确性,超出这个范围性能会下降(论文图10显示过高压缩导致更大损失)。
总结
REFRAG作为延迟敏感、知识密集任务的专门解决方案,用额外的模型训练和系统复杂性换取显著加速,这个trade-off在很多场景下是值得的。如论文所说,“REFRAG…无需修改LLM架构”,意味着一旦编码器/投影对齐,就能与任何解码器模型配合使用。
从长远看,随着编码器预训练技术和强化学习策略的持续改进,REFRAG的训练复杂度可能会降低,而性能收益会进一步提升。这种思路也为其他需要处理长序列的AI应用提供了参考。
论文:
https://arxiv.org/abs/2509.01092
作者:DhanushKumar